如果您想了解使用Python和Rpy2进行统计测试的相关知识,那么本文是一篇不可错过的文章,我们将对Kolmogorov和T检验进行全面详尽的解释,并且为您提供关于eclispe中使用python库p
如果您想了解使用Python和Rpy2进行统计测试的相关知识,那么本文是一篇不可错过的文章,我们将对Kolmogorov和T检验进行全面详尽的解释,并且为您提供关于eclispe中使用python库 pyswip 进行prolog编程、iPython和R之间GLM结果的差异、KS(Kolmogorov-Smirnov)值、ping包测试内容写入文件,并使用python对相应的结果进行统计分析的有价值的信息。
本文目录一览:- 使用Python和Rpy2进行统计测试(Kolmogorov和T检验)(python 统计检验)
- eclispe中使用python库 pyswip 进行prolog编程
- iPython和R之间GLM结果的差异
- KS(Kolmogorov-Smirnov)值
- ping包测试内容写入文件,并使用python对相应的结果进行统计分析
(python 统计检验)")
使用Python和Rpy2进行统计测试(Kolmogorov和T检验)(python 统计检验)
我已经运行了一些算法,并希望对结果进行一些统计分析。我有两个向量的错误率平均值。
使用R,使用下面的行,我将得到所有信息。
t.test(methodresults1,methodresults2,var.equal=FALSE,paired=FALSE,alternative="less")由于我使用的是Python,因此我想使用Rpy2项目。
我尝试过:
import rpy2.robjects as R# methodresults1 and methodresults2 are numpy arrays.# kolmogorov testnormality_res = R.r[''ks.test''](R.FloatVector(methodresults1.tolist()),''pnorm'',mean=R.FloatVector(methodresults1.mean().tolist()),sd=R.FloatVector(methodresults1.std().tolist())))# t-testres = R.r[''t.test''](R.FloatVector(methodresults1.tolist()),R.FloatVector(methodresults2.tolist()),alternative=''two.sided'',var.equal=FALSE,paired=FALSE)res.rx(''p.value'')[0][0]res.rx(''statistic'')[0][0]res.rx(''parameter'')[0][0]我无法同时执行这两项测试。
我还发现t检验的问题在于var.equal语句,它给了我 * SyntaxError:关键字不能是表达式(第1行)。
额外的问题:是否有更好的方法来处理numpy和Rpy2?
答案1
小编典典如它所说:“ SyntaxError:关键字不能是表达式(第1行)。 ”
在Python中,符号不能包含字符“。”。
from rpy2.robjects.packages import importrfrom rpy2.robjects.vectors import StrVectorstats = importr("stats")stats.t_test(methodresults1, methodresults2, **{''var.equal'': False, ''paired'': False, ''alternative'': StrVector(("less", ))})查看rpy2文档中有关功能的更多信息。

eclispe中使用python库 pyswip 进行prolog编程
from pyswip import Prolog
prolog = Prolog()
prolog.assertz("father(michael,john)")
prolog.assertz("father(michael,gina)")
list(prolog.query("father(michael,X)")) == [{''X'': ''john''}, {''X'': ''gina''}]
for soln in prolog.query("father(X,Y)"):
print(soln["X"], "is the father of", soln["Y"])
首先需要对库pyswip进行安装 pip install pyswip
安装好之后 在eclipse中创建一个python工程
创建一个名为 test1.py的python文件 输入如下代码 测试是否可以使用库pyswip 进行prolog编程
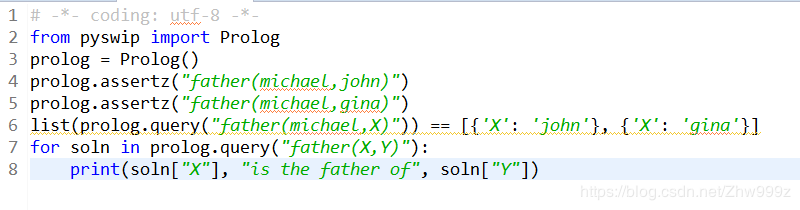
输出结果为:


iPython和R之间GLM结果的差异
结果非常相似,但它们是不同的.我有点希望它们是一样的.我做错了什么,是否有我缺少的参数,或者由于某些基础计算的差异?
任何帮助赞赏!
编辑:我不知道这是否保证关闭,但我用Ben的编辑(和更清洁)代码重新编写代码,python和R之间的结果现在是相同的.我根本没有更改python代码,以及我以前的R代码和Ben的代码,而不同的应该是(据我所知)做同样的事情.无论问题的重点是现在都没有实际意义.尽管如此,谢谢你看看.
生成随机数据并运行glm:
set.seed(666)
dat <- data.frame(a=rnorm(500),b=runif(500),c=as.factor(sample(1:5,500,replace=TRUE)))
library(plyr)
dat <- mutate(dat,y0=((jitter(a)^2+(-log10(b)))/(as.numeric(c)/10))+rnorm(500),y=(y0>=mean(y0)))
fit1 <- glm(y~a+b+c,data=dat,family=binomial(''logit''))
summary(fit1)
Call:
glm(formula = y ~ a + b + c,family = binomial("logit"),data = dat)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.5369 -0.8154 -0.5479 0.9314 2.3831
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.2363 0.3007 4.111 3.94e-05 ***
a -0.2051 0.1062 -1.931 0.0535 .
b -1.6103 0.3834 -4.200 2.67e-05 ***
c2 -0.5114 0.3091 -1.654 0.0980 .
c3 -1.3169 0.3147 -4.184 2.86e-05 ***
c4 -2.0017 0.3342 -5.990 2.09e-09 ***
c5 -2.5084 0.3772 -6.651 2.92e-11 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(dispersion parameter for binomial family taken to be 1)
Null deviance: 631.31 on 499 degrees of freedom
Residual deviance: 537.84 on 493 degrees of freedom
AIC: 551.84
Number of Fisher Scoring iterations: 4
输出相同的数据以供在python中使用:
write.table(dat,file=''test.txt'',row.names=F,col.names=T,quote=F,sep='','' )
现在的python代码:
import pandas as pd
import statsmodels.api as sm
import pylab as pl
import numpy as np
data = pd.read_csv(''test.txt'')
data.describe()
dummy_c = pd.get_dummies(data[''c''],prefix=''c'')
data = data[[''y'',''a'',''b'']].join(dummy_c.ix[:,''c_2'':])
data_depend = data[''y'']
data_independ = data.iloc[:,1:]
data_independ = sm.add_constant(data_independ,prepend=False)
glm_binom = sm.GLM(data_depend,data_independ,family=sm.families.Binomial())
res = glm_binom.fit()
print res.summary()
产量:
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: y No. Observations: 500
Model: GLM Df Residuals: 493
Model Family: Binomial Df Model: 6
Link Function: logit Scale: 1.0
Method: IRLS Log-Likelihood: -268.92
Date: Sun,27 Oct 2013 Deviance: 537.84
Time: 01:26:47 Pearson chi2: 514.
No. Iterations: 6
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
a -0.2051 0.106 -1.931 0.054 -0.413 0.003
b -1.6103 0.383 -4.200 0.000 -2.362 -0.859
c_2 -0.5114 0.309 -1.654 0.098 -1.117 0.094
c_3 -1.3169 0.315 -4.184 0.000 -1.934 -0.700
c_4 -2.0017 0.334 -5.990 0.000 -2.657 -1.347
c_5 -2.5084 0.377 -6.651 0.000 -3.248 -1.769
const 1.2363 0.301 4.111 0.000 0.647 1.826
==============================================================================
解决方法
set.seed(101)
dat <- data.frame(a=rnorm(500),family=binomial(''logit''))
fit2 <- update(fit1,control=glm.control(maxit=6))
all.equal(fit1,fit2)
coef(fit1)
## (Intercept) a b c2 c3 c4
## 1.22283193 -0.07544488 -1.54732712 -0.36477556 -1.46313143 -1.95008291
## c5
## -3.11914945
我同意@ Roland的评论,一个可重复的例子会有所帮助.最可能的区别在于对比编码,例如:
fit3 <- update(fit1,contrasts=list(c=contr.sum)) coef(fit3) ## ## (Intercept) a b c1 c2 c3 ## -0.15659594 -0.07544488 -1.54732712 1.37942787 1.01465231 -0.08370356 ## c4 ## -0.57065503
如果您使用仅包含连续预测变量的模型,结果是否更好?
更新:对比度编码不能是整个故事,因为偏差/对数似然以及系数不同.
值")
KS(Kolmogorov-Smirnov)值
KS(Kolmogorov-Smirnov)值越大,表示模型能够将正、负客户区分开的程度越大。KS值的取值范围是[0,1]
ks越大,表示计算预测值的模型区分好坏用户的能力越强。
| ks值 | 含义 |
|---|---|
| > 0.3 | 模型预测性较好 |
| 0,2~0.3 | 模型可用 |
| 0~0.2 | 模型预测能力较差 |
| < 0 | 模型错误 |
通常来讲,KS>0.2即表示模型有较好的预测准确性。
ks求解方法:
ks需要TPR和FPR两个值:真正类率(true positive rate ,TPR), 计算公式为TPR=TP/ (TP+ FN),刻画的是分类器所识别出的 正实例占所有正实例的比例。另外一个是假正类率(false positive rate, FPR),计算公式为FPR= FP / (FP + TN),计算的是分类器错认为正类的负实例占所有负实例的比例。KS=max(TPR-FPR)。其中:
TP:真实为1且预测为1的数目
FN:真实为1且预测为0的数目
FP:真实为0的且预测为1的数目
TN:真实为0的且预测为0的数目
一句话概括:
KS曲线是两条线,其横轴是阈值,纵轴是TPR(上面那条)与FPR(下面那条)的值,值范围[0,1] 。两条曲线之间之间相距最远的地方对应的阈值,就是最能划分模型的阈值。
计算步骤:
1. 按照分类模型返回的概率升序排列 ,也可以直接是数据,根据某一阈值判断为1或0即可
2. 把0-1之间等分N份,等分点为阈值,计算TPR、FPR (可以将每一个都作为阈值)
3. 对TPR、FPR描点画图即可 (以10%*k(k=1,2,3,…,9)为横坐标,分别以TPR和FPR的值为纵坐标,就可以画出两个曲线,这就是K-S曲线。)
KS值即为Max(TPR-FPR)
Python代码实现:
#-*- coding:utf-8 -*-
#自己实现计算ks与调包
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
import seaborn as sns
#%matplotlib inline
#%config InlineBackend.figure_format = ''retina''
plt.rcParams[''font.sans-serif''] = [''SimHei''] # 中文字体设置-黑体
plt.rcParams[''axes.unicode_minus''] = False # 解决保存图像是负号''-''显示为方块的问题
sns.set(font=''SimHei'') # 解决Seaborn中文显示问题
class BinJianAna:
def __init__(self):
pass
def ComuTF(self,lst1,lst2):
#计算TPR和FPR
#lst1为真实值,lst2为预测值
TP = sum([1 if a==b==1 else 0 for a,b in zip(lst1,lst2)])#正例被预测为正例
FN = sum([1 if a==1 and b==0 else 0 for a,b in zip(lst1,lst2)])#正例被预测为反例
TPR = TP/(TP+FN)
TN = sum([1 if a==b==0 else 0 for a,b in zip(lst1,lst2)])#反例被预测为反例
FP = sum([1 if a==0 and b==1 else 0 for a,b in zip(lst1,lst2)])#反例被预测为正例
FPR = FP/(TN+FP)
return TPR - FPR
def Getps_ks(self,real_data,data):
#real_data为真实值,data为原数据
d = []
for i in data:
pre_data = [1 if line >=i else 0 for line in data]
d.append(self.ComuTF(real_data,pre_data))
return max(d),data[d.index(max(d))]
def GetKS(self,y_test,y_pred_prob):
''''''
功能: 计算KS值,输出对应分割点和累计分布函数曲线图
输入值:
y_pred_prob: 一维数组或series,代表模型得分(一般为预测正类的概率)
y_test: 真实值,一维数组或series,代表真实的标签({0,1}或{-1,1})
''''''
fpr,tpr,thresholds = roc_curve(y_test,y_pred_prob)
ks = max(tpr-fpr)
#画ROC曲线
plt.plot([0,1],[0,1],''k--'')
plt.plot(fpr,tpr)
plt.xlabel(''False Positive Rate'')
plt.ylabel(''True Positive Rate'')
plt.show()
#画ks曲线
plt.plot(tpr)
plt.plot(fpr)
plt.plot(tpr-fpr)
plt.show()
return fpr,tpr,thresholds,ks
if __name__ == ''__main__'':
a = BinJianAna()
data = [790,22,345,543,564,342,344,666,789,123,231,234,235,347,234,237,178,198,567,222]#原始评分数据
real_data = [1,1,1,1,1,1,0,0,0,1,1,0,0,1,1,0,0,1,1,0]
y_pred_prob = [0.42,0.73,0.55,0.37,0.57,0.70,0.25,0.23,0.46,0.62,0.76,0.46,0.55,0.56,0.56,0.38,0.37,0.73,0.77,0.21]
#以下只为演示如何调用方法,2种方法独立计算,数据之间无关联,因此得出的ks不一样
print(a.Getps_ks(real_data,data))#自己实现
print(a.GetKS(real_data,y_pred_prob))#代码实现
本文链接:https://blog.csdn.net/sinat_30316741/article/details/80018932

ping包测试内容写入文件,并使用python对相应的结果进行统计分析
一、ping包测试内容写入log文件,bat脚本如下:
@ECHO OFF
%~d0
cd %cd%\
start CMD.EXE /C "ping.exe 192.168.1.21 >>1.21.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.45 >>1.45.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.77 >>1.77.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.79 >>1.79.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.114 >>1.114.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.120 >>1.120.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.121 >>1.121.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.113 >>1.113.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.116 >>1.116.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.119 >>1.119.log" -n 300
start CMD.EXE /C "ping.exe 192.168.1.117 >>1.117.log" -n 300二、对生成的.Log文件进行分析并将数据存储到excel中,代码如下:
import re,os,time
import xlwt
import os
#获取当前文件夹下扩展名为.log的文件名列表
def readFileList():
items = os.listdir(".")
newList = []
for names in items:
if names.endswith(".log"):
newList.append(names)
return newList
#获取log文件中的统计信息
def readMsg(file):
#for i in fileList:
f = open(file,''r'')
fileMsg = f.readlines()
ipMatch2 = re.search(r''(([01]?\d?\d|2[0-4]\d|25[0-5]\d)\.){3}([01]?\d?\d|2[0-4]\d|25[0-5]\d)'', fileMsg[-2])
if ipMatch2==None:
ipMatch = re.search(r''(([01]?\d?\d|2[0-4]\d|25[0-5]\d)\.){3}([01]?\d?\d|2[0-4]\d|25[0-5]\d)'',fileMsg[-4])
IP = ipMatch.group()
#print(IP)
dataPackage = fileMsg[-3:-2][0].strip(''\n'').replace(" ","")
dataPackageClient = dataPackage.split('','')[0].split('':'')[1]
dataPackageSever = dataPackage.split('','')[1]
dataPackageLose = dataPackage.split('','')[2]
#print(dataPackage)
delayTime = fileMsg[-1].strip(''\n'').replace(" ","")
delayTimeMin = delayTime.split('','')[0]
delayTimeMax = delayTime.split('','')[1]
delayTimeAvg = delayTime.split('','')[2]
#print(delayTime)
else:
IP = ipMatch2.group()
dataPackageClient = ''ping fail''
dataPackageSever = None
dataPackageLose = None
delayTimeMin = None
delayTimeMax = None
delayTimeAvg = None
#print(IP)
#print("ping fail")
return [IP, dataPackageClient,dataPackageSever,dataPackageLose,delayTimeMin,delayTimeMax,delayTimeAvg]
#print(''---------------------------------------'')
#将得到的统计信息写入到excel表格中
def writeData():
newTable = ''ping.xls''
wb = xlwt.Workbook(encoding=''utf-8'')
ws = wb.add_sheet(''ping'', cell_overwrite_ok=True) # 创建表
headData = [''IP'', ''已发送'',''已接收'',''丢失'',''最短'',''最长'',''平均'']
for colnum in range(0, 7):
ws.write(0, colnum, headData[colnum], xlwt.easyxf(''font:bold on''))
index = 1
for i in range(len(dataMsg)): #excel的列数
for j in range(0,7): #excel的行数
# print RSSIt[i]
ws.write(index, j, dataMsg[i][j])
index += 1
wb.save(newTable)
if __name__ == ''__main__'':
fileList = readFileList()
print(fileList)
dataMsg = []
for file in fileList:
dataMsg.append(readMsg(file))
print(dataMsg)
writeData()
关于使用Python和Rpy2进行统计测试和Kolmogorov和T检验的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于eclispe中使用python库 pyswip 进行prolog编程、iPython和R之间GLM结果的差异、KS(Kolmogorov-Smirnov)值、ping包测试内容写入文件,并使用python对相应的结果进行统计分析的相关知识,请在本站寻找。
本文标签:




