最近很多小伙伴都在问NumPy-按频率快速稳定地对大型数组进行arg排序和数组按照频率排序这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展"importnumpyasnp"Impo
最近很多小伙伴都在问NumPy-按频率快速稳定地对大型数组进行arg排序和数组按照频率排序这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展"import numpy as np" ImportError: No module named numpy、3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数、Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案、Difference between import numpy and import numpy as np等相关知识,下面开始了哦!
本文目录一览:- NumPy-按频率快速稳定地对大型数组进行arg排序(数组按照频率排序)
- "import numpy as np" ImportError: No module named numpy
- 3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数
- Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案
- Difference between import numpy and import numpy as np
")
NumPy-按频率快速稳定地对大型数组进行arg排序(数组按照频率排序)
如何解决NumPy-按频率快速稳定地对大型数组进行arg排序
我有任何类似a的大型一维NumPy数组dtype,它的某些元素可能会重复。
如何找到排序索引ix,该索引将按值的降序/升序对a sense described here进行稳定排序(question here中的稳定性)?
我想找到最快最简单的方法。也许现有的标准numpy函数可以做到这一点。
还有另一个相关的Try it online!,但它专门要求删除重复的数组,即仅输出唯一的排序值,我需要原始数组的所有值,包括重复的值。
我已经编写了第一个试用版来完成该任务,但是它不是最快的(使用Python的循环),并且可能不是最短/最简单的形式。如果相等元素的重复次数不高且数组很大,则此python循环可能会非常昂贵。如果在NumPy中可用(例如,虚构的a),那么具有简短的功能来完成所有操作也将是一件好事。
{{3}}
np.argsort_by_freq()
输出:
import numpy as npnp.random.seed(1)hi,n,desc = 7,24,Truea = np.random.choice(np.arange(hi),(n,),p = (lambda p = np.random.random((hi,)): p / p.sum())())us,cs = np.unique(a,return_counts = True)af = np.zeros(n,dtype = np.int64)for u,c in zip(us,cs):af[a == u] = cif desc:ix = np.argsort(-af,kind = ''stable'') # Descending sortelse:ix = np.argsort(af,kind = ''stable'') # Ascending sortprint(''rows: i_col(0) / original_a(1) / freqs(2) / sorted_a(3)'')print('' / sorted_freqs(4) / sorting_ix(5)'')print(np.stack((np.arange(n),a,af,a[ix],af[ix],ix,0))
解决方法
我可能会丢失一些东西,但是似乎可以使用Counter然后根据该元素的值的计数,使用该元素的值,然后使用该索引断开联系,对每个元素的索引进行排序。例如:
from collections import Countera = [ 1,1,3,5,4,6,0]counts = Counter(a)t = [(counts[v],v,i) for i,v in enumerate(a)]t.sort()print([v[2] for v in t])t.sort(reverse=True)print([v[2] for v in t])
输出:
[13,14,8,16,17,18,22,2,9,10,15,7,11,12,19,20,21,23][23,13]
如果要保持具有相等计数的组的索引的升序,则可以对降序使用lambda函数:
t.sort(key = lambda x:(-x[0],-x[1],x[2]))print([v[2] for v in t])
输出:
[5,23,13]
如果要按照元素最初出现在数组中的顺序来保持元素的顺序如果它们的计数相同,则不要按值排序,而按其索引排序数组中的第一个匹配项:
a = [ 1,0]counts = Counter(a)idxs = {}t = []for i,v in enumerate(a):if not v in idxs:idxs[v] = it.append((counts[v],idxs[v],i))t.sort()print([v[2] for v in t])t.sort(key = lambda x:(-x[0],x[1],x[2]))print([v[2] for v in t])
输出:
[13,23][5,13,14]
要根据计数排序,然后再在数组中定位,则完全不需要该值或第一个索引:
from collections import Countera = [ 1,v in enumerate(a)]t.sort()print([v[1] for v in t])t.sort(key = lambda x:(-x[0],x[1]))print([v[1] for v in t])
对于字符串数组,这将产生与示例数据的先前代码相同的输出:
a = [''g'',''g'',''c'',''f'',''d'',''a'',''e'',''b'',''f'' ]
这将产生输出:
,
[18,24][3,24,18]
我只是使用不带python循环的numpy函数就可以解决任何dtype的非常快速的解决方案,它可以在O(N log N)时间内工作。使用的numpy函数:np.unique,np.argsort和数组索引。
尽管在原始问题中并未询问,但我实现了额外的标记equal_order_by_val,如果它为False,则将具有相同频率的数组元素排序为相等的稳定范围,这意味着可能会有c d d c d c输出在下面的输出转储中,因为这是元素以相同频率进入原始数组的顺序。当flag为True时,此类元素还按原始数组的值排序,结果为c c c d d d。换句话说,在False的情况下,我们仅按键freq进行稳定排序,当它为True时,我们按(freq,value)进行升序排序,并按(-freq,value)进行降序排序。
Try it online!
import string,mathimport numpy as npnp.random.seed(0)# Generating input datahi,n,desc = 7,25,Trueletters = np.array(list(string.ascii_letters),dtype = np.object_)[:hi]a = np.random.choice(letters,(n,),p = (lambda p = np.random.random((letters.size,)): p / p.sum())())for equal_order_by_val in [False,True]:# Solving taskus,ui,cs = np.unique(a,return_inverse = True,return_counts = True)af = cs[ui]sort_key = -af if desc else afif equal_order_by_val:shift_bits = max(1,math.ceil(math.log(us.size) / math.log(2)))sort_key = ((sort_key.astype(np.int64) << shift_bits) +np.arange(us.size,dtype = np.int64)[ui])ix = np.argsort(sort_key,kind = ''stable'') # Do sorting itself# Printing resultsprint(''\\nequal_order_by_val:'',equal_order_by_val)for name,val in [(''i_col'',np.arange(n)),(''original_a'',a),(''freqs'',af),(''sorted_a'',a[ix]),(''sorted_freqs'',af[ix]),(''sorting_ix'',ix),]:print(name.rjust(12),'' ''.join([str(e).rjust(2) for e in val]))
输出:
equal_order_by_val: Falsei_col 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24original_a g g c f d d g a a a f f f g f c f a e b g d c b ffreqs 5 5 3 7 3 3 5 4 4 4 7 7 7 5 7 3 7 4 1 2 5 3 3 2 7sorted_a f f f f f f f g g g g g a a a a c d d c d c b b esorted_freqs 7 7 7 7 7 7 7 5 5 5 5 5 4 4 4 4 3 3 3 3 3 3 2 2 1sorting_ix 3 10 11 12 14 16 24 0 1 6 13 20 7 8 9 17 2 4 5 15 21 22 19 23 18equal_order_by_val: Truei_col 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24original_a g g c f d d g a a a f f f g f c f a e b g d c b ffreqs 5 5 3 7 3 3 5 4 4 4 7 7 7 5 7 3 7 4 1 2 5 3 3 2 7sorted_a f f f f f f f g g g g g a a a a c c c d d d b b esorted_freqs 7 7 7 7 7 7 7 5 5 5 5 5 4 4 4 4 3 3 3 3 3 3 2 2 1sorting_ix 3 10 11 12 14 16 24 0 1 6 13 20 7 8 9 17 2 15 22 4 5 21 19 23 18

"import numpy as np" ImportError: No module named numpy
问题:没有安装 numpy
解决方法:
下载文件,安装
numpy-1.8.2-win32-superpack-python2.7
安装运行 import numpy,出现
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
import numpy
File "C:\Python27\lib\site-packages\numpy\__init__.py", line 153, in <module>
from . import add_newdocs
File "C:\Python27\lib\site-packages\numpy\add_newdocs.py", line 13, in <module>
from numpy.lib import add_newdoc
File "C:\Python27\lib\site-packages\numpy\lib\__init__.py", line 8, in <module>
from .type_check import *
File "C:\Python27\lib\site-packages\numpy\lib\type_check.py", line 11, in <module>
import numpy.core.numeric as _nx
File "C:\Python27\lib\site-packages\numpy\core\__init__.py", line 6, in <module>
from . import multiarray
ImportError: DLL load failed: %1 不是有效的 Win32 应用程序。原因是:python 装的是 64 位的,numpy 装的是 32 位的
重新安装 numpy 为:numpy-1.8.0-win64-py2.7
---Numpy 的统计函数")
3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数
目录
[TOC]
前言
具体我们来学 Numpy 的统计函数
(一)函数一览表
调用方式:np.*
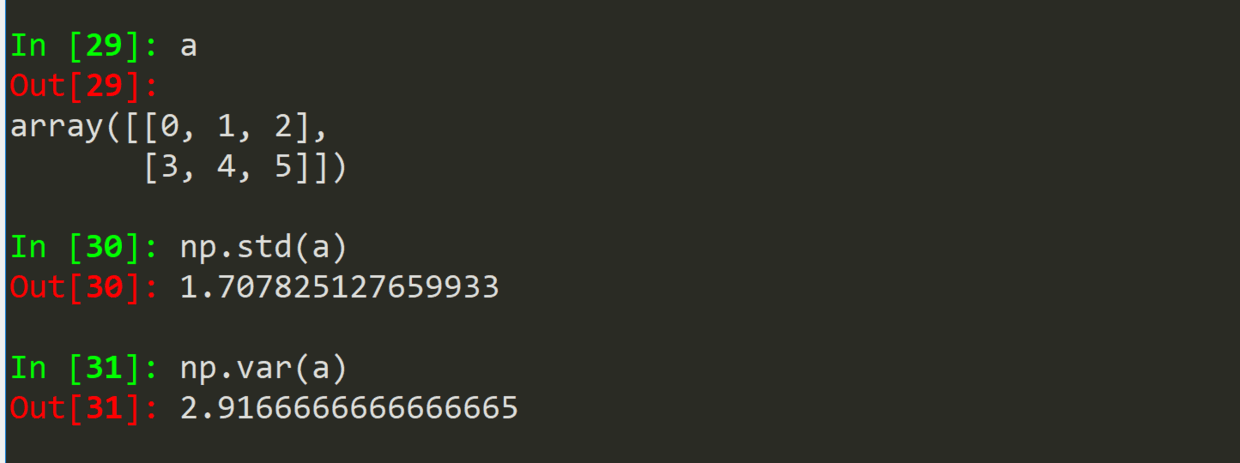
| .sum(a) | 对数组 a 求和 |
|---|---|
| .mean(a) | 求数学期望 |
| .average(a) | 求平均值 |
| .std(a) | 求标准差 |
| .var(a) | 求方差 |
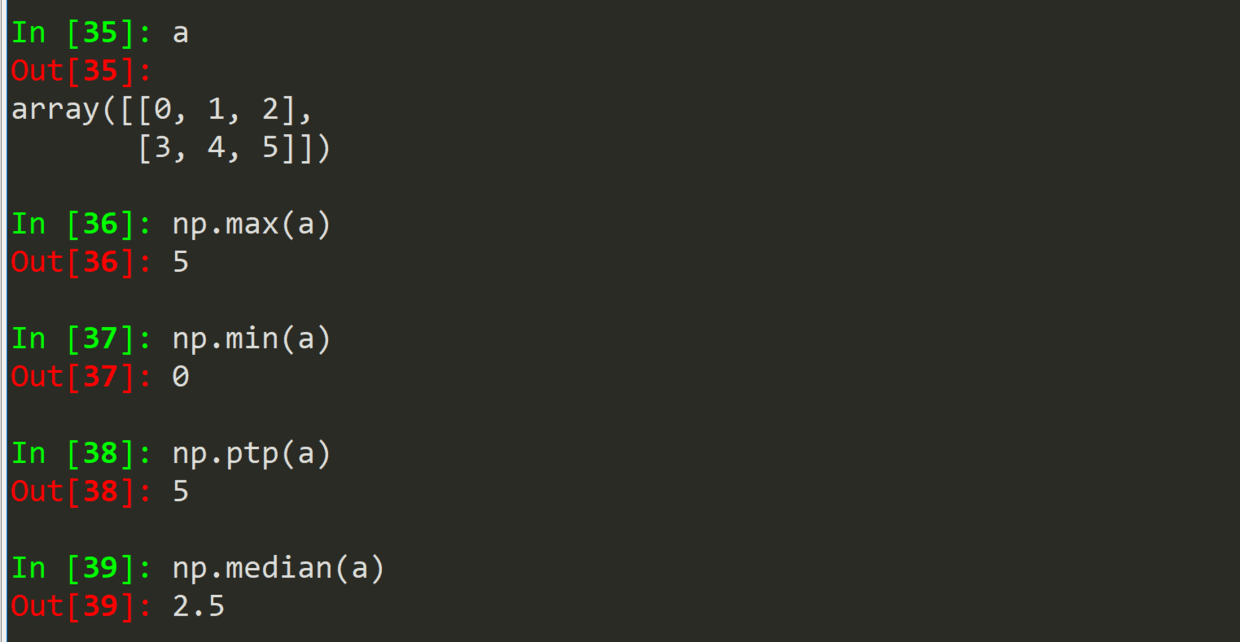
| .ptp(a) | 求极差 |
| .median(a) | 求中值,即中位数 |
| .min(a) | 求最大值 |
| .max(a) | 求最小值 |
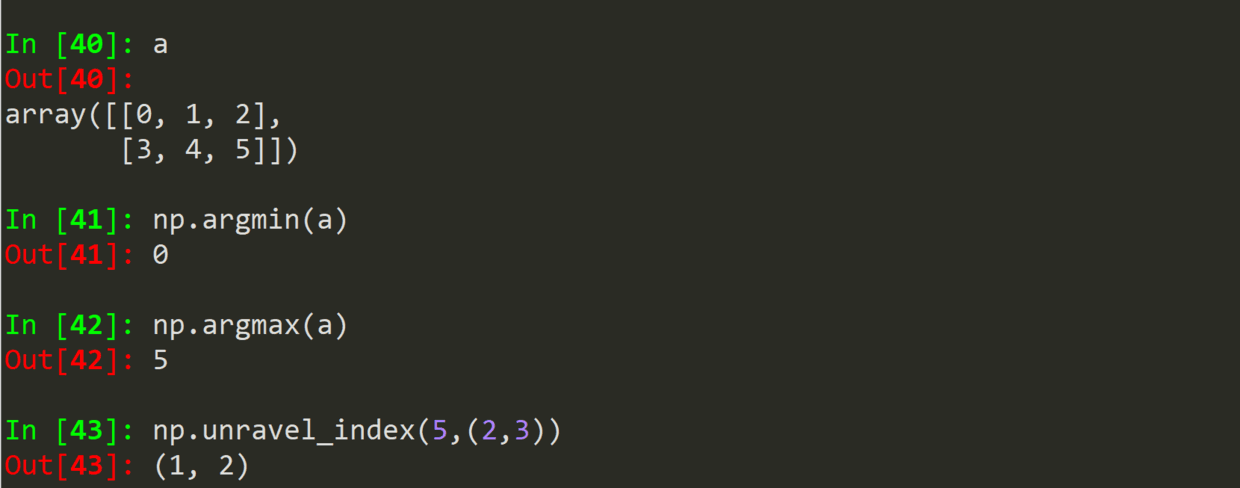
| .argmin(a) | 求最小值的下标,都处里为一维的下标 |
| .argmax(a) | 求最大值的下标,都处里为一维的下标 |
| .unravel_index(index, shape) | g 根据 shape, 由一维的下标生成多维的下标 |
(二)统计函数 1
(1)说明

(2)输出
.sum(a)

.mean(a)

.average(a)

.std(a)
.var(a)
(三)统计函数 2
(1)说明

(2)输出
.max(a) .min(a)
.ptp(a)
.median(a)
.argmin(a)
.argmax(a)
.unravel_index(index,shape)
作者:Mark
日期:2019/02/11 周一

Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案
如何解决Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案?
希望有人能在这里提供帮助。我一直在绕圈子一段时间。我只是想设置一个 python 脚本,它将一些 json 数据从 REST API 加载到云数据库中。我在 Anaconda 上设置了一个虚拟环境(因为 GCP 库推荐这样做),安装了依赖项,现在我只是尝试导入库并向端点发送请求。 我使用 Conda(和 conda-forge)来设置环境并安装依赖项,所以希望一切都干净。我正在使用带有 Python 扩展的 VS 编辑器作为编辑器。 每当我尝试运行脚本时,我都会收到以下消息。我已经尝试了其他人在 Google/StackOverflow 上找到的所有解决方案,但没有一个有效。我通常使用 IDLE 或 Jupyter 进行脚本编写,没有任何问题,但我对 Anaconda、VS 或环境变量(似乎是相关的)没有太多经验。 在此先感谢您的帮助!
\Traceback (most recent call last):
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\__init__.py",line 22,in <module>
from . import multiarray
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\multiarray.py",line 12,in <module>
from . import overrides
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\overrides.py",line 7,in <module>
from numpy.core._multiarray_umath import (
ImportError: DLL load Failed while importing _multiarray_umath: The specified module Could not be found.
During handling of the above exception,another exception occurred:
Traceback (most recent call last):
File "c:\API\citi-bike.py",line 4,in <module>
import numpy as np
File "C:\Conda\envs\gcp\lib\site-packages\numpy\__init__.py",line 150,in <module>
from . import core
File "C:\Conda\envs\gcp\lib\site-packages\numpy\core\__init__.py",line 48,in <module>
raise ImportError(msg)
ImportError:
IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE!
Importing the numpy C-extensions Failed. This error can happen for
many reasons,often due to issues with your setup or how NumPy was
installed.
We have compiled some common reasons and troubleshooting tips at:
https://numpy.org/devdocs/user/troubleshooting-importerror.html
Please note and check the following:
* The Python version is: python3.9 from "C:\Conda\envs\gcp\python.exe"
* The NumPy version is: "1.21.1"
and make sure that they are the versions you expect.
Please carefully study the documentation linked above for further help.
Original error was: DLL load Failed while importing _multiarray_umath: The specified module Could not be found.
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

Difference between import numpy and import numpy as np
Difference between import numpy and import numpy as np
| up vote 18 down vote favorite 5 |
I understand that when possible one should use This helps keep away any conflict due to namespaces. But I have noticed that while the command below works the following does not Can someone please explain this? python numpy
|
||||||||
add a comment |
4 Answers
active oldest votes
| up vote 13 down vote |
numpy is the top package name, and doing When you do In your above code: Here is the difference between
|
|||
| add a comment |
| up vote 7 down vote |
The When you import a module via the numpy package is bound to the local variable Thus, is equivalent to, When trying to understand this mechanism, it''s worth remembering that When importing a submodule, you must refer to the full parent module name, since the importing mechanics happen at a higher level than the local variable scope. i.e. I also take issue with your assertion that "where possible one should [import numpy as np]". This is done for historical reasons, mostly because people get tired very quickly of prefixing every operation with Finally, to round out my exposé, here are 2 interesting uses of the 1. long subimports2. compatible APIs
|
||
| add a comment |
| up vote 1 down vote |
when you call the statement
|
||
| add a comment |
| up vote 1 down vote |
This is a language feature. This feature allows:
Notice however that Said that, when you run You receive an
|
||||||||
add a comment |
关于NumPy-按频率快速稳定地对大型数组进行arg排序和数组按照频率排序的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于"import numpy as np" ImportError: No module named numpy、3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数、Anaconda Numpy 错误“Importing the Numpy C Extension Failed”是否有另一种解决方案、Difference between import numpy and import numpy as np等相关知识的信息别忘了在本站进行查找喔。
本文标签:




