本文将带您了解关于Mysql数据库索引ISNUll,ISNOTNUll,!=是否走索引的新内容,同时我们还将为您解释mysql索引为null的相关知识,另外,我们还将为您提供关于ISNULL、ISNU
本文将带您了解关于Mysql数据库索引IS NUll ,IS NOT NUll ,!= 是否走索引的新内容,同时我们还将为您解释mysql索引为null的相关知识,另外,我们还将为您提供关于ISNULL、IS NULL、IS NOT NULL 、IFNULL()、COALESC()区别、Mysql is null 索引、mysql IS NULL使用索引案例讲解、MySQL ISNULL() 函数和 IS NULL 运算符有什么区别?的实用信息。
本文目录一览:- Mysql数据库索引IS NUll ,IS NOT NUll ,!= 是否走索引(mysql索引为null)
- ISNULL、IS NULL、IS NOT NULL 、IFNULL()、COALESC()区别
- Mysql is null 索引
- mysql IS NULL使用索引案例讲解
- MySQL ISNULL() 函数和 IS NULL 运算符有什么区别?
")
Mysql数据库索引IS NUll ,IS NOT NUll ,!= 是否走索引(mysql索引为null)
声明在前面
总结就是 不能单纯说 走和不走,需要看数据库版本,数据量等 ,希望不要引起大家的误会,也不要被标题党误导了。
1 数据库版本:
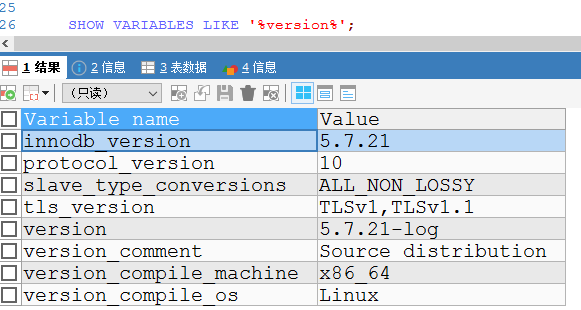
2 建表语句
CREATE TABLE s1 (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(200),
key2 VARCHAR(200),
key3 VARCHAR(200),
key_part1 VARCHAR(200),
key_part2 VARCHAR(200),
key_part3 VARCHAR(200),
common_field VARCHAR(200),
PRIMARY KEY (id)
) ENGINE=INNODB CHARSET=utf8;3 建索引语句
CREATE INDEX isz_key1 ON s1(key1);
CREATE INDEX isz_key2 ON s1(key2);
CREATE INDEX isz_key3 ON s1(key3);
CREATE INDEX idx_key_part ON s1 (key_part1, key_part2, key_part3);4 铺底数据
DELIMITER $$
CREATE PROCEDURE pre ()
BEGIN
DECLARE i INT;
SET i = 0;
WHILE
i < 9000 DO
INSERT INTO s1 (
key1,
key2,
key3,
key_part1,
key_part2,
key_part3,
common_field
)
VALUES
(
''a'',
''注意应收热热账款状态为有效状态下,应收账款编号与应热热付流水号一一对应,(已结佣、已热热、已失效3种情况为无效热热,其他均为有效状态)'',
''cc'',
''a应收账款状态为a'',
''cc'',
''注意应erect账款状态为有效状态下,应收账款编号与应付流水号一一对应,(已结佣、已热热无效、已失效3种情况为热热状态,其他均为有效状态)'',
''ddff''
);
SET i = i + 1;
END WHILE;
END $$
CALL pre ();
DROP PROCEDURE pre;
select COUNT(1)FROM s1;IS NULL ,IS NOT NUll 是否走索引
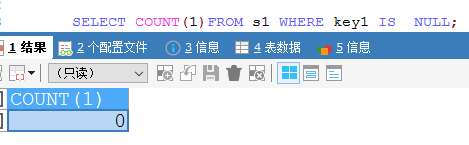
EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS NULL; 表里 key1 为is null的总数为0 查询is null 走索引
 EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS not NULL; 表里 key1 的列 is not null 的总数为0,不存在值为null 查询is not null 不走索引
EXPLAIN SELECT *FROM s1 WHERE s1.`key1` IS not NULL; 表里 key1 的列 is not null 的总数为0,不存在值为null 查询is not null 不走索引
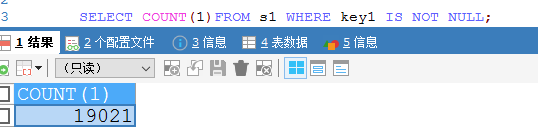
 Is null count为19012条 ,is not count为9条 实验结果 is null 和 is not null 都走索引
Is null count为19012条 ,is not count为9条 实验结果 is null 和 is not null 都走索引
 测试application 表,is null count有305条,表总有324条 ,is null 不走索引
测试application 表,is null count有305条,表总有324条 ,is null 不走索引
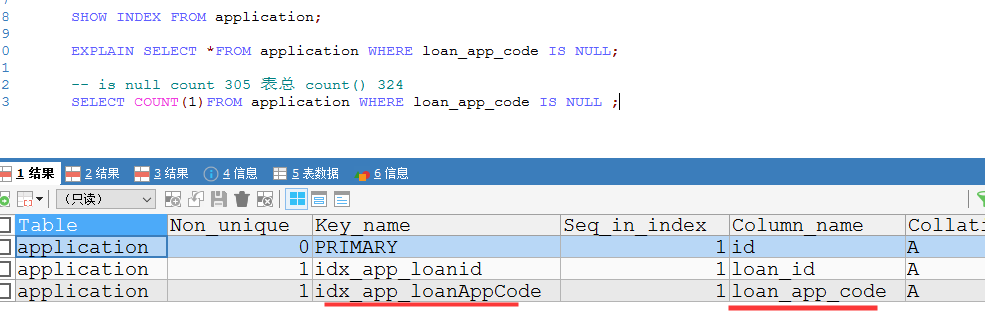

总结: 并不是 is null ,is not null走和不走索引是和数据量或者和其他元素有关系(这里我只是测试到和数据量有关系) sql优化器在执行的时候会计算成本,其实和基数,选择性,直方图有关,其实就是看你所搜索的部分占全表的比例是走索引还是全表成本低。
!=走索引吗?
<> 和!= 是同一个意思 ,都是不等于
测试一 <> 走索引,存在<>的数据量有9条

测试二<>走索引存在不等于的数据量有305条
 测试三 <> 不走索引 值都是“abc”,不是“abc”的总条数为0
测试三 <> 不走索引 值都是“abc”,不是“abc”的总条数为0
SELECT COUNT(1)FROM s1 WHERE s1.`key3` =''abc''; -- 0
测试四 <>走索引
总结:并不能一句话说 走和不走,需要看条件,比如数据量,等于“abc”的数据量和不等于“abc”的量,mysql在执行的时候会判断走索引的成本和全表扫描的成本,然后选择成本小的那个
、COALESC()区别")
ISNULL、IS NULL、IS NOT NULL 、IFNULL()、COALESC()区别
IFNULL()、COALESC()
用于select 选择字段中表示为null值替换自定义默认值,如:将null转换为0

ISNULL()、IS NULL、IS NOT NULL
用于where后面作为条件
ISNULL() 与IS NULL功能一样都是判断为null值作为where条件
IS NOT NULL 与前两个功能相反,判断不为Null的数据
Mysql is null 索引
看到很多网上谈优化mysql的文章,发现很多在谈到mysql的null是不走索引的,在此我觉得很有必要纠正下这类结论。
mysql is null是有索引的,而且是很高效的,(版本:mysql5.5)
表结构如下:
CREATE TABLE `student` (
`stu_no` int(2) unsigned zerofill NOT NULL AUTO_INCREMENT COMMENT ''学员编号'',
`stu_name` varchar(30) CHARACTER SET utf8 DEFAULT NULL COMMENT ''学员姓名'',
`stu_sex` varchar(3) CHARACTER SET utf8 NOT NULL COMMENT ''学员性别'',
`stu_age` tinyint(2) unsigned zerofill DEFAULT NULL COMMENT ''学员年代'',
`grade` double(5,2) unsigned zerofill DEFAULT NULL COMMENT ''成绩'',
`class_no` int(2) unsigned zerofill DEFAULT NULL COMMENT ''所在班级编号'',
PRIMARY KEY (`stu_no`),
KEY `class_no` (`class_no`),
KEY `stu_name` (`stu_name`) COMMENT ''学生姓名索引''
) ENGINE=MyISAM AUTO_INCREMENT=13 DEFAULT CHARSET=latin1;测试几条数据:
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''01'', ''李白'', ''男'', ''18'', ''60.00'', ''01'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''02'', ''杜甫'', ''男'', ''20'', ''76.00'', ''01'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''03'', ''张飞'', ''男'', ''32'', ''80.00'', ''02'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''04'', ''韩信'', ''男'', ''26'', ''98.00'', ''02'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''05'', ''了龙'', ''男'', ''27'', ''56.00'', ''02'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''06'', ''大乔'', ''女'', ''17'', ''88.00'', ''01'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''07'', ''小乔'', ''女'', ''16'', ''96.00'', ''01'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''08'', ''小乔'', ''女'', ''16'', ''90.00'', ''01'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''09'', ''关哥'', ''男'', ''32'', ''80.00'', ''02'');
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''10'', ''刘备'', ''男'', ''36'', ''98.00'', NULL);
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''11'', ''宋江'', ''男'', ''37'', NULL, NULL);
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''12'', ''李逵'', '''', ''27'', NULL, NULL);
INSERT INTO `test`.`student` (`stu_no`, `stu_name`, `stu_sex`, `stu_age`, `grade`, `class_no`) VALUES (''13'', NULL, ''女'', ''21'', ''39.00'', ''01''); 
可以看到使用了索引stu_name,ref=const,索引效率还是很高的。

mysql IS NULL使用索引案例讲解
简介
mysql的sql查询语句中使用is null、is not null、!=对索引并没有任何影响,并不会因为where条件中使用了is null、is not null、!=这些判断条件导致索引失效而全表扫描。
mysql官方文档也已经明确说明is null并不会影响索引的使用。
MySQL can perform the same optimization on col_name IS NULL that it can use for col_name = constant_value. For example, MySQL can use indexes and ranges to search for NULL with IS NULL.
事实上,导致索引失效而全表扫描的通常是因为一次查询中回表数量太多。mysql计算认为使用索引的时间成本高于全表扫描,于是mysql宁可全表扫描也不愿意使用索引。
案例
CREATE TABLE `user_info` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(11) DEFAULT NULL, `age` int(4) DEFAULT NULL, PRIMARY KEY (`id`), KEY `index_name` (`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `user_info` (`id`, `name`, `age`) VALUES (''1'', ''tom'', ''18'');
INSERT INTO `user_info` (`id`, `name`, `age`) VALUES (''2'', null, ''19'');
INSERT INTO `user_info` (`id`, `name`, `age`) VALUES (''3'', ''cat'', ''20'');
执行sql查询时使用is null、is not null,发现依然使用的索引查询,并没有出现索引失效的问题。


分析
分析上述现象,则需要详细了解mysql索引的工作原理以及索引数据结构。下面,分别通过工具解析和直接查看二进制文件两种方式分别分析mysql索引数据结构。
工具解析
innodb_ruby是一个非常强大的mysql分析工具,可以用来轻松解析mysql的.ibd文件进而深入理解mysql的数据结构。
首先安装innodb_ruby工具:
yum install -y rubygems ruby-deve gem install innodb_ruby
innodb_ruby的功能很多,此处我们只需要用来解析mysql的索引结构,因此只需要如下的命令即可。更多的功能和命令详见wiki。
innodb_space -s ibdata1 -T sakila/film -I PRIMARY index-recurse
解析主键索引:
$ innodb_space -s /usr/soft/mysql-5.6.31/data -T test/user_info -I PRIMARY index-recurse ROOT NODE #3: 3 records, 89 bytes RECORD: (id=1) → (name="tom", age=18) RECORD: (id=2) → (name=:NULL, age=19) RECORD: (id=3) → (name="cat", age=20)
解析普通索引index_name:
$ innodb_space -s /usr/soft/mysql-5.6.31/data -T test/user_info -I index_name index-recurse ROOT NODE #4: 3 records, 38 bytes RECORD: (name=:NULL) → (id=2) RECORD: (name="cat") → (id=3) RECORD: (name="tom") → (id=1)
通过解析工具数据mysql的索引结构可以发现,null值也被储存到了索引树中,并且null值被处理成最小的值放在index_name索引树的最左侧。
二进制文件
找到user_info表对应的物理文件user_info.ibd,通过软件例如UltraEdit打开,直接定位到第5个数据页(mysql默认一个数据页占用16KB)。
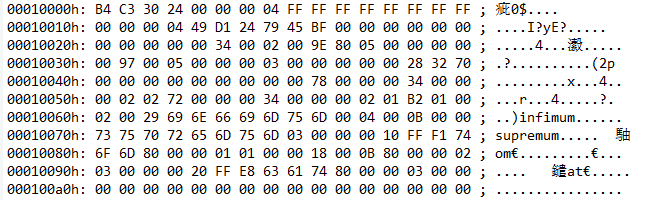
如图,这些二进制数据就是index_name索引对应的索引页数据,只挑选其中的索引记录,展开如下:
最小记录0x00010063
01 B2 01 00 02 00 29 记录头信息 69 6E 66 69 6D 75 6D 最小记录(固定值infimum)
最大记录0x00010070
00 04 00 0B 00 00 记录头信息 73 75 70 72 65 6D 75 6D 最大记录(固定值supremum)
ID为1的索引0x0001007f
03 00 00 00 10 FF F1 记录头信息 74 6F 6D 字段name的值:tom 80 00 00 01 RowID:主键id的值为1
ID为2的索引0x0001008c
01 00 00 18 00 0B 记录头信息 字段name的值:null 80 00 00 02 RowID:主键id的值为2
ID为3的索引0x00010097
03 00 00 00 20 FF E8 记录头信息 63 61 74 字段name的值:cat 80 00 00 03 RowID:主键id的值为3
最小记录的记录头信息最后2字节00 29 -> 0x00010063偏移0x0029 -> 0x0001008C,即ID为2的索引位置;
ID为2的记录头信息最后2字节00 0B -> 0x0001008C偏移0x000B -> 0x00010097,即ID为3的索引位置;
ID为3的记录头信息最后2字节FF E8 -> 0x00010097偏移0xFFE8 -> 0x0001007F,即ID为1的索引位置;
ID为1的记录头信息最后2字节FF F1 -> 0x0001007F偏移0xFFF1 -> 0x00010070,最大记录的记录位置;
由此可见索引记录是通过单向链表并以索引值排序串联在一起,而null值被处理成最小的值放在了索引链表的最开始位置,也就是索引树的最左侧。与innodb_ruby工具解析出来的结果一致。
误解原因
为何大众误解认为is null、is not null、!=这些判断条件会导致索引失效而全表扫描呢?
导致索引失效而全表扫描的通常是因为一次查询中回表数量太多。mysql计算认为使用索引的时间成本高于全表扫描,于是mysql宁可全表扫描也不愿意使用索引。使用索引的时间成本高于全表扫描的临界值可以简单得记忆为20%左右。
详细的分析过程可以见笔者的另一篇博客:mysql回表致索引失效。
也就是如果一条查询语句导致的回表范围超过全部记录的20%,则会出现索引失效的问题。而is null、is not null、!=这些判断条件经常会出现在这些回表范围很大的场景,然后被人误解为是这些判断条件导致的索引失效。
复现索引失效
复现索引失效,只需要回表范围超过全部记录的20%,如下插入1000条非null记录。
delimiter // CREATE PROCEDURE init_user_info() BEGIN DECLARE indexNo INT; SET indexNo = 0; WHILE indexNo < 1000 DO START TRANSACTION; insert into user_info(name,age) values (concat(floor(rand()*1000000000)),floor(rand()*100)); SET indexNo = indexNo + 1; COMMIT; END WHILE; END // delimiter ; call init_user_info();
此时user_info表中一共有1003条记录,其中只有1条记录的name值为null。那么is null判断语句导致的回表记录只有1/1003不会超过临界值,而is not null判断语句导致的回表记录有1002/1003远远超过临界值,将出现索引失效的现象。
由下两图也可以见,is null依然正常使用索引,而is not null如预期由于回表率太高而宁可全表扫描也不使用索引。


使用mysql的optimizer tracing(mysql5.6版本开始支持)功能来分析sql的执行计划:
SET optimizer_trace="enabled=on"; explain select * from user_info where name is not null; SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
optimizer tracing输出的执行计划可见,该查询下,使用全表扫描所需要的时间成本为206.9;而使用索引所需要的时间成本为1203.4,远远高于全表扫描。因此mysql最终选择全表扫描而出现索引失效的现象。
{
"rows_estimation": [
{
"table": "`user_info`",
"range_analysis": {
"table_scan": {
"rows": 1004, // 全表扫描需要扫描1004条记录
"cost": 206.9 // 全表扫描需要的成本为206.9
},
"potential_range_indices": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_name",
"usable": true,
"key_parts": [
"name",
"id"
]
}
],
"setup_range_conditions": [],
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "index_name",
"ranges": [
"NULL < name"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 1002, // 索引需要扫描1002条记录
"cost": 1203.4, // 索引需要的成本为1203.4
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
}
]
}
到此这篇关于mysql IS NULL使用索引案例讲解的文章就介绍到这了,更多相关mysql IS NULL使用内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- MySQL流程控制IF()、IFNULL()、NULLIF()、ISNULL()函数的使用
- 一文带你探究MySQL中的NULL
- MySQL系列关于NUll值的经验总结分析教程
- MySql关于null的函数使用分享
- 基于MySQL在磁盘上存储NULL值
 函数和 IS NULL 运算符有什么区别?")
MySQL ISNULL() 函数和 IS NULL 运算符有什么区别?

显然,ISNULL()函数和IS NULL运算符没有任何区别,并且共享一些共同的行为。我们唯一能看到的区别是它们的语法。ISNULL()函数将表达式作为其参数,而IS NULL比较运算符将表达式放在其左侧。否则,如果表达式为NULL,则两者都返回1,如果表达式不为NULL,则返回0。以下示例将演示上述概念−
mysql> Select 1 IS NULL; +-----------+ | 1 IS NULL | +-----------+ | 0 | +-----------+ 1 row in set (0.00 sec) mysql> Select ISNULL(1); +-----------+ | ISNULL(1) | +-----------+ | 0 | +-----------+ 1 row in set (0.00 sec) mysql> Select ISNULL(1/0); +-------------+ | ISNULL(1/0) | +-------------+ | 1 | +-------------+ 1 row in set (0.00 sec) mysql> Select 1/0 IS NULL; +-------------+ | 1/0 IS NULL | +-------------+ | 1 | +-------------+ 1 row in set (0.00 sec) mysql> Select * from Employee WHERE Salary IS NULL; +----+-------+--------+ | ID | Name | Salary | +----+-------+--------+ | 7 | Aryan | NULL | | 8 | Vinay | NULL | +----+-------+--------+ 2 rows in set (0.00 sec) mysql> Select * from Employee WHERE ISNULL(Salary); +----+-------+--------+ | ID | Name | Salary | +----+-------+--------+ | 7 | Aryan | NULL | | 8 | Vinay | NULL | +----+-------+--------+ 2 rows in set (0.00 sec)
以上就是MySQL ISNULL() 函数和 IS NULL 运算符有什么区别?的详细内容,更多请关注php中文网其它相关文章!
今天关于Mysql数据库索引IS NUll ,IS NOT NUll ,!= 是否走索引和mysql索引为null的介绍到此结束,谢谢您的阅读,有关ISNULL、IS NULL、IS NOT NULL 、IFNULL()、COALESC()区别、Mysql is null 索引、mysql IS NULL使用索引案例讲解、MySQL ISNULL() 函数和 IS NULL 运算符有什么区别?等更多相关知识的信息可以在本站进行查询。
本文标签:




