这篇文章主要围绕DMA和cache一致性问题和dmacache一致性展开,旨在为您提供一份详细的参考资料。我们将全面介绍DMA和cache一致性问题的优缺点,解答dmacache一致性的相关问题,同时
这篇文章主要围绕DMA和cache一致性问题和dma cache一致性展开,旨在为您提供一份详细的参考资料。我们将全面介绍DMA和cache一致性问题的优缺点,解答dma cache一致性的相关问题,同时也会为您带来ARM Cortex-A53 Cache与内存的映射关系以及Cache的一致性分析、Cache 工作原理、Cache 一致性,你想知道的都在这里、Cache一致性与2种基本写策略(1)、Cache一致性协议与MESI(2)的实用方法。
本文目录一览:- DMA和cache一致性问题(dma cache一致性)
- ARM Cortex-A53 Cache与内存的映射关系以及Cache的一致性分析
- Cache 工作原理、Cache 一致性,你想知道的都在这里
- Cache一致性与2种基本写策略(1)
- Cache一致性协议与MESI(2)
")
DMA和cache一致性问题(dma cache一致性)
Cache原理
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。缓存的出现主要是为了解决CPU运算速度与内存 读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。在缓存中的数据是内存中的 一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
只要Cache的空间与主存空间在一定范围内保持适当比例的映射关系,Cache的命中率还是相当高的。一般规定Cache与内存的空间比为4:1000,即128kB Cache可映射32MB内存;256kB Cache可映射64MB内存。在这种情况下。命中率都在90%以上。至于没有命中的数据,CPU只好直接从内存获取。获取的同时,也把它拷进Cache。
cache一致性问题
由于缓存存在于cpu与内存中间,所以任何外设对内存的修改并不能保证cache中也得到同样的更新,同样处理器对缓存中内容的修改也不能保证内存中的数据 得到更新。这种缓存中数据与内存中数据的不同步和不一致现象将可能导致使用DMA 传输数据时 或 处理器运行自修改代码时产生错误。
Cache的一致性就是指Cache中的数据,与对应的内存中的数据是一致的。
Cache的基本结构
Cache通常由相联存储器实现。相联存储器的每一个存储块都具有额外的存储信息,称为标签(Tag)。当访问相联存储器时,将地址和每一个标签同时进行比较,从而对标签相同的存储块进行访问。Cache的3种基本结构如下:
全相联Cache
在全相联Cache中,存储的块与块之间。以及存储顺序或保存的存储器地址之间没有直接的关系。程序可以访问很多的子程序、堆栈和段,而它们是位于主存储器的不同部位上。 因此。Cache保存着很多互不相关的数据块。
Cache必须对每个块和块自身的地址加以存储。当请求数据时,Cache控制器要把请求地址同所有地址加以比较进行确认。
这种Cache结构的主要优点是。
它能够在给定的时间内去存储主存器中的不同的块,命中率高;缺点是每一次请求数据同Cache中的地址进行比较需要相当的时间,速度较慢。
直接映像Cache
直接映像Cache不同于全相联Cache。地址仅需比较一次。
在直接映像Cache中。由于每个主存储器的块在Cache中仅存在一个位置,因而把地址的比较次数减少为一次。其做法是,为Cache中的每个块位置分配一个索引字段,用Tag字段区分存放在Cache位置上的不同的块。单路直接映像把主存储器分成若干页。主存储器的每一页与Cache存储器的大小相同。匹配的主存储器的偏移量可以直接映像为Cache偏移量。Cache的Tag存储器(偏移量)保存着主存储器的页地址(页号)。
以上可以看出。直接映像Cache优于全相联Cache,能进行快速查找,其缺点是当主存储器的组之间做频繁调用时,Cache控制器必须做多次转换。
组相联Cache
组相联Cache是介于全相联Cache和直接映像Cache之间的一种结构。这种类型的Cache使用了几组直接映像的块。对于某一个给定的索引号,可以允许有几个块位置。因而可以增加命中率和系统效率。
Cache与DRAM存取的一致性
在CPU与主存之间增加了Cache之后,便存在数据在CPU和Cache及主存之间如何存取的问题。读写各有2种方式。
贯穿读出式(Look Through)
该方式将Cache隔在CPU与主存之间,CPU对主存的所有数据请求都首先送到Cache,由Cache自行在自身查找。如果命中。 则切断CPU对主存的请求,并将数据送出;不命中。则将数据请求传给主存。
该方法的优点是降低了CPU对主存的请求次数,缺点是延迟了CPU对主存的访问时间。
旁路读出式(Look Aside)
在这种方式中,CPU发出数据请求时,并不是单通道地穿过Cache。而是向Cache和主存同时发出请求。由于Cache速度更快,如果命中,则Cache在将数据回送给CPU的同时,还来得及中断CPU对主存的请求;不命中。则Cache不做任何动作。由CPU直接访问主存。它的优点是没有时间延迟,缺点是每次CPU对主存的访问都存在,这样。就占用了一部分总线时间。
写穿式(Write Through)
任一从CPU发出的写信号送到Cache的同时,也写入主存,以保证主存的数据能同步地更新。它的优点是操作简单,但由于主存的慢速,降低了系统的写速度并占用了总线的时间。
回写式(Copy Back)
为了克服贯穿式中每次数据写入时都要访问主存。从而导致系统写速度降低并占用总线时间的弊病,尽量减少对主存的访问次数,又有了回写式。
它是这样工作的:数据一般只写到Cache,这样有可能出现Cache中的数据得到更新而主存中的数据不变(数据陈旧)的情况。但此时可在Cache 中设一标志地址及数据陈旧的信息。只有当Cache中的数据被再次更改时。才将原更新的数据写入主存相应的单元中,然后再接受再次更新的数据。这样保证了Cache和主存中的数据不致产生冲突。
Cache与DMA的一致性问题
在进行DMA 操作时,如果没有对Cache 进行适当的操作,将可能产生以下两种错误:
1.DMA 从外设读取数据到供处理器使用。DMA 将外部数据直接传到内存中,但cache 中仍然保留的是旧数据,这样处理器在访问数据时直接访问缓存将得到错误的数据。
2.DMA 向外设写入由处理器提供的数据。处理器在处理数据时数据会先存放到cache 中,此时cache 中的数据有可能还没来得及写回到内存中的数据。如果这时DMA 直接从内存中取出数据传送到外设,外设将可能得到错误的数据。
为了正确进行DMA 传输,必须进行必要的cache 操作。 cache 操作主要分为 invalidate (作废) 和writeback (写回) ,有时也将两着放在一起使用。
一致性DMA映射和流式DMA映射
DMA如果使用cache,那么一定要考虑cache的一致性。解决DMA导致的一致性的方法最简单的就是禁止DMA目标地址范围内的cache功能。但是这样就会牺牲性能。
因此在DMA是否使用cache的问题上,可以根据DMA缓冲区期望保留的的时间长短来决策。DAM的映射就分为:一致性DMA映射和流式DMA映射。
一致性DMA映射申请的缓存区能够使用cache,并且保持cache一致性。一致性映射具有很长的生命周期,在这段时间内占用的映射寄存器,即使不使用也不会释放。生命周期为该驱动的生命周期。
流式DMA映射实现比较复杂。只知道种方式的生命周期比较短,而且禁用cache。一些硬件对流式映射有优化。建立流式DMA映射,需要告诉内核数据的流动方向。
1. DMA 从外设读取数据到供处理器使用时,可先进性invalidate 操作。这样将迫使处理器在读取cache中的数据时,先从内存中读取数据到缓存,保证缓存和内存中数据的一致性。
2.DMA 向外设写入由处理器提供的数据时,可先进性writeback 操作。这样可以DMA传输数据之前先将缓存中的数据写回到内存中。
如果不清楚DMA 操作的方向,也可先同时进行invalidate 和writeback 操作。操作的结果等同于invalidate 和 writeback 操作效果的和。

ARM Cortex-A53 Cache与内存的映射关系以及Cache的一致性分析
ARM Cortex-A53 Cache与内存的映射关系以及Cache的一致性分析
题记:如果文章有理解不对的地方,欢迎大家批评指正,谢谢大家。
摘要:本文以Cortex-A53为例,首先分析Cache与内存隐射的直接、全相连、组相连等三种映像方式,以及Cache的命中流程。ARM CPU 扩展Trustzone功能后,内存也具有安全属性,相应的Cache也做了扩展,标志命中的内存地址是安全还是非安全的。针对CPU访问内存数据的Cache一致性问题,主要结合现行的Android标配TEE系统,介绍双系统的Cache一致性。
关键字:Cache命中;Cache一致性; TrustZone;TEE系统






Cache 工作原理、Cache 一致性,你想知道的都在这里
可以随便到网上查一查,各大互联网公司笔试面试特别喜欢考一道算法题,即 LRU缓存机制,又顺手查了一下LRU缓存机制最近有哪些企业喜欢考察,超级大热门!

今天给大家分享一篇关于 Cache 的硬核的技术文,基本上关于Cache的所有知识点都可以在这篇文章里看到。
关于 Cache 这方面内容图比较多,不想自己画了,所以图都来自《Computer Architecture : A Quantitative Approach》。
这是一本体系架构方面的神书,推荐大家看一下。
本文主要内容如下,基本涉及了Cache的概念,工作原理,以及保持一致性的入门内容。
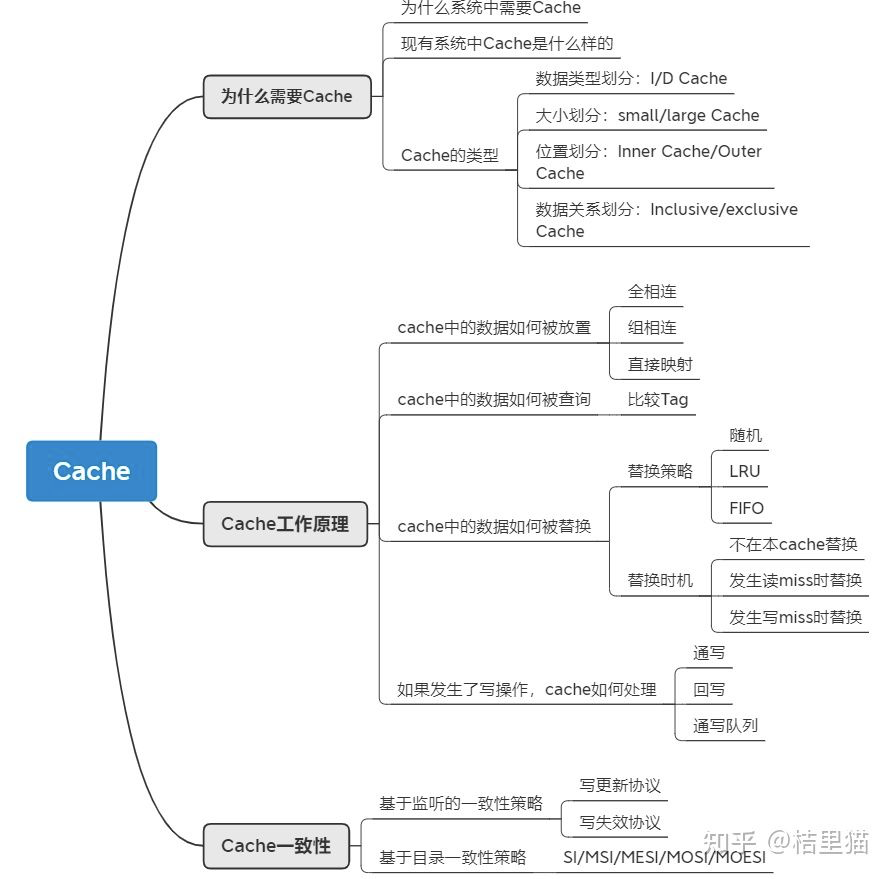
1、为什么需要 Cache
1.1 为什么需要 Cache
我们首先从一张图来开始讲为什么需要 Cache.
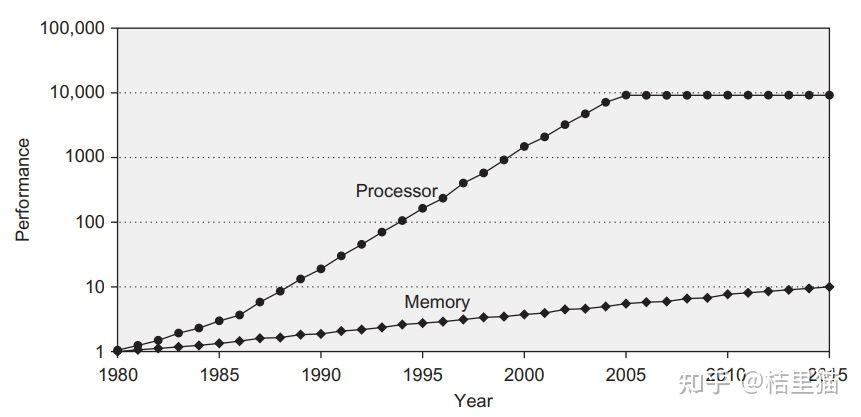
上图是 CPU 性能和 Memory 存储器访问性能的发展。
我们可以看到,随着工艺和设计的演进,CPU 计算性能其实发生了翻天覆地的变化,但是DRAM存储性能的发展没有那么快。
所以造成了一个问题,存储限制了计算的发展。
容量与速度不可兼得。
如何解决这个问题呢?可以从计算访问数据的规律入手。
我们随便贴段代码:
for (j = 0; j < 100; j = j + 1)
for( i = 0; i < 5000; i = i + 1)
x[i][j] = 2 * x[i][j];
可以看到,由于大量循环的存在,我们访问的数据其实在内存中的位置是相近的。
换句专业点的话说,我们访问的数据有局部性。
我们只需要将这些数据放入一个小而快的存储中,这样就可以快速访问相关数据了。
总结起来,Cache是为了给CPU提供高速存储访问,利用数据局部性而设计的小存储单元。
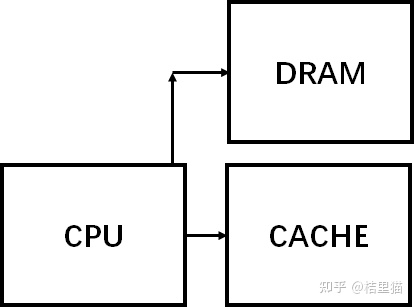
1.2 实际系统中的 Cache
我们展示一下实际系统中的 Cache 。
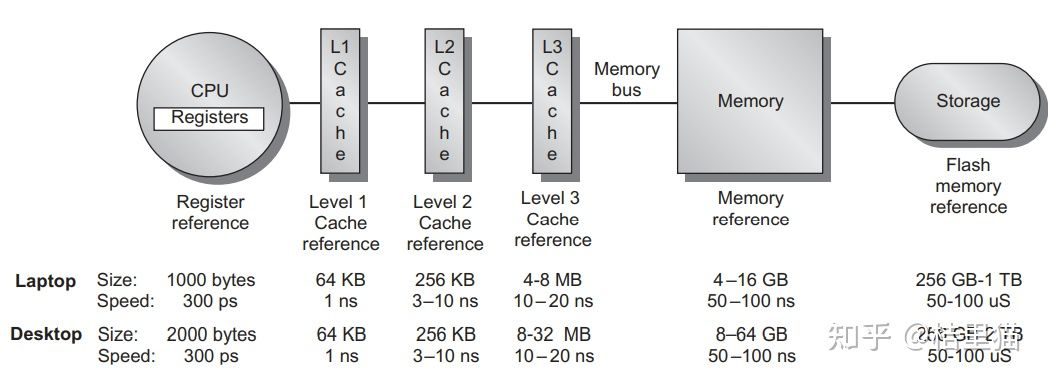
如上图所示,整个系统的存储架构包括了 CPU 的寄存器,L1/L2/L3 CACHE,DRAM 和硬盘。
数据访问时先找寄存器,寄存器里没有找 L1 Cache, L1 Cache 里没有找 L2 Cache 依次类推,最后找到硬盘中。
同时,我们可以看到,速度与存储容量的折衷关系。容量越小,访问速度越快!
其中,一个概念需要搞清楚。
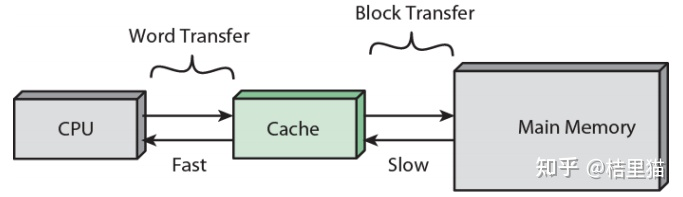
CPU 和 Cache 是 word 传输的,而 Cache 到主存是以块传输的,一块大约 64Byte 。
现有 SOC 中的 Cache 一般组成如下。
1.3 Cache 的分类
Cache按照不同标准分类可以分为若干类。
-
按照数据类型划分:I-Cache与D-Cache。其中I-Cache负责放置指令,D-Cache负责方式数据。两者最大的不同是D-Cache里的数据可以写回,I-Cache是只读的。 -
按照大小划分:分为small Cache和large Cache。没路组(后文组相连介绍)<4KB叫small Cache, 多用于L1 Cache, 大于4KB叫large Cache。多用于L2及其他Cache. -
按照位置划分:Inner Cache和Outer Cache。一般独属于CPU微架构的叫Inner Cache, 例如上图的L1 L2 CACHE。不属于CPU微架构的叫outer Cache. -
按照数据关系划分:Inclusive/exclusive Cache: 下级Cache包含上级的数据叫inclusive Cache。不包含叫exclusive Cache。举个例子,L3 Cache里有L2 Cache的数据,则L2 Cache叫exclusive Cache。
2、Cache的工作原理
要讲清楚 Cache 的工作原理,需要回答 4 个问题:
-
数据如何放置 -
数据如何查询 -
数据如何被替换 -
如果发生了写操作,Cache如何处理
2.1 数据如何放置
这个问题也好解决。我们举个简单的栗子来说明问题。
假设我们主存中有 32 个块,而我们的 Cache 一共有 8 个 Cache 行( 一个 Cache 行放一行数据)。
假设我们要把主存中的块 12 放到 Cache 里。
那么应该放到 Cache 里什么位置呢?
三种方法:
-
全相连(Fully associative)。可以放在Cache的任何位置。 -
直接映射(Direct mapped)。只允许放在Cache的某一行。比如12 mod 8 -
组相连(set associative)。可以放在Cache的某几行。例如2路组相连,一共有4组,所以可以放在0,1位置中的一个。
可以看到,全相连和直接映射是Cache组相连的两种极端情况。
不同的放置方式主要影响有两点:
1、组相连组数越大,比较电路就越大,但Cache利用率更高,Cache miss发生的概率小。2、组相连数目变小,Cache经常发生替换,但是比较电路比较小。
这也好理解,内存中的块在Cache中可放置的位置多,自然找起来就麻烦。
2.2 如何在Cache中找数据
其实找数据就是一个比对过程,如下图所示。

我们地址都以 Byte 为单位的。
但主存于Cache之间的数据交换单位都是块(block,现代Cache一般一个block大约64Byte)。所以地址对最后几位是block offset。
由于我们采用了组相连,则还有几个比特代表的是存储到了哪个组。
组内放着若干数据,我们需要比较Tag, 如果组内有Tag出现,则说明我们访问的数据在缓存中,可以开心的使用了。
比如举个 2 路组相连的例子,如下图所示。
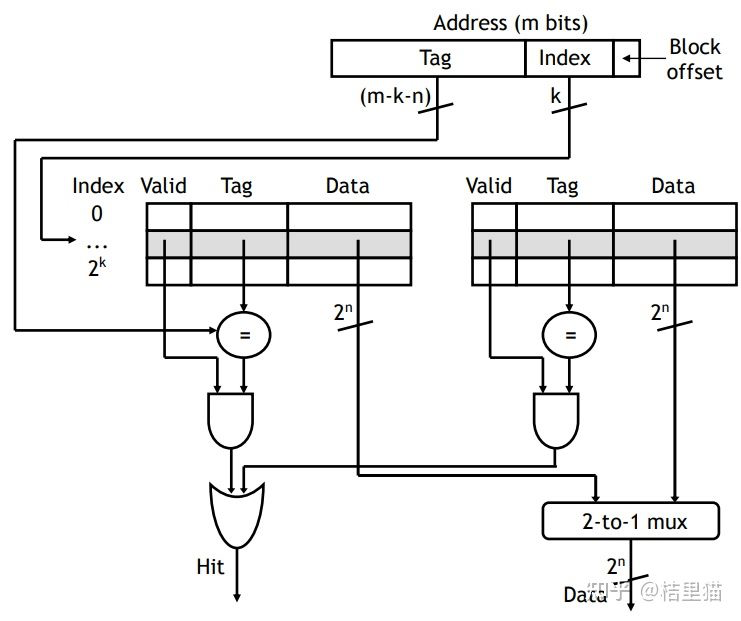
T表示Tag。直接比较Tag,就能得知是不是命中了。如果命中了,则根据index(组号)将对应的块取出来即可。
如上图所示。用index选出位于组相连的哪个组。然后并行的比较Tag, 判断最后是不是在Cache中。上图是2路组相连,也就是说两组并行比较。
那如果不在缓存中呢?这就涉及到另一个问题。
不在缓存中如何替换 Cache ?
2.3 如何替换Cache中的数据
Cache中的数据如何被替换的?这个就比较简单直接。
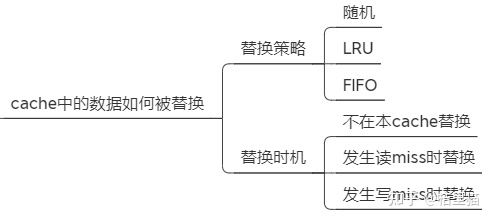
-
随机替换。如果发生Cache miss里随机替换掉一块。 -
Least recently used. LRU。最近使用的块最后替换。 -
First in, first out (FIFO), 先进先出。
实际上第一个不怎么使用,LRU 和 FIFO 根据实际情况选择即可。
Cache 在什么时候数据会被替换内?也有几种策略。
-
不在本 Cache 替换。如果Cache miss了,直接转发访问地址到主存,取到的数据不会写到Cache. -
在读MISS时替换。如果读的时候Cache里没有该数据,则从主存读取该数据后写入Cache。 -
在写MISS时替换。如果写的时候Cache里没有该数据,则将本数据调入Cache再写。
2.4 如果发生了写操作怎么办
Cache毕竟是个临时缓存。
如果发生了写操作,会造成Cache和主存中的数据不一致。如何保证写数据操作正确呢?
也有三种策略。
-
通写:直接把数据写回Cache的同时写回主存。极其影响写速度。
-
回写:先把数据写回Cache, 然后当Cache的数据被替换时再写回主存。

-
通写队列:通写与回写的结合。先写回一个队列,然后慢慢往主存储写。如果多次写同一个数据,直接写这个队列。避免频繁写主存。
3、Cache一致性
Cache 一致性是 Cache 中遇到的比较坑的一个问题。
什么原因需要 Cache 处理一致性呢?
主要是多核系统中,假如core 0读了主存储的数据,写了数据。core 1也读了主从的数据。这个时候core 1并不知道数据已经被改动了,也就是说,core 1 Cache中的数据过时了,会产生错误。
Cache一致性的保证就是让多核访问不出错。

Cache一致性主要有两种策略。
策略一:基于监听的一致性策略
这种策略是所有Cache均监听各Cache的写操作,如果一个Cache中的数据被写了,有两种处理办法。
写更新协议:某个Cache发生写了,就索性把所有Cache都给更新了。
写失效协议:某个Cache发生写了,就把其他Cache中的该数据块置为无效。
策略 1 由于监听起来成本比较大,所以只应用于极简单的系统中。
策略二:基于目录的一致性策略
这种策略是在主存处维护一张表。记录各数据块都被写到了哪些Cache, 从而更新相应的状态。一般来讲这种策略采用的比较多。又分为下面几个常用的策略。
-
SI: 对于一个数据块来讲,有share和invalid两种状态。如果是share状态,直接通知其他Cache, 将对应的块置为无效。 -
MSI:对于一个数据块来讲,有share和invalid,modified三种状态。其中modified状态表表示该数据只属于这个Cache, 被修改过了。当这个数据被逐出Cache时更新主存。这么做的好处是避免了大量的主从写入。同时,如果是invalid时写该数据,就要保证其他所有Cache里该数据的标志位不为M,负责要先写回主存储。 -
MESI:对于一个数据来讲,有4个状态。modified, invalid, shared, exclusive。其中exclusive状态用于标识该数据与其他Cache不依赖。要写的时候直接将该Cache状态改成M即可。
我们着重讲讲 MESI。图中黑线:CPU的访问。红线:总线的访问,其他Cache的访问。
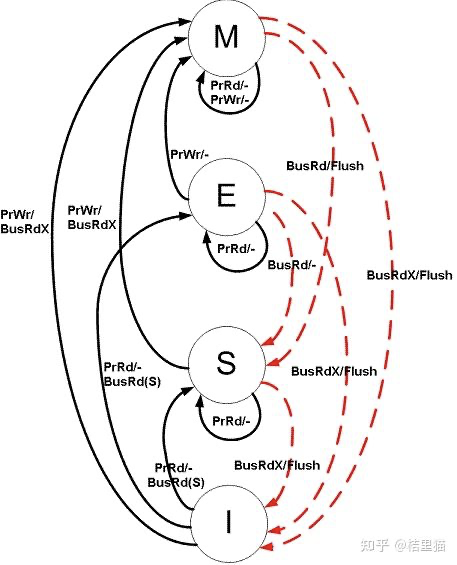
当前状态时I状态时,如果发生处理器读操作 prrd。
-
如果其他Cache里有这份数据,如果其他Cache里是M态,先 把M态写回主存再读。否则直接读。最终状态变为S。 -
其他Cache里没这个数据,直接变到E状态。
当前状态为S态。
-
如果发生了处理器读操作,仍然在S态。 -
如果发生了处理器写操作,则跳转到M状态。 -
如果其他Cache发生了写操作,跳到I态。
当前状态E态
-
发生了处理器读操作还是E。 -
发生了处理器写操作变成M。 -
如果其他Cache发生了读操作,变到S状态。
当前状态M态
-
发生了读操作依旧是M态。 -
发生了写操作依旧是M态。 -
如果其他Cache发生了读操作,则将数据写回主存储,变换到S态。
4、总结
Cache 在计算机体系架构中有非常重要的地位,本文讲了 Cache中最主要的内容,具体细节可以再根据某个点深入研究。
近期热文
Seata RPC 模块的重构之路
我参与 Seata 开源项目的一些感悟
分布式事务中间件 Seata 的设计原理
Kubernetes Operator 服务化实践
Kafka 顺序消费线程模型的实践与优化
图解:Kafka 水印备份机制
记一次 Kafka 集群线上扩容
我对支付平台架构设计的一些思考
聊聊 Tomcat 的架构设计
基于Jenkins Pipeline自动化部署
从源码的角度解析线程池运行原理
本文分享自微信公众号 - 后端进阶(objcoding)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
")
Cache一致性与2种基本写策略(1)
(1) 一致性问题的产生——信息不对称导致的问题
现实生活中常常会出现因为沟通不畅而导致的扯皮,一方改了某些东西,又没有及时通知到另一方,导致两方掌握的信息不一致,这就是一致性问题。
多核处理器也有这样的问题,在下面这个简单的多核处理器示例中,内存中有一个数据x,它的值为3,它被缓存到Core 0和Core 1中,不过Core 0将x改为5,如果Core 1不知道x已经被修改了,还在使用旧的值,就会导致程序出错,这就是Cache的不一致。
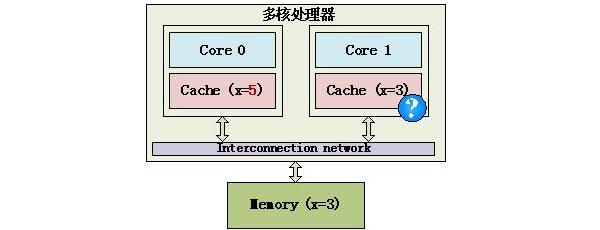
Cache的不一致示例
(2) Cache一致性的底层操纵
为了保证Cache的一致性,处理器提供了2个保证Cache一致性的底层操作:Write invalidate和Write update。
Write invalidate(置无效):当一个内核修改了一份数据,其他内核上如果有这份数据的拷贝,就置成无效(invalid)。
下面这个例子中,3个Core都使用了内存中的变量x,Core 0将它修改为5,其他Core就将自己对应的Cache line置成无效(invalid)。

Write invalidate示例
Write update(写更新):当一个内核修改了一份数据,其他地方如果有这份数据的拷贝,就都更新到最新值。Write update示例如下:

Write update示例
Write invalidate和Write update比较:Write invalidate是一种很简单的方式,不需要更新数据,如果Core 1和Core 2以后不再使用变量x,这时候采用Write invalidate就非常有效。不过由于一个valid标志对应一个Cache line,将valid标志置成invalid后,这个Cache line中其他的本来有效的数据也不能被使用了。Write update策略会产生大量的数据更新操作,不过只用更新修改的数据,如果Core 1和Core 2会使用变量x,那么Write update就比较有效。由于Write invalidate简单,大多数处理器都使用Write invalidate策略。
")
Cache一致性协议与MESI(2)
Write invalidate提供了实现Cache一致性的简单思想,处理器上会有一套完整的协议,来保证Cache一致性。比较经典的Cache一致性协议当属MESI协议,奔腾处理器有使用它,很多其他的处理器都是使用它的变种。
单核处理器Cache中每个Cache line有2个标志:dirty和valid标志,它们很好的描述了Cache和Memory(内存)之间的数据关系(数据是否有效,数据是否被修改),而在多核处理器中,多个核会共享一些数据,MESI协议就包含了描述共享的状态。
在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
| 状态 | 描述 |
| M(Modified) | 这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 |
| E(Exclusive) | 这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中。 |
| S(Shared) | 这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中。 |
| I(Invalid) | 这行数据无效 |
MESI状态
M(Modified)和E(Exclusive)状态的Cache line,数据是独有的,不同点在于M状态的数据是dirty的(和内存的不一致),E状态的数据是clean的(和内存的一致)。
S(Shared)状态的Cache line,数据和其他的Cache共享。只有clean的数据才能被多个Cache共享。
I(Invalid)表示这个Cache line无效。
E状态示例如下:

E状态
只有Core 0访问变量x,它的Cache line状态为E(Exclusive)。
S状态示例如下:

S状态
3个Core都访问变量x,它们对应的Cache line为S(Shared)状态。
M状态和I状态示例如下:

M状态和I状态
Core 0修改了x的值之后,这个Cache line变成了M(Modified)状态,其他Core对应的Cache line变成了I(Invalid)状态。
在MESI协议中,每个Cache的Cache控制器不仅知道自己的读写操作,而且也监听(snoop)其它Cache的读写操作。每个Cache line所处的状态根据本核和其它核的读写操作在4个状态间进行迁移。
MESI协议状态迁移图如下:

MESI协议状态迁移图
在上图中,Local Read表示本内核读本Cache中的值,Local Write表示本内核写本Cache中的值,Remote Read表示其它内核读其它Cache中的值,Remote Write表示其它内核写其它Cache中的值,箭头表示本Cache line状态的迁移,环形箭头表示状态不变。
MESI状态之间的迁移过程如下:
| 当前状态 | 事件 | 行为 | 下一个状态 |
| I(Invalid) | Local Read | 从Memory中取数据, 状态变成E |
E |
| Local Write | 从Memory中取数据,在Cache中修改, 状态变成M |
M | |
| Remote Read | 既然是Invalid,别的核的操作与它无关 | I | |
| Remote Write | 既然是Invalid,别的核的操作与它无关 | I | |
| E(Exclusive) | Local Read | 从Cache中取数据, 状态不变 |
E |
| Local Write | 修改Cache中的数据, 状态变成M |
M | |
| Remote Read | 数据和其他核共用,状态变成了S | S | |
| Remote Write | 数据被修改,本Cache line不能再使用,状态变成I | I | |
| S(Shared) | Local Read | 从Cache中取数据, 状态不变 |
S |
| Local Write | 修改Cache中的数据, 状态变成M, 其他核共享的Cache line置无效 |
M | |
| Remote Read | 状态不变 | S | |
| Remote Write | 数据被修改,本Cache line不能再使用,状态变成I | I | |
| M(Modified) | Local Read | 从Cache中取数据, 状态不变 |
M |
| Local Write | 修改Cache中的数据,状态不变 | M | |
| Remote Read | 这行数据被写到内存中,使其它核能使用到最新的数据, 状态变成S |
S | |
| Remote Write | 这行数据被写到内存中,使其它核能使用到最新的数据,由于其它核会修改这行数据, 状态变成I |
I |
MESI状态迁移
AMD的Opteron处理器使用从MESI中演化出的MOSEI协议,O(Owned)是MESI中S和M的一个合体,表示本Cache line被修改,和内存中的数据不一致,不过其它的核可以有这份数据的拷贝,状态为S。
Intel的core i7处理器使用从MESI中演化出的MSEIF协议,F(Forward)从Share中演化而来,一个Cache line如果是Forward状态,它可以把数据直接传给其它内核的Cache,而Share则不能。
今天关于DMA和cache一致性问题和dma cache一致性的分享就到这里,希望大家有所收获,若想了解更多关于ARM Cortex-A53 Cache与内存的映射关系以及Cache的一致性分析、Cache 工作原理、Cache 一致性,你想知道的都在这里、Cache一致性与2种基本写策略(1)、Cache一致性协议与MESI(2)等相关知识,可以在本站进行查询。
本文标签:




