针对Pythonnumpy入门系列21零散知识点和pythonnumpy.ones这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展Java零散知识点、Jupyter中的Numpy在打印时出错
针对Python numpy 入门系列 21 零散知识点和python numpy.ones这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展Java 零散知识点、Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable、numpy.random.random & numpy.ndarray.astype & numpy.arange、numpy.ravel()/numpy.flatten()/numpy.squeeze()等相关知识,希望可以帮助到你。
本文目录一览:- Python numpy 入门系列 21 零散知识点(python numpy.ones)
- Java 零散知识点
- Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable
- numpy.random.random & numpy.ndarray.astype & numpy.arange
- numpy.ravel()/numpy.flatten()/numpy.squeeze()
")
Python numpy 入门系列 21 零散知识点(python numpy.ones)
np.random.uniform
借助numpy.random.uniform()方法,我们可以从均匀分布中获取随机样本,并使用此方法将随机样本作为numpy数组返回。

用法:numpy.random.uniform(low=0.0, high=1.0, size=None)
Return:以numpy数组形式返回随机样本。
范例1:
在此示例中,我们可以看到,通过使用numpy.random.uniform()方法,我们能够从均匀分布中获取随机样本并返回随机样本。
# import numpy import numpy as np import matplotlib.pyplot as plt # Using uniform() method gfg = np.random.uniform(-5, 5, 5000) plt.hist(gfg, bins = 50, density = True) plt.show()

函数原型: numpy.random.uniform(low,high,size)
- 功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
- 参数介绍:
low: 采样下界,float类型,默认值为0;
high: 采样上界,float类型,默认值为1;
size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出 m * n * k 个样本,缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。
@H_301_81@
mean() 函数
mean()函数功能:求取均值
经常操作的参数为axis,以m * n矩阵举例:
axis 不设置值,对 m*n 个数求均值,返回一个实数
axis = 0:压缩行,对各列求均值,返回 1* n 矩阵
axis =1:压缩列,对各行求均值,返回 m *1 矩阵
np.testing.assert_equal
用法:
testing.assert_equal(actual, desired, err_msg='', verbose=True)
如果两个对象不相等,则引发 AssertionError。
给定两个对象(标量、列表、元组、字典或 numpy 数组),检查这些对象的所有元素是否相等。在第一个冲突值处引发异常。
当actual 和desired 之一是标量而另一个是数组 时,该函数检查数组 对象的每个元素是否等于标量。
此函数处理 NaN 比较,就好像 NaN 是 “normal” 数字一样。也就是说,如果两个对象在相同位置都有 NaN,则不会引发 AssertionError。这与关于 NaN 的 IEEE 标准形成对比,后者表示 NaN 与任何东西相比都必须返回 False。
参数:
- actual: array_like
-
要检查的对象。
- desired: array_like
-
预期的对象。
- err_msg: str,可选
-
失败时要打印的错误消息。
- verbose: 布尔型,可选
-
如果为 True,则将冲突值附加到错误消息中。
抛出:
- AssertionError
-
如果实际和期望不相等。
例子:
>>> np.testing.assert_equal([4,5], [4,6])
Traceback (most recent call last):
...
AssertionError:
Items are not equal:
item=1
ACTUAL:5
DESIRED:6
np.random.choice 从数组中随机抽取元素
参数replace
用来设置是否可以取相同元素:
True表示可以取相同数字;
False表示不可以取相同数字。
默认是True
参数p
p实际是个数组,大小(size)应该与指定的a相同,用来规定选取a中每个元素的概率,默认为概率相同
import numpy as np # 参数意思分别 是从a 中以概率P,随机选择3个, p没有指定的时候相当于是一致的分布 a1 = np.random.choice(a=5, size=3, replace=False, p=None) print(a1) # 非一致的分布,会以多少的概率提出来 a2 = np.random.choice(a=5, size=3, replace=False, p=[0.2, 0.1, 0.3, 0.4, 0.0]) print(a2) # replacement 代表的意思是抽样之后还放不放回去,如果是False的话,那么出来的三个数都不一样,如果是True的话, 有可能会出现重复的,因为前面的抽的放回去了。 # ———————————————— # 链接:https://blog.csdn.net/qfpkzheng/article/details/79061601
结果
[0 2 1]
[3 0 2]
REF
https://vimsky.com/examples/usage/numpy-random-uniform-in-python.html
https://www.zhihu.com/question/424417883/answer/1703791656
https://blog.csdn.net/lilong117194/article/details/78397329/
https://vimsky.com/examples/usage/python-numpy.testing.assert_equal.html

Java 零散知识点
Java 零散知识点
一:数组
1. 数组复制的几种方法效率比较
效率:System.arraycopy > clone > Arrays.copyOf > for 循环
for 循环
for 循环的话,效率最低.
System.arrycopy()
System.arraycopy () 源码中可以看到是 native 方法:native 关键字说明其修饰的方法是一个原生态方法,方法对应的实现不是在当前文件,而是在用其他语言(如 C 和 C++)实现的文件中。 可以将 native 方法比作 Java 程序同C程序的接口。
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,int length);
Arrays.copyOf()
从源码中可以看到本质上是调用的 arraycopy 方法。,那么其效率必然是比不上 arraycopy 的。
public static int[] copyOf(int[] original, int newLength) {
int[] copy = new int[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
使用 clone 方法
clone () 的完整定义:protected native Object clone () throws CloneNotSupportedException; 只有 Object [] 数组的 clone () 方法才返回 Object 类型,子类重写了父类的方法。
而 clone () 和 System.arraycopy 只是从实验的结果来看是 System.arraycopy 的效率高。
2.Arrays.asList () 方法
将一个数组转化为一个 List 对象,这个方法会返回一个 ArrayList 类型的对象, 这个 ArrayList 类并非 java.util.ArrayList 类,而是 Arrays 类的静态内部类!用这个对象对列表进行添加删除更新操作,就会报 UnsupportedOperationException 异常。本质上仍是一个数组。
二:类名
1. 类名称名称相关问题
- 方法是可以和类名同名的,和构造方法唯一的区别就是,构造方法没有返回值而方法可以有返回值。
public class TestConStructor
{
public TestConStructor()
{
System.out.println("constructor");
}
public void TestConStructor()
{
System.out.println("not constructor");
}
public static void main(String[] args)
{
TestConStructor testConStructor = new TestConStructor();
System.out.println("main");
testConStructor.TestConStructor();
}
三: Servlet
1.Servlet 的生命周期
Servlet 的生命周期可以分为初始化阶段,运行阶段和销毁阶段三个阶段。
- init ():仅执行一次,负责在装载 Servlet 时初始化 Servlet 对象
- service () :核心方法,一般 HttpServlet 中会有 get,post 两种处理方式。在调用 doGet 和 doPost 方法时会构造 servletRequest 和 servletResponse 请求和响应对象作为参数。
- destory ():在停止并且卸载 Servlet 时执行,负责释放资源
初始化阶段:Servlet 启动,会读取配置文件中的信息,构造指定的 Servlet 对象,创建 ServletConfig 对象,将 ServletConfig 作为参数来调用 init () 方法。
四:参数传递
当参数为引用类型时:只有对引用对象的内部做了修改,才会影响原对象,如果直接将引用修改了,则对原对象没有影响,唯一的影响就是:这个被修改的引用,现在不是原来对象的引用,而是新对象的引用。
引用传递指的是传递的时候,传递的是对象的引用。如果对引用的内部成员进行操作,则会直接影响到原对象,但是如果直接把此引用指向了其他对象,那对不起,这个引用从此以后,便与之前的对象没有任何关系,当前代表的仅仅是新指向的对象。
:TypeError: 'numpy.ndarray' object is not callable")
Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable
如何解决Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: ''numpy.ndarray'' object is not callable?
晚安, 尝试打印以下内容时,我在 jupyter 中遇到了 numpy 问题,并且得到了一个 错误: 需要注意的是python版本是3.8.8。 我先用 spyder 测试它,它运行正确,它给了我预期的结果
使用 Spyder:
import numpy as np
for i in range (5):
n = np.random.rand ()
print (n)
Results
0.6604903457995978
0.8236300859753154
0.16067650689842816
0.6967868357083673
0.4231597934445466
现在有了 jupyter
import numpy as np
for i in range (5):
n = np.random.rand ()
print (n)
-------------------------------------------------- ------
TypeError Traceback (most recent call last)
<ipython-input-78-0c6a801b3ea9> in <module>
2 for i in range (5):
3 n = np.random.rand ()
----> 4 print (n)
TypeError: ''numpy.ndarray'' object is not callable
感谢您对我如何在 Jupyter 中解决此问题的帮助。
非常感谢您抽出宝贵时间。
阿特,约翰”
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

numpy.random.random & numpy.ndarray.astype & numpy.arange
今天看到这样一句代码:
xb = np.random.random((nb, d)).astype(''float32'') #创建一个二维随机数矩阵(nb行d列)
xb[:, 0] += np.arange(nb) / 1000. #将矩阵第一列的每个数加上一个值要理解这两句代码需要理解三个函数
1、生成随机数
numpy.random.random(size=None)
size为None时,返回float。
size不为None时,返回numpy.ndarray。例如numpy.random.random((1,2)),返回1行2列的numpy数组
2、对numpy数组中每一个元素进行类型转换
numpy.ndarray.astype(dtype)
返回numpy.ndarray。例如 numpy.array([1, 2, 2.5]).astype(int),返回numpy数组 [1, 2, 2]
3、获取等差数列
numpy.arange([start,]stop,[step,]dtype=None)
功能类似python中自带的range()和numpy中的numpy.linspace
返回numpy数组。例如numpy.arange(3),返回numpy数组[0, 1, 2]
/numpy.flatten()/numpy.squeeze()")
numpy.ravel()/numpy.flatten()/numpy.squeeze()
numpy.ravel(a, order=''C'')
Return a flattened array
numpy.chararray.flatten(order=''C'')
Return a copy of the array collapsed into one dimension
numpy.squeeze(a, axis=None)
Remove single-dimensional entries from the shape of an array.
相同点: 将多维数组 降为 一维数组
不同点:
ravel() 返回的是视图(view),意味着改变元素的值会影响原始数组元素的值;
flatten() 返回的是拷贝,意味着改变元素的值不会影响原始数组;
squeeze()返回的是视图(view),仅仅是将shape中dimension为1的维度去掉;
ravel()示例:
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.ravel()
16 print("a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19
20 print(a)
21 log_type(''a'',a)
flatten()示例
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.flatten()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)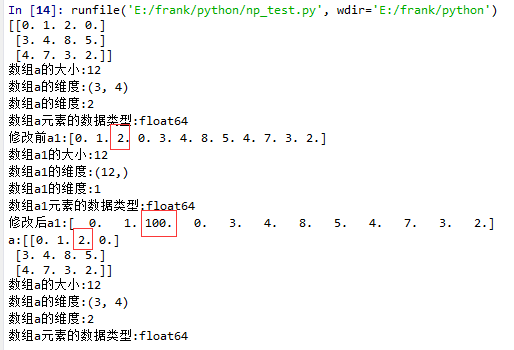
squeeze()示例:
1. 没有single-dimensional entries的情况
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.squeeze()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)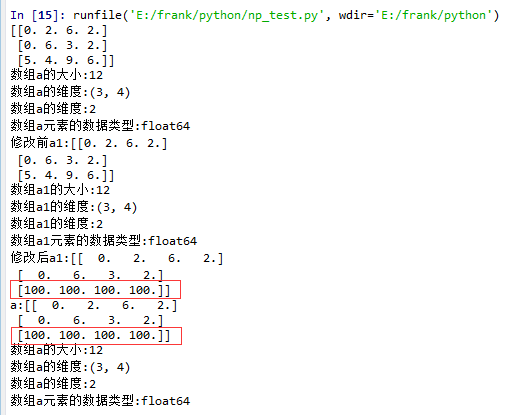
从结果中可以看到,当没有single-dimensional entries时,squeeze()返回额数组对象是一个view,而不是copy。
2. 有single-dimentional entries 的情况
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((1,3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.squeeze()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)
我们今天的关于Python numpy 入门系列 21 零散知识点和python numpy.ones的分享已经告一段落,感谢您的关注,如果您想了解更多关于Java 零散知识点、Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable、numpy.random.random & numpy.ndarray.astype & numpy.arange、numpy.ravel()/numpy.flatten()/numpy.squeeze()的相关信息,请在本站查询。
本文标签:




