本文的目的是介绍为什么我不能在JBoss上的Solr中实例化DataImportHandler?的详细情况,特别关注solrjdbc的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现
本文的目的是介绍为什么我不能在JBoss上的Solr中实例化DataImportHandler?的详细情况,特别关注solr jdbc的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解为什么我不能在JBoss上的Solr中实例化DataImportHandler?的机会,同时也不会遗漏关于Apache Solr DataImportHandler远程代码执行漏洞(CVE-2019-0193) 分析、import mysql data to solr4.2.0、java – 为什么我不能在我的ArrayList上调用Collections.sort()?、Java:为什么我不能在Comparator中抛出异常?的知识。
本文目录一览:- 为什么我不能在JBoss上的Solr中实例化DataImportHandler?(solr jdbc)
- Apache Solr DataImportHandler远程代码执行漏洞(CVE-2019-0193) 分析
- import mysql data to solr4.2.0
- java – 为什么我不能在我的ArrayList上调用Collections.sort()?
- Java:为什么我不能在Comparator中抛出异常?
")
为什么我不能在JBoss上的Solr中实例化DataImportHandler?(solr jdbc)
我正在尝试在JBoss 5.1上设置Solr 3.5.0。一切正常。我将war复制到deploy
dir中,将dist和contrib目录中的所有依赖项都复制到lib(或更早的deploy)目录中。
我可以启动服务器,一切正常,但是每当我想激活DataImportHandler来索引数据库中的数据时,都会出现错误。
基本上,我要做的是复制是从example / example-DIH / solr /
db复制一个核心(或者整个示例,都没关系),我在solr.xml中注册了核心,并且在启动时出现错误:
15:17:10,707 SEVERE [RequestHandlers] org.apache.solr.common.SolrException: Error Instantiating Request Handler, org.apache.solr.handler.dataimport.DataImportHandler is not a org.apache.solr.request.SolrRequestHandlerat org.apache.solr.core.SolrCore.createInstance(SolrCore.java:427)at org.apache.solr.core.SolrCore.createRequestHandler(SolrCore.java:461)at org.apache.solr.core.RequestHandlers.initHandlersFromConfig(RequestHandlers.java:157)我很确定我的请求处理程序定义正确,但是请确保:
<requestHandler name="/dataimport"><lst name="defaults"> <str name="config">dataimport.xml</str></lst>据我所知,此错误可能是由DataImportHandler和SolrRequestHandler可能持有不同的类加载器引起的。
在示例中,每当我从start.jar应用程序启动Solr时(我认为它会启动Jetty服务器),它都可以正常工作。
我的问题是:这是否真的是由于类加载器问题或其他原因引起的?而且,更重要的是:我该如何解决?
答案1
小编典典这是一个类加载器问题,根据Lucene Developer Mailing
List上的这篇文章,您需要执行以下操作:
确保dataimport罐不在类路径中,并且不是由其他类加载器加载,而是从solrconfig.xml中指定的路径加载。这将确保由相同的类加载器加载数据导入类。
请参阅主题以获取更多详细信息。
 分析")
Apache Solr DataImportHandler远程代码执行漏洞(CVE-2019-0193) 分析
作者:Longofo@知道创宇404实验室
时间:2019年8月8日
原文链接
漏洞概述
2019年08月01日,Apache Solr官方发布预警,Apache Solr DataImport功能 在开启Debug模式时,可以接收来自请求的"dataConfig"参数,这个参数的功能与data-config.xml一样,不过是在开启Debug模式时方便通过此参数进行调试,并且Debug模式的开启是通过参数传入的。在dataConfig参数中可以包含script恶意脚本导致远程代码执行。
我对此漏洞进行了应急,由于在应急时构造的PoC很鸡肋,需要存在数据库驱动,需要连接数据库并且无回显,这种方式在实际利用中很难利用。后来逐渐有新的PoC被构造出来,经过了几个版本的PoC升级,到最后能直接通过直接传递数据流的方式,无需数据库驱动,无需连接数据库且能回显。下面记录下PoC升级的历程以及自己遇到的一些问题。感谢@Badcode与@fnmsd师傅提供的帮助。
测试环境
分析中涉及到的与Solr相关的环境如下:
- Solr-7.7.2
- JDK 1.8.0_181
相关概念
一开始没有去仔细去查阅Solr相关资料,只是粗略翻了下文档把漏洞复现了,那时候我也觉得数据应该能回显,于是就开始调试尝试构造回显,但是没有收获。后来看到新的PoC,感觉自己还没真正明白这个漏洞的原理就去盲目调试,于是又回过头去查阅Solr资料与文档,下面整理了与该漏洞有关的一些概念。
Solr工作机制
1.solr是在lucene工具包的基础之上进行了封装,并且以web服务的形式对外提供索引功能
2.业务系统需要使用到索引的功能(建索引,查索引)时,只要发出http请求,并将返回数据进行解析即可
(1) 索引数据的创建
根据配置文件提取一些可以用来搜索的数据(封装成各种Field),把各field再封装成document,然后对document进行分析(对各字段分词),得到一些索引目录写入索引库,document本身也会被写入一个文档信息库
(2) 索引数据的查询
根据关键词解析(queryParser)出查询条件query(Termquery),利用搜索工具(indexSearcher)去索引库获取文档id,然后再根据文档id去文档信息库获取文档信息
Solr DataImportHandler
Solr DataImportHandler可以批量把数据导入到索引库中,根据Solr文档中的描述,DataImportHandler有如下功能:
- 读取关系数据库中数据或文本数据
- 根据配置从xml(http/file方式)读取与建立索引数据
- 根据配置聚合来自多个列和表的数据来构建Solr文档
- 使用文档更新Solr(更新索引、文档数据库等)
- 根据配置进行完全导入的功能(full-import,完全导入每次运行时会创建整个索引)
- 检测插入/更新字段并执行增量导入(delta-import,对增加或者被修改的字段进行导入)
- 调度full-import与delta-import
- 可以插入任何类型的数据源(ftp,scp等)和其他用户可选格式(JSON,csv等)
通过搜索到的资料与官方文档中对DataImportHandler的描述,根据我的理解整理出DataImport处理的大致的流程图如下(只画了与该漏洞相关的主要部分):
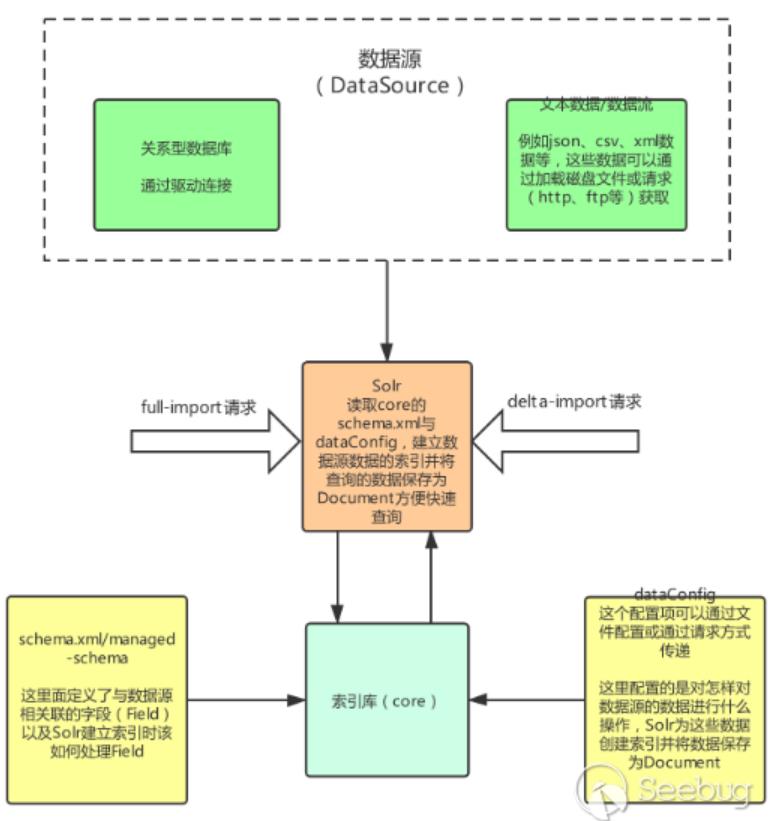
几个名词解释:
- Core:索引库,其中包含schema.xml/managed-schema,schema.xml是模式文件的传统名称,可以由使用该模式的用户手动编辑,managed-schema是Solr默认使用的模式文件的名称,它支持在运行时动态更改,data-config文件可配置为xml形式或通过请求参数传递(在dataimport开启debug模式时可通过dataConfig参数传递)
通过命令行创建core
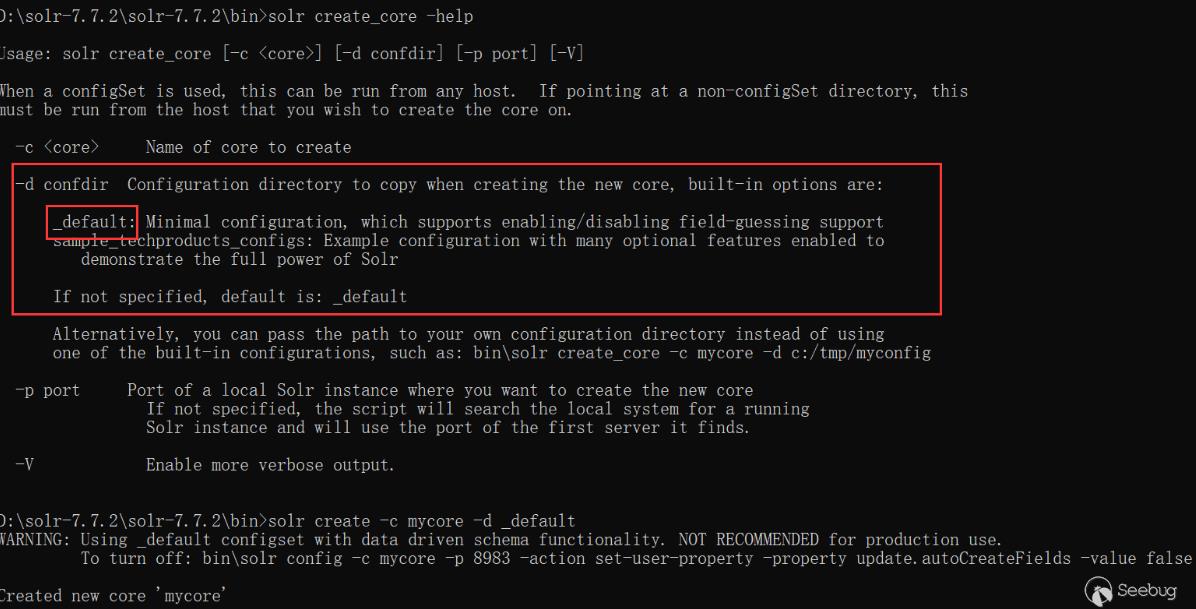
-d 参数是指定配置模板,在solr 7.7.2下,有_default与sample_techproducts_configs两种模板可以使用

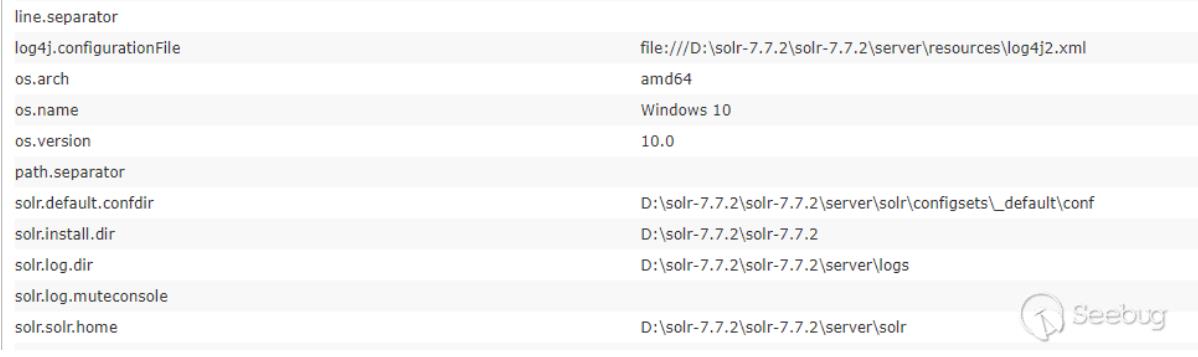
通过web页面创建core
一开始以为从web页面无法创建core,虽然有一个Add Core,但是点击创建的core目录为空无法使用,提示无法找到配置文件,必须在solr目录下创建好对应的core,在web界面才能添加。然后尝试了使用绝对路径配置,绝对路径也能在web界面看到,但是solr默认不允许使用除了创建的core目录之外的配置文件,如果这个开关设为了true,就能使用对应core外部的配置文件:
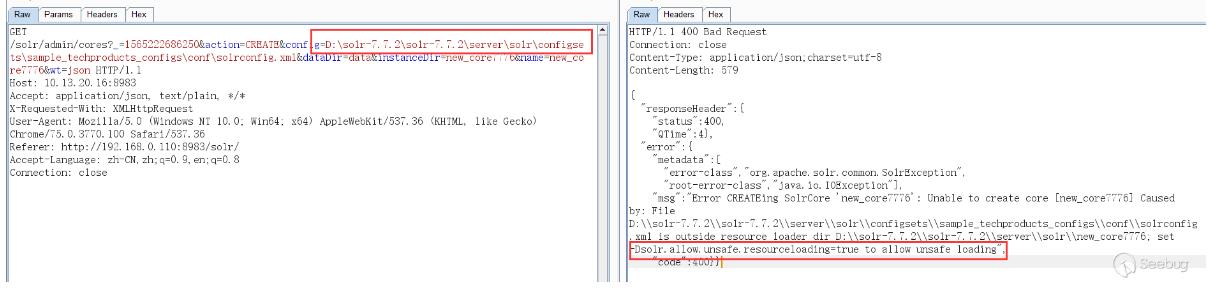
后来在回头去查阅时在Solr Guide 7.5文档中发现通过configSet参数也能创建core,configSet可以指定为_default与sample_techproducts_configs,如下表示创建成功,不过通过这种方式创建的core的没有conf目录,它的配置是相当于链接到configSet模板的,而不是使用copy模板的方式:

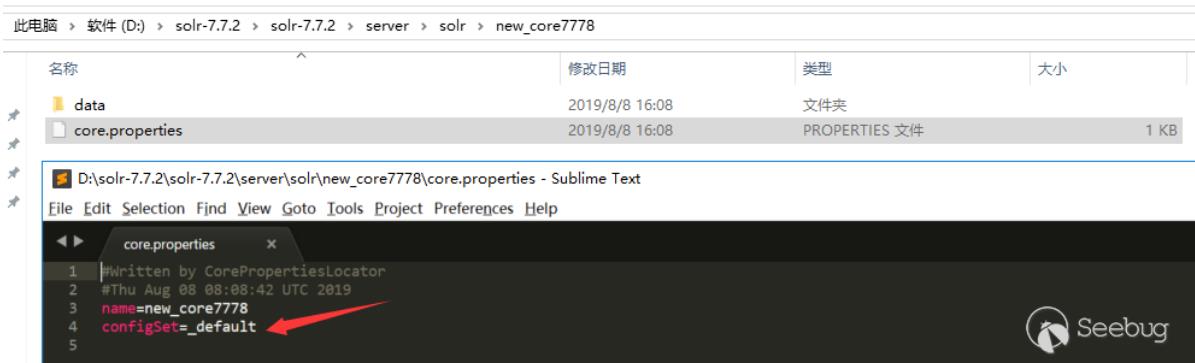
通过以上两种方式都能创建core,但是要使用dataimport功能,还是需要编辑配置solrconfig.xml文件,如果能通过web请求方式更改配置文件以配置dataimport功能就能更好利用这个漏洞了。
schema.xml/managed-schema:这里面定义了与数据源相关联的字段(Field)以及Solr建立索引时该如何处理Field,它的内容可以自己打开新建的core下的schema.xml/managed-schema看下,内容太长就不贴了,解释下与该漏洞相关的几个元素:
Field: 域的定义,相当于数据源的字段
Name:域的名称
Type:域的类型
Indexed:是否索引
Stored:是否存储
multiValued:是否多值,如果是多值在一个域中可以保持多个值
example:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="name" type="string" indexed="true" stored="true" required="true" multiValued="false" />
dynamicField:动态域,PoC最后一个阶段便是根据这个字段回显的
动态字段定义允许使用约定优于配置,对于字段,通过模式规范来匹配字段名称
示例:name ="*_i"将匹配dataConfig中以_i结尾的任何字段(如myid_i,z_i)
限制:name属性中类似glob的模式必须仅在开头或结尾处具有"*"。
这里的含义就是当dataConfig插入数据发现某一个域没有定义时,这时可以使用动态域当作字段名称 进行数据存储,这个会在后面PoC的进化中看到
example:
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
<dynamicField name="*_is" type="pints" indexed="true" stored="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="strings" indexed="true" stored="true"/>
<dynamicField name="*_l" type="plong" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="plongs" indexed="true" stored="true"/>
dataConfig:这个配置项可以通过文件配置或通过请求方式传递(在dataimport开启Debug模式时可以通过dataConfig参数),他配置的时怎样获取数据(查询语句、url等等)要读什么样的数据(关系数据库中的列、或者xml的域)、做什么样的处理(修改/添加/删除)等,Solr为这些数据数据创建索引并将数据保存为Document
对于此漏洞需要了解dataConfig的以下几个元素:
Transformer:实体提取的每组字段可以在索引过程直接使用,也可以使用来修改字段或创建一组全新的字段, 甚至可以返回多行数据。必须在entity级别上配置Transformer
RegexTransformer:使用正则表达式从字段(来自源)提取或操作值
ScriptTransformer:可以用Javascript或Java支持的任何其他脚本语言编写 Transformer,该漏洞使用的是这个
DateFormatTransformer:用于将日期/时间字符串解析为java.util.Date实例
NumberFormatTransformer:可用于解析String中的数字
TemplateTransformer:可用于覆盖或修改任何现有的Solr字段或创建新的Solr字段
HTMLStripTransformer:可用于从字符串字段中删除HTML
ClobTransformer:可用于在数据库中创建Clob类型的String
LogTransformer:可用于将数据记录到控制台/日志
EntityProcessor:实体处理器
SqlEntityProcessor:不指定时,默认的处理器
XPathEntityProcessor:索引XML类型数据时使用
FileListEntityProcessor:一个简单的实体处理器,可用于根据某些条件枚举文件系统中的文件 列表
CachedSqlEntityProcessor:SqlEntityProcessor的扩展
PlainTextEntityProcessor:将数据源中的所有内容读入名 为"plainText"的单个隐式字段。内容不会以任何方式解析,但是 您可以根据需要添加transform来操作“plainText”中的数据
LineEntityProcessor:为每行读取返回一个名为"rawLine"的字段。内容不会以任何方式解析, 但您可以添加transform来操作“rawLine”中的数据或创建其他附加字段
SolrEntityProcessor:从不同的Solr实例和核心导入数据
dataSource:数据源,他有以下几种类型,每种类型有自己不同的属性
JdbcDataSource:数据库源
URLDataSource:通常与XPathEntityProcessor配合使用,可以使用file://、http://、 ftp://等协议获取文本数据源
HttpDataSource:与URLDataSource一样,只是名字不同
FileDataSource:从磁盘文件获取数据源
FieldReaderDataSource:如果字段包含xml信息时,可以使用这个配合XPathEntityProcessor 使用
ContentStreamDataSource:使用post数据作为数据源,可与任何EntityProcessor配合使用
Entity:实体,相当于将数据源的操作的数据封装成一个Java对象,字段就对应对象属性
对于xml/http数据源的实体可以在默认属性之上具有以下属性:
processor(必须):值必须是 "XPathEntityProcessor"
url(必须):用于调用REST API的URL。(可以模板化)。如果数据源是文件,则它必须是文件位置
stream (可选):如果xml非常大,则将此值设置为true
forEach(必须):划分记录的xpath表达式。如果有多种类型的记录用“|”(管道)分隔它们。如果 useSolrAddSchema设置为''true'',则可以省略。
xsl(可选):这将用作应用XSL转换的预处理器。提供文件系统或URL中的完整路径。
useSolrAddSchema(可选):如果输入到此处理器的xml具有与solr add xml相同的模式,则将其 值设置为“true”。如果设置为true,则无需提及任何字段。
flatten(可选):如果设置为true,则无论标签名称如何,所有标签下的文本都将提取到一个字段中
实体的field可以具有以下属性:
xpath(可选):要映射为记录中的列的字段的xpath表达式。如果列不是来自xml属性(是由变换器 创建的合成字段),则可以省略它。如果字段在模式中标记为多值,并且在xpath的 给定行中找到多个值,则由XPathEntityProcessor自动处理。无需额外配置
commonField:可以是(true | false)。如果为true,则在创建Solr文档之前,记录中遇到的此 字段将被复制到其他记录
PoC进化历程
PoC第一阶段--数据库驱动+外连+无回显
根据官方漏洞预警描述,是DataImportHandler在开启Debug模式时,能接收dataConfig这个参数,这个参数的功能与data-config.xml一样,不过是在开启Debug模式时方便通过此参数进行调试,并且Debug模式的开启是通过参数传入的。在dataConfig参数中可以包含script脚本,在文档搜到一个ScriptTransformer的例子:
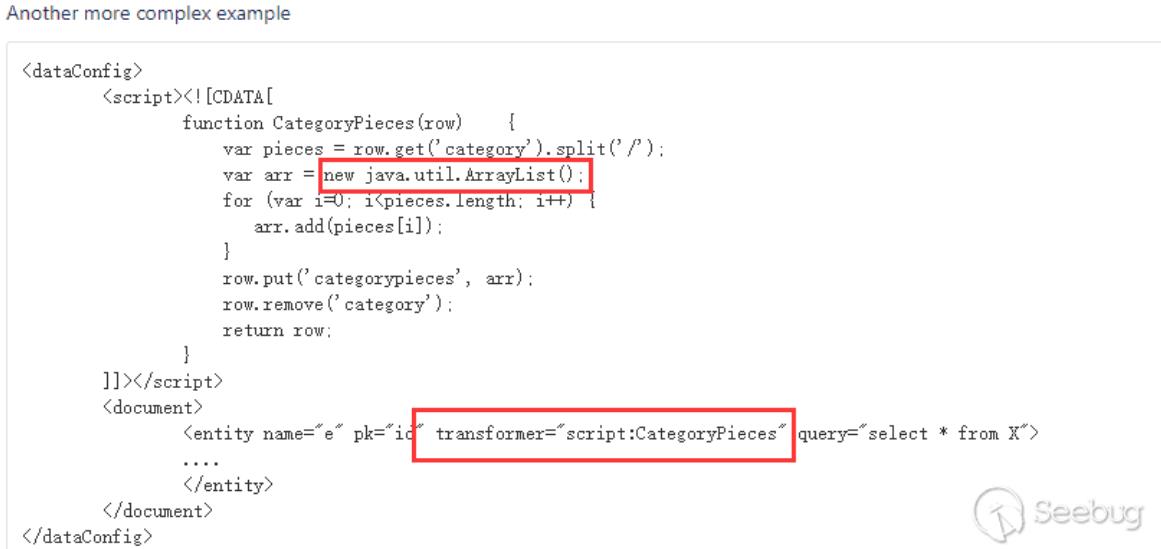
可以看到在script中能执行java代码,于是构造下PoC(通过logs查看相关报错信息查看PoC构造出现的问题),这个数据库是可以外连的,所以数据库的相关信息可以自己控制,测试过是可以的(只是演示使用的127.0.0.1):
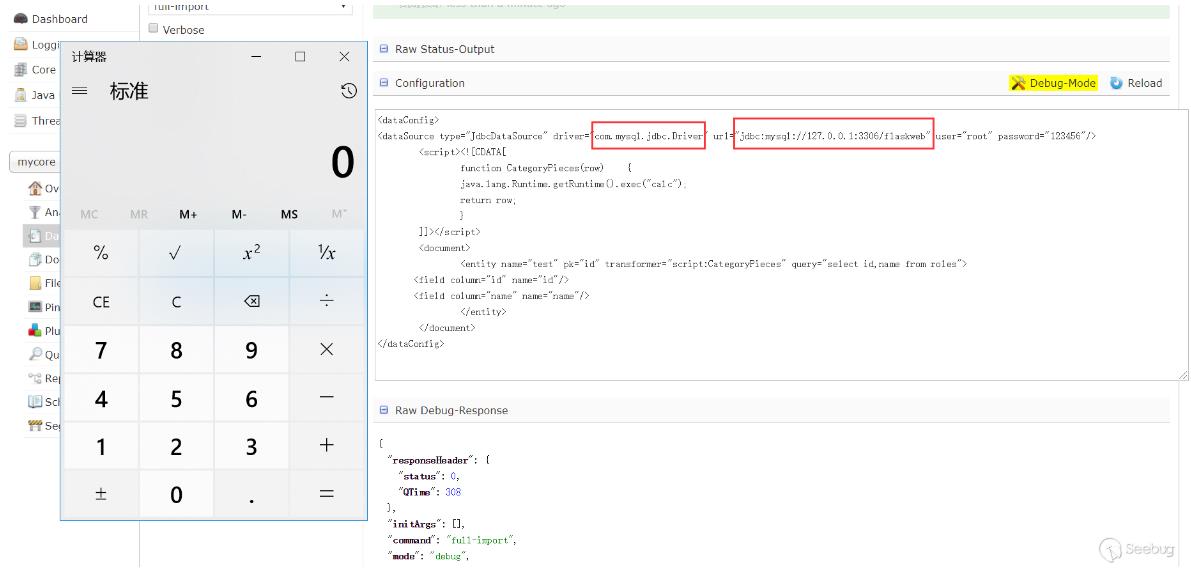
在ScriptTransformer那个例子中,能看到row.put的字样,猜测应该是能回显的,测试下:
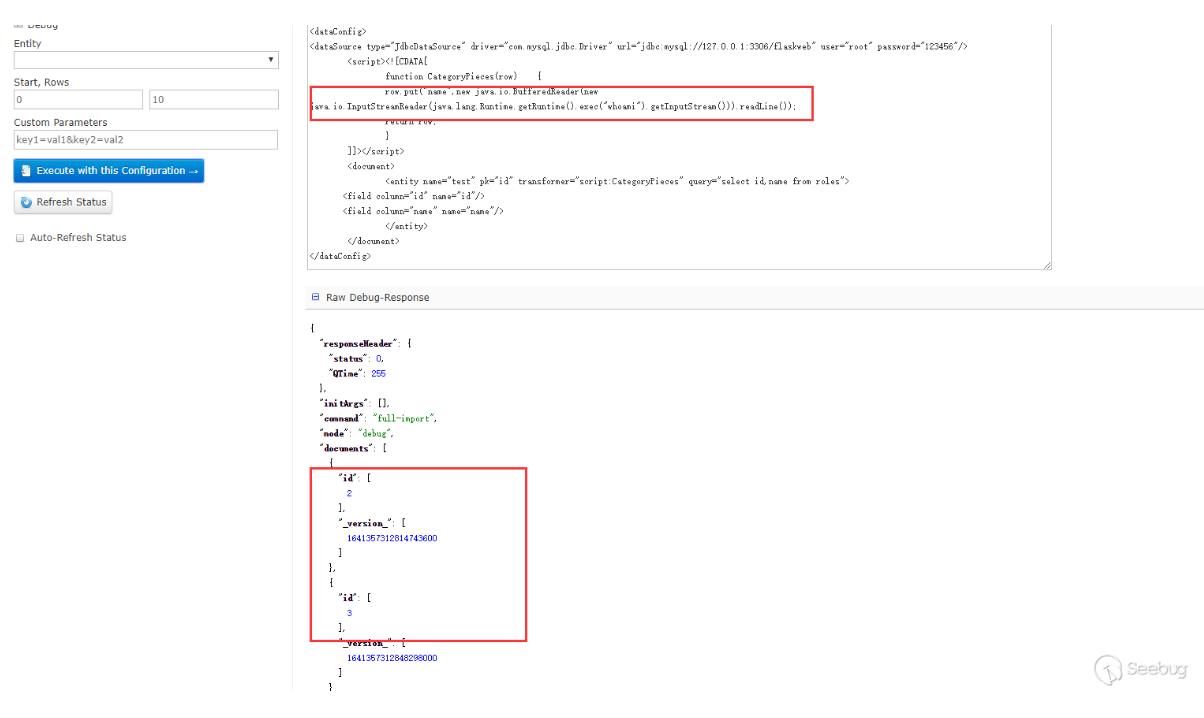
这里只能查看id字段,name字段看不到,也没有报错,然后尝试了下把数据put到id里面:
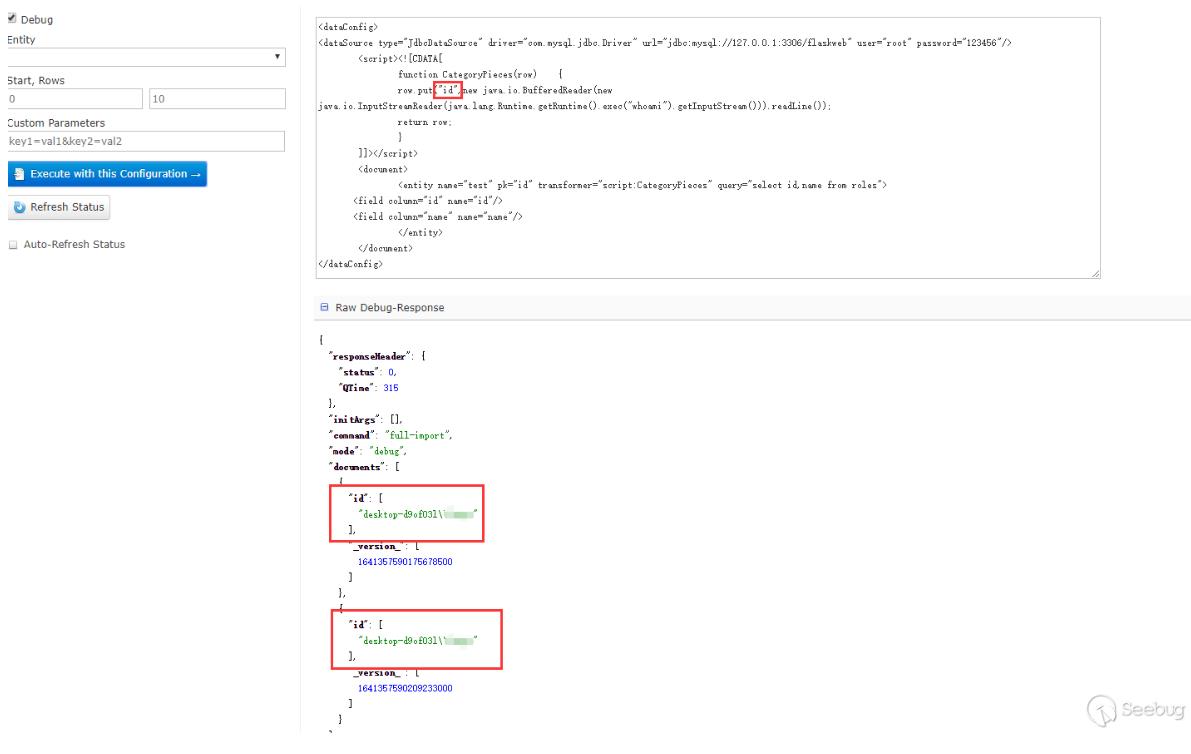
能看到回显的信息。一开始不知道为什么put到name不行,后来看到在第三阶段的PoC,又回过头去查资料才意识到dataConfig与schema是配合使用的。因为在schema中没有配置name这个field,但是默认配置了id这个fileld,所以solr不会把name这个字段数据放到Document中去而id字段在其中。在第三阶段的PoC中,每个Field中的name属性都有"_s",然后去搜索发现可以在schema配置文件中可以配置dynamicField,如下是默认配置好的dynamicField:
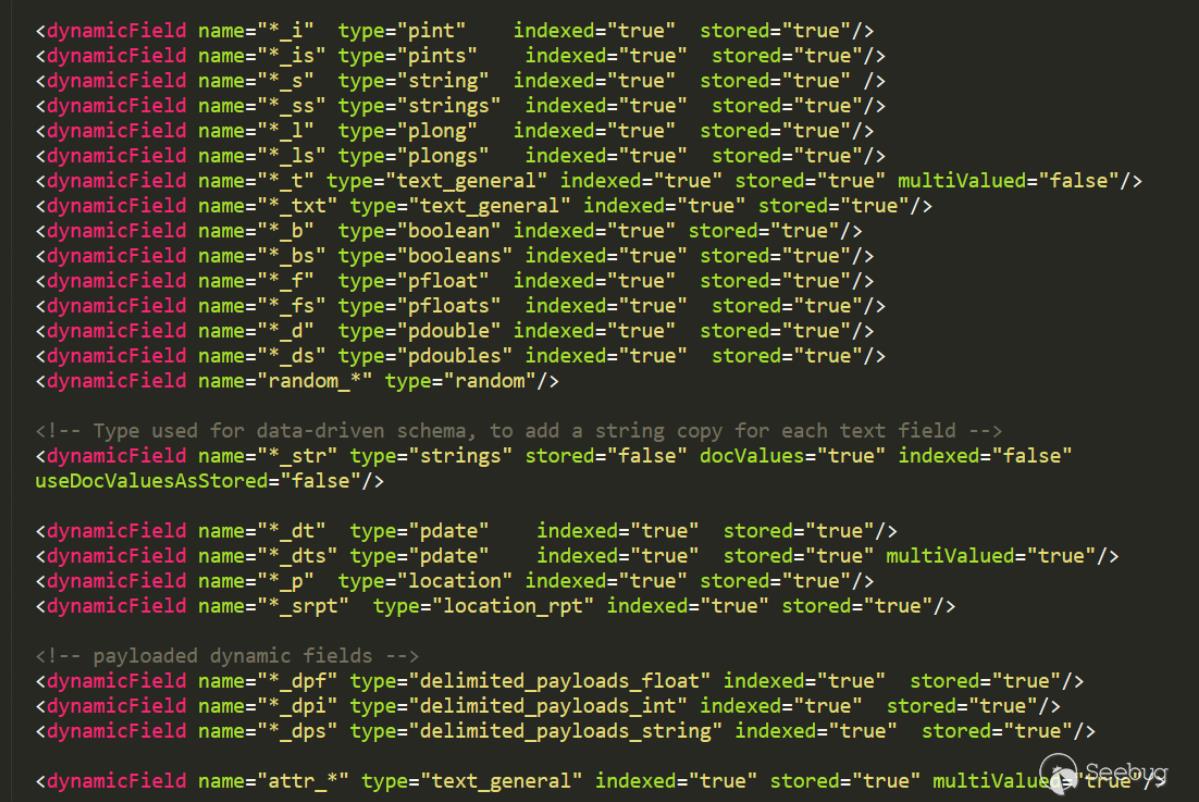
在上面的相关概念中对这个字段有介绍,可以翻上去查看下,测试下,果然是可以的:
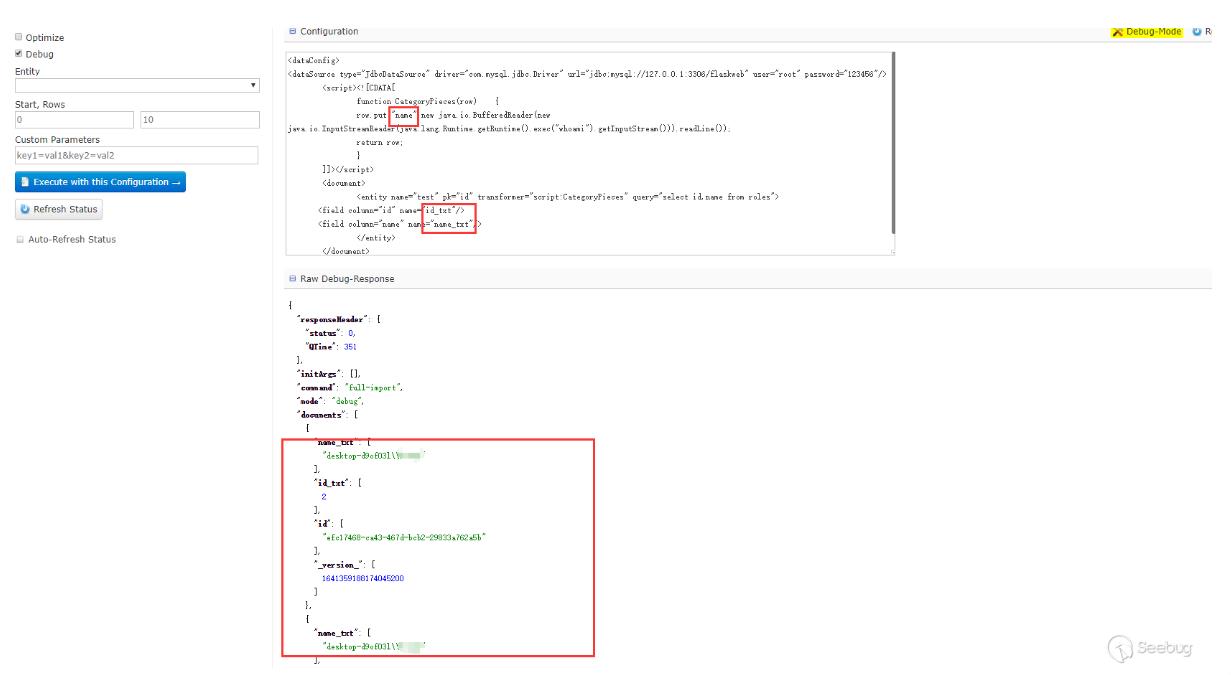
只要dynamicField能匹配dataConfig中field的name属性,solr就会自动加到document中去,如果schema配置了相应的field,那么配置的field优先,没有配置则根据dynamicField匹配。
PoC第二阶段--外连+无回显
在文档中说到JdbcDataSource可以使用JNDI,
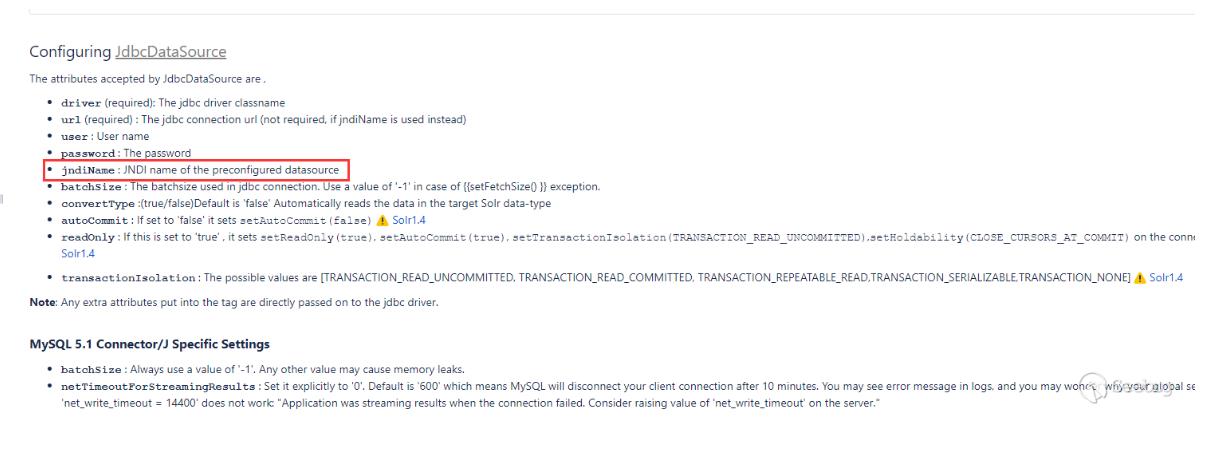
测试下能不能进行JNDI注入:
这里有一个JNDI+LDAP的恶意demo。使用这种方式无需目标的CLASSPATH存在数据库驱动。
PoC第三阶段--无外连+有回显
这个阶段的PoC来自@fnmsd师傅,使用的是ContentStreamDataSource,但是文档中没有对它进行描述如何使用。在stackoverflower找到一个使用例子:
在相关概念中说到了ContentStreamDataSource能接收Post数据作为数据源,结合第一阶段说到的dynamicField就能实现回显了。
只演示下效果图,不给出具体的PoC:
后来回过头去看其他类型的DataSource时,使用URLDataSource/HttpDataSource也可以,文档中提供了一个例子:
构造测试也是可行的,可以使用http、ftp等协议
参考链接
- https://cwiki.apache.org/confluence/display/SOLR/DataImportHandler#DataImportHandler-URLDataSource
- https://lucene.apache.org/solr/guide/7_5/
- https://stackoverflow.com/questions/51838282/correct-using-contentstreamdatasource-in-dih
- https://www.cnblogs.com/peaceliu/p/7786851.html

import mysql data to solr4.2.0
公司绝大部分的数据是存储在数据库中。假如有一天数据库已经很大了,公司决定将数据导入到索引中,以改善数据检索的效果,该怎么办呢?
Solr 已经为我们准备好了这样的工具,那就是Data Import Handler 。学习了这几天的solr ,感觉solr 的核心就是它的两个配置文件:schema.xml 和solrconfig.xml
第一步:建立数据库表,并插入测试数据。
在测试数据库中建立一张商品表,表的结构如下:
往数据库表中插入一些数据:
第二步:准备相关的JAR 包。
做过数据库开发的童鞋都知道,要想用数据可就需要连接数据库的接口,java上叫JDBC(Java Data Base Connectivity),别的语言也有类似的接口。
那么,这次我们需要两个jar包,分别是solr-dataimporthandler-4.2.0.jar和solr-dataimporthandler-extras-4.2.0.jar,mysql-connector-java-6.0.2.jar前两个可以在solr的解压目录下的dist目录中获取,后一个我想大家都可以找到的。
将这两个jar包复制到E:\lucene\luceneData\solr4\server\solr\WEB-INF\lib这个目录下。
第三步:配置导入设置
1. 默认dataImport功能在Solr5中是禁用的,需要在$SolrHome/conf/solrconfig.xml中添加如下配置开启数据导入功能:
| <!-- Data import from mysql 要放在<config></config>中哦--> <requestHandler name="/dataimport"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler> |
2. 因为前面定义了导入的配置文件是data-config.xml,所以在solrconfig.xml同级目录下新建这个文件,贴出我的配置,内容如下:
| <?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource name="fromMysql" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/jrbac?serverTimezone=UTC" user="root" password="root"/> <document> <entity name="commodity" query="select com_Id,com_Name,com_Title,com_Content,com_Price,com_Number,com_Type,com_SalesVolume,com_Brand,com_ImgURL from jrbac_commodity"> <field column="com_Id" name="id"/> <field column="com_Name" name="comName"/> <field column="com_Title" name="comTitle"/> <field column="com_Content" name="comContent"/> <field column="com_Price" name="comPrice"/> <field column="com_Number" name="comNumber"/> <field column="com_Type" name="comType"/> <field column="com_SalesVolume" name="comSalesvolume"/> <field column="com_Brand" name="comBrand"/> <field column="com_ImgURL" name="comImgurl"/> </entity> </document> </dataConfig> |
其中fromMysql为数据源自定义名称,随便取,没什么约束,type这是固定值,表示JDBC数据源,后面的driver表示JDBC驱动类,这跟你使用的数据库有关,url即JDBC链接URL,后面的user,password分别表示链接数据库的账号密码,下面的entity映射有点类似hiberante的mapping映射,column即数据库表的列名称,name即schema.xml中定义的域名称。
还有些设置项、参数不知道什么意思,后面后会说的。现在只要清楚field这个标签是设置数据库表中的列(column)和Solr中的字段的映射关系的。
第四步:进行数据导入
1. 重启Solr,进入管理页面,选中Dataimport这个选项。如果一切正常会出现如下图所示的界面。
右面的那些代码是你点击Configuration后出现的,是data-config.xml文件中的内容,也是应该首先检查的地方,如果没有这些配置信息,说明数据库导入的配置文件没生效,是solrconfig.xml文件中开启导入功能的地方出错。
2. 开始导入,要注意command参数,它有两个选项,如下图:  full-import:全量导入,它会覆盖原有的索引 delta-import:即增量导入,它会在原有索引的基础上追加
full-import:全量导入,它会覆盖原有的索引 delta-import:即增量导入,它会在原有索引的基础上追加
下面的几个多选框含义解释如下: verbose:这个选项设为true的话,会打印导入的一些中间过程的详细信息,有利于调试以及了解内部操作细节 clean:表示是否在导入数据创建索引之前先清空掉原有的索引 commit:表示是否立即提交索引 optimize:表示是否优化索引 debug: 表示是否开启调试模式
3.然后选择需要导入的Entity,点击Execute按钮开始执行数据导入操作,如图:
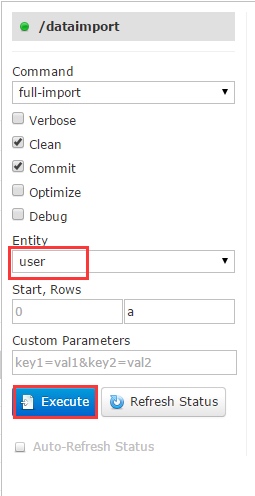
正常的话就开始进行导入了,如下图
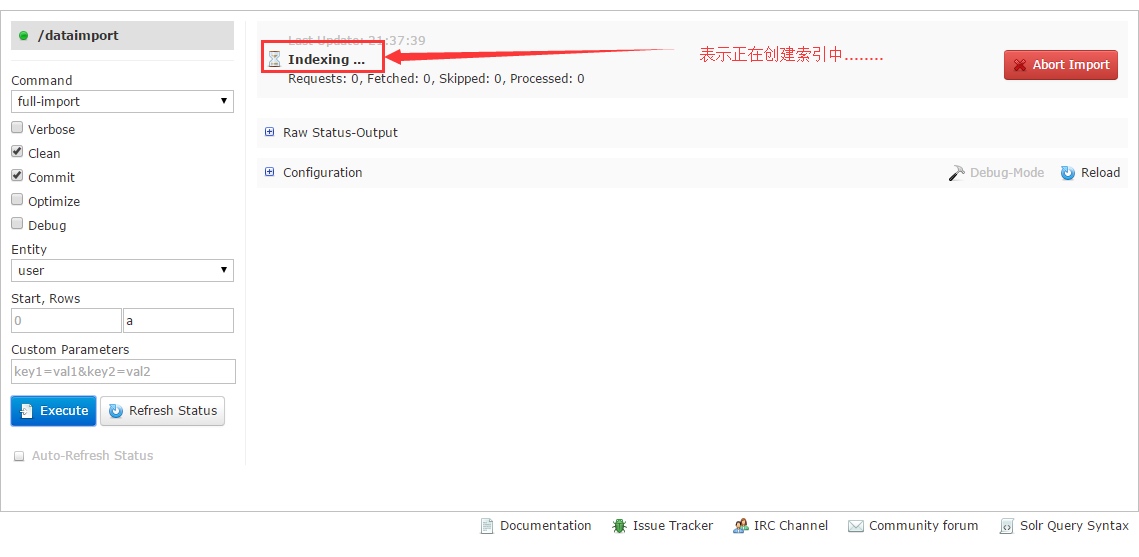
我们可以通过Refresh Status这个按钮刷新状态,如果出现错误或者Fetched一直是0,那就表明有问题了,你要查看日志进行检查。如果导入成功,就会看到下图所示的情况:
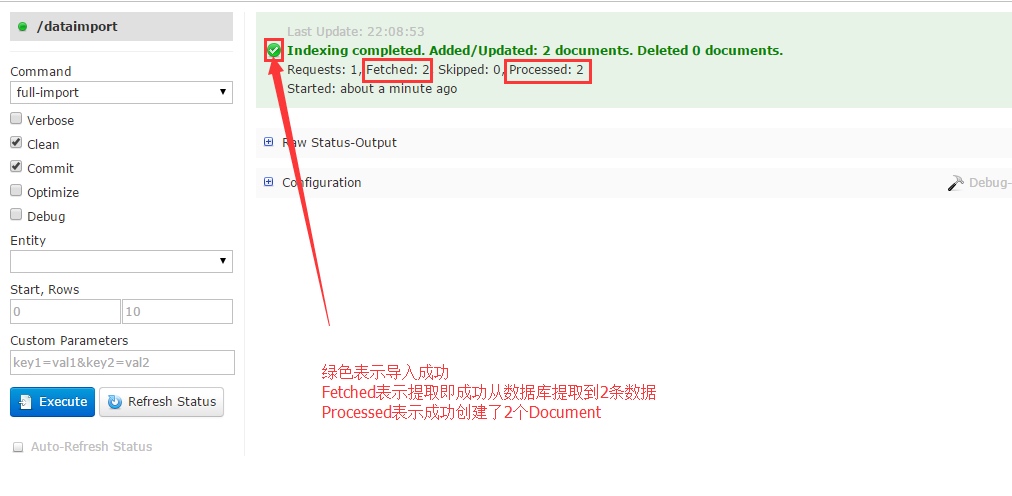
查看OverView菜单,会看到文档信息。
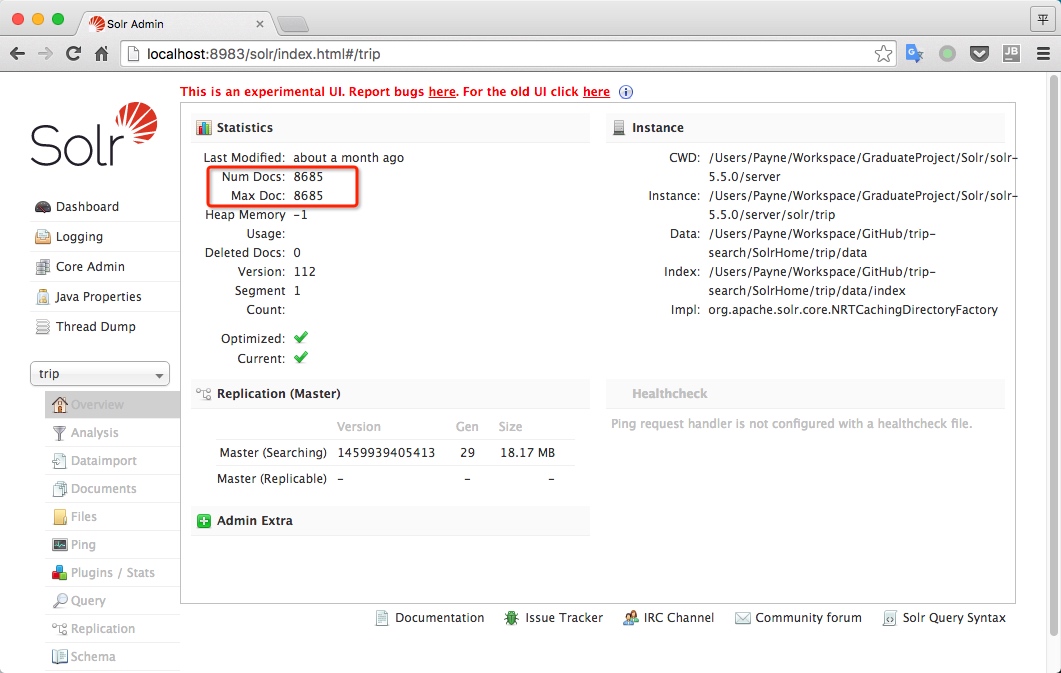
在查询中点击Execute Query按钮,就能看到我们导进去并建好索引的信息,更具体的查询用法后面会讲到,下面是默认的查询,显示文档的所有信息。
第五步:较为复杂的字段映射
数据库单表多个字段到solr多值字段
例如我数据库一个表中有关于地址的几个字段,分别是国家、省份、地区这样的字段(sight_place_1, sight_place_2, sight_place_3..)我需要把这几个字段放到solr中一个多值字段sight_place中。
题外话:对于关系型数据库不应该这样建表的,至少要满足第二范式,但这里用mysql只是为了存数据。
其实对于这个需求比较容易实现,修改data-config.xml文件中的entity就行了,配置如下
<field column="sight_place_1" name="sight_place"/>
<field column="sight_place_2" name="sight_place"/>
<field column="sight_place_3" name="sight_place"/>
<field column="sight_place_4" name="sight_place"/>
<field column="sight_place_5" name="sight_place"/>
数据库单表单字段到solr多值字段
前提:数据库中的单字段中的数据包含多值信息,并且用分隔符分开。例如数据库中sight_type字段的值是
| sight_name | sight_type |
|---|---|
| 故宫 | 古迹,世界文化遗产,历史建筑,博物馆 |
<entity name="sight" query="SELECT * FROM sight" transformer="RegexTransformer">
<field column="sight_type" name="sight_type" splitBy=","/>
</entity>
这样,导入到sight_type中的数据就是多值的
sight_type{
"博物馆",
"历史建筑",
"世界文化遗产",
"古迹"
}
特别注意: entity的属性transformer要为RegexTransformer,字段映射field属性splitBy设置为你的分隔符
数据库中多表联查到solr多值字段
1. 对于熟悉sql语句的人来讲,通过相对复杂的查询语句可以查到任何条件的结果,例如下面要说的 group_concat
select sight_place_1,GROUP_CONCAT(sight_place_2) as subplace FROM sight GROUP BY sight_place_1
这条查询的结果是
| sight_place_1 | subplace |
|---|---|
| 中国 | 北京,台湾,江苏,香港,宁夏,陕西 |
这样就回到了上面的方法了。当然这并不是多表,只是个简单的实例,你可以用更复杂的sql语句实现多表联查。
2. 另外solr也提供了子查询功能,例如下面的实例,更复杂的可以查看官方Wiki
<entity name="comment" pk="id" query="SELECT * FROM comment">
<field column="blogpost_id" name="blogpost_id"/>
<field column="comment_text" name="comment_text" />
<entity name="comment_tags" pk="comment_id" query="SELECT * FROM comment_tags WHERE comment_id=''${comment.id}''">
<field column="tag" name="tag" />
</entity>
</entity>
一些问题
不可行:多值字段按照下标取值 本来我想着取多值字段的sight_place的第二个值,就是省份,但最后发现这并不可行,solr中的多值应该就是个无序列表,但却可以发现在查询结果中,先插入的在下面,后插入的在上面,也不是真的无序。但没找到有序访问的方法。下面是关于这个问题的链接
Query specificly indexed value in multivalued field
Query a specific index value in a multivalue field in Solr
答案中建议我们可以用动态域(dynamic field)或者前缀的方式解决。
?")
java – 为什么我不能在我的ArrayList上调用Collections.sort()?
我定义了一个定义为的类
public class Store implements Serializable,Comparable<Store> { ... }
我在另一个类中有一个字段定义为:
ArrayList<Store> fStores = new ArrayList<Store>();
我想对这个集合进行排序,所以在我调用的方法中:
Collection.sort(fStores);
但是,我收到以下编译错误:
The method sort(ArrayList<Store>) is undefined for the type Collection
ArrayList实现List,并从文档中:
public static <T extends Comparable<? super T>> void sort(List<T> list)
那么,为什么我会收到错误?我也尝试创建自己的Comparator后代,并将其传递给sort方法,但没有运气.
我猜这里有一些关于“< T extends Comparable<?super T>>”的内容.我不理解… ?
解决方法
Collections
从Collections
This class consists exclusively of static methods that operate on or return collections. It contains polymorphic algorithms that operate on collections,“wrappers”,which return a new collection backed by a specified collection,and a few other odds and ends
所以基本上如果你必须排序或做任何这样的算法使用这个.
接下来是: – >
Collection
这是一个提供Java集合框架基础的接口.它不包括地图和排序地图.它表示一组称为其元素的对象,并具有具体实现的实现.当您想使用ArrayLists和Maps时,需要考虑这一点.
所以,在底线,你有一个静态算法来运行,它存在于集合中.所以,使用Collections.sort

Java:为什么我不能在Comparator中抛出异常?
直接的答案是因为Comparator.compares接口被指定为不会引发异常。但是为什么呢?
或换句话说:我Comparator必须依赖可以引发异常的函数。从理论上讲,这不应该发生。但是,如果发生这种情况,我希望它脱离我正在使用的整个函数Comparator(在中Collections.sort)。即我希望它的行为就像发生未处理的异常一样。
似乎这不可能以一种显而易见的自然方式进行(因为如果接口说它不能抛出异常,就不会)。
我该如何解决?用丑陋的try / catch并打印出异常,并希望我能识别出来?那似乎是一个非常丑陋的方式。
今天关于为什么我不能在JBoss上的Solr中实例化DataImportHandler?和solr jdbc的介绍到此结束,谢谢您的阅读,有关Apache Solr DataImportHandler远程代码执行漏洞(CVE-2019-0193) 分析、import mysql data to solr4.2.0、java – 为什么我不能在我的ArrayList上调用Collections.sort()?、Java:为什么我不能在Comparator中抛出异常?等更多相关知识的信息可以在本站进行查询。
本文标签:




