本文将为您提供关于PythonPandasDataframe按组中的最大值选择行的详细介绍,我们还将为您解释pandas分组后取各组最大几行的相关知识,同时,我们还将为您提供关于PANDAS中类似SQ
本文将为您提供关于Python Pandas Dataframe按组中的最大值选择行的详细介绍,我们还将为您解释pandas分组后取各组最大几行的相关知识,同时,我们还将为您提供关于PANDAS中类似SQL的窗口函数:Python Pandas Dataframe中的行编号、Pandas如何将DataFrame按列分组构成新的DataFrame?、Python 处理 Pandas DataFrame 中的行和列、Python DaskDataframe按列分组的实用信息。
本文目录一览:- Python Pandas Dataframe按组中的最大值选择行(pandas分组后取各组最大几行)
- PANDAS中类似SQL的窗口函数:Python Pandas Dataframe中的行编号
- Pandas如何将DataFrame按列分组构成新的DataFrame?
- Python 处理 Pandas DataFrame 中的行和列
- Python DaskDataframe按列分组
")
Python Pandas Dataframe按组中的最大值选择行(pandas分组后取各组最大几行)
我有一个通过df.pivot创建的数据框:
type start endF_Type to_date A 20150908143000 345 316B 20150908140300 NaN 480 20150908140600 NaN 120 20150908143000 10743 8803C 20150908140100 NaN 1715 20150908140200 NaN 1062 20150908141000 NaN 145 20150908141500 418 NaN 20150908141800 NaN 450 20150908142900 1973 1499 20150908143000 19522 16659D 20150908143000 433 65E 20150908143000 7290 7375F 20150908143000 0 0G 20150908143000 1796 340我想为每个“ F_TYPE”过滤并返回一行,仅返回最大“ to_date”的行。我想返回以下数据框:
type start endF_Type to_date A 20150908143000 345 316B 20150908143000 10743 8803C 20150908143000 19522 16659D 20150908143000 433 65E 20150908143000 7290 7375F 20150908143000 0 0G 20150908143000 1796 340谢谢..
答案1
小编典典使用标准方法groupby(keys)[column].idxmax()。但是,要使用所需的行,idxmax您需要idxmax返回唯一的索引值。获得唯一索引的一种方法是调用reset_index。
从中获取索引值后,groupby(keys)[column].idxmax()您可以使用来选择整行df.loc:
In [20]: df.loc[df.reset_index().groupby([''F_Type''])[''to_date''].idxmax()]Out[20]: start endF_Type to_date A 20150908143000 345 316B 20150908143000 10743 8803C 20150908143000 19522 16659D 20150908143000 433 65E 20150908143000 7290 7375F 20150908143000 0 0G 20150908143000 1796 340注意:idxmax返回索引 标签 ,不一定是普通 标签
。使用后reset_index的指数标签碰巧也是序,但由于idxmax正在恢复标签(不是序号),最好是 始终
使用idxmax与配合df.loc,而不是df.iloc(因为我原来在这个岗位做。)

PANDAS中类似SQL的窗口函数:Python Pandas Dataframe中的行编号
我来自sql背景,并且经常使用以下数据处理步骤:
- 按一个或多个字段对数据表进行分区
- 对于每个分区,在其每一行中添加一个行号,以行的一个或多个其他字段对行进行排名,分析人员在其中指定升序或降序
例如:
df = pd.DataFrame({'key1' : ['a','a','b','a'],'data1' : [1,2,3,3],'data2' : [1,10,30]})
df
data1 data2 key1
0 1 1 a
1 2 10 a
2 2 2 a
3 3 3 b
4 3 30 a
我正在寻找如何执行相当于此sql窗口函数的PANDAS:
RN = ROW_NUMBER() OVER (PARTITION BY Key1 ORDER BY Data1 ASC,Data2 DESC)
data1 data2 key1 RN
0 1 1 a 1
1 2 10 a 2
2 2 2 a 3
3 3 3 b 1
4 3 30 a 4
我尝试了以下在没有“分区”的情况下必须工作的方法:
def row_number(frame,orderby_columns,orderby_direction,name):
frame.sort_index(by = orderby_columns,ascending = orderby_direction,inplace = True)
frame[name] = list(xrange(len(frame.index)))
我试图将这个想法扩展到可以使用分区(熊猫中的组),但是以下操作不起作用:
df1 = df.groupby('key1').apply(lambda t: t.sort_index(by=['data1','data2'],ascending=[True,False],inplace = True)).reset_index()
def nf(x):
x['rn'] = list(xrange(len(x.index)))
df1['rn1'] = df1.groupby('key1').apply(nf)
但是当我这样做时,我得到了很多NaN。
理想情况下,有一种简洁的方法可以复制sql的窗口函数功能(我已经弄清楚了基于窗口的聚合……这是熊猫的一个内衬)……有人可以和我分享最惯用的方法吗?在PANDAS中编号这样的行?

Pandas如何将DataFrame按列分组构成新的DataFrame?
初始的DataFrame是这样的:
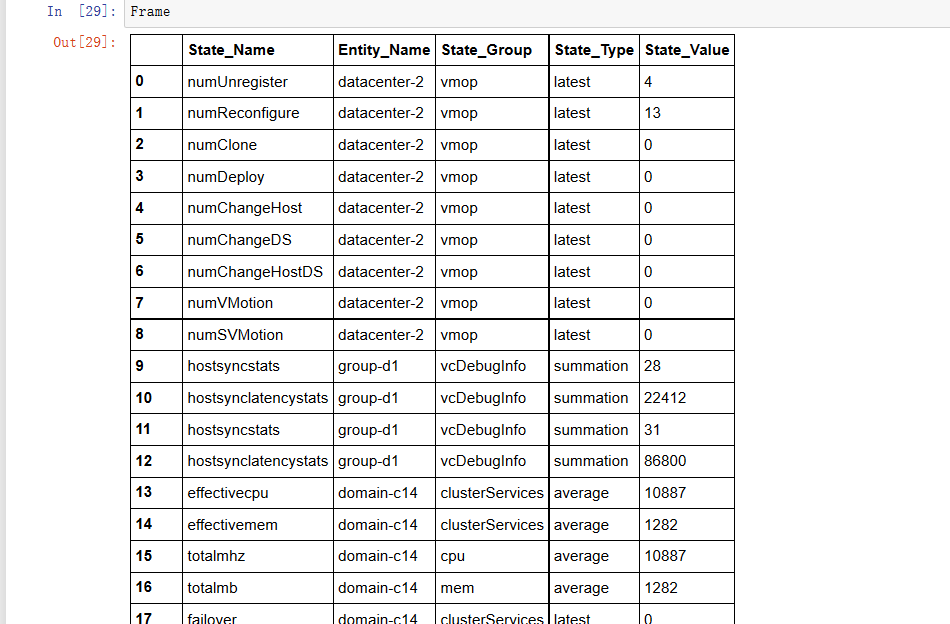
我想形成这样的:

这个是通过调用gruoupby().first()形成的,但不是完整的DataFrame。

Python 处理 Pandas DataFrame 中的行和列
前言:
数据框是一种二维数据结构,即数据以表格的方式在行和列中对齐。我们可以对行/列执行基本操作,例如选择、删除、添加和重命名。在本文中,我们使用的是nba.csv文件。
处理列
为了处理列,我们对列执行基本操作,例如选择、删除、添加和重命名。
列选择:为了在 Pandas DataFrame 中选择一列,我们可以通过列名调用它们来访问这些列。
# Import pandas package
import pandas as pd
# 定义包含员工数据的字典
data = {''Name'':[''Jai'', ''Princi'', ''Gaurav'', ''Anuj''],
''Age'':[27, 24, 22, 32],
''Address'':[''Delhi'', ''Kanpur'', ''Allahabad'', ''Kannauj''],
''Qualification'':[''Msc'', ''MA'', ''MCA'', ''Phd'']}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 选择两列
print(df[[''Name'', ''Qualification'']])输出:

列添加:为了在 Pandas DataFrame 中添加列,我们可以将新列表声明为列并添加到现有数据框。
# Import pandas package
import pandas as pd
# 定义包含学生数据的字典
data = {''Name'': [''Jai'', ''Princi'', ''Gaurav'', ''Anuj''],
''Height'': [5.1, 6.2, 5.1, 5.2],
''Qualification'': [''Msc'', ''MA'', ''Msc'', ''Msc'']}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 声明要转换为列的列表
address = [''Delhi'', ''Bangalore'', ''Chennai'', ''Patna'']
# 使用“地址”作为列名并将其等同于列表
df[''Address''] = address
# 观察结果
print(df)输出:

有关更多示例,请参阅在 Pandas列删除中向现有 DataFrame 添加新列:为了删除 Pandas DataFrame 中的列,我们可以使用该方法。通过删除具有列名的列来删除列。drop()
# importing pandas module
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除通过的列
data.drop(["Team", "Weight"], axis = 1, inplace = True)
# 展示
print(data)输出:如输出图像所示,新输出没有传递的列。这些值被删除,因为轴设置为等于 1,并且由于 inplace 为 True,因此在原始数据框中进行了更改。
删除列之前的数据框- 删除列:
之后的数据框:

处理行
为了处理行,我们可以对行执行基本的操作,例如选择、删除、添加和重命名。
行选择Pandas 提供了一种从数据框中检索行的独特方法。DataFrame.loc[]方法用于从 Pandas DataFrame 中检索行。也可以通过将整数位置传递给 iloc[] 函数来选择行。
# importing pandas package
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name")
# 通过 loc 方法检索行
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
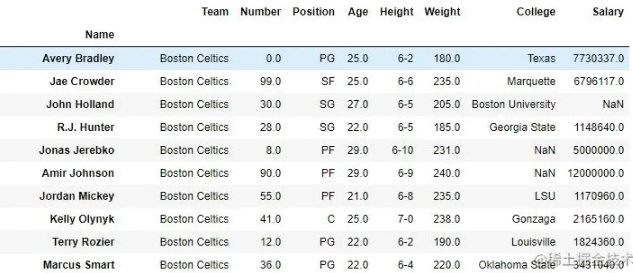
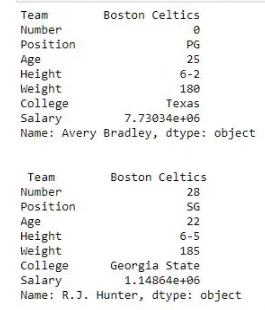
print(first, "\n\n\n", second)输出:如输出图像所示,由于两次都只有一个参数,因此返回了两个系列。
有关更多示例,请参阅Pandas 使用 .loc Row Addition提取行:为了在 Pandas DataFrame 中添加一行,我们可以将旧数据帧与新数据帧连接。
# importing pandas module
import pandas as pd
# 制作数据框
df = pd.read_csv("nba.csv", index_col ="Name")
df.head(10)
new_row = pd.DataFrame({''Name'':''Geeks'', ''Team'':''Boston'', ''Number'':3,
''Position'':''PG'', ''Age'':33, ''Height'':''6-2'',
''Weight'':189, ''College'':''MIT'', ''Salary'':99999},
index =[0])
# 简单地连接两个数据框
df = pd.concat([new_row, df]).reset_index(drop = True)
df.head(5)输出:添加行前的数据框- 添加行
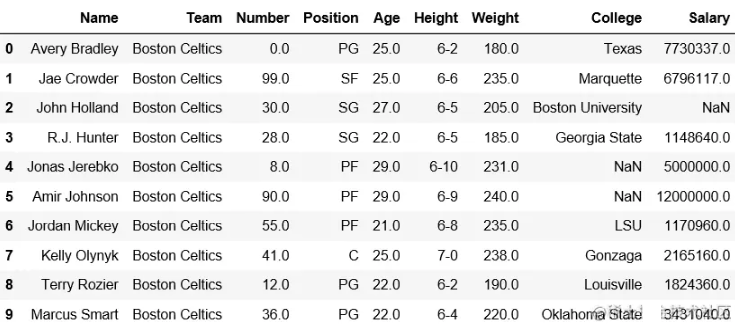
后的数据框-

删除行:为了删除 Pandas DataFrame 中的一行,我们可以使用 drop() 方法。通过按索引标签删除行来删除行。
# importing pandas module
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除传递的值
data.drop(["Avery Bradley", "John Holland", "R.J. Hunter",
"R.J. Hunter"], inplace = True)
# 展示
data输出:如输出图像所示,新输出没有传递的值。由于 inplace 为 True,因此删除了这些值并在原始数据框中进行了更改。
删除值之前的数据框- 删除值

后的数据框:
到此这篇关于Python 处理 Pandas DataFrame 中的行和列的文章就介绍到这了,更多相关Python Pandas DataFrame 内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- Python pandas按行、按列遍历DataFrame的几种方式
- Python Pandas 修改表格数据类型 DataFrame 列的顺序案例
- python读取和保存为excel、csv、txt文件及对DataFrame文件的基本操作指南
- python Dataframe 合并与去重详情
- 解读Python中的frame是什么

Python DaskDataframe按列分组
如何解决Python DaskDataframe按列分组?
我正在尝试在简单的数据帧上计算groupby操作:
import dask.dataframe as dd,t pandas as pd numpy as np
pdf = pd.DataFrame({''A'':[1,2,1],''B'':[4,5,6],''C'':[7,8,9],''D'':[1,3]})
pdf.columns=[''A'',''A'',''B'',''B'']
pdf.groupby(by=pdf.columns,axis=1).mean() # works
Out[83]:
A B
0 2.5 4.0
1 3.5 5.0
2 3.5 6.0
但是很快:
ddf = dd.from_pandas(pdf,npartitions=1)
#group = ddf.groupby(by=ddf.columns,axis=1).mean() #breaks
#group = ddf.groupby(by=list(ddf.columns),axis=1).mean() #breaks
TypeError: __init__() got an unexpected keyword argument ''axis''
文档说明(坐标轴:{0或“索引”,1或“列”},默认为0(在dask中不受支持)`)。 有工作区吗?
作为参考,沿着axis=0分组时不会发生这种情况:
pdf = pd.DataFrame({''A'':[1,3]})
pdf.groupby(''A'').mean()
ddf = dd.from_pandas(pdf,npartitions=1)
ddf.groupby(''A'').mean().compute()
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
关于Python Pandas Dataframe按组中的最大值选择行和pandas分组后取各组最大几行的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于PANDAS中类似SQL的窗口函数:Python Pandas Dataframe中的行编号、Pandas如何将DataFrame按列分组构成新的DataFrame?、Python 处理 Pandas DataFrame 中的行和列、Python DaskDataframe按列分组的相关信息,请在本站寻找。
本文标签:




