在本文中,我们将为您详细介绍JPA实体何时以及为什么应该实现Serializable接口?的相关知识,并且为您解答关于jpa的实现的疑问,此外,我们还会提供一些关于hibernate对象为什么需要实现
在本文中,我们将为您详细介绍JPA 实体何时以及为什么应该实现 Serializable 接口?的相关知识,并且为您解答关于jpa的实现的疑问,此外,我们还会提供一些关于hibernate 对象为什么需要实现 Serializable 接口、HttpServlet为什么实现Serializable?、Java 基础 (十一)--Serializable 和 Externalizable 接口实现序列化、Java 序列化和反序列化为什么要实现 Serializable 接口的有用信息。
本文目录一览:- JPA 实体何时以及为什么应该实现 Serializable 接口?(jpa的实现)
- hibernate 对象为什么需要实现 Serializable 接口
- HttpServlet为什么实现Serializable?
- Java 基础 (十一)--Serializable 和 Externalizable 接口实现序列化
- Java 序列化和反序列化为什么要实现 Serializable 接口
")
JPA 实体何时以及为什么应该实现 Serializable 接口?(jpa的实现)
问题在标题中。下面我只是描述了我的一些想法和发现。
当我有一个非常简单的域模型(3 个没有任何关系的表)时,我的所有实体都没有实现该Serializable接口。
但是当域模型变得更加复杂时,我得到了一个RuntimeException,说我的一个实体没有实现Serializable。
我使用 Hibernate 作为 JPA 实现,我想知道:
- 它是供应商特定的要求/行为吗?
- 我的可序列化实体会发生什么?它们应该可序列化以进行存储或传输吗?
- 什么时候需要使我的实体可序列化?
答案1
小编典典如果您混合使用 HQL 和本机 SQL 查询,通常会发生这种情况。在 HQL 中,Hibernate
将您传入的类型映射到数据库可以理解的任何类型。当您运行本机 SQL
时,您必须自己进行映射。如果您不这样做,则默认映射是将参数序列化并将其发送到数据库(希望它确实理解它)。

hibernate 对象为什么需要实现 Serializable 接口
注意区分持久化和序列化,持久化是把对象中的信息转换为数据库中的表来存储;序列化是将对象(java 对象)直接变成字符串等流,存储到硬盘上,不涉及数据库表。
序列化的目的主要是方便直接传输对象,而不是每次都要连接数据库表。
hibernate 有两种缓存。其中,一级缓存为 session 级别,通常由内存管理。二级缓存是 sessionFactory 级别,存储介质可以是内存或硬盘。对于二级缓存,如果将对象写进硬盘,就必须序列化,以及兼容对象在网络中的传输 等等。
java 中常见的几个类(如:Interger、String 等),都实现了 java.io.Serializable 接口。
实现 java.io.Serializable 接口的类是可序列化的。没有实现此接口的类将不能使它们的任一状态被序列化或逆序列化。序列化类的所有子类本身都是可序列化的。这个序列化接口没有任何方法和域,仅用于标识序列化的语意。
确切的说应该是对象的序列化,一般程序在运行时,产生对象,这些对象随着程序的停止运行而消失,但如果我们想把某些对象(因为是对象,所以有各自 不同的特性)保存下来,在程序终止运行后,这些对象仍然存在,可以在程序再次运行时读取这些对象的值,或者在其他程序中利用这些保存下来的对象。这种情况 下就要用到对象的序列化。
只有序列化的对象才可以存储在存储设备上。为了对象的序列化而需要继承的接口也只是一个象征性的接口而已,也就是说继承这个接口说明这个对象可以 被序列化了,没有其他的目的。之所以需要对象序列化,是因为有时候对象需要在网络上传输,传输的时候需要这种序列化处理,从服务器硬盘上把序列化的对象取 出,然后通过网络传到客户端,再由客户端把序列化的对象读入内存,执行相应的处理。
将二级缓存中的内容持久化保存下来,便于恢复缓存的信息,hibernate 的缓存机制通过使用序列化,断定应该是基于序列化的缓存,如没有 serializable 接口,在序列化时,使用 objectOutputStream 的 write(object)方法将对象保存到文件时将会出现异常。
Hibernate 并不要求持久化类必须实现 Java.io.Serializable 接口,但是对于采用分布式结构的 Java 应用,当 Java 对象在不同的进程节点之间传输时,这个对象所属的类必须实现 Serializable 接口,此外,在 Java Web 应用中,如果希望对 HttpSession 中存放的 Java 对象进行持久化,那么这个 Java 对象所属的类也必须实现 Serializable 接口。

HttpServlet为什么实现Serializable?
在我对Servlet的理解中,该Servlet将由Container实例化,其init()方法将被调用一次,并且Servlet将像单例一样存活,直到JVM关闭。
我不希望我的servlet被序列化,因为当应用服务器恢复或正常启动时,它将被重新构造。Servlet不应该包含特定于会话的成员,因此将其写入磁盘并重新实例化是没有意义的。有实际用途吗?
我担心的是,我在其中放置了一些不可序列化的字段,然后我的应用程序将在生产环境中神秘地失败,在生产环境中将进行另一种会话复制。
答案1
小编典典从技术上讲,我相信servlet容器被允许以类似于EJB会话bean的方式将servlet对象“钝化”到磁盘。因此,您是正确的问题,您的应用是否会由于不可序列化的字段而失败。
实际上,我从未听说过有容器可以做到这一点,所以它实际上只是早期J2EE糟糕时期的遗留物。我不用担心。
--Serializable 和 Externalizable 接口实现序列化")
Java 基础 (十一)--Serializable 和 Externalizable 接口实现序列化
序列化在日常开发中经常用到,特别是涉及到网络传输的时候,例如调用第三方接口,通过一个约定好的实体进行传输,这时你必须实现序列
化,这些都是大家都了解的内容,所以文章也会讲一下序列化的高级内容。
序列化与反序列化简单认知:
我们知道,对象在不具有可达性的时候,会被 GC,这些对象都是保存在堆中,而现实中,我们可能需要将对象进行持久化,并且在需要的时候
进行读取转换,这就是序列化的工作。
1、序列化:
将一个对象转换成字节流或者说是字节数组,并且可以存储或传输的形式的过程。
存储:可以把一个对象存储到文件、数据库等
网络传输:可以转化成字节或 XML 进行网络传输
2、反序列化:
和序列化是一个相反的过程,在需要的时候,把字节数组转化成对象。
序列化广泛应用于远程调用等所有涉及网络传输的地方
序列化相关接口:
Serializable、Externalizable、ObjectOutput、ObjectInput、ObjectOutputStream、ObjectInputStream
Serializable 接口:
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Student implements Serializable {
private int id;
private String name;
private int sex;
private transient String addr;
} public static void main(String[] args) throws Exception{
Student student = new Student(1001, "sam", 1, "SH");
File file = new File("D:\\a.txt");
FileOutputStream fileOutputStream = new FileOutputStream(file);
ObjectOutputStream outputStream = new ObjectOutputStream(fileOutputStream);
outputStream.writeObject(student);
outputStream.close();
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream(file));
Student student1 = (Student)inputStream.readObject();
System.out.println(student1.toString());
inputStream.close();
}结果:
Student(id=1001, name=sam, sex=1, addr=null) 我们通过 Binary Viewer 查看这个二进制文件 a.txt,下面二进制内容解释参考自:https://www.cnblogs.com/xrq730/p/4821958.html
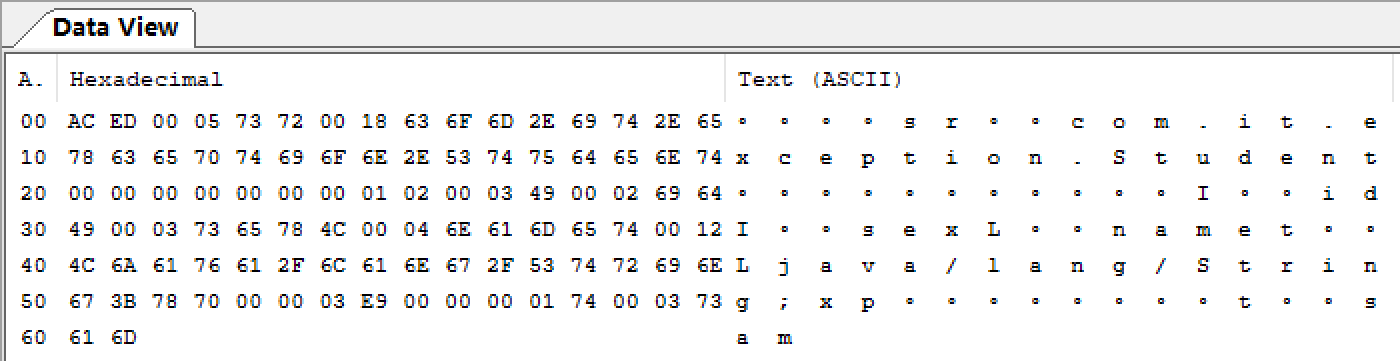
第一部分:序列化文件头
1、AC ED:STREAM_MAGIC 序列化协议
2、00 05:STREAM_VERSION 序列化协议版本
3、73:TC_OBJECT 声明这是一个新的对象
第二部分:序列化的类的描述,在这里是 Student 类
1、72:TC_CLASSDESC 声明这里开始一个新的 class
2、00 18: 十进制的 24,表示 class 名字的长度是 24 个字节
3、63 6F 6D ... 6E 74 20:表示的是 “com.it.exception.Student” 这一串字符,可以数一下确实是 24 个字节
4、00 00 00 00 00 00 00 01:SerialVersion,序列化 ID,1
5、02:标记号,声明该对象支持序列化
6、00 03:该类所包含的域的个数为 3 个
第三部分:是对象中各个属性项的描述
1、49:int 类型
2、00 02:十进制的 2,表示字段长度
3、69 64:表示字段 id
4、49:int 类型
省略了 sex、name 属性,可以自行查看
5、74:TC_STRING,代表一个 new String,用 String 来引用对象
第四部分:该对象父类的信息,如果没有父类就没有这部分。有父类和第 2 部分差不多
1、00 12:十进制的 18,表示父类的长度
2、4C 6A 61 ... 6E 67 3B:“L/java/lang/String;” 表示的是父类属性
3、78:TC_ENDBLOCKDATA,对象块结束的标志
4、70:TC_NULL,说明没有其他超类的标志
第五部分:输出对象的属性项的实际值,如果属性项是一个对象,这里还将序列化这个对象,规则和第 2 部分一样
1、00 03:十进制的 3,属性的长度
2、73 61 6D:字符串 "sam",name 的属性值
以上是二进制文件的解析,可以得出结论:
1、序列化之后保存的是对象的信息
2、被声明为 transient 的属性不会被序列化,这就是 transient 关键字的作用,addr 字段并没有保存
所以,我们得出结论,static 字段也不会被序列化,因为 static 变量属于类的
Externalizable 接口:
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out) throws IOException;
restored cannot be found.
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
}使用样例:
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Student implements Externalizable{
private static final long serialVersionUID = 1L;
private int id;
private String name;
private int sex;
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(id);
out.writeObject(name);
out.writeObject(sex);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
id = (Integer)in.readObject();
name = (String)in.readObject();
sex = (Integer)in.readObject();
}
}public class Test {
public static void main(String[] args) throws Exception{
Student student = new Student(1001, "sam", 1);
File file = new File("D:\\a.txt");
FileOutputStream fileOutputStream = new FileOutputStream(file);
ObjectOutputStream outputStream = new ObjectOutputStream(fileOutputStream);
outputStream.writeObject(student);
outputStream.close();
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream(file));
Student student1 = (Student)inputStream.readObject();
System.out.println(student1.toString());
inputStream.close();
}
}结果:
Student(id=1001, name=sam, sex=1)从结果看 Externalizable 接口同样可以实现序列化和反序列化,但是有些地方不太一样,需要注意
1、相关类必须有默认构造器,否则会抛出异常,是因为在读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,然后再将被
保存对象的字段的值分别填充到新对象中。
2、需要重写 writeExternal 和 readExternal 方法,去控制序列化,并且写入字段顺序和读取顺序要保持一致,写入和读取支持多种类型,不必
一定使用 object,这样不用类型转换
自定义序列化:
我们使用序列化的时候,一般情况都是使用默认的方式,而如果在一些特殊场景下我们需要进行特殊处理,例如字段加密,因为序列化是不安
全的。
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class Student implements Serializable{
private static final long serialVersionUID = 1L;
private int id;
private String name;
private int sex;
private void writeObject(ObjectOutputStream outputStream) throws Exception {
outputStream.defaultWriteObject();
outputStream.writeBoolean(true);
}
private void readObject(ObjectInputStream inputStream) throws Exception {
inputStream.defaultReadObject();
boolean flag = inputStream.readBoolean();
System.out.println("flag: " + flag);
}
}测试代码不变
flag: true
Student(id=1001, name=sam, sex=1)从代码上看和 Externalizable 接口几乎一样的,通过 writeObject () 和 readObject () 实现自定义的过程
原因:
虚拟机会首先试图调用对象里的 writeObject () 和 readObject (),进行用户自定义的序列化和反序列化。如果没有这样的方法,那么默认调用的
是 ObjectOutputStream 的 defaultWriteObject 以及 ObjectInputStream 的 defaultReadObject 方法
我们在查看 jdk 集合的源码中可以看到,ArrayList、HashMap 等在实现序列化的时候,都是自定义 writeObject () 和 readObject () 的
PS:虚拟机通过反射来调用 writeObject () 和 readObject ()
ArrayList 序列化:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
transient Object[] elementData; //通过数组保存集合数据
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
s.defaultReadObject();
s.readInt(); // ignored
if (size > 0) {
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
}ArrayList 这样实现的目的:
ArrayList 是动态数组,数组中的数据在达到阀值就会扩容,如果数组扩容后长度设为 100,而里面只存放了 10 条数据,那就会序列化 90 个
null 元素。为了保证在序列化的时候不会将这么多 null 同时进行序列化,ArrayList 把元素数组设置为 transient,然后通过遍历数组讲数据进行
序列化和反序列化
总结:
1、在 Java 中,只要一个类实现了 Serializable 接口,那么它就可以被序列化
2、通过ObjectOutputStream和ObjectInputStream对对象进行序列化及反序列化
3、当父类继承 Serializable 接口,所有子类都可以被序列化
4、子类实现了 Serializable 接口,如果想要父类的属性也能实现序列化,必须父类也实现 Serializable 接口,否则父类中的属性不能序列
化(不报错,数据丢失),但是在子类中属性仍能正确序列化
5、如果序列化的属性是对象,则这个对象也必须实现 Serializable 接口,否则会报错
6、序列化并不保存静态变量
7、反序列化能否成功,要求:①. 类路径相同,②. 序列化 ID 保持一致 (serialVersionUID),否则无法成功
8、反序列化时,如果对象的属性有修改或删减,则修改的部分属性会丢失,但不会报错
5、序列化数据如果比较敏感,可以采用加密的方式,增加一定安全性
内容参考:
https://www.cnblogs.com/xrq730/p/4821958.html
http://www.importnew.com/18024.html
https://www.ibm.com/developerworks/cn/java/j-lo-serial/

Java 序列化和反序列化为什么要实现 Serializable 接口
当你无法从一楼蹦到三楼时,不要忘记走楼梯。要记住伟大的成功往往不是一蹴而就的,必须学会分解你的目标,逐步实施。
公司的系统在做服务化, 需要把所有model包里的类都实现Serializable接口, 同时还要显示指定serialVersionUID的值。听到这个需求, 我脑海里突然出现了好几个问题, 比如说:
- 序列化和反序列化是什么?
- 实现序列化和反序列化为什么要实现Serializable接口?
- 实现Serializable接口就算了, 为什么还要显示指定serialVersionUID的值?
- 我要为serialVersionUID指定个什么值?
下面我们来一一解答这几个问题.
序列化和反序列化
- 序列化:把对象转换为字节序列的过程称为对象的序列化.
- 反序列化:把字节序列恢复为对象的过程称为对象的反序列化.
什么时候需要用到序列化和反序列化呢?
当我们只在本地JVM里运行下Java实例, 这个时候是不需要什么序列化和反序列化的, 但当我们需要将内存中的对象持久化到磁盘, 数据库中时, 当我们需要与浏览器进行交互时, 当我们需要实现RPC时, 这个时候就需要序列化和反序列化了.
前两个需要用到序列化和反序列化的场景, 是不是让我们有一个很大的疑问? 我们在与浏览器交互时, 还有将内存中的对象持久化到数据库中时, 好像都没有去进行序列化和反序列化, 因为我们都没有实现Serializable接口, 但一直正常运行.
下面先给出结论:
只要我们对内存中的对象进行持久化或网络传输, 这个时候都需要序列化和反序列化.
理由:
服务器与浏览器交互时真的没有用到Serializable接口吗? JSON格式实际上就是将一个对象转化为字符串, 所以服务器与浏览器交互时的数据格式其实是字符串, 我们来看来String类型的源码:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
...
}String类型实现了Serializable接口, 并显示指定serialVersionUID的值。
然后我们再来看对象持久化到数据库中时的情况, Mybatis数据库映射文件里的insert代码:
<insert id="insertUser" parameterType="org.tyshawn.bean.User">
INSERT INTO t_user(name, age) VALUES (#{name}, #{age})
</insert>实际上我们并不是将整个对象持久化到数据库中, 而是将对象中的属性持久化到数据库中, 而这些属性都是实现了Serializable接口的基本属性.
实现序列化和反序列化为什么要实现Serializable接口?
在Java中实现了Serializable接口后, JVM会在底层帮我们实现序列化和反序列化, 如果我们不实现Serializable接口, 那自己去写一套序列化和反序列化代码也行, 至于具体怎么写, Google一下你就知道了.
实现Serializable接口就算了, 为什么还要显示指定serialVersionUID的值?
如果不显示指定serialVersionUID, JVM在序列化时会根据属性自动生成一个serialVersionUID, 然后与属性一起序列化, 再进行持久化或网络传输. 在反序列化时, JVM会再根据属性自动生成一个新版serialVersionUID, 然后将这个新版serialVersionUID与序列化时生成的旧版serialVersionUID进行比较, 如果相同则反序列化成功, 否则报错.
如果显示指定了serialVersionUID, JVM在序列化和反序列化时仍然都会生成一个serialVersionUID, 但值为我们显示指定的值, 这样在反序列化时新旧版本的serialVersionUID就一致了.
在实际开发中, 不显示指定serialVersionUID的情况会导致什么问题? 如果我们的类写完后不再修改, 那当然不会有问题, 但这在实际开发中是不可能的, 我们的类会不断迭代, 一旦类被修改了, 那旧对象反序列化就会报错. 所以在实际开发中, 我们都会显示指定一个serialVersionUID, 值是多少无所谓, 只要不变就行.
写个实例测试下:
(1) User类
不显示指定serialVersionUID.
public class User implements Serializable {
private String name;
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name=''" + name + ''\'''' +
", age=" + age +
''}'';
}
}(2) 测试类
先进行序列化, 再进行反序列化.
public class SerializableTest {
private static void serialize(User user) throws Exception {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("D:\\111.txt")));
oos.writeObject(user);
oos.close();
}
private static User deserialize() throws Exception {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("D:\\111.txt")));
return (User) ois.readObject();
}
public static void main(String[] args) throws Exception {
User user = new User();
user.setName("tyshawn");
user.setAge(18);
System.out.println("序列化前的结果: " + user);
serialize(user);
User dUser = deserialize();
System.out.println("反序列化后的结果: " + dUser);
}
}(3) 结果
先注释掉反序列化代码, 执行序列化代码, 然后User类新增一个属性sex
public class User implements Serializable {
private String name;
private Integer age;
private String sex;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
return "User{" +
"name=''" + name + ''\'''' +
", age=" + age +
", sex=''" + sex + ''\'''' +
''}'';
}
}再注释掉序列化代码执行反序列化代码, 最后结果如下:
序列化前的结果: User{name=''tyshawn'', age=18}
Exception in thread "main" java.io.InvalidClassException: org.tyshawn.SerializeAndDeserialize.User; local class incompatible: stream classdesc serialVersionUID = 1035612825366363028, local class serialVersionUID = -1830850955895931978
报错结果为序列化与反序列化产生的serialVersionUID不一致.
接下来我们在上面User类的基础上显示指定一个serialVersionUID
private static final long serialVersionUID = 1L;再执行上述步骤, 测试结果如下:
序列化前的结果: User{name=''tyshawn'', age=18}
反序列化后的结果: User{name=''tyshawn'', age=18, sex=''null''}
显示指定serialVersionUID后就解决了序列化与反序列化产生的serialVersionUID不一致的问题.更多面试题,欢迎关注 公众号Java面试题精选
Java序列化的其他特性
先说结论, 被transient关键字修饰的属性不会被序列化, static属性也不会被序列化.
我们来测试下这个结论:
(1) User类
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
private transient String sex;
private static String signature = "你眼中的世界就是你自己的样子";
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public static String getSignature() {
return signature;
}
public static void setSignature(String signature) {
User.signature = signature;
}
@Override
public String toString() {
return "User{" +
"name=''" + name + ''\'''' +
", age=" + age +
", sex=''" + sex + ''\'''' +
", signature=''" + signature + ''\'''' +
''}'';
}
}(2) 测试类
public class SerializableTest {
private static void serialize(User user) throws Exception {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("D:\\111.txt")));
oos.writeObject(user);
oos.close();
}
private static User deserialize() throws Exception {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("D:\\111.txt")));
return (User) ois.readObject();
}
public static void main(String[] args) throws Exception {
User user = new User();
user.setName("tyshawn");
user.setAge(18);
user.setSex("man");
System.out.println("序列化前的结果: " + user);
serialize(user);
User dUser = deserialize();
System.out.println("反序列化后的结果: " + dUser);
}
}(3) 结果
先注释掉反序列化代码, 执行序列化代码, 然后修改User类signature = “我的眼里只有你”, 再注释掉序列化代码执行反序列化代码, 最后结果如下:
序列化前的结果: User{name=''tyshawn'', age=18, sex=''man'', signature=''你眼中的世界就是你自己的样子''}
反序列化后的结果: User{name=''tyshawn'', age=18, sex=''null'', signature=''我的眼里只有你''}
static属性为什么不会被序列化?
因为序列化是针对对象而言的, 而static属性优先于对象存在, 随着类的加载而加载, 所以不会被序列化.
看到这个结论, 是不是有人会问, serialVersionUID也被static修饰, 为什么serialVersionUID会被序列化? 其实serialVersionUID属性并没有被序列化, JVM在序列化对象时会自动生成一个serialVersionUID, 然后将我们显示指定的serialVersionUID属性值赋给自动生成的serialVersionUID.
今天关于JPA 实体何时以及为什么应该实现 Serializable 接口?和jpa的实现的讲解已经结束,谢谢您的阅读,如果想了解更多关于hibernate 对象为什么需要实现 Serializable 接口、HttpServlet为什么实现Serializable?、Java 基础 (十一)--Serializable 和 Externalizable 接口实现序列化、Java 序列化和反序列化为什么要实现 Serializable 接口的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

