在本文中,我们将为您详细介绍Pythonnumpy模块-array2string()实例源码的相关知识,并且为您解答关于pythonnumpy.array的疑问,此外,我们还会提供一些关于Jupyte
在本文中,我们将为您详细介绍Python numpy 模块-array2string() 实例源码的相关知识,并且为您解答关于python numpy.array的疑问,此外,我们还会提供一些关于Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable、List2String 与 Array2String、numpy.random.random & numpy.ndarray.astype & numpy.arange、numpy.ravel()/numpy.flatten()/numpy.squeeze()的有用信息。
本文目录一览:- Python numpy 模块-array2string() 实例源码(python numpy.array)
- Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable
- List2String 与 Array2String
- numpy.random.random & numpy.ndarray.astype & numpy.arange
- numpy.ravel()/numpy.flatten()/numpy.squeeze()
 实例源码(python numpy.array)")
Python numpy 模块-array2string() 实例源码(python numpy.array)
Python numpy 模块,array2string() 实例源码
我们从Python开源项目中,提取了以下50个代码示例,用于说明如何使用numpy.array2string()。
- def export_collada(mesh):
- ''''''
- Export a mesh as a COLLADA file.
- ''''''
- from ..templates import get_template
- from string import Template
- template_string = get_template(''collada.dae.template'')
- template = Template(template_string)
- # we bother setting this because np.array2string uses these printoptions
- np.set_printoptions(threshold=np.inf, precision=5, linewidth=np.inf)
- replacement = dict()
- replacement[''VERTEX''] = np.array2string(mesh.vertices.reshape(-1))[1:-1]
- replacement[''FACES''] = np.array2string(mesh.faces.reshape(-1))[1:-1]
- replacement[''norMALS''] = np.array2string(mesh.vertex_normals.reshape(-1))[1:-1]
- replacement[''VCOUNT''] = str(len(mesh.vertices))
- replacement[''VCOUNTX3''] = str(len(mesh.vertices) * 3)
- replacement[''FCOUNT''] = str(len(mesh.faces))
- export = template.substitute(replacement)
- return export
- def var_label(var, precision=3):
- """Return label of variable node."""
- if var.name is not None:
- return var.name
- elif isinstance(var, gof.Constant):
- h = np.asarray(var.data)
- is_const = False
- if h.ndim == 0:
- is_const = True
- h = np.array([h])
- dstr = np.array2string(h, precision=precision)
- if ''\\n'' in dstr:
- dstr = dstr[:dstr.index(''\\n'')]
- if is_const:
- dstr = dstr.replace(''['', '''').replace('']'', '''')
- return dstr
- else:
- return type_to_str(var.type)
- def _format_items(items):
- formatter = lambda x: ''%.3e'' % x
- last_large_output = None
- for key, value in items:
- value = np.asarray(value)
- large_output = value.ndim >= 1
- # If there was a prevIoUs output,print a separator.
- if last_large_output is not None:
- yield ''\\n'' if large_output or last_large_output else '' ''
- format_string = ''%s:\\n%s'' if large_output else ''%s: %s''
- yield format_string % (key,
- np.array2string(value, style=formatter,
- formatter={''float_kind'': formatter}))
- last_large_output = large_output
- def _format_items(items):
- formatter = lambda x: ''%.3e'' % x
- last_large_output = None
- for key,
- formatter={''float_kind'': formatter}))
- last_large_output = large_output
- def test_basic(self):
- """Basic test of array2string."""
- a = np.arange(3)
- assert_(np.array2string(a) == ''[0 1 2]'')
- assert_(np.array2string(a, max_line_width=4) == ''[0 1\\n 2]'')
- def test_style_keyword(self):
- """This should only apply to 0-D arrays. See #1218."""
- stylestr = np.array2string(np.array(1.5),
- style=lambda x: "Value in 0-D array: " + str(x))
- assert_(stylestr == ''Value in 0-D array: 1.5'')
- def test_format_function(self):
- """Test custom format function for each element in array."""
- def _format_function(x):
- if np.abs(x) < 1:
- return ''.''
- elif np.abs(x) < 2:
- return ''o''
- else:
- return ''O''
- x = np.arange(3)
- if sys.version_info[0] >= 3:
- x_hex = "[0x0 0x1 0x2]"
- x_oct = "[0o0 0o1 0o2]"
- else:
- x_hex = "[0x0L 0x1L 0x2L]"
- x_oct = "[0L 01L 02L]"
- assert_(np.array2string(x, formatter={''all'':_format_function}) ==
- "[. o O]")
- assert_(np.array2string(x, formatter={''int_kind'':_format_function}) ==
- "[. o O]")
- assert_(np.array2string(x, formatter={''all'':lambda x: "%.4f" % x}) ==
- "[0.0000 1.0000 2.0000]")
- assert_equal(np.array2string(x, formatter={''int'':lambda x: hex(x)}),
- x_hex)
- assert_equal(np.array2string(x, formatter={''int'':lambda x: oct(x)}),
- x_oct)
- x = np.arange(3.)
- assert_(np.array2string(x, formatter={''float_kind'':lambda x: "%.2f" % x}) ==
- "[0.00 1.00 2.00]")
- assert_(np.array2string(x, formatter={''float'':lambda x: "%.2f" % x}) ==
- "[0.00 1.00 2.00]")
- s = np.array([''abc'', ''def''])
- assert_(np.array2string(s, formatter={''numpystr'':lambda s: s*2}) ==
- ''[abcabc defdef]'')
- def test_datetime_array_str(self):
- a = np.array([''2011-03-16'', ''1920-01-01'', ''2013-05-19''], dtype=''M'')
- assert_equal(str(a), "[''2011-03-16'' ''1920-01-01'' ''2013-05-19'']")
- a = np.array([''2011-03-16T13:55'', ''1920-01-01T03:12''], dtype=''M'')
- assert_equal(np.array2string(a, separator='','',
- formatter={''datetime'': lambda x:
- "''%s''" % np.datetime_as_string(x, timezone=''UTC'')}),
- "[''2011-03-16T13:55Z'',''1920-01-01T03:12Z'']")
- # Check that one NaT doesn''t corrupt subsequent entries
- a = np.array([''2010'', ''NaT'', ''2030'']).astype(''M'')
- assert_equal(str(a), "[''2010'' ''NaT'' ''2030'']")
- def arr2str(a):
- return np.array2string(a, max_line_width=np.inf,
- precision=None, suppress_small=None).replace(''\\n'', '''')
- def periodicDataDump(filename,d):
- """
- dump a ndarray to disk. If first time,just dump it.
- Else,load current ary and cat d to it before dumping.
- """
- old=True
- if len(d)!=0:
- if os.path.exists(filename):
- if old:
- d0 = np.load(filename)
- np.save(filename,np.concatenate((d0,d)))
- else:
- with open(filename,''a'') as outfile:
- for i in range(0,d.shape[0]):
- outstr = ''''
- for val in d[i]:
- outstr+=''%.14g '' % (val)
- outstr += ''\\n''
- outfile.write(outstr)#nparyTolistStr(d[i],brackets=False,dmtr='' '')+''\\n'')
- #outfile.write(re.sub("\\n ","\\n",re.sub("[\\\\[\\\\]]","",np.array2string(d,precision=16))))
- else:
- if old:
- np.save(filename,d)
- else:
- with open(filename,''w'') as outfile:
- for i in range(0,dmtr='' ''))
- #outfile.write(re.sub("\\n ",np.array2string(d))))
- #print nparyTolistStr(d[i],dmtr='' '')
- #raise IOError(''\\n\\n''+s)
- def test_basic(self):
- """Basic test of array2string."""
- a = np.arange(3)
- assert_(np.array2string(a) == ''[0 1 2]'')
- assert_(np.array2string(a, max_line_width=4) == ''[0 1\\n 2]'')
- def test_style_keyword(self):
- """This should only apply to 0-D arrays. See #1218."""
- stylestr = np.array2string(np.array(1.5),
- style=lambda x: "Value in 0-D array: " + str(x))
- assert_(stylestr == ''Value in 0-D array: 1.5'')
- def test_format_function(self):
- """Test custom format function for each element in array."""
- def _format_function(x):
- if np.abs(x) < 1:
- return ''.''
- elif np.abs(x) < 2:
- return ''o''
- else:
- return ''O''
- x = np.arange(3)
- if sys.version_info[0] >= 3:
- x_hex = "[0x0 0x1 0x2]"
- x_oct = "[0o0 0o1 0o2]"
- else:
- x_hex = "[0x0L 0x1L 0x2L]"
- x_oct = "[0L 01L 02L]"
- assert_(np.array2string(x, formatter={''numpystr'':lambda s: s*2}) ==
- ''[abcabc defdef]'')
- def test_datetime_array_str(self):
- a = np.array([''2011-03-16'', "[''2010'' ''NaT'' ''2030'']")
- def __repr__(self):
- if len(self.data) >= 1:
- str = ''-----------------------------------------\\n''
- for each in self._list:
- array = np.asarray(each)
- str = str + np.array2string(array) \\
- + ''\\n-----------------------------------------\\n''
- return str.rstrip("\\n") # Remove trailing newline character
- else:
- return ''No matrix found''
- def matrix_mismatch_string_builder(rec_mat, exp_mat):
- expected_mat_str = np.array2string(np.asarray(exp_mat))
- received_mat_str = np.array2string(np.asarray(rec_mat))
- output_str = str("\\n----------------------\\n"
- + " Expected Output "
- + "\\n----------------------\\n"
- + expected_mat_str
- + "\\n----------------------\\n"
- + " Received Output "
- + "\\n----------------------\\n"
- + received_mat_str)
- return output_str
- def test_basic(self):
- """Basic test of array2string."""
- a = np.arange(3)
- assert_(np.array2string(a) == ''[0 1 2]'')
- assert_(np.array2string(a, max_line_width=4) == ''[0 1\\n 2]'')
- def test_style_keyword(self):
- """This should only apply to 0-D arrays. See #1218."""
- stylestr = np.array2string(np.array(1.5),
- style=lambda x: "Value in 0-D array: " + str(x))
- assert_(stylestr == ''Value in 0-D array: 1.5'')
- def test_format_function(self):
- """Test custom format function for each element in array."""
- def _format_function(x):
- if np.abs(x) < 1:
- return ''.''
- elif np.abs(x) < 2:
- return ''o''
- else:
- return ''O''
- x = np.arange(3)
- if sys.version_info[0] >= 3:
- x_hex = "[0x0 0x1 0x2]"
- x_oct = "[0o0 0o1 0o2]"
- else:
- x_hex = "[0x0L 0x1L 0x2L]"
- x_oct = "[0L 01L 02L]"
- assert_(np.array2string(x, formatter={''numpystr'':lambda s: s*2}) ==
- ''[abcabc defdef]'')
- def test_datetime_array_str(self):
- a = np.array([''2011-03-16'', "[''2011-03-16'' ''1920-01-01'' ''2013-05-19'']")
- a = np.array([''2011-03-16T13:55Z'', ''1920-01-01T03:12Z''], "[''2010'' ''NaT'' ''2030'']")
- def __str__(self):
- formatter = {''float_kind'': lambda x: "{: 7.1f}".format(x) }
- mmsiStr = " MMSI {:} ".format(self.mmsi) if self.mmsi is not None else ""
- predStateStr = ("Pred state:" + np.array2string(self.predicted_state,
- precision=1,
- suppress_small=True,
- formatter=formatter)
- if self.predicted_state is not None else "")
- return ("State: " + np.array2string(self.state, precision=1, suppress_small=True,formatter=formatter) +
- " ({0:}|{1:}) ".format(self.m, self.n) +
- predStateStr +
- mmsiStr)
- def __str__(self):
- timeString = self.getTimeString()
- mmsiString = ''MMSI: '' + str(self.mmsi) if self.mmsi is not None else ""
- return (''Time: '' + timeString + " " +
- ''State:'' + np.array2string(self.state, formatter={''float_kind'': lambda x: ''{: 7.1f}''.format(x)}) + " " +
- ''High accuracy: {:1} ''.format(self.highAccuracy) +
- mmsiString)
- def test_basic(self):
- """Basic test of array2string."""
- a = np.arange(3)
- assert_(np.array2string(a) == ''[0 1 2]'')
- assert_(np.array2string(a, max_line_width=4) == ''[0 1\\n 2]'')
- def test_style_keyword(self):
- """This should only apply to 0-D arrays. See #1218."""
- stylestr = np.array2string(np.array(1.5),
- style=lambda x: "Value in 0-D array: " + str(x))
- assert_(stylestr == ''Value in 0-D array: 1.5'')
- def test_format_function(self):
- """Test custom format function for each element in array."""
- def _format_function(x):
- if np.abs(x) < 1:
- return ''.''
- elif np.abs(x) < 2:
- return ''o''
- else:
- return ''O''
- x = np.arange(3)
- if sys.version_info[0] >= 3:
- x_hex = "[0x0 0x1 0x2]"
- x_oct = "[0o0 0o1 0o2]"
- else:
- x_hex = "[0x0L 0x1L 0x2L]"
- x_oct = "[0L 01L 02L]"
- assert_(np.array2string(x, formatter={''numpystr'':lambda s: s*2}) ==
- ''[abcabc defdef]'')
- def test_datetime_array_str(self):
- a = np.array([''2011-03-16'', "[''2010'' ''NaT'' ''2030'']")
- def main():
- n_particles = 6
- bounds = [(-0.7, 0.7)] * (3 * n_particles)
- np.random.seed(1)
- ret = sda(sutton_chen, None, bounds=bounds)
- # np.set_printoptions(precision=4)
- print(''xmin =\\n{}''.format(np.array2string(ret.x, max_line_width=40)))
- print("global minimum: f(xmin) = {}".format(ret.fun))
- def check_mixed_mode(vis,mode):
- logger.info(''Check for mixed mode'')
- tb.open(vis + ''/SPECTRAL_WINDOW'')
- bw_spw = np.array(tb.getcol(''TOTAL_BANDWIDTH''))
- tb.close()
- if len(np.unique(bw_spw)) != 1:
- if mode == ''split'':
- logger.info(''Splitting continuum from spectral line'')
- cont_spw = np.where(bw_spw==np.max(np.unique(bw_spw)))[0]
- print np.array2string(cont_spw,'')[1:-1]
- split(vis=vis, outputvis=vis+''.continuum'', spw=np.array2string(cont_spw,'')[1:-1], datacolumn=''data'')
- spec_line = np.delete(bw_spw, cont_spw)
- logger.info(''Splitting spectral line'')
- for i in range(len(np.unique(spec_line))):
- spec_line_spw = np.where(bw_spw==np.unique(spec_line)[i])[0]
- split(vis=vis, outputvis=vis+''.sp{0}''.format(i), spw=np.array2string(spec_line_spw,datacolumn=''data'')
- ms.writehistory(message=''eMER_CASA_Pipeline: Spectral line split from {0}''.format(vis),msname=vis+''.sp{0}''.format(i))
- ms.writehistory(message=''eMER_CASA_Pipeline: Spectral lines split from this ms'',msname=vis)
- os.system(''mv {0} {1}''.format(vis, vis+''.original''))
- os.system(''mv {0} {1}''.format(vis+''.continuum'', vis))
- logger.info(''Will continue with continuum,original data is {0}''.format(vis+''.original''))
- return_variable = ''''
- if mode == ''check'':
- logger.info(''MS is mixed mode. Please split'')
- return_variable = True
- else:
- if mode == ''split'':
- logger.info(''Not mixed mode,continuing'')
- return_variable = ''''
- if mode == ''check'':
- return_variable = False
- return return_variable
- def test_basic(self):
- """Basic test of array2string."""
- a = np.arange(3)
- assert_(np.array2string(a) == ''[0 1 2]'')
- assert_(np.array2string(a, max_line_width=4) == ''[0 1\\n 2]'')
- def test_style_keyword(self):
- """This should only apply to 0-D arrays. See #1218."""
- stylestr = np.array2string(np.array(1.5),
- style=lambda x: "Value in 0-D array: " + str(x))
- assert_(stylestr == ''Value in 0-D array: 1.5'')
- def test_format_function(self):
- """Test custom format function for each element in array."""
- def _format_function(x):
- if np.abs(x) < 1:
- return ''.''
- elif np.abs(x) < 2:
- return ''o''
- else:
- return ''O''
- x = np.arange(3)
- if sys.version_info[0] >= 3:
- x_hex = "[0x0 0x1 0x2]"
- x_oct = "[0o0 0o1 0o2]"
- else:
- x_hex = "[0x0L 0x1L 0x2L]"
- x_oct = "[0L 01L 02L]"
- assert_(np.array2string(x, formatter={''numpystr'':lambda s: s*2}) ==
- ''[abcabc defdef]'')
- def test_datetime_array_str(self):
- a = np.array([''2011-03-16'', "[''2010'' ''NaT'' ''2030'']")
- def getRefForMatrix(self, matrix):
- matrix_name = np.array2string(matrix)
- if matrix_name in self.tdict:
- return self.tdict[matrix_name]
- oldidx = self.ntindex
- self.ntindex += 1
- # setup the empty texture array
- self.matrices[oldidx] = matrix
- self.tdict[matrix_name] = oldidx
- # Now fill in the values
- return oldidx
- def test_basic(self):
- """Basic test of array2string."""
- a = np.arange(3)
- assert_(np.array2string(a) == ''[0 1 2]'')
- assert_(np.array2string(a, max_line_width=4) == ''[0 1\\n 2]'')
- def test_style_keyword(self):
- """This should only apply to 0-D arrays. See #1218."""
- stylestr = np.array2string(np.array(1.5),
- style=lambda x: "Value in 0-D array: " + str(x))
- assert_(stylestr == ''Value in 0-D array: 1.5'')
- def test_format_function(self):
- """Test custom format function for each element in array."""
- def _format_function(x):
- if np.abs(x) < 1:
- return ''.''
- elif np.abs(x) < 2:
- return ''o''
- else:
- return ''O''
- x = np.arange(3)
- if sys.version_info[0] >= 3:
- x_hex = "[0x0 0x1 0x2]"
- x_oct = "[0o0 0o1 0o2]"
- else:
- x_hex = "[0x0L 0x1L 0x2L]"
- x_oct = "[0L 01L 02L]"
- assert_(np.array2string(x, formatter={''numpystr'':lambda s: s*2}) ==
- ''[abcabc defdef]'')
- def test_structure_format(self):
- dt = np.dtype([(''name'', np.str_, 16), (''grades'', np.float64, (2,))])
- x = np.array([(''Sarah'', (8.0, 7.0)), (''John'', (6.0, 7.0))], dtype=dt)
- assert_equal(np.array2string(x),
- "[(''Sarah'',[ 8.,7.]) (''John'',[ 6.,7.])]")
- # for issue #5692
- A = np.zeros(shape=10, dtype=[("A", "M8[s]")])
- A[5:].fill(np.nan)
- assert_equal(np.array2string(A),
- "[(''1970-01-01T00:00:00'',) (''1970-01-01T00:00:00'',) " +
- "(''1970-01-01T00:00:00'',)\\n (''1970-01-01T00:00:00'',) (''NaT'',)\\n " +
- "(''NaT'',)]")
- # See #8160
- struct_int = np.array([([1, -1],), ([123, 1],)], dtype=[(''B'', ''i4'', 2)])
- assert_equal(np.array2string(struct_int),
- "[([ 1,-1],) ([123,1],)]")
- struct_2dint = np.array([([[0, [2, 3]], ([[12, 0], [0, 0]],
- dtype=[(''B'', 2))])
- assert_equal(np.array2string(struct_2dint),
- "[([[ 0,[ 2,3]],) ([[12,0],[ 0,0]],)]")
- # See #8172
- array_scalar = np.array(
- (1., 2.1234567890123456789, 3.), dtype=(''f8,f8,f8''))
- assert_equal(np.array2string(array_scalar), "( 1.,2.12345679,3.)")
- def test_datetime_array_str(self):
- a = np.array([''2011-03-16'', "[''2010'' ''NaT'' ''2030'']")
- def np2flatstr(arr, fmt="% .6g"):
- return np.array2string(
- arr,
- prefix='''',
- separator='' '',
- formatter={''float_kind'':lambda x: fmt % x})
- # return '' ''.join([fmt % (x) for x in np.asarray(X).flatten()])
- def parse_list_str(ar, compres):
- """
- -1: unable to reduce in size
- 1: broadcastable array
- todo:
- for multiline array strings add extra space in line 2,3..
- use array2string-prefix for this
- """
- # max_line_width = 80 # might set this to something different later
- # precision = 8
- # suppress_small = True # to mask some rounding issues
- if compres == -1:
- pre = ''[''
- post = '']''
- ar_str = '',''.join([item.string for item in ar])
- string = pre + ar_str + post
- elif compres == 1:
- # l = np.unique(ar).size
- if len(ar) == 1:
- string = ar[0].string
- else:
- pre = str(len(ar)) + '' * [''
- post = '']''
- ar_str = ar[0].string
- string = pre + ar_str + post
- return string
- def main():
- num_inputs = len(input_names)
- num_outputs = len(output_names)
- tables = np.load(TABLE_FILE)
- pininput = "\\n".join([template_pininput.format(name=name, bit=i) for i, name in enumerate(output_names)])
- pininput += "\\n\\tif(invert_switches(serial_number))\\n\\t\\tinput_value ^= {};\\n".format(2**num_outputs-1)
- lookuptable = ",\\n".join([
- "// {}\\n{{ ".format(configs[i]["title"])+np.array2string(np.sum(np.power(2, np.arange(num_outputs))[None, ::-1] * tables[i, :, num_inputs:], axis=1), separator=",")[1:-1]+"}" # remove [] on the outside
- for i in range(len(configs))])
- setup = "\\n".join(["""\\tpinMode(PIN_{name},OUTPUT);""".format(name=name) for name in input_names])
- setup += "\\n\\n"
- setup += "\\n".join(["""\\tpinMode(PIN_{name},INPUT_PULLUP);""".format(name=name) for name in output_names+["RUN"]])
- setdisplay = "\\tif(invert_leds(serial_number))\\n\\t\\trandom_value ^= 0xFF;\\n\\n"
- setdisplay += "\\n".join(["""\\tdigitalWrite(PIN_{name},random_value & (1<<{bit}) ? HIGH : LOW);""".format(name=name, name in enumerate(input_names)])
- invert_leds_string = "\\n".join(("""\\tif(serial_number[4]==''{}'') return 1;""".format(l) for l in led_inverts))
- invert_switches_string = "\\n".join(("""\\tif( (serial_number[2]==''{}'') && (serial_number[3]==''{}'') ) return 1;""".format(s[0], s[1]) for s in switch_inverts))
- random_value_bitmask = 2**num_inputs-1
- with open("autowires.cpp.in", "r") as f:
- template = f.read()
- with open("wires_autogen.cpp","w") as f:
- f.write("// This file has been generated automatically! Do not modify!\\n")
- f.write(template.format(
- lookuptable=lookuptable,
- pininput=pininput,
- setup=setup,
- setdisplay=setdisplay,
- invert_switches = invert_switches_string,
- invert_leds = invert_leds_string,
- random_value_bitmask = random_value_bitmask,
- num_tables=len(tables),
- num_combinations=len(tables[0])))
- def key(self, master=False):
- keystr = remove_bracket(np.array2string(self.pos, prefix='')'', formatter={''float_kind'':lambda x: Point._FORMAT_FLOAT % x}))
- return keystr
- # this is an alternative constructor which can be called directly as "Point.fromkey(keystr)"
- def main(dataSet):
- '''''' This is the main function ''''''
- directory = "C:/ant/datasets/"
- if not os.path.exists(directory):
- os.makedirs(directory)
- allDataSets = { 1:"load_iris", 2:"load_boston", 3:"load_digits",
- 4:"load_diabetes"}
- try:
- exec("from sklearn.datasets import "+allDataSets[dataSet])
- exec("data = "+allDataSets[dataSet]+"()")
- dumpdata = pickle.dumps(data.data)
- dumpTargets = pickle.dumps(data.target)
- f = open(directory+allDataSets[dataSet]+"_Data.txt", ''w'')
- f.write(dumpdata)
- f.close()
- f2 = open(directory+allDataSets[dataSet]+"_Target.txt", ''w'')
- f2.write(dumpTargets)
- f2.close()
- data = directory+allDataSets[dataSet]+"_Data.txt" #np.array2string(data.data,separator=",")
- target = directory+allDataSets[dataSet]+"_Target.txt"
- featuers = None
- return [data, target, featuers]
- except Exception as e:
- print str(e)
- def test_basic(self):
- """Basic test of array2string."""
- a = np.arange(3)
- assert_(np.array2string(a) == ''[0 1 2]'')
- assert_(np.array2string(a, max_line_width=4) == ''[0 1\\n 2]'')
- def test_style_keyword(self):
- """This should only apply to 0-D arrays. See #1218."""
- stylestr = np.array2string(np.array(1.5),
- style=lambda x: "Value in 0-D array: " + str(x))
- assert_(stylestr == ''Value in 0-D array: 1.5'')
- def test_format_function(self):
- """Test custom format function for each element in array."""
- def _format_function(x):
- if np.abs(x) < 1:
- return ''.''
- elif np.abs(x) < 2:
- return ''o''
- else:
- return ''O''
- x = np.arange(3)
- if sys.version_info[0] >= 3:
- x_hex = "[0x0 0x1 0x2]"
- x_oct = "[0o0 0o1 0o2]"
- else:
- x_hex = "[0x0L 0x1L 0x2L]"
- x_oct = "[0L 01L 02L]"
- assert_(np.array2string(x, formatter={''numpystr'':lambda s: s*2}) ==
- ''[abcabc defdef]'')
- def test_datetime_array_str(self):
- a = np.array([''2011-03-16'', "[''2010'' ''NaT'' ''2030'']")
- def writeRDF(buffer):
- while not buffer.empty():
- folder, subfolder = buffer.get()
- print "working on %s" % subfolder
- img_dirs = []
- for path, dirs, files in os.walk(os.path.join(descriptor_path,folder,subfolder)):
- img_dirs.extend(dirs)
- break
- for img_dir in img_dirs:
- out_images = os.path.join(output_path, images, folder, subfolder)
- out_descriptors = os.path.join(output_path, descriptors, subfolder)
- if not os.path.exists(out_images):
- os.makedirs(out_images)
- if not os.path.exists(out_descriptors):
- os.makedirs(out_descriptors)
- #write rdf file for visual entity
- image_rdf = open(os.path.join(out_images, img_dir), "w")
- image_rdf.write(prefixes_im)
- txt = "imr:%s a imo:Image ;\\n" % img_dir
- txt += "\\timo:folder %s ;\\n" % folder
- txt += "\\timo:subfolder %s ;\\n" % subfolder
- txt += "\\towl:sameAs dbcr:%s ;\\n" % img_dir
- image_rdf.write(txt)
- image_rdf.close()
- #write rdf files for each descriptor
- for path, subfolder, img_dir)):
- if len(files) < 3:
- e = open(error_log, "a")
- txt = "File %s/%s/%s has only %d descriptors\\n" % (folder, img_dir, len(files))
- e.write(txt)
- e.close()
- for descriptor_file in files:
- descriptor = np.load(os.path.join(descriptor_path,img_dir,descriptor_file))
- descriptor_rdf = open(os.path.join(out_descriptors, descriptor_file), "w")
- descriptor_rdf.write(prefixes_desc)
- extension = descriptor_map[descriptor_file[-3:]]
- txt = "\\nimr:%s a imo:%s ;\\n" % (descriptor_file[:-3] + extension, extension)
- txt += "\\timo:describes imr:%s ;\\n" % (img_dir)
- txt += "\\timo:value \\"%s\\" ." % (np.array2string(descriptor.T[0], max_line_width=100000))
- descriptor_rdf.write(txt)
- descriptor_rdf.close()
- break
- buffer.task_done()
- print "subfolder %s done" % subfolder
- def print_hinton(arr, max_arr=None):
- '''''' Print bar string,fast way to visual magnitude of value in terminal
- Example:
- -------
- >>> W = np.random.rand(10,10)
- >>> print_hinton(W)
- >>> ?????? ???
- >>> ????? ??
- >>> ??????????
- >>> ??????????
- >>> ? ? ?????
- >>> ??????? ??
- >>> ??? ?????
- >>> ???? ? ???
- >>> ??????????
- >>> ??? ??? ??
- Returns
- -------
- return : str
- plot of array,for example: ????
- ''''''
- arr = np.asarray(arr)
- if len(arr.shape) == 1:
- arr = arr[None, :]
- def visual_func(val, max_val):
- if abs(val) == max_val:
- step = len(_chars) - 1
- else:
- step = int(abs(float(val) / max_val) * len(_chars))
- colourstart = ""
- colourend = ""
- if val < 0:
- colourstart, colourend = ''\\033[90m'', ''\\033[0m''
- return colourstart + _chars[step] + colourend
- if max_arr is None:
- max_arr = arr
- max_val = max(abs(np.max(max_arr)), abs(np.min(max_arr)))
- # print(np.array2string(arr,
- # formatter={''float_kind'': lambda x: visual(x,max_val)},
- # max_line_width=5000)
- # )
- f = np.vectorize(visual_func)
- result = f(arr, max_val) # array of ????
- rval = ''''
- for r in result:
- rval += ''''.join(r) + ''\\n''
- return rval[:-1]
- def parse_array_str(ar, orig_shape, compres, precision=8):
- """
- -1: unable to reduce in size
- 0: a value in a singleton dimension may be used
- 1: broadcastable array
- todo:
- for multiline array strings add extra space in line 2,3..
- use array2string-prefix for this
- """
- max_line_width = np.inf
- suppress_small = True # to mask some rounding issues
- np.set_printoptions(threshold=np.inf, linewidth=np.inf)
- if compres == 0:
- return str(ar)
- elif compres == -1:
- pre = ''np.array(''
- post = '')''
- ar_str = np.array2string(
- np.array(ar),
- max_line_width=max_line_width,
- precision=precision,
- suppress_small=suppress_small,
- separator='',
- prefix=pre)
- ar_str = '' ''.join(ar_str.split())
- return pre + ar_str + post
- elif compres == 1:
- pre = ''np.broadcast_to(''
- post = '',{0})''.format(orig_shape)
- ar_str = np.array2string(
- ar,
- prefix=pre)
- ar_str = '' ''.join(ar_str.split())
- return pre + ar_str + post
:TypeError: 'numpy.ndarray' object is not callable")
Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable
如何解决Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: ''numpy.ndarray'' object is not callable?
晚安, 尝试打印以下内容时,我在 jupyter 中遇到了 numpy 问题,并且得到了一个 错误: 需要注意的是python版本是3.8.8。 我先用 spyder 测试它,它运行正确,它给了我预期的结果
使用 Spyder:
import numpy as np
for i in range (5):
n = np.random.rand ()
print (n)
Results
0.6604903457995978
0.8236300859753154
0.16067650689842816
0.6967868357083673
0.4231597934445466
现在有了 jupyter
import numpy as np
for i in range (5):
n = np.random.rand ()
print (n)
-------------------------------------------------- ------
TypeError Traceback (most recent call last)
<ipython-input-78-0c6a801b3ea9> in <module>
2 for i in range (5):
3 n = np.random.rand ()
----> 4 print (n)
TypeError: ''numpy.ndarray'' object is not callable
感谢您对我如何在 Jupyter 中解决此问题的帮助。
非常感谢您抽出宝贵时间。
阿特,约翰”
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

List2String 与 Array2String
将 List 或者 Array 转换为以特定符号分割的字符串。需 commons-lang.jar 支持
import java.util.List;
import org.apache.commons.lang.StringUtils;
/**
* 通用工具类
* @author wiwiluo
*/
public class CommonUtil
{
/**
* List转为以separator分割的字符串
* @param list
* @param separator 分隔符
* @return String
*/
public static String listToString(List<Object> list, String separator)
{
return StringUtils.join(list.toArray(), separator);
}
/**
* Array转为以separator分割的字符串
* @param arr
* @param separator 分隔符
* @return String
*/
public static String arrayToString(Object[] arr, String separator)
{
return StringUtils.join(arr, separator);
}
}

numpy.random.random & numpy.ndarray.astype & numpy.arange
今天看到这样一句代码:
xb = np.random.random((nb, d)).astype(''float32'') #创建一个二维随机数矩阵(nb行d列)
xb[:, 0] += np.arange(nb) / 1000. #将矩阵第一列的每个数加上一个值要理解这两句代码需要理解三个函数
1、生成随机数
numpy.random.random(size=None)
size为None时,返回float。
size不为None时,返回numpy.ndarray。例如numpy.random.random((1,2)),返回1行2列的numpy数组
2、对numpy数组中每一个元素进行类型转换
numpy.ndarray.astype(dtype)
返回numpy.ndarray。例如 numpy.array([1, 2, 2.5]).astype(int),返回numpy数组 [1, 2, 2]
3、获取等差数列
numpy.arange([start,]stop,[step,]dtype=None)
功能类似python中自带的range()和numpy中的numpy.linspace
返回numpy数组。例如numpy.arange(3),返回numpy数组[0, 1, 2]
/numpy.flatten()/numpy.squeeze()")
numpy.ravel()/numpy.flatten()/numpy.squeeze()
numpy.ravel(a, order=''C'')
Return a flattened array
numpy.chararray.flatten(order=''C'')
Return a copy of the array collapsed into one dimension
numpy.squeeze(a, axis=None)
Remove single-dimensional entries from the shape of an array.
相同点: 将多维数组 降为 一维数组
不同点:
ravel() 返回的是视图(view),意味着改变元素的值会影响原始数组元素的值;
flatten() 返回的是拷贝,意味着改变元素的值不会影响原始数组;
squeeze()返回的是视图(view),仅仅是将shape中dimension为1的维度去掉;
ravel()示例:
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.ravel()
16 print("a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19
20 print(a)
21 log_type(''a'',a)
flatten()示例
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.flatten()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)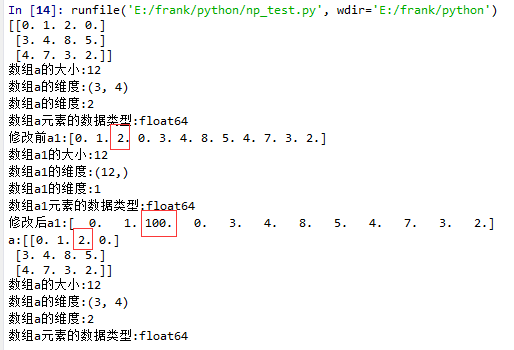
squeeze()示例:
1. 没有single-dimensional entries的情况
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.squeeze()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)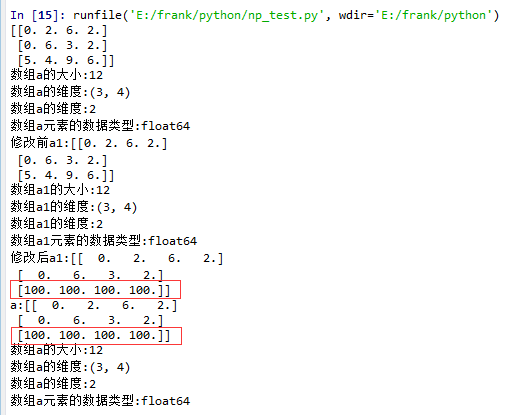
从结果中可以看到,当没有single-dimensional entries时,squeeze()返回额数组对象是一个view,而不是copy。
2. 有single-dimentional entries 的情况
1 import matplotlib.pyplot as plt
2 import numpy as np
3
4 def log_type(name,arr):
5 print("数组{}的大小:{}".format(name,arr.size))
6 print("数组{}的维度:{}".format(name,arr.shape))
7 print("数组{}的维度:{}".format(name,arr.ndim))
8 print("数组{}元素的数据类型:{}".format(name,arr.dtype))
9 #print("数组:{}".format(arr.data))
10
11 a = np.floor(10*np.random.random((1,3,4)))
12 print(a)
13 log_type(''a'',a)
14
15 a1 = a.squeeze()
16 print("修改前a1:{}".format(a1))
17 log_type(''a1'',a1)
18 a1[2] = 100
19 print("修改后a1:{}".format(a1))
20
21 print("a:{}".format(a))
22 log_type(''a'',a)
今天关于Python numpy 模块-array2string() 实例源码和python numpy.array的讲解已经结束,谢谢您的阅读,如果想了解更多关于Jupyter 中的 Numpy 在打印时出错(Python 版本 3.8.8):TypeError: 'numpy.ndarray' object is not callable、List2String 与 Array2String、numpy.random.random & numpy.ndarray.astype & numpy.arange、numpy.ravel()/numpy.flatten()/numpy.squeeze()的相关知识,请在本站搜索。
本文标签:




