在本文中,我们将为您详细介绍NumPy教程的相关知识,并且为您解答关于第16章:统计函数的疑问,此外,我们还会提供一些关于AnacondaNumpy错误“ImportingtheNumpyCExten
在本文中,我们将为您详细介绍NumPy 教程的相关知识,并且为您解答关于第 16 章:统计函数的疑问,此外,我们还会提供一些关于Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案、cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”、DAX 第六篇:统计函数(描述性统计)、Excel基础教程-统计函数的有用信息。
本文目录一览:- NumPy 教程(第 16 章):统计函数(numpy的统计函数)
- Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案
- cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”
- DAX 第六篇:统计函数(描述性统计)
- Excel基础教程-统计函数
:统计函数(numpy的统计函数)")
NumPy 教程(第 16 章):统计函数(numpy的统计函数)
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等
-
numpy.amin()用于计算数组中的元素沿指定轴的最小值 -
numpy.amax()用于计算数组中的元素沿指定轴的最大值
示例:
In [1]: import numpy as np
In [2]: num = np.array([[3,7,5],[8,4,3],[2,9]])
In [3]: num
Out[3]:
array([[3,9]])
In [4]: np.amin(num,1)
Out[4]: array([3,3,2])
In [5]: np.amin(num,0)
Out[5]: array([2,3])
In [6]: np.amin(num)
Out[6]: 2
In [7]: np.amax(num)
Out[7]: 9
In [8]: np.amax(num,axis=0)
Out[8]: array([8,9])
numpy.ptp() 函数
计算数组中元素最大值与最小值的差(最大值 - 最小值)
In [1]: import numpy as np
In [2]: num = np.array([[3,9]])
In [4]: np.ptp(num)
Out[4]: 7
In [5]: np.ptp(num,axis=1)
Out[5]: array([4,5,7])
In [6]: np.ptp(num,axis=0)
Out[6]: array([6,6])
numpy.percentile() 函数
百分位数是统计中使用的度量,表示小于这个值的观察值的百分比,
numpy.percentile(a,q,axis)
参数说明:
-
a: 输入数组
-
q: 要计算的百分位数,在 0 ~ 100 之间
-
axis: 沿着它计算百分位数的轴
首先明确百分位数:
第 p 个百分位数是这样一个值,它使得至少有 p% 的数据项小于或等于这个值,且至少有 (100-p)% 的数据项大于或等于这个值
In [1]: import numpy as np
In [2]: num = np.array([[10,4],[3,2,1]])
In [3]: num
Out[3]:
array([[10,[ 3,1]])
In [4]: np.percentile(num,50)
Out[4]: 3.5
In [5]: np.percentile(num,50,axis=0)
Out[5]: array([6.5,4.5,2.5])
In [6]: np.percentile(num,axis=1)
Out[6]: array([7.,2.])
In [7]: np.percentile(num,axis=1,keepdims=True)
Out[7]:
array([[7.],[2.]])
numpy.median() 函数
用于计算数组 a 中元素的中位数(中值)
In [1]: import numpy as np
In [2]: num = np.array([[30,65,70],[80,95,10],[50,90,60]])
In [3]: num
Out[3]:
array([[30,60]])
In [4]: np.median(num)
Out[4]: 65.0
In [5]: np.median(num,axis=0)
Out[5]: array([50.,90.,60.])
In [6]: np.median(num,axis=1)
Out[6]: array([65.,80.,60.])
numpy.mean() 函数
返回数组中元素的算术平均值。 如果提供了轴,则沿其计算
算术平均值是沿轴的元素的总和除以元素的数量
In [1]: import numpy as np
In [2]: num = np.array([[1,[4,6]])
In [3]: num
Out[3]:
array([[1,6]])
In [4]: np.mean(num)
Out[4]: 3.6666666666666665
In [5]: np.mean(num,axis=0)
Out[5]: array([2.66666667,3.66666667,4.66666667])
In [6]: np.mean(num,axis=1)
Out[6]: array([2.,4.,5.])
numpy.average() 函数
根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值
该函数可以接受一个轴参数。 如果没有指定轴,则数组会被展开
加权平均值即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数
考虑数组[1,4]和相应的权重[4,1],通过将相应元素的乘积相加,并将和除以权重的和,来计算加权平均值
加权平均值 = (1*4 + 2*3 + 3*2 + 4*1) / (4 + 3 + 2 + 1)
示例:
In [1]: import numpy as np
In [2]: num = np.array([1,4])
In [3]: num
Out[3]: array([1,4])
In [4]: np.average(num)
Out[4]: 2.5
In [5]: np.average(num,weights=np.array([4,1]))
Out[5]: 2.0
In [6]: np.average([1,weights=[4,1],returned=True)
Out[6]: (2.0,10.0)
在多维数组中,可以指定用于计算的轴
In [1]: import numpy as np
In [2]: num = np.arange(6).reshape(3,2)
In [3]: num
Out[3]:
array([[0,5]])
In [4]: np.average(num,weights=np.array([3,5]))
Out[4]: array([0.625,2.625,4.625])
In [5]: np.average(num,5]),returned=True)
Out[5]: (array([0.625,4.625]),array([8.,8.,8.]))
标准差
标准差是一组数据平均值分散程度的一种度量
标准差是方差的算术平方根,标准差公式如下:
std = sqrt(mean((x - x.mean())**2))
如果数组是 [1,2,3,4],则其平均值为 2.5。 因此,差的平方是 [2.25,0.25,2.25],并且其平均值的平方根除以 4,即 sqrt(5/4) ,结果为 1.1180339887498949
In [1]: import numpy as np
In [2]: np.std([1,4])
Out[2]: 1.118033988749895
方差
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即 mean((x - x.mean())** 2)
换句话说,标准差是方差的平方根
In [3]: np.var([1,4])
Out[3]: 1.25

Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案
如何解决Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案?
希望有人能在这里提供帮助。我一直在绕圈子一段时间。我只是想设置一个 python 脚本,它将一些 json 数据从 REST API 加载到云数据库中。我在 Anaconda 上设置了一个虚拟环境(因为 GCP 库推荐这样做),安装了依赖项,现在我只是尝试导入库并向端点发送请求。 我使用 Conda(和 conda-forge)来设置环境并安装依赖项,所以希望一切都干净。我正在使用带有 Python 扩展的 VS 编辑器作为编辑器。 每当我尝试运行脚本时,我都会收到以下消息。我已经尝试了其他人在 Google/StackOverflow 上找到的所有解决方案,但没有一个有效。我通常使用 IDLE 或 Jupyter 进行脚本编写,没有任何问题,但我对 Anaconda、VS 或环境变量(似乎是相关的)没有太多经验。 在此先感谢您的帮助!
\Traceback (most recent call last):
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\__init__.py",line 22,in <module>
from . import multiarray
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\multiarray.py",line 12,in <module>
from . import overrides
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\overrides.py",line 7,in <module>
from numpy.core._multiarray_umath import (
ImportError: DLL load Failed while importing _multiarray_umath: The specified module Could not be found.
During handling of the above exception,another exception occurred:
Traceback (most recent call last):
File "c:\API\citi-bike.py",line 4,in <module>
import numpy as np
File "C:\Conda\envs\gcp\lib\site-packages\numpy\__init__.py",line 150,in <module>
from . import core
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\__init__.py",line 48,in <module>
raise ImportError(msg)
ImportError:
IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE!
Importing the numpy C-extensions Failed. This error can happen for
many reasons,often due to issues with your setup or how NumPy was
installed.
We have compiled some common reasons and troubleshooting tips at:
https://numpy.org/devdocs/user/troubleshooting-importerror.html
Please note and check the following:
* The Python version is: python3.9 from "C:\Conda\envs\gcp\python.exe"
* The NumPy version is: "1.21.1"
and make sure that they are the versions you expect.
Please carefully study the documentation linked above for further help.
Original error was: DLL load Failed while importing _multiarray_umath: The specified module Could not be found.
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”
如何解决cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”?
我正在尝试升级一些软件包并为现有的 Python 程序整合我的 requirements.txt,以便将其移至 docker 容器。
这个容器将基于 tensorflow docker 容器,这决定了我必须使用的一些包版本。我们在 windows 下工作,我们希望能够在我们的机器上本地运行该程序(至少在一段时间内)。所以我需要找到一个适用于 docker 和 Windows 10 的配置。
Tensorflow 2.4.1 需要 numpy~=1.19.2。使用 numpy 1.20 时,pip 会抱怨 numpy 1.20 是一个不兼容的版本。
但是在使用 numpy~=1.19.2 时,导入 cvxpy 时出现以下错误。 pip 安装所有软件包都很好:
RuntimeError: module compiled against API version 0xe but this version of numpy is 0xd
Traceback (most recent call last):
File "test.py",line 1,in <module>
import cvxpy
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\__init__.py",line 18,in <module>
from cvxpy.atoms import *
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\__init__.py",line 20,in <module>
from cvxpy.atoms.geo_mean import geo_mean
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\geo_mean.py",in <module>
from cvxpy.utilities.power_tools import (fracify,decompose,approx_error,lower_bound,File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\utilities\power_tools.py",in <module>
from cvxpy.atoms.affine.reshape import reshape
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\affine\reshape.py",in <module>
from cvxpy.atoms.affine.hstack import hstack
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\affine\hstack.py",in <module>
from cvxpy.atoms.affine.affine_atom import AffAtom
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\affine\affine_atom.py",line 22,in <module>
from cvxpy.cvxcore.python import canonInterface
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\cvxcore\python\__init__.py",line 3,in <module>
import _cvxcore
ImportError: numpy.core.multiarray Failed to import
重现步骤:
1.)
在 Windows 10 下创建一个新的 Python 3.8 venv 并激活它
2.) 通过 requirements.txt 安装以下 pip install -r requirements.txt:
cvxpy
numpy~=1.19.2 # tensorflow 2.4.1 requires this version
3.) 通过 test.py
python test.py
import cvxpy
if __name__ == ''__main__'':
pass
如果我想使用 tensorflow 2.3,也会发生同样的事情。在这种情况下需要 numpy~=1.18,错误完全相同。
搜索错误发现很少的命中,可悲的是没有帮助我。
我该怎么做才能解决这个问题?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
")
DAX 第六篇:统计函数(描述性统计)
统计函数用于创建聚合,对数据进行统计分析。在使用统计函数时,必须考虑到数据模型,表之间关系,数据重复等因素,一般都会搭配过滤函数实现数据的提取和分析。
统计量一般是:均值、求和、计数、最大值、最小值、求中位数、求分位数、方差和标准差等。
一,求均值
均值分为几何均值和算术均值,几何平均数是n个变量值连乘积的n次方根:
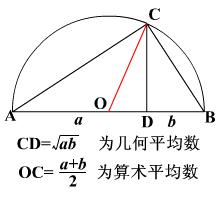
常用下面两个函数计算列值的算术平均值,AVERAGE函数用于对表中的数值型的列计算均值,并且只能用于基础表,参数的格式是table[decimal_column]:
AVERAGE(<column>)
AVERAGEX(<table>,<expression>) 而AVERAGEX函数功能更为强大,参数table可以是基础表,也可以是返回表值的函数;参数 expression 是关于列的表达式,函数计算表达式的均值:
=AVERAGEX(InternetSales, InternetSales[Freight]+ InternetSales[TaxAmt])对于几何均值,有下面两个函数来计算:
GEOMEAN(<column>)
GEOMEANX(<table>, <expression>) 二,求和
通过以下两个函数来计算加和,SUM函数只能用于数值型的列,并且只能用于基础表,参数的格式是table[decimal_column]:
SUM(<column>)
SUMX(<table>, <expression>) SUMX函数从表中计算每一个行的加和,参数table可以是基础表,也可以是返回表值的函数;参数 expression 是关于列的表达式,只有数值会被加和,忽略空值,date,逻辑值或文本值:
示例,第一个参数是过滤器返回的表值,计算[Freight]的加和:
=SUMX(FILTER(InternetSales, InternetSales[SalesTerritoryID]=5),[Freight])可以把SUMX函数,转换为CALCULATE函数:
=CALCULATE( SUM(InternetSales[Freight]), FILTER(InternetSales, InternetSales[SalesTerritoryID]=5))三,计数
常用的计数函数有8个,函数的语法如下:
COUNT(<column>)
COUNTA(<column>)
DISTINCTCOUNT(<column>)
DISTINCTCOUNTNOBLANK (<column>)
COUNTBLANK(<column>)
COUNTROWS(<table>)
COUNTX(<table>,<expression>)
COUNTAX(<table>,<expression>)
这8个函数都用于计数,根据函数的名称,大致分为5类:
- 函数名称中的 A 是指适用于Any 数据类型,不带A的函数只能用于数值、日期和字符串,不支持逻辑类型;不统计Blank值;
- 函数名称带后缀X的函数适用于基础表和返回表值的表达式,不带X的函数只能用于基础表;不统计Blank值;
- 统计Blank值
- 统计总行数
- 唯一值计数
下面的6个函数用于基础表,根据列值和列的类型进行计数:
- COUNT :统计列值不为Blank的行的数量,列值的类型可以是:数值、日期和字符串,不支持逻辑类型,Blank值会被忽略。
- COUNTA :统计列值不为Blank的行的数量,列值的类型可以是:数值、日期、字符串和逻辑类型,Blank值会被忽略。
- COUNTBLANK :统计列值是Blank的行的数量,列值的类型可以是任意类型,该函数只统计包含Blank值的行的数量。
- COUNTROWS :统计表的总行数
- DISTINCTCOUNT :统计列值不重复的数量,列值的类型可以是任意类型,包含BLANK,在该函数中BLANK的值是相同的。
- DISTINCTCOUNTNOBLANK :统计列值不为Blank,且不重复的数量,列值的类型可以是任意类型
下面的2个函数用于基础表,或返回表的表达式中:
- COUNTX :统计列值不为Blank的行的数量,列值的类型可以是:数值、日期和字符串,不支持逻辑类型,Blank值会被忽略。
- COUNTAX :统计列值不为Empty(Blank)的行的数量,列值的类型可以是:数值、日期、字符串和逻辑类型,Blank值会被忽略。
注意:在COUNTAX函数中,如果列中包含表达式,而表达式的结果是空值,在这种情况下,COUNTAX函数把包含公式的列值作为非空(nonblank)看待,计数值会增加。如果COUNTAX函数的列中不包含表达式,当列值为Blank时,COUNTAX函数会忽略Blank值,计数值不会增加。
四,求最大值和最小值
通过以下6个函数来计算列值的最大值和最小值,在进行比较时,Blank(或Empty Cell)会被忽略掉。
MAX(<column>)
MAXA(<column>)
MAXX(<table>,<expression>)
MIN(<column>)
MINA(<column>)
MINX(<table>, < expression>)
1,列值比较
根据函数中是否带后缀A,把函数分为两类:
- 带后缀A的统称为最值 - A函数,有MAXA和MINA共2个;
- 不带后缀A的统称为常规最值函数,有MAX、MAXX、MIN和MINX 共4个。
这两类函数在功能上有微小的区别:
- 常规最值函数:不支持逻辑值的比较,但是支持数值、日期和文本的比较,忽略Blank;如果所有的列值都是Blank/Empty,导致列中没有可用的值,那么常规最值函数最终返回Blank。
- 最值 - A函数:不支持文本的比较,但是支持数值、日期和逻辑值的比较,忽略Blank;如果所有的列值都是Blank/Empty,导致列中没有可用的值,那么最值 - A函数最终返回0。
注意:在比较逻辑值时,TRUE被视为1,FALSE被视为0。
2,比较两个值
在比较两个值时,如果参数为Blank,那么Blank被视为0:
MIN(<expression1>, <expression2>)
MAX(<expression1>, <expression2>)五,中位数
中位数和分位数都是针对数值型进行统计的,Blank、日期、逻辑值和文本会被忽略。
MEDIAN(<column>)
MEDIANX(<table>, <expression>)
六,分位数
k表示期望的百分位值,其中INC是指inclusive(包含),EXC是指exclusive(不包含)。后缀带EXC的函数,参数k的取值范围是0-1,不包含0和1;后缀带INC的函数,参数k的取值范围是0-1,包含0和1。
PERCENTILE.EXC(<column>, <k>)
PERCENTILE.INC(<column>, <k>)
PERCENTILEX.EXC(<table>, <expression>, k)
PERCENTILEX.INC(<table>, <expression>, k)当指定百分位数的值介于数组中的两个值之间时,这4个函数都会进行插值。 如果无法插入指定的k百分位数,则返回错误。
- 对于 INC函数,如果k不是1 /(n - 1)的倍数,则这4个函数将进行插值以确定第k个百分位数的值。
- 对于 EXC函数,如果k不是1 /(n + 1)的倍数,则这4个函数将进行插值以确定第k个百分位数的值。
PERCENTILE.INC
计算原理是:对于数组中的每个值,都会按照从小到大的顺序给定一个百分位(基于n-1),假如数组有n个数值,这n个百分位分别是:0/(n-1)、1/(n-1)、2/(n-1)……n-1/(n-1),当k值与这些百分位相同时,即k是1/(n-1)的倍数,直接返回数组中对应的数值,如果k不是 1/(n-1) 的倍数,则 PERCENTILE.INC 使用插值法来确定第k个百分点的值。
PERCENTILE.EXC
计算原理是:对于数组中的每个值,都会按照从小到大的顺序给定一个百分位(基于n+1),假如数组有n个数值,这n个百分位分别是:1/(n+1)、2/(n+1)、3/(n+1)……n/(n+1),当k值与这些百分位相同时,即k是1/(n+1)的倍数,直接返回数组中对应的数值,如果k不是 1/(n+1) 的倍数,则 PERCENTILE.EXC 使用插值法来确定第k个百分点的值。
引用简书上《 分位数计算,分析Excel中函数实现原理》的一个例子,作者是过桥0811 :
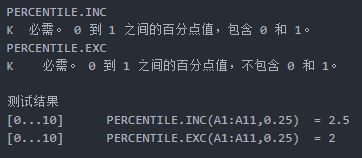

Python代码实现:


import math
def percentile_inc(array,k):
if len(array) == 0:
return "数组不能为空"
if k > 1 or k < 0:
return "系数需为 0 到 1 之间的百分点值,包含 0 和 1"
array_sort = sorted(array)
address = (len(array_sort) - 1) * k + 1
if address == len(array_sort):
return array_sort[len(array_sort) - 1]
i = int(math.modf(address)[1]) #取出整数部分
j = math.modf(address)[0] #取出小数部分
value = array_sort[i-1] + (array_sort[i] - array_sort[i-1]) * j
#print("数组为:" + str(array), "系数为:" + str(k),"百分位数为:" + str(value))
return value
def percentile_exc(array,k):
if len(array) == 0:
return "数组不能为空"
if k >= 1 or k <= 0:
return "系数需为 0 到 1 之间的百分点值,不包含 0 和 1 "
array_sort = sorted(array)
address = (len(array_sort) + 1) * k
if address < 1:
return "因系数过小,不能通过插入值来确定指定的百分点的值"
i = int(math.modf(address)[1]) #取出整数部分
j = math.modf(address)[0] #取出小数部分
value = array_sort[i-1] + (array_sort[i] - array_sort[i-1]) * j
#print("数组为:" + str(array), "系数为:" + str(k),"百分位数为:" + str(value))
return value
print(percentile_inc([10,9,8,7,6,5,4,3,2,1,0],0))
print(percentile_inc([10,9,8,7,6,5,4,3,2,1,0],0.01))
print(percentile_inc([10,9,8,7,6,5,4,3,2,1,0],0.25))
print(percentile_inc([10,9,8,7,6,5,4,3,2,1,0],1))
print(percentile_inc([1,3,2,4],0.3)) # 官网测试数据
print(percentile_exc([10,9,8,7,6,5,4,3,2,1,0],0))
print(percentile_exc([10,9,8,7,6,5,4,3,2,1,0],0.01))
print(percentile_exc([10,9,8,7,6,5,4,3,2,1,0],0.09))
print(percentile_exc([10,9,8,7,6,5,4,3,2,1,0],0.25))
print(percentile_exc([1,2,3,6,6,6,7,8,9],0.25)) # 官网测试数据七,求方差和标准方差
标准差是方差的算术平方根,反映一个数据集的离散程度。DAX通过以下8个函数计算方差和标准方差,这些函数只适用于数值型列,并且会忽略Blank值:
VAR.S(<columnName>)
VAR.P(<columnName>)
VARX.S(<table>, <expression>)
VARX.P(<table>, <expression>)STDEV.S(<ColumnName>)
STDEV.P(<ColumnName>)
STDEVX.S(<table>, <expression>)
STDEVX.P(<table>, <expression>)
根据函数后缀的不同,可以把函数分为两类:后缀为P表示返回整个总体的方差或标准差,后缀为S表示返回样本总体的方差或标准差。
对于方差来说,整个总体和样本总体的计算公式是不同的:
- 整个总体的方差计算公式是:∑(x - x̃)²/n
- 样本总体的方差计算公式是:∑(x - x̃)²/(n-1)
注释: x̃ 是 数据的均值,n是数据的数量
参考文档:
Statistical functions
原文出处:https://www.cnblogs.com/ljhdo/p/4486928.html

Excel基础教程-统计函数
有时候需要进行一些数据统计,比如算一下及格人数,各个分数段等等,下面我们来看一个练习;
1、启动Excel
1)点击;开始-所有程序-Microsoft-Microsoft Office Excel 2003”;

2)出现一个满是格子的空白窗口,这就是一张电子表格了,第一个格子看着边框要粗一些,处于选中状态;

2、Excel窗口
1)点菜单;文件-打开”命令,打开上次的;成绩表”文件;
2)在姓名的下面输入;及格数”,然后把光标移到旁边一格;

3)点一下编辑栏旁边的;fx”,在出来的函数列表里面找到;统计”,在下面找到;COUNTIF”,点;确定”按钮;

4)接下来是数据区域面板,从;78”向下拖到;68”,框选中三个人的语文成绩;

5)切换到英文输入法,在函数面板的第二个文本框中输入;=60”,然后点;确定”,也就是60分以上算及格;

点;确定”后,单元格中出现统计结果;

6)拖动填充手柄,把旁边两格也填充上,这样就把各学科的及格人数统计好了;

我们今天的关于NumPy 教程和第 16 章:统计函数的分享已经告一段落,感谢您的关注,如果您想了解更多关于Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案、cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”、DAX 第六篇:统计函数(描述性统计)、Excel基础教程-统计函数的相关信息,请在本站查询。
本文标签:




