以上就是给各位分享NumPy教程,其中也会对第10章:数组迭代进行解释,同时本文还将给你拓展"importnumpyasnp"ImportError:Nomodulenamednumpy、3.7Pyt
以上就是给各位分享NumPy 教程,其中也会对第 10 章:数组迭代进行解释,同时本文还将给你拓展"import numpy as np" ImportError: No module named numpy、3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数、Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案、cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- NumPy 教程(第 10 章):数组迭代(python数组迭代)
- "import numpy as np" ImportError: No module named numpy
- 3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数
- Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案
- cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”
:数组迭代(python数组迭代)")
NumPy 教程(第 10 章):数组迭代(python数组迭代)
NumPy 迭代器对象 numpy.nditer 提供了一种灵活访问一个或者多个数组元素的方式,迭代器最基本的任务的可以完成对数组元素的访问
使用 arange() 函数创建一个 2X3 数组,并使用 nditer 对它进行迭代
In [1]: import numpy as np
In [2]: num = np.arange(6).reshape(2,3)
In [3]: num
Out[3]:
array([[0,1,2],[3,4,5]])
In [4]: for x in np.nditer(num):
...: print(x,end=',')
...:
0,2,3,5,以上实例不是使用标准 C 或者 Fortran 顺序,选择的顺序是和数组内存布局一致的,这样做是为了提升访问的效率,默认是行序优先(row-major order,或者说是 C-order)
这反映了默认情况下只需访问每个元素,而无需考虑其特定顺序。我们可以通过迭代上述数组的转置来看到这一点,并与以 C 顺序访问数组转置的 copy 方式做对比
In [5]: for x in np.nditer(num.T):
...: print(x,In [6]: for x in np.nditer(num.T.copy(order='C')):
...: print(x,从上述例子可以看出,a 和 a.T 的遍历顺序是一样的,也就是他们在内存中的存储顺序也是一样的,但是 a.T.copy(order = ‘C’) 的遍历结果是不同的,那是因为它和前两种的存储方式是不一样的,默认是按行访问
控制遍历顺序
-
Fortran order:列序优先for x in np.nditer(sum,order='F'): -
C order:行序优先for x in np.nditer(sum.T,order='C')
原始数组
In [1]: import numpy as np
In [2]: num = np.arange(0,60,5).reshape(3,4)
In [3]: num
Out[3]:
array([[ 0,10,15],[20,25,30,35],[40,45,50,55]])
原始数组转置
In [4]: t = num.T
In [5]: t
Out[5]:
array([[ 0,20,40],[ 5,45],[10,50],[15,35,55]])
以 C 风格顺序排序
In [6]: c = t.copy(order='C')
In [7]: c
Out[7]:
array([[ 0,55]])
In [8]: for x in np.nditer(c):
...: print(x,40,15,55,以 F 风格顺序排序
In [9]: f = t.copy(order='F')
In [10]: f
Out[10]:
array([[ 0,55]])
In [11]: for x in np.nditer(f):
...: print(x,')
...:
0,强制 nditer 对象使用某种顺序排序
原始数组
In [1]: import numpy as np
In [2]: num = np.arange(0,55]])
以 C 风格顺序排序
In [4]: for x in np.nditer(num,order='C'):
...: print(x,以 F 风格顺序排序
In [5]: for x in np.nditer(num,order='F'):
...: print(x,修改数组中元素的值
nditer 对象有另一个可选参数 op_flags。 默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值得修改,必须指定 read-write 或者 write-only 的模式
In [1]: import numpy as np
In [2]: num = np.arange(0,55]])
In [4]: for x in np.nditer(num,op_flags=['readwrite']):
...: x[...] = 2 * x
...:
In [5]: num
Out[5]:
array([[ 0,30],[ 40,70],[ 80,90,100,110]])
使用外部循环
nditer类的构造器拥有flags参数,它可以接受下列值
-
c_index 可以跟踪 C 顺序的索引
-
f_index 可以跟踪 Fortran 顺序的索引
-
multi-index 每次迭代可以跟踪一种索引类型
-
external_loop 给出的值是具有多个值的一维数组,而不是零维数组
迭代器遍历对应于每列,并组合为一维数组
In [1]: import numpy as np
In [2]: num = np.arange(0,flags=['external_loop'],')
...:
[ 0 40 80],[10 50 90],[ 20 60 100],[ 30 70 110],广播迭代
如果两个数组是可广播的,nditer 组合对象能够同时迭代它们。 假设数组 a 的维度为 3X4,数组 b 的维度为 1X4 ,则使用以下迭代器(数组 b 被广播到 a 的大小)
In [1]: import numpy as np
In [2]: a = np.arange(0,4)
In [3]: b = np.array([1,4],dtype=int)
In [4]: a
Out[4]:
array([[ 0,55]])
In [5]: b
Out[5]: array([1,4])
In [6]: for x,y in np.nditer([a,b]):
...: print('%d:%d' % (x,y),')
...:
0:1,5:2,10:3,15:4,20:1,25:2,30:3,35:4,40:1,45:2,50:3,55:4,
"import numpy as np" ImportError: No module named numpy
问题:没有安装 numpy
解决方法:
下载文件,安装
numpy-1.8.2-win32-superpack-python2.7
安装运行 import numpy,出现
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
import numpy
File "C:\Python27\lib\site-packages\numpy\__init__.py", line 153, in <module>
from . import add_newdocs
File "C:\Python27\lib\site-packages\numpy\add_newdocs.py", line 13, in <module>
from numpy.lib import add_newdoc
File "C:\Python27\lib\site-packages\numpy\lib\__init__.py", line 8, in <module>
from .type_check import *
File "C:\Python27\lib\site-packages\numpy\lib\type_check.py", line 11, in <module>
import numpy.core.numeric as _nx
File "C:\Python27\lib\site-packages\numpy\core\__init__.py", line 6, in <module>
from . import multiarray
ImportError: DLL load failed: %1 不是有效的 Win32 应用程序。原因是:python 装的是 64 位的,numpy 装的是 32 位的
重新安装 numpy 为:numpy-1.8.0-win64-py2.7
---Numpy 的统计函数")
3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数
目录
[TOC]
前言
具体我们来学 Numpy 的统计函数
(一)函数一览表
调用方式:np.*
| .sum(a) | 对数组 a 求和 |
|---|---|
| .mean(a) | 求数学期望 |
| .average(a) | 求平均值 |
| .std(a) | 求标准差 |
| .var(a) | 求方差 |
| .ptp(a) | 求极差 |
| .median(a) | 求中值,即中位数 |
| .min(a) | 求最大值 |
| .max(a) | 求最小值 |
| .argmin(a) | 求最小值的下标,都处里为一维的下标 |
| .argmax(a) | 求最大值的下标,都处里为一维的下标 |
| .unravel_index(index, shape) | g 根据 shape, 由一维的下标生成多维的下标 |
(二)统计函数 1
(1)说明

(2)输出
.sum(a)

.mean(a)

.average(a)

.std(a)
.var(a)
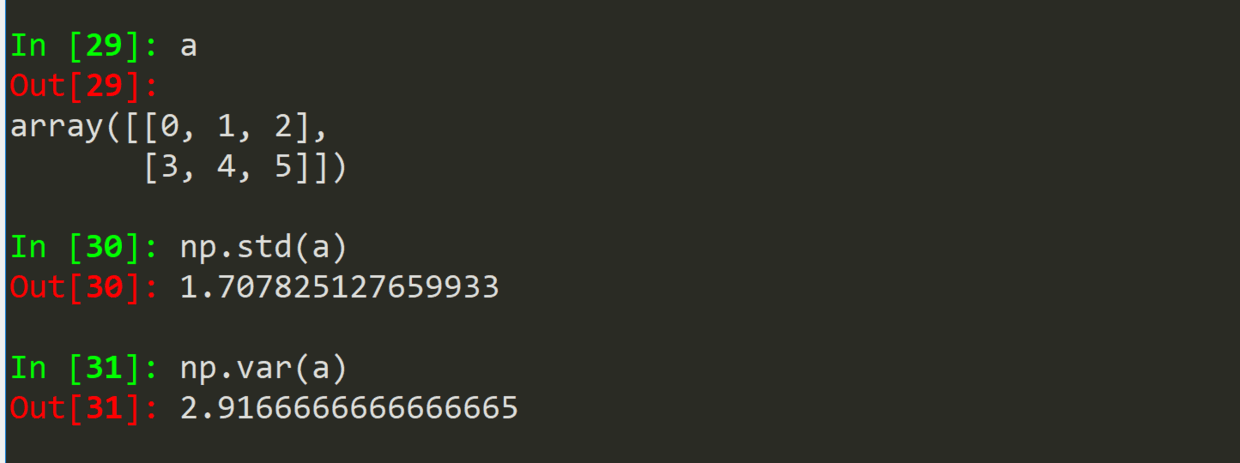
(三)统计函数 2
(1)说明

(2)输出
.max(a) .min(a)
.ptp(a)
.median(a)
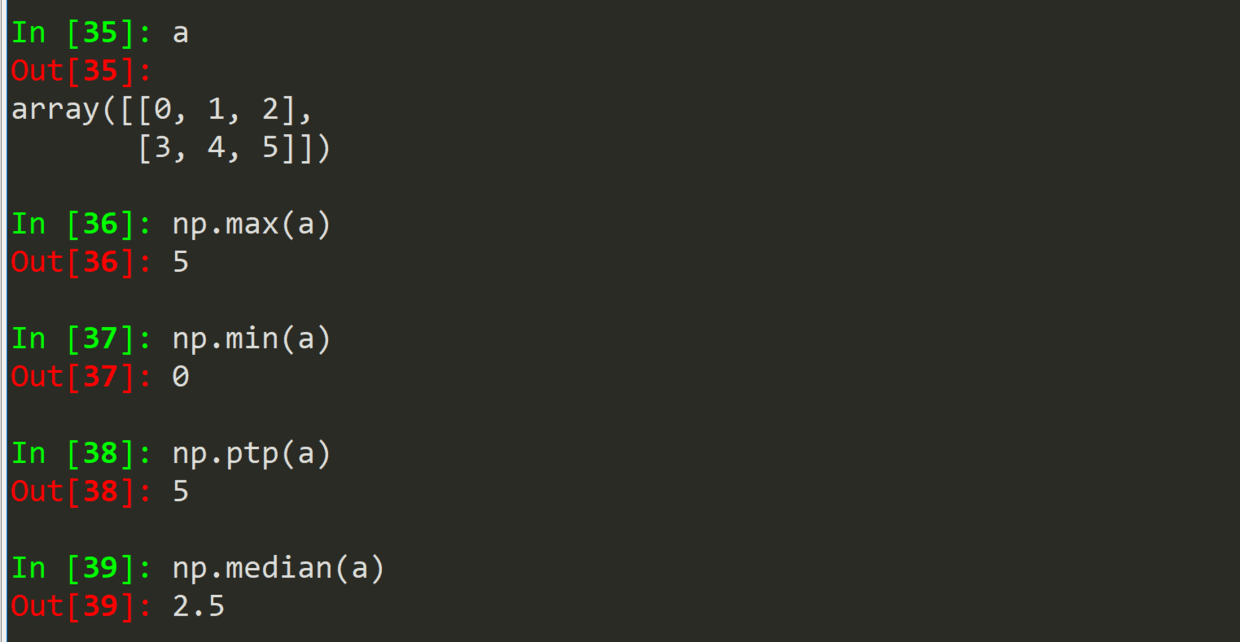
.argmin(a)
.argmax(a)
.unravel_index(index,shape)
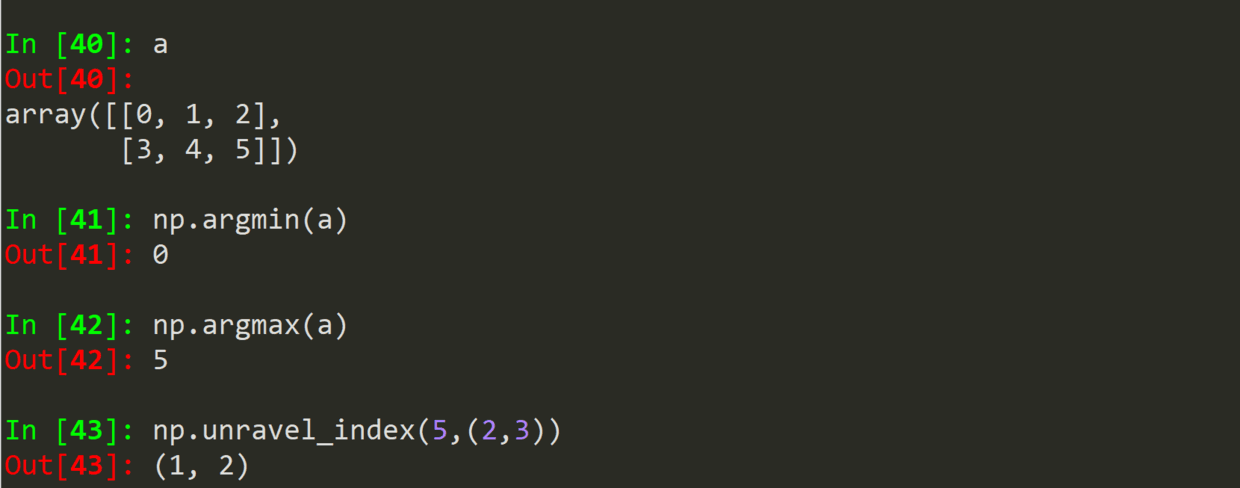
作者:Mark
日期:2019/02/11 周一

Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案
如何解决Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案?
希望有人能在这里提供帮助。我一直在绕圈子一段时间。我只是想设置一个 python 脚本,它将一些 json 数据从 REST API 加载到云数据库中。我在 Anaconda 上设置了一个虚拟环境(因为 GCP 库推荐这样做),安装了依赖项,现在我只是尝试导入库并向端点发送请求。 我使用 Conda(和 conda-forge)来设置环境并安装依赖项,所以希望一切都干净。我正在使用带有 Python 扩展的 VS 编辑器作为编辑器。 每当我尝试运行脚本时,我都会收到以下消息。我已经尝试了其他人在 Google/StackOverflow 上找到的所有解决方案,但没有一个有效。我通常使用 IDLE 或 Jupyter 进行脚本编写,没有任何问题,但我对 Anaconda、VS 或环境变量(似乎是相关的)没有太多经验。 在此先感谢您的帮助!
\Traceback (most recent call last):
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\__init__.py",line 22,in <module>
from . import multiarray
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\multiarray.py",line 12,in <module>
from . import overrides
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\overrides.py",line 7,in <module>
from numpy.core._multiarray_umath import (
ImportError: DLL load Failed while importing _multiarray_umath: The specified module Could not be found.
During handling of the above exception,another exception occurred:
Traceback (most recent call last):
File "c:\API\citi-bike.py",line 4,in <module>
import numpy as np
File "C:\Conda\envs\gcp\lib\site-packages\numpy\__init__.py",line 150,in <module>
from . import core
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\__init__.py",line 48,in <module>
raise ImportError(msg)
ImportError:
IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE!
Importing the numpy C-extensions Failed. This error can happen for
many reasons,often due to issues with your setup or how NumPy was
installed.
We have compiled some common reasons and troubleshooting tips at:
https://numpy.org/devdocs/user/troubleshooting-importerror.html
Please note and check the following:
* The Python version is: python3.9 from "C:\Conda\envs\gcp\python.exe"
* The NumPy version is: "1.21.1"
and make sure that they are the versions you expect.
Please carefully study the documentation linked above for further help.
Original error was: DLL load Failed while importing _multiarray_umath: The specified module Could not be found.
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”
如何解决cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”?
我正在尝试升级一些软件包并为现有的 Python 程序整合我的 requirements.txt,以便将其移至 docker 容器。
这个容器将基于 tensorflow docker 容器,这决定了我必须使用的一些包版本。我们在 windows 下工作,我们希望能够在我们的机器上本地运行该程序(至少在一段时间内)。所以我需要找到一个适用于 docker 和 Windows 10 的配置。
Tensorflow 2.4.1 需要 numpy~=1.19.2。使用 numpy 1.20 时,pip 会抱怨 numpy 1.20 是一个不兼容的版本。
但是在使用 numpy~=1.19.2 时,导入 cvxpy 时出现以下错误。 pip 安装所有软件包都很好:
RuntimeError: module compiled against API version 0xe but this version of numpy is 0xd
Traceback (most recent call last):
File "test.py",line 1,in <module>
import cvxpy
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\__init__.py",line 18,in <module>
from cvxpy.atoms import *
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\__init__.py",line 20,in <module>
from cvxpy.atoms.geo_mean import geo_mean
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\geo_mean.py",in <module>
from cvxpy.utilities.power_tools import (fracify,decompose,approx_error,lower_bound,File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\utilities\power_tools.py",in <module>
from cvxpy.atoms.affine.reshape import reshape
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\affine\reshape.py",in <module>
from cvxpy.atoms.affine.hstack import hstack
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\affine\hstack.py",in <module>
from cvxpy.atoms.affine.affine_atom import AffAtom
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\atoms\affine\affine_atom.py",line 22,in <module>
from cvxpy.cvxcore.python import canonInterface
File "c:\Projekte\algo5\venv\lib\site-packages\cvxpy\cvxcore\python\__init__.py",line 3,in <module>
import _cvxcore
ImportError: numpy.core.multiarray Failed to import
重现步骤:
1.)
在 Windows 10 下创建一个新的 Python 3.8 venv 并激活它
2.) 通过 requirements.txt 安装以下 pip install -r requirements.txt:
cvxpy
numpy~=1.19.2 # tensorflow 2.4.1 requires this version
3.) 通过 test.py
python test.py
import cvxpy
if __name__ == ''__main__'':
pass
如果我想使用 tensorflow 2.3,也会发生同样的事情。在这种情况下需要 numpy~=1.18,错误完全相同。
搜索错误发现很少的命中,可悲的是没有帮助我。
我该怎么做才能解决这个问题?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
关于NumPy 教程和第 10 章:数组迭代的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于"import numpy as np" ImportError: No module named numpy、3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数、Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案、cvxpy 和 numpy 之间的版本冲突:“针对 API 版本 0xe 编译的模块,但此版本的 numpy 是 0xd”等相关知识的信息别忘了在本站进行查找喔。
本文标签:




