对于SimplifyMachineLearningInferenceonKuberneteswithAmazonSageMakerOperators感兴趣的读者,本文将会是一篇不错的选择,并为您提供关
对于Simplify Machine Learning Inference on Kubernetes with Amazon SageMaker Operators感兴趣的读者,本文将会是一篇不错的选择,并为您提供关于175+ Customers Achieve Machine Learning Success with AWS’s Machine Learning Solutions Lab、Analyzing chest X-ray images with machine learning、augemtation 错误,tensorflow.python.keras.preprocessing.image.ImageDataGenerator、Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age的有用信息。
本文目录一览:- Simplify Machine Learning Inference on Kubernetes with Amazon SageMaker Operators
- 175+ Customers Achieve Machine Learning Success with AWS’s Machine Learning Solutions Lab
- Analyzing chest X-ray images with machine learning
- augemtation 错误,tensorflow.python.keras.preprocessing.image.ImageDataGenerator
- Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age

Simplify Machine Learning Inference on Kubernetes with Amazon SageMaker Operators
https://amazonaws-china.com/blogs/machine-learning/simplify-machine-learning-inference-on-kubernetes-with-amazon-sagemaker-operators/
Amazon SageMaker Operators for Kubernetes allows you to augment your existing Kubernetes cluster with Amazon SageMaker hosted endpoints.
Machine learning inferencing requires investment to create a reliable and efficient service. For an XGBoost model, developers have to create an application, such as through Flask that will load the model and then run the endpoint, which requires developers to think about queue management, faultless deployment, and reloading of newly trained models. The serving container then has to be pushed to a Docker repository, where Kubernetes can be configured to pull from, and deploy on the cluster. These steps require your data scientist to work on tasks unrelated to improving model accuracy, or bringing in a dev ops engineer, which adds to development schedules and requires more time to iterate.
With the Amazon SageMaker Operators, developers only need to write a YAML file that specifies the S3 stored locations of the saved models, and live predictions become available through a secure endpoint. Reconfiguring the endpoint is as simple as updating the YAML file. On top of being easy to use, the service also has the following features:
- Multi-model endpoint – Host multiple models in one endpoint without additional cost
- Elastic Inference – Run your smaller workloads on split GPUs that you can deploy at low cost
- Dynamic Auto Scaling – Endpoints can adjust capacity based on the maximum number of instances that you provide
- Availability Zone Transfer – If there is an outage, Amazon SageMaker will automatically move your endpoint to another Availability Zone within your VPC
- A/B Testing – Set up multiple models, and direct traffic proportional to the amount that you set on a single endpoint
This post demonstrates how to set up Amazon SageMaker Operators for Kubernetes to create and update endpoints for a pre-trained XGBoost model completely from kubectl. The solution contains the following steps:
- Create an IAM Amazon SageMaker role, which gives Amazon SageMaker permissions needed to serve your model
- Prepare a YAML file that deploys your model to Amazon SageMaker
- Deploy your model to Amazon SageMaker
- Query the endpoint to obtain predictions
- Perform an eventually consistent update to the deployed model
Prerequisites
This post assumes you have the following prerequisites:
- A Kubernetes cluster
- The Amazon SageMaker Operators installed on your cluster
- An XGBoost model you can deploy
For information about installing the operator onto an Amazon EKS cluster, see Introducing Amazon SageMaker Operators for Kubernetes. You can bring your own XGBoost model, but this tutorial uses the existing model from the previously mentioned post.
Creating an Amazon SageMaker execution role
Amazon SageMaker needs an IAM role that it can assume to serve your model. If you do not have one already, create one with the following bash code:
export assume_role_policy_document=''{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {
"Service": "sagemaker.amazonaws.com"
},
"Action": "sts:AssumeRole"
}]
}''
aws iam create-role --role-name <execution role name> \
--assume-role-policy-document \
"$assume_role_policy_document"
aws iam attach-role-policy --role-name <execution role name> \
--policy-arn \
arn:aws:iam::aws:policy/AmazonSageMakerFullAccess
Replace <execution role name> with a suitable role name. This creates an IAM role that Amazon SageMaker can use to assume when serving your model.
Preparing your hosting deployment
The operators provide a Custom Resource Definition (CRD) named HostingDeployment. You use a HostingDeployment to configure your model deployment on Amazon SageMaker Hosting.
To prepare your hosting deployment, create a file called hosting.yaml with the following contents:
apiVersion: sagemaker.aws.amazon.com/v1
kind: HostingDeployment
metadata:
name: hosting-deployment
spec:
region: us-east-2
productionVariants:
- variantName: AllTraffic
modelName: xgboost-model
initialInstanceCount: 1
instanceType: ml.r5.large
initialVariantWeight: 1
models:
- name: xgboost-model
executionRoleArn: SAGEMAKER_EXECUTION_ROLE_ARN
containers:
- containerHostname: xgboost
modelDataUrl: s3://BUCKET_NAME/model.tar.gz
image: 825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest
Replace SAGEMAKER_EXECUTION_ROLE_ARN with the ARN of the execution role you created in the previous step. Replace BUCKET_NAME with the bucket that contains your model.
Make sure that the bucket Region, HostingDeployment Region, and image ECR Region are all equivalent.
Deploying your model to Amazon SageMaker
You can now start the deployment by running kubectl apply -f hosting.yaml. See the following code:
$ kubectl apply -f hosting.yaml
hostingdeployment.sagemaker.aws.amazon.com/hosting-deployment createdYou can track deployment status with kubectl get hostingdeployments. See the following code:
$ kubectl get hostingdeployments
NAME STATUS SAGEMAKER-ENDPOINT-NAME
hosting-deployment Creating hosting-deployment-38ecac47487611eaa81606fc3390e6baYour model endpoint may take up to fifteen minutes to be deployed. You can use the below command to view the status. The endpoint will be ready for queries once it achieves the InService status.
$ kubectl get hostingdeployments
NAME STATUS SAGEMAKER-ENDPOINT-NAME
hosting-deployment InService hosting-deployment-38ecac47487611eaa81606fc3390e6baQuerying the endpoint
After the endpoint is in service, you can test that it works with the following example code:
$ aws sagemaker-runtime invoke-endpoint \
--region us-east-2 \
--endpoint-name SAGEMAKER-ENDPOINT-NAME \
--body $(seq 784 | xargs echo | sed ''s/ /,/g'') \
>(cat) \
--content-type text/csv > /dev/nullThis bash command connects to the HTTPS endpoint using AWS CLI. The model you created is based on the MNIST digit dataset, and your predictor reads what number is in the image. When you make this call, it sends an inference payload that contains 784 features in CSV format, which represent pixels in an image. You see the predicted number that the model believes is in the payload. See the following code:
$ aws sagemaker-runtime invoke-endpoint \
--region us-east-2 \
--endpoint-name hosting-deployment-38ecac47487611eaa81606fc3390e6ba \
--body $(seq 784 | xargs echo | sed ''s/ /,/g'') \
>(cat) \
--content-type text/csv > /dev/null
8.0This confirms that your endpoint is up and running.
Eventually consistent updates
After you deploy a model, you can make changes to the Kubernetes YAML and the operator updates the endpoint. The updates propagate to Amazon SageMaker in an eventually consistent way. This enables you to configure your endpoints declaratively and lets the operator handle the details.
To demonstrate this, you can change the instance type of the model from ml.r5.large to ml.c5.2xlarge. Complete the following steps:
- Modify the instance type in
hosting.yamlto beml.c5.2xlarge. See the following code:apiVersion: sagemaker.aws.amazon.com/v1 kind: HostingDeployment metadata: name: hosting-deployment spec: region: us-east-2 productionVariants: - variantName: AllTraffic modelName: xgboost-model initialInstanceCount: 1 instanceType: ml.c5.2xlarge initialVariantWeight: 1 models: - name: xgboost-model executionRoleArn: SAGEMAKER_EXECUTION_ROLE_ARN containers: - containerHostname: xgboost modelDataUrl: s3://BUCKET_NAME/model.tar.gz image: 825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest - Apply the change to the Kubernetes cluster. See the following code:
$ kubectl apply -f hosting.yaml hostingdeployment.sagemaker.aws.amazon.com/hosting-deployment configured - Get the status of the hosting deployment. It will show as
Updatingand then change toInServicewhen ready. See the following code:$ kubectl get hostingdeployments NAME STATUS SAGEMAKER-ENDPOINT-NAME hosting-deployment Updating hosting-deployment-38ecac47487611eaa81606fc3390e6ba
The endpoint remains live and fully available throughout the update. For more information and additional examples, see the GitHub repo.
Cleaning up
To delete the endpoint, and not incur further usage charges, run kubectl delete -f hosting.yaml. See the following code:
$ kubectl delete -f hosting.yaml
hostingdeployment.sagemaker.aws.amazon.com "hosting-deployment" deletedConclusion
This post demonstrated how Amazon SageMaker Operators for Kubernetes supports real-time inference. It also supports training and hyperparameter tuning.
As always, please share your experience and feedback, or submit additional example YAML specs or operator improvements. You can share how you’re using Amazon SageMaker Operators for Kubernetes by posting on the AWS forum for Amazon SageMaker, creating issues in the GitHub repo, or sending it through your AWS Support contacts.
About the authors
 Cade Daniel is a Software Development Engineer with AWS Deep Learning. He develops products that make training and serving DL/ML models more efficient and easy for customers. Outside of work, he enjoys practicing his Spanish and learning new hobbies.
Cade Daniel is a Software Development Engineer with AWS Deep Learning. He develops products that make training and serving DL/ML models more efficient and easy for customers. Outside of work, he enjoys practicing his Spanish and learning new hobbies.
 Alex Chung is a Senior Product Manager with AWS in Deep Learning. His role is to make AWS Deep Learning products more accessible and cater to a wider audience. He’s passionate about social impact and technology, getting his regular gym workout, and cooking healthy meals.
Alex Chung is a Senior Product Manager with AWS in Deep Learning. His role is to make AWS Deep Learning products more accessible and cater to a wider audience. He’s passionate about social impact and technology, getting his regular gym workout, and cooking healthy meals.

175+ Customers Achieve Machine Learning Success with AWS’s Machine Learning Solutions Lab
https://amazonaws-china.com/blogs/machine-learning/175-customers-achieve-machine-learning-success-with-awss-machine-learning-solutions-lab/
AWS introduced the Machine Learning (ML) Solutions Lab a little over two years ago to connect our machine learning experts and data scientists with AWS customers. Our goal was to help our customers solve their most pressing business problems using ML. We’ve helped our customers increase fraud detection rates, improved forecasting and predictions for more efficient operations, drive additional revenues through personalization, and even help organizations scale their response to crisis like human trafficking.
Since we began, we’ve successfully assisted over 175 customers across a diverse spectrum of industries including retail, healthcare, energy, public sector and sports to create new machine learning-powered solutions. And we’ve increased our capacity more than 5x and expanded from North America to Asia, Australia and Europe to meet the growing ML needs of our customers around the world.
In our partnership with the National Football League (NFL), we’ve identified and built an entirely new way for fans to engage with the sport through Next Gen Stats, which features stats such as Completion Probability, 3rd Down Conversion Probability, Expected Yards After Catch, Win Probability, and Catch Prediction. Today, Next Gen Stats are an important part of how fans experience the game. And recently we’ve kicked off a new initiative with the NFL to tackle the next challenge—predicting and limiting player injury. As part of this initiative we’re working with the NFL to develop the “Digital Athlete”, a virtual representation of a composite NFL player which will enable us to eventually predict injury and recovery trajectories
In healthcare, we’re working with Cerner, the world’s largest publicly traded healthcare IT company, to apply machine learning-driven solutions to its mission of improving the health of individuals and populations while reducing costs and increasing clinician satisfaction. One important area of this project is using health prediction capabilities to uncover important and potentially life-saving insights within trusted-source, digital health data. For example, using Amazon SageMaker we built a solution to enable researchers to query anonymized patient data to build complex models and algorithms that predicts congestive heart failure up to 15 months before clinical manifestation. And Cerner will also be using AWS AI services such as the newly introduced Amazon Transcribe Medical to free up physicians from tasks such as writing down notes through a virtual scribe.
In the public sector, we collaborated with the NASA Heliophysics Lab to better understand solar super storms. We brought together the expert scientists at NASA with the machine learning experts in the ML Solutions Lab and the AWS Professional Services organizations to improve the ability to predict and categorize solar super storms. With Amazon SageMaker, NASA is using unsupervised learning and anomaly detection to explore the extreme conditions associated with super storms. Such space weather can create radiation hazards for astronauts, cause upsets in satellite electronics, interfere with airplane and shipping radio communications, and damage electric power grids on the ground – making prediction and early warnings critical.
World Kinect Energy Services, a global leader in energy management, fuel supply, and sustainability, turned to the ML Solutions Lab to improve their ability to anticipate the impact of weather changes on energy prices. An important piece of their business model involves trading financial contracts derived from energy prices. This requires an accurate forecast of the energy price. To improve and automate the process of forecasting—historically done manually—we collaborated with them to develop a model using Amazon SageMaker to predict the upcoming weather trends and therefore the prices of future months’ electricity, enabling unprecedented long-range energy trading. By using a deep learning forecasting model to replace the old manual process, World Kinect Energy Services improves their hedging strategy. With the current results, the team is now adding additional signals focused on trend and volatility and is on its way to realizing an accuracy of greater than 60% over the manual process.
And in manufacturing, we worked with Formosa Plastics, one of Taiwan’s top petrochemical companies and a leading plastics manufacturers, to apply ML to more accurately detect defects and reduce manual labor costs. Formosa Plastics needed to ensure the highest Silicon Wafer quality, but the defect inspection process was time consuming and required time from a highly experienced engineers.
Together with the ML Solutions Lab, Fromosa Plastics created and deployed a model using Amazon SageMaker to automatically detect defects. The model reduced their employee time spent doing manual inspection in half and increased the accuracy of detection.
Energized by the progress our customers have made and listening closely to their needs, we continue to increase our capacity to support even more customers seeking Amazon’s expertise in ML. And we recently introduced a new program, AWS Machine Learning Embark program, which combines workshops, on-site training, an ML Solutions Lab engagement, and an AWS DeepRacer event to help organizations fast-track their adoption of ML.
We started the ML Solutions Lab because we believe machine learning has the ability to transform every industry, process, and business, but the path to machine learning success is not always straightforward. Many organizations need a partner to help them along their journey. Amazon has been investing in machine learning for more than 20 years, innovating in areas such as fulfilment and logistics, personalization and recommendations, forecasting, robotics and automation, fraud prevention, and supply chain optimization. We bring the learnings from this experience to every customer engagement. We’re excited to be a part of our customers’ adoption of this transformational technology, and we look forward to another year of working hand in hand with our customers to find the most impactful ML use cases for their organization. To learn more about the AWS Machine Learning Solutions Lab contact your account manager or visit us at https://aws.amazon.com/ml-solutions-lab/.
About the Author
Michelle K. Lee, Vice President of the Machine Learning Solutions Lab, AWS

Analyzing chest X-ray images with machine learning
Analyzing chest X-ray images with machine learning algorithms is easier said than done. That’s because typically, the clinical labels required to train those algorithms are obtained with rule-based natural language processing or human annotation, both of which tend to introduce inconsistencies and errors. Additionally, it’s challenging to assemble data sets that represent an adequately diverse spectrum of cases, and to establish clinically meaningful and consistent labels given only images.

In an effort to move forward the goalpost with respect to X-ray image classification, researchers at Google devised AI models to spot four findings on human chest X-rays: pneumothorax (collapsed lungs), nodules and masses, fractures, and airspace opacities (filling of the pulmonary tree with material). In a paper published in the journal Nature, the team claims the model family, which was evaluated using thousands of images across data sets with high-quality labels, demonstrated “radiologist-level” performance in an independent review conducted by human experts.
The study’s publication comes months after Google AI and Northwestern Medicine scientists created a model capable of detecting lung cancer from screening tests better than human radiologists with an average of eight years experience, and roughly a year after New York University used Google’s Inception v3 machine learning model to detect lung cancer. AI also underpins the Topplay tech giant’s advances in diabetic retinopathy diagnosis through eye scans, as well as Alphabet subsidiary DeepMind’s AI that can recommend the proper line of treatment for 50 eye diseases with 94% accuracy.
This newer work tapped over 600,000 images sourced from two de-identified data sets, the first of which was developed in collaboration with Apollo Hospitals and which consists of X-rays collected over years from multiple locations. As for the second corpus, it’s the publicly available ChestX-ray14 image set released by the National Institutes of Health, which has historically served as a resource for AI efforts but which suffers shortcomings in accuracy.

augemtation 错误,tensorflow.python.keras.preprocessing.image.ImageDataGenerator
如何解决augemtation 错误,tensorflow.python.keras.preprocessing.image.ImageDataGenerator?
未能找到可以处理输入的数据适配器:<class ''tensorflow.python.keras.preprocessing.image.ImageDataGenerator''>,<class ''nonetype''>
我正在尝试实现深度学习模型并且我已经运行了 10 多次代码,有时在 41,72,88,100 epoch 我遇到了这个错误,有没有人可以帮助我
def Tuning_Model():
for k in range(FOLDS):
timestamp = datetime.fromtimestamp(time()).strftime(''%Y%m%d-%H%M%s'')
output_directory = model_path + "\\" + timestamp
if not os.path.exists(output_directory):
os.makedirs(output_directory)
# Training image augmentation
train_data_generator =tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1. / 255,fill_mode="constant",shear_range=0.2,zoom_range=(0.5,1),horizontal_flip=True,rotation_range=360,channel_shift_range=25,brightness_range=(0.75,1.25))
# Validation image augmentation
val_data_generator =tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1. / 255,1.25))
test_data_generator =tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
train_data_generator = train_data_generator.flow_from_directory(
train_data_path,target_size = RAW_IMG_SIZE,batch_size = BATCH_SIZE,class_mode =''categorical''
)
val_data_generator = val_data_generator.flow_from_directory(
val_data_path,class_mode = ''categorical'')
test_data = test_data_generator.flow_from_directory(
test_data_path,target_size = IMG_SIZE,class_mode = ''categorical'',shuffle = False)
train_data_generator = crop_generator(train_data_generator,IMG_SIZE)
val_data_generator = crop_generator(val_data_generator,IMG_SIZE)
model = Build_Model(model_name)
model_checkpoint = ModelCheckpoint(output_directory + "\\best_model.hdf5",verbose=1,save_best_only=True)
early_stopping = EarlyStopping(patience=STOPPING_PATIENCE,restore_best_weights=True)
reduce_lr = ReduceLROnPlateau(''val_loss'',factor=0.5,patience=LR_PATIENCE,min_lr=0.000003125)
model.compile(loss=''binary_crossentropy'',optimizer=Adam(lr=INITIAL_LR),metrics=[''categorical_accuracy''])
history = model.fit_generator(
generator = train_data_generator,steps_per_epoch = train_image_count // BATCH_SIZE,epochs = epochs,validation_data = val_data_generator,validation_steps= val_image_count // BATCH_SIZE,callbacks = [model_checkpoint,early_stopping,reduce_lr],shuffle = False)
# Load the last best model
model = load_model(
output_directory + "\\best_model.hdf5")
# Evaluate model on test set
predictions = model.predict_generator(test_data_generator,test_image_count // BATCH_SIZE + 1)
y_true = test_data_generator.classes
y_pred = np.argmax(predictions,axis=1)
print(classification_report(y_true,y_pred,labels=CLASSES,target_names=CLASS_NAMES))
report = classification_report(y_true,target_names=CLASS_NAMES,output_dict=True)
with open(output_directory + ''\\classification_report.csv'',''w'') as f:
for key in report.keys():
f.write("%s,%s\n" % (key,report[key]))
conf_arr = confusion_matrix(y_true,labels=CLASSES)
print(conf_arr)
np.savetxt(output_directory + "\\confusion_matrix.csv",conf_arr,delimiter=",")
# Clear model from GPU after each iteration
print("Finished testing fold {}\n".format(k + 1))
K.clear_session()
k = k + 1
if __name__ == ''__main__'':
Tuning_Model()
ValueError: Failed to find data adapter that can handle input: <class ''tensorflow.python.keras.preprocessing.image.ImageDataGenerator''>,<class ''nonetype
解决方法
在拟合模型之前,您是否检查过训练/测试数据是否为 numpy 数组的形式?
也可能是这样,您从 keras 导入模型,例如 keras.Sequential(),但从 Tensorflow 导入生成器,例如 tf.keras.preprocessing.image.ImageDataGenerator()。

Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age
https://amazonaws-china.com/blogs/apn/automated-refactoring-from-mainframe-to-serverless-functions-and-containers-with-blu-age/
By Alexis Henry, Chief Technology Officer at Blu Age
By Phil de Valence, Principal Solutions Architect for Mainframe Modernization at AWS
 |
 |
Mainframe workloads are often tightly-coupled legacy monoliths with millions of lines of code, and customers want to modernize them for business agility.
Manually rewriting a legacy application for a cloud-native architecture requires re-engineering use cases, functions, data models, test cases, and integrations. For a typical mainframe workload with millions of lines of code, this involves large teams over long periods of time, which can be risky and cost-prohibitive.
Fortunately, Blu Age Velocity accelerates the mainframe transformation to agile serverless functions or containers. It relies on automated refactoring and preserves the investment in business functions while expediting the reliable transition to newer languages, data stores, test practices, and cloud services.
Blu Age is an AWS Partner Network (APN) Select Technology Partner that helps organizations enter the digital era by modernizing legacy systems while substantially reducing modernization costs, shortening project duration, and mitigating the risk of failure.
In this post, we’ll describe how to transform a typical mainframe CICS application to Amazon Web Services (AWS) containers and AWS Lambda functions. We’ll show you how to increase mainframe workload agility with refactoring to serverless and containers.
Customer Drivers
There are two main drivers for mainframe modernization with AWS: cost reduction and agility. Agility has many facets related to the application, underlying infrastructure, and modernization itself.
On the infrastructure agility side, customers want to go away from rigid mainframe environments in order to benefit from the AWS Cloud’s elastic compute, managed containers, managed databases, and serverless functions on a pay-as-you-go model.
They want to leave the complexity of these tightly-coupled systems in order to increase speed and adopt cloud-native architectures, DevOps best practices, automation, continuous integration and continuous deployment (CI/CD), and infrastructure as code.
On the application agility side, customers want to stay competitive by breaking down slow mainframe monoliths into leaner services and microservices, while at the same time unleashing the mainframe data.
Customers also need to facilitate polyglot architectures where development teams decide on the most suitable programming language and stack for each service.
Some customers employ large teams of COBOL developers with functional knowledge that should be preserved. Others suffer from the mainframe retirement skills gap and have to switch to more popular programming languages quickly.
Customers also require agility in the transitions. They want to choose when and how fast they execute the various transformations, and whether they’re done simultaneously or independently.
For example, a transition from COBOL to Java is not only a technical project but also requires transitioning code development personnel to the newer language and tools. It can involve retraining and new hiring.
A transition from mainframe to AWS should go at a speed which reduces complexity and minimizes risks. A transition to containers or serverless functions should be up to each service owner to decide. A transition to microservices needs business domain analysis, and consequently peeling a monolith is done gradually over time.
This post shows how Blu Age automated refactoring accelerates the customer journey to reach a company’s desired agility with cloud-native architectures and microservices. Blu Age does this by going through incremental transitions at a customer’s own pace.
Sample Mainframe COBOL Application
Let’s look at a sample application of a typical mainframe workload that we will then transform onto AWS.
This application is a COBOL application that’s accessed by users via 3270 screens defined by CICS BMS maps. It stores data in a DB2 z/OS relational database and in VSAM indexed files, using CICS Temporary Storage (TS) queues.
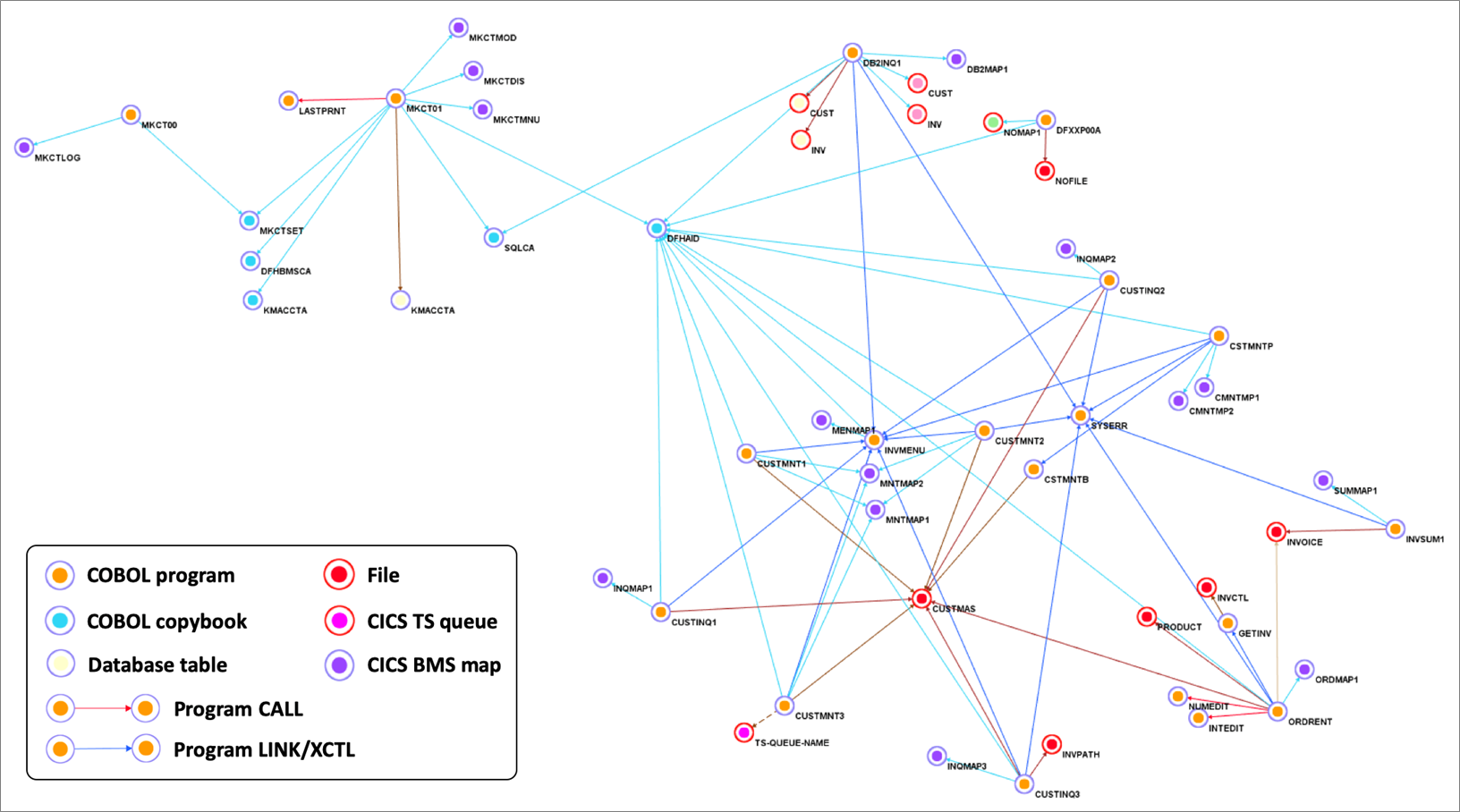
Figure 1 – Sample COBOL CICS application showing file dependencies.
We use Blu Age Analyzer to visualize the application components such as programs, copybooks, queues, and data elements.
Figure 1 above shows the Analyzer display. Each arrow represents a program call or dependency. You can see the COBOL programs using BMS maps for data entry and accessing data in DB2 database tables or VSAM files.
You can also identify the programs which are data-independent and those which access the same data file. This information helps define independent groupings that facilitate the migration into smaller services or even microservices.
This Analyzer view allows customers to identify the approach, groupings, work packages, and transitions for the automated refactoring.
In the next sections, we describe how to do the groupings and the transformation for three different target architectures: compute with Amazon Elastic Compute Cloud (Amazon EC2), containers with Amazon Elastic Kubernetes Service (Amazon EKS), and serverless functions with AWS Lambda.
Automated Refactoring to Elastic Compute
First, we transform the mainframe application to be deployed on Amazon EC2. This provides infrastructure agility with a large choice of instance types, horizontal scalability, auto scaling, some managed services, infrastructure automation, and cloud speed.
Amazon EC2 also provides some application agility with DevOps best practices, CI/CD pipeline, modern accessible data stores, and service-enabled programs.
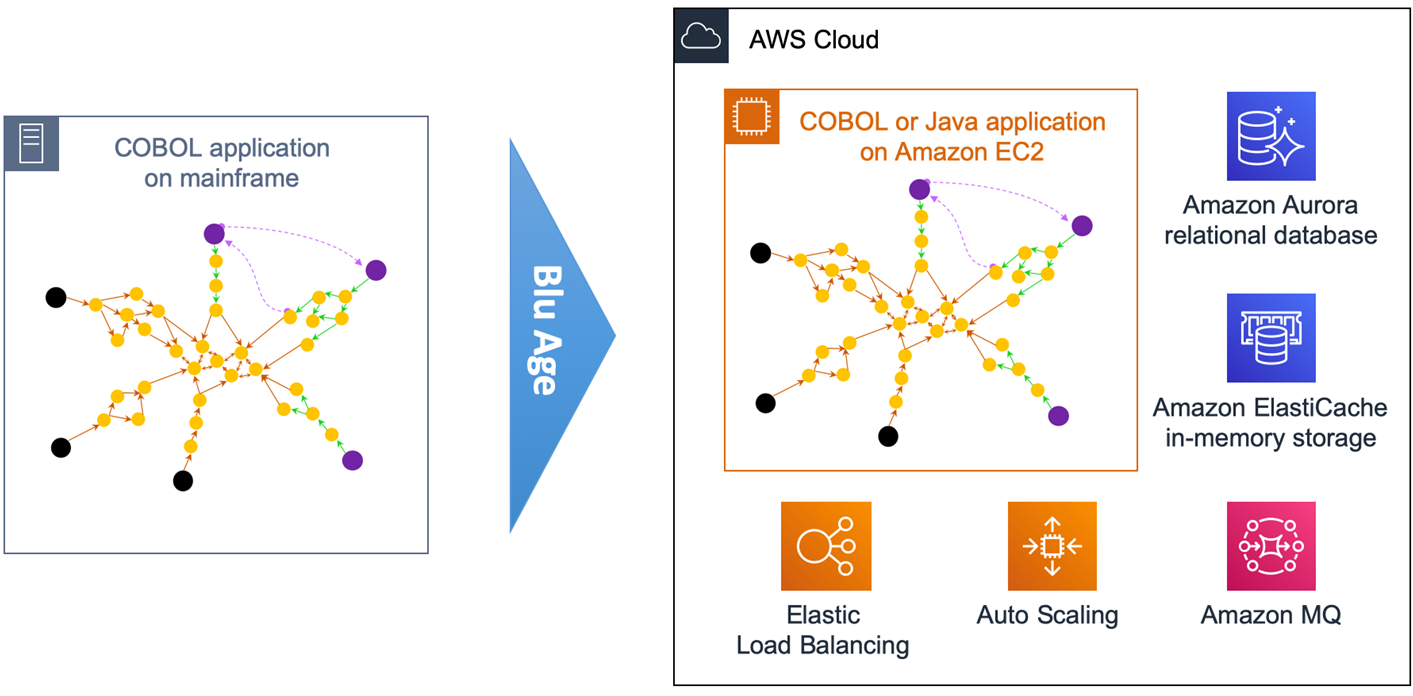
Figure 2 – Overview of automated refactoring from mainframe to Amazon EC2.
Figure 2 above shows the automated refactoring of the mainframe application to Amazon EC2.
The DB2 tables and VSAM files are refactored to Amazon Aurora relational database. Amazon ElastiCache is used for in-memory temporary storage or for performance acceleration, and Amazon MQ takes care of the messaging communications.
Once refactored, the application becomes stateless and elastic across many duplicate Amazon EC2 instances that benefit from Auto Scaling Groups and Elastic Load Balancing (ELB). The application code stays monolithic in this first transformation.
With such monolithic transformation, all programs and dependencies are kept together. That means we create only one grouping.
Figure 3 below shows the yellow grouping that includes all application elements. Using Blu Age Analyzer, we define groupings by assigning a common tag to multiple application elements.
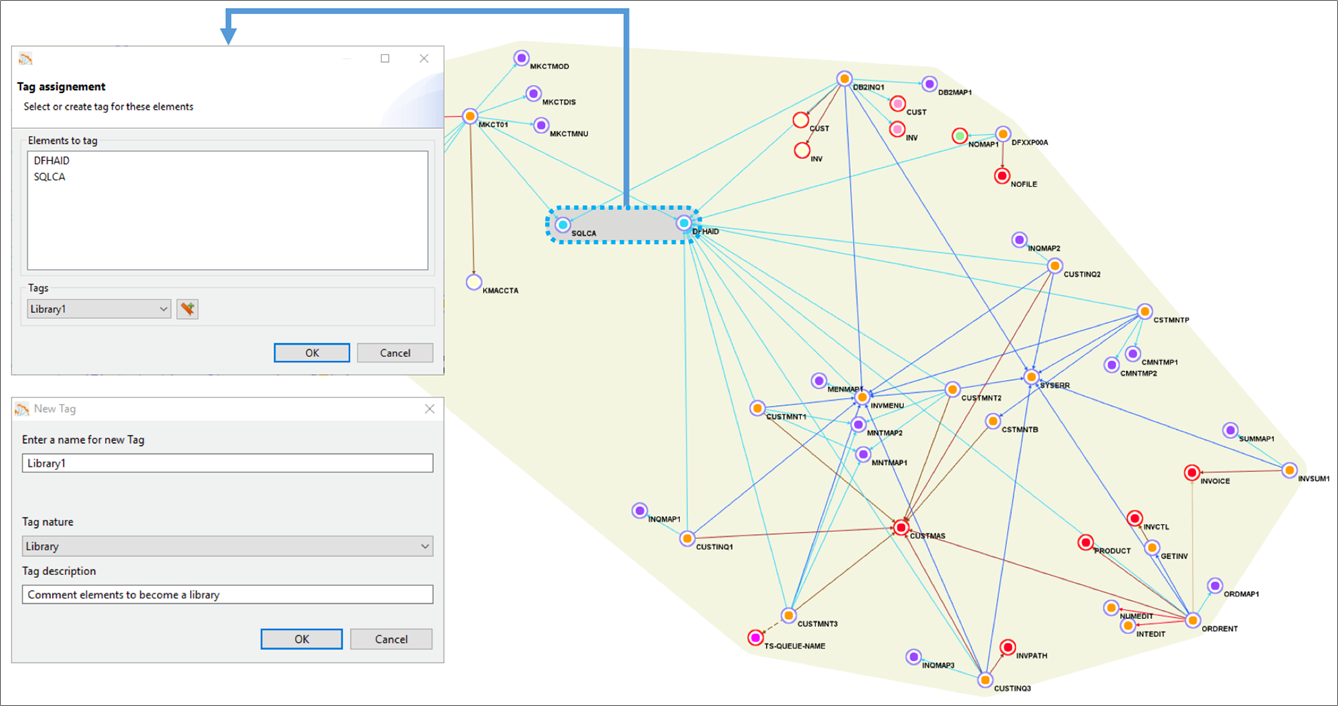
Figure 3 – Blu Age Analyzer with optional groupings for work packages and libraries.
With larger applications, it’s very likely we’d break down the larger effort by defining incremental work packages. Each work package is associated with one grouping and one tag.
Similarly, some shared programs or copybooks can be externalized and shared using a library. Each library is associated with one grouping and one tag. For example, in Figure 3 one library is created based on two programs, as shown by the grey grouping.
Ultimately, once the project is complete, all programs and work packages are deployed together within the same Amazon EC2 instances.
For each tag, we then export the corresponding application elements to Git.
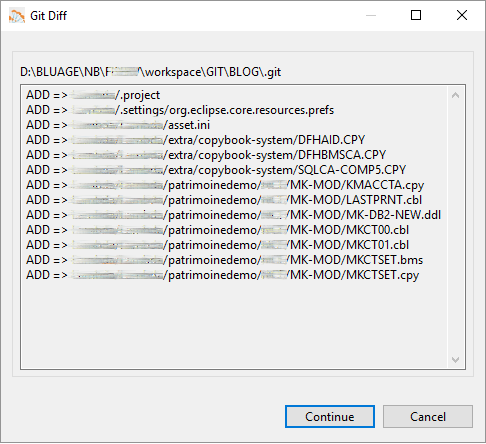
Figure 4 – Blu Age Analyzer export to Git.
Figure 4 shows the COBOL programs, copybooks, DB2 Data Definition Language (DDL), and BMS map being exported to Git.
As you can see in Figure 5 below, the COBOL application elements are available in the Integrated Development Environment (IDE) for maintenance, or for new development and compilation.
Blu Age toolset allows maintaining the migrated code in either in COBOL or in Java.
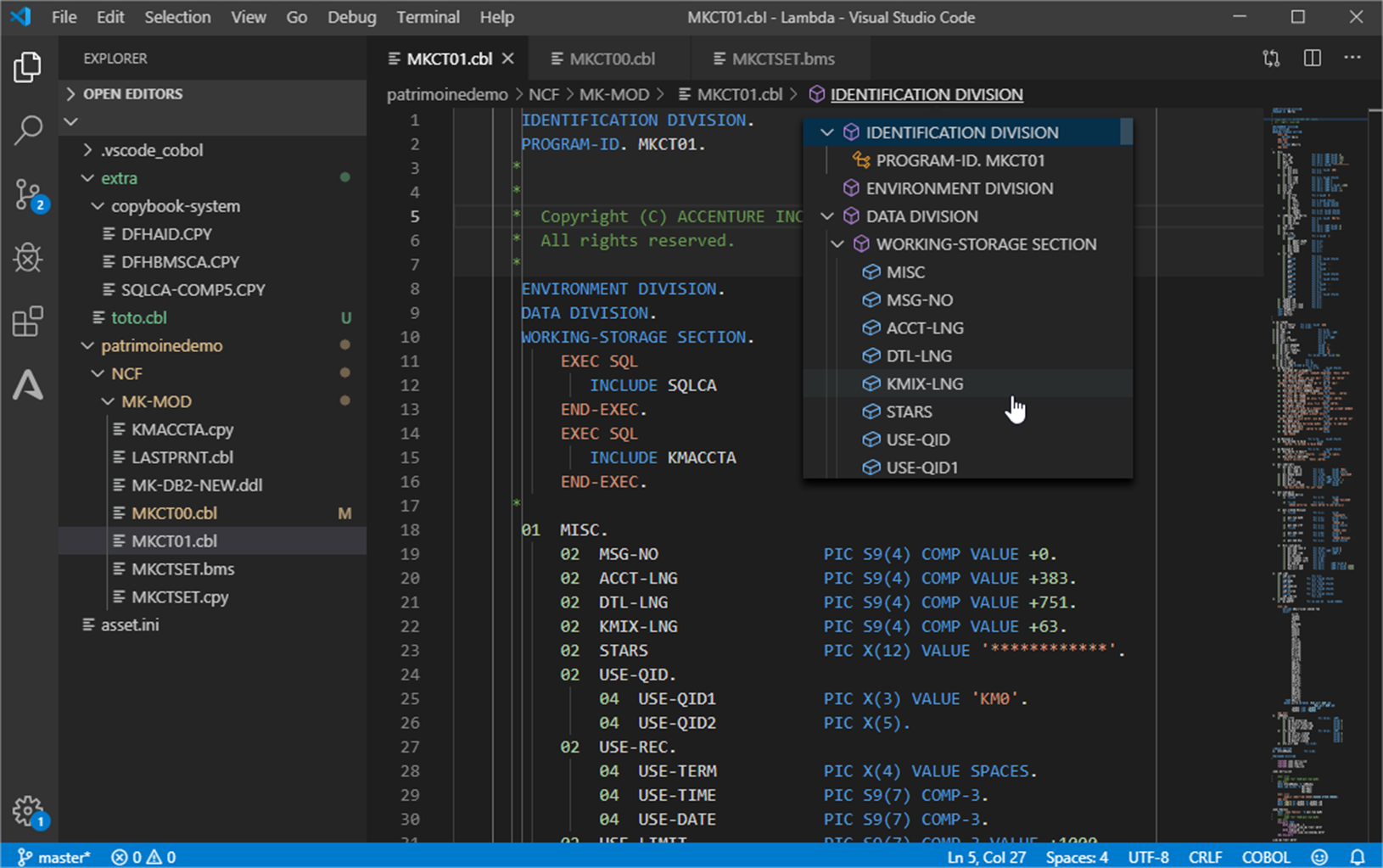
Figure 5 – Integrated Development Environment with COBOL application.
The code is recompiled and automatically packaged for the chosen target Amazon EC2 deployment.
During this packaging, the compute code is made stateless with any shared or persistent data externalized to data stores. This follows many of The Twelve-Factor App best practices that enable higher availability, scalability, and elasticity on the AWS Cloud.
In parallel, based on the code refactoring, the data from VSAM and DB2 z/OS is converted to the PostgreSQL-compatible edition of Amazon Aurora with corresponding data access queries conversions. Blu Age Velocity also generates the scripts for data conversion and migration.
Once deployed, the code and data go through unit, integration, and regression testing in order to validate functional equivalence. This is part of an automated CI/CD pipeline which also includes quality and security gates. The application is now ready for production on elastic compute.
Automated Refactoring to Containers
In this section, we increase agility by transforming the mainframe application to be deployed as different services in separate containers managed by Amazon EKS.
The application agility increases because the monolith is broken down into different services that can evolve and scale independently. Some services execute online transactions for users’ direct interactions. Some services execute batch processing. All services run in separate containers in Amazon EKS.
With such an approach, we can create microservices with both independent data stores and independent business functionalities. Read more about How to Peel Mainframe Monoliths for AWS Microservices with Blu Age.
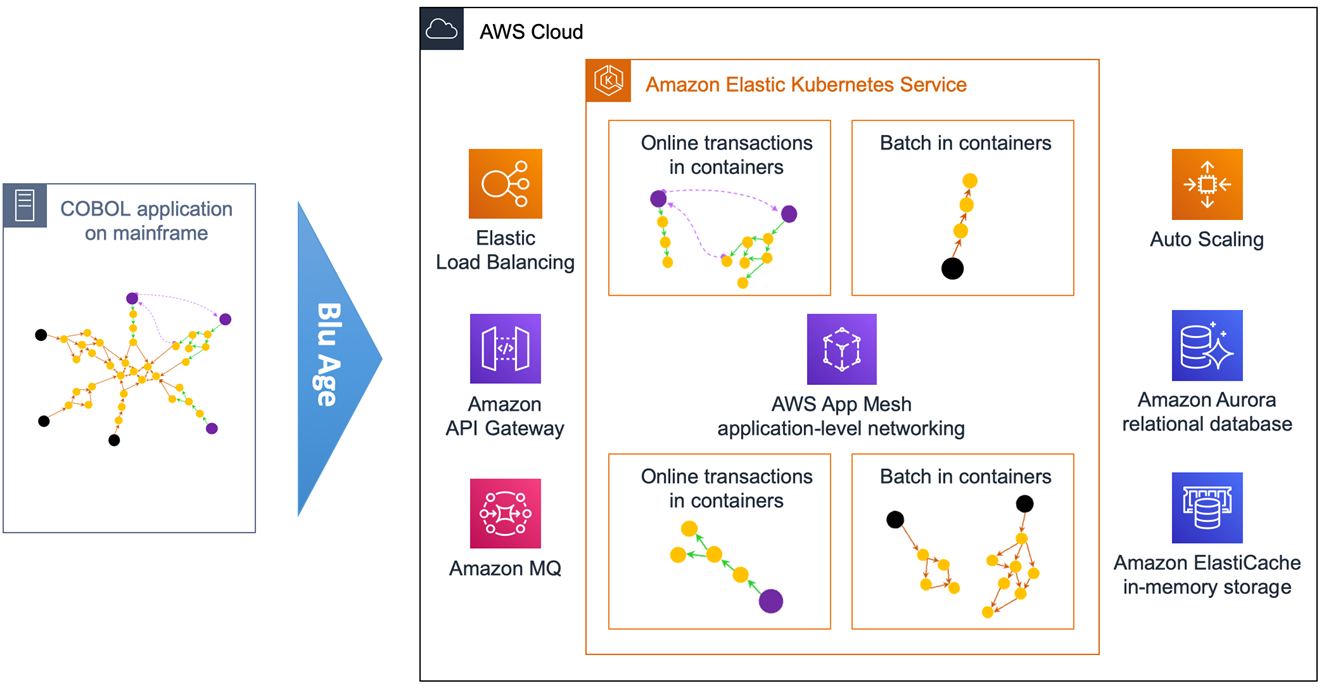
Figure 6 – Overview of automated refactoring from mainframe to Amazon EKS.
Figure 6 shows the automated refactoring of the mainframe application to Amazon EKS. You could also use Amazon Elastic Container Service (Amazon ECS) and AWS Fargate.
The mainframe application monolith is broken down targeting different containers for various online transactions, and different containers for various batch jobs. Each service DB2 tables and VSAM files are refactored to their own independent Amazon Aurora relational database.
AWS App Mesh facilitates internal application-level communication, while Amazon API Gateway and Amazon MQ focus more on the external integration.
With the Blu Age toolset, some services can still be maintained and developed in COBOL while others can be maintained in Java, which simultaneously allows a polyglot architecture.
For the application code maintained in COBOL on AWS, Blu Age Serverless COBOL provides native integration COBOL APIs for AWS services such as Amazon Aurora, Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB, Amazon ElastiCache, and Amazon Kinesis, among others.
With such refactoring, programs and dependencies are grouped into separate services. This is called service decomposition and means we create multiple groupings in Blu Age Analyzer.
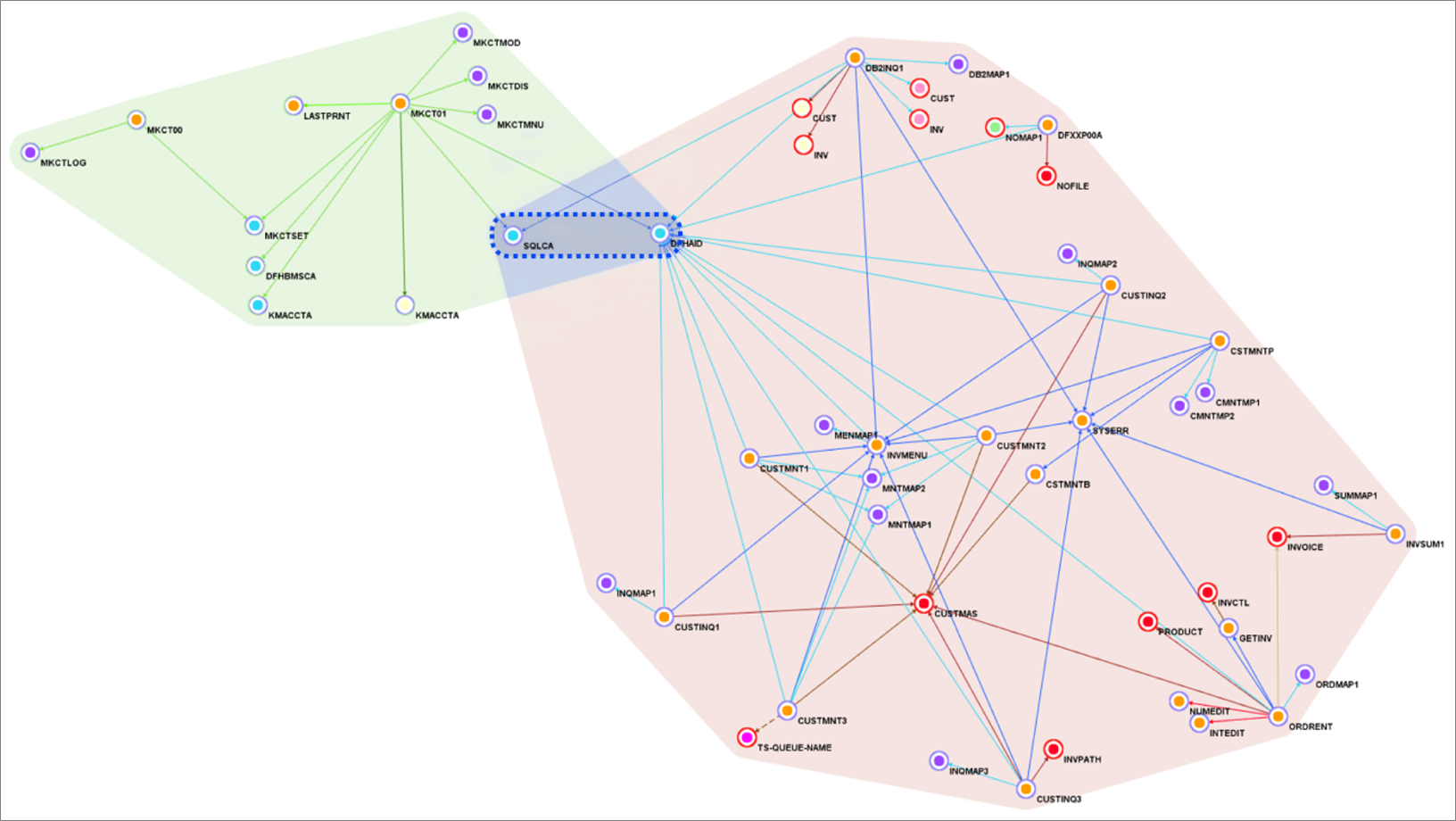
Figure 7 – Blu Age Analyzer with two services groupings and one library grouping.
Figure 7 shows one service grouping in green, another service grouping in rose, and a library grouping in blue. Groupings are formalized with one tag each.
For each tag, we export the corresponding application elements to Git and open them in the IDE for compilation. We can create one Git project per tag providing independence and agility to individual service owner.
Figure 8 – COBOL program in IDE ready for compilation.
The Blu Age compiler for containers compiles the code and packages it into a Docker container image with all the necessary language runtime configuration for deployment and services communication.
The REST APIs for communication are automatically generated. The container images are automatically produced, versioned and stored into Amazon Elastic Container Registry (Amazon ECR), and the two container images are deployed onto Amazon EKS.
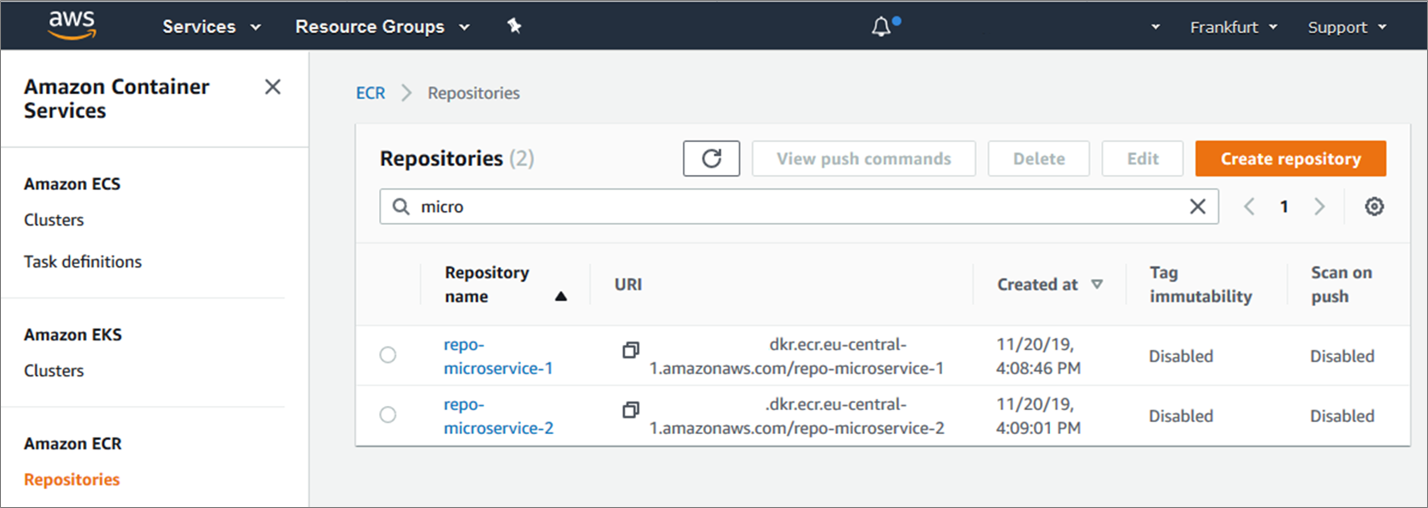
Figure 9 – AWS console showing the two container images created in Amazon ECR.
Figure 9 above shows the two new Docker container images referenced in Amazon ECR.
After going through data conversion and extensive testing similar to the previous section, the application is now ready for production on containers managed by Amazon EKS.
Automated Refactoring to Serverless Functions
Now, we can increase agility and cost efficiency further by targeting serverless functions in AWS Lambda.
Not only is the monolith broken down into separate services, but the services become smaller functions with no need to manage servers or containers. With Lambda, there’s no charge when the code is not running.
Not all programs are good use-cases for Lambda. Technical characteristics make Lambda better suited for short-lived lightweight stateless functions. For this reason, some services are deployed in Lambda while others are still deployed in containers or elastic compute.
For example, long-running batch processing cannot run in Lambda but they can run in containers. Online transactions or batch-specific short functions, on the other hand, can run in Lambda.
With this approach, we can create granular microservices with independent data stores and business functions.
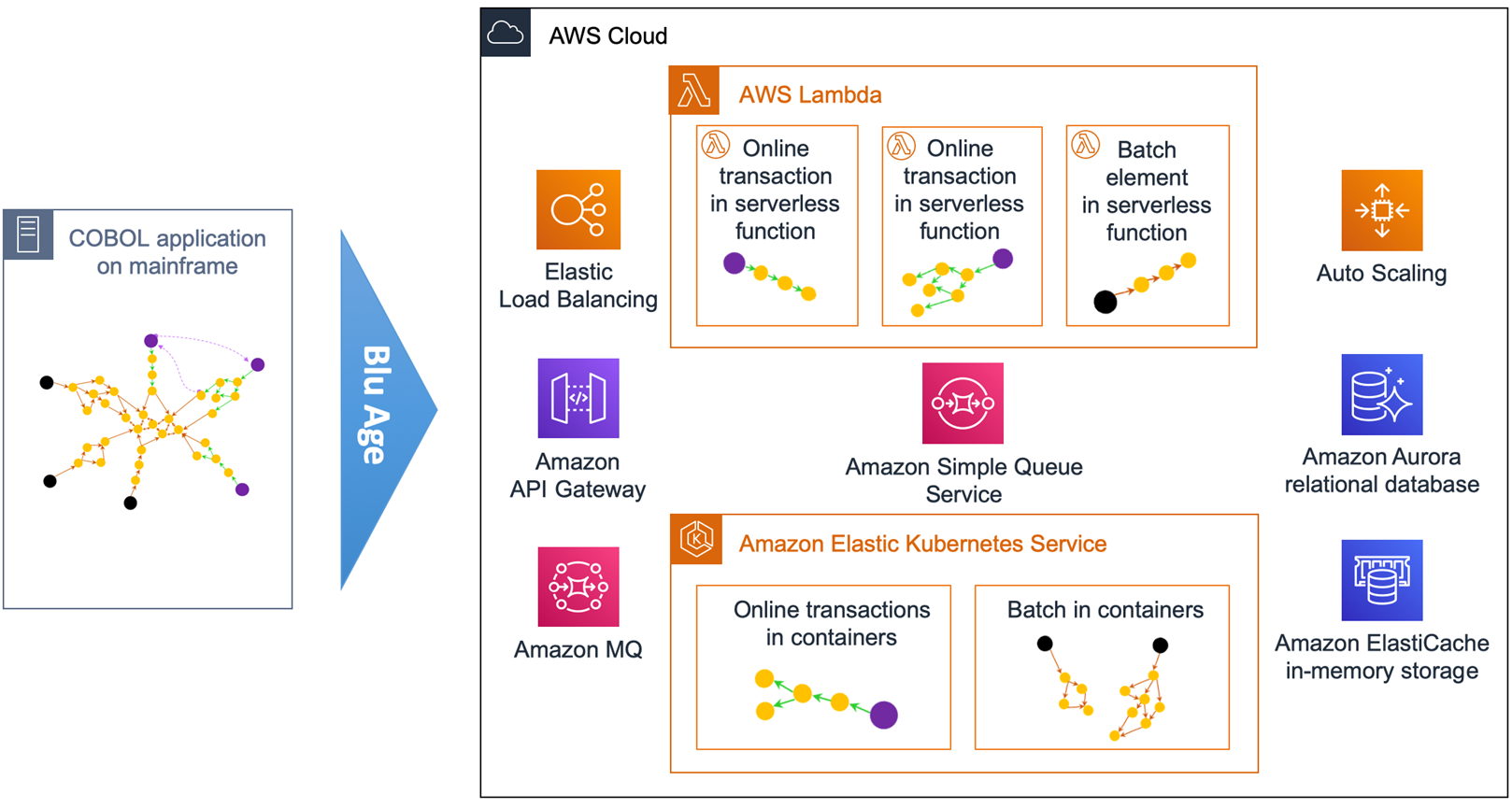
Figure 10 – Overview of automated refactoring from mainframe to AWS Lambda.
Figure 10 shows the automated refactoring of the mainframe application to Lambda and Amazon EKS. Short-lived stateless transactions and programs are deployed in Lambda, while long-running or unsuitable programs run in Docker containers within Amazon EKS.
Amazon Simple Queue Service (SQS) is used for service calls within or across Lambda and Amazon EKS. Such architecture is similar to a cloud-native application architecture that’s much better positioned in the Cloud-Native Maturity Model.
With this refactoring, programs and dependencies are grouped into more separate services in Blu Age Analyzer.
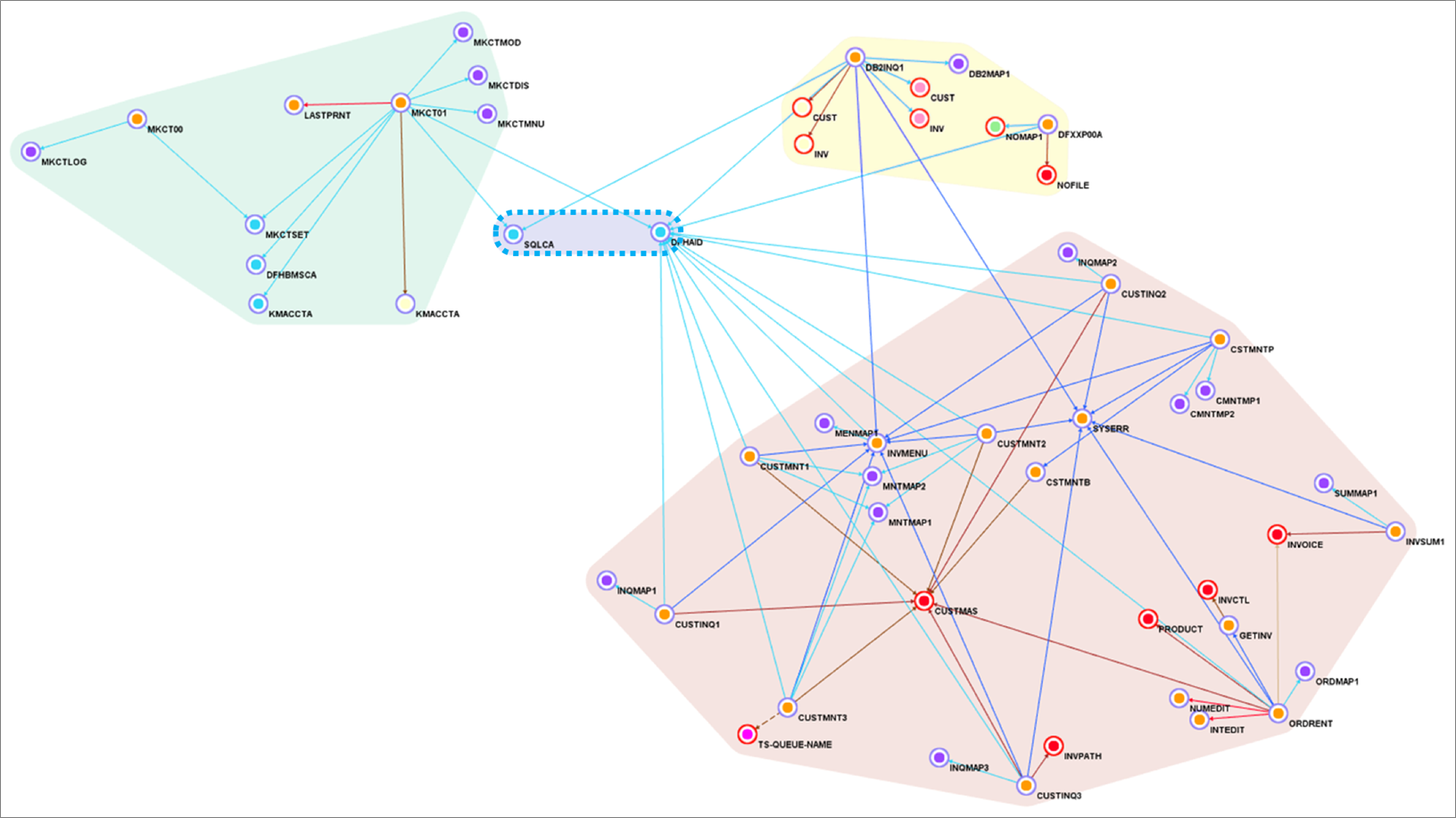
Figure 11 – Blu Age Analyzer with two AWS Lambda groupings, on container grouping and one library grouping.
In Figure 11 above, the green grouping and yellow grouping are tagged for Lambda deployment. The rose grouping stays tagged for container deployment, while the blue grouping stays a library. Same as before, the code is exported tag after tag into Git, then opened within the IDE for compilation.
The compilation and deployment for Lambda does not create a container image, but it creates compiled code ready to be deployed on Blu Age Serverless COBOL layer for Lambda.
Here’s the Serverless COBOL layer added to the deployed functions.
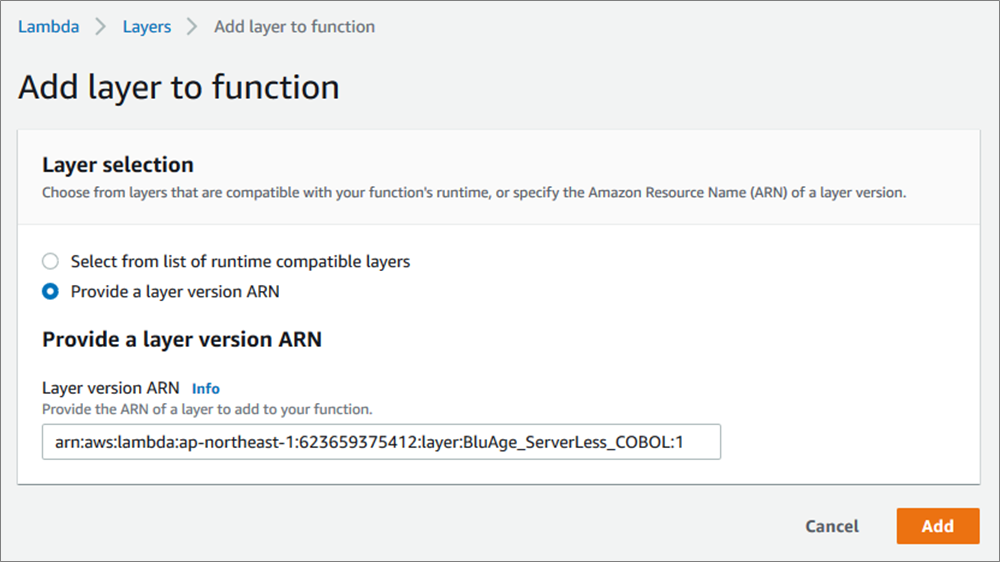
Figure 12 – Blu Age Serverless COBOL layer added to AWS Lambda function.
Now, here’s the two new Lambda functions created once the compiled code is deployed.

Figure 13 – AWS console showing the two AWS Lambda functions created.
After data conversion and thorough testing similar to the previous sections, the application is now ready for production on serverless functions and containers.
With business logic in Lambda functions, this logic can be invoked from many sources (REST APIs, messaging, object store, streams, databases) for innovations.
Incremental Transitions
Automated refactoring allows customers to accelerate modernization and minimize project risks on many dimensions.
On one side, the extensive automation for the full software stack conversion including code, data formats, dependencies provides functional equivalence preserving core business logic.
On the other side, the solution provides incremental transitions and accelerators tailored to the customer constraints and objectives:
- Incremental transition from mainframe to AWS: As shown with Blu Age Analyzer, a large application migration is piece-mealed into small work packages with coherent programs and data elements. The migration does not have to be a big bang, and it can be executed incrementally over time.
. - Incremental transition from COBOL to Java: Blu Age compilers and toolset supports maintaining the application code either in the original COBOL or Java.
.
All the deployment options described previously can be maintained similarly in COBOL or in Java and co-exist. That means you can choose to keep developing in COBOL if appropriate, and decide to start developing in Java when convenient facilitating knowledge transfer between developers.
. - Incremental transition from elastic compute, to containers, to functions: Some customers prefer starting with elastic compute, while others prefer jumping straight to containers or serverless functions. Blu Age toolset has the flexibility to switch from one target to the other following the customer specific needs.
. - Incremental transition from monolith to services and microservices: Peeling a large monolith is a long process, and the monolith can be kept and deployed on the various compute targets. When time comes, services or microservices are identified in Blu Age Analyzer, and then extracted and deployed on elastic compute, containers, or serverless functions.
From a timeline perspective, the incremental transition from mainframe to AWS is a short-term project with achievable return on investment, as shown on Figure 14.
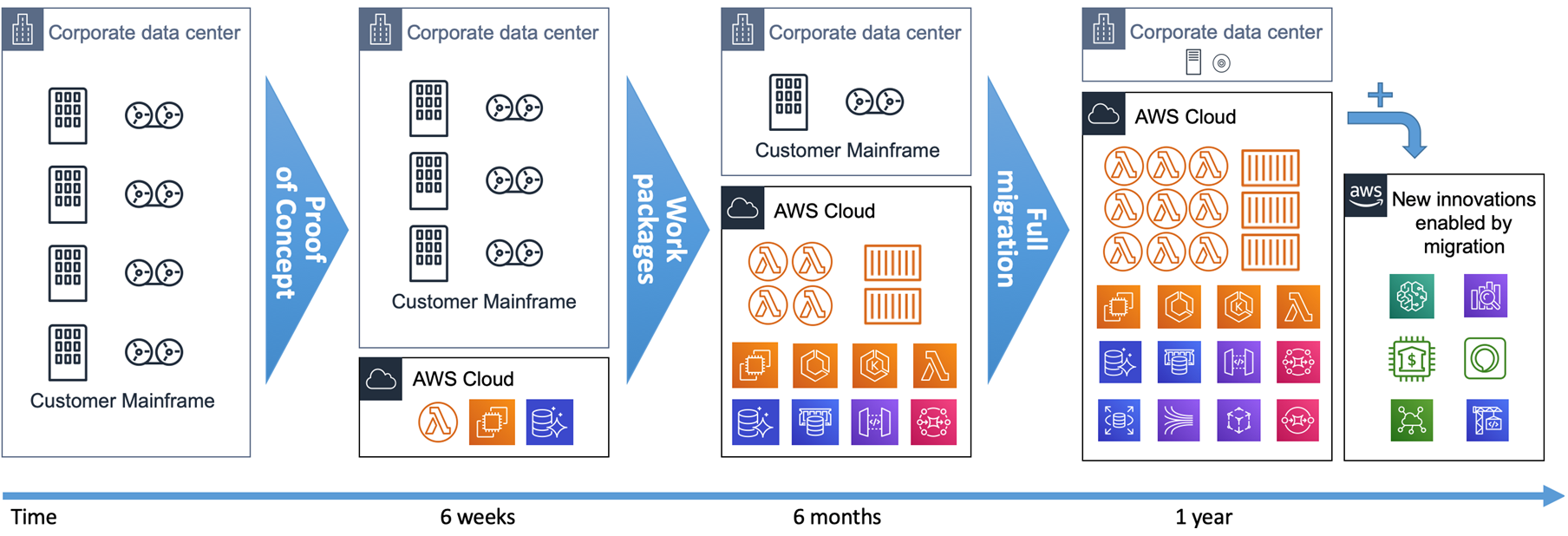
Figure 14 – Mainframe to AWS transition timeline.
We recommend starting with a hands-on Proof-of-Concept (PoC) with customers’ real code. It’s the only way to prove the technical viability and show the outcome quality within 6 weeks.
Then, you can define work packages and incrementally refactor the mainframe application to AWS targeting elastic compute, containers, or serverless functions.
The full refactoring of a mainframe workload onto AWS can be completed in a year. As soon as services are refactored and in production on AWS, new integrations and innovations become possible for analytics, mobile, voice, machine learning (ML), or Internet of Things (IoT) use cases.
Summary
Blu Age mainframe automated refactoring provides the speed and flexibility to meet the agility needs of customers. It leverages the AWS quality of service for high security, high availability, elasticity, and rich system management to meet or exceed the mainframe workloads requirements.
While accelerating modernization, Blu Age toolset allows incremental transitions adapting to customers priorities. It accelerates mainframe modernization to containers or serverless functions
Blu Age also gives the option to keep developing in COBOL or transition smoothly to Java. It facilitates the identification and extraction of microservices.
For more details, visit the Serverless COBOL page and contact Blu Age to learn more.
.

.
Blu Age – APN Partner Spotlight
Blu Age is an APN Select Technology Partner that helps organizations enter the digital era by modernizing legacy systems while substantially reducing modernization costs, shortening project duration, and mitigating the risk of failure.
Contact Blu Age | Solution Overview | AWS Marketplace
*Already worked with Blu Age? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.
我们今天的关于Simplify Machine Learning Inference on Kubernetes with Amazon SageMaker Operators的分享就到这里,谢谢您的阅读,如果想了解更多关于175+ Customers Achieve Machine Learning Success with AWS’s Machine Learning Solutions Lab、Analyzing chest X-ray images with machine learning、augemtation 错误,tensorflow.python.keras.preprocessing.image.ImageDataGenerator、Automated Refactoring from Mainframe to Serverless Functions and Containers with Blu Age的相关信息,可以在本站进行搜索。
本文标签:




