在这篇文章中,我们将为您详细介绍Linux字符串截取和处理命令cut、printf、awk、sed、sort、wc的内容,并且讨论关于linux中字符串截取的相关问题。此外,我们还会涉及一些关于cut
在这篇文章中,我们将为您详细介绍Linux字符串截取和处理命令 cut、printf、awk、sed、sort、wc的内容,并且讨论关于linux中字符串截取的相关问题。此外,我们还会涉及一些关于cut、sort、wc、uniq、tee、tr、split、grep、cut、awk、sed的使用、int、dev、uat、prod、pp、sit、ides、qas、pet、sim、zha环境是什么、Linux awk、sort、uniq命令的知识,以帮助您更全面地了解这个主题。
本文目录一览:- Linux字符串截取和处理命令 cut、printf、awk、sed、sort、wc(linux中字符串截取)
- cut、sort、wc、uniq、tee、tr、split
- grep、cut、awk、sed的使用
- int、dev、uat、prod、pp、sit、ides、qas、pet、sim、zha环境是什么
- Linux awk、sort、uniq命令
")
Linux字符串截取和处理命令 cut、printf、awk、sed、sort、wc(linux中字符串截取)
1. cut [选项] 文件名
-f 列号 #提取第几列(分隔符默认为\t)
-d 分隔符 #指定分隔符
例如:cut -f 2 a.txt #截取文件a.txt内容的第二列(列号从1开始)
cut -f 2,4 a.txt #截取文件a.txt内容的第二列和第四列
cut -d ":" -f 1,3 /etc/passwd #截取文件passwd文件的第1列和第三列,以:分割取其中的第一列和第三列
2. printf ''输出类型 输出格式'' 输出内容
输出类型:
%ns 输出字符串,n是数字,指代输出几个字符
%ni 输出整数。n是数字,指代输出几个数字
%m.nf 位数和小数位数。例如:%8.2f 代表输出8位数,其中2位是小数,6位是整数
输出格式:
\a 输出警告声音
\b 输出退格键,也就是BackSpace键
\f 消除屏幕
\n 换行
\r 回撤
\t 水平制表符
\v 垂直制表符
举例:
printf ''%s %s %s\n'' 1 2 3 4 5 6 #表示每三个位一组输出,并加换行符
printf ''%s\t%s\t%s\t'' $(cat a.txt) #表示以4列的形式输出
3. awk ''条件1{动作1}条件2{动作2}...'' 文件名
awk ''{printf $2 "\t" $6 "\n"}'' a.txt #输出文件a.txt的第二列和第6列
4. sed [选项] ''[动作]'' 文件名 #说明:动作必须用引号引起来
选项:
-n 一般sed命令会把所有数据都输出到屏幕。如果加入此选择,则只会把经过sed命令处理的行输出到屏幕。
-e 允许对输入数据应用多条sed命令编辑
-i 用sed的修改结果直接修改读取的数据的文件,而不是修改屏幕输出
动作:
a\ 追加,在当前行后添加一行或多行。添加多行时除最后一行外,每行末尾需要用"\"代表数据未完结。
c\ 行替换,用c后面的字符替换原数据行,替换多行时除最后一行外,每行末尾需要用"\"代表数据未完结。
i\ 插入,在当前插入一行或多行,插入多行时,除最后一行外每行末尾需用"\"代表数据未完结。
d 删除,删除指定的行
p 打印,输出指定的行
s 字符串替换,用一个字符串替换另外一个字符串。格式为"行范围 s/旧字符串/新字符串/g"
sed可以接收管道符的输出结果
举例:
sed ''2p'' a.txt #输出第2行后,又把所有内容输出一遍
sed -n ''2p'' a.txt #只输出第二行
sed ''2,4d'' a.txt #删除第2到4行,只删除屏幕输出,不会更改文件本身的内容
sed ''2a hello'' a.txt #在第二行插入一行 hello
sed ''2i hello'' \
word'' a.txt #在第二行前插入多行 hello 一行 word一行
sed ''2c no person'' a.txt #用no person 替换第二行
sed ''4s/99/55/g'' a.txt #把第4行的99替换为55
sed -i ''4s/99/55/g'' a.txt #把第4行的99替换为55,修改的是原文件而不是屏幕输出
sed -i ''s/99/55/g'' a.txt #s前不加行号时表示替换整个文件中匹配的字符串
sed -e ''s/Liming//g;s/Gao//g'' a.txt #-e表示允许多个条件执行,把Liming替换为空,把Gao替换为空
5. sort [选项] 文件名 #排序
选项:
-f 忽略大小写
-n 以数值型进行排序,默认使用字符串型排序
-r 反向排序
-t 指定分隔符,默认分隔符是制表符
-k n[,m] 按照指定的字段范围排序。从第n字段开始,m字段结束(默认到行尾)
6. wc [选项] 文件名 #统计
选项:
-l 只统计行数
-w 只统计单词数
-m 只统计字符数

cut、sort、wc、uniq、tee、tr、split
8.10 shell特殊符号_cut命令
- *任意个任意字符
- ?任意一个字符
- #注释字符
- \脱义字符
- |管道符
- 几个与管道有关的命令
- cut分割,-d分隔符 -f指定段号,-c指定第几个字符
# cat /etc/passwd |head -2 |cut -d ":" -f 1以:分割,显示第一段
# cat /etc/passwd |head -2 |cut -d ":" -f 1,2以:分割,显示第一二段
# cat /etc/passwd |head -2 |cut -d ":" -f 1-3以:分割,显示第一二三段
# cat /etc/passwd |head -2 |cut -c 4 - sort排序(默认以ASCII码排序),-n以数字排序(字母与特殊符号会认为是0) -r反序排序 -t分隔符(指定第几段排序,使用很少) -kn1/-kn1,n2(使用很少)
# sort /etc/passwd - wc-l统计行数 -m统计字符数 -w统计词(以空白字符作为分隔符)
# wc -l 1.txt
# wc -m 1.txt
# wc -w 1.txt - uniq 去重,-c统计重复行数
# sort -n 2.txt | uniq -c - tee和>类似,重定向的同时还在屏幕上显示,-a追加并显示
# sort -n 2.txt |uniq -c |tee a.txt
# sort -n 2.txt |uniq -c |tee -a a.txt
# >2.txt清空2.txt命令 - tr替换字符,tr''a'' ''b'',大小写替换tr ''[a-z]'' ''[A-Z]''
# echo "aminglinux" |tr ''[al]'' ''[AL]'' - split 切割 -b大小(默认单位字节),-l行数
# split -b 100M bigfile
# split -l 1000 bigfile
- cut分割,-d分隔符 -f指定段号,-c指定第几个字符
8.11 sort_wc_uniq命令
8.12 tee_tr_split命令
8.13 shell特殊符号下
- $变量前缀,!$组合,正则里面表示行尾
- ;多条命令写到一行,用分号分割
- ~用户家目录,后面正则表达式表示匹配符
- &放到命令后面,会把命令丢到后台
>,>>,2>,2>>,&>&>正确和错误的输出内容全部输入到一个文件中- []指定字符中的一个,[0-9],[a-zA-Z],[abc]
- ||和&&,用于命令之间
- ||前边命令成功不执行后边命令,前边命令不成功执行后边命令
- &&前边命令执行成功则执行后边命令,前边命令不成功不执行后边命令
扩展
- source exec 区别http://alsww.blog.51cto.com/2001924/1113112
- Linux特殊符号大全http://ask.apelearn.com/question/7720
- sort并未按ASCII排序http://blog.csdn.net/zenghui08/article/details/7938975

grep、cut、awk、sed的使用
grep、cut、awk、sed 常常应用在查找日志、数据、输出结果等等,并对我们想要的数据进行提取。
通常grep,sed命令是对行进行提取,cut跟awk是对列进行提取
处理海量数据之grep命令
grep应用场景:
通常对数据进行 行的提取
语法:
grep [选项]...[内容]...[file]
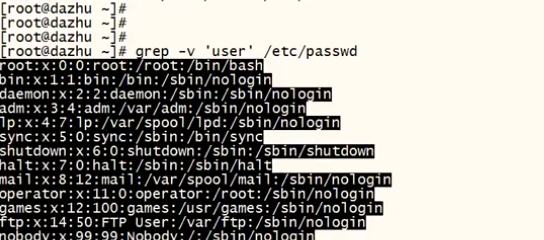
-v #对内容进行取反提取
-n #对提取的内容显示行号(原文件中对应行号)
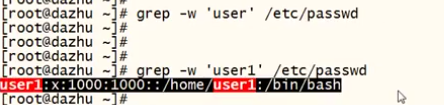
-w #精确匹配
-i #忽略大小写
^ #匹配开头行首
-E #正则匹配
系统文件进行实例演示:
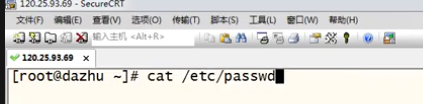

1. 提取是区分大小写的提取
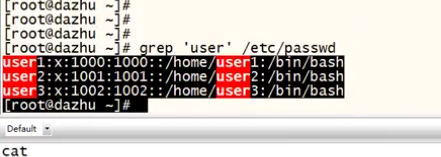
2. -v 提取上述以外的内容
-w 全字符匹配
-i
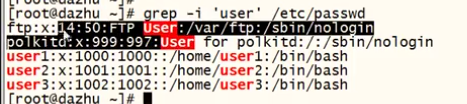
^ 开头
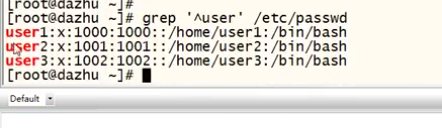
-E 正则

处理海量数据之cut命令
cut应用场景:
通常对数据进行列的提取
语法:
cut [选项]...[file]
-d #指定分割符
-f #指定截取区域
-c #以字符为单位进行分割
注意:不加-d选项,默认为制表符,不是空格
仍然以系统文件为实例
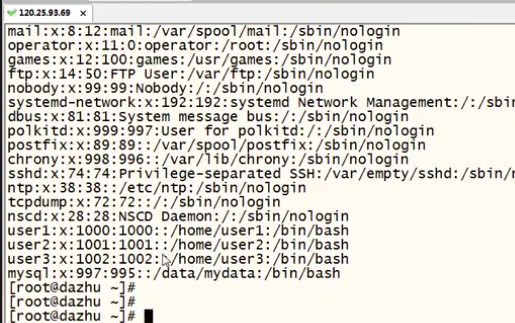
-d与-f:
eg:
以'':''为分隔符,截取出/etc/passwd的第一列跟第三列
cut -d '':'' -f 1,3 /etc/passwd
eg:
以'':''为分隔符,截取出/etc/passwd的第一列到第三列
cut -d '':'' -f 1-3 /etc/passwd
eg:
以'':''为分隔符,截取出/etc/passwd的第二列到最后一列
cut -d '':'' -f 2- /etc/passwd
-c:
eg:
截取/etc/passwd文件从第二个字符到第九个字符
cut -c 2-9 /etc/passwd
eg:
截取linux上面所有可登陆普通用户
/bin/bash #代表可以登录的用户
/sbin/nologin #代表不可以登录的用户
grep ''/bin/bash'' /etc/passwd | cut -d '':'' -f 1 | grep -v root
cut -d '':'' -f 1--------第一列代表所有用户

-v #对内容进行取反提取

处理海量数据之awk命令
awk的简介:
其实一门编程语言,支持条件判断,数组,循环等功能,与grep,sed被称为 linux三剑客
awk的应用场景:
通常对数据进行 列的提取 先执行条件再执行动作
语法:
awk ''条件 {执行动作}''文件名
awk ''条件1 {执行动作} 条件2 {执行动作} ...'' 文件名
或awk [选项] ''条件1 {执行动作} 条件2 {执行动作} ...'' 文件名
特殊要点与举例说明:
printf #格式化输出,不会自动换行。
( %ns:字符串型,n代表有多少个字符;
%ni:整型,n代表输出几个数字;
%.nf:浮点型,n代表的是小数点后有多少个小数)
print #打印出内容,默认会自动换行
\t #制表符(tab键 )
\n #换行符
eg:



注意:%s 是字符串 %i 是整形
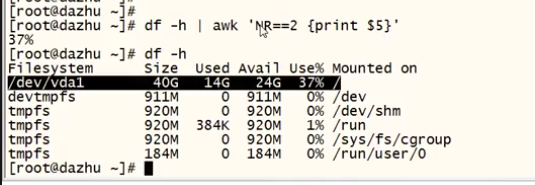
df -h 磁盘空间分区使用率

df -h |grep /dev/vda1 | awk ''{printf "/dev/vda1的使用率是:"} {print $5 }''
与之前传参不同: $1 #代表第一列 $2 #代表第二列 $0 #代表一整行
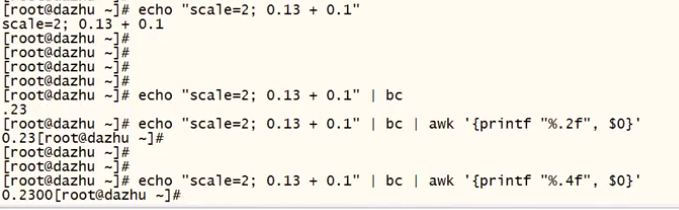
%.nf:浮点型,n代表的是小数点后有多少个小数 \n换行
小数:echo "scale=2; 0.13 + 0.1" | bc | awk ''{printf "%.2f\n", $0}''
-F #指定分割符
eg:cat /etc/passwd | awk -F":" ''{print $1}''
以:为分隔符打印出第一列
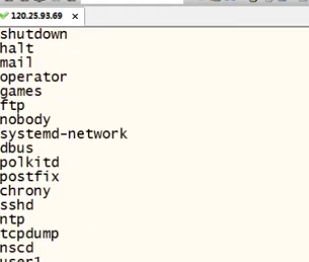
另一种方式

BEGIN #在读取所有行内容前就开始执行,常常被用于修改内置变量的值
FS #BEGIN时定义分割符
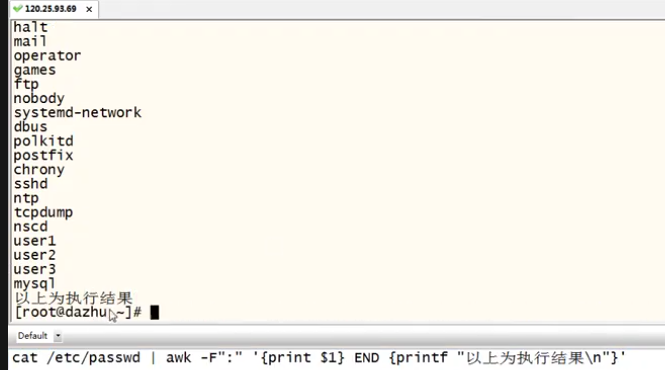
eg:cat /etc/passwd | awk ''BEGIN {FS=":"} {print $1}''
![]()
END #结束的时候 执行 (在最后的时刻才会执行)
NR #行号
eg:df -h | awk ''NR==2 {print $5}''
打印多行:
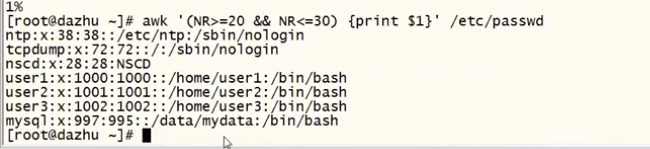

打印行数

处理海量数据之sed命令
sed的应用场景:(只更改输出 不会对源文件进行操作)
主要对数据进行处理(选取,新增,替换,删除,搜索)
sed语法:
sed [选项] [动作] 文件名
常见的选项与参数:
-n #把匹配到的行输出打印到屏幕
p #以行为单位进行查询,通常与-n一起使用
eg:
df -h | sed -n ''2p''

d #删除 (只是打印的内容看不见 并不是对原文件删除)
eg:
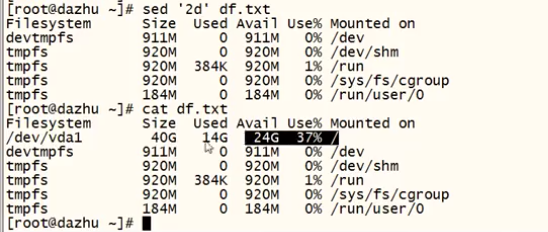
sed ''2d'' df.txt

源文件保留
a #在行的下面插入新的内容
eg: sed ''2a 1234567890'' df.txt
i #在行的上面插入新的内容
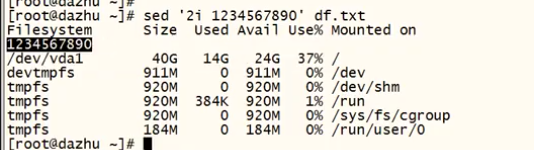
eg: sed ''2i 1234567890'' df.txt
c #替换
eg: sed ''2c 1234567890'' df.txt
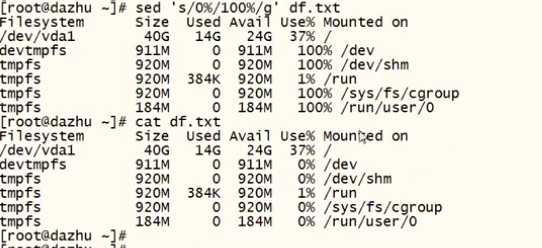
s/要被取代的内容/新的字符串/g #指定内容进行替换
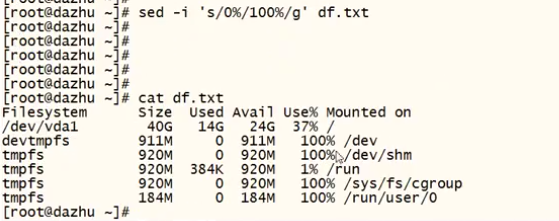
-i #对源文件进行修改(高危操作,慎用,用之前需要备份源文件)
修改 不打印
搜索:(同grep)
在文件中搜索内容 ''/100%/p''
eg:
cat -n df.txt | sed -n ''/100%/p''

-e #表示可以执行多条动作 (注意)
eg:
cat -n df.txt | sed -n -e ''s/100%/100%-----100%/g'' -e ''/100%-----100%/p''

转载自: https://www.cnblogs.com/hmm1995/p/10418968.html

int、dev、uat、prod、pp、sit、ides、qas、pet、sim、zha环境是什么
| 缩写 | 英文 | 解释 |
| int | Initialization | 初始化 |
| dev | development | 开发 |
| pp | Pre production | 预生产 |
| sit | System Integrate Test | 系统整合测试(内测) |
| ides | Internet Demonstration and Evaluation System | 交互式演示与评估系统 |
| qas | Quality Assurance System | 质量保证系统 |
| uat | Use Acceptance Test | 用户验收测试 |
| pet | Peformance Evaluation Test | 性能评估测试(压测) |
| sim | Simulation | 仿真 |
| pro/newPro | production | 生产 |
| prod | production | 生产 |
| zha | 生产 |

Linux awk、sort、uniq命令
Linux awk命令
语法
awk [选项参数] ‘script‘ var=value file(s)
awk [选项参数] -f scriptfile var=value file(s)
选项参数说明:
-F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or --asign var=value 赋值一个用户定义变量。
-f scripfile or --file scriptfile 从脚本文件中读取awk命令。
$n : 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 : 这个变量包含执行过程中当前行的文本内容。
每行按空格或TAB分割,输出文本中的1、4项
awk ‘{print $1,$4}‘ log.txt
使用","分割
awk -F,‘{print $1,$2}‘ log.txt
使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割
awk -F ‘[,]‘ ‘{print $1,$2,$5}‘ log.txt
awk -v # 设置变量
awk -va=1 ‘{print $1,$1+a}‘ log.txt
awk -f {awk脚本} {文件名}
awk -f cal.awk log.txt
过滤第一列大于2的行
awk ‘$1>2‘ log.txt
过滤第一列等于2的行
awk ‘$1==2 {print $1,$3}‘ log.txt
过滤第一列大于2并且第二列等于‘Are‘的行
awk ‘$1>2 && $2=="Are" {print $1,$3}‘ log.txt
输出第二列包含 "th",并打印第二列与第四列
awk ‘$2 ~ /th/ {print $2,$4}‘ log.txt
输出包含"re" 的行
awk ‘/re/ ‘ log.txt
忽略大小写
awk ‘BEGIN{IGnorECASE=1} /this/‘ log.txt
计算文件大小
ls -l *.txt | awk ‘{sum+=$5} END {print sum}‘
从文件中找出长度大于80的行
awk ‘length>80‘ log.txt
打印九九乘法表
seq 9 | sed ‘H;g‘ | awk -v RS=‘‘ ‘{for(i=1;i<=NF;i++)printf("%dx%d=%d%s",i,NR,i*NR,i==NR?"\n":"\t")}‘
Linux sort命令
语法
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
参数说明:
-b 忽略每行前面开始处的空格字符。
-c 检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-k 以哪一列进行排序
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
-u 去除重复行
对文件的行进行排序:
sort /etc/passwd
以 : 作为分隔符,以第3列按照数值大小进行排序:
sort -t : -nk 3 /etc/passwd
以 : 作为分隔符,分别按第4列、第3列按照数值大小进行排序:
sort -t: -nk 4 -nk 3 /etc/passwd
以 : 作为分隔符,以第4列按照数值大小进行排序,然后针对排序的列去重(sort|uniq是针对行去重,两者有区别):
sort -t: -nk 4 -u /etc/passwd
Linux uniq命令
语法
uniq [-cdu][-f<列数>][-s<字符位置>][文件]
参数说明:
-c 在每行前面显示该行重复的次数。
-d 仅显示重复的行列。
-u 仅没有重复的行列。
-f<N> 忽略前N列进行去重。
-s<字符位置> 忽略比较指定的字符。
例:
cat test.txt
2 b
5 e
3 c
1 a
4 d
1 a
2 b
2 a
1 b
排序并显示重复行次数:
[[email protected] ~]# sort test.txt|uniq -c
2 1 a
1 1 b
1 2 a
2 2 b
1 3 c
1 4 d
1 5 e
[[email protected] ~]#
忽略前1列,从第二列开始去重
[[email protected] ~]# sort -k 2 test.txt|uniq -f 1
1 a
1 b
3 c
4 d
5 e
[[email protected] ~]#
提示:uniq只会检查相邻的行,因此要去重必须先排序。
关于Linux字符串截取和处理命令 cut、printf、awk、sed、sort、wc和linux中字符串截取的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于cut、sort、wc、uniq、tee、tr、split、grep、cut、awk、sed的使用、int、dev、uat、prod、pp、sit、ides、qas、pet、sim、zha环境是什么、Linux awk、sort、uniq命令的相关信息,请在本站寻找。
本文标签:




