如果您想了解使用numpy数组的列值上的条件过滤PandasDataFrame的相关知识,那么本文是一篇不可错过的文章,我们将对python数组过滤进行全面详尽的解释,并且为您提供关于Datafram
如果您想了解使用 numpy 数组的列值上的条件过滤 Pandas DataFrame的相关知识,那么本文是一篇不可错过的文章,我们将对python数组过滤进行全面详尽的解释,并且为您提供关于Dataframe 中的 Dataframe 以检索股票信息、DataFrame 执行 groupby 聚合操作后,如何继续保持 DataFrame 对象而不变成 Series 对象、DataFrame.nunique(),DataFrame.count()、numpy.random.random & numpy.ndarray.astype & numpy.arange的有价值的信息。
本文目录一览:- 使用 numpy 数组的列值上的条件过滤 Pandas DataFrame(python数组过滤)
- Dataframe 中的 Dataframe 以检索股票信息
- DataFrame 执行 groupby 聚合操作后,如何继续保持 DataFrame 对象而不变成 Series 对象
- DataFrame.nunique(),DataFrame.count()
- numpy.random.random & numpy.ndarray.astype & numpy.arange
")
使用 numpy 数组的列值上的条件过滤 Pandas DataFrame(python数组过滤)
-
假设您有类似的情况:
A B 0 10 [11,0] 1 20 [11,10] 2 30 [11,10] 3 40 [10,0] 4 50 [11,0] 5 60 [10,0]
-
并且只想过滤包含 10 的数组中的那些
A B 1 20 [11,0]
-
你可以使用 .apply
#create the dataframe df = pd.DataFrame(columns = ['A','B']) df.A = [10,20,30,40,50,60] df.B = [[11,0],[11,10],[10,0]] # results is a boolean indicating whether the value is found in the list # apply the filter in the column 'B' of the dataframe results = df.B.apply(lambda a: 10 in a) # filter the dataframe based on the boolean df_filtered = df[results] print(df_filtered) -
然后你得到:
A B 1 20 [11,10] 2 30 [11,10] 3 40 [10,0] 5 60 [10,0]
您可以在以下位置找到更多详细信息:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html
,请记住,索引数据框需要一个 True/False 值列表,因此如果推送紧急,您仍然可以在其他地方构建该列表(列表理解/for 循环)并将其传递到 df 中,如 {{1} }.只需确保 df 的每一行都有一个条目。
在没有具体示例的情况下很难提出解决方案,但您可以尝试这样的方法:
dt[contructed_true_false_list]
我综合了评论者的回答。请注意,当我读取列表中的数据时,它以字符串形式出现,因此您可能需要处理其中的 str(2) 部分。
df[df.apply(lambda x: True if str(2) in x['B'] else False,axis=1)]
A B
0 a [1,2,3]
1 b [2,3,4]

Dataframe 中的 Dataframe 以检索股票信息
如何解决Dataframe 中的 Dataframe 以检索股票信息
所以我有一个包含股票代码、评级、公司名称等的数据框。我想要做的是添加一个名为额外信息的新列,我可以在其中包含一个数据框内的数据框。
我知道我可以使用下面的代码来获取公司特定信息的数据框:
data <- getSymbols("TSLA",src = ''yahoo'',from = as.Date(Sys.time())-7,auto.assign=FALSE,verbose=TRUE)
但是,当我在“额外信息”列上单击它的值时,我想获得每家公司的此股票信息。有什么想法吗?
解决方法
也许您可以将数据存储在列表中。
library(quantmod)stock <- c("TSLA",''QQQ'')result <- sapply(stock,getSymbols,src = ''yahoo'',auto.assign = FALSE,from = as.Date(Sys.time())-7,verbose=TRUE,simplify = FALSE)
现在您可以访问带有 $ 符号的个股。
result$TSLA# TSLA.Open TSLA.High TSLA.Low TSLA.Close TSLA.Volume TSLA.Adjusted#2021-02-01 814.29 842.00 795.56 839.81 25391400 839.81#2021-02-02 844.68 880.50 842.20 872.79 24346200 872.79#2021-02-03 877.02 878.08 853.06 854.69 18343500 854.69#2021-02-04 855.00 856.50 833.42 849.99 15812700 849.99#2021-02-05 855.00 864.77 839.00 852.23 18566637 852.23
当您查看 result 对象时,您会看到带有其名称的股票代码。


DataFrame 执行 groupby 聚合操作后,如何继续保持 DataFrame 对象而不变成 Series 对象
刚接触 pandas 不久,在处理特征时,碰到一个恶心的问题:用 groupby 聚合后,之前的 dataframe 对象变成了 series 对象,聚合的字段变成了索引 index,导致获取这些字段时很麻烦,后面发现 reset_index () 这个函数,兼职完美的解决了我的需求。
元素数据如下:
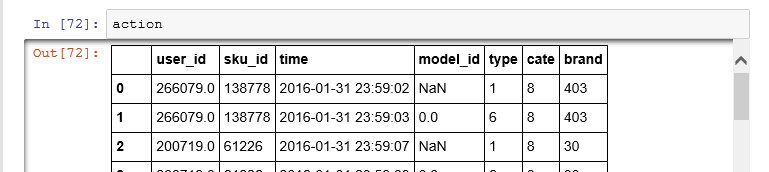
聚合后变成了这样:
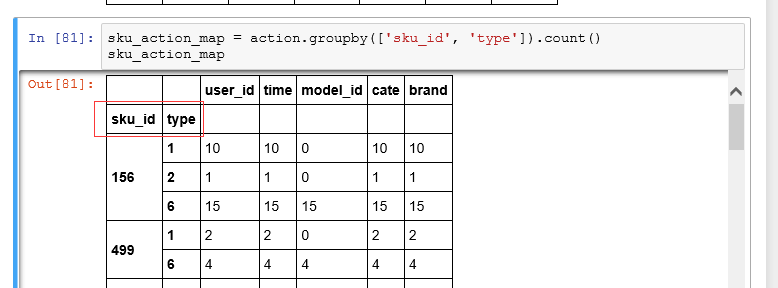
尝试这样访问按照 column 的方式获取值,结果报错了,后面发现已经变成了 Series 对象了,不是 DataFrame 了

可是我还想把 sku_id 和 type 这 2 个字段作为 column 呀。。。诶 233。。
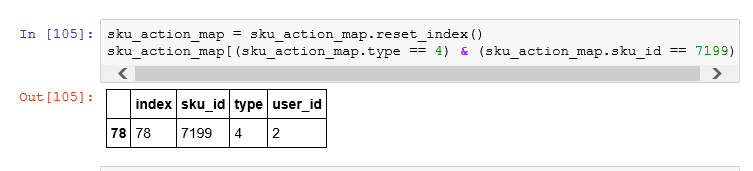
于是乎终于找到了这个函数 reset_index ()

由变成 DataFrame 对象了,完美解决问题
原文:https://blog.csdn.net/u014252563/article/details/70835271
,DataFrame.count()")
DataFrame.nunique(),DataFrame.count()
1. nunique()
DataFrame.nunique(axis = 0,dropna = True )
功能:计算请求轴上的不同观察结果
参数:
- axis : {0或''index'',1或''columns''},默认为0。0或''index''用于行方式,1或''列''用于列方式。
- dropna : bool,默认为True,不要在计数中包含NaN。
返回: Series
>>> df = pd.DataFrame({''A'': [1, 2, 3], ''B'': [1, 1, 1]})
>>> df.nunique()
A 3
B 1
dtype: int64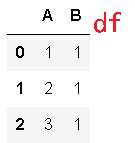
>>> df.nunique(axis=1)
0 1
1 2
2 2
dtype: int64
2. count()
DataFrame.count(axis = 0,level = None,numeric_only = False )
功能:计算每列或每行的非NA单元格。
None,NaN,NaT和numpy.inf都被视作NA
参数:
- axis : {0或''index'',1或''columns''},默认为0(行),如果为每列生成0或''索引''计数。如果为每行生成1或''列''计数。
- level : int或str,可选,如果轴是MultiIndex(分层),则沿特定级别计数,折叠到DataFrame中。一个STR指定级别名称。
- numeric_only : boolean,默认为False,仅包含float,int或boolean数据。
返回:Series或DataFrame对于每个列/行,非NA / null条目的数量。如果指定了level,则返回DataFrame。
从字典构造DataFrame
>>> df = pd.DataFrame({"Person":
... ["John", "Myla", "Lewis", "John", "Myla"],
... "Age": [24., np.nan, 21., 33, 26],
... "Single": [False, True, True, True, False]})
>>> df
Person Age Single
0 John 24.0 False
1 Myla NaN True
2 Lewis 21.0 True
3 John 33.0 True
4 Myla 26.0 False注意不计数的NA值
>>> df.count()
Person 5
Age 4
Single 5
dtype: int64每行计数:
>>> df.count(axis=''columns'')
0 3
1 2
2 3
3 3
4 3
dtype: int64计算MultiIndex的一个级别:
>>> df.set_index(["Person", "Single"]).count(level="Person")
Age
Person
John 2
Lewis 1
Myla 1
参考文献:
【1】pandas.DataFrame.count

numpy.random.random & numpy.ndarray.astype & numpy.arange
今天看到这样一句代码:
xb = np.random.random((nb, d)).astype(''float32'') #创建一个二维随机数矩阵(nb行d列)
xb[:, 0] += np.arange(nb) / 1000. #将矩阵第一列的每个数加上一个值要理解这两句代码需要理解三个函数
1、生成随机数
numpy.random.random(size=None)
size为None时,返回float。
size不为None时,返回numpy.ndarray。例如numpy.random.random((1,2)),返回1行2列的numpy数组
2、对numpy数组中每一个元素进行类型转换
numpy.ndarray.astype(dtype)
返回numpy.ndarray。例如 numpy.array([1, 2, 2.5]).astype(int),返回numpy数组 [1, 2, 2]
3、获取等差数列
numpy.arange([start,]stop,[step,]dtype=None)
功能类似python中自带的range()和numpy中的numpy.linspace
返回numpy数组。例如numpy.arange(3),返回numpy数组[0, 1, 2]
关于使用 numpy 数组的列值上的条件过滤 Pandas DataFrame和python数组过滤的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于Dataframe 中的 Dataframe 以检索股票信息、DataFrame 执行 groupby 聚合操作后,如何继续保持 DataFrame 对象而不变成 Series 对象、DataFrame.nunique(),DataFrame.count()、numpy.random.random & numpy.ndarray.astype & numpy.arange的相关知识,请在本站寻找。
本文标签:




