在本文中,我们将详细介绍如何使用ApacheFlume发送日志数据至ApachePulsar的各个方面,并为您提供关于flume收集日志到hdfs的相关解答,同时,我们也将为您带来关于ApacheFl
在本文中,我们将详细介绍如何使用 Apache Flume 发送日志数据至 Apache Pulsar的各个方面,并为您提供关于flume收集日志到hdfs的相关解答,同时,我们也将为您带来关于Apache Flink 和 Apache Pulsar 的批流融合、Apache IoTDB x Apache Pulsar Meetup、Apache Pulsar 在智联招聘的实践 -- 从消息队列到基于 Apache Pulsar 的事件中心、Apache Pulsar 正式引入 Cloud Storage Sink 连接器:实现 Apache Pulsar 数据上云的有用知识。
本文目录一览:- 如何使用 Apache Flume 发送日志数据至 Apache Pulsar(flume收集日志到hdfs)
- Apache Flink 和 Apache Pulsar 的批流融合
- Apache IoTDB x Apache Pulsar Meetup
- Apache Pulsar 在智联招聘的实践 -- 从消息队列到基于 Apache Pulsar 的事件中心
- Apache Pulsar 正式引入 Cloud Storage Sink 连接器:实现 Apache Pulsar 数据上云
")
如何使用 Apache Flume 发送日志数据至 Apache Pulsar(flume收集日志到hdfs)
阅读本文需要约 7 分钟。
Apache Flume 是一个分布式的、可靠易用的系统,可以有效地收集和汇总来自多种源系统的大量日志数据,或转移这些数据至一个数据中心存储。
Apache Pulsar 是 Yahoo 基于 Apache BookKeeper 开发和开源的下一代分布式消息系统。Apache Pulsar 已经从下一代分布式消息系统演化成为一个流原生数据平台。
本文主要介绍使用 Flume 实现日志搜集,并发送日志数据至 Pulsar 进行消费。整体架构如下:
本文主要涉及 Flume 和 Pulsar 服务的搭建、测试、数据的发送及消费,全面讲解了 Flume 如何发送数据到 Pulsar 以及 Pulsar 如何消费数据。上图虽然画了 3 个 Flume 服务,但是本次测试只使用了一个,目的是快速走通整个流程,消费数据时也是只启动了一个消费端。后期如果有需求,可以根据此次试验快速完成扩展。
安装环境依赖
在搭建本次试验之前,需要安装以下依赖,本次试验是在 Mac 系统上进行的测试。
Docker
https://www.docker.com/get-started
Java 8 https://www.oracle.com/technetwork/java/javase/downloads/index.html
Maven 3.5 或更高版本 https://archive.apache.org/dist/maven/maven-3/
Git https://www.linode.com/docs/development/version-control/how-to-install-git-on-linux-mac-and-windows/
Telnet
http://www.telnet.org/htm/howto.htm
编译并打包项目
你能通过以下任一方式编译并打包项目:
方法 1:在本地编译并打包本项目
注意
在打包本项目之前,需要安装并配置好 Java 、 Maven 和 Git 的相关环境。
1、从 GitHub 克隆 Flume sink 代码。
git clone https://github.com/streamnative/pulsar-flume-ng-sink.git2、使用 Maven 将本项目打包。
1 cd pulsar-flume-ng-sink
2 mvn clean package如果出现以下信息,则说明打包成功:
1 [INFO] ------------------------------------------------------------------------
2 [INFO] BUILD SUCCESS
3 [INFO] ------------------------------------------------------------------------方法 2:使用 Docker 镜像编译
并打包本项目
如果本地不方便安装 Java 和 Maven 环境,可以使用 Docker 环境进行打包。
1、拉取并启动镜像。
本次使用的 Docker 镜像是 maven:3.6-jdk-8 ,带有 Maven 、 Java 和 Git 的相关环境。
1 docker pull maven:3.6-jdk-8
2 docker run -d -it --name docker-package maven:3.6-jdk-8 /bin/bash上述命令会启动一个基于镜像 maven:3.6-jdk-8 名称为 docker-package 的 Docker 服务。
1 docker ps -a | grep docker-package
2 580376b38aa8 maven:3.6-jdk-8 "/usr/local/bin/mvn-…" 5 minutes ago Up 5 minutes docker-package
3 docker exec -it docker-package /bin/bash使用上述命令确认该镜像是否成功启动。成功启动后,我们就已经在 Docker 服务中了。
2、克隆代码并打包。
成功启动该镜像后,可以非常方便地进行打包。类似地,我们可以使用与在本地打包相同的方法,在 Docker 中对本项目进行打包。
1 git clone https://github.com/streamnative/pulsar-flume-ng-sink.git
2 cd pulsar-flume-ng-sink/
3 mvn clean package如果出现以下信息,则说明打包成功:
1 [INFO] ------------------------------------------------------------------------
2 [INFO] BUILD SUCCESS
3 [INFO] ------------------------------------------------------------------------打包成功后,在本目录下的 target 文件夹中会出现一个 jar 包,名字类似于 flume-ng-pulsar-sink-<version>.jar。
安装 Pulsar
为了方便测试,本次安装 standalone Pulsar,并且使用 Docker 镜像 apachepulsar/pulsar:2.3.0 启动服务。
1docker pull apachepulsar/pulsar:2.3.0
2docker run -d -it -p 6650:6650 -p 8080:8080 -v $PWD/data:/pulsar/data --name pulsar-flume-standalone apachepulsar/pulsar:2.3.0 bin/pulsar standalone该服务暴露 6650 和 8080 端口供外部服务使用,该容器将 Pulsar 服务的 data 目录挂载在了当前目录下,并且命名为 pulsar-flume-standalone。 -d 参数表示使该服务使用后台模式运行;-it 参数表示以交互模式运行容器,并为容器分配一个伪输入终端。
1docker logs -f pulsar-flume-standalone
2
307:53:43.844 [pulsar-web-55-6] INFO org.apache.pulsar.broker.web.PulsarWebResource - Successfully validated clusters on tenant [public]
407:53:43.856 [pulsar-web-55-6] INFO org.apache.pulsar.broker.admin.impl.NamespacesBase - [null] Created namespace public/default
507:53:43.859 [pulsar-web-55-6] INFO org.eclipse.jetty.server.RequestLog - 172.17.0.3 - - [28/Apr/2019:07:53:43 +0000] "PUT /admin/v2/namespaces/public/default HTTP/1.1" 204 0 "-" "Jersey/2.27 (HttpUrlConnection 1.8.0_181)" 17
607:53:43.864 [pulsar-web-55-6] INFO org.apache.pulsar.broker.web.PulsarWebResource - Successfully validated clusters on tenant [public]
707:53:43.868 [pulsar-ordered-OrderedExecutor-1-0-EventThread] INFO org.apache.pulsar.zookeeper.ZooKeeperDataCache - [State:CONNECTED Timeout:30000 sessionid:0x1000112d2ea000a local:/127.0.0.1:38464 remoteserver:localhost/127.0.0.1:2181 lastZxid:154 xid:41 sent:41 recv:43 queuedpkts:0 pendingresp:0 queuedevents:0] Received ZooKeeper watch event: WatchedEvent state:SyncConnected type:NodeDataChanged path:/admin/policies/public/default
807:53:43.869 [pulsar-web-55-6] INFO org.apache.pulsar.broker.admin.impl.NamespacesBase - [null] Successfully updated the replication clusters on namespace public/default使用 docker logs -f pulsar-flume-standalone 命令查看 Docker 日志。如果出现以上的日志信息,则说明 Pulsar 在单机模式下启动成功了。
使用 Flume
使用 Docker 搭建 Flume 环境。
1、启动 Flume 容器
1 docker pull maven:3.6-jdk-8
2 docker run -d -it --link pulsar-flume-standalone -p 44445:44445 --name flume maven:3.6-jdk-8 /bin/bash以上命令会启动一个名称为 flume 的服务,它链接到 pulsar-flume-standalone 容器,暴露 44445 端口的 Flume 服务。
1 docker ps -a | grep flume
2 27c7555e5481 maven:3.6-jdk-8 "/usr/local/bin/mvn-…" 46 seconds ago Up 45 seconds 0.0.0.0:44445->44445/tcp flume使用 docker ps 命令可以看到启动的 Flume 服务。
2、安装 Flume 服务
(1)进入 Flume 容器。
docker exec -it flume /bin/bash(2)下载并解压 Apache Flume 压缩包到当前目录。
1 wget http://apache.01link.hk/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
2 tar -zxvf apache-flume-1.9.0-bin.tar.gz(3)退出 Flume 容器。
3、部署 pulsar-flume-ng-sink
(1)修改配置文件。本次测试需使用以下 2 个配置文件:
配置文件 flume-example.conf (https://github.com/streamnative/pulsar-flume-ng-sink/blob/master/src/test/resources/flume-example.conf)
flume-example.conf 中兼容 Flume 的配置。更多关于 Flume 配置的信息,参阅 Flume 官方文档,此处简单介绍以下信息:
1 # Describe/configure the source
2 a1.sources.r1.type = netcat
3 a1.sources.r1.bind = 0.0.0.0
4 a1.sources.r1.port = 44445
5
6 ## Describe the sink
7 a1.sinks.k1.type = org.apache.flume.sink.pulsar.PulsarSink
8 # Configure the pulsar service url (without `pulsar://`)
9 a1.sinks.k1.serviceUrl = pulsar-flume-standalone:6650
10 a1.sinks.k1.topicName = flume-test-topic
11 a1.sinks.k1.producerName = flume-test-producer参数说明:
a1.sources.r1.type
指定数据来源。为了方便测试,此处指定 netcat 可以使用 Telnet 工具进行测试。
a1.sources.r1.bind
绑定本机的 IP 地址。
a1.sources.r1.port
绑定本机的 44445 端口。启动容器会映射该端口映射,方便测试。
a1.sinks.k1.type
指定使用的 PulsarSink 类。这个不需要更改。
a1.sinks.k1.serviceUrl
指定 Pulsar 服务的地址。你可以根据实际需求,更改该参数。此处使用容器地址是 pulsar-flume-standalone:6650。如需支持 SSL,可以配置打开 useTLS 选项。
a1.sinks.k1.topicName
指定需要发送至 Pulsar 的目标 Topic。如果 Pulsar 服务没有该 Topic ,则会自动新建该 Topic。
a1.sinks.k1.producerName
指定 sink 的名称,不能重复。
以上是一些比较简单的配置,根据这些配置,我们可以完成本次试验。更多关于生产环境参数的置、客户端配置和 Producer 配置等信息,参阅 pulsar-flume-ng-sink 的配置 (https://github.com/streamnative/pulsar-flume-ng-sink#configurations)。
配置文件 flume-env.sh (https://github.com/streamnative/pulsar-flume-ng-sink/blob/master/src/test/resources/flume-env.sh)
flume-env.sh 文件是 Flume 在启动的时需要使用的一些库的查找路径,需要将已打包好的 flume-ng-pulsar-sink-<version>.jar 的 jar 包复制到该路径下。
以下是本次测使用的 flume-env.sh 配置:
1 #!/bin/sh
2 export JAVA_HOME=/docker-java-home
3
4 FLUME_CLASSPATH=/docker-java-home/lib(2)复制配置文件至 Flume 服务器。
按照以上步骤修改完配置文件后,可以将这些配置复制到 Flume 服务所在的容器。
1 docker cp flume-example.conf flume:/apache-flume-1.9.0-bin/conf/
2 docker cp flume-env.sh flume:/apache-flume-1.9.0-bin/conf/(3)复制 flume-ng-pulsar-sink-.jar 至 Flume 容器。
使用以下任一方法:
方法 1
如果在本地进行了打包,使用以下命令可以将该 jar 包复制到 Flume 容器。进入打包文件的根目录,使用 Docker 命令进行复制。
1 cd pulsar-flume-ng-sink
2 docker cp target/flume-ng-pulsar-sink-1.9.0.jar flume:apache-flume-1.9.0-bin/lib/方法 2
如果在容器中进行了打包,首先将容器中已打包的 jar 包复制到本地,再使用 Docker 命令复制到 Flume 容器中。
1 docker cp docker-package:/pulsar-flume-ng-sink/target/flume-ng-pulsar-sink-1.9.0.jar .
2 docker cp flume-ng-pulsar-sink-1.9.0.jar flume:apache-flume-1.9.0-bin/lib/至此,已成功构建启动 Flume 服务所需要的环境和配置文件。
4、启动 Flume 服务
进入 Flume 容器并启动 flume agent。
1 docker exec -it flume /bin/bash
2 apache-flume-1.9.0-bin/bin/flume-ng agent --conf apache-flume-1.9.0-bin/conf/ -f apache-flume-1.9.0-bin/conf/flume-example.conf -n a1在以上命令中,--conf 指定 Flume 服务的配置文件夹,-f 指定配置文件,-n 指定名称(需要与配置文件里的相同)。
如果出现如下信息,则说明 flume-ng agent 启动成功。
1 Info: Sourcing environment configuration script /apache-flume-1.9.0-bin/conf/flume-env.sh
2 Info: Including Hive libraries found via () for Hive access
3 + exec /docker-java-home/bin/java -Xmx20m -cp ''/apache-flume-1.9.0-bin/conf:/apache-flume-1.9.0-bin/lib/*:/docker-java-home/lib:/lib/*'' -Djava.library.path= org.apache.flume.node.Application -f apache-flume-1.9.0-bin/conf/flume-example.conf -n a15、启动消费端
在新的窗口中进入 Pulsar 的容器,再启动消费端(用于消费 Flume 发出的信息)。
测试使用的脚本文件在这里(https://github.com/streamnative/pulsar-flume-ng-sink/blob/master/src/test/python/pulsar-flume.py)。脚本文件内容如下:
1 import pulsar
2
3 client = pulsar.Client(''pulsar://localhost:6650'')
4 consumer = client.subscribe(''flume-test-topic'',
5 subscription_name=''sub'')
6
7 while True:
8 msg = consumer.receive()
9 print("Received message: ''%s''" % msg.data())
10 consumer.acknowledge(msg)
11
12 client.close()首先,该脚本会连接到本地 Pulsar 服务的 6650 端口。由于在 Pulsar 服务所在的容器中启动的该脚本,因此,服务地址是 localhost:6650。该脚本会在 flume-test-topic Topic 上进行消费,该 Topic 正是我们在 flume-example.conf 中配置的 Topic ,并且指定订阅名称为 sub。
(1)复制测试脚本文件到 Pulsar 服务所在的容器。
1 cd pulsar-flume-ng-sink
2 docker cp src/test/python/pulsar-flume.py pulsar-flume-standalone:/pulsar/(2)进入 Pulsar 服务容器。
docker exec -it pulsar-flume-standalone /bin/bash(3)启动消费者脚本。
1 python pulsar-flume.py
2 2019-04-28 09:01:43.581 INFO Client:88 | Subscribing on Topic :flume-test-topic
3 2019-04-28 09:01:43.582 INFO ConnectionPool:72 | Created connection for pulsar://localhost:6650
4 2019-04-28 09:01:43.585 INFO ClientConnection:300 | [127.0.0.1:56088 -> 127.0.0.1:6650] Connected to broker
5 2019-04-28 09:01:43.590 INFO HandlerBase:52 | [persistent://public/default/flume-test-topic, sub, 0] Getting connection from pool
6 2019-04-28 09:01:43.590 INFO ConnectionPool:72 | Created connection for pulsar://c063d9580d4c:6650
7 2019-04-28 09:01:43.591 INFO ClientConnection:302 | [127.0.0.1:56090 -> 127.0.0.1:6650] Connected to broker through proxy. Logical broker: pulsar://c063d9580d4c:6650
8 2019-04-28 09:01:43.614 INFO ConsumerImpl:169 | [persistent://public/default/flume-test-topic, sub, 0] Created consumer on broker [127.0.0.1:56090 -> 127.0.0.1:6650]启动脚本后出现以上信息,则说明消费端已经成功启动。
6、发送消息进行测试
如前文所述,本次测试使用 Telnet 工具。
开启一个新的窗口,使用以下 Telnet 命令,发送数据到 Flume 的 44445 端口。
1 ➜ ~ telnet localhost 44445
2 Trying ::1...
3 Connected to localhost.
4 Escape character is ''^]''.
5 hello
6 OK
7 world
8 OK此时,在刚才开启的消费端可以看到通过 Telnet 发送的信息,内容大致如下:
1 ''eceived message: ''hello
2 ''eceived message: ''world以上正是通过 Telnet 发送到 Flume 44445 端口的数据。
清理环境
完成本次测试后,使用以下命令停止并且删除相关容器:
1docker stop flume
2docker rm flume
3docker stop pulsar-flume-standalone
4docker rm pulsar-flume-standalone
5docker stop docker-package
6docker rm docker-package更多信息
Apache Pulsar Connector 系列文章:
Pulsar Connector 预览篇
Pulsar Sink 入门指南
Pulsar Source 入门篇
使用 Elastic Beats 搜集日志到 Pulsar
审校 | Anonymitaet
编辑 | Irene
更多关于 Pulsar 的技术干货和产品动态,请关注 StreamNative 微信公众号。
本文分享自微信公众号 - StreamNative(StreamNative)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。

Apache Flink 和 Apache Pulsar 的批流融合
本文由郭斯杰老师在 Flink Forward San Francisco 2019 大会上的演讲内容整理而成。Apache Flink(以下简称 Flink)和 Apache Pulsar(以下简称Pulsar)的开源数据技术框架能够以不同的方式融合来提供大规模弹性数据处理,本文将详细介绍 Flink 和 Pulsar 在批流应用程序的融合情况。
本文目录:
1. Apache Pulsar 简介
2. Pulsar 数据视图:分片数据流
3. Flink + Pulsar 的融合
3.1 未来融合方式
3.2 现有融合方式
4. 总结
1.Apache Pulsar 简介
Apache Pulsar 是一个开源的分布式发布-订阅消息系统, 由 Apache 软件基金会管理,并于 2018 年 9 月成为 Apache顶级开源项目。 Pulsar 是一种多租户、高性能解决方案,用于服务器到服务器消息传递,包括多个功能,例如,在一个 Pulsar 实例中对多个集群提供原生支持、集群间消息跨地域的无缝复制、发布和端到端的低延迟、超过一百万个主题的无缝扩展以及由 Apache BookKeeper 提供的持久消息存储保证消息传递。现在我们来讨论Pulsar 和其他发布-订阅消息传递框架之间的主要区别:
第一个区别是,虽然 Pulsar 提供了灵活的发布-订阅消息传递系统,但它也由持久的日志存储支持——因此需在一个框架下集成消息传递和存储功能。由于 Pulsar 采用了分层架构,它可以即时故障恢复、支持独立可扩展性和无需均衡的集群扩展。Pulsar 的架构与其他发布-订阅系统类似,框架由主题组成,而主题是主要数据实体。如下图所示,生产者向主题发送数据,消费者从主题接收数据。
第二个区别是,Pulsar 的框架构建从一开始就考虑到了多租户。这意味着每个 Pulsar 主题都有一个分层的管理结构,使得资源分配、资源管理和团队协作变得高效而容易。由于 Pulsar 提供属性(租户)级、命名空间级和主题级的资源隔离,Pulsar 的多租户特性不仅能使数据平台管理人员轻松扩展新的团队,还能跨集群共享数据,简化团队协作。
最后,Pulsar 灵活的消息传递框架统一了流式和队列数据消费模型,并提供了更大的灵活性。如下图所示,Pulsar 保存主题中的数据,而多个团队可以根据其工作负载和数据消费模式独立地消费数据。
2.Pulsar 数据视图:分片数据流
Apache Flink 是一个流式优先计算框架,它将批处理视为流处理的特殊情况。在对数据流的看法上,Flink 区分了有界和无界数据流之间的批处理和流处理,并假设对于批处理工作负载数据流是有限的,具有开始和结束。
在数据层上,Apache Pulsar 与 Apache Flink 的观点相似。该框架也使用流作为所有数据的统一视图,分层架构允许传统发布-订阅消息传递,用于流式工作负载和连续数据处理;并支持分片流(Segmented Streams)和有界数据流的使用,用于批处理和静态工作负载。
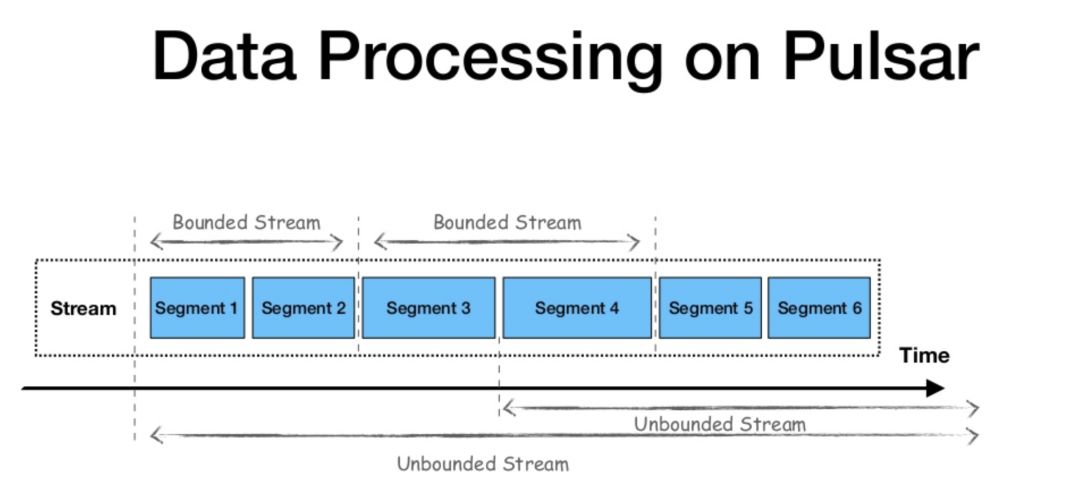
如下图所示,为了并行处理数据,生产者向主题发送数据后,Pulsar 根据数据流量对主题进行分区,再在每个分区中进行分片,并使用 Apache BookKeeper 进行分片存储。这一模式允许在同一个框架中集成传统的发布-订阅消息系统和分布式并行计算。

3.Flink + Pulsar 的融合
Apache Flink 和 Apache Pulsar 已经以多种方式融合。在以下内容中,我会介绍两个框架间未来一些可行的融合方式,并分享一些融合使用两个框架的示例。
3.1 未来融合方式
Pulsar 能以不同的方式与 Apache Flink 融合,一些可行的融合包括,使用流式连接器(Streaming Connectors)支持流式工作负载,或使用批式源连接器(Batch Source Connectors)支持批式工作负载。Pulsar 还提供了对 Schema 的原生支持,可以与 Flink 集成并提供对数据的结构化访问,例如,使用 Flink SQL 在 Pulsar 中查询数据。另外,还能将 Pulsar 作为 Flink 的状态后端。由于 Pulsar 具有分层架构(Apache Bookkeeper 支持下的 Streams 和 Segmented Streams),因此可以将 Pulsar 作为存储层并存储 Flink 状态。
从架构的角度来看,我们可以想象两个框架之间的融合,使用 Apache Pulsar 作为统一的数据层视图,使用 Apache Flink 作为统一的计算、数据处理框架和 API。
3.2 现有融合方式
两个框架之间的融合正在进行中,开发人员已经可以通过多种方式融合使用 Pulsar 和 Flink。例如,在 Flink DataStream 应用程序中,Pulsar 可以作为流数据源和流接收器。开发人员能使 Flink 作业从 Pulsar 中获取数据,再进行计算并处理实时数据,最后将数据作为流接收器发送回 Pulsar 主题。示例如下:
PulsarSourceBuilder<String>builder = PulsarSourceBuilder.builder(new SimpleStringSchema()) .serviceUrl(serviceUrl) .topic(inputTopic) .subscriptionName(subscription);SourceFunction<String> src = builder.build();DataStream<String> input = env.addSource(src); DataStream<WordWithCount> wc = input .flatMap((FlatMapFunction<String, WordWithCount>) (line, collector) -> { for (String word : line.split("\\s")) { collector.collect(new WordWithCount(word, 1)); } }) .returns(WordWithCount.class) .keyBy("word") .timeWindow(Time.seconds(5)) .reduce((ReduceFunction<WordWithCount>) (c1, c2) -> new WordWithCount(c1.word, c1.count + c2.count)); if (null != outputTopic) { wc.addSink(new FlinkPulsarProducer<>( serviceUrl, outputTopic, new AuthenticationDisabled(), wordWithCount -> wordWithCount.toString().getBytes(UTF_8), wordWithCount -> wordWithCount.word )).setParallelism(parallelism);} else { // print the results with a single thread, rather than in parallel wc.print().setParallelism(1);}
另一个开发人员可利用的框架间的融合,已经包括将 Pulsar 用作 Flink 应用程序的流式源和流式表接收器,代码示例如下:
PulsarSourceBuilder<String> builder = PulsarSourceBuilder.builder(new SimpleStringSchema()) .serviceUrl(serviceUrl) .topic(inputTopic) .subscriptionName(subscription);SourceFunction<String> src = builder.build();DataStream<String> input = env.addSource(src); DataStream<WordWithCount> wc = input .flatMap((FlatMapFunction<String, WordWithCount>) (line, collector) -> { for (String word : line.split("\\s")) { collector.collect( new WordWithCount(word, 1) ); } }) .returns(WordWithCount.class) .keyBy(ROUTING_KEY) .timeWindow(Time.seconds(5)) .reduce((ReduceFunction<WordWithCount>) (c1, c2) -> new WordWithCount(c1.word, c1.count + c2.count)); tableEnvironment.registerDataStream("wc",wc);Table table = tableEnvironment.sqlQuery("select word, `count` from wc");table.printSchema();TableSink sink = null;if (null != outputTopic) { sink = new PulsarJsonTableSink(serviceUrl, outputTopic, new AuthenticationDisabled(), ROUTING_KEY);} else { // print the results with a csv file sink = new CsvTableSink("./examples/file", "|");}table.writeToSink(sink);
最后,Flink 融合 Pulsar 作为批处理接收器,负责完成批处理工作负载。Flink 在静态数据集完成计算之后,批处理接收器将结果发送至 Pulsar。示例如下:
// create PulsarOutputFormat instancefinal OutputFormat pulsarOutputFormat = new PulsarOutputFormat(serviceUrl, topic, new AuthenticationDisabled(), wordWithCount -> wordWithCount.toString().getBytes()); // create DataSetDataSet<String> textDS = env.fromElements(EINSTEIN_QUOTE); // convert sentences to wordstextDS.flatMap(new FlatMapFunction<String, WordWithCount>() { @Override public void flatMap(String value, Collector<WordWithCount> out) throws Exception { String[] words = value.toLowerCase().split(" "); for(String word: words) { out.collect(new WordWithCount(word.replace(".", ""), 1)); } }}) // filter words which length is bigger than 4.filter(wordWithCount -> wordWithCount.word.length() > 4) // group the words.groupBy(new KeySelector<WordWithCount, String>() { @Override public String getKey(WordWithCount wordWithCount) throws Exception { return wordWithCount.word; }}) // sum the word counts.reduce(new ReduceFunction<WordWithCount>() { @Override public WordWithCount reduce(WordWithCount wordWithCount1, WordWithCount wordWithCount2) throws Exception { return new WordWithCount(wordWithCount1.word, wordWithCount1.count + wordWithCount2.count); }}) // write batch data to Pulsar.output(pulsarOutputFormat);
4.总结
Pulsar 和 Flink 对应用程序在数据和计算级别如何处理数据的视图基本一致,将“批”作为“流”的特殊情况进行“流式优先”处理。通过 Pulsar 的 Segmented Streams 方法和 Flink 在一个框架下统一批处理和流处理工作负载的几个步骤,可以应用多种方法融合两种技术,提供大规模的弹性数据处理。欢迎订阅 Apache Flink 和 Apache Pulsar 邮件,及时了解领域最新发展,或在社区分享您的想法和建议。
▼ 社区福利 ▼
推荐 4 个 Apache 顶级项目的官方公众号,希望对大家了解开源大数据生态,扩展技术视野有所帮助。
Apache Pulsar是下一代云原生流数据平台,助力企业快速分析实时数据,激活数据价值,实现 C 位出道。这里是 Pulsar 前沿技术的传播圣地,也是技术爱好者、开发者和终极用户时刻关注的技术平台。我们定时分享 Pulsar 优质内容,包括社区活动、技术文章、用户案例、行业动态和热点话题等,让你全面拥抱 Pulsar 的一手讯息。Apache Pulsar,助力千万企业和技术人开疆拓土、共同成长。
▼ Apache Pulsar ▼
Apache HBase 技术社区,研究探讨 HBase 内核原理,源码剖析,周边生态以及实践应用,汇集众多 Apache HBase PMC&Committer 以及爱好使用者,提供一线 Apache HBase 企业实战资料以及 Flink 集成等资讯。
▼ HBase 技术社区 ▼
Apache Kylin,介绍 Kylin 的功能特性、应用案例、经验分享、社区资讯、活动等。开源大数据分布式 OLAP 引擎 Apache Kylin 于 2014 年开源,在 2015 年和 2016 年连续获得 InfoWorld 的 BOSSIE 奖:年度最佳开源大数据工具奖,发展至今在全球已经拥有超过 1000 家企业用户。作为首个被 Apache 软件基金会认证的由中国人主导的顶级开源项目,Kylin 为万亿数据提供亚秒级查询,并可以和现有的 Hadoop / Spark 及 BI 无缝集成。
▼ Apache Kylin ▼
Ververica,由 Apache Flink Community China 运营管理,旨在联合国内的 Flink 大 V,向国内宣传和普及 Flink 相关的技术。公众号将持续输出 Flink 最新社区动态,入门教程、Meetup 资讯、应用案例以及源码解析等内容,希望联合社区同学一起推动国内大数据技术发展。
▼ Ververica ▼
/ Apache Flink 极客挑战赛,10 万奖金等你拿 /
你也「在看」吗?