本文的目的是介绍在ScikitLearn中运行SelectKBest之后获取功能名称的最简单方法的详细情况,特别关注scikitlearnknn的相关信息。我们将通过专业的研究、有关数据的分析等多种方
本文的目的是介绍在Scikit Learn中运行SelectKBest之后获取功能名称的最简单方法的详细情况,特别关注scikit learn knn的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解在Scikit Learn中运行SelectKBest之后获取功能名称的最简单方法的机会,同时也不会遗漏关于node.js – 通过Jenkins CI在Docker容器中运行Selenium测试的最简单方法、perl – 获取CPAN中可用包名称的最全面列表的最简单方法?、python – 在scikit-learn中保存新数据的特征向量、scikit-learn 的 5 大新功能 - 知乎的知识。
本文目录一览:- 在Scikit Learn中运行SelectKBest之后获取功能名称的最简单方法(scikit learn knn)
- node.js – 通过Jenkins CI在Docker容器中运行Selenium测试的最简单方法
- perl – 获取CPAN中可用包名称的最全面列表的最简单方法?
- python – 在scikit-learn中保存新数据的特征向量
- scikit-learn 的 5 大新功能 - 知乎
")
在Scikit Learn中运行SelectKBest之后获取功能名称的最简单方法(scikit learn knn)
我想进行监督学习。
到目前为止,我知道对所有功能都进行监督学习。
但是,我也想用K最佳功能进行实验。
我阅读了文档,发现在Scikit中学习有SelectKBest方法。
不幸的是,我不确定找到这些最佳功能后如何创建新的数据框:
假设我要进行5种最佳功能的实验:
from sklearn.feature_selection import SelectKBest, f_classifselect_k_best_classifier = SelectKBest(score_func=f_classif, k=5).fit_transform(features_dataframe, targeted_class)现在,如果我要添加下一行:
dataframe = pd.DataFrame(select_k_best_classifier)我将收到一个没有功能名称的新数据框(仅索引从0到4)。
我应该将其替换为:
dataframe = pd.DataFrame(fit_transofrmed_features, columns=features_names)我的问题是如何创建features_names列表?
我知道我应该使用:select_k_best_classifier.get_support()
返回布尔值数组。
数组中的true值表示右列中的索引。
我应该如何将此布尔数组与可以通过该方法获得的所有要素名称的数组一起使用:
feature_names = list(features_dataframe.columns.values)答案1
小编典典您可以执行以下操作:
mask = select_k_best_classifier.get_support() #list of booleansnew_features = [] # The list of your K best featuresfor bool, feature in zip(mask, feature_names): if bool: new_features.append(feature)然后更改功能的名称:
dataframe = pd.DataFrame(fit_transofrmed_features, columns=new_features)
node.js – 通过Jenkins CI在Docker容器中运行Selenium测试的最简单方法
这就是我想要做的更详细的事情.
>开始对Jenkins CI工作进行测试
>在同一台机器上加载Docker镜像,相关的Docker容器将启动.这个容器基于Unix OS.此外,将执行Docker容器中的某些配置.
>测试将通过xvfb以无头模式执行(从本地或远程),报告将保存在Jenkins机器上.
通过GitLab CI我已经通过.gitlab-ci.yml配置文件实现了它并且它运行得非常好:
image: "my-docker-image"
stages:
- "chrome-tests"
before_script:
- "apt-get update"
- "apt-get install -y wget bzip2"
- "npm install"
cache:
paths:
- node_modules/
run-tests-on-chrome:
stage: "chrome-tests"
script:
- "whereis xvfb-run"
- "xvfb-run --server-args='-screen 0 1600x1200x24' npm run test-chrome"
但我想与Jenkins CI实现相同的程序.什么是最简单的方法,并在Jenkins调用的Docker镜像中运行我的自动化测试?我应该写一个Dockerfile或者不是或者或者?
解决方法
要使用Docker容器内的无头浏览器运行Selenium测试并使用docker-compose将其链接到您的应用程序,您只需使用预定义的独立服务器即可.
https://github.com/SeleniumHQ/docker-selenium
我目前正在使用Chrome Standalone图片.
这是您的docker-compose应该是什么样子:
version: '3'
services:
your-app:
build:
context: .
dockerfile: Dockerfile
your_selenium_application:
build:
context: .
dockerfile: Dockerfile.selenium.test
depends_on:
- chrome-server
- your-app
chrome-server:
image: selenium/standalone-chrome:3.4.0-einsteinium
当运行docker-compose时,它将启动您的应用程序,将与您的应用程序交互的selenium环境,以及将为您提供无头浏览器的独立服务器.因为它们是链接的,所以在你的selenium代码中,你可以通过你的app:80向主机发出测试请求.您的无头浏览器将是chrome-server:4444 / wd / hub,这是默认地址.
这可以在Jenkins内部完成,只需在Jenkins Job中的Execute Shell中使用一个命令. docker-compose还允许您在本地计算机上轻松运行测试,结果应该相同.

perl – 获取CPAN中可用包名称的最全面列表的最简单方法?
到目前为止,由于软件包已经是一个私有项目,我并没有过多担心软件包的名称,但是现在我想提交给CPAN,但是,我希望软件包的名称能够很好地适应生态包名称已在CPAN中.
为了找到适合我的包的“CPAN名称”,我将不得不检查所有这些包名的全面列表1.
What is the simplest way to get this comprehensive listing of names of packages in CPAN?
ObPedantry
(如果上面的问题对你来说已经足够清楚了,你可以放心地忽略下面的内容.)
我不认为我可以通过“包名称”在技术上正确定义我的意思,所以让我至少给出一个“操作定义”.
例如,如果是单线
$perl -MFoo::Bar::Baz -c -e 1
失败并以错误开头
Can't locate Foo/Bar/Baz.pm in @INC ...
…,但在从CPAN安装一些发行版之后,相同的oneliner成功了
-e Syntax OK
…然后我会说“Foo :: Bar :: Baz是CPAN中的包名”.
(我们可以分开包装/模块的区别,并考虑区分重要的情况,但请不要.)
此外,如果在检查列表之后这个问题询问我发现,一方面,CPAN中实际上有许多以前缀Foo :: Bar ::开头的着名包名,而另一方面,没有(或者可以忽略不计)以前缀Fubar ::开头,这对我来说是一个足够的理由让我将Fubar :: Frobozz包的名称改为Foo :: Bar :: Frobozz,然后再将其提交给CPAN.
1当然,在检查这样的列表之后,我可能会发现我的软件包没有添加足够的新功能,相对于CPAN中已有的功能,以保证我的软件包最终提交给CPAN.
解决方法
任何CPAN镜像都有新的副本,例如:
http://www.cpan.org/modules/02packages.details.txt.gz

python – 在scikit-learn中保存新数据的特征向量
[{
'contains(the)': 'True','contains(cat)': 'True','contains(is)': 'True','contains(hungry)': 'True'
}...
]
我训练的列表中有相同的句子,有数千种动物变种.当我对列表进行矢量化时,它会考虑所有提到的不同动物,并在每个动物的矢量中创建一个索引(”’,’是’和’饥饿’不会改变).现在,当我尝试在新句子上使用模型时,我想预测一个项目:
[{
'contains(the)': 'True','contains(emu)': 'True','contains(hungry)': 'True'
}]
没有原始训练集,当我使用DictVectorizer时,它会生成:(1,1,1).这是用于训练我的模型的原始向量之外的几千个索引,因此SVM模型将无法使用它.或者即使向量的长度是正确的,因为它是在大量句子上训练的,因此这些特征可能与原始值不对应.如何获得新数据以符合训练向量的维度?永远不会有比训练集更多的功能,但并不是所有功能都保证存在于新数据中.
有没有办法使用pickle来保存特征向量?或者我考虑过的一种方法是生成一个字典,其中包含值为’False’的所有可能特征.这会强制新数据进入正确的矢量大小,并仅计算新数据中存在的项目.
我觉得我可能没有充分描述这个问题,所以如果有些事情不清楚,我会尝试更好地解释它.先感谢您!
编辑:感谢larsman的回答,解决方案非常简单:
from sklearn.pipeline import Pipeline
from sklearn import svm
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False)
svm_clf = svm.SVC(kernel='linear')
vec_clf = Pipeline([('vectorizer',vec),('svm',svm_clf)])
vec_clf.fit(X_Train,Y_Train)
joblib.dump(vec_clf,'vectorizer_and_SVM.pkl')
管道和支持向量机被训练成数据.现在,所有未来的模型都可以取消管道,并在SVM中内置了一个特征向量器.
解决方法
How do I get new data to conform to the dimensions of the training vectors?
通过使用transform方法而不是fit_transform.后者从您提供的数据集中学习新的词汇表.
Is there a way to use pickle to save the feature vector?
挑选训练有素的矢量化器.更好的是,制作矢量化器的管道和SVM并腌制它.您可以使用sklearn.externals.joblib.dump进行有效的酸洗.
(旁白:如果你传递布尔值True而不是字符串“True”,矢量化器会更快.)

scikit-learn 的 5 大新功能 - 知乎

CDA 数据分析师 出品
Python 的主要功能机器学习库的最新版本包括许多新功能和错误修复。你可以从 Scikit-learn 官方 0.22 发行要点中找到有关这些更改的完整说明。
通过 pip 完成安装更新:
pip install --upgrade scikit-learn
或 conda:
conda install scikit-learn
最新的 Scikit-learn 中有 5 个新功能值得你注意。
1. 新的绘图 API
新的绘图 API 可用,无需重新计算即可正常工作。支持的图包括一些相关图,混淆矩阵和 ROC 曲线。下面是 Scikit-learn 用户指南中的示例,对 API 进行了演示:
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import plot_roc_curve
from sklearn.datasets import load_wine
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
svc = SVC(random_state=42)
svc.fit(X_train, y_train)
svc_disp = plot_roc_curve(svc, X_test, y_test)
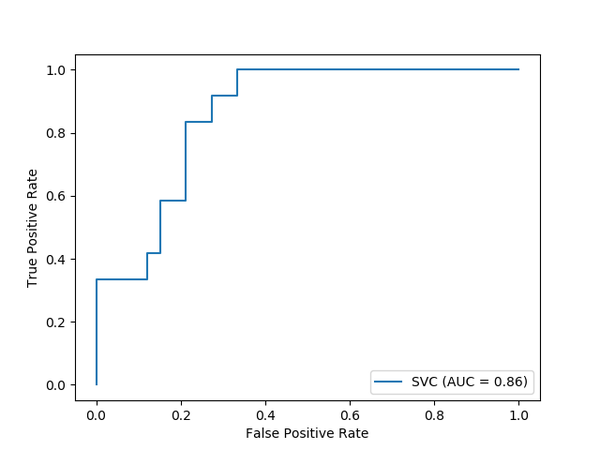
请注意,绘制是通过最后一行代码完成的。
2. 堆叠概括
Scikit-learn 已经集成了用于减少估计量偏差的整体学习技术。StackingClassifier 和 StackingRegressor 是启用估算器堆叠的模块,并使用 final_estimator 这些堆叠的估算器预测作为其输入。请参阅用户指南中的示例,使用以下定义为的回归估计量 estimators 和梯度增强回归最终估计量:
from sklearn.linear_model import RidgeCV, LassoCV
from sklearn.svm import SVR
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import StackingRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
estimators = [(''ridge'', RidgeCV()),
(''lasso'', LassoCV(random_state=42)),
(''svr'', SVR(C=1, gamma=1e-6))]
reg = StackingRegressor(
estimators=estimators,
final_estimator=GradientBoostingRegressor(random_state=42))
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
reg.fit(X_train, y_train)
StackingRegressor(...)

3. 任何估计器特征的重要性
现在,任何适合的 Scikit-learn 估计器都可以使用基于置换的重要性特征。从用户指南中描述如何计算功能的排列重要性:
特征排列重要性计算方式如下:首先,在 X 定义的数据集上评估通过评分定义的基线度量。接着,对验证集中的要素列进行置换,并再次评估度量。排列重要性定义为基线度量和来自特征列度量之间的差异。
发行说明中的完整示例:
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
X, y = make_classification(random_state=0, n_features=5, n_informative=3)
rf = RandomForestClassifier(random_state=0).fit(X, y)
result = permutation_importance(rf, X, y, n_repeats=10, random_state=0, n_jobs=-1)
fig, ax = plt.subplots()
sorted_idx = result.importances_mean.argsort()
ax.boxplot(result.importances[sorted_idx].T, vert=False, labels=range(X.shape[1]))
ax.set_title("Permutation Importance of each feature")
ax.set_ylabel("Features")
fig.tight_layout()
plt.show()
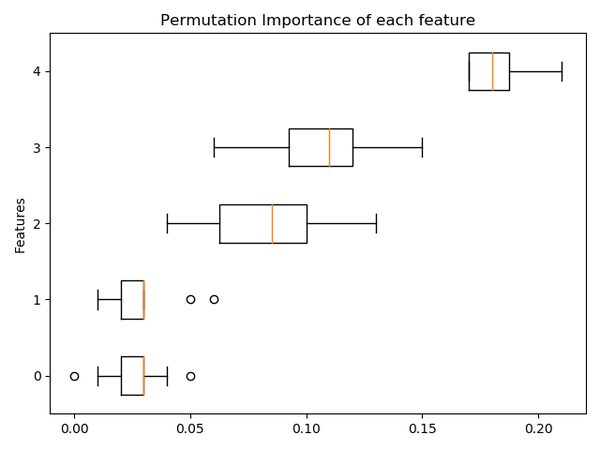
4. 梯度提升缺失价值支持
梯度提升分类器和回归器现在都已经具备了处理缺失值的能力,从而消除了手动插补的需要。以下是遗漏的方式:
在训练过程中,树木种植者会根据潜在的收益,在每个分割点上了解缺失值的样本应归子级左还是右子级。进行预测时,因此将具有缺失值的样本分配给左或右的子级。如果在训练过程中没有遇到给定特征的缺失值,则将具有缺失值的样本映射到样本最多的那一方。
以下示例演示:
from sklearn.experimental import enable_hist_gradient_boosting
# noqa
from sklearn.ensemble import HistGradientBoostingClassifier
import numpy as np
X = np.array([0, 1, 2, np.nan]).reshape(-1, 1)
y = [0, 0, 1, 1]
gbdt = HistGradientBoostingClassifier(min_samples_leaf=1).fit(X, y)
print(gbdt.predict(X))
[0 0 1 1]
5. 基于 KNN 的缺失值估算
现在,梯度增强本身就支持缺失值插补,但可以使用 K 近邻插值器在任何数据集上执行显式插补。只要在训练集中,n 个最近邻居的平均值就推算出每个缺失值,只要两个样本都不缺失的特征就近了。欧式距离是使用的默认距离度量。
一个例子:
import numpy as np
from sklearn.impute import KNNImputer
X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)
print(imputer.fit_transform(X))
[[1,2,4]
[3,4,3]
[5.5 ,6,5]
[8,8,7]]
最新版本的 Scikit-learn 中有更多功能,这里就不做过多介绍了。你可以去官网获取更多的信息!

获取更多优质内容,可前往:疫情当下,宅家也能好好提升自己,为未来蓄能 —— 蓄势待发!
关于在Scikit Learn中运行SelectKBest之后获取功能名称的最简单方法和scikit learn knn的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于node.js – 通过Jenkins CI在Docker容器中运行Selenium测试的最简单方法、perl – 获取CPAN中可用包名称的最全面列表的最简单方法?、python – 在scikit-learn中保存新数据的特征向量、scikit-learn 的 5 大新功能 - 知乎的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

