这篇文章主要围绕NumPy-流行dtypes的快速紧凑序列化和到字节数组展开,旨在为您提供一份详细的参考资料。我们将全面介绍NumPy-流行dtypes的快速紧凑序列化的优缺点,解答到字节数组的相关问
这篇文章主要围绕NumPy-流行dtypes的快速紧凑序列化和到字节数组展开,旨在为您提供一份详细的参考资料。我们将全面介绍NumPy-流行dtypes的快速紧凑序列化的优缺点,解答到字节数组的相关问题,同时也会为您带来"import numpy as np" ImportError: No module named numpy、3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数、Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案、C# int 到字节[]的实用方法。
本文目录一览:- NumPy-流行dtypes的快速紧凑序列化(到字节)数组(numpy 序列化)
- "import numpy as np" ImportError: No module named numpy
- 3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数
- Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案
- C# int 到字节[]
数组(numpy 序列化)")
NumPy-流行dtypes的快速紧凑序列化(到字节)数组(numpy 序列化)
如何解决NumPy-流行dtypes的快速紧凑序列化(到字节)数组?
我有一个数组a,可以是任何流行的dtype,包括np.str_或任何标准Python类型(存储为np.object_)。
任务是将a转换为字节(serialize),以便:
- 每个数组的元素表示为可变数量的不可逆字节,即给定元素的字节,应该可以将元素精确地还原回来。换句话说,每个元素都应该可以序列化和反序列化。
- 序列化功能应立即处理整个数组。
- 序列化应该尽可能快。
- 最好也是紧凑的,以便每个元素产生接近最小长度的字节序列,以便仍然可以反序列化。
- 串行化应产生总紧凑的字节序列,其中包含所有子序列(每个元素)以及有关其大小的信息。例如。一种好方法是串联每个元素的序列化字节,再提供另一个具有所有子序列长度的数组。
- 序列化应该支持所有流行的
dtype,包括np.str_和所有Python标准类型(存储为np.object_dtype)。 - 反序列化功能也应该可用。
- 如果这样的序列化函数在numpy库中可用或使用numpy函数实现,那将很棒。
为什么需要这个?当前的一种应用是,我想对庞大的流行dtypes的numpy数组进行哈希处理。每个元素应产生一个整数散列。这应该是快速且抗冲突的,即不同的元素应产生几乎唯一的哈希,哈希的任何子位也应具有抗冲突性。我们应该假设哈希函数只能处理字节序列。
为实现此请求的序列化功能是必需的。 Collision resistant和快速hash function已经给出。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

"import numpy as np" ImportError: No module named numpy
问题:没有安装 numpy
解决方法:
下载文件,安装
numpy-1.8.2-win32-superpack-python2.7
安装运行 import numpy,出现
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
import numpy
File "C:\Python27\lib\site-packages\numpy\__init__.py", line 153, in <module>
from . import add_newdocs
File "C:\Python27\lib\site-packages\numpy\add_newdocs.py", line 13, in <module>
from numpy.lib import add_newdoc
File "C:\Python27\lib\site-packages\numpy\lib\__init__.py", line 8, in <module>
from .type_check import *
File "C:\Python27\lib\site-packages\numpy\lib\type_check.py", line 11, in <module>
import numpy.core.numeric as _nx
File "C:\Python27\lib\site-packages\numpy\core\__init__.py", line 6, in <module>
from . import multiarray
ImportError: DLL load failed: %1 不是有效的 Win32 应用程序。原因是:python 装的是 64 位的,numpy 装的是 32 位的
重新安装 numpy 为:numpy-1.8.0-win64-py2.7
---Numpy 的统计函数")
3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数
目录
[TOC]
前言
具体我们来学 Numpy 的统计函数
(一)函数一览表
调用方式:np.*
| .sum(a) | 对数组 a 求和 |
|---|---|
| .mean(a) | 求数学期望 |
| .average(a) | 求平均值 |
| .std(a) | 求标准差 |
| .var(a) | 求方差 |
| .ptp(a) | 求极差 |
| .median(a) | 求中值,即中位数 |
| .min(a) | 求最大值 |
| .max(a) | 求最小值 |
| .argmin(a) | 求最小值的下标,都处里为一维的下标 |
| .argmax(a) | 求最大值的下标,都处里为一维的下标 |
| .unravel_index(index, shape) | g 根据 shape, 由一维的下标生成多维的下标 |
(二)统计函数 1
(1)说明

(2)输出
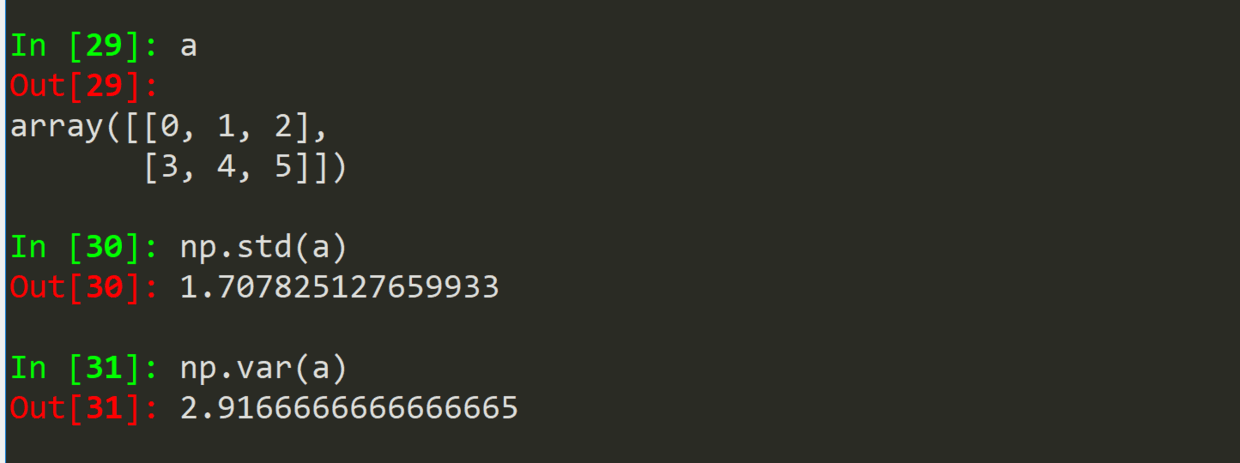
.sum(a)

.mean(a)

.average(a)

.std(a)
.var(a)
(三)统计函数 2
(1)说明

(2)输出
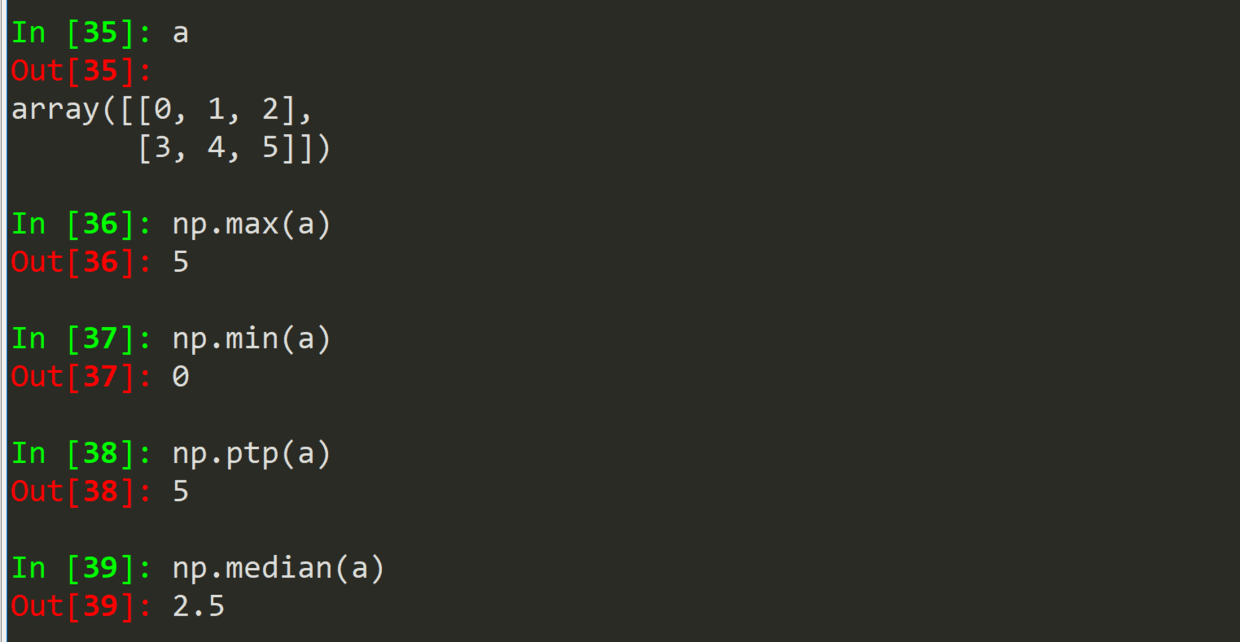
.max(a) .min(a)
.ptp(a)
.median(a)
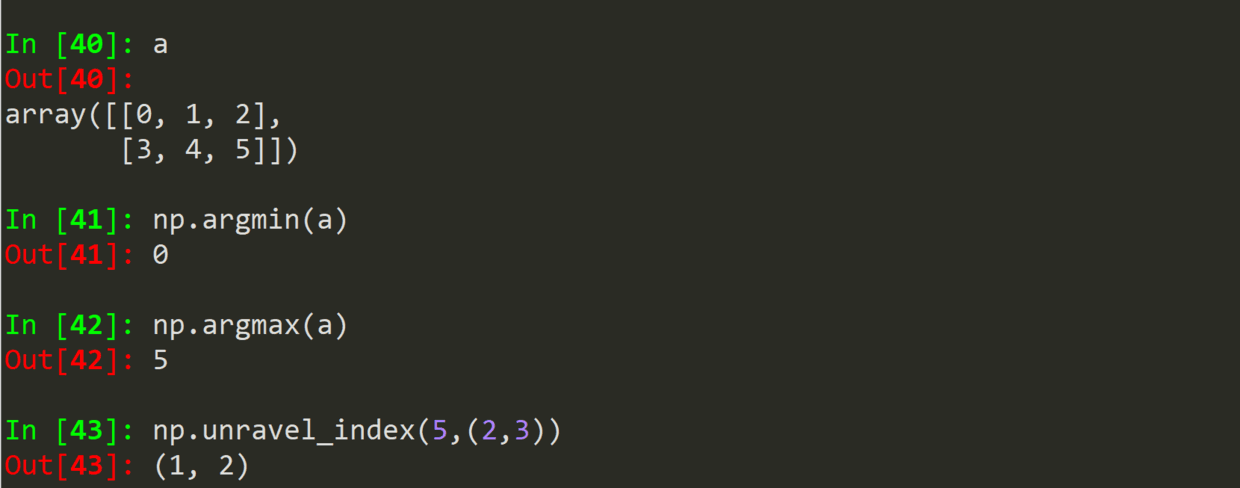
.argmin(a)
.argmax(a)
.unravel_index(index,shape)
作者:Mark
日期:2019/02/11 周一

Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案
如何解决Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案?
希望有人能在这里提供帮助。我一直在绕圈子一段时间。我只是想设置一个 python 脚本,它将一些 json 数据从 REST API 加载到云数据库中。我在 Anaconda 上设置了一个虚拟环境(因为 GCP 库推荐这样做),安装了依赖项,现在我只是尝试导入库并向端点发送请求。 我使用 Conda(和 conda-forge)来设置环境并安装依赖项,所以希望一切都干净。我正在使用带有 Python 扩展的 VS 编辑器作为编辑器。 每当我尝试运行脚本时,我都会收到以下消息。我已经尝试了其他人在 Google/StackOverflow 上找到的所有解决方案,但没有一个有效。我通常使用 IDLE 或 Jupyter 进行脚本编写,没有任何问题,但我对 Anaconda、VS 或环境变量(似乎是相关的)没有太多经验。 在此先感谢您的帮助!
\Traceback (most recent call last):
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\__init__.py",line 22,in <module>
from . import multiarray
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\multiarray.py",line 12,in <module>
from . import overrides
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\overrides.py",line 7,in <module>
from numpy.core._multiarray_umath import (
ImportError: DLL load Failed while importing _multiarray_umath: The specified module Could not be found.
During handling of the above exception,another exception occurred:
Traceback (most recent call last):
File "c:\API\citi-bike.py",line 4,in <module>
import numpy as np
File "C:\Conda\envs\gcp\lib\site-packages\numpy\__init__.py",line 150,in <module>
from . import core
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\__init__.py",line 48,in <module>
raise ImportError(msg)
ImportError:
IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE!
Importing the numpy C-extensions Failed. This error can happen for
many reasons,often due to issues with your setup or how NumPy was
installed.
We have compiled some common reasons and troubleshooting tips at:
https://numpy.org/devdocs/user/troubleshooting-importerror.html
Please note and check the following:
* The Python version is: python3.9 from "C:\Conda\envs\gcp\python.exe"
* The NumPy version is: "1.21.1"
and make sure that they are the versions you expect.
Please carefully study the documentation linked above for further help.
Original error was: DLL load Failed while importing _multiarray_umath: The specified module Could not be found.
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
![C# int 到字节[]](http://www.gvkun.com/zb_users/upload/2025/04/18ef349c-5f85-44e8-8e1b-6d9efecf80f51744859634126.jpg "C# int 到字节[]")
C# int 到字节[]
我需要将其转换int为byte[]一种方法是使用BitConverter.GetBytes(). 但我不确定这是否符合以下规范:
XDR 有符号整数是一个 32 位数据,它对 [-2147483648,2147483647]
范围内的整数进行编码。整数以二进制补码表示。最高和最低有效字节分别是 0 和 3。整数声明如下:
资源:RFC1014 3.2
我怎样才能进行满足上述规范的 int 到 byte 转换?
答案1
小编典典RFC 只是想说一个有符号整数是一个普通的 4 字节整数,字节以大端方式排序。
现在,您很可能正在使用 little-endian
机器,并且BitConverter.GetBytes()会给您byte[]相反的结果。所以你可以尝试:
int intValue;byte[] intBytes = BitConverter.GetBytes(intValue);Array.Reverse(intBytes);byte[] result = intBytes;但是,为了使代码具有最大的可移植性,您可以这样做:
int intValue;byte[] intBytes = BitConverter.GetBytes(intValue);if (BitConverter.IsLittleEndian) Array.Reverse(intBytes);byte[] result = intBytes;关于NumPy-流行dtypes的快速紧凑序列化和到字节数组的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于"import numpy as np" ImportError: No module named numpy、3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数、Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案、C# int 到字节[]等相关内容,可以在本站寻找。
本文标签:




