在本文中,我们将给您介绍关于NumPy-任何dtype数组的降序稳定arg-sort的详细内容,并且为您解答数组降序排列python的相关问题,此外,我们还将为您提供关于"importnumpyasn
在本文中,我们将给您介绍关于NumPy-任何dtype数组的降序稳定arg-sort的详细内容,并且为您解答数组降序排列python的相关问题,此外,我们还将为您提供关于"import numpy as np" ImportError: No module named numpy、5.4 (Java学习笔记)集合的排序(Collections.sort(),及Arrays.sort())、C# bubble sort,selection sort,insertion sort、C++ sort(STL sort)排序算法详解的知识。
本文目录一览:- NumPy-任何dtype数组的降序稳定arg-sort(数组降序排列python)
- "import numpy as np" ImportError: No module named numpy
- 5.4 (Java学习笔记)集合的排序(Collections.sort(),及Arrays.sort())
- C# bubble sort,selection sort,insertion sort
- C++ sort(STL sort)排序算法详解
")
NumPy-任何dtype数组的降序稳定arg-sort(数组降序排列python)
如何解决NumPy-任何dtype数组的降序稳定arg-sort
NumPy的np.argsort可以通过传递function getAllTimeZones(){
$selectOptions = "";
foreach(\\DateTimeZone::listIdentifiers() as $zoneLabel)
{
$currentTimeInZone = new \\DateTime("Now",new \\DateTimeZone($zoneLabel));
$currentTimeDiff = $currentTimeInZone->format(''P'');
$selectOptions .= "<option value=\\"$zoneLabel\\">(GMT $currentTimeDiff) $zoneLabel</option>\\n";
}
return $selectOptions;
}
参数来完成stable sorting。
kind = ''stable''也不支持倒序(降序)。
如果需要不稳定的行为,则可以通过np.argsort轻松地对降序建模。
我正在寻找一种高效/简便的解决方案,以解决任何可比较的desc_ix = np.argsort(a)[::-1]的降序稳定NumPy数组a。在最后一段中看到我的“稳定性”的意思。
对于dtype是任何数字的情况,可以通过对数组求反的形式轻松地进行稳定的arg降序排序:
dtype
但是我需要支持任何可比较的print(np.argsort(-np.array([1,2,3,3]),kind = ''stable''))
# prints: array([3,4,5,1,0],dtype=int64)
,包括dtype和np.str_。
仅出于说明目的-也许是降序排列,np.object_的经典含义表示从右到左枚举相等的元素。如果是这样,那么在我的问题中stable的含义有所不同-元素的相等范围应从左到右枚举,而彼此之间的相等范围按降序排列。即应该像上面的最后一个代码一样实现相同的行为。即我想要稳定性,就像Python在下一个代码中实现的一样:
stable + descending
解决方法
我认为这个公式应该有效:
,
import numpy as npa = np.array([1,2,3,3])s = len(a) - 1 - np.argsort(a[::-1],kind=''stable'')[::-1]print(s)# [3 4 5 1 2 0]
我们可以利用np.unique(...,return_inverse=True)-
,
u,tags = np.unique(a,return_inverse=True)out = np.argsort(-tags,kind=''stable'')
一种最简单的解决方案是将任何dtype的排序后的唯一元素映射到升序整数,然后对负整数进行稳定的arg升序排序。
Try it online!
import numpy as npa = np.array([''a'',''b'',''c'',''c''])u = np.unique(a)i = np.searchsorted(u,a)desc_ix = np.argsort(-i,kind = ''stable'')print(desc_ix)# prints [3 4 5 1 2 0]

"import numpy as np" ImportError: No module named numpy
问题:没有安装 numpy
解决方法:
下载文件,安装
numpy-1.8.2-win32-superpack-python2.7
安装运行 import numpy,出现
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
import numpy
File "C:\Python27\lib\site-packages\numpy\__init__.py", line 153, in <module>
from . import add_newdocs
File "C:\Python27\lib\site-packages\numpy\add_newdocs.py", line 13, in <module>
from numpy.lib import add_newdoc
File "C:\Python27\lib\site-packages\numpy\lib\__init__.py", line 8, in <module>
from .type_check import *
File "C:\Python27\lib\site-packages\numpy\lib\type_check.py", line 11, in <module>
import numpy.core.numeric as _nx
File "C:\Python27\lib\site-packages\numpy\core\__init__.py", line 6, in <module>
from . import multiarray
ImportError: DLL load failed: %1 不是有效的 Win32 应用程序。原因是:python 装的是 64 位的,numpy 装的是 32 位的
重新安装 numpy 为:numpy-1.8.0-win64-py2.7
集合的排序(Collections.sort(),及Arrays.sort())")
5.4 (Java学习笔记)集合的排序(Collections.sort(),及Arrays.sort())
1.Comparable接口
这个接口顾名思义就是用于排序的,如果要对某些对象进行排序,那么该对象所在的类必须实现
Comparabld接口。Comparable接口只有一个方法CompareTo(),这个方法可以看做是指定的排序规则。
内置类已经实现了CompareTo方法,例如long
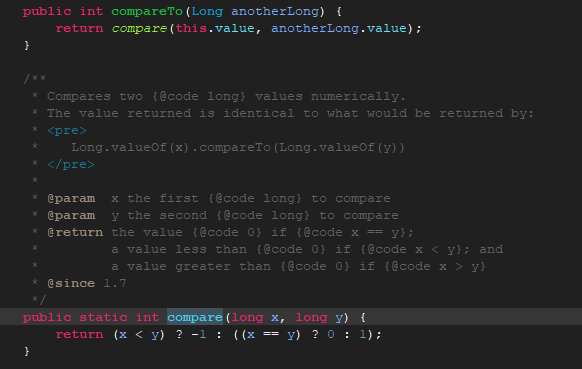
小于返回-1,等于返回0,大于返回1.
这里只举一个例子,例如int,double,Date等可以排序的内置类都已经实现了CompareTo方法,即指定了排序规则。
2.Collections.sort()和Arrays.sort()方法。
Colections是对集合进行操作的工具类,Collection.sort是对集合排序的方法。
Collections.sort()的底层实质是是调用Arrays.sort();
我们来看下Collections.sort()的源码:

首先传递进去的集合必须是Comparable接口及其子类,而且后续会用到Comparable接口中的CompareTo方法。所以进行排序的类必须实现Comparable,
可以看出如果没有实现Comparable接口,参数传递会出现错误。
我们点进list.sort()方法,就会看到下面代码:
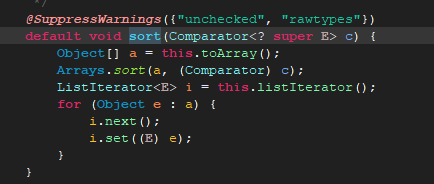
我们可以看到,它是先将集合转换成数组,然后调用Arrays.sort()方法。
排序排完后又将数组中元素逐个放入集合。
我们接下点进Arrays.sort()方法的源码:
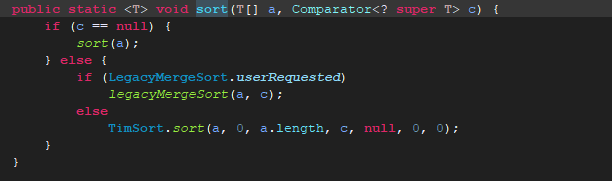
参数有两个,有一个之前转换成数组的集合a,c是一种排序规则,后面会讲到。没有指定的话,会自动设置为null。
然后判断是否有排序规则,有就调用使用排序规则的排序方法。这里看出当设置了排序规则c时,会进入使用排序规则的比较方法进行比较,
此时compareTo()是不起作用的,起作用的是排序规则c中的compare()方法。
接着进入sort().
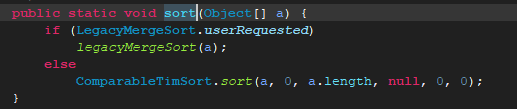
我们可以看到这里有两个排序算法,使用LegacyMergeSort.userRequested控制,第一个是归并排序,也就是LegacyMergeSort.userRequested为true时进入的语句,
注意默认状态下LegcyMergeSort是false,所以默认进去的是ComparableTimSort.sort()。这时一种优化的排序算法,有兴趣可以去查询下,当然这种算法比较复杂,
不便于理解。legactMergeSort()便于理解些,我们就先分析这个排序算法。
默认是进入ComparableTimSort(),要想进入legacyMergeSort()我们就需要设置下LegacyMergeSort.userRequested的值。
这时我们可以自己设置LegacyMergeSort.userRequested的值,这句话是加在main中Sort调用之前的。
System.setProperty("java.util.Arrays.useLegacyMergeSort", "true");设置为true后我们进入的就是legcyMergeSort();
/*
注意:
这里只是对排序算法的一种优化,排序时的规则是不变的的。
(例如我现在要进行升序排序,可以用很多算法,但是最后的结果一定是升序的。)
这里我们主要看CompareTo()方法返回值(1,0,-1)在排序中起到的作用,不关心具体算法的优化,有兴趣的可以自行查阅相关算法。
*/
那么我们这时就会进入gacyMergeSort();
我们点击该方法,看它的代码:
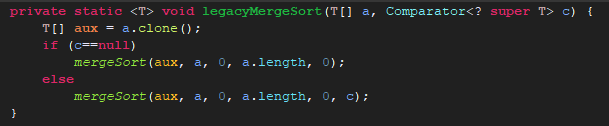
首先将存放集合数组的数组克隆,然后将克隆后的数组作为参数传递进aux,这里c为null进入第一个mergeSort();
进入mergeSort()我们可以看到:
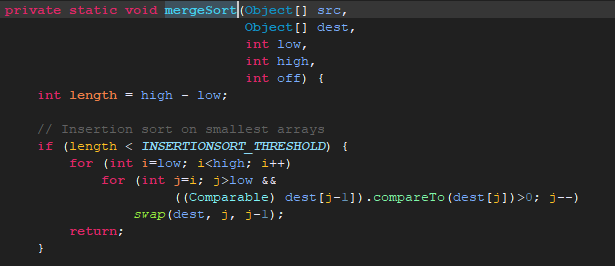
我们先看传递进去的参数,srt,dest都是存放数据的数组,str是克隆的数组,dest是原数组,low=0,high=数组长度,off = 0;
首先定义了一个legth = high - low,得到的其实也是数组长度,
一开始进行一个判断,长度小于INSERTIONSORT_THRESHOLD(常量7)就采用更适合长度小于7的数组的插入排序算法,
我们可以看到代码中排序的依据是CompareTo()的返回值,如果返回值大于0则交换位置,反之则不交换。
如果不小于则采用适合数组长度大于7的其他排序方法。
后面还有更适合数组长度大于7的算法,这里没有贴出这部分代码,有兴趣可自己去了解下。
(这里只是对排序算法执行次数的一种优化,排序时的规则是不变的的。我们这里主要看CompareTo方法起到作用,不关心排序算法的优化。)
这里我们举一个简单的例子,假设现在我在链表里面存放了三个long型数据312;
我们从调用Collections.Sort()方法开始分析源码执行的过程,理解CompareTo方法的作用。
进入mergeSort()方法后,我们先来看下传递进来的参数:
dest[] = {3,1,2}, low = 0, high = 3(数组长度);
接下来分析代码执行过程:
首先i=0,然后j = 0,不满足条件直接跳出,然后i++
此时i = 1,j=1,此时将元素转换为Comparable接口调用CompareTo方法根据之前看的long里面的Compare方法(Comparable)dest[0].compareTo(dest[1]) = 1.
如果没有实现Comparable接口,这里转型也会出现错误。
//调用ComparTo()返回值不清楚的,回到前面去看long里面CompareTo方法
交换dest[0],dest[1]位置,此时数组顺序:132.,然后j--,不满足循环条件直接跳出,执行i++。
此时i=2,j=2,(Comparable)dest[1].compareTo(dest[2]) = 1,交换dest[1],dest[2],此时数组顺序:123.执行i++;
i=3,不满足循环条件,退出执行retun,结束排序,最终数组顺序:123;
大家可以自己结合CompareTo方法的返回值分析分析排序过程。
了解了CompareTo在排序中起到的作用后,平常我们在实现Comparable接口,
实现其中的CompareTo方法时我们就可以明确CompareTo的返回值。
例如,a<b return 1.再结合CompareTo方法为1则交换位置,此时就是降序排列,
如果是a>b return 1,就变成升序。分析源码后我们可以自己分析排序到是升序还是降序。
我们也可以这样理解,如果返回1就代表交换这两个元素位置。
//一般情况下大于返回1,等于返回0,小于返回-1,更符合我们的思维习惯,这时排序是升序
建议一般情况下这样写,此时是升序,如果是要求降序排列,改变返回值,将a>b return -1就是降序了。
再次声明,要使用排序方法,必须实现Comparable接口。
我们来举一个具体的例子。例如新闻,我们首先要看时间降序(即最近发生的新闻出现在最前面),
其次按点击量降序(即点击量多的出现在前面)。
那么我们结合CompareTo方法在排序时的作用来考虑时间和点击量比较的返回值。
首先,最近发生的新闻排在前面,如果A新闻时间在B新闻时间后面(也就是A新闻发生的时间离我们最近),
越在后面的时间的数值越大,Date本质上也是一个long型数。那么最近发生的排在前面应该降序。也就是if(a时间> b时间)return -1;
对Date这一块理解有问题的,可参考https://www.cnblogs.com/huang-changfan/p/9495067.html
如果时间相同,我们再来考虑点击量,点击量大的排在前面。
那么这也是一个降序,if(点击量a > 点击量b) return -1;
这里也可以用之前如果返回1,就代表交换位置,-1就不交换位置这样来理解,理解的方式有很多种,
但归根结底都是对源码执行过程的分析,把握这一点就可以以不变应万变。
接下来我们来看具体的代码。
NewS类代码
import java.text.SimpleDateFormat;
import java.util.Date;
public class News implements Comparable<News>{
private String newsName;
private Date date;
private int click;
private String timeS;
public News(){}
public News(String newsName, Date date, int click){
setNewsName(newsName);
setDate(date);
setClick(click);
}
public String getNewsName() {
return newsName;
}
this.newsName = newsName;
}
return date;
}
this.date = date;
DateFormat china_time = new SimpleDateFormat("yyyy-MM-dd hh-mm-ss");
timeS = china_time.format(date);
}
public int getClick() {
return click;
}
this.click = click;
}
public int compareTo(News o) {
// TODO Auto-generated method stub
if(this.getDate().after(o.getDate()))//这句话就是如果this.getDate()的值 > o.getDate(),就降序排列。
return -1; //也可以理解为如果this.getDate()的值 >o.getDate(),则不交换位置,即降序。
if(this.getClick() > o.click)//如果this的点击数大于o的点击数则降序排列,即点击量大的排在前面
return -1; //如果this的点击量大于o的点击量,则不交换位置,即降序排列
return 1;
}
public String toString(){
return "标题:" + this.newsName + "时间" + timeS
+ "点击量" + this.click + "\n";
}
运行代码
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.Date;
import java.util.LinkedList;
import java.util.List;
public static void main(String[] args) {
List<News> newsList = new LinkedList<>();
newsList.add(new News("国庆高峰堵车,各景点爆满!",new Date(),1000));//设置为当前时间
newsList.add(new News("国庆仍有大部分家里蹲!",new Date(System.currentTimeMillis()-60*60*1000),100));//设置为当前时间前一小时
newsList.add(new News("惊呆,游客竟在做这种事!!!",new Date(),10000));//设置为当前时间,点击量10000
System.setProperty("java.util.Arrays.useLegacyMergeSort", "true");//设置为true进入legacySort()
System.out.println(newsList);
Collections.sort(newsList);
System.out.println(newsList);
}
}
运行结果:
//排序前新闻
[标题:国庆高峰堵车,各景点爆满!时间2018-10-07 09-23-53点击量1000
, 标题:国庆仍有大部分家里蹲!时间2018-10-07 08-23-54点击量100
, 标题:惊呆,游客竟在做这种事!!!时间2018-10-07 09-23-54点击量10000
]
//排序后新闻
[标题:惊呆,游客竟在做这种事!!!时间2018-10-07 09-23-54点击量10000
, 标题:国庆高峰堵车,各景点爆满!时间2018-10-07 09-23-53点击量1000
, 标题:国庆仍有大部分家里蹲!时间2018-10-07 08-23-54点击量100
]我们可以看到,首先按时间(距离我们最近发生的新闻排在最前面)进行排序,时间相同按点击量排序。
我们可以看出mergeSort中使用Compareto方法只是判断是否大于0,
当我们的CompareTo()返回的是0或-1时,for()语句中判断都是false,那么我们能否在返回时不要-1,只返回0,1呢?
在当前方法(LeacySort()中的mergeSort())显然是可以的,因为0 > 0,-1>0的结果是相同的。
你要确定你进去的是LeacySort()中的mergeSort(),最好设置如下语句:
System.setProperty("java.util.Arrays.useLegacyMergeSort", "true");如果没有设置的话LegcyMergeSort.userRequested默认为false,进去的就是另外一种排序算法,在另外一种算法中这样设置是不行的。
当默认为false时,我们进入另外一个算法看下:(这个算法只是简单点的过一遍,不分析具体步骤)
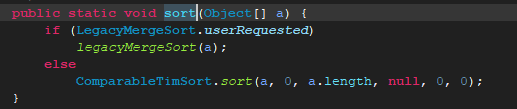
为false时进去的是ComparebleTimSort.sort();我们进入这个算法看下:
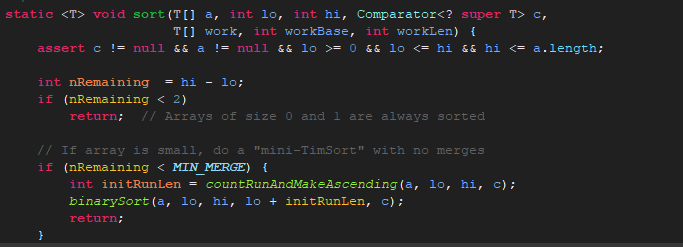
首先一个断言,一般情况下都没有问题,
然后nRemaing = hi - lo,hi是数组长度,lo是0.
MIN_MERGE是32。
接着就是根据数组a计算initRunLen的值,
我们先进入countRunAndMakeAscending();
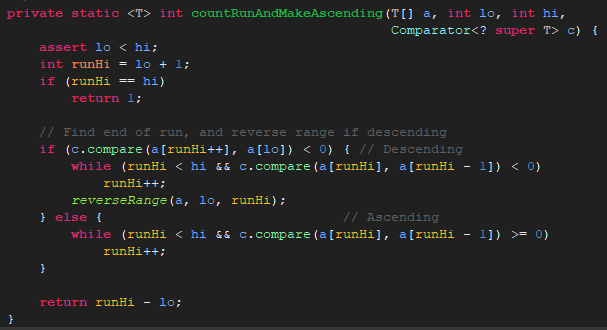
但我们将-1也设置为0时,else后面的语句判断的是返回值>=0。-1和0去判断得到的结果是不同的。
这里会造成这个值有问题,而这个值需要传递到排序算法中,就会导致排序出现问题。News中的CompareTo方法的
返回值只有0,1的话这里的runHi - lo是3,如果是按照正常的1,0,-1来的话runHi - lo是2。这个可以结合源码自己分析一下。
这个执行完之后就要将得到的值,传入我们的排序算法中开始排序了。(上述分析都是基于之前代码中创建的三个新闻对象来分析的)
返回runHi-lo后,我们回到上一级
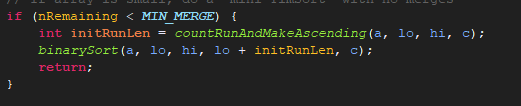
我们将值传入binarSort()中,然后点击binarySort:
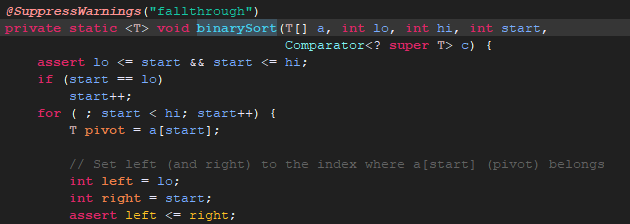
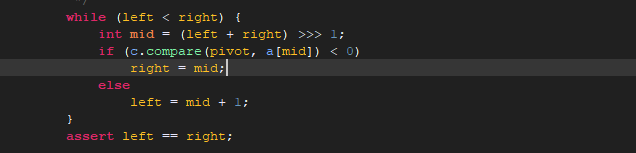
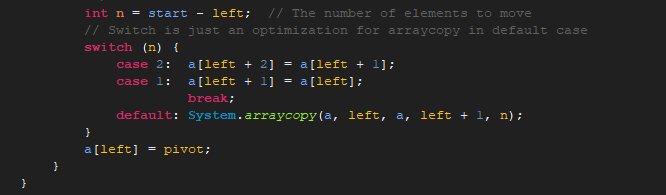
这个具体过程就不一一分析了,有兴趣的可以分析下这些算法。
start就是之前的返回值(runHi - lo),如有只有1,0返回的是3,如果是正常的-1,0,1返回的是2.
我们来看第一个for语句,如果start是3就直接跳出循环(hi是数组长度,这里为3)不进行排序,原有数据不会发生变化。
如果是2,进行排序,最后输出是按照规则排序好的数据。
大家可以试下修改上面代码中Nwes的compareTo()方法的返回值和运行代码中设置true,false的部分:
(1)将 return -1改成return 0,LegacyMergeSort.userRequested为false时,输出未正常排序结果。
LegacyMergeSort.userRequested为true时,输出正常排序结果。
结合上述内容理解下整个的过程。
无论是哪种排序方法,严格按照(1,0,-1)返回,都可以输出对应逻辑排序结果。
结合例子、源码与上述内容分析分析,就可以清楚的知道排序执行的流程以及compareTo()返回值的作用。
3.Comparator接口
Comparator和Comparable类似,底层实现是一样的,理解了Comparable中CompareTo()方法的作用后
理解Comparator就很简单了。
我们之前说的实现Comparable接口的CompareTo方法是写在需要进行排序的类里面的,可以说这种方法就从属于这个类。
但Comparator就不一样了,它只是制定了一种排序规则,不需要从属于谁,谁需要用这个规则拿来用就可以了。
具体的操作是,新建一个规则类,例如我要按照新闻点击量排序,那么我可以把这个类命名为NwesClickSort
这个类需要实现Comparator接口,并且实现里面的ompare()方法。
我们来看下Comparator接口中compare方法:

这个作用和compareTo()方法的作用一样,也是比较两个值(o1,o2),然后返回1,0,-1.
使用compare排序时,就是调用这个方法来进行排序。
使用时,我们需要为NewsClickSort这个类实例化一个对象,这个对象代表一种排序规则。
然后将集合和对象(排序规则)传递到Collections.sort()中。
我们先来看个例子://这里面我们指定了一种排序规则,按照点击量来排序,Nwes类还是之前的代码,没有任何修改。
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.Date;
import java.util.LinkedList;
import java.util.List;
public static void main(String[] args) {
List<News> newsList = new LinkedList<>();
newsList.add(new News("国庆高峰堵车,各景点爆满!",new Date(),1000));//设置为当前时间
newsList.add(new News("国庆仍有大部分家里蹲!",new Date(System.currentTimeMillis()-60*60*1000),100));//设置为当前时间前一小时
newsList.add(new News("惊呆,游客竟在做这种事!!!",new Date(),10000));//设置为当前时间,点击量10000
System.setProperty("java.util.Arrays.useLegacyMergeSort", "true");//设置为true进入legacySort()
System.out.println(newsList);
Collections.sort(newsList,new NewsClickSort());//传递进去的集合,和排序规则
System.out.println(newsList);
}
}
public int compare(News o1, News o2) {
if(o1.getClick() < o2.getClick()){
return 1;//这里写得不是很规范,最好是加上等于返回0,最后小于返回-1.
}else{
return -1;
}
}
}
运行结果:
//排序前结果
[标题:国庆高峰堵车,各景点爆满!时间2018-10-10 08-40-50点击量1000
, 标题:国庆仍有大部分家里蹲!时间2018-10-10 07-40-50点击量100
, 标题:惊呆,游客竟在做这种事!!!时间2018-10-10 08-40-50点击量10000
]
//排序后结果
[标题:惊呆,游客竟在做这种事!!!时间2018-10-10 08-40-50点击量10000
, 标题:国庆高峰堵车,各景点爆满!时间2018-10-10 08-40-50点击量1000
, 标题:国庆仍有大部分家里蹲!时间2018-10-10 07-40-50点击量100
]排序规则中只指定了点击量,所以排序后的结果是按点击量来排序的。
我们可以看到上面代码也设置了
System.setProperty("java.util.Arrays.useLegacyMergeSort", "true");//我们就来分析下使用comparator接口中的compare方法的执行过程。
第一步当然是点进main中的
Collections.sort
注意那个c,就是实例化的比较规则。
我们继续点击sort():

我们会发现和之前看Comparable接口排序的执行过程是一样的。
只是这时候c是实例化的排序规则,不是null了。
继续点击sort()
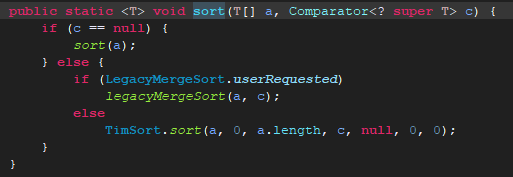
这时c不等于null,所以进入后面的if(LegcyMergeSort.userRequested)进行判断
前面说了默认LegayMergeSort.userRequested是false,这里我们设置了为true,
所以我们点进legacyMergeSort():
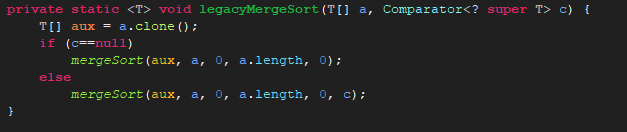
c不等于null,我们点进第二个分支:
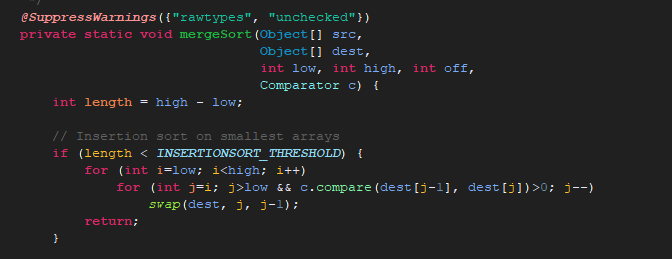
我们会发现和之前sort排序过程及CompareTo()的实现思路是一样的,只是一个调用的是compareTo方法,
一个调用的是c.compare()方法。
LegayMergeSort.userRequested为false时,也和之前分析的sort排序过程及compareTo()的实现思路是一样的,区别只是一个调用
的是compareTo()方法,一个调用的是c.compare()方法。
LegayMergeSort.userRequested为false时的后续执行过程有兴趣可以去看下,会发现和前面讲的一样。
到这里整个比较过程就很清楚了。

C# bubble sort,selection sort,insertion sort
https://www.cnblogs.com/Fred1987/archive/2020/02/12/12299546.html
static void Main(string[] args)
{
InsertionSortDemo();
Console.ReadLine();
}
static void InsertionSortDemo()
{
Random rnd = new Random();
int[] arr = new int[100];
for (int i = 0; i < 100; i++)
{
arr[i] = rnd.Next(0, 1000);
}
Console.WriteLine("Raw data:");
foreach (var a in arr)
{
Console.Write(a + "\t");
}
InsertionSort(arr);
Console.WriteLine("\n\n\nAfter insertion sort:");
foreach(var a in arr)
{
Console.Write(a + "\t");
}
}
static void InsertionSort(int[] arr)
{
int inner, temp;
for (int outer = 0; outer < arr.Length; outer++)
{
temp = arr[outer];
inner = outer;
while (inner > 0 && arr[inner - 1] >= temp)
{
arr[inner] = arr[inner - 1];
inner--;
}
arr[inner] = temp;
}
}
static void SelectSortDemo()
{
Random rnd = new Random();
int[] arr = new int[100];
for (int i = 0; i < 100; i++)
{
arr[i] = rnd.Next(0, 10000);
}
Console.WriteLine("Raw data:");
foreach (var a in arr)
{
Console.Write(a + "\t");
}
SelectionSort(arr);
Console.WriteLine("\n\n\nAfter selection sort:");
foreach(var a in arr)
{
Console.Write(a + "\t");
}
}
public void SelectSort(int[] arr)
{
int min;
for(int outer=0;outer<=arr.Length;outer++)
{
min = outer;
for(int inner=outer+1;inner<=arr.Length;inner++)
{
if(arr[inner]<arr[min])
{
min = inner;
}
}
if(min!=outer)
{
int temp = arr[min];
arr[min] = arr[outer];
arr[outer] = temp;
}
}
}
static void SelectionSortDemo()
{
Random rnd = new Random();
int[] arr = new int[100];
for (int i = 0; i < 100; i++)
{
arr[i] = rnd.Next(0, 1000);
}
Console.WriteLine("Raw data:");
foreach (var a in arr)
{
Console.Write(a + "\t");
}
int[] selectionArr = SelectionSort(arr);
Console.WriteLine("\n\nSelection sort:");
foreach(var a in selectionArr)
{
Console.Write(a + "\t");
}
}
static int[] SelectionSort(int[] arr)
{
int min = 0;
for(int i=0;i<arr.Length-1;i++)
{
min = i;
for(int j=i+1;j<arr.Length;j++)
{
if(arr[j]<arr[min])
{
min = j;
}
}
if (i != min)
{
int temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
}
}
return arr;
}
static void BubbleDemo()
{
Random rnd = new Random();
int[] arr = new int[100];
for(int i=0;i<100;i++)
{
arr[i] = rnd.Next(0, 1000);
}
Console.WriteLine("Raw data:");
foreach(var a in arr)
{
Console.Write(a + "\t");
}
int[] ascArr = BubbleSort(arr, true);
Console.WriteLine("\n\n\nAsc order:");
foreach(var a in ascArr)
{
Console.Write(a + "\t");
}
int[] descArr = BubbleSort(arr, false);
Console.WriteLine("\n\n\nDesc order:");
foreach(var a in descArr)
{
Console.Write(a + "\t");
}
}
static int[] BubbleSort(int[] arr,bool isAsc)
{
if(arr==null && arr.Length==0)
{
return null;
}
for(int i=0;i<arr.Length;i++)
{
for(int j=i+1;j<arr.Length;j++)
{
//Ascending
if(isAsc)
{
if(arr[i]>arr[j])
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
//Descending
else
{
if(arr[i]<arr[j])
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}
}
return arr;
}
排序算法详解")
C++ sort(STL sort)排序算法详解
在很多应用中,排序都是至关重要的,而且很多 STL 算法也只适用于有序对象序列。定义在 algorithm 头文件中的函数模板 sort<Iter>() 默认会将元素段排成升序,这也就意味着排序的对象的类型需要支持< 运算符。 对象也必须是可交换的,这说明可以用定义在 utility 头文件中的函数模板 swap() 来对两个对象进行交换。这进一步表明这种对象的类型需要实现移动构造函数和移动赋值运算符。
函数模板 sort<Iter>() 的类型参数 Iter 是元素段元素对应的迭代器类型,而且它们必须支持随机访问迭代器。这表明 sort() 算法只能对提供随机访问迭代器的容器中的元素进行排序,也说明 sort() 只能接受 array、vector、deque 或标准数组中的元素。可以回顾前面章节,list 和 forward_list 容器都有成员函数 sort(); 这些用来排序的特殊成员函数是必要的,因为 list 只提供双向迭代器,且 forward_list 只提供正向迭代器。
可以从函数调用的参数中推导出 sort() 的模板类型参数,它们是定义被排序对象范围的迭代器。当然,迭代器类型隐式定义了这个元素段中对象的类型。下面是一个使用 sort() 算法的示例:
std::vector<int> numbers {99,77,33,66,22,11,44,88};
std::sort(std::begin(numbers),std::end(numbers));
std::copy(std::begin(numbers),std::end(numbers),std:: ostream_iterator<int> {std::cout," "}) ;
// Output: 11 22 33 44 66 77 88 99
sort() 调用将 number 容器的全部元素排成升序,然后用 copy() 算法输出结果。可以不必对容器的全部内容进行排序。下面这条语句对 numbers 中除了第一个和最后一个元素之外的元素进行了排序:std::sort(++std::begin(numbers),--std::end(numbers));为了将元素排成降序,需要提供一个用来比较元素的函数对象,作为 sort() 的第三个参数:
std::sort(std::begin(numbers),std::greater<>());这个比较函数必须返回布尔值,而且有两个参数,它们要么是迭代器解引用后得到的类型,要么是迭代器解引用后可以隐式转换成的类型。参数可以是不同类型的。只要比较函数满足这些条件,它就可以是你喜欢的任何样子,也包括 lambda 表达式。例如:
std::deque<string> words { "one","two","nine","one","three","four","five","six" };
std::sort(std::begin(words),std::end(words),[](const string& s1,const string& s2) { return s1.back()> s2.back();});
std::copy(std::begin(words),std::ostream_iterator<string> {std::cout," "}); // six four two one nine nine one three five
这段代码对 deque 容器 words 中的 string 元素进行了排序,并且输出了排序后的结果。这里的比较函数是一个 lambda 表达式,它们用每个单词的最后一个字母来比较排序的顺序。结果元素以它们最后一个字母的降序来排序。下面在一个简单的示例中介绍 sort() 的用法。这里会先从键盘读取 Name 对象,然后将它们按升序排列,再输出结果。Name 类定义在 Name.h 头文件中,它包含下面这些代码:
#ifndef NAME_H
#define NAME_H
#include <string> // For string class
class Name
{
private:
std::string first {};
std::string second {};
public:
Name(const std::string& name1,const std::string& name2) : first(name1),second(name2){}
Name()=default;
std::string get_first() const { return first; }
std::string get_second() const { return second; }
friend std::istream& operator>>(std::istream& in,Name& name);
friend std::ostream& operator<<(std::ostream& out,const Name& name);
};
// Stream input for Name objects
inline std::istream& operator>>(std::istream& in,Name& name)
{
return in >> name.first >> name.second;
}
// Stream output for Name objects
inline std::ostream& operator<<(std::ostream& out,const Name& name)
{
return out << name.first << " " << name.second;
}
#endif
这个流插入和提取运算符被定义为 Name 对象的友元函数。可以将 operator<() 定义为类的成员函数,但为了展示如何为 sort() 算法指定比较函数参数,这里没有定义它。下面是程序代码:// Sorting class objects
#include <iostream> // For standard streams
#include <string> // For string class
#include <vector> // For vector container
#include <iterator> // For stream and back insert iterators
#include <algorithm> // For sort() algorithm
#include "Name.h"
int main()
{
std::vector<Name> names;
std::cout << "Enter names as first name followed by second name. Enter Ctrl+Z to end:";
std::copy(std::istream_iterator<Name>(std::cin),std::istream_iterator<Name>(),std::back_insert_iterator<std::vector<Name>>(names));
std::cout << names.size() << " names read. Sorting in ascending sequence...\n";
std::sort(std::begin(names),std::end(names),[](const Name& name1,const Name& name2) {return name1.get_second() < name2.get_second(); });
std::cout << "\nThe names in ascending sequence are:\n";
std::copy(std::begin(names),std::ostream_iterator<Name>(std::cout,"\n"));
}
main() 中的一切几乎都是使用 STL 模板完成的。names 容器用来保存从 cin 读入的姓名。输入由 copy() 算法执行,它使用一个 istream_iterator<Name> 实例读入 Name 对象。 istream_iterator<Name> 默认的构造函数会创建流的结束迭代器。copy() 函数用 back_insert_iterator<Name>() 创建的 back_inserter<Name> 迭代器将输入的每个对象复制到 names 中。为 Name 类重载的流运算符允许使用流迭代器来输入和输出 Name 对象。Name 对象的比较函数是用 lambda 表达式定义的,它是 sort() 算法的第三个参数。如果想将 operator<() 定义为 Name 类的成员函数,可以省略这个参数。然后用 copy() 算法将排序后的 names 写入标准输出流,它会将前两个参数指定范围内的元素复制到作为第三个参数的 ostream_iterator<Name> 对象中。
下面是示例输出:
Enter names as first name followed by second name. Enter Ctrl+Z to end:
Jim Jones
Bill Jones
Jane Smith
John Doe
Janet Jones
Willy Schaferknaker
^Z
6 names read. Sorting in ascending sequence...
The names in ascending sequence are:
John Doe
Jim Jones
Bill Jones
Janet Jones
Willy Schaferknaker
Jane Smith
关于NumPy-任何dtype数组的降序稳定arg-sort和数组降序排列python的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于"import numpy as np" ImportError: No module named numpy、5.4 (Java学习笔记)集合的排序(Collections.sort(),及Arrays.sort())、C# bubble sort,selection sort,insertion sort、C++ sort(STL sort)排序算法详解等相关知识的信息别忘了在本站进行查找喔。
本文标签:




