在这里,我们将给大家分享关于Java中的HashTable详解的知识,让您更了解javahashtable的本质,同时也会涉及到如何更有效地C#中的Hashtable类使用详解、C#正则表达式与Has
在这里,我们将给大家分享关于Java中的HashTable详解的知识,让您更了解java hashtable的本质,同时也会涉及到如何更有效地C#中的Hashtable 类使用详解、C#正则表达式与HashTable详解、hashtable PHP 源代码分析 Zend HashTable详解第1/3页、Hashtable与Java中的整数键的内容。
本文目录一览:- Java中的HashTable详解(java hashtable)
- C#中的Hashtable 类使用详解
- C#正则表达式与HashTable详解
- hashtable PHP 源代码分析 Zend HashTable详解第1/3页
- Hashtable与Java中的整数键
")
Java中的HashTable详解(java hashtable)
目录- 概论
- 对比HashMap 的初始容量
- 默认11 的初始容量
- 任意指定非负的容量
- 对比HashMap 的 对null 值的支持
- HashTable key value 都不支持null
- 升级HashTable 使其支持null 做value
- 对比 HashTable 的继承关系
- Dictionary
- 对比HashMap 的初始容量
- Hashtable
- 线程安全
- contains方法
- debug 源码 put 方法
- 总结
- 你觉得HashTable 还有什么可以改进的地方吗,欢迎讨论
概论
HashTable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。
Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
对比HashMap 的初始容量
默认11 的初始容量
需要注意的是Hashtable的默认初始容量大小是11,而HashMap 是16,但是他们的加载因子都是0.75f
/** * Constructs a new, empty hashtable with a default initial capacity (11) * and load factor (0.75). */ public Hashtable() { this(11, 0.75f); }/** * Constructs an empty <tt>HashMap</tt> with the default initial capacity * (16) and the default load factor (0.75). */public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}任意指定非负的容量
还有一点就是Hashtable的initialCapacity 也就是初始容量是是可以是你指定的任何非负整数,也就是你给它设置个0 也可以的
public Hashtable(int initialCapacity) { this(initialCapacity, 0.75f);}public Hashtable(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0) initialCapacity = 1; this.loadFactor = loadFactor; table = new Entry<?,?>[initialCapacity]; threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);}但是你看一下HashMap 的初始容量就不那么听话了,默认情况下,当我们设置HashMap的初始化容量时,实际上HashMap会采用第一个大于该数值的2的幂作为初始化容量(0 1 除外)
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity);}对比HashMap 的 对null 值的支持
HashTable key value 都不支持null
首先HashMap 是支持null 值做key和value 的,但是HashTable 是不支持的,key 也不支持 value 也不支持
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null;}聪明的你们发现了吗,上面值检测了value ==null 则抛出NPE 但是没有说key 啊,因为如果key 是null 的话,key.hashCode()则会抛出异常,根本不需要判断,但是value 就不会抛出来
但是需要注意的实HashMap 对null 值虽然支持,但是可以从hash值的计算方法中看出,<null,value>的键值对,value 会覆盖的。
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}升级HashTable 使其支持null 做value
大部分代码都是直接copy 的HashTable,只去掉了value 的空值检测
public class BuerHashTable<K, V> extends Hashtable<K, V> { // ..... 省略了部分代码,直接copy HashTable 的即可,主要是BuerHashTable.Entry 的定义和构造方法 public synchronized V put(K key, V value) { // Makes sure the key is not already in the hashtable. Entry<?,?> tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null; } private void addEntry(int hash, K key, V value, int index) { modCount++; BuerHashTable.Entry<?,?> tab[] = table; if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; hash = key.hashCode(); index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. @SuppressWarnings("unchecked") BuerHashTable.Entry<K,V> e = (BuerHashTable.Entry<K,V>) tab[index]; tab[index] = new BuerHashTable.Entry<>(hash, key, value, e); count++; }}接下来,就可以将null 值作为value 存入BuerHashTable 了
BuerHashTable<String, String> buerHashTable = new BuerHashTable<>();buerHashTable.put("a", null);对比 HashTable 的继承关系
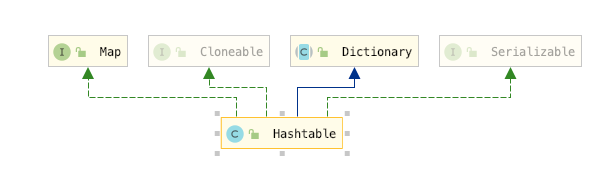
Dictionary
这个类是HashTable特有继承的,HashMap 是没有继承的,但是这个抽象类其实是没有多大意义的,因为它的方法都在Map接口中有,其实这个就是个历史问题了,因为Map接口是在Java1.2 中才加进去的,而Dictionary抽象类在Java1.0中就存在了
public abstractclass Dictionary<K,V> { public Dictionary() { } abstract public int size(); abstract public boolean isEmpty(); abstract public Enumeration<K> keys(); abstract public Enumeration<V> elements(); abstract public V get(Object key); /** * @exception NullPointerException if the <code>key</code> or */ abstract pu.........
C#中的Hashtable 类使用详解
一:Hashtable 类简单说明
1)表示根据键的哈希代码进行组织的键/值对的集合。使用哈希代码生成的哈希值,是唯一地标识数据的固定长度的数字值。
2)HashTable是System.Collections命名空间提供的一个容器,用于处理和表现类似keyvalue的键值对,其中key通常用来快速查找,key区分大小写;value用于存储对应key值。Hashtable中keyvalue键值对均为object类型,所以Hashtable可以支持任何类型的keyvalue键值对.
二:Hashtable 类的构造函数

三:Hashtable 类的属性
| 构造函数 | 构造函数说明 |
|---|---|
| Count | 获取包含在 Hashtable 中的键/值对的数目。 |
| EqualityComparer | 获取要用于 IEqualityComparer 的 Hashtable。 |
| IsFixedSize | 获取一个值,该值指示 Hashtable 是否具有固定大小。 |
| Item[Object] | 获取或设置与指定的键关联的值。 |
| Keys | 获取包含 ICollection 中的键的 Hashtable。 |
| Values | 获取一个 ICollection,它包含 Hashtable 中的值。 |
四:Hashtable 类的常用方法
1: Hashtable.Add(Object, Object) 的方法介绍
- 1)作用:将带有指定键和值的元素添加到 Hashtable 中。
- 2)语法:
public virtual void Add (object key, object value);
3)使用举例:
// 创建并初始化新的哈希表.
var myHT = new Hashtable();
myHT.Add("one", "The");
myHT.Add("two", "quick");
myHT.Add("three", "brown");
myHT.Add("four", "fox");
// 显示哈希表.
Console.WriteLine("哈希表包含以下内容:");
Console.WriteLine("\t-KEY-\t-VALUE-");
foreach (DictionaryEntry de in myHT)
{
Console.WriteLine($"\t{de.Key}:\t{de.Value}");
}4)运行结果:
哈希表包含以下内容:
-KEY- -VALUE-
three: brown
one: The
two: quick
four: fox
2: Hashtable.Clone ()的方法介绍
- 1)作用:创建 Hashtable 的浅表副本
- 2)语法:
public virtual object Clone ();
3)使用举例:
// 创建并初始化新的哈希表.
var myHT = new Hashtable();
myHT.Add(1, "Freedom");
myHT.Add(2, "Justice");
myHT.Add(3, "destiny");
myHT.Add(4, "GUNDAM");
// 克隆新的哈希表.
var myHT2 = (Hashtable)myHT.Clone();
// 显示克隆的哈希表.
Console.WriteLine("哈希表包含以下内容:");
Console.WriteLine("\t-KEY-\t-VALUE-");
foreach (DictionaryEntry de in myHT2)
{
Console.WriteLine($"\t{de.Key}:\t{de.Value}");
}4)运行结果:
哈希表包含以下内容:
-KEY- -VALUE-
4: GUNDAM
3: destiny
2: Justice
4: Freedom
3: Hashtable.ContainsKey(Object)和ContainsValue(Object)的方法介绍
- 1)作用:确定 Hashtable 是否包含特定键或者特定值。
- 2)语法:
public virtual bool ContainsKey (object key); public virtual bool ContainsValue (object value);
3)使用举例:
// 创建并初始化新的哈希表.
var myHT = new Hashtable();
myHT.Add(1, "Freedom");
myHT.Add(2, "Justice");
myHT.Add(3, "destiny");
myHT.Add(4, "GUNDAM");
Console.WriteLine("The key \"{0}\" is {1}.", 3, myHT.ContainsKey(3) ? "在哈希表中" : "不在在哈希表中");
Console.WriteLine("The key \"{0}\" is {1}.", 6, myHT.ContainsKey(6) ? "在哈希表中" : "不在在哈希表中");
Console.WriteLine("The value \"{0}\" is {1}.", "Freedom", myHT.ContainsValue("Freedom") ? "在哈希表中" : "不在在哈希表中");
Console.WriteLine("The value \"{0}\" is {1}.", "GUNDAM", myHT.ContainsValue("GUNDAM") ? "在哈希表中" : "不在在哈希表中");
4)运行结果:
The key "3" is 在哈希表中.
The key "6" is 不在在哈希表中.-
The value "Freedom" is 在哈希表中.
The value "GUNDAM" is 在哈希表中.
4:Hashtable.Remove(Object)的方法介绍
- 1)作用:确定 Hashtable 是否包含特定键或者特定值。
- 2)语法:
public virtual void Remove (object key);
3)使用举例:
// 创建并初始化新的哈希表.
var myHT = new Hashtable();
myHT.Add(1, "Freedom");
myHT.Add(2, "Justice");
myHT.Add(3, "destiny");
myHT.Add(4, "GUNDAM");
myHT.Remove(4);//移除指定键的元素
foreach (DictionaryEntry de in myHT)
{
Console.WriteLine($"\t{de.Key}:\t{de.Value}");
}4)运行结果:
3: destiny
2: Justice
1: Freedom
到此这篇关于C#中的Hashtable 类使用详解的文章就介绍到这了,更多相关C# Hashtable 类 内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- js 模拟实现类似c#下的hashtable的简单功能代码
- 聊聊C# 中HashTable与Dictionary的区别说明
- C# ArrayList、HashSet、HashTable、List、Dictionary的区别详解
- C#中哈希表(HashTable)用法实例详解(添加/移除/判断/遍历/排序等)
- ,Dictionary
- C#中遍历Hashtable的4种方法

C#正则表达式与HashTable详解
1、正则表达
Regular Expressiong,Regex、Regexp
常见语法:
- 字符匹配
- 重复匹配
- 字符定位
- 转义匹配
其他高级语法(字符分组、字符替换和字符决策)
正则表达式软件:RegEx Tester
匹配规则
- 原样匹配
元字符匹配:
- 原样匹配的时候,采用的都是不变的直接量字符
- 采用元字符可以匹配一类字符,元字符可以是一个单独的字符,也可以是一对(前一个字符通常是反斜杠)元字符:
正则表达式

- [a-zA-Z]:匹配a到z的任意字符
- [0-9]:匹配0到9的任意数字
转义字符
如果想查找元字符本身,就必须采用\配合对应院子符来取消特定字符。
如果想查找\或.就采用\或.
限定字符
限定字符又叫重复描述字符,标识一个字符要出现的次数

分组()

Ip地址正则表达式:
Ip地址匹配(需验证)
((25[0-5]|2[0-4]\d|[01]?\d?\d)\.){3}(25[0-5]|2[0-4]\d|[01]?\d?\d)
删除空行:^[\s\t]*\n
2、C#中正则表达式构建与匹配
使用方法:
- 引用命名空间System.Text.RegularExpressions
- 构造正则表达式
- 在使用正则表达式时,要先构造正则表达式,这就用到了Regex类。
其构建方式有两种:
- 基本形式:Regex(正则表达式)
- 重载形式:Regex(正则表达式,匹配选项)
其中匹配选项提供一些特殊的帮助,是一个枚举值,包括下面六个值:
- IgnoreCase(忽略大小写)
- ReghtToLeft(从右向左)
- None(默认)
- CultureInvariant(忽略区域)
- MultLine(多行模式)
- SingleLine(单行模式)
在Regex类中包含IsMatch(),Replace(),Split()等
IsMatch():测试字符是否满足正则表达式,返回一个布尔值,验证用户输入的数据是否满足条件(例如是否为合法手机号,是否为合法邮箱等)。
IsMatch()的使用格式:Regex.IsMatch(要判断的字符串,正则表达式)
using System;
using System.Text.RegularExpressions;
namespace 正则表达式的构建及匹配
{
class Program
{
static void Main(string[] args)
{
//判断是否为北京市固定电话,区号为010,民用电话号码为7-8位
string pattern = @"^(010|010-)\d{7,8}$"; //判定的模式
string[] input = { "010-12345678", "01023415678", "01098765897", "031078965476" };
Console.WriteLine("静态方法");
foreach (string outstr in input)
{
bool mybool = Regex.IsMatch(outstr.Trim(),pattern);
if(mybool)
{
Console.WriteLine(outstr+"是北京固话");
}
else
{
Console.WriteLine(outstr+"不是北京市固话");
}
}
//实例化的方式
Console.WriteLine("实例化方式");
foreach (string outstr in input)
{
Match mymatch = Regex.Match(outstr.Trim(), pattern);
if (mymatch.Success)
{
Console.WriteLine(outstr + "是北京固话");
}
else
{
Console.WriteLine(outstr + "不是北京市固话");
}
}
Console.ReadKey();
}
}
}正则表达式的替换
格式:Regex.Replace(要搜索匹配项的字符串,要替换的原字符串,替换后的字符串);
using System;
using System.Text.RegularExpressions;
namespace 正则表的是的替换
{
class Program
{
static void Main(string[] args)
{
//将www.替换为http://www.
string mystr = "Welcome to www.darly.net WWW.darly.com WwW.darly.org";
string pattern = @"\bw{3}\.\w+\.(com|net|org)\b";
string replacement1 = @"http://$&"; //$&匹配的内容
string replacement2 = "\n"+ @"http://$&"; //$&匹配的内容,此种方式只是将响应的字符拼接到匹配的字符串前面,
Console.WriteLine("替换前的字符串"+mystr);
Console.WriteLine("替换后的字符串1-1" + Regex.Replace(mystr, pattern, replacement1));
Console.WriteLine("替换后的字符串2-1" + Regex.Replace(mystr, "www.", @"http://www.")); //此种方式是将匹配的内容替换成目标字符
Console.WriteLine("替换后的字符串1_2" + Regex.Replace(mystr, pattern, replacement2,RegexOptions.IgnoreCase));
Console.WriteLine("替换后的字符串2-2" + Regex.Replace(mystr, "www.", "\n"+@"http://www.",RegexOptions.IgnoreCase));
Regex myregex = new Regex(pattern,RegexOptions.IgnoreCase);
string result = myregex.Replace(mystr, replacement2);
Console.WriteLine("替换后的字符串3" +result);
Regex myregex4 = new Regex(pattern,RegexOptions.IgnoreCase);
string result4 = myregex4.Replace(mystr, replacement2);
Console.WriteLine("替换后的字符串4" + result4);
string pattern5 = @"\bw{3}\.";
string replacement5 = "\n" + @"http://www.";
Console.WriteLine("替换后的字符串5" + Regex.Replace(mystr,pattern5,replacement5,RegexOptions.IgnoreCase));
Console.ReadLine();
}
}
}正则表达式拆分
要通过正则表达式拆分字符串,就要通过Regex类的Split方法,格式为:
Regex.Split(要拆分的字符串,要匹配的正则表达式模式)
using System;
using System.Text.RegularExpressions;
namespace 正则表达式的拆分
{
class Program
{
static void Main(string[] args)
{
string input = "一、张三 二、李四 三、王五 四、赵六";
string patern = @"\b[一二三四]、";
Console.WriteLine(Type.GetType((Regex.Split(input, patern)).ToString()));
foreach (string outstr in Regex.Split(input,patern))
{
if(!string.IsNullOrEmpty(outstr))Console.WriteLine(outstr);
}
Console.ReadKey();
}
}
}HashTable概述及元素添加
HashTable也被称作为哈希表,键值对或者关联数组。
用于处理和表写类似Ken/value的减值对,其中Key通常可用来快速查找,同时Key是区分大小写;Value用于存储对应于Key的值。HashTable中key/value键值对均为Object类型,所有HashTable可以支持任何类型的Key/Value键值对。
Hashtable特点:键与值成对存在,键时唯一的不能重复的
HashTable中的每个元素时一个存储在DictionaryEntry对象中的键值对
HashTable优点 :把数据的存储和查找的时间大降低几乎可以看成是常数时间;而代价仅仅小号比较多的内容。然而在当前可利用内存越来越多的情况下,用空间换取时间的做法是可取的。另外,编码比较容易也是他的特点之一。
声明格式:
引入命名空间:using System.Collections;
元素添加方法 Add
using System;
using System.Collections;
namespace Hasehtable1
{
class Program
{
static void Main(string[] args)
{
Hashtable ht = new Hashtable();
ht.Add("name", "darly");
ht.Add("gender", "男");
ht[3] = "王五"; //用此种方式一堆Hashtable去增加元素时应该注意
//如果对应的键key存在只是达到一种重新赋值的结果,如果不存在才会增加对应键值对
ht["gender"] = "女";
//数组通过length可以确定长度
//集合是通过count来确定个数
Console.WriteLine(ht.Count);
Console.ReadKey();
}
}
}Hashtable遍历
遍历用到DictionaryEntry(字典键/值对)
using System;
using System.Collections;
namespace Hasehtable1
{
class Program
{
static void Main(string[] args)
{
Hashtable ht = new Hashtable();
ht.Add("name", "darly");
ht.Add("gender", "男");
ht[3] = "王五"; //用此种方式一堆Hashtable去增加元素时应该注意
//如果对应的键key存在只是达到一种重新赋值的结果,如果不存在才会增加对应键值对
ht["gender"] = "女";
ht["department"] = "测试部";
//数组通过length可以确定长度
//集合是通过count来确定个数
Console.WriteLine(ht.Count);
foreach(object myobj in ht)
{
Console.WriteLine(myobj); //此处仅仅输入的是类型
}
foreach (DictionaryEntry myobj in ht)
{
Console.WriteLine("键为:{0},值为:{1}",myobj.Key,myobj.Value);
}
foreach(object myobj in ht.Keys)
{
Console.WriteLine("键为:{0};值为{1}", myobj,ht[myobj]);
}
Console.ReadKey();
}
}
}Hashtable元素的删除
- Remove
- Clear
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Hashtable元素删除
{
class Program
{
static void Main(string[] args)
{
Hashtable ht = new Hashtable();
ht.Add(1, "张飒");
ht.Add(true,"李四");
ht.Add(false, "王五");
ht.Add(3, "赵六");
foreach(DictionaryEntry myde in ht)
{
Console.WriteLine("键为{0},值为:{1}", myde.Key, myde.Value);
}
//删除Remove
ht.Remove(false);
Console.WriteLine("移除结果");
foreach (DictionaryEntry myde in ht)
{
Console.WriteLine("键为{0},值为:{1}", myde.Key, myde.Value);
}
//删除Clear,删除所有内容
ht.Clear();
Console.WriteLine("清除结果");
foreach (DictionaryEntry myde in ht)
{
Console.WriteLine("键为{0},值为:{1}", myde.Key, myde.Value);
}
Console.ReadLine();
}
}
}HashTable元素查找
Hashtable特点:键与值成对存在,键时唯一的不能重复的,在查找元素的时候,我们往往是依据键查找值的。
三种方法:(前两种方法是实质是一样的)
- Contains
- ContainsKey
- ContainsValue
using System;
using System.Collections;
namespace Hashtable元素查找
{
class Program
{
static void Main(string[] args)
{
Hashtable ht = new Hashtable();
ht.Add(1, "张三");
ht.Add(2, "里斯");
ht.Add(3, "王五");
ht.Add(4, "赵六");
ht[5] = "何七";
ht[6] = "张三";
Console.WriteLine("添加的结果");
foreach(DictionaryEntry myde in ht)
{
Console.WriteLine("键为{0}——职位{1}", myde.Key, myde.Value);
}
//元素查找
if(ht.ContainsKey(1)) //ContainsKey()存在返回true,不存在返回false
Console.WriteLine("存在键=1的元素");
else Console.WriteLine("不存在该该键");
if (ht.ContainsValue("张三")) Console.WriteLine("存在值为张三的元素");
else Console.WriteLine("不存在值为张三的元素");
Console.Read();
}
}
}任务小结
统计指定字符串(字符串可自行声明)中汉字的个数以及每个汉字出现的次数,将其输出到屏幕上
编程思路:
- 判断汉字,可以通过正则表达式
- 然后可将对应汉字存入ArrayList中
- 通过一定的运算规则,计算出汉字的个数与出现的次数并将结果对应存入Hashtable
- 遍历Hashtable即可完成任务实施
using System;
using System.Text.RegularExpressions;
using System.Collections;
namespace 任务小结
{
class Program
{
static void Main(string[] args)
{
//统计指定字符串(字符串可自行声明)中汉字的个数以及每个汉字出现的次数,将其输出到屏幕上
Console.WriteLine("请输入一个字符串,系统将自动计算汉字个数以及每个汉字的出现次数");
string mystr = Console.ReadLine();
string pattern = @"[^\u4e00-\u9fa5]"; //判定非汉字的字符,将非汉字的字符替换掉就是全部的汉字
Regex myregex = new Regex(pattern);
string chnstr = myregex.Replace(mystr, "");
Hashtable ht = new Hashtable();
for (int i = 0; i < chnstr.Length; i++)
{
int val = 1;
if(ht.ContainsKey(chnstr[i]))
{
val = Convert.ToInt32(ht[chnstr[i]]);
++val;
ht[chnstr[i]] = val;
}
else
{
ht.Add(chnstr[i], val);
}
}
Console.WriteLine("原有的字符串是:" + mystr);
foreach (DictionaryEntry de in ht)
{
Console.WriteLine("汉字{0}出现了{1}次",de.Key,de.Value);
}
Console.ReadKey();
}
}
}到此这篇关于C#正则表达式与HashTable详解的文章就介绍到这了,更多相关C# 正则表达式内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- C#正则表达式大全
- 如何使用正则表达式判断邮箱(以C#为例)
- C# 中使用正则表达式匹配字符的含义
- C#中正则表达式与回车换行符问题
- 使用C#的正则表达式验证中文字符(实例代码)
- ,Dictionary
- C#中遍历Hashtable的4种方法
- C#将hashtable值转换到数组中的方法
- C# Hashtable/Dictionary写入和读取对比详解

hashtable PHP 源代码分析 Zend HashTable详解第1/3页
HashTable在通常的数据结构教材中也称作散列表,哈希表。其基本原理比较简单(如果你对其不熟悉,请查阅随便一本数据结构教材或在网上搜索),但PHP的实现有其独特的地方。理解了HashTable的数据存储结构,对我们分析PHP的源代码,特别是Zend Engine中的虚拟机的实现时,有很重要的帮助。它可以帮助我们在大脑中模拟一个完整的虚拟机的形象。它也是PHP中其它一些数据结构如数组实现的基础。
Zend HashTable的实现结合了双向链表和向量(数组)两种数据结构的优点,为PHP提供了非常高效的数据存储和查询机制。
Let''s begin!
一、 HashTable的数据结构
在Zend Engine中的HashTable的实现代码主要包括zend_hash.h, zend_hash.c这两个文件中。Zend HashTable包括两个主要的数据结构,其一是Bucket(桶)结构,另一个是HashTable结构。Bucket结构是用于保存数据的容器,而HashTable结构则提供了对所有这些Bucket(或桶列)进行管理的机制。
复制代码 代码如下:
typedef struct bucket {
ulong h; /* Used for numeric indexing */
uint nKeyLength; /* key 长度 */
void *pData; /* 指向Bucket中保存的数据的指针 */
void *pDataPtr; /* 指针数据 */
struct bucket *pListNext; /* 指向HashTable桶列中下一个元素 */
struct bucket *pListLast; /* 指向HashTable桶列中前一个元素 */
struct bucket *pNext; /* 指向具有同一个hash值的桶列的后一个元素 */
struct bucket *pLast; /* 指向具有同一个hash值的桶列的前一个元素 */
char arKey[1]; /* 必须是最后一个成员,key名称*/
} Bucket;
在Zend HashTable中,每个数据元素(Bucket)有一个键名(key),它在整个HashTable中是唯一的,不能重复。根据键名可以唯一确定HashTable中的数据元素。键名有两种表示方式。第一种方式使用字符串arKey作为键名,该字符串的长度为nKeyLength。注意到在上面的数据结构中arKey虽然只是一个长度为1的字符数组,但它并不意味着key只能是一个字符。实际上Bucket是一个可变长的结构体,由于arKey是Bucket的最后一个成员变量,通过arKey与nKeyLength结合可确定一个长度为nKeyLength的key。这是C语言编程中的一个比较常用的技巧。另一种键名的表示方式是索引方式,这时nKeyLength总是0,长整型字段h就表示该数据元素的键名。简单的来说,即如果nKeyLength=0,则键名为h;否则键名为arKey, 键名的长度为nKeyLength。
当nKeyLength > 0时,并不表示这时的h值就没有意义。事实上,此时它保存的是arKey对应的hash值。不管hash函数怎么设计,冲突都是不可避免的,也就是说不同的arKey可能有相同的hash值。具有相同hash值的Bucket保存在HashTable的arBuckets数组(参考下面的解释)的同一个索引对应的桶列中。这个桶列是一个双向链表,其前向元素,后向元素分别用pLast, pNext来表示。新插入的Bucket放在该桶列的最前面。
在Bucket中,实际的数据是保存在pData指针指向的内存块中,通常这个内存块是系统另外分配的。但有一种情况例外,就是当Bucket保存的数据是一个指针时,HashTable将不会另外请求系统分配空间来保存这个指针,而是直接将该指针保存到pDataPtr中,然后再将pData指向本结构成员的地址。这样可以提高效率,减少内存碎片。由此我们可以看到PHP HashTable设计的精妙之处。如果Bucket中的数据不是一个指针,pDataPtr为NULL。
HashTable中所有的Bucket通过pListNext, pListLast构成了一个双向链表。最新插入的Bucket放在这个双向链表的最后。
注意在一般情况下,Bucket并不能提供它所存储的数据大小的信息。所以在PHP的实现中,Bucket中保存的数据必须具有管理自身大小的能力。
复制代码 代码如下:
typedef struct _hashtable {
uint nTableSize;
uint nTableMask;
uint nNumOfElements;
ulong nNextFreeElement;
Bucket *pInternalPointer;
Bucket *pListHead;
Bucket *pListTail;
Bucket **arBuckets;
dtor_func_t pDestructor;
zend_bool persistent;
unsigned char nApplyCount;
zend_bool bApplyProtection;
#if ZEND_DEBUG
int inconsistent;
#endif
} HashTable;
当前1/3页 123下一页
立即学习“PHP免费学习笔记(深入)”;
以上就介绍了hashtable PHP 源代码分析 Zend HashTable详解第1/3页,包括了hashtable方面的内容,希望对PHP教程有兴趣的朋友有所帮助。

Hashtable与Java中的整数键
Hashtable<int,ArrayList<byte>> block = new Hashtable<int,ArrayList<byte>>();
但是我在整数和字节上都会显示“这个令牌后面的尺寸”.
如果我使用像:
哈希表< String,byte []> – 一切都很好.有人可以解释为什么吗
谢谢.
解决方法
正如@Giuseppe所说,你可以这样定义它:
Hashtable<Integer,ArrayList<Byte>> table = new Hashtable<Integer,ArrayList<Byte>>();
然后把原始的int放在它中作为键:
table.put(4,...);
因为自从Java 1.5以来,autoboxing将自动将原始int改成后面的整数(包装).
如果您需要更多的速度(并且测量包装收集类是问题!),您可以使用第三方库,可以在其集合中存储原语.这种图书馆的一个例子是Trove和Colt.
今天的关于Java中的HashTable详解和java hashtable的分享已经结束,谢谢您的关注,如果想了解更多关于C#中的Hashtable 类使用详解、C#正则表达式与HashTable详解、hashtable PHP 源代码分析 Zend HashTable详解第1/3页、Hashtable与Java中的整数键的相关知识,请在本站进行查询。
本文标签:




