在这里,我们将给大家分享关于Python爬虫从入门到放弃的知识,让您更了解十四之Scrapy框架中选择器的用法的本质,同时也会涉及到如何更有效地Python爬虫从入门到放弃(二十三)之Scrapy的中
在这里,我们将给大家分享关于Python爬虫从入门到放弃的知识,让您更了解十四之 Scrapy框架中选择器的用法的本质,同时也会涉及到如何更有效地Python 爬虫从入门到放弃(二十三)之 Scrapy 的中间件 Downloader Middleware 实现 User-Agent 随机切换、python 爬虫从入门到放弃(二)之爬虫的原理、Python 爬虫从入门到放弃(十九)之 Scrapy 爬取所有知乎用户信息 (下)、Python 爬虫从入门到放弃(十八)之 Scrapy 爬取所有知乎用户信息 (上)的内容。
本文目录一览:- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法(python爬虫css选择器)
- Python 爬虫从入门到放弃(二十三)之 Scrapy 的中间件 Downloader Middleware 实现 User-Agent 随机切换
- python 爬虫从入门到放弃(二)之爬虫的原理
- Python 爬虫从入门到放弃(十九)之 Scrapy 爬取所有知乎用户信息 (下)
- Python 爬虫从入门到放弃(十八)之 Scrapy 爬取所有知乎用户信息 (上)
之 Scrapy框架中选择器的用法(python爬虫css选择器)")
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法(python爬虫css选择器)
原文地址https://www.cnblogs.com/zhaof/p/7189860.html
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分
Xpath是专门在XML文件中选择节点的语言,也可以用在HTML上。
CSS是一门将HTML文档样式化语言,选择器由它定义,并与特定的HTML元素的样式相关联。
XPath选择器
常用的路径表达式,这里列举了一些常用的,XPath的功能非常强大,内含超过100个的内建函数。
下面为常用的方法

nodeName 选取此节点的所有节点
/ 从根节点选取
// 从匹配选择的当前节点选择文档中的节点,不考虑它们的位置
. 选择当前节点
.. 选取当前节点的父节点
@ 选取属性
* 匹配任何元素节点
@* 匹配任何属性节点
Node() 匹配任何类型的节点
CSS选择器
CSS层叠样式表,语法由两个主要部分组成:选择器,一条或多条声明
Selector {declaration1;declaration2;……}
下面为常用的使用方法

.class .color 选择class=”color”的所有元素
#id #info 选择id=”info”的所有元素
* * 选择所有元素
element p 选择所有的p元素
element,element div,p 选择所有div元素和所有p元素
element element div p 选择div标签内部的所有p元素
[attribute] [target] 选择带有targe属性的所有元素
[arrtibute=value] [target=_blank] 选择target=”_blank”的所有元素
选择器的使用例子
上面我们列举了两种选择器的常用方法,下面通过scrapy帮助文档提供的一个地址来做演示
地址:http://doc.scrapy.org/en/latest/_static/selectors-sample1.html
这个地址的网页源码为:

<html>
<head>
<base href=''http://example.com/'' />
<title>Example website</title>
</head>
<body>
<div id=''images''>
<a href=''image1.html''>Name: My image 1 <br /><img src=''image1_thumb.jpg'' /></a>
<a href=''image2.html''>Name: My image 2 <br /><img src=''image2_thumb.jpg'' /></a>
<a href=''image3.html''>Name: My image 3 <br /><img src=''image3_thumb.jpg'' /></a>
<a href=''image4.html''>Name: My image 4 <br /><img src=''image4_thumb.jpg'' /></a>
<a href=''image5.html''>Name: My image 5 <br /><img src=''image5_thumb.jpg'' /></a>
</div>
</body>
</html>
我们通过scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html来演示两种选择器的功能
获取title
这里的extract_first()就可以获取title标签的文本内容,因为我们第一个通过xpath返回的结果是一个列表,所以我们通过extract()之后返回的也是一个列表,而extract_first()可以直接返回第一个值,extract_first()有一个参数default,例如:extract_first(default="")表示如果匹配不到返回一个空

In [1]: response.xpath(''//title/text()'')
Out[1]: [<Selector xpath=''//title/text()'' data=''Example website''>]
In [2]: response.xpath(''//title/text()'').extract_first()
Out[2]: ''Example website''
In [6]: response.xpath(''//title/text()'').extract()
Out[6]: [''Example website'']
同样的我们也可以通过css选择器获取,例子如下:
In [7]: response.css(''title::text'')
Out[7]: [<Selector xpath=''descendant-or-self::title/text()'' data=''Example website''>]
In [8]: response.css(''title::text'').extract_first()
Out[8]: ''Example website''查找图片信息
这里通过xpath和css结合使用获取图片的src地址:

In [13]: response.xpath(''//div[@id="images"]'').css(''img'')
Out[13]:
[<Selector xpath=''descendant-or-self::img'' data=''<img src="image1_thumb.jpg">''>,
<Selector xpath=''descendant-or-self::img'' data=''<img src="image2_thumb.jpg">''>,
<Selector xpath=''descendant-or-self::img'' data=''<img src="image3_thumb.jpg">''>,
<Selector xpath=''descendant-or-self::img'' data=''<img src="image4_thumb.jpg">''>,
<Selector xpath=''descendant-or-self::img'' data=''<img src="image5_thumb.jpg">''>]
In [14]: response.xpath(''//div[@id="images"]'').css(''img::attr(src)'').extract()
Out[14]:
[''image1_thumb.jpg'',
''image2_thumb.jpg'',
''image3_thumb.jpg'',
''image4_thumb.jpg'',
''image5_thumb.jpg'']
查找a标签信息
这里分别通过xapth和css选择器获取a标签的href内容,以及文本信息,css获取属性信息是通过attr,xpath是通过@属性名

In [15]: response.xpath(''//a/@href'')
Out[15]:
[<Selector xpath=''//a/@href'' data=''image1.html''>,
<Selector xpath=''//a/@href'' data=''image2.html''>,
<Selector xpath=''//a/@href'' data=''image3.html''>,
<Selector xpath=''//a/@href'' data=''image4.html''>,
<Selector xpath=''//a/@href'' data=''image5.html''>]
In [16]: response.xpath(''//a/@href'').extract()
Out[16]: [''image1.html'', ''image2.html'', ''image3.html'', ''image4.html'', ''image5.html'']
In [17]: response.css(''a::attr(href)'')
Out[17]:
[<Selector xpath=''descendant-or-self::a/@href'' data=''image1.html''>,
<Selector xpath=''descendant-or-self::a/@href'' data=''image2.html''>,
<Selector xpath=''descendant-or-self::a/@href'' data=''image3.html''>,
<Selector xpath=''descendant-or-self::a/@href'' data=''image4.html''>,
<Selector xpath=''descendant-or-self::a/@href'' data=''image5.html''>]
In [18]: response.css(''a::attr(href)'').extract()
Out[18]: [''image1.html'', ''image2.html'', ''image3.html'', ''image4.html'', ''image5.html'']
In [27]: response.css(''a::text'').extract()
Out[27]:
[''Name: My image 1 '',
''Name: My image 2 '',
''Name: My image 3 '',
''Name: My image 4 '',
''Name: My image 5 '']
In [28]: response.xpath(''//a/text()'').extract()
Out[28]:
[''Name: My image 1 '',
''Name: My image 2 '',
''Name: My image 3 '',
''Name: My image 4 '',
''Name: My image 5 '']
In [29]:
高级用法
查找属性名称包含img的所有的超链接,通过contains实现

In [36]: response.xpath(''//a[contains(@href,"image")]/@href'').extract()
Out[36]: [''image1.html'', ''image2.html'', ''image3.html'', ''image4.html'', ''image5.html'']
In [37]: response.css(''a[href*=image]::attr(href)'').extract()
Out[37]: [''image1.html'', ''image2.html'', ''image3.html'', ''image4.html'', ''image5.html'']
In [38]:
查找img的src属性

In [41]: response.xpath(''//a[contains(@href,"image")]/img/@src'').extract()
Out[41]:
[''image1_thumb.jpg'',
''image2_thumb.jpg'',
''image3_thumb.jpg'',
''image4_thumb.jpg'',
''image5_thumb.jpg'']
In [42]: response.css(''a[href*=image] img::attr(src)'').extract()
Out[42]:
[''image1_thumb.jpg'',
''image2_thumb.jpg'',
''image3_thumb.jpg'',
''image4_thumb.jpg'',
''image5_thumb.jpg'']
In [43]:
提取a标签的文本中name后面的内容,这里提供了正则的方法re和re_first

In [43]: response.css(''a::text'').re(''Name\:(.*)'')
Out[43]:
['' My image 1 '',
'' My image 2 '',
'' My image 3 '',
'' My image 4 '',
'' My image 5 '']
In [44]: response.css(''a::text'').re_first(''Name\:(.*)'')
Out[44]: '' My image 1 ''
之 Scrapy 的中间件 Downloader Middleware 实现 User-Agent 随机切换")
Python 爬虫从入门到放弃(二十三)之 Scrapy 的中间件 Downloader Middleware 实现 User-Agent 随机切换
原文地址 https://www.cnblogs.com/zhaof/p/7345856.html
总架构理解 Middleware
通过 scrapy 官网最新的架构图来理解:

这个图较之前的图顺序更加清晰,从图中我们可以看出,在 spiders 和 ENGINE 提及 ENGINE 和 DOWNLOADER 之间都可以设置中间件,两者是双向的,并且是可以设置多层.
关于 Downloader Middleware 我在 http://www.cnblogs.com/zhaof/p/7198407.html 这篇博客中已经写了详细的使用介绍。
如何实现随机更换 User-Agent
这里要做的是通过自己在 Downlaoder Middleware 中定义一个类来实现随机更换 User-Agent, 但是我们需要知道的是 scrapy 其实本身提供了一个 user-agent 这个我们在源码中可以看到如下图:


from scrapy import signals
class UserAgentMiddleware(object):
"""This middleware allows spiders to override the user_agent"""
def __init__(self, user_agent=''Scrapy''):
self.user_agent = user_agent
@classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings[''USER_AGENT''])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o
def spider_opened(self, spider):
self.user_agent = getattr(spider, ''user_agent'', self.user_agent)
def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b''User-Agent'', self.user_agent)
从源代码中可以知道,默认 scrapy 的 user_agent=‘Scrapy’, 并且这里在这个类里有一个类方法 from_crawler 会从 settings 里获取 USER_AGENT 这个配置,如果 settings 配置文件中没有配置,则会采用默认的 Scrapy,process_request 方法会在请求头中设置 User-Agent.
关于随机切换 User-Agent 的库
github 地址为:https://github.com/hellysmile/fake-useragent
安装:pip install fake-useragent
基本的使用例子:

from fake_useragent import UserAgent
ua = UserAgent()
print(ua.ie)
print(ua.chrome)
print(ua.Firefox)
print(ua.random)
print(ua.random)
print(ua.random)
这里可以获取我们想要的常用的 User-Agent, 并且这里提供了一个 random 方法可以直接随机获取,上述代码的结果为:

关于配置和代码
这里我找了一个之前写好的爬虫,然后实现随机更换 User-Agent,在 settings 配置文件如下:

DOWNLOADER_MIDDLEWARES = {
''jobboleSpider.middlewares.RandomUserAgentMiddleware'': 543,
''scrapy.downloadermiddlewares.useragent.UserAgentMiddleware'': None,
}
RANDOM_UA_TYPE= ''random''
这里我们要将系统的 UserAgent 中间件设置为 None,这样就不会启用,否则默认系统的这个中间会被启用
定义 RANDOM_UA_TYPE 这个是设置一个默认的值,如果这里不设置我们会在代码中进行设置,在 middleares.py 中添加如下代码:

class RandomUserAgentMiddleware(object):
''''''
随机更换User-Agent
''''''
def __init__(self,crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get(''RANDOM_UA_TYPE'',''random'')
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
def process_request(self,request,spider):
def get_ua():
return getattr(self.ua,self.ua_type)
request.headers.setdefault(''User-Agent'',get_ua())
上述代码的一个简单分析描述:
1. 通过 crawler.settings.get 来获取配置文件中的配置,如果没有配置则默认是 random,如果配置了 ie 或者 chrome 等就会获取到相应的配置
2. 在 process_request 方法中我们嵌套了一个 get_ua 方法,get_ua 其实就是为了执行 ua.ua_type,但是这里无法使用 self.ua.self.us_type,所以利用了 getattr 方法来直接获取,最后通过 request.heasers.setdefault 来设置 User-Agent
通过上面的配置我们就实现了每次请求随机更换 User-Agent
之爬虫的原理")
python 爬虫从入门到放弃(二)之爬虫的原理
原文地址 https://www.cnblogs.com/zhaof/p/6898138.html
在上文中我们说了:爬虫就是请求网站并提取数据的自动化程序。其中请求,提取,自动化是爬虫的关键!下面我们分析爬虫的基本流程
爬虫的基本流程
发起请求
通过 HTTP 库向目标站点发起请求,也就是发送一个 Request,请求可以包含额外的 header 等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,会得到一个 Response,Response 的内容便是所要获取的页面内容,类型可能是 HTML,Json 字符串,二进制数据(图片或者视频)等类型
解析内容
得到的内容可能是 HTML, 可以用正则表达式,页面解析库进行解析,可能是 Json, 可以直接转换为 Json 对象解析,可能是二进制数据,可以做保存或者进一步的处理
保存数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
什么是 Request,Response
浏览器发送消息给网址所在的服务器,这个过程就叫做 HTPP Request
服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应的处理,然后把消息回传给浏览器,这个过程就是 HTTP Response
浏览器收到服务器的 Response 信息后,会对信息进行相应的处理,然后展示
Request 中包含什么?
请求方式
主要有:GET/POST 两种类型常用,另外还有 HEAD/PUT/DELETE/OPTIONS
GET 和 POST 的区别就是:请求的数据 GET 是在 url 中,POST 则是存放在头部
GET: 向指定的资源发出 “显示” 请求。使用 GET 方法应该只用在读取数据,而不应当被用于产生 “副作用” 的操作中,例如在 Web Application 中。其中一个原因是 GET 可能会被网络蜘蛛等随意访问
POST: 向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
HEAD:与 GET 方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中 “关于该资源的信息”(元信息或称元数据)。
PUT:向指定资源位置上传其最新内容。
OPTIONS:这个方法可使服务器传回该资源所支持的所有 HTTP 请求方法。用 ''*'' 来代替资源名称,向 Web 服务器发送 OPTIONS 请求,可以测试服务器功能是否正常运作。
DELETE:请求服务器删除 Request-URI 所标识的资源。
请求 URL
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL 的格式由三个部分组成:
第一部分是协议 (或称为服务方式)。
第二部分是存有该资源的主机 IP 地址 (有时也包括端口号)。
第三部分是主机资源的具体地址,如目录和文件名等。
爬虫爬取数据时必须要有一个目标的 URL 才可以获取数据,因此,它是爬虫获取数据的基本依据。
请求头
包含请求时的头部信息,如 User-Agent,Host,Cookies 等信息,下图是请求请求百度时,所有的请求头部信息参数

请求体
请求是携带的数据,如提交表单数据时候的表单数据(POST)
Response 中包含了什么
所有 HTTP 响应的第一行都是状态行,依次是当前 HTTP 版本号,3 位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
响应状态
有多种响应状态,如:200 代表成功,301 跳转,404 找不到页面,502 服务器错误
- 1xx 消息 —— 请求已被服务器接收,继续处理
- 2xx 成功 —— 请求已成功被服务器接收、理解、并接受
- 3xx 重定向 —— 需要后续操作才能完成这一请求
- 4xx 请求错误 —— 请求含有词法错误或者无法被执行
- 5xx 服务器错误 —— 服务器在处理某个正确请求时发生错误 常见代码: 200 OK 请求成功 400 Bad Request 客户端请求有语法错误,不能被服务器所理解 401 Unauthorized 请求未经授权,这个状态代码必须和 WWW-Authenticate 报头域一起使用 403 Forbidden 服务器收到请求,但是拒绝提供服务 404 Not Found 请求资源不存在,eg:输入了错误的 URL 500 Internal Server Error 服务器发生不可预期的错误 503 Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常 301 目标永久性转移 302 目标暂时性转移
响应头
如内容类型,类型的长度,服务器信息,设置 Cookie, 如下图
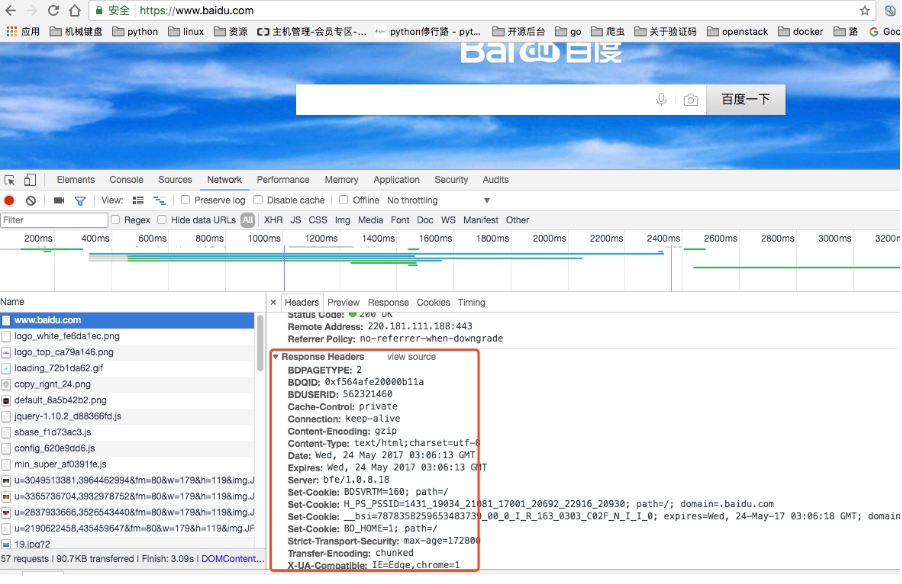
响应体
最主要的部分,包含请求资源的内容,如网页 HTMl, 图片,二进制数据等
能爬取什么样的数据
网页文本:如 HTML 文档,Json 格式化文本等
图片:获取到的是二进制文件,保存为图片格式
视频:同样是二进制文件
其他:只要请求到的,都可以获取
如何解析数据
- 直接处理
- Json 解析
- 正则表达式处理
- BeautifulSoup 解析处理
- PyQuery 解析处理
- XPath 解析处理
关于抓取的页面数据和浏览器里看到的不一样的问题
出现这种情况是因为,很多网站中的数据都是通过 js,ajax 动态加载的,所以直接通过 get 请求获取的页面和浏览器显示的不同。
如何解决 js 渲染的问题?
分析 ajax
Selenium/webdriver
Splash
PyV8,Ghost.py
怎样保存数据
文本:纯文本,Json,Xml 等
关系型数据库:如 mysql,oracle,sql server 等结构化数据库
非关系型数据库:MongoDB,Redis 等 key-value 形式存储
之 Scrapy 爬取所有知乎用户信息 (下)")
Python 爬虫从入门到放弃(十九)之 Scrapy 爬取所有知乎用户信息 (下)
原文地址 https://www.cnblogs.com/zhaof/p/7228131.html
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:
https://github.com/pythonsite/spider
items 中的代码主要是我们要爬取的字段的定义

class UserItem(scrapy.Item):
id = Field()
name = Field()
account_status = Field()
allow_message= Field()
answer_count = Field()
articles_count = Field()
avatar_hue = Field()
avatar_url = Field()
avatar_url_template = Field()
badge = Field()
business = Field()
employments = Field()
columns_count = Field()
commercial_question_count = Field()
cover_url = Field()
description = Field()
educations = Field()
favorite_count = Field()
favorited_count = Field()
follower_count = Field()
following_columns_count = Field()
following_favlists_count = Field()
following_question_count = Field()
following_topic_count = Field()
gender = Field()
headline = Field()
hosted_live_count = Field()
is_active = Field()
is_bind_sina = Field()
is_blocked = Field()
is_advertiser = Field()
is_blocking = Field()
is_followed = Field()
is_following = Field()
is_force_renamed = Field()
is_privacy_protected = Field()
locations = Field()
is_org = Field()
type = Field()
url = Field()
url_token = Field()
user_type = Field()
logs_count = Field()
marked_answers_count = Field()
marked_answers_text = Field()
message_thread_token = Field()
mutual_followees_count = Field()
participated_live_count = Field()
pins_count = Field()
question_count = Field()
show_sina_weibo = Field()
thank_from_count = Field()
thank_to_count = Field()
thanked_count = Field()
type = Field()
vote_from_count = Field()
vote_to_count = Field()
voteup_count = Field()
这些字段的是在用户详细信息里找到的,如下图所示,这里一共有 58 个字段,可以详细研究每个字段代表的意思:
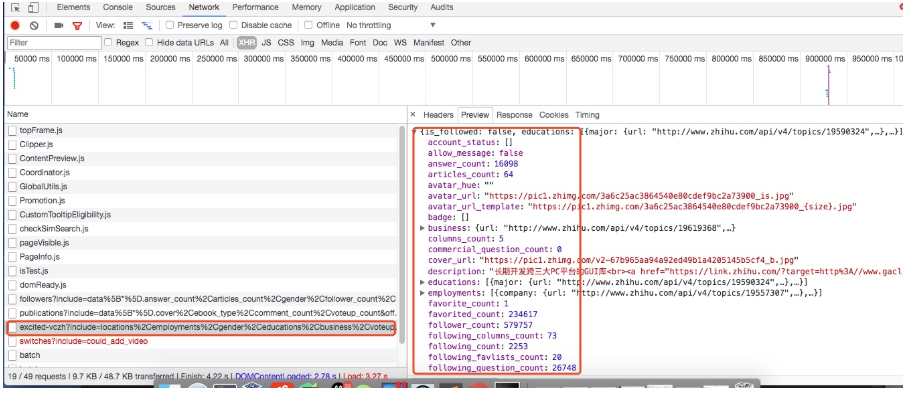
关于 spiders 中爬虫文件 zhihu.py 中的主要代码
这段代码是非常重要的,主要的处理逻辑其实都是在这里

class ZhihuSpider(scrapy.Spider):
name = "zhihu"
allowed_domains = ["www.zhihu.com"]
start_urls = [''http://www.zhihu.com/'']
#这里定义一个start_user存储我们找的大V账号
start_user = "excited-vczh"
#这里把查询的参数单独存储为user_query,user_url存储的为查询用户信息的url地址
user_url = "https://www.zhihu.com/api/v4/members/{user}?include={include}"
user_query = "locations,employments,gender,educations,business,voteup_count,thanked_Count,follower_count,following_count,cover_url,following_topic_count,following_question_count,following_favlists_count,following_columns_count,avatar_hue,answer_count,articles_count,pins_count,question_count,columns_count,commercial_question_count,favorite_count,favorited_count,logs_count,marked_answers_count,marked_answers_text,message_thread_token,account_status,is_active,is_bind_phone,is_force_renamed,is_bind_sina,is_privacy_protected,sina_weibo_url,sina_weibo_name,show_sina_weibo,is_blocking,is_blocked,is_following,is_followed,mutual_followees_count,vote_to_count,vote_from_count,thank_to_count,thank_from_count,thanked_count,description,hosted_live_count,participated_live_count,allow_message,industry_category,org_name,org_homepage,badge[?(type=best_answerer)].topics"
#follows_url存储的为关注列表的url地址,fllows_query存储的为查询参数。这里涉及到offset和limit是关于翻页的参数,0,20表示第一页
follows_url = "https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}"
follows_query = "data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics"
#followers_url是获取粉丝列表信息的url地址,followers_query存储的为查询参数。
followers_url = "https://www.zhihu.com/api/v4/members/{user}/followers?include={include}&offset={offset}&limit={limit}"
followers_query = "data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics"
def start_requests(self):
''''''
这里重写了start_requests方法,分别请求了用户查询的url和关注列表的查询以及粉丝列表信息查询
:return:
''''''
yield Request(self.user_url.format(user=self.start_user,include=self.user_query),callback=self.parse_user)
yield Request(self.follows_url.format(user=self.start_user,include=self.follows_query,offset=0,limit=20),callback=self.parse_follows)
yield Request(self.followers_url.format(user=self.start_user,include=self.followers_query,offset=0,limit=20),callback=self.parse_followers)
def parse_user(self, response):
''''''
因为返回的是json格式的数据,所以这里直接通过json.loads获取结果
:param response:
:return:
''''''
result = json.loads(response.text)
item = UserItem()
#这里循环判断获取的字段是否在自己定义的字段中,然后进行赋值
for field in item.fields:
if field in result.keys():
item[field] = result.get(field)
#这里在返回item的同时返回Request请求,继续递归拿关注用户信息的用户获取他们的关注列表
yield item
yield Request(self.follows_url.format(user = result.get("url_token"),include=self.follows_query,offset=0,limit=20),callback=self.parse_follows)
yield Request(self.followers_url.format(user = result.get("url_token"),include=self.followers_query,offset=0,limit=20),callback=self.parse_followers)
def parse_follows(self, response):
''''''
用户关注列表的解析,这里返回的也是json数据 这里有两个字段data和page,其中page是分页信息
:param response:
:return:
''''''
results = json.loads(response.text)
if ''data'' in results.keys():
for result in results.get(''data''):
yield Request(self.user_url.format(user = result.get("url_token"),include=self.user_query),callback=self.parse_user)
#这里判断page是否存在并且判断page里的参数is_end判断是否为False,如果为False表示不是最后一页,否则则是最后一页
if ''page'' in results.keys() and results.get(''is_end'') == False:
next_page = results.get(''paging'').get("next")
#获取下一页的地址然后通过yield继续返回Request请求,继续请求自己再次获取下页中的信息
yield Request(next_page,self.parse_follows)
def parse_followers(self, response):
''''''
这里其实和关乎列表的处理方法是一样的
用户粉丝列表的解析,这里返回的也是json数据 这里有两个字段data和page,其中page是分页信息
:param response:
:return:
''''''
results = json.loads(response.text)
if ''data'' in results.keys():
for result in results.get(''data''):
yield Request(self.user_url.format(user = result.get("url_token"),include=self.user_query),callback=self.parse_user)
#这里判断page是否存在并且判断page里的参数is_end判断是否为False,如果为False表示不是最后一页,否则则是最后一页
if ''page'' in results.keys() and results.get(''is_end'') == False:
next_page = results.get(''paging'').get("next")
#获取下一页的地址然后通过yield继续返回Request请求,继续请求自己再次获取下页中的信息
yield Request(next_page,self.parse_followers)
上述的代码的主要逻辑用下图分析表示:
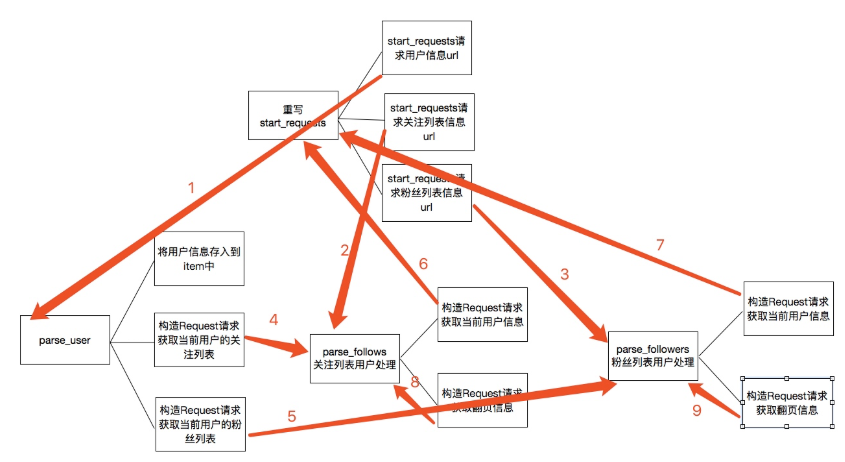
关于上图的一个简单描述:
1. 当重写 start_requests,一会有三个 yield,分别的回调函数调用了 parse_user,parse_follows,parse_followers,这是第一次会分别获取我们所选取的大 V 的信息以及关注列表信息和粉丝列表信息
2. 而 parse 分别会再次回调 parse_follows 和 parse_followers 信息,分别递归获取每个用户的关注列表信息和分析列表信息
3. parse_follows 获取关注列表里的每个用户的信息回调了 parse_user,并进行翻页获取回调了自己 parse_follows
4. parse_followers 获取粉丝列表里的每个用户的信息回调了 parse_user,并进行翻页获取回调了自己 parse_followers
通过上面的步骤实现所有用户信息的爬取,最后是关于数据的存储
关于数据存储到 mongodb
这里主要是 item 中的数据存储到 mongodb 数据库中,这里主要的一个用法是就是插入的时候进行了一个去重检测

class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get(''MONGO_URI''),
mongo_db=crawler.settings.get(''MONGO_DATABASE'', ''items'')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
#这里通过mongodb进行了一个去重的操作,每次更新插入数据之前都会进行查询,判断要插入的url_token是否已经存在,如果不存在再进行数据插入,否则放弃数据
self.db[''user''].update({''url_token'':item["url_token"]},{''$set'':item},True)
return item
之 Scrapy 爬取所有知乎用户信息 (上)")
Python 爬虫从入门到放弃(十八)之 Scrapy 爬取所有知乎用户信息 (上)
原文地址 https://www.cnblogs.com/zhaof/p/7215617.html
爬取的思路
首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示:
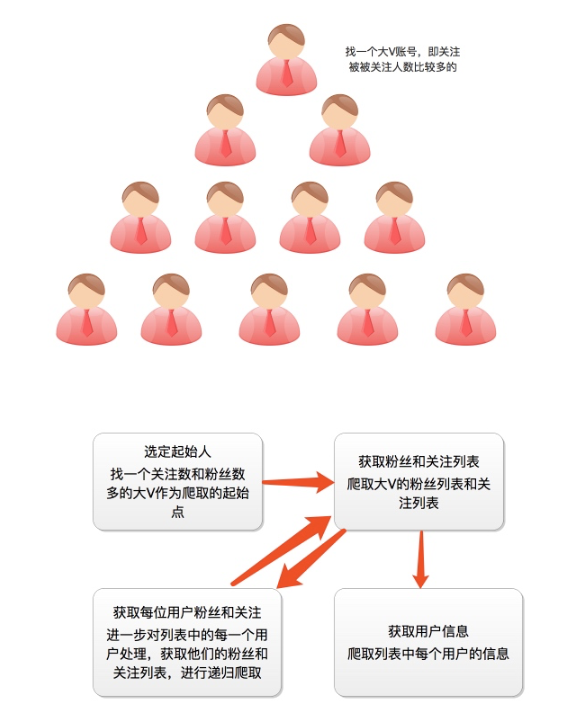
爬虫分析过程
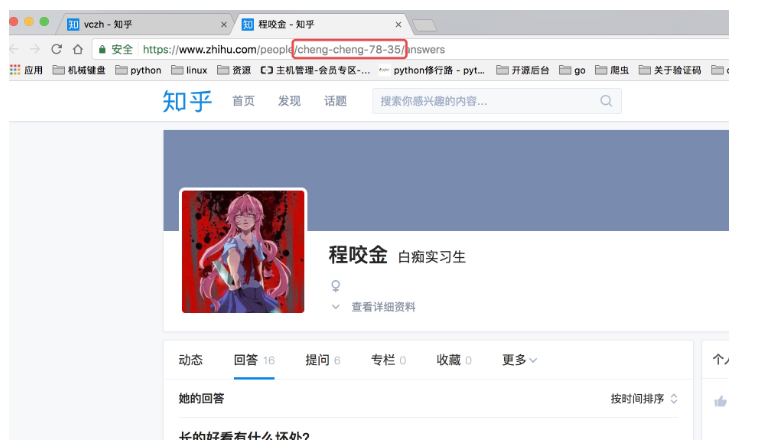
这里我们找的账号地址是:https://www.zhihu.com/people/excited-vczh/answers
我们抓取的大 V 账号的主要信息是:
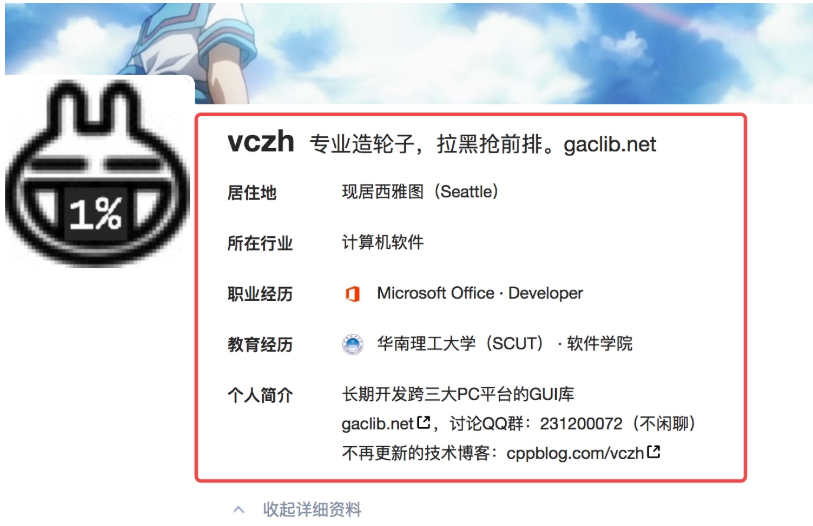
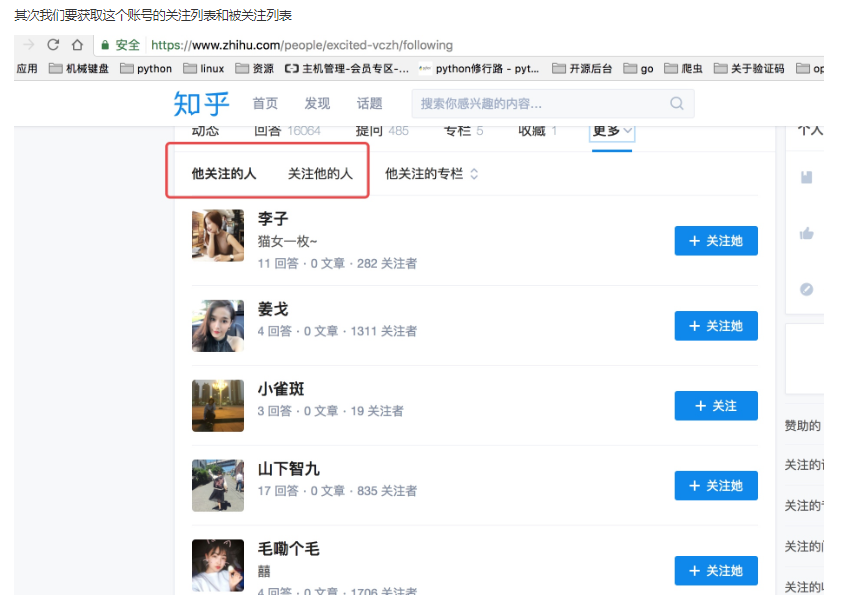
这里我们需要通过抓包分析如果获取这些列表的信息以及用户的个人信息内容
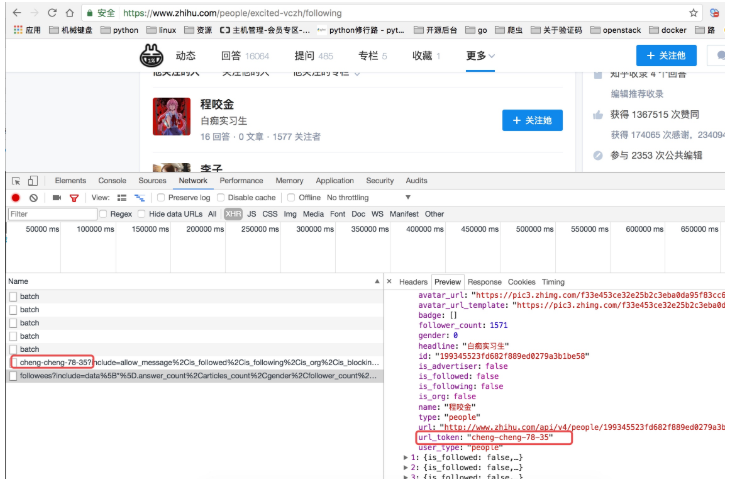
当我们查看他关注人的列表的时候我们可以看到他请求了如下图中的地址,并且我们可以看到返回去的结果是一个 json 数据,而这里就存着一页关乎的用户信息。
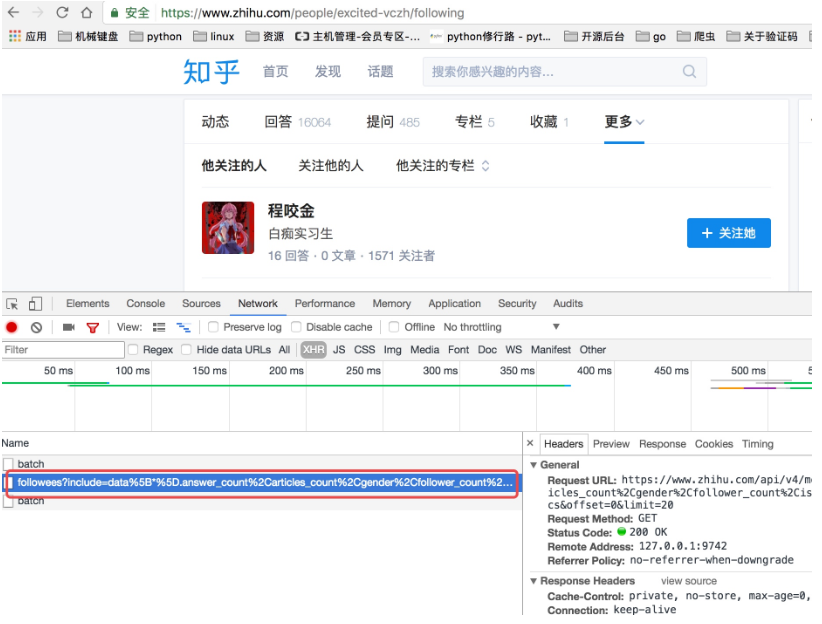

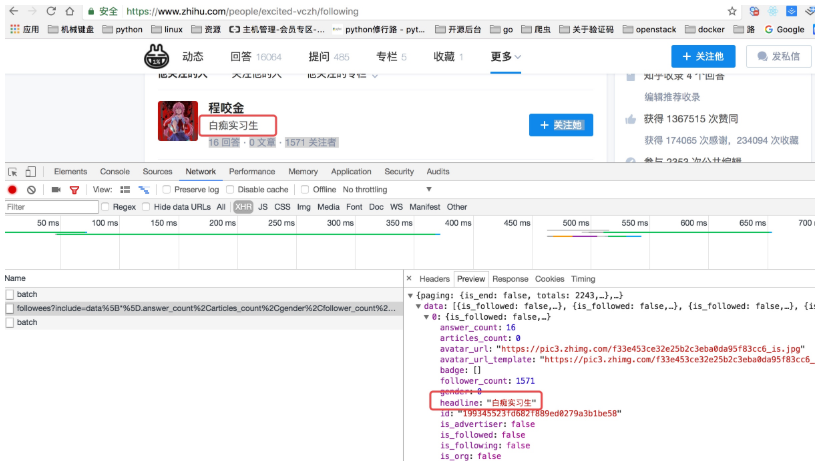
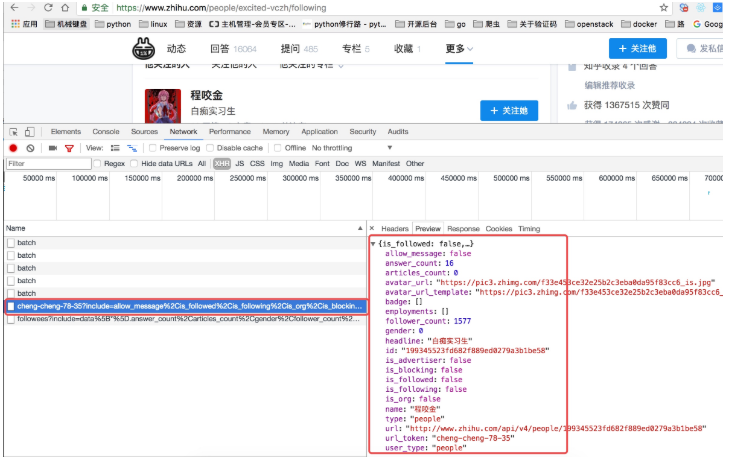
上面虽然可以获取单个用户的个人信息,但是不是特别完整,这个时候我们获取一个人的完整信息地址是当我们将鼠标放到用户名字上面的时候,可以看到发送了一个请求:

我们可以看这个地址的返回结果可以知道,这个地址请求获取的是用户的详细信息:
通过上面的分析我们知道了以下两个地址:
获取用户关注列表的地址:https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
获取单个用户详细信息的地址:https://www.zhihu.com/api/v4/members/excited-vczh?include=locations%2Cemployments%2Cgender%2Ceducations%2Cbusiness%2Cvoteup_count%2Cthanked_Count%2Cfollower_count%2Cfollowing_count%2Ccover_url%2Cfollowing_topic_count%2Cfollowing_question_count%2Cfollowing_favlists_count%2Cfollowing_columns_count%2Cavatar_hue%2Canswer_count%2Carticles_count%2Cpins_count%2Cquestion_count%2Ccolumns_count%2Ccommercial_question_count%2Cfavorite_count%2Cfavorited_count%2Clogs_count%2Cmarked_answers_count%2Cmarked_answers_text%2Cmessage_thread_token%2Caccount_status%2Cis_active%2Cis_bind_phone%2Cis_force_renamed%2Cis_bind_sina%2Cis_privacy_protected%2Csina_weibo_url%2Csina_weibo_name%2Cshow_sina_weibo%2Cis_blocking%2Cis_blocked%2Cis_following%2Cis_followed%2Cmutual_followees_count%2Cvote_to_count%2Cvote_from_count%2Cthank_to_count%2Cthank_from_count%2Cthanked_count%2Cdescription%2Chosted_live_count%2Cparticipated_live_count%2Callow_message%2Cindustry_category%2Corg_name%2Corg_homepage%2Cbadge%5B%3F (type%3Dbest_answerer)%5D.topics
这里我们可以从请求的这两个地址里发现一个问题,关于用户信息里的 url_token 其实就是获取单个用户详细信息的一个凭证也是请求的一个重要参数,并且当我们点开关注人的的链接时发现请求的地址的唯一标识也是这个 url_token
创建项目进行再次分析
通过命令创建项目
scrapy startproject zhihu_user
cd zhihu_user
scrapy genspider zhihu www.zhihu.com
直接通过 scrapy crawl zhihu 启动爬虫会看到如下错误:
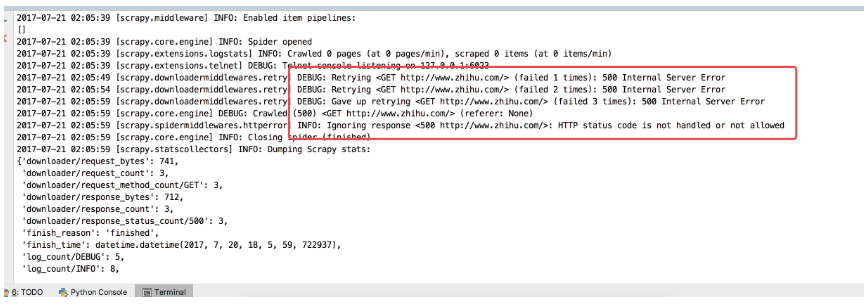
这个问题其实是爬取网站的时候经常碰到的问题,大家以后见多了就知道是怎么回事了,是请求头的问题,应该在请求头中加 User-Agent, 在 settings 配置文件中有关于请求头的配置默认是被注释的,我们可以打开,并且加上 User-Agent, 如下:

关于如何获取 User-Agent,可以在抓包的请求头中看到也可以在谷歌浏览里输入:chrome://version/ 查看
这样我们就可以正常通过代码访问到知乎了
然后我们可以改写第一次的请求,这个我们前面的 scrapy 文章关于 spiders 的时候已经说过如何改写 start_request,我们让第一次请求分别请求获取用户列表以及获取用户信息

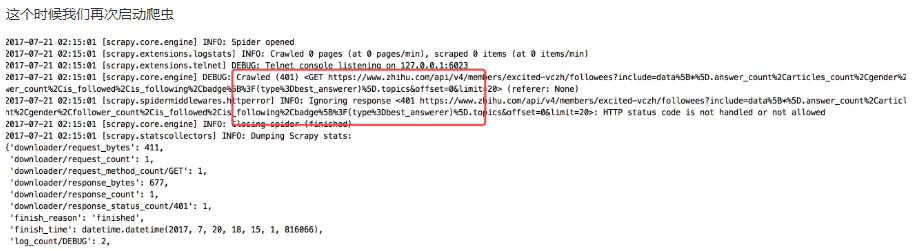
我们会看到是一个 401 错误,而解决的方法其实还是请求头的问题,从这里我们也可以看出请求头中包含的很多信息都会影响我们爬取这个网站的信息,所以当我们很多时候直接请求网站都无法访问的时候就可以去看看请求头,看看是不是请求头的哪些信息导致了请求的结果,而这里则是因为如下图所示的参数:
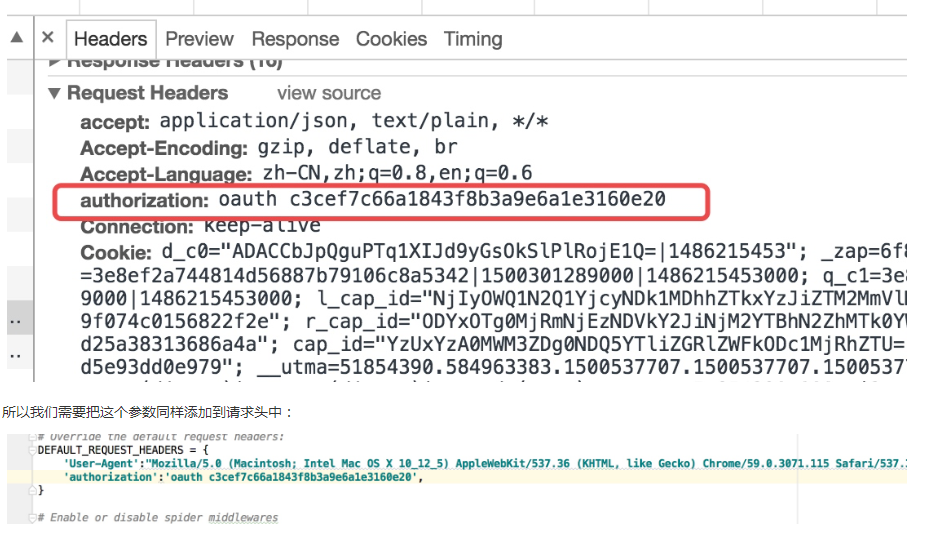
然后重新启动爬虫,这个时候我们已经可以获取到正常的内容
到此基本的分析可以说是都分析好了,剩下的就是具体代码的实现,在下一篇文张中写具体的实现代码内容!
今天关于Python爬虫从入门到放弃和十四之 Scrapy框架中选择器的用法的介绍到此结束,谢谢您的阅读,有关Python 爬虫从入门到放弃(二十三)之 Scrapy 的中间件 Downloader Middleware 实现 User-Agent 随机切换、python 爬虫从入门到放弃(二)之爬虫的原理、Python 爬虫从入门到放弃(十九)之 Scrapy 爬取所有知乎用户信息 (下)、Python 爬虫从入门到放弃(十八)之 Scrapy 爬取所有知乎用户信息 (上)等更多相关知识的信息可以在本站进行查询。
本文标签:




