对于想了解如何在SpringKafkaConsumer中跳过损坏的的读者,本文将提供新的信息,我们将详细介绍不可序列化的消息?,并且为您提供关于ApacheKafka(九)-KafkaConsumer
对于想了解如何在Spring Kafka Consumer中跳过损坏的的读者,本文将提供新的信息,我们将详细介绍不可序列化的消息?,并且为您提供关于Apache Kafka(九)- Kafka Consumer 消费行为、CDH-Kafka-SparkStreaming 异常:org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/uti、FlinkKafkaConsumer和版本控制的消费者FlinkKafkaConsumer09 / FlinkKafkaConsumer010 / FlinkKafkaConsumer011之间的区别、flume 传递到 kafka 的消息,consumer 接收不到的有价值信息。
本文目录一览:- 如何在Spring Kafka Consumer中跳过损坏的(不可序列化的)消息?
- Apache Kafka(九)- Kafka Consumer 消费行为
- CDH-Kafka-SparkStreaming 异常:org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/uti
- FlinkKafkaConsumer和版本控制的消费者FlinkKafkaConsumer09 / FlinkKafkaConsumer010 / FlinkKafkaConsumer011之间的区别
- flume 传递到 kafka 的消息,consumer 接收不到
消息?")
如何在Spring Kafka Consumer中跳过损坏的(不可序列化的)消息?
有没有一种方法可以配置Spring Kafka使用者以跳过无法读取/处理(已损坏)的记录?
我看到一种情况,如果无法反序列化,则消费者将停留在同一记录上。这是消费者抛出的错误。
Caused by: com.fasterxml.jackson.databind.JsonMappingException: Can not construct instance of java.time.LocalDate: no long/Long-argument constructor/factory method to deserialize from Number value使用者轮询该主题,并一直循环循环打印相同的错误,直到程序被杀死为止。
在具有以下消费者工厂配置的@KafkaListener中,
Map<String, Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);答案1
小编典典您需要ErrorHandlingDeserializer:https : //docs.spring.io/spring-
kafka/docs/2.2.0.RELEASE/reference/html/_reference.html#error-handling-
deserializer
如果无法升级到该2.2版本,请考虑实施自己的版本并返回null无法正确反序列化的那些记录。
- 源代码在这里:[https](https://github.com/spring-projects/spring-
- kafka/blob/master/spring-
- kafka/src/main/java/org/springframework/kafka/support/serializer/ErrorHandlingDeserializer2.java)
- //github.com/spring-projects/spring-kafka/blob/master/spring-
kafka/src/main/java/org/springframework/kafka/support/serializer/ErrorHandlingDeserializer2.java
- Kafka Consumer 消费行为")
Apache Kafka(九)- Kafka Consumer 消费行为
1. Poll Messages
在Kafka Consumer 中消费messages时,使用的是poll模型,也就是主动去Kafka端取数据。其他消息管道也有的是push模型,也就是服务端向consumer推送数据,consumer仅需等待即可。
Kafka Consumer的poll模型使得consumer可以控制从log的指定offset去消费数据、消费数据的速度、以及replay events的能力。
Kafka Consumer 的poll模型工作如下图:
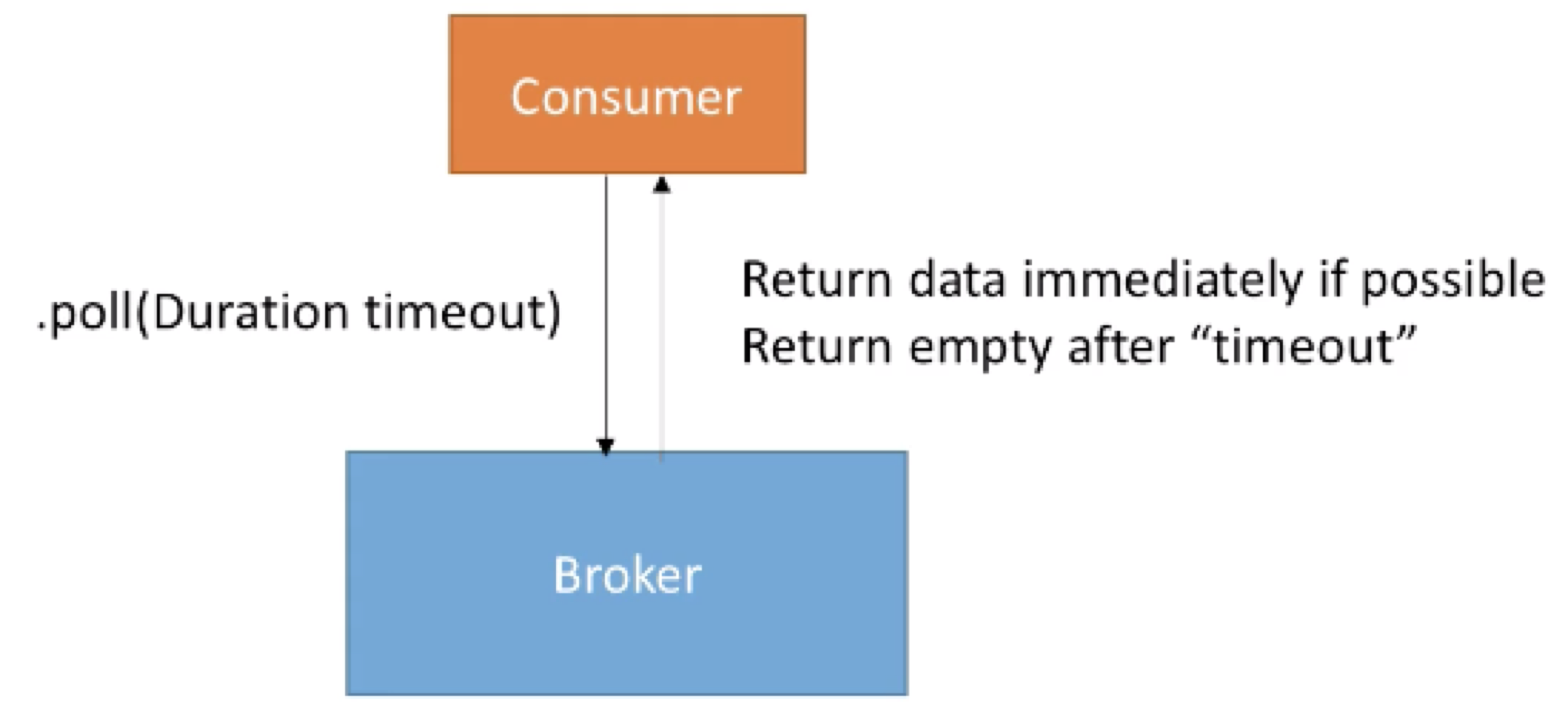
- · Consumer 调用.poll(Duration timeout) 方法,向broker请求数据
- · 若是broker端有数据则立即返回;否则在timeout时间后返回empty
我们可以通过参数控制 Kafka Consumer 行为,主要有:
- · Fetch.min.bytes(默认值是1)
o 控制在每个请求中,至少拉取多少数据
o 增加此参数可以提高吞吐并降低请求的数目,但是代价是增加延时
- · Max.poll.records(默认是500)
o 控制在每个请求中,接收多少条records
o 如果消息普遍都比较小而consumer端又有较大的内存,则可以考虑增大此参数
o 最好是监控在每个请求中poll了多少条消息
- · Max.partitions.fetch.bytes(默认为1MB)
o Broker中每个partition可返回的最多字节
o 如果目标端有100多个partitions,则需要较多内存
- · Fetch.max.bytes(默认50MB)
o 对每个fetch 请求,可以返回的最大数据量(一个fetch请求可以覆盖多个partitions)
o Consumer并行执行多个fetch操作
默认情况下,一般不建议手动调整以上参数,除非我们的consumer已经达到了默认配置下的最高的吞吐,且需要达到更高的吞吐。
2. Consumer Offset Commit 策略
在一个consumer 应用中,有两种常见的committing offsets的策略,分别为:
- · (较为简单)enable.auto.commit = true:自动commit offsets,但必须使用同步的方式处理数据
- · (进阶)enable.auto.commit = false:手动commit offsets
在设置enable.auto.commit = true时,考虑以下代码:
while(true) {
List<Records> batch = consumer.poll(Duration.ofMillis(100));
doSomethingSynchronous(batch);
}
一个Consumer 每隔100ms poll一次消息,然后以同步地方式处理这个batch的数据。此时offsets 会定期自动被commit,此定期时间由 auto.commit.interval.ms 决定,默认为 5000,也就是在每次调用 .poll() 方法 5 秒后,会自动commit offsets。
但是如果在处理数据时用的是异步的方式,则会导致“at-most-once”的行为。因为offsets可能会在数据被处理前就被commit。
所以对于新手来说,使用 enable.auto.commit = true 可能是有风险的,所以不建议一开始就使用这种方式 。
若设置 enable.auto.commit = false,考虑以下代码:
while(true) {
List<Records> batch = consumer.poll(Duration.ofMillis(100));
if isReady(batch){
doSomethingSynchronous(batch);
consumer.commitSync();
}
}
此例子明确指示了在同步地处理了数据后,再主动commit offsets。这样我们可以控制在什么条件下,去commit offsets。一个比较典型的场景为:将接收的数据读入缓存,然后flush 缓存到一个数据库中,最后再commit offsets。
3. 手动Commit Offset 示例
首先我们关闭自动commit offsets :
// disable auto commit of offsets
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
指定每个请求最多接收10条records,便于测试:properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "10"); 添加以下代码逻辑:
public static void main(String[] args) throws IOException {
Logger logger = LoggerFactory.getLogger(ElasticSearchConsumer.class.getName());
RestHighLevelClient client = createClient();
// create Kafka consumer
KafkaConsumer<String, String> consumer = createConsumer("kafka_demo");
// poll for new data
while(true){
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMinutes(100));
logger.info("received " + records.count() + "records");
for(ConsumerRecord record : records) {
// construct a kafka generic ID
String kafka_generic_id = record.topic() + "_" + record.partition() + "_" + record.offset();
// where we insert data into ElasticSearch
IndexRequest indexRequest = new IndexRequest(
"kafkademo"
).id(kafka_generic_id).source(record.value(), XContentType.JSON);
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
String id = indexResponse.getId();
logger.info(id);
try {
Thread.sleep(10); // introduce a small delay
} catch (InterruptedException e) {
e.printStackTrace();
}
}
logger.info("Committing offsets...");
consumer.commitSync(); // commit offsets manually
logger.info("Offsets have been committed");
}
}这里我们在处理每次获取的10条records后(也就是for 循环完整执行一次),手动执行一次offsets commit。打印日志记录为:
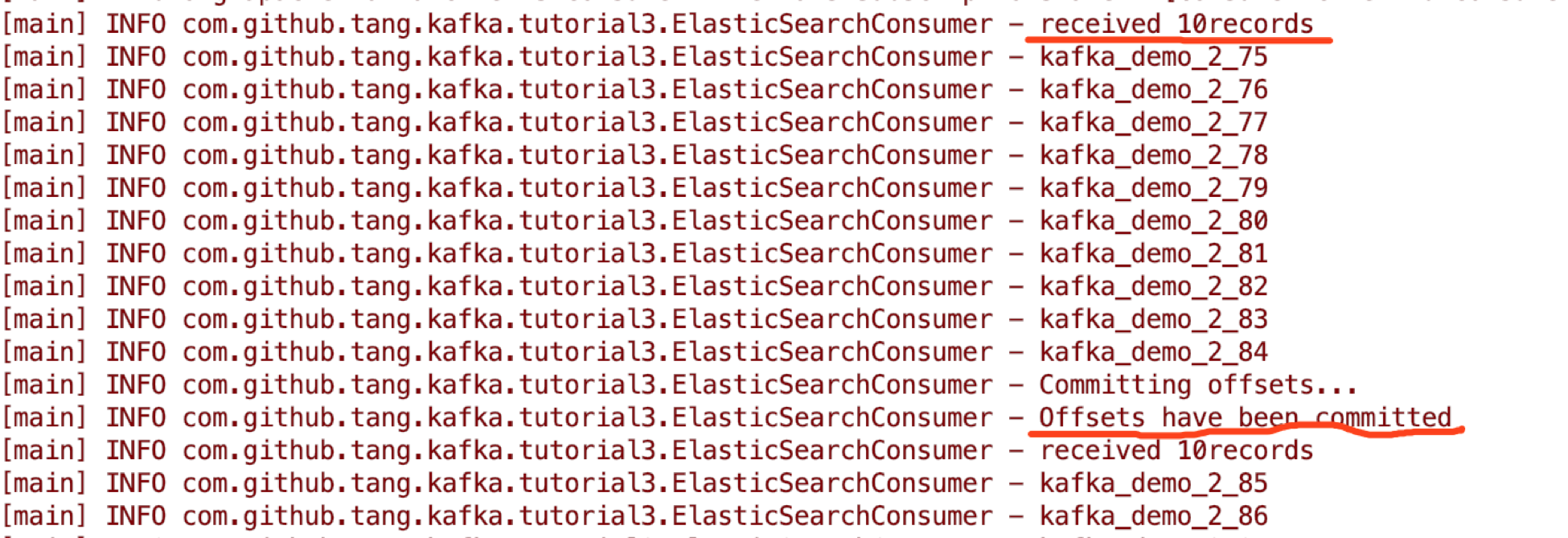
手动停止consumer 程序后,可以看到最后的committed offsets为165:
使用consumer-group cli 也可以验证当前committed offsets为165:

4. Performance Improvement using Batching
在这个例子中,consumer 限制每次poll 10条数据,然后每条依次处理(插入elastic search)。此方法效率较低,我们可以通过使用 batching 的方式增加吞吐。这里实现的方式是使用 elastic search API 提供的BulkRequest,基于之前的代码,修改如下:
public static void main(String[] args) throws IOException {
Logger logger = LoggerFactory.getLogger(ElasticSearchConsumer.class.getName());
RestHighLevelClient client = createClient();
// create Kafka consumer
KafkaConsumer<String, String> consumer = createConsumer("kafka_demo");
// poll for new data
while(true){
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMinutes(100));
// bulk request
BulkRequest bulkRequest = new BulkRequest();
logger.info("received " + records.count() + "records");
for(ConsumerRecord record : records) {
// construct a kafka generic ID
String kafka_generic_id = record.topic() + "_" + record.partition() + "_" + record.offset();
// where we insert data into ElasticSearch
IndexRequest indexRequest = new IndexRequest(
"kafkademo"
).id(kafka_generic_id).source(record.value(), XContentType.JSON);
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
// add to our bulk request (takes no time)
bulkRequest.add(indexRequest);
//String id = indexResponse.getId();
//logger.info(id);
try {
Thread.sleep(10); // introduce a small delay
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// bulk response
BulkResponse bulkItemResponses = client.bulk(bulkRequest, RequestOptions.DEFAULT);
logger.info("Committing offsets...");
consumer.commitSync(); // commit offsets manually
logger.info("Offsets have been committed");
}
}
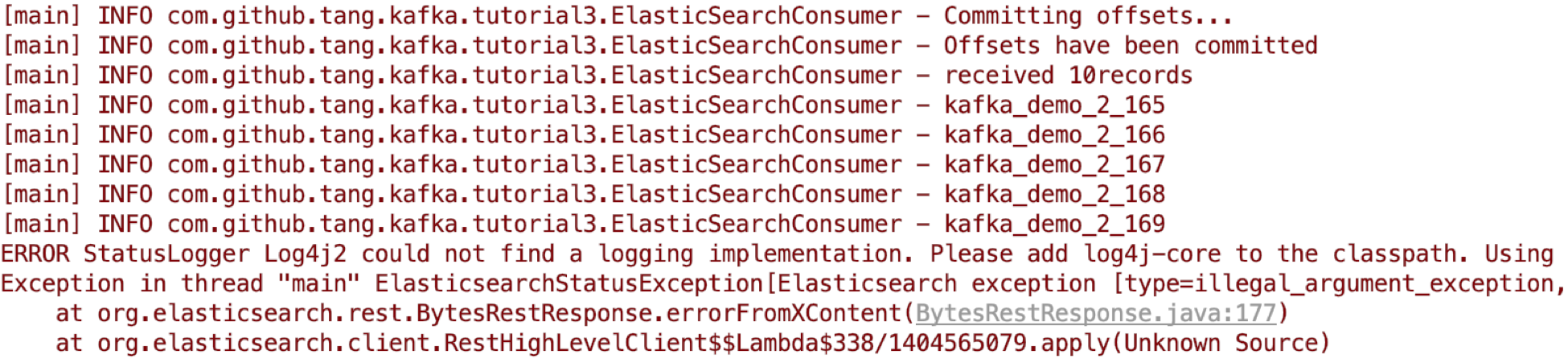
可以看到,consumer在poll到记录后,并不会一条条的向elastic search 发送,而是将它们放入一个BulkRequest,并在for循环结束后发送。在发送完毕后,再手动commit offsets。
执行结果为:


CDH-Kafka-SparkStreaming 异常:org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/uti
参考文章:
flume kafka sparkstreaming整合后集群报错org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/ut
https://blog.csdn.net/u010936936/article/details/77247075?locationNum=2&fps=1
最近在使用CDH 环境 提交 Kafka-Spark Streaming 作业的时候遇到了一些问题,特此记录如下:
主要的报错信息为:
Exception in thread "streaming-start" java.lang.NoSuchMethodError: org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/util/Collection;
Exception in thread "streaming-start" java.lang.NoSuchMethodError: org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/util/Collection;
并且在报错之前,可以看到 kafka-client 为 0.9.0 版本
18/11/01 16:48:04 INFO AppInfoParser: Kafka version : 0.9.0.0
18/11/01 16:48:04 INFO AppInfoParser: Kafka commitId : cb8625948210849f
但是,我们查看打的包高于此版本。
原因分析
其实这个在官方文档中有介绍。地址如下:
https://www.cloudera.com/documentation/spark2/latest/topics/spark2_kafka.html#running_jobs
简单说,就是kafka集成spark2,需要在CDH中进行设置。官网介绍了2中方法。这里我采用了第二种,在CDH中进行修改配置的方法。
步骤如下:
1.进入CDH的spark2配置界面,在搜索框中输入SPARK_KAFKA_VERSION,出现如下图,
2.然后选择对应版本,这里我应该选择的是None,
即 : 选用集群上传的Kafka-client 版本 !!
3.然后保存配置,重启生效。
4.重新跑sparkstreaming任务,问题解决。


FlinkKafkaConsumer和版本控制的消费者FlinkKafkaConsumer09 / FlinkKafkaConsumer010 / FlinkKafkaConsumer011之间的区别
版本化的Kafka使用者(和生产者)是针对那些版本的Kafka客户端构建的,旨在与每个特定版本的Kafka一起使用。未版本化的连接器FlinkKafkaConsumer和FlinkKafkaProducer使用通用客户端库构建,并且与自0.10开始的所有版本的Kafka兼容。
请注意,在Flink 1.11中删除了Kafka 0.8和0.9的版本化使用者和生产者,而在Flink 1.12(https://issues.apache.org/jira/browse/FLINK-19152)中则删除了0.10和0.11版本。
编辑:
在某些情况下,仅允许来自水槽的背压来节流水源就足够了。但是在其他情况下(例如多个来源),效果可能不够好。
您将在http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/Kafka-Rate-Limit-in-FlinkConsumer-td36417.html上找到有关此问题的讨论以及进行自己的速率限制的代码。

flume 传递到 kafka 的消息,consumer 接收不到
OSC 请你来轰趴啦!1028 苏州源创会,一起寻宝 AI 时代 
做的是 flume+kafka, 把 flume 接收到的消息传递到 kafka,后台程序监控消息队列,取出 flume 传递过来的消息。现在的问题是:
1、通过 Producer 生产的消息,Consumer 程序能接收到,但是 flume 生产的消息,consumer 接收不到;
2、flume 生产的消息通过 kafka 的 kafka-console-consumer.sh 命令行能接收到。
flume 整合 kafka 的配置:
agent.sources.s1.type = netcat
agent.sources.s1.bind = 192.168.80.129
agent.sources.s1.port = 44444
agent.sources.s1.channels=c1
#config channels
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100
#config sinks
agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k1.channel=c1
agent.sinks.k1.brokerList=192.168.80.129:9092
agent.sinks.k1.topic=test
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder
agent.sinks.k1.producer.type=sync
agent.sinks.k1.custom.encoding=UTF-8
agent.sinks.k1.custom.topic.name=test
consumer 部分代码:
public class KafkaConsumerTest{
public static void main(String[] args){
String zkInfo = "192.168.80.129:2181";//zookeeper 地址
String topic = "test";//topic 名称,与上边 flume 里配置的 topic 相同
KafkaConsumerTest consumer = new KafkaConsumerTest();
consumer.setConsumer(zkInfo);
consumer.consume(lock,topic);
}
/**
*
* @param zkInfo
*/
public void setConsumer(String zkInfo) {
Properties props = new Properties();
props.put("zookeeper.connect",zkInfo);
props.put("group.id", "test-consumer-group");
props.put("serializer.class", "kafka.serializer.StringEncoder");
ConsumerConfig config = new ConsumerConfig(props);
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
}
/**
*
* @param hdfsPath
* @param topic
* @throws InterruptedException
*/
public void consume(String lock,String topic) throws InterruptedException {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
Map<String, List<KafkaStream<String, String>>> consumerMap = consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
List<KafkaStream<String, String>> streams = consumerMap.get(topic);
System.out.println(streams.size());
ThreadPoolManager tpm = ThreadPoolManager.newInstance();
for(final KafkaStream stream : streams){
tpm.dbShortSchedule(new ConsumerThread(stream,lock), 0);
}
System.out.println("finish");
}
}
线程里就是打印接收到的消息,就不贴代码了。
consumer 命令行接收的命令是:(这是在 192.168.80.129 上运行的,所以写了 localhost,java 代码是在本地 eclipse 里运行的,写了 ip 地址)
./kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
不知道哪里有问题,还请各位指点一二!!!
今天的关于如何在Spring Kafka Consumer中跳过损坏的和不可序列化的消息?的分享已经结束,谢谢您的关注,如果想了解更多关于Apache Kafka(九)- Kafka Consumer 消费行为、CDH-Kafka-SparkStreaming 异常:org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/uti、FlinkKafkaConsumer和版本控制的消费者FlinkKafkaConsumer09 / FlinkKafkaConsumer010 / FlinkKafkaConsumer011之间的区别、flume 传递到 kafka 的消息,consumer 接收不到的相关知识,请在本站进行查询。
本文标签:




