如果您想了解在GPU上使用tensorflow以及在相同代码中使用numpy数组:内存开销延迟?的相关知识,那么本文是一篇不可错过的文章,我们将为您提供关于1.15之后的Tensorflow-无需安装
如果您想了解在 GPU 上使用 tensorflow 以及在相同代码中使用 numpy 数组:内存开销延迟?的相关知识,那么本文是一篇不可错过的文章,我们将为您提供关于1.15 之后的 Tensorflow - 无需安装 tensorflow-gpu 包、@tensorflow/tfjs-node-gpu 适用于 NVIDIA P4,但在 GKE 上使用 V100 失败、Choiche GPU tensorflow-directml 或 multi-gpu、gpu 机器安装 nvidia-smi 和 python 的 tensorflow-gpu 模块的有价值的信息。
本文目录一览:- 在 GPU 上使用 tensorflow 以及在相同代码中使用 numpy 数组:内存开销延迟?
- 1.15 之后的 Tensorflow - 无需安装 tensorflow-gpu 包
- @tensorflow/tfjs-node-gpu 适用于 NVIDIA P4,但在 GKE 上使用 V100 失败
- Choiche GPU tensorflow-directml 或 multi-gpu
- gpu 机器安装 nvidia-smi 和 python 的 tensorflow-gpu 模块

在 GPU 上使用 tensorflow 以及在相同代码中使用 numpy 数组:内存开销延迟?
如何解决在 GPU 上使用 tensorflow 以及在相同代码中使用 numpy 数组:内存开销延迟?
我正在使用 tf.signal.fft 通过张量流计算傅立叶变换。我已成功安装 tensorflow-gpu 并拥有适合我的代码的正确驱动程序和版本,以便实际使用支持 CUDA 的 GPU。事实上,我可以检查 GPU 是否正在被使用(尽管总是在 1-2% 左右,但其内存通常为 80%)。
我正在求解一个带有 Fourier split-step method 的偏微分方程,其中每个时间增量看起来像 psi(t+dt) = InverseFourier [ potential(t) * Fourier( psi(t) ) ]。
虽然 InverseFourier 和 Fourier 是张量流方法,但 potential 只是一个 numpy 数组,每一步都需要计算。我现在的疑问是:这个 numpy 计算真的在 cpu 上运行吗?因此,在 GPU 被运载之前,必须将阵列从 RAM 移至 GPU 内存。也许这会导致开销并因此导致时间延迟?
我完全错了吗?有没有办法检查开销时间?我应该用 tensorflow 函数做所有事情吗?

1.15 之后的 Tensorflow - 无需安装 tensorflow-gpu 包
如何解决1.15 之后的 Tensorflow - 无需安装 tensorflow-gpu 包
问题
请确认在 TensorFlow1.15 之后要同时使用 cpu 和 GPU,安装 tensorflow 包就足够了,tensorflow-gpu 就不用了需要。
背景
仍然看到说明要安装 tensorflow-gpu 的文章,例如pip install tensorflow-gpu==2.2.0 和 PyPi repository for tensorflow-gpu package 使用最新的 tensorflow-gpu 2.4.1。
Annaconda 文档还引用了 tensorflow-gpu 包。
- Working with GPU packages - Available packages - TensorFlow
TensorFlow 是一个通用的机器学习库,但最常用于深度学习应用。 Anaconda 中支持三种 tensorflow 包变体,其中之一是 NVIDIA GPU 版本。这是通过安装元包tensorflow-gpu来选择的:
但是,根据 TensorFlow v2.4.1(截至 2021 年 4 月)核心文档 GPU support - Older versions of TensorFlow
对于 1.15 及更早版本,cpu 和 GPU 包是分开的:
pip install tensorflow==1.15 # cpupip install tensorflow-gpu==1.15 # GPU
根据 TensorFlow 核心指南 Use a GPU。
TensorFlow 代码和 tf.keras 模型将透明地在单个 GPU 上运行,无需更改代码。
根据Difference between installation libraries of TensorFlow GPU vs CPU。
只是一个简短的(不必要的?)注意...从 TensorFlow 2.0 开始,这些没有分开,您只需安装 tensorflow(因为如果您安装了适当的卡/CUDA,这包括 GPU 支持)。
因此想要明确确认 tensorflow-gpu 包只是为了方便(指定了 tensorflow-gpu 等的旧脚本),不再需要。 tensorflow 和 tensorflow-gpu 包现在没有区别了。
解决方法
在这里对包命名感到困惑是合理的。然而,这是我的理解。对于 tf 1.15 或 older,CPU 和 GPU 包是分开的:
pip install tensorflow==1.15 # CPUpip install tensorflow-gpu==1.15 # GPU
因此,如果我想完全在 CPU 的 tf 版本上工作,我会使用第一个命令,否则,如果我想完全在 GPU 版本上工作tf,我会使用第二个命令。
现在,在 tf 2.0 或更高版本中,我们只需要一个命令即可方便地在两种硬件上运行。因此,在基于CPU和GPU的系统中,我们需要相同的命令来安装tf,即:
pip install tensorflow
现在,我们可以在基于 CPU 的系统上对其进行测试 (no GPU)
import tensorflow as tfprint(tf.__version__)print(''1: '',tf.config.list_physical_devices(''GPU''))print(''2: '',tf.test.is_built_with_cuda)print(''3: '',tf.test.gpu_device_name())print(''4: '',tf.config.get_visible_devices())2.4.11: []2: <function is_built_with_cuda at 0x7f2ce91415f0>3:4: [PhysicalDevice(name=''/physical_device:CPU:0'',device_type=''CPU'')]
或者也在基于 CPU 的系统上进行测试(with GPU)
2.4.11: [PhysicalDevice(name=''/physical_device:GPU:0'',device_type=''GPU'')]2: <function is_built_with_cuda at 0x7fb6affd0560>3: /device:GPU:04: [PhysicalDevice(name=''/physical_device:CPU:0'',device_type=''CPU''),PhysicalDevice(name=''/physical_device:GPU:0'',device_type=''GPU'')]
因此,如您所见,这只是用于 CPU 和 GPU 情况的单个命令。希望现在更清楚了。但是直到现在(在 tf > = 2 中)我们还可以在安装 -gpu / -cpu 时使用 tf 后缀,分别巧妙地用于 GPU / CPU。
!pip install tensorflow-gpu....Installing collected packages: tensorflow-gpuSuccessfully installed tensorflow-gpu-2.4.1# -------------------------------------------------------------!pip install tensorflow-cpu....Installing collected packages: tensorflow-cpuSuccessfully installed tensorflow-cpu-2.4.1

@tensorflow/tfjs-node-gpu 适用于 NVIDIA P4,但在 GKE 上使用 V100 失败
如何解决@tensorflow/tfjs-node-gpu 适用于 NVIDIA P4,但在 GKE 上使用 V100 失败
我的 tfjs-node-gpu 代码在 GKE 上的 NVIDIA p4 上运行良好(并在浏览器中使用 WebGL),但在 v100 和 t4 上运行失败。
节点在我的预热中的第一个预测调用中崩溃。我正在使用 128x128 的小块来预测 4 倍图像的放大,使用理想的甘斯。 v100 初始化正常,显示为 nvidia_smi,显示为 TF 设备,NUMA 内容一切正常。它只是使我的节点快速服务器崩溃。我无法找到崩溃堆栈,因为这是在 Docker 容器中启动的,而我最后一次尝试从 stderr 记录崩溃失败。
我已经尝试过最新的 tfjs-node-gpu 3.0 和 2.8.5。 GKE 配置为安装 NV 驱动程序,目前为 410.104 和 CUDA 10.0。
我尝试启用调试模式,并将 {verbose: true} 传递给我的预热函数中失败的 model.predict() 调用。都没有在预热调用中添加任何输出,这很奇怪,因为我确实在对 model.predict()
关于如何进一步调试的任何建议?

Choiche GPU tensorflow-directml 或 multi-gpu
如何解决Choiche GPU tensorflow-directml 或 multi-gpu
我正在 Windows PC 上使用 tensorflow 训练模型,但训练量很低,所以我正在尝试将 tensorflow 配置为使用 GPU。 我安装了 tensorflow-directml(在 python 3.6 的 conda 环境中),因为我的 GPU 是 AMD Radeon GPU。 用这个简单的代码
import tensorflow as tf
tf.test.is_gpu_available()
我收到此输出
2021-05-14 11:02:30.113880:我 tensorflow/core/platform/cpu_feature_guard.cc:142] 你的 cpu 支持 此 TensorFlow 二进制文件未编译为使用的说明:AVX2 2021-05-14 11:02:30.121580:我 张量流/stream_executor/platform/default/dso_loader.cc:99] 成功打开动态库 C:\\Users\\v.rocca\\anaconda3\\envs\\tfradeon\\lib\\site-packages\\tensorflow_core\\python/directml.adbd007a01a52364381a1c71ebb6fa1b2389c88d.dll 2021-05-14 11:02:30.765470:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:249] DirectML 设备枚举:找到 2 个兼容的适配器。 2021-05-14 11:02:30.984834:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:185] DirectML: 在适配器 0 上创建设备(Radeon (TM) 530)2021-05-14 11:02:31.150992:我 张量流/stream_executor/platform/default/dso_loader.cc:99] 成功打开动态库Kernel32.dll 2021-05-14 11:02:31.174716:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:185] DirectML: 在适配器 1 上创建设备(Intel(R) UHD Graphics 620)True
因此,tensorflow 使用 Intel 的集成 GPU 而不是 Radeon GPU。 如果我从管理硬件中禁用英特尔 GPU,我会在输出中收到正确的 GPU
2021-05-14 10:47:09.171568:我 tensorflow/core/platform/cpu_feature_guard.cc:142] 你的 cpu 支持 此 TensorFlow 二进制文件未编译为使用的说明:AVX2 2021-05-14 10:47:09.176828:我 张量流/stream_executor/platform/default/dso_loader.cc:99] 成功打开动态库 C:\\Users\\v.rocca\\anaconda3\\envs\\tfradeon\\lib\\site-packages\\tensorflow_core\\python/directml.adbd007a01a52364381a1c71ebb6fa1b2389c88d.dll 2021-05-14 10:47:09.421265:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:249] DirectML 设备枚举:找到 1 个兼容的适配器。 2021-05-14 10:47:09.626567:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:185] DirectML: 在适配器 0 上创建设备(Radeon (TM) 530)
我不想每次都禁用英特尔 GPU,所以这是我的问题。 是否可以选择我想使用的 GPU?或者是否可以同时使用两个 GPU? 谢谢
解决方法
来自Microsoft:
gpu_config = tf.GPUOptions()
gpu_config.visible_device_list = "1"
session = tf.Session(config=tf.ConfigProto(gpu_options=gpu_config))

gpu 机器安装 nvidia-smi 和 python 的 tensorflow-gpu 模块
os: ubuntu14.04.4
python: 2.7.13
tensorflow-gpu: 1.4.1
cuda: 8.0.44-1
cudnn: cudnn-8.0-linux-x64-v6.0-tgz
1. 安装支持 gpu 设置的 tensorflow-gpu
pip install tensorflow-gpu==1.4.1 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2. 安装 cuda
dpkg -i cuda-repo-ubuntu1404_10.0.130-1_amd64.deb
apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1404/x86_64/7fa2af80.pub
apt-get update
apt-get install cuda=8.0.44-1安装完 cuda,就有 nvidia-smi 命令可以在 shell 命令行查看 gpu 设备。因为 nvidia-418、nvidia-418-dev 这 2 个已经被当成依赖安装完成了。
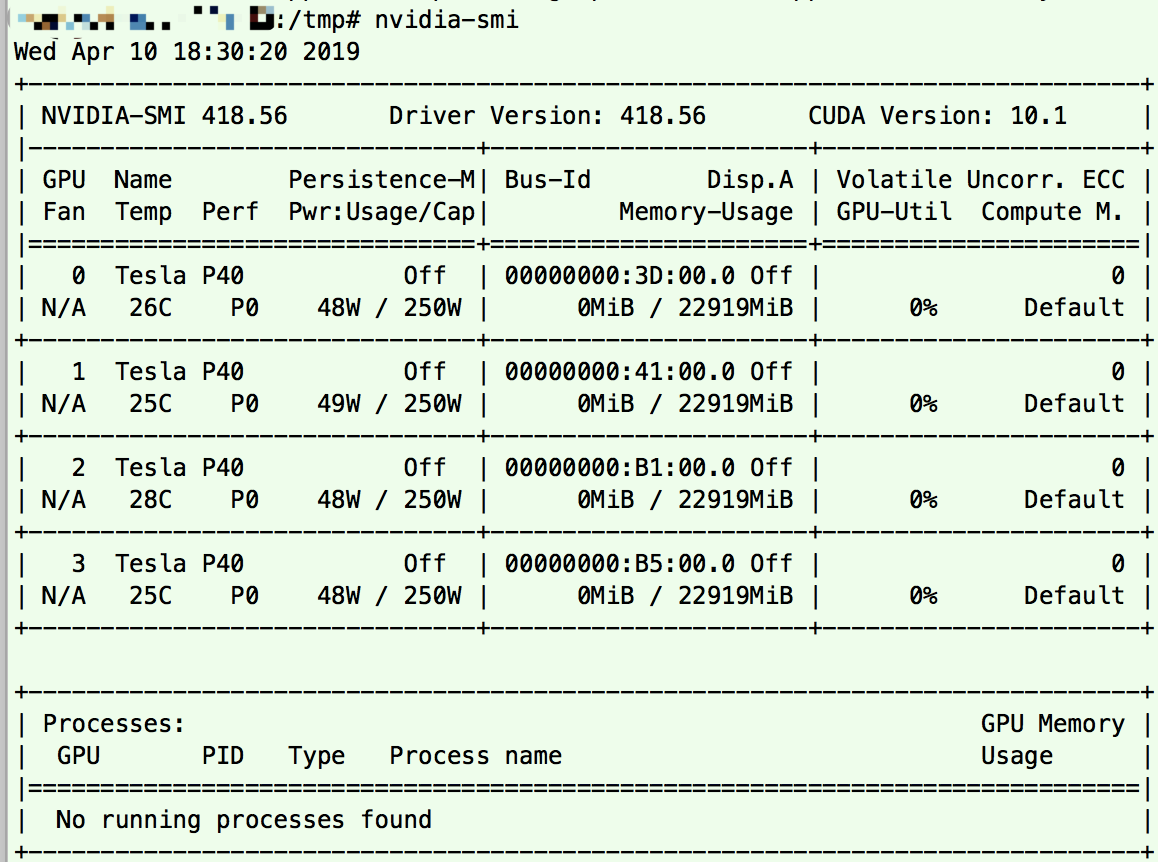
当时因为碰到这个问题 https://devtalk.nvidia.com/default/topic/1048630/b/t/post/5322060/
解决思路来自 https://developer.nvidia.com/cuda-10.0-download-archive 选择操作系统、版本,下载 cuda-repo-ubuntu1404_10.0.130-1_amd64.deb。
3. 安装 cudnn
因为 libcudnn.so.6: cannot open shared object file: No such file or directory 这个报错
google 了一圈发现, 问题出在 TensorFlow 1.4-gpu 是基于 cuDNN6,需要的也就是 libcudnn.so.6 了。
解决方案:
到官网 https://developer.nvidia.com/cudnn 下载相应的 cudnn 库
tar xvzf cudnn-8.0-linux-x64-v6.0.tgz
cp -P cuda/include/cudnn.h /usr/local/cuda/include
cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
Now set Path variables
$ vim ~/.bashrc
翻到最底部加上:
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME=/usr/local/cuda
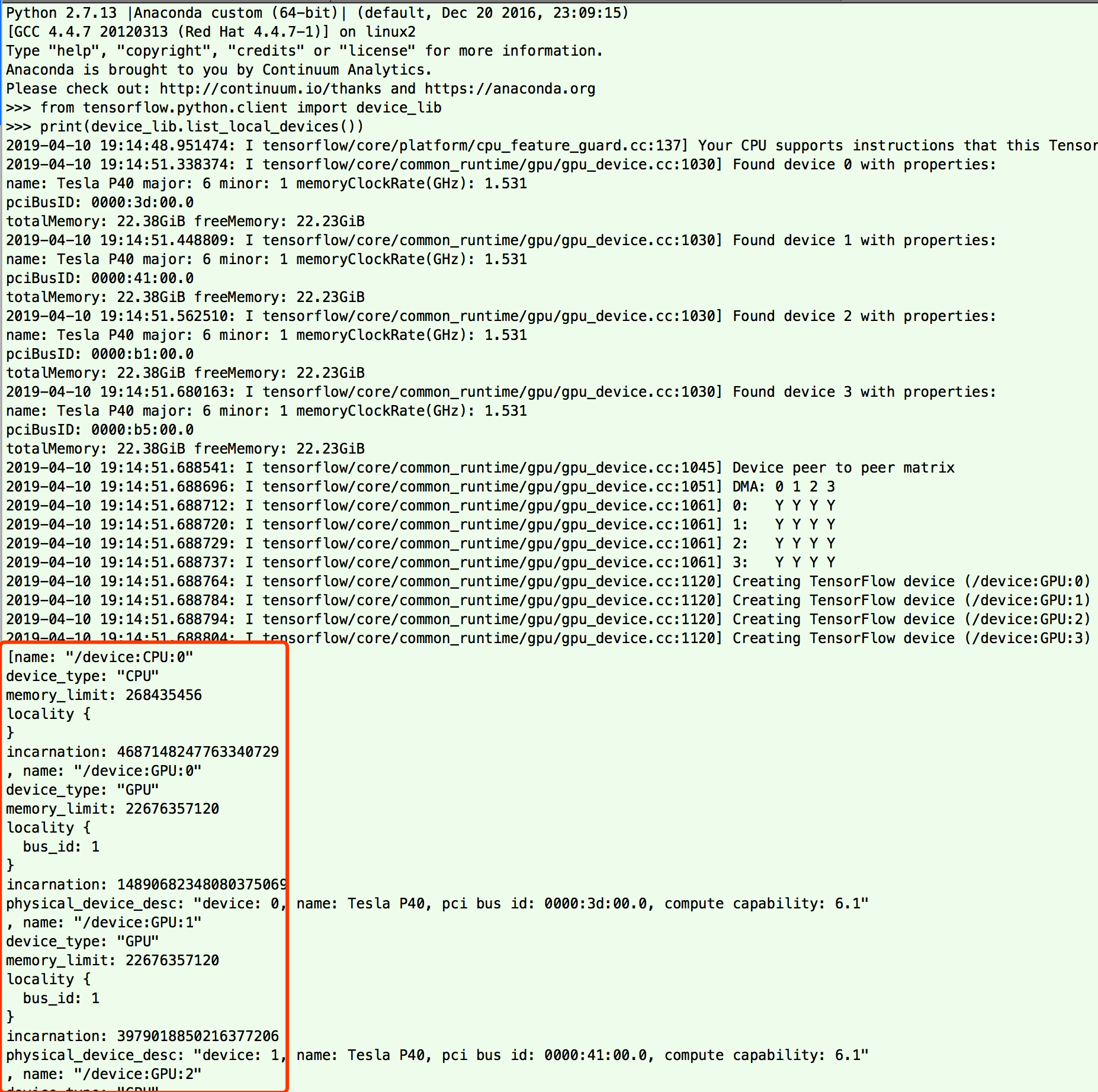
最后进去 python 命令行
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
看看输出信息有没有显示 GPU 设备
另外如果 nvidia-smi 碰到以下报错,可以尝试重启 (反正我是这么解决的。。)
Failed to initialize NVML: Driver/library version mismatch
今天关于在 GPU 上使用 tensorflow 以及在相同代码中使用 numpy 数组:内存开销延迟?的介绍到此结束,谢谢您的阅读,有关1.15 之后的 Tensorflow - 无需安装 tensorflow-gpu 包、@tensorflow/tfjs-node-gpu 适用于 NVIDIA P4,但在 GKE 上使用 V100 失败、Choiche GPU tensorflow-directml 或 multi-gpu、gpu 机器安装 nvidia-smi 和 python 的 tensorflow-gpu 模块等更多相关知识的信息可以在本站进行查询。
本文标签:




