本文的目的是介绍Python中如何根据列值从DataFrame中选择行?的详细情况,特别关注pythondataframe选取一列的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一
本文的目的是介绍Python中如何根据列值从DataFrame中选择行?的详细情况,特别关注python dataframe 选取一列的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解Python中如何根据列值从DataFrame中选择行?的机会,同时也不会遗漏关于pandas dataframe根据列值筛选数据、Python dataframe中如何使y列按x列进行统计?、python DataFrame中的排列、Python Pandas Dataframe按组中的最大值选择行的知识。
本文目录一览:- Python中如何根据列值从DataFrame中选择行?(python dataframe 选取一列)
- pandas dataframe根据列值筛选数据
- Python dataframe中如何使y列按x列进行统计?
- python DataFrame中的排列
- Python Pandas Dataframe按组中的最大值选择行
")
Python中如何根据列值从DataFrame中选择行?(python dataframe 选取一列)
如何DataFrame基于Python Pandas中某些列的值从中选择行?
在SQL中,我将使用:
SELECT *FROM tableWHERE colume_name = some_value答案1
小编典典要选择列值等于标量的行some_value,请使用==:
df.loc[df[''column_name''] == some_value]要选择列值可迭代的行some_values,请使用isin:
df.loc[df[''column_name''].isin(some_values)]结合以下条件&:
df.loc[(df[''column_name''] >= A) & (df[''column_name''] <= B)]注意括号。由于Python的运算符优先级规则,&绑定比<=和更紧密>=。因此,最后一个示例中的括号是必需的。没有括号
df[''column_name''] >= A & df[''column_name''] <= B被解析为
df[''column_name''] >= (A & df[''column_name'']) <= B这导致一个系列的真值是模棱两可的错误。
要选择列值不相等的行 some_value,请使用!=:
df.loc[df[''column_name''] != some_value]isin返回一个布尔系列,因此要选择值不在 in的行,请some_values使用~以下命令对布尔系列求反:
df.loc[~df[''column_name''].isin(some_values)]例如,
import pandas as pdimport numpy as npdf = pd.DataFrame({''A'': ''foo bar foo bar foo bar foo foo''.split(), ''B'': ''one one two three two two one three''.split(), ''C'': np.arange(8), ''D'': np.arange(8) * 2})print(df)# A B C D# 0 foo one 0 0# 1 bar one 1 2# 2 foo two 2 4# 3 bar three 3 6# 4 foo two 4 8# 5 bar two 5 10# 6 foo one 6 12# 7 foo three 7 14print(df.loc[df[''A''] == ''foo''])输出
A B C D0 foo one 0 02 foo two 2 44 foo two 4 86 foo one 6 127 foo three 7 14如果您要包含多个值,请将它们放在列表中(或更普遍地说,是任何可迭代的)并使用isin:
print(df.loc[df[''B''].isin([''one'',''three''])])输出
A B C D0 foo one 0 01 bar one 1 23 bar three 3 66 foo one 6 127 foo three 7 14但是请注意,如果您希望多次执行此操作,则先创建索引然后再使用会更有效df.loc:
df = df.set_index([''B''])print(df.loc[''one''])输出
A C DB one foo 0 0one bar 1 2one foo 6 12或者,要包含索引中的多个值,请使用df.index.isin:
df.loc[df.index.isin([''one'',''two''])]输出
A C DB one foo 0 0one bar 1 2two foo 2 4two foo 4 8two bar 5 10one foo 6 12
pandas dataframe根据列值筛选数据
关于方法,大概查到了以下:
1. DataFrame.filter()
2. DataFrame.loc()
3. df[df[''字段'']==值]
4. df.where(df[''字段''] == 值)
以下为四种查询的结果
1.filter(items=[]) 结果貌似是list 形式的,没成功
2.loc() 是根据标签进行查询,所以参数为字段名称是不合理的
3.df[df[''字段'']==值] 最终使用了这种办法,结果是理想的
(这里需要注意字段类型的对应,因为我这里值是int 类型的,由于我放成了字符串,导致找了好久的问题)
4 条件为 status =1000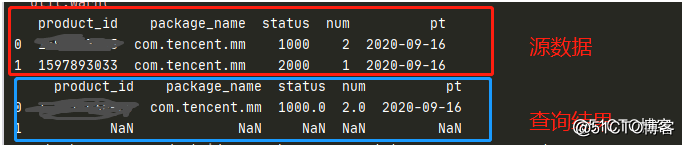

Python dataframe中如何使y列按x列进行统计?
如图:busy=0 or 1,求出busy=1时los的平均,同样对busy=0时也求出los的平均

Python dataframe中如何使y列按x列进行统计? >> python
这个答案描述的挺清楚的:
http://www.goodpm.net/postreply/python/1010000008981394/Pythondataframe中如何使y列按x列进行统计.html

python DataFrame中的排列
有 20 个符号,您将获得 20 个!排列大约是 2.4E18。你永远不会有足够的内存来保存这么多排列。假设每个字符 1 个字节,则需要 48 艾字节的存储空间。

Python Pandas Dataframe按组中的最大值选择行
我有一个通过df.pivot创建的数据框:
type start endF_Type to_date A 20150908143000 345 316B 20150908140300 NaN 480 20150908140600 NaN 120 20150908143000 10743 8803C 20150908140100 NaN 1715 20150908140200 NaN 1062 20150908141000 NaN 145 20150908141500 418 NaN 20150908141800 NaN 450 20150908142900 1973 1499 20150908143000 19522 16659D 20150908143000 433 65E 20150908143000 7290 7375F 20150908143000 0 0G 20150908143000 1796 340我想为每个“ F_TYPE”过滤并返回一行,仅返回最大“ to_date”的行。我想返回以下数据框:
type start endF_Type to_date A 20150908143000 345 316B 20150908143000 10743 8803C 20150908143000 19522 16659D 20150908143000 433 65E 20150908143000 7290 7375F 20150908143000 0 0G 20150908143000 1796 340谢谢..
答案1
小编典典使用标准方法groupby(keys)[column].idxmax()。但是,要使用所需的行,idxmax您需要idxmax返回唯一的索引值。获得唯一索引的一种方法是调用reset_index。
从中获取索引值后,groupby(keys)[column].idxmax()您可以使用来选择整行df.loc:
In [20]: df.loc[df.reset_index().groupby([''F_Type''])[''to_date''].idxmax()]Out[20]: start endF_Type to_date A 20150908143000 345 316B 20150908143000 10743 8803C 20150908143000 19522 16659D 20150908143000 433 65E 20150908143000 7290 7375F 20150908143000 0 0G 20150908143000 1796 340注意:idxmax返回索引 标签 ,不一定是普通 标签
。使用后reset_index的指数标签碰巧也是序,但由于idxmax正在恢复标签(不是序号),最好是 始终
使用idxmax与配合df.loc,而不是df.iloc(因为我原来在这个岗位做。)
我们今天的关于Python中如何根据列值从DataFrame中选择行?和python dataframe 选取一列的分享已经告一段落,感谢您的关注,如果您想了解更多关于pandas dataframe根据列值筛选数据、Python dataframe中如何使y列按x列进行统计?、python DataFrame中的排列、Python Pandas Dataframe按组中的最大值选择行的相关信息,请在本站查询。
本文标签:




