本文将介绍Pythonnumpy模块-logaddexp()实例源码的详细情况,特别是关于python中numpy模块的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同
本文将介绍Python numpy 模块-logaddexp() 实例源码的详细情况,特别是关于python中numpy模块的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable、numpy.random.random & numpy.ndarray.astype & numpy.arange、numpy.ravel()/numpy.flatten()/numpy.squeeze()、Numpy:数组创建 numpy.arrray() , numpy.arange()、np.linspace ()、数组基本属性的知识。
本文目录一览:- Python numpy 模块-logaddexp() 实例源码(python中numpy模块)
- Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable
- numpy.random.random & numpy.ndarray.astype & numpy.arange
- numpy.ravel()/numpy.flatten()/numpy.squeeze()
- Numpy:数组创建 numpy.arrray() , numpy.arange()、np.linspace ()、数组基本属性
 实例源码(python中numpy模块)")
Python numpy 模块-logaddexp() 实例源码(python中numpy模块)
Python numpy 模块,logaddexp() 实例源码
我们从Python开源项目中,提取了以下50个代码示例,用于说明如何使用numpy.logaddexp()。
- def test_NotImplemented_not_returned(self):
- # See gh-5964 and gh-2091. Some of these functions are not operator
- # related and were fixed for other reasons in the past.
- binary_funcs = [
- np.power, np.add, np.subtract, np.multiply, np.divide,
- np.true_divide, np.floor_divide, np.bitwise_and, np.bitwise_or,
- np.bitwise_xor, np.left_shift, np.right_shift, np.fmax,
- np.fmin, np.fmod, np.hypot, np.logaddexp, np.logaddexp2,
- np.logical_and, np.logical_or, np.logical_xor, np.maximum,
- np.minimum, np.mod
- ]
- # These functions still return NotImplemented. Will be fixed in
- # future.
- # bad = [np.greater,np.greater_equal,np.less,np.less_equal,np.not_equal]
- a = np.array(''1'')
- b = 1
- for f in binary_funcs:
- assert_raises(TypeError, f, a, b)
- def get_collision_force(self, entity_a, entity_b):
- if (not entity_a.collide) or (not entity_b.collide):
- return [None, None] # not a collider
- if (entity_a is entity_b):
- return [None, None] # don''t collide against itself
- # compute actual distance between entities
- delta_pos = entity_a.state.p_pos - entity_b.state.p_pos
- dist = np.sqrt(np.sum(np.square(delta_pos)))
- # minimum allowable distance
- dist_min = entity_a.size + entity_b.size
- # softmax penetration
- k = self.contact_margin
- penetration = np.logaddexp(0, -(dist - dist_min)/k)*k
- force = self.contact_force * delta_pos / dist * penetration
- force_a = +force if entity_a.movable else None
- force_b = -force if entity_b.movable else None
- return [force_a, force_b]
- def test_NotImplemented_not_returned(self):
- # See gh-5964 and gh-2091. Some of these functions are not operator
- # related and were fixed for other reasons in the past.
- binary_funcs = [
- np.power, b)
- def test_NotImplemented_not_returned(self):
- # See gh-5964 and gh-2091. Some of these functions are not operator
- # related and were fixed for other reasons in the past.
- binary_funcs = [
- np.power, b)
- def test_NotImplemented_not_returned(self):
- # See gh-5964 and gh-2091. Some of these functions are not operator
- # related and were fixed for other reasons in the past.
- binary_funcs = [
- np.power, b)
- def test_NotImplemented_not_returned(self):
- # See gh-5964 and gh-2091. Some of these functions are not operator
- # related and were fixed for other reasons in the past.
- binary_funcs = [
- np.power, b)
- def increment(self,logL,nlive=None):
- """
- Increment the state of the evidence integrator
- Simply uses rectangle rule for initial estimate
- """
- if(logL<=self.logLs[-1]):
- print(''WARNING: NS integrator received non-monotonic logL. {0:.3f} -> {1:.3f}''.format(self.logLs[-1],logL))
- if nlive is None:
- nlive = self.nlive
- oldZ = self.logZ
- logt=-1.0/nlive
- Wt = self.logw + logL + logsubexp(0,logt)
- self.logZ = logaddexp(self.logZ,Wt)
- # Update information estimate
- if np.isfinite(oldZ) and np.isfinite(self.logZ):
- self.info = exp(Wt - self.logZ)*logL + exp(oldZ - self.logZ)*(self.info + oldZ) - self.logZ
- # Update history
- self.logw += logt
- self.iteration += 1
- self.logLs.append(logL)
- self.log_vols.append(self.logw)
- def test_NotImplemented_not_returned(self):
- # See gh-5964 and gh-2091. Some of these functions are not operator
- # related and were fixed for other reasons in the past.
- binary_funcs = [
- np.power, b)
- def _expected_durations(self,
- dur_potentials,cumulative_obs_potentials,
- alphastarl,betal,normalizer):
- if self.trunc is not None:
- raise NotImplementedError, "_expected_durations can''t handle trunc"
- T = self.T
- logpmfs = -np.inf*np.ones_like(alphastarl)
- errs = np.seterr(invalid=''ignore'')
- for t in xrange(T):
- cB, offset = cumulative_obs_potentials(t)
- np.logaddexp(dur_potentials(t) + alphastarl[t] + betal[t:] +
- cB - (normalizer + offset),
- logpmfs[:T-t], out=logpmfs[:T-t])
- np.seterr(**errs)
- expected_durations = np.exp(logpmfs.T)
- return expected_durations
- # Todo call this ''time homog''
- def messages_backwards(self):
- # NOTE: np.maximum calls are because the C++ code doesn''t do
- # np.logaddexp(-inf,-inf) = -inf,it likes nans instead
- from hsmm_messages_interface import messages_backwards_log
- betal, betastarl = messages_backwards_log(
- np.maximum(self.trans_matrix,1e-50),self.aBl,np.maximum(self.aDl,-1000000),
- self.aDsl,np.empty_like(self.aBl),
- self.right_censoring,self.trunc if self.trunc is not None else self.T)
- assert not np.isnan(betal).any()
- assert not np.isnan(betastarl).any()
- if not self.left_censoring:
- self._normalizer = np.logaddexp.reduce(np.log(self.pi_0) + betastarl[0])
- else:
- raise NotImplementedError
- return betal, betastarl
- def _expected_durations(self,normalizer):
- logpmfs = -np.inf*np.ones((self.Tfull,alphastarl.shape[1]))
- errs = np.seterr(invalid=''ignore'') # logaddexp(-inf,-inf)
- # Todo censoring not handled correctly here
- for tblock in xrange(self.Tblock):
- possible_durations = self.segmentlens[tblock:].cumsum()[:self.trunc]
- cB, offset = cumulative_obs_potentials(tblock)
- logpmfs[possible_durations -1] = np.logaddexp(
- dur_potentials(tblock) + alphastarl[tblock]
- + betal[tblock:tblock+self.trunc if self.trunc is not None else None]
- + cB - (offset + normalizer),
- logpmfs[possible_durations -1])
- np.seterr(**errs)
- return np.exp(logpmfs.T)
- ###################
- # sparate trans #
- ###################
- def aBl_einsum(self):
- if self._aBBl is None:
- sigmas = np.array([[c.sigmas for c in d.components] for d in self.obs_distns])
- Js = -1./(2*sigmas)
- mus = np.array([[c.mu for c in d.components] for d in self.obs_distns])
- # all_likes is T x Nstates x Ncomponents
- all_likes = \\
- (np.einsum(''td,td,nkd->tnk'',self.data,Js)
- - np.einsum(''td,nkd,2*mus,Js))
- all_likes += (mus**2*Js - 1./2*np.log(2*np.pi*sigmas)).sum(2)
- # weights is Nstates x Ncomponents
- weights = np.log(np.array([d.weights.weights for d in self.obs_distns]))
- all_likes += weights[na,...]
- # aBl is T x Nstates
- aBl = self._aBl = np.logaddexp.reduce(all_likes, axis=2)
- aBl[np.isnan(aBl).any(1)] = 0.
- aBBl = self._aBBl = np.empty((self.Tblock,self.num_states))
- for idx, (start,stop) in enumerate(self.changepoints):
- aBBl[idx] = aBl[start:stop].sum(0)
- return self._aBBl
- def _expected_statistics_from_messages_slow(trans_potential,likelihood_log_potential,alphal,betal):
- expected_states = alphal + betal
- expected_states -= expected_states.max(1)[:,na]
- np.exp(expected_states,out=expected_states)
- expected_states /= expected_states.sum(1)[:,na]
- Al = np.log(trans_potential)
- log_joints = alphal[:-1,:,na] + (betal[1:,na,:] + likelihood_log_potential[1:,:]) + Al[na,...]
- log_joints -= log_joints.max((1,2))[:,na]
- joints = np.exp(log_joints)
- joints /= joints.sum((1,na] # NOTE: renormalizing each isnt really necessary
- expected_transcounts = joints.sum(0)
- normalizer = np.logaddexp.reduce(alphal[0] + betal[0])
- return expected_states, expected_transcounts, normalizer
- ### EM
- def _messages_backwards_log_slow(trans_potential, init_potential, likelihood_log_potential,
- feature_weights, window_data):
- errs = np.seterr(over=''ignore'')
- Al = np.log(trans_potential)
- pil = np.log(init_potential)
- aBl = likelihood_log_potential
- nhs = trans_potential.shape[0]
- sequence_length = aBl.shape[0]
- betal = np.zeros((sequence_length, nhs * 2))
- giant_Al_pil = np.tile(np.vstack((np.tile(pil, (nhs,1)), Al )), (1,2))
- for t in xrange(betal.shape[0]-2,-1,-1):
- temp_constant = np.sum(feature_weights[:-nhs-1] * window_data[t+1,:]) + feature_weights[-1]
- temp_exp = temp_constant + feature_weights[-nhs-1:-1]
- temp_logaddexp = np.logaddexp(0, temp_exp)
- temp_log_linear = np.tile(temp_exp, 2) * np.repeat([0,1], nhs) - np.tile(temp_logaddexp, 2)
- np.logaddexp.reduce( giant_Al_pil + betal[t+1] +
- np.hstack((aBl[t+1], aBl[t+1])) +
- temp_log_linear
- ,axis=1 ,out=(betal[t]))
- np.seterr(**errs)
- return betal
- def _messages_backwards_log_fast(trans_potential, likelihood_log_potential_llt):
- errs = np.seterr(over=''ignore'')
- Al = np.log(trans_potential)
- pil = np.log(init_potential)
- aBl = likelihood_log_potential_llt
- nhs = trans_potential.shape[0]
- sequence_length = aBl.shape[0]
- betal = np.zeros((sequence_length,2))
- for t in xrange(betal.shape[0]-2,-1):
- np.logaddexp.reduce( giant_Al_pil + betal[t+1] + aBl[t+1], axis=1, out=(betal[t]))
- np.seterr(**errs)
- return betal
- ### Gibbs sampling
- def _expected_segmentation_states(init_potential, expected_states, trans_potential, expected_joints,
- feature_weights, window_data):
- #log_q(s_t) for s_t = 1
- data_length = window_data.shape[0]
- mega_mat = np.hstack((window_data[:data_length - 1,:], expected_states[:data_length - 1,:]))
- temp_1 = np.sum(feature_weights * mega_mat, axis=1)
- with np.errstate(invalid=''ignore''):
- temp_2 = np.sum(np.sum(expected_joints[:data_length - 1,:] * np.log(trans_potential), axis = 1), axis = 1)
- log_s_t_1 = temp_1 + temp_2
- log_s_t_1 = np.append(log_s_t_1, -float("inf")) #the last state is always zero so the probability of s_t = 1 is zero
- #log q(s_t) for s_t = 0
- log_s_t_0 = np.sum(expected_states[1:, :] * np.log(init_potential), axis = 1)
- log_s_t_0 = np.append(log_s_t_0, 0)
- temp_stack = np.hstack((log_s_t_1[:, na], log_s_t_0[:, na])) #number of rows is the length of the sequence
- expected_states = np.exp(temp_stack - np.logaddexp.reduce(temp_stack[:,na], axis = 1))
- return expected_states
- def _parallel_predict_log_proba(estimators, estimators_features, X, n_classes):
- """Private function used to compute log probabilities within a job."""
- n_samples = X.shape[0]
- log_proba = np.empty((n_samples, n_classes))
- log_proba.fill(-np.inf)
- all_classes = np.arange(n_classes, dtype=np.int)
- for estimator, features in zip(estimators, estimators_features):
- log_proba_estimator = estimator.predict_log_proba(X[:, features])
- if n_classes == len(estimator.classes_):
- log_proba = np.logaddexp(log_proba, log_proba_estimator)
- else:
- log_proba[:, estimator.classes_] = np.logaddexp(
- log_proba[:, estimator.classes_],
- log_proba_estimator[:, range(len(estimator.classes_))])
- missing = np.setdiff1d(all_classes, estimator.classes_)
- log_proba[:, missing] = np.logaddexp(log_proba[:, missing],
- -np.inf)
- return log_proba
- def _free_energy(self, v):
- """Computes the free energy F(v) = - log sum_h exp(-E(v,h)).
- Parameters
- ----------
- v : array-like,shape (n_samples,n_features)
- Values of the visible layer.
- Returns
- -------
- free_energy : array-like,)
- The value of the free energy.
- """
- return (- safe_sparse_dot(v, self.intercept_visible_)
- - np.logaddexp(0, safe_sparse_dot(v, self.components_.T)
- + self.intercept_hidden_).sum(axis=1))
- def test_NotImplemented_not_returned(self):
- # See gh-5964 and gh-2091. Some of these functions are not operator
- # related and were fixed for other reasons in the past.
- binary_funcs = [
- np.power, b)
- def logaddexp(arr):
- """Computes log(exp(arr[0]) + exp(arr[1]) + ...). """
- assert(len(arr) >= 2)
- res = np.logaddexp(arr[0], arr[1])
- for i in arr[2:]:
- res = np.logaddexp(res, i)
- return res
- def test_logaddexp_values(self):
- x = [1, 2, 3, 4, 5]
- y = [5, 1]
- z = [6, 6, 6]
- for dt, dec_ in zip([''f'', ''d'', ''g''], [6, 15, 15]):
- xf = np.log(np.array(x, dtype=dt))
- yf = np.log(np.array(y, dtype=dt))
- zf = np.log(np.array(z, dtype=dt))
- assert_almost_equal(np.logaddexp(xf, yf), zf, decimal=dec_)
- def test_logaddexp_range(self):
- x = [1000000, -1000000, 1000200, -1000200]
- y = [1000200, -1000200, 1000000, -1000000]
- z = [1000200, -1000000]
- for dt in [''f'', ''g'']:
- logxf = np.array(x, dtype=dt)
- logyf = np.array(y, dtype=dt)
- logzf = np.array(z, dtype=dt)
- assert_almost_equal(np.logaddexp(logxf, logyf), logzf)
- def test_inf(self):
- inf = np.inf
- x = [inf, -inf, inf, inf, 1, -inf, 1]
- y = [inf, inf, -inf]
- z = [inf, 1]
- with np.errstate(invalid=''raise''):
- for dt in [''f'', ''g'']:
- logxf = np.array(x, dtype=dt)
- logyf = np.array(y, dtype=dt)
- logzf = np.array(z, dtype=dt)
- assert_equal(np.logaddexp(logxf, logzf)
- def test_nan(self):
- assert_(np.isnan(np.logaddexp(np.nan, np.inf)))
- assert_(np.isnan(np.logaddexp(np.inf, np.nan)))
- assert_(np.isnan(np.logaddexp(np.nan, 0)))
- assert_(np.isnan(np.logaddexp(0, np.nan)))
- def _free_energy(self,h)).
- v : array-like, self.components_.T)
- + self.intercept_hidden_).sum(axis=1))
- def sigmoid(x):
- if x >= 0:
- return math.exp(-np.logaddexp(0, -x))
- else:
- return math.exp(x - np.logaddexp(x, 0))
- def sigmoid(x):
- return math.exp(-np.logaddexp(0, -x))
- def check_forward(self, x_data, t_data, class_weight, use_cudnn=True):
- x = chainer.Variable(x_data)
- t = chainer.Variable(t_data)
- loss = softmax_cross_entropy.softmax_cross_entropy(
- x, t, use_cudnn=use_cudnn, normalize=self.normalize,
- cache_score=self.cache_score, class_weight=class_weight)
- self.assertEqual(loss.data.shape, ())
- self.assertEqual(loss.data.dtype, self.dtype)
- self.assertEqual(hasattr(loss.creator, ''y''), self.cache_score)
- loss_value = float(cuda.to_cpu(loss.data))
- # Compute expected value
- loss_expect = 0.0
- count = 0
- x = numpy.rollaxis(self.x, self.x.ndim).reshape(
- (self.t.size, self.x.shape[1]))
- t = self.t.ravel()
- for xi, ti in six.moves.zip(x, t):
- if ti == -1:
- continue
- log_z = numpy.ufunc.reduce(numpy.logaddexp, xi)
- if class_weight is None:
- loss_expect -= (xi - log_z)[ti]
- else:
- loss_expect -= (xi - log_z)[ti] * class_weight[ti]
- count += 1
- if self.normalize:
- if count == 0:
- loss_expect = 0.0
- else:
- loss_expect /= count
- else:
- loss_expect /= len(t_data)
- testing.assert_allclose(
- loss_expect, loss_value, **self.check_forward_options)
- def integrate_remainder(sampler, logwidth, logVolremaining, logZ, H, globalLmax):
- # logwidth remains the same Now for each sample
- remainder = list(sampler.remainder())
- logV = logwidth
- L0 = remainder[-1][2]
- L0 = globalLmax
- logLs = [Li - L0 for ui, xi, Li in remainder]
- Ls = numpy.exp(logLs)
- LsMax = Ls.copy()
- LsMax[-1] = numpy.exp(globalLmax - L0)
- Lmax = LsMax[1:].sum(axis=0) + LsMax[-1]
- #Lmax = Ls[1:].sum(axis=0) + Ls[-1]
- Lmin = Ls[:-1].sum(axis=0) + Ls[0]
- logLmid = log(Ls.sum(axis=0)) + L0
- logZmid = logaddexp(logZ, logV + logLmid)
- logZup = logaddexp(logZ, logV + log(Lmax) + L0)
- logZlo = logaddexp(logZ, logV + log(Lmin) + L0)
- logZerr = logZup - logZlo
- assert numpy.isfinite(H).all()
- assert numpy.isfinite(logZerr).all(), logZerr
- for i in range(len(remainder)):
- ui, Li = remainder[i]
- wi = logwidth + Li
- logZnew = logaddexp(logZ, wi)
- #Hprev = H
- H = exp(wi - logZnew) * Li + exp(logZ - logZnew) * (H + logZ) - logZnew
- H[H < 0] = 0
- #assert (H>0).all(),(H,Hprev,wi,Li,logZ,logZnew)
- logZ = logZnew
- #assert numpy.isfinite(logZerr + (H / sampler.nlive_points)**0.5),sampler.nlive_points,logZerr)
- return logV + logLmid, logZerr, logZmid, logZerr + (H / sampler.nlive_points)**0.5, logZerr + (H / sampler.nlive_points)**0.5
- def test_logaddexp_values(self):
- x = [1, decimal=dec_)
- def test_logaddexp_range(self):
- x = [1000000, logzf)
- def test_inf(self):
- inf = np.inf
- x = [inf, logzf)
- def test_nan(self):
- assert_(np.isnan(np.logaddexp(np.nan, np.nan)))
- def forward(self, x):
- """
- Implementation of softplus. Overflow avoided by use of the logaddexp function.
- self._lower is added before returning.
- """
- return np.logaddexp(0, x) + self._lower
- def ctc_loss(label, prob, remainder, seq_length, batch_size, num_gpu=1, big_num=1e10):
- label_ = [0, 0]
- prob[prob < 1 / big_num] = 1 / big_num
- log_prob = np.log(prob)
- l = len(label)
- for i in range(l):
- label_.append(int(label[i]))
- label_.append(0)
- l_ = 2 * l + 1
- a = np.full((seq_length, l_ + 1), -big_num)
- a[0][1] = log_prob[remainder][0]
- a[0][2] = log_prob[remainder][label_[2]]
- for i in range(1, seq_length):
- row = i * int(batch_size / num_gpu) + remainder
- a[i][1] = a[i - 1][1] + log_prob[row][0]
- a[i][2] = np.logaddexp(a[i - 1][2], a[i - 1][1]) + log_prob[row][label_[2]]
- for j in range(3, l_ + 1):
- a[i][j] = np.logaddexp(a[i - 1][j], a[i - 1][j - 1])
- if label_[j] != 0 and label_[j] != label_[j - 2]:
- a[i][j] = np.logaddexp(a[i][j], a[i - 1][j - 2])
- a[i][j] += log_prob[row][label_[j]]
- return -np.logaddexp(a[seq_length - 1][l_], a[seq_length - 1][l_ - 1])
- # label is done with remove_blank
- # pred is got from pred_best
- def _forward_cpu_one(self, x, W):
- begin = self.begins[t]
- end = self.begins[t + 1]
- w = W[self.paths[begin:end]]
- wxy = w.dot(x) * self.codes[begin:end]
- loss = numpy.logaddexp(0.0, -wxy) # == log(1 + exp(-wxy))
- return numpy.sum(loss)
- def check_forward(self, use_cudnn=True):
- x = chainer.Variable(x_data)
- t = chainer.Variable(t_data)
- loss = functions.softmax_cross_entropy(
- x,
- cache_score=self.cache_score)
- self.assertEqual(loss.data.shape, xi)
- loss_expect -= (xi - log_z)[ti]
- count += 1
- if self.normalize:
- if count == 0:
- loss_expect = 0.0
- else:
- loss_expect /= count
- else:
- loss_expect /= len(t_data)
- gradient_check.assert_allclose(
- loss_expect, **self.check_forward_options)
- def check_forward(self, use_cudnn=True):
- x = chainer.Variable(x_data)
- y = functions.log_softmax(x, use_cudnn)
- self.assertEqual(y.data.dtype, self.dtype)
- log_z = numpy.ufunc.reduce(
- numpy.logaddexp, self.x, keepdims=True)
- y_expect = self.x - log_z
- gradient_check.assert_allclose(
- y_expect, y.data, **self.check_forward_options)
- def js_with(self, p):
- log_p = np.array([p.log_likelihood(ngram) for ngram in p.unique_ngrams()])
- log_q = np.array([self.log_likelihood(ngram) for ngram in p.unique_ngrams()])
- log_m = np.logaddexp(log_p - np.log(2), log_q - np.log(2))
- kl_p_m = np.sum(np.exp(log_p) * (log_p - log_m))
- log_p = np.array([p.log_likelihood(ngram) for ngram in self.unique_ngrams()])
- log_q = np.array([self.log_likelihood(ngram) for ngram in self.unique_ngrams()])
- log_m = np.logaddexp(log_p - np.log(2), log_q - np.log(2))
- kl_q_m = np.sum(np.exp(log_q) * (log_q - log_m))
- return 0.5*(kl_p_m + kl_q_m) / np.log(2)
- def test_logaddexp_values(self):
- x = [1, decimal=dec_)
- def test_logaddexp_range(self):
- x = [1000000, logzf)
- def test_inf(self):
- inf = np.inf
- x = [inf, logzf)
- def test_nan(self):
- assert_(np.isnan(np.logaddexp(np.nan, np.nan)))
- def js_with(self, log_q - np.log(2))
- kl_q_m = np.sum(np.exp(log_q) * (log_q - log_m))
- return 0.5 * (kl_p_m + kl_q_m) / np.log(2)
- def js_with(self, log_q - np.log(2))
- kl_q_m = np.sum(np.exp(log_q) * (log_q - log_m))
- return 0.5*(kl_p_m + kl_q_m) / np.log(2)
- def evalObjectiveFunction(clean_biascount,Pword_plus,Pword_minus,ratio,removing_words):
- mlog(evalObjectiveFunction.__name__,"call")
- import numpy as np
- import math
- #Obj = np.log(1)
- Obj = 0
- for doc in clean_biascount:
- Pdoc = calcProbabilityDocument(Pword_plus,doc[1],removing_words)
- i = clean_biascount.index(doc)
- if i == 0:
- mlog(evalObjectiveFunction.__name__,''Pdoc 0 '' + str(Pdoc) + '' type '' + str(type(Pdoc)))
- t00 = np.exp(np.float64(Pdoc[0]))
- t01 = np.exp(np.float64(Pdoc[1]))
- t1 = t00 - t01
- #print str(t1)
- t2 = abs(t1)
- Obj = np.log(t2)
- #print str(Obj)
- if i % 100 == 0:
- mlog(evalObjectiveFunction.__name__,"Pdoc + " + str(i) + "= " + str(Pdoc))
- if doc[0] == True:
- Obj = np.logaddexp(Obj,Pdoc[0])
- if i % 100 == 1:
- mlog(evalObjectiveFunction.__name__,"Obj+ " + str(i) + " after += " + str(Obj))
- Obj = np.log(np.exp(Obj) - np.exp(Pdoc[1]))
- elif doc[0] == False:
- Obj = np.log(np.exp(np.float64(Obj)) + np.exp(np.float64(Pdoc[1])))
- if i % 100 == 2:
- mlog(evalObjectiveFunction.__name__,"Obj- " + str(i) + " after += " + str(Obj))
- Obj = np.log(np.exp(Obj) - np.exp(Pdoc[0]))
- if Obj == 0.0:
- mlog(evalObjectiveFunction.__name__, "Obj=0 fuck " + str(i) + "")
- mlog(evalObjectiveFunction.__name__,"Obj = " + str(np.exp(Obj)))
- if math.isnan(np.exp(Obj))==False:
- print ''J = '' + str(np.exp(Obj))
- return Obj #type np.log
- def sigmoid(x):
- x = np.array(x)
- return np.exp(-np.logaddexp(0, -x))
- def update_phi(self, doc_number, time):
- """
- Update variational multinomial parameters,based on a document and a time-slice.
- This is done based on the original Blei-LDA paper,where:
- log_phi := beta * exp(?(gamma)),over every topic for every word.
- Todo: incorporate lee-sueng trick used in **Lee,Seung: Algorithms for non-negative matrix factorization,NIPS 2001**.
- """
- num_topics = self.lda.num_topics
- # digamma values
- dig = np.zeros(num_topics)
- for k in range(0, num_topics):
- dig[k] = digamma(self.gamma[k])
- n = 0 # keep track of iterations for phi,log_phi
- for word_id, count in self.doc:
- for k in range(0, num_topics):
- self.log_phi[n][k] = dig[k] + self.lda.topics[word_id][k]
- log_phi_row = self.log_phi[n]
- phi_row = self.phi[n]
- # log normalize
- v = log_phi_row[0]
- for i in range(1, len(log_phi_row)):
- v = np.logaddexp(v, log_phi_row[i])
- # subtract every element by v
- log_phi_row = log_phi_row - v
- phi_row = np.exp(log_phi_row)
- self.log_phi[n] = log_phi_row
- self.phi[n] = phi_row
- n +=1 # increase iteration
- return self.phi, self.log_phi
- def test_logaddexp_values(self):
- x = [1, decimal=dec_)
- def test_logaddexp_range(self):
- x = [1000000, logzf)
:TypeError: 'numpy.ndarray' object is not callable")
Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable
如何解决Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: ''numpy.ndarray'' object is not callable?
晚安, 尝试打印以下内容时,我在 jupyter 中遇到了 numpy 问题,并且得到了一个 错误: 需要注意的是python版本是3.8.8。 我先用 spyder 测试它,它运行正确,它给了我预期的结果
使用 Spyder:
import numpy as np
for i in range (5):
n = np.random.rand ()
print (n)
Results
0.6604903457995978
0.8236300859753154
0.16067650689842816
0.6967868357083673
0.4231597934445466
现在有了 jupyter
import numpy as np
for i in range (5):
n = np.random.rand ()
print (n)
-------------------------------------------------- ------
TypeError Traceback (most recent call last)
<ipython-input-78-0c6a801b3ea9> in <module>
2 for i in range (5):
3 n = np.random.rand ()
----> 4 print (n)
TypeError: ''numpy.ndarray'' object is not callable
感谢您对我如何在 Jupyter 中解决此问题的帮助。
非常感谢您抽出宝贵时间。
阿特,约翰”
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

numpy.random.random & numpy.ndarray.astype & numpy.arange
今天看到这样一句代码:
xb = np.random.random((nb, d)).astype(''float32'') #创建一个二维随机数矩阵(nb行d列)
xb[:, 0] += np.arange(nb) / 1000. #将矩阵第一列的每个数加上一个值要理解这两句代码需要理解三个函数
1、生成随机数
numpy.random.random(size=None)
size为None时,返回float。
size不为None时,返回numpy.ndarray。例如numpy.random.random((1,2)),返回1行2列的numpy数组
2、对numpy数组中每一个元素进行类型转换
numpy.ndarray.astype(dtype)
返回numpy.ndarray。例如 numpy.array([1, 2, 2.5]).astype(int),返回numpy数组 [1, 2, 2]
3、获取等差数列
numpy.arange([start,]stop,[step,]dtype=None)
功能类似python中自带的range()和numpy中的numpy.linspace
返回numpy数组。例如numpy.arange(3),返回numpy数组[0, 1, 2]
/numpy.flatten()/numpy.squeeze()")
numpy.ravel()/numpy.flatten()/numpy.squeeze()
numpy.ravel(a, order=''C'')
Return a flattened array
numpy.chararray.flatten(order=''C'')
Return a copy of the array collapsed into one dimension
numpy.squeeze(a, axis=None)
Remove single-dimensional entries from the shape of an array.
相同点: 将多维数组 降为 一维数组
不同点:
ravel() 返回的是视图(view),意味着改变元素的值会影响原始数组元素的值;
flatten() 返回的是拷贝,意味着改变元素的值不会影响原始数组;
squeeze()返回的是视图(view),仅仅是将shape中dimension为1的维度去掉;
ravel()示例:
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.ravel()
16 print("a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19
20 print(a)
21 log_type(''a'',a)
flatten()示例
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.flatten()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)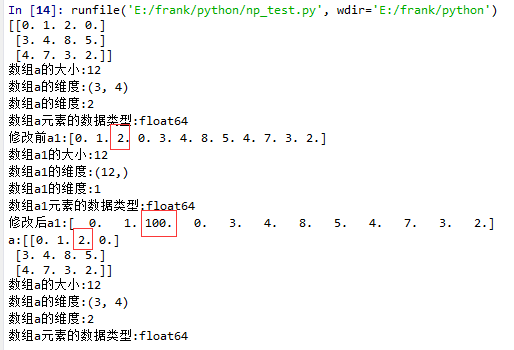
squeeze()示例:
1. 没有single-dimensional entries的情况
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.squeeze()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)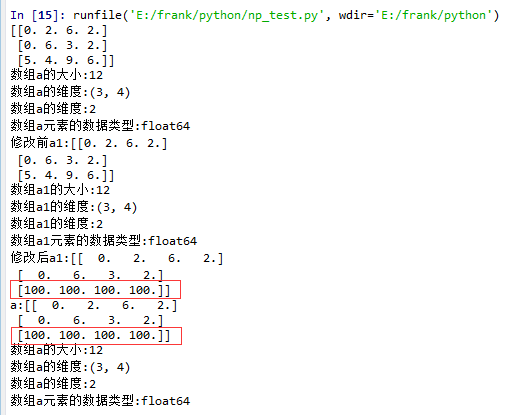
从结果中可以看到,当没有single-dimensional entries时,squeeze()返回额数组对象是一个view,而不是copy。
2. 有single-dimentional entries 的情况
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((1,3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.squeeze()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)
 , numpy.arange()、np.linspace ()、数组基本属性")
Numpy:数组创建 numpy.arrray() , numpy.arange()、np.linspace ()、数组基本属性
一、Numpy数组创建
part 1:np.linspace(起始值,终止值,元素总个数
import numpy as np
''''''
numpy中的ndarray数组
''''''
ary = np.array([1, 2, 3, 4, 5])
print(ary)
ary = ary * 10
print(ary)
''''''
ndarray对象的创建
''''''
# 创建二维数组
# np.array([[],[],...])
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
print(a)
# np.arange(起始值, 结束值, 步长(默认1))
b = np.arange(1, 10, 1)
print(b)
print("-------------np.zeros(数组元素个数, dtype=''数组元素类型'')-----")
# 创建一维数组:
c = np.zeros(10)
print(c, ''; c.dtype:'', c.dtype)
# 创建二维数组:
print(np.zeros ((3,4)))
print("----------np.ones(数组元素个数, dtype=''数组元素类型'')--------")
# 创建一维数组:
d = np.ones(10, dtype=''int64'')
print(d, ''; d.dtype:'', d.dtype)
# 创建三维数组:
print(np.ones( (2,3,4), dtype=np.int32 ))
# 打印维度
print(np.ones( (2,3,4), dtype=np.int32 ).ndim) # 返回:3(维)
结果图:

part 2 :np.linspace ( 起始值,终止值,元素总个数)
import numpy as np
a = np.arange( 10, 30, 5 )
b = np.arange( 0, 2, 0.3 )
c = np.arange(12).reshape(4,3)
d = np.random.random((2,3)) # 取-1到1之间的随机数,要求设置为诶2行3列的结构
print(a)
print(b)
print(c)
print(d)
print("-----------------")
from numpy import pi
print(np.linspace( 0, 2*pi, 100 ))
print("-------------np.linspace(起始值,终止值,元素总个数)------------------")
print(np.sin(np.linspace( 0, 2*pi, 100 )))
结果图:

二、Numpy的ndarray对象属性:
数组的结构:array.shape
数组的维度:array.ndim
元素的类型:array.dtype
数组元素的个数:array.size
数组的索引(下标):array[0]
''''''
数组的基本属性
''''''
import numpy as np
print("--------------------案例1:------------------------------")
a = np.arange(15).reshape(3, 5)
print(a)
print(a.shape) # 打印数组结构
print(len(a)) # 打印有多少行
print(a.ndim) # 打印维度
print(a.dtype) # 打印a数组内的元素的数据类型
# print(a.dtype.name)
print(a.size) # 打印数组的总元素个数
print("-------------------案例2:---------------------------")
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a)
# 测试数组的基本属性
print(''a.shape:'', a.shape)
print(''a.size:'', a.size)
print(''len(a):'', len(a))
# a.shape = (6, ) # 此格式可将原数组结构变成1行6列的数据结构
# print(a, ''a.shape:'', a.shape)
# 数组元素的索引
ary = np.arange(1, 28)
ary.shape = (3, 3, 3) # 创建三维数组
print("ary.shape:",ary.shape,"\n",ary )
print("-----------------")
print(''ary[0]:'', ary[0])
print(''ary[0][0]:'', ary[0][0])
print(''ary[0][0][0]:'', ary[0][0][0])
print(''ary[0,0,0]:'', ary[0, 0, 0])
print("-----------------")
# 遍历三维数组:遍历出数组里的每个元素
for i in range(ary.shape[0]):
for j in range(ary.shape[1]):
for k in range(ary.shape[2]):
print(ary[i, j, k], end='' '')
结果图:

今天的关于Python numpy 模块-logaddexp() 实例源码和python中numpy模块的分享已经结束,谢谢您的关注,如果想了解更多关于Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable、numpy.random.random & numpy.ndarray.astype & numpy.arange、numpy.ravel()/numpy.flatten()/numpy.squeeze()、Numpy:数组创建 numpy.arrray() , numpy.arange()、np.linspace ()、数组基本属性的相关知识,请在本站进行查询。
本文标签:




