对于在python数组中排序日期感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍python中数组排序函数,并为您提供关于perl–在Unix中排序日期/时间、python–根据另一个数组中的数
对于在python数组中排序日期感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍python中数组排序函数,并为您提供关于perl – 在Unix中排序日期/时间、python – 根据另一个数组中的数据对numpy数组进行排序、python数据分析(二) python numpy--数组和矢量运算--数组对象、Python数据结构与算法之常见的分配排序法示例【桶排序与基数排序】_python的有用信息。
本文目录一览:- 在python数组中排序日期(python中数组排序函数)
- perl – 在Unix中排序日期/时间
- python – 根据另一个数组中的数据对numpy数组进行排序
- python数据分析(二) python numpy--数组和矢量运算--数组对象
- Python数据结构与算法之常见的分配排序法示例【桶排序与基数排序】_python
")
在python数组中排序日期(python中数组排序函数)
如何在python 2.4上对以下日期数组进行排序
timestamps = [''2011-06-2'', ''2011-08-05'', ''2011-02-04'', ''2010-1-14'', ''2010-12-13'', ''2010-1-12'', ''2010-2-11'', ''2010-2-07'', ''2010-12-02'', ''2011-11-30'', ''2010-11-26'', ''2010-11-23'', ''2010-11-22'', ''2010-11-16'']答案1
小编典典sorted(timestamps, key=lambda d: map(int, d.split(''-'')))
perl – 在Unix中排序日期/时间
2012-07-24 10:05:08 AM 2012-07-26 10:13:58 AM 2012-07-24 10:13:58 AM 2012-07-24 10:57:50 AM 2012-07-24 11:15:03 AM 2012-07-24 11:26:08 PM 2012-07-25 11:26:08 PM
期望的输出
2012-07-24 10:05:08 AM 2012-07-24 10:13:58 AM 2012-07-24 10:57:50 AM 2012-07-24 11:15:03 AM 2012-07-24 11:26:08 PM 2012-07-25 11:26:08 PM 2012-07-26 10:13:58 AM
我试过的代码
sort -t ":" -k 1 -k 2 -k 3 Input.txt | sort -t " " -k 3
但我没有得到理想的输出.
谁能提出任何建议?
我写了一段代码……但问题仍然存在……
码
sed 's/ 12:/00:/g' Input.txt | sort -k 1,1 -k 3,3 -k 2,2 | sed 's/00:/12:/g'
首先改变上午12:43:01到00:43:01 ….然后应用sort命令.
解决方法
假设您的数据存储在/ tmp / foo中,您可以将时间戳转换为具有GNU日期的数字可排序格式.例如:
date -f /tmp/foo '+%s' | sort |
while read; do
date -d "@$REPLY" "+%F %I:%M:%s %p"
done
这应该在所有情况下正确处理排序,特别是在所有AM时间应该在同一日期的所有PM时间之前的情况下.例如,上午12:01现在在晚上10:00之前列出.

python – 根据另一个数组中的数据对numpy数组进行排序
data = np.array([[0,1,0],[1,[0,1]]) result = np.array([[0,1],0]]) # this is what the final sorted array should look like: '''''' array([[0,0]]) ''''''
我已经尝试做argsort以便将数据转换为排序顺序然后将其应用于结果但是argsort似乎根据每个元素对数组的顺序进行排序,而我希望排序处理数据的每一行[:,4]作为一个整体.
ind = np.argsort(data) indind =np.argsort(ind) ind array([[0,2,3,2],3]])
按行排序的好方法是什么?
解决方法
这是一种方法,将每一行视为索引元组,然后在数据和结果之间找到与这些线性索引等价物相对应的匹配索引.这些索引将表示行的新顺序,当将其索引到结果中时,将为我们提供所需的输出.实现看起来像这样 –
# Slice out from result everything except the last column r = result[:,:-1] # Get linear indices equivalent of each row from r and data ID1 = np.ravel_multi_index(r.T,r.max(0)+1) ID2 = np.ravel_multi_index(data.T,r.max(0)+1) # Search for ID2 in ID1 and use those indices index into result out = result[np.where(ID1[:,None] == ID2)[1]]
方法#2
如果保证数据中的所有行都在结果中,您可以使用另一种基于argsort的方法,如下所示 –
# Slice out from result everything except the last column r = result[:,r.max(0)+1) sortidx_ID1 = ID1.argsort() sortidx_ID2 = ID2.argsort() out = result[sortidx_ID1[sortidx_ID2]]
示例运行更一般的案例 –
In [37]: data
Out[37]:
array([[ 3,5],[ 4,9,4],[ 7,11],[ 5,4,4]])
In [38]: result
Out[38]:
array([[ 7,11,55],8],[ 3,5,7],88]])
In [39]: r = result[:,:-1]
...: ID1 = np.ravel_multi_index(r.T,r.max(0)+1)
...: ID2 = np.ravel_multi_index(data.T,r.max(0)+1)
...:
In [40]: result[np.where(ID1[:,None] == ID2)[1]] # Approach 1
Out[40]:
array([[ 3,88]])
In [41]: sortidx_ID1 = ID1.argsort() # Approach 2
...: sortidx_ID2 = ID2.argsort()
...:
In [42]: result[sortidx_ID1[sortidx_ID2]]
Out[42]:
array([[ 3,88]])
 python numpy--数组和矢量运算--数组对象")
python数据分析(二) python numpy--数组和矢量运算--数组对象
Numpy
numpy是数值计算最重要的基础包,几乎所有的科学运算的模块底层所用的都是numpy数组。
Numpy本身没有提供多么高级的数据分析功能,他所提供的功能主要是:
1.具有矢量算术运算(用数组表达式代替循环的做法通常称为矢量化),矢量化计算因为不使用循环,因此速度会快1到两个数量级
2.广播。(不同大小的数组之间的运算)
3.提供了对整组数据进行快速运算的标准函数。
4.用于读写磁盘数据的工具以及操作内存映射文件的工具(将数组保存及读取为文件,mmap系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read(),write()等操作)
5.线性代数,随机数生成,以及傅里叶变换的功能。
Numpy 和pandas的dataframe
NumPy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
Numpy本身没有提供多少数据分析功能,但是理解Numpy数组以及面向数组的计算会有助于更加高效的使用pandas等科学计算和数据分析工具。
Numpy数组
本篇我们将主要讨论数组对象ndarray以及如何创建一个数组对象。
(1)ndarray对象
numpy当中的数组是一个ndarray对象,ndarray对象是用于存放同类型元素的多维数组,是numpy中的基本对象之一,另一个是func对象。ndarray 中的每个元素在内存中都有相同存储大小的区域,而且
Numpy 就是 C 的逻辑, 创建存储容器 “Array” 的时候是寻找内存上的一连串区域来存放, 而 Python 存放的时候则是不连续的区域, 这使得 Python 在索引这个容器里的数据时不是那么有效率。

以下是一个例子,比较含有100万的整数的list和array全部乘以2的时间
In [7]: import numpy as np
In [8]: my_arr = np.arange(1000000)
In [9]: my_list = list(range(1000000))list对象和array数组对象中的元素全部乘以2.
In [10]: %time for _ in range(10): my_arr2 = my_arr * 2
CPU times: user 20 ms, sys: 50 ms, total: 70 ms
Wall time: 72.4 ms
In [11]: %time for _ in range(10): my_list2 = [x * 2 for x in my
_list]
CPU times: user 760 ms, sys: 290 ms, total: 1.05 s
Wall time: 1.05 sndarray 内部由以下内容组成:
-
一个指向数据(内存或内存映射文件中的一块数据)的指针。
-
数据类型或 dtype,描述在数组中的固定大小值的格子。
-
一个表示数组形状(shape)的元组,表示各维度大小的元组。
-
一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数,默认创建array是以row即order=C方式创建,所以此处的跨度元组默认指的是每一行的字节数。
a = np.array([[0,1,2],[3,4,5],[6,7,8]], dtype=np.float32)
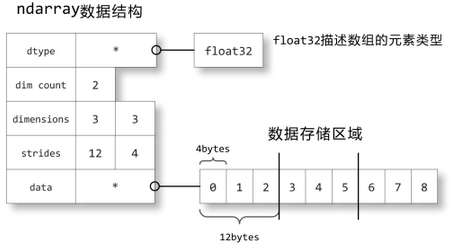
数据存储区域保存着数组中所有元素的二进制数据,dtype对象则知道如何将元素的二进制数据转换为可用的值。数组的维数、大小等信息都保存在ndarray数组对象的数据结构中。
strides中保存的是当每个轴的下标增加1时,数据存储区中的指针所增加的字节数。例如图中的strides为12,4,即第0轴的下标增加1时,数据的地址增加12个字节:即a[1,0]的地址比a[0,0]的地址要高12个字节,正好是3个单精度浮点数的总字节数;第1轴下标增加1时,数据的地址增加4个字节,正好是单精度浮点数的字节数
(2)创建ndarray
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
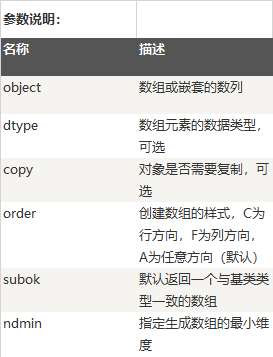
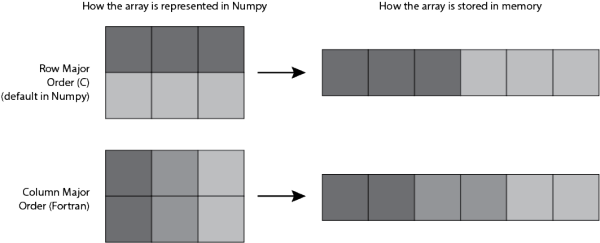
特别需要解释的是order,在我们看来的 2D Array, 如果追溯到计算机内存里, 它其实是储存在一个连续空间上的. 而对于这个连续空间, 我们如果创建 Array 的方式不同, 在这个连续空间上的排列顺序也有不同. 这将影响之后所有的事情! 我们后面会用 Python 进行运算时间测试.
在 Numpy 中, 创建 2D Array 的默认方式是 “C-type” 以 row 为主在内存中排列, 而如果是 “Fortran” 的方式创建的, 就是以 column 为主在内存中排列
a = np.zeros((200, 200), order=''C'')
b = np.zeros((200, 200), order=''F'')
N = 9999
def f1(a):
for _ in range(N):
np.concatenate((a, a), axis=0)
def f2(b):
for _ in range(N):
np.concatenate((b, b), axis=0)
t0 = time.time()
f1(a)
t1 = time.time()
f2(b)
t2 = time.time()
print((t1-t0)/N) # 0.000040
print((t2-t1)/N) # 0.000070
row 为主的存储方式, 如果在 row 的方向上合并矩阵, 将会更快. 因为只要我们将思维放在 1D array 那, 直接再加一个 row 放在1D array 后面就好了, 所以在上面的测试中, f1 速度要更快. 但是在以 column 为主的系统中, 往 1D array 后面加 row 的规则变复杂了, 消耗的时间也变长. 如果以 axis=1 的方式合并, “F” 方式的 f2 将会比 “C” 方式的 f1 更好。
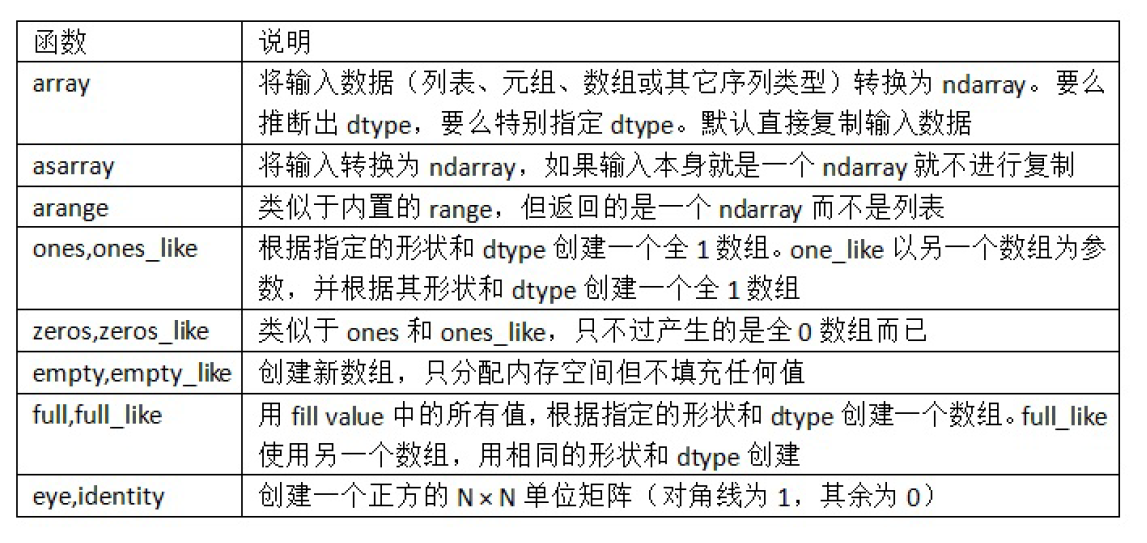
创建数组的其他方式:
np.zeros,np.empty,np.ones 都可以分别用来创建全为0的数组,为空的数组(只分配内存空间不赋值),全为一的数组等。
In [29]: np.zeros(10)
Out[29]: array([ 0.,
0.,
0.,
0.,
0.,
0.,
0.,
0.,
0.,
0.
])
In [30]: np.zeros((3, 6))
Out[30]:
array([[ 0.,
0.,
0.,
0.,
0.,
0.],
[ 0.,
0.,
0.,
0.,
0.,
0.],
[ 0.,
0.,
0.,
0.,
0.,
0.]])
In [31]: np.empty((2, 3, 2))
Out[31]:
array([[[ 0.,
0.],
[ 0.,
0.],
[ 0.,
0.]],
[[ 0.,
0.],
[ 0.,
0.],
[ 0.,
0.]]])下表列出了其他的一些用于创建数组的函数
NumPy 数据类型
numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。下表列举了常用 NumPy 基本类型。
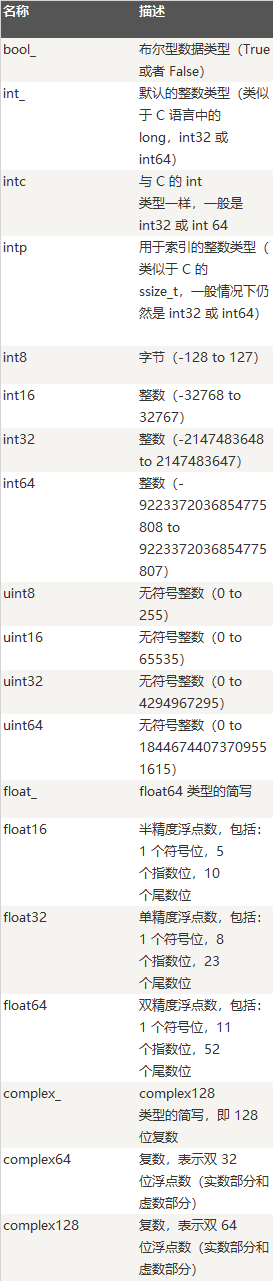
对于narray对象的dtype定义有两种方式,一种是在创建时,第二种是使用astype函数进行修改,当你创建numpy的数组对象且没有指定dtype,np.arrary会尝试为这个新建的数组推断出一个合适的类型,因为ndarray面向的是数值运算,默认创建的类型都是float64(浮点数)。
使用astype方法进行转换:
In [37]: arr = np.array([1, 2, 3, 4, 5])
In [38]: arr.dtype
Out[38]: dtype(''int64'')
In [39]: float_arr = arr.astype(np.float64)
In [40]: float_arr.dtype
Out[40]: dtype(''float64'')

Python数据结构与算法之常见的分配排序法示例【桶排序与基数排序】_python
这篇文章主要介绍了
箱排序(桶排序)
箱排序是根据关键字的取值范围1~m,预先建立m个箱子,箱排序要求关键字类型为有限类型,可能会有无限个箱子,实用价值不大,一般用于基数排序的中间过程。
桶排序是箱排序的实用化变种,其对数据集的范围,如[0,1) 进行划分为n个大小相同的子区间,每一个子区间为一个桶,然后将n非记录分配到各桶中。因为关键字序列是均匀分布在[0,1)上的,所以一般不会有很多记录落入同一个桶中。
以下的桶排序方法采用字典实现,所以对于整数类型,并不需要建立多余空间
立即学习“Python免费学习笔记(深入)”;
def BuckSort(A): bucks = dict() # 桶 for i in A: bucks.setdefault(i,[]) # 每个桶默认为空列表 bucks[i].append(i) # 往对应的桶中添加元素 A_sort = [] for i in range(min(A), max(A)+1): if i in bucks: # 检查是否存在对应数字的桶 A_sort.extend(bucks[i]) # 合并桶中数据 return A_sort
基数排序
# 基数排序
# 输入:待排序数组s, keysize关键字位数, 亦即装箱次数, radix基数
def RadixSort(s, keysize=4, radix=10):
# 按关键字的第k分量进行分配 k = 4,3,2,1
def distribute(s,k):
box = {r:[] for r in range(radix)} # 分配用的空箱子
for item in s: # 依次扫描s[],将其装箱
t = item
t /= 10**(k-1)
t %= 10 # 去关键字第k位
box[t].append(item)
return box
# 按分配结果重新排列数据
def collect(s,box):
a = 0
for i in range(radix):
s[a:a + len(box[i])] = box[i][:] # 将箱子中元素的合并,覆盖到原来的数组中
a += len(box[i]) # 增加偏移值
# 核心算法
for k in range(1,keysize+1):
box = distribute(s,k) # 按基数分配
collect(s,box) # 按分配结果拼合以下摘自:《数据结构与算法——理论与实践》
基数排序可以拓展为按多关键字排序,如对扑克牌按花色、按点数排序。
一般地,设线性表有那个待排序元素,每个元素包含d个关键字{k1,k2,...,kd},则该线性表对关键字有序指,对于线性表中任意两个元素r[i]和r[j],1 {k1i,k2i,...,kdi} 其中k1称为最主位关键字,kd称为最次位关键字
其排序方法分两种:最高位优先MSD(most significant digit frist)与最低位优先LSD(least significant digit first)
MSD: 先按k1排序分组,同一组的个元素,若关键字k1相等,再对各组按k2排序分成子组,依次类推,直到最次位kd对各子组排序后,再将各组链接起来。
LSD: 与MSD相反,先按kd排序,再对kd-1排序,依次类推。
PS:这里再为大家推荐一款关于排序的演示工具供大家参考:
在线动画演示插入/选择/冒泡/归并/希尔/快速排序算法过程工具:
http://tools.jb51.net/aideddesign/paixu_ys
以上就是本文所有的内容了,希望可以给大家带来帮助!!
相关推荐:
Python实现字符串匹配算法实例代码
Python爬虫入门心得分享
python中关于logging库的使用总结
以上就是Python数据结构与算法之常见的分配排序法示例【桶排序与基数排序】_
关于在python数组中排序日期和python中数组排序函数的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于perl – 在Unix中排序日期/时间、python – 根据另一个数组中的数据对numpy数组进行排序、python数据分析(二) python numpy--数组和矢量运算--数组对象、Python数据结构与算法之常见的分配排序法示例【桶排序与基数排序】_python的相关知识,请在本站寻找。
本文标签:




