本文将为您提供关于来自PyExecutor的Spark日志记录的详细介绍,我们还将为您解释spark日志的相关知识,同时,我们还将为您提供关于.spark.sql.execution.WholeSta
本文将为您提供关于来自PyExecutor的Spark日志记录的详细介绍,我们还将为您解释spark 日志的相关知识,同时,我们还将为您提供关于.spark.sql.execution.WholeStageCodegenExec$ 这个异常影响运行吗?spark on yarn 的任务、Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTask、Executor 框架(二)Executor 与 ExecutorService 两个基本接口、Executor, ExecutorService 和 Executors 间的区别与联系的实用信息。
本文目录一览:- 来自PyExecutor的Spark日志记录(spark 日志)
- .spark.sql.execution.WholeStageCodegenExec$ 这个异常影响运行吗?spark on yarn 的任务
- Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTask
- Executor 框架(二)Executor 与 ExecutorService 两个基本接口
- Executor, ExecutorService 和 Executors 间的区别与联系
")
来自PyExecutor的Spark日志记录(spark 日志)
使用pyspark on访问Spark的log4j记录器的正确方法是什么
遗嘱执行人?
在驱动程序中这样做很容易,但我似乎不明白如何访问
executor上的日志记录功能,以便我可以在本地进行日志记录并
纱线收集当地的原木。
有什么方法可以访问本地记录器吗?
标准的日志记录过程是不够的,因为我无法访问spark
执行器的上下文。
答案1
小编典典不能对执行器使用本地log4j记录器。Python工作人员由
执行器jvm没有到java的“回调”连接,它们只是接收
命令。但是有一种方法可以使用标准python从执行者那里进行日志记录
伐木并用纱线捕捉它们。
在HDFS上,将每个python配置一次日志记录的python模块文件放入其中
worker和proxy日志记录函数(命名为logger.py):
import osimport loggingimport sysclass YarnLogger: @staticmethod def setup_logger(): if not ''LOG_DIRS'' in os.environ: sys.stderr.write(''Missing LOG_DIRS environment variable, pyspark logging disabled'') return file = os.environ[''LOG_DIRS''].split('','')[0] + ''/pyspark.log'' logging.basicConfig(filename=file, level=logging.INFO, format=''%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s'') def __getattr__(self, key): return getattr(logging, key)YarnLogger.setup_logger()然后在应用程序中导入此模块:
spark.sparkContext.addPyFile(''hdfs:///path/to/logger.py'')import loggerlogger = logger.YarnLogger()您可以在pyspark函数内部使用,例如普通的日志记录库:
def map_sth(s): logger.info("Mapping " + str(s)) return sspark.range(10).rdd.map(map_sth).count()在pyspark.log日志将在资源管理器上可见并将在上收集
应用程序完成,这样以后可以使用’yarn logs访问这些日志
-应用程序ID….`。

.spark.sql.execution.WholeStageCodegenExec$ 这个异常影响运行吗?spark on yarn 的任务
20/03/23 10:13:08 INFO cluster.YarnScheduler: Adding task set 1.0 with 1 tasks
20/03/23 10:13:08 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, slave2, executor 1, partition 0, PROCESS_LOCAL, 7778 bytes)
20/03/23 10:13:08 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on slave2:32779 (size: 6.3 KB, free: 912.3 MB)
20/03/23 10:13:09 WARN scheduler.TaskSetManager: Lost task 0.0 in stage 1.0 (TID 1, slave2, executor 1): java.lang.NullPointerException
at security.view.model.FirewallIncidentCount
at security.view.model.FirewallIncidentCount
at scala.collection.Iterator
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec
at org.apache.spark.sql.execution.SparkPlan
at org.apache.spark.rdd.RDD
at org.apache.spark.rdd.RDD
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$11.apply(Executor.scala:407)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1408)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:413)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)

Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTask
Executor 与 ExecutorService 两个基本接口")
Executor 框架(二)Executor 与 ExecutorService 两个基本接口
一、Executor 接口简介
Executor 接口是 Executor 框架的一个最基本的接口,Executor 框架的大部分类都直接或间接地实现了此接口。
只有一个方法
void execute(Runnable command): 在未来某个时间执行给定的命令。该命令可能在新的线程、已入池的线程或者正调用的线程中执行,这由 Executor 实现决定。
Executor 的几种实现原理介绍:
1、 <font color="blue">Executor 接口并没有严格地要求执行是异步的。</font > 在最简单的情况下,执行程序可以在调用者的线程中立即运行已提交的任务:
class DirectExecutor implements Executor {
public void execute(Runnable r) {
r.run();
}
}
2、 更常见的是,任务是在某个不是调用者线程的线程中执行的。以下执行程序将为每个任务生成一个新线程。
class ThreadPerTaskExecutor implements Executor {
public void execute(Runnable r) {
new Thread(r).start();
}
}
3、 许多 Executor 实现都对调度任务的方式和时间强加了某种限制。以下执行程序使任务提交与第二个执行程序保持连续,这说明了一个复合执行程序。
class SerialExecutor implements Executor {
private final Queue<Runnable> tasks = new ArrayDeque<Runnable>();
private final Executor executor;
Runnable active;
SerialExecutor(Executor executor) {
this.executor = executor;
}
public synchronized void execute(final Runnable r) {
tasks.offer(new Runnable() {
public void run() {
try {
r.run();
} finally {
scheduleNext();
}
}
});
if (active == null) {
scheduleNext();
}
}
protected synchronized void scheduleNext() {
if ((active = tasks.poll()) != null) {
executor.execute(active);
}
}
}
二、ExecutorService 接口简介
ExecutorService 是一个接口,提供了管理终止的方法,以及可为跟踪一个或多个异步任务执行状况而生成 Future 的方法。 ExecutorService 的实现:
- 三个实现类:
AbstractExecutorService(默认实现类) ,ScheduledThreadPoolExecutor,ThreadPoolExecutor Executors提供了此接口的几种常用实现的工厂方法。
方法摘要
1. 从 Executor 接口中继承了不跟踪异步线程,没有返回的 execute 方法:
void execute(Runnable command):
在未来某个时间执行给定的命令。该命令可能在新的线程、已入池的线程或者正调用的线程中执行,这由 Executor 实现决定。
2. 扩展的跟踪异步线程、返回 Future 接口的实现类的方法:
Future<?> submit(Runnable task): 提交一个 Runnable 任务用于执行,并返回一个表示该任务的 Future。该 Future 的 get 方法在成功 完成时将会返回 null。
**<T> Future<T> submit(Runnable task,T result): ** 提交一个 Runnable 任务用于执行,并返回一个表示该任务的 Future。该 Future 的 get 方法在成功完成时将会返回给定的结果。
<T> Future<T> submit(Callable<T> task): 提交一个返回值的任务用于执行,返回一个表示任务的未决结果的 Future。<font color="blue"> 该 Future 的 get 方法在成功完成时将会返回该任务的结果。如果想立即 < font color="red"> 阻塞任务的等待 </font>,则可以使用 result = exec.submit (aCallable).get (); 形式的构造 </font>
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException: 执行给定的任务,当所有任务完成时,返回保持任务状态和结果的 Future 列表。返回列表的所有元素的 Future.isDone () 为 true。注意,可以正常地或通过抛出异常来终止已完成 任务。如果正在进行此操作时修改了给定的 collection,则此方法的结果是不确定的。
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout,TimeUnit unit) throws InterruptedException: 超时等待,同上。
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException,ExecutionException: 与 invokeAll 的区别是,<font color="red"> 任务列表里只要有一个任务完成了,就立即返回。而且一旦正常或异常返回后,则取消尚未完成的任务。</font>
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout,TimeUnit unit) throws InterruptedException: 超时等待,同上。
boolean awaitTermination(long timeout,TimeUnit unit) throws InterruptedException: 一直等待,直到所有任务完成。请求关闭、发生超时或者当前线程中断,无论哪一个首先发生之后,都将导致阻塞,直到所有任务完成执行,或者超时时间的到来 <font color="red"> 如果此执行程序终止,则返回 true;如果终止前超时期满,则返回 false </font>
3. 管理生命周期
void shutdown(): 启动一次顺序关闭,执行以前提交的任务,但不接受新任务。如果已经关闭,则调用没有其他作用。 List<Runnable> shutdownNow(): 试图停止所有正在执行的活动任务,暂停处理正在等待的任务,并返回等待执行的任务列表。 无法保证能够停止正在处理的活动执行任务,但是会尽力尝试。例如,<font color="blue"> 在 ThreadPoolExecutor 中,通过 Thread.interrupt () 来取消典型的实现,所以如果任务无法响应中断,则永远无法终止。</font> boolean isShutdown(): 如果此执行程序已关闭,则返回 true。 boolean isTerminated(): 如果关闭后所有任务都已完成,则返回 true。注意,除非首先调用 shutdown 或 shutdownNow,否则 isTerminated 永不为 true。
用法示例
下面给出了一个网络服务的简单结构,这里线程池中的线程作为传入的请求。它使用了预先配置的 Executors.newFixedThreadPool (int) 工厂方法:
class NetworkService implements Runnable {
private final ServerSocket serverSocket;
private final ExecutorService pool;
public NetworkService(int port, int poolSize)
throws IOException {
serverSocket = new ServerSocket(port);
pool = Executors.newFixedThreadPool(poolSize);
}
public void run() { // run the service
try {
for (;;) {
pool.execute(new Handler(serverSocket.accept()));
}
} catch (IOException ex) {
pool.shutdown();
}
}
}
class Handler implements Runnable {
private final Socket socket;
Handler(Socket socket) { this.socket = socket; }
public void run() {
// read and service request on socket
}
}
<br/>
下列方法分两个阶段关闭 ExecutorService。第一阶段调用 shutdown 拒绝传入任务,然后调用 shutdownNow(如有必要)取消所有遗留的任务:
void shutdownAndAwaitTermination(ExecutorService pool) {
pool.shutdown(); // Disable new tasks from being submitted
try {
// Wait a while for existing tasks to terminate
if (!pool.awaitTermination(60, TimeUnit.SECONDS)) {
pool.shutdownNow(); // Cancel currently executing tasks
// Wait a while for tasks to respond to being cancelled
if (!pool.awaitTermination(60, TimeUnit.SECONDS))
System.err.println("Pool did not terminate");
}
} catch (InterruptedException ie) {
// (Re-)Cancel if current thread also interrupted
pool.shutdownNow();
// Preserve interrupt status
Thread.currentThread().interrupt();
}
}
参考文献
- 《java 并发编程的艺术》

Executor, ExecutorService 和 Executors 间的区别与联系
UML 简要类图关系:
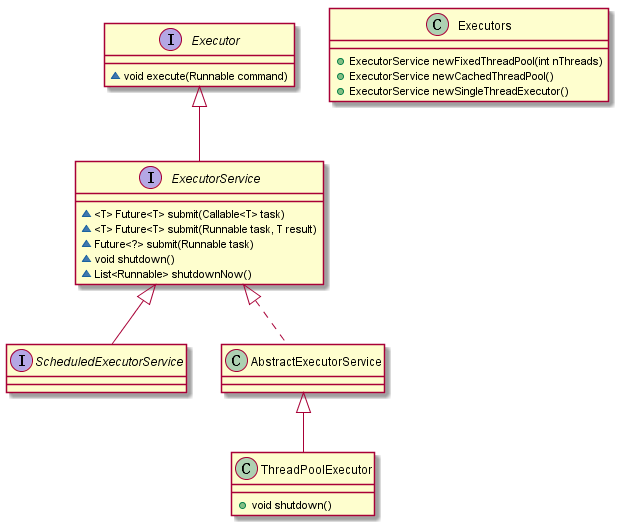
下面详细看一下三者的区别:
Executor vs ExecutorService vs Executors
正如上面所说,这三者均是 Executor 框架中的一部分。Java 开发者很有必要学习和理解他们,以便更高效的使用 Java 提供的不同类型的线程池。总结一下这三者间的区别,以便大家更好的理解:
- Executor 和 ExecutorService 这两个接口主要的区别是:ExecutorService 接口继承了 Executor 接口,是 Executor 的子接口
- Executor 和 ExecutorService 第二个区别是:Executor 接口定义了
execute()方法用来接收一个Runnable接口的对象,而 ExecutorService 接口中的submit()方法可以接受Runnable和Callable接口的对象。 - Executor 和 ExecutorService 接口第三个区别是 Executor 中的
execute()方法不返回任何结果,而 ExecutorService 中的submit()方法可以通过一个 Future 对象返回运算结果。 - Executor 和 ExecutorService 接口第四个区别是除了允许客户端提交一个任务,ExecutorService 还提供用来控制线程池的方法。比如:调用
shutDown()方法终止线程池。可以通过 《Java Concurrency in Practice》 一书了解更多关于关闭线程池和如何处理 pending 的任务的知识。 - Executors 类提供工厂方法用来创建不同类型的线程池。比如:
newSingleThreadExecutor()创建一个只有一个线程的线程池,newFixedThreadPool(int numOfThreads)来创建固定线程数的线程池,newCachedThreadPool()可以根据需要创建新的线程,但如果已有线程是空闲的会重用已有线程。
总结
下表列出了 Executor 和 ExecutorService 的区别:
| Executor | ExecutorService |
|---|---|
| Executor 是 Java 线程池的核心接口,用来并发执行提交的任务 | ExecutorService 是 Executor 接口的扩展,提供了异步执行和关闭线程池的方法 |
| 提供 execute () 方法用来提交任务 | 提供 submit () 方法用来提交任务 |
| execute () 方法无返回值 | submit () 方法返回 Future 对象,可用来获取任务执行结果 |
| 不能取消任务 | 可以通过 Future.cancel () 取消 pending 中的任务 |
| 没有提供和关闭线程池有关的方法 | 提供了关闭线程池的方法 |
关于来自PyExecutor的Spark日志记录和spark 日志的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于.spark.sql.execution.WholeStageCodegenExec$ 这个异常影响运行吗?spark on yarn 的任务、Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTask、Executor 框架(二)Executor 与 ExecutorService 两个基本接口、Executor, ExecutorService 和 Executors 间的区别与联系等相关内容,可以在本站寻找。
本文标签:




