如果您对scikit-learn中的TfidfVectorizer:ValueError:np.nan是无效的文档和namesklearnisnotdefined感兴趣,那么这篇文章一定是您不可错过的
如果您对scikit-learn中的TfidfVectorizer:ValueError:np.nan是无效的文档和name sklearn is not defined感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解scikit-learn中的TfidfVectorizer:ValueError:np.nan是无效的文档的各种细节,并对name sklearn is not defined进行深入的分析,此外还有关于2 python 文本特征提取 CountVectorizer, TfidfVectorizer、CountVectorizer().适合scikit-learn Python给出内存错误、CountVectorizer,Tf-idfVectorizer和word2vec构建词向量的区别、Keras Seq 中的 TextVectorization:ValueError:squeeze_dims[0] 不在 [-1,1] 中对于具有输入形状的“text_vectorization/Squeeze”(操作:“Squeeze”):[?]的实用技巧。
本文目录一览:- scikit-learn中的TfidfVectorizer:ValueError:np.nan是无效的文档(name sklearn is not defined)
- 2 python 文本特征提取 CountVectorizer, TfidfVectorizer
- CountVectorizer().适合scikit-learn Python给出内存错误
- CountVectorizer,Tf-idfVectorizer和word2vec构建词向量的区别
- Keras Seq 中的 TextVectorization:ValueError:squeeze_dims[0] 不在 [-1,1] 中对于具有输入形状的“text_vectorization/Squeeze”(操作:“Squeeze”):[?]
")
scikit-learn中的TfidfVectorizer:ValueError:np.nan是无效的文档(name sklearn is not defined)
我正在使用scikit-learn的TfidfVectorizer从文本数据中提取一些特征。我有一个带分数(可以为+1或-1)和审阅(文本)的CSV文件。我将这些数据放入一个DataFrame中,以便可以运行Vectorizer。
这是我的代码:
import pandas as pdimport numpy as npfrom sklearn.feature_extraction.text import TfidfVectorizerdf = pd.read_csv("train_new.csv", names = [''Score'', ''Review''], sep='','')# x = df[''Review''] == np.nan## print x.to_csv(path=''FindNaN.csv'', sep='','', na_rep = ''string'', index=True)## print df.isnull().values.any()v = TfidfVectorizer(decode_error=''replace'', encoding=''utf-8'')x = v.fit_transform(df[''Review''])这是我得到的错误的回溯:
Traceback (most recent call last): File "/home/PycharmProjects/Review/src/feature_extraction.py", line 16, in <module>x = v.fit_transform(df[''Review'']) File "/home/b/hw1/local/lib/python2.7/site- packages/sklearn/feature_extraction/text.py", line 1305, in fit_transform X = super(TfidfVectorizer, self).fit_transform(raw_documents) File "/home/b/work/local/lib/python2.7/site-packages/sklearn/feature_extraction/text.py", line 817, in fit_transformself.fixed_vocabulary_) File "/home/b/work/local/lib/python2.7/site- packages/sklearn/feature_extraction/text.py", line 752, in _count_vocab for feature in analyze(doc): File "/home/b/work/local/lib/python2.7/site-packages/sklearn/feature_extraction/text.py", line 238, in <lambda>tokenize(preprocess(self.decode(doc))), stop_words) File "/home/b/work/local/lib/python2.7/site-packages/sklearn/feature_extraction/text.py", line 118, in decode raise ValueError("np.nan is an invalid document, expected byte or " ValueError: np.nan is an invalid document, expected byte or unicode string.我检查了CSV文件和DataFrame中是否有被读取为NaN的内容,但找不到任何内容。有18000行,没有一个返回isnanTrue。
这是什么df[''Review''].head()样子:
0 This book is such a life saver. It has been s... 1 I bought this a few times for my older son and... 2 This is great for basics, but I wish the space... 3 This book is perfect! I''m a first time new mo... 4 During your postpartum stay at the hospital th... Name: Review, dtype: object答案1
小编典典您需要将dtype转换object为unicode字符串,如回溯中明确提到的那样。
x = v.fit_transform(df[''Review''].values.astype(''U'')) ## Even astype(str) would work在TFIDF Vectorizer的“文档”页面中:
fit_transform(raw_documents,y = None)
参数:raw_documents:可迭代
的iterable,它产生 str , unicode 或 file对象

2 python 文本特征提取 CountVectorizer, TfidfVectorizer
1. TF-IDF概述
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,互联网上的搜索引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
(1)TF
TF: Term Frequency, 用于衡量一个词在一个文件中的出现频率。因为每个文档的长度的差别可以很大,因而一个词在某个文档中出现的次数可能远远大于另一个文档,所以词频通常就是一个词出现的次数除以文档的总长度,相当于是做了一次归一化。
TF(t) = (词t在文档中出现的总次数) / (文档的词总数).
(2)IDF
IDF: 逆向文件频率,用于衡量一个词的重要性。计算词频TF的时候,所有的词语都被当做一样重要的,但是某些词,比如”is”, “of”, “that”很可能出现很多很多次,但是可能根本并不重要,因此我们需要减轻在多个文档中都频繁出现的词的权重。
ID(t) = log(总文档数/词t出现的文档数)
TF-IDF:上面两个乘起来,就是TF-IDF TF-IDF = TF * IDF
sklearn.feature_extraction.text.TfidfVectorizer:可以把一大堆文档转换成TF-IDF特征的矩阵。
Convert a collection of raw documents to a matrix of TF-IDF features.
Equivalent to CountVectorizer followed by TfidfTransformer.
举例:
# 初始化TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=tok,stop_words=stop_words)
labels = list()
# 特征提取
data = vectorizer.fit_transform(load_data(labels))
# 初始化LogisticRegression模型
log_reg= LogisticRegression(class_weight="balanced")
# 训练模型
log_reg.fit(data, numpy.asarray(labels))
# 根据输入预测
log_reg.predict_proba(input)2.文本特征提取:
将文本数据转化成特征向量的过程,比较常用的文本特征表示法为词袋法
词袋法: 不考虑词语出现的顺序,每个出现过的词汇单独作为一列特征 这些不重复的特征词汇集合为词表 每一个文本都可以在很长的词表上统计出一个很多列的特征向量 如果每个文本都出现的词汇,一般被标记为 停用词 不计入特征向量
3.TF-IDF的预处理
在scikit-learn中,有两种方法进行TF-IDF的预处理。
第一种方法是在用CountVectorizer类向量化之后再调用TfidfTransformer类进行预处理。
CountVectorizer:只考虑词汇在文本中出现的频率
TfidfVectorizer:除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量,能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征(1)CountVectorizer
CountVectorizer单独求词频
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
''This is the first document.'',
''This document is the second document.'',
''And this is the third one.'',
''Is this the first document?'',
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(type(X))
print(vectorizer.get_feature_names())![]()
print(X.toarray())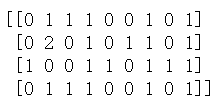
X的第一行5个1显示了corpus的第一行数据在排列中的相应位置,数字表示出现的次数。
CountVectorizer和TfidfTransformer搭配计算TF-IDF
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print (tfidf) 
tfidf结果如下:
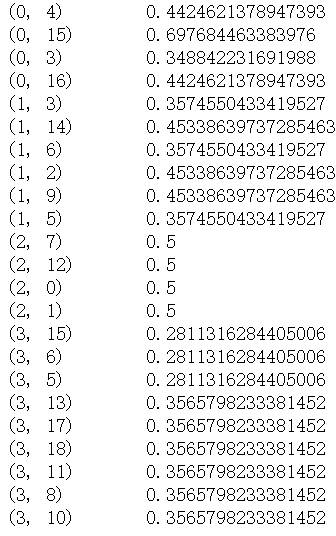
(2)TfidfVectorizer
第二种方法是直接用TfidfVectorizer完成向量化与TF-IDF预处理。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
re = tfidf2.fit_transform(corpus)
print(re) 由于第二种方法比较的简洁,因此在实际应用中推荐使用,一步到位完成向量化,TF-IDF与标准化。

4. TF-IDF小结
TF-IDF是非常常用的文本挖掘预处理基本步骤,但是如果预处理中使用了Hash Trick,则一般就无法使用TF-IDF了,因为Hash Trick后我们已经无法得到哈希后的各特征的IDF的值。使用了TF-IDF并标准化以后,我们就可以使用各个文本的词特征向量作为文本的特征,进行分类或者聚类分析。当然TF-IDF不光可以用于文本挖掘,在信息检索等很多领域都有使用。因此值得好好的理解这个方法的思想。
参考文献:
【1】使用不同的方法计算TF-IDF值
.适合scikit-learn Python给出内存错误")
CountVectorizer().适合scikit-learn Python给出内存错误
path = ''data/products.tsv'' products = pd.read_table(path,header= None,names = [''label'',''entry''])
X = products.entry
y = products.label
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=1)
# Vectorizing the Dataset
vect = CountVectorizer()
vect.fit(X_train.values.astype(''U''))
X_train_dtm = vect.transform(X_train)
X_test_dtm = vect.transform(X_test)
解决方法
正确的值实际上取决于任务,因此您应将其视为超参数并尝试对其进行调整.在NLP(英语)中,人们通常使用~10,000作为词汇量.您也可以使用HashVectorizer执行相同操作,但是您冒着哈希共谋的风险,这会导致多个单词增加相同的计数器.
path = ''data/products.tsv'' products = pd.read_table(path,random_state=1)
# Vectorizing the Dataset
vect = CountVectorizer(max_features=10000)
vect.fit(X_train.values.astype(''U''))
X_train_dtm = vect.transform(X_train)
X_test_dtm = vect.transform(X_test)

CountVectorizer,Tf-idfVectorizer和word2vec构建词向量的区别
CountVectorizer和Tf-idfVectorizer构建词向量都是通过构建字典的方式,比如在情感分析问题中,我需要把每一个句子(评论)转化为词向量,这两种方法是如何构建的呢?拿CountVectorizer来说,首先构建出一个字典,字典包含了所有样本出现的词汇,每一个词汇对应着它出现的顺序和频率。对于每一个句子来说,构建出来的词向量的长度就是整个词典的长度,词向量的每一维上都代表这一维对应的单词的频率。同理,Tf-idf就是将频率换成Tf权值。
CountVectorizer有几个参数个人觉得比较重要:
max_df:可以设置为范围在[0.0 1.0]的float,也可以设置为没有范围限制的int,默认为1.0。这个参数的作用是作为一个阈值,当构造语料库的关键词集的时候,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。如果参数中已经给定了vocabulary,则这个参数无效
min_df:类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词
max_features:默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集
Tf-idfVectorizer也有上述参数,除此之外还有一个个人觉得能用得上的:
norm:默认为''l2'',可设为''l1''或None,计算得到tf-idf值后,如果norm=''l2'',则整行权值将归一化,即整行权值向量为单位向量,如果norm=None,则不会进行归一化。大多数情况下,使用归一化是有必要的。(这里的l1和l2的区别我目前也不太明白)
通过这些方法转化的词向量维度还是比较大的,而且是稀疏阵,为了避免过拟合等问题,所以在实际处理中需要降维处理。
word2vec的话比他们要复杂一些,是利用类似神经网络进行训练得到的词向量,每一个单词有对应的向量。一般如果像微博评论情感分析这种问题,在求评论向量的时候,可以直接对每一个词向量求平均作为句子向量。至于word2vec实现不在这里赘述。word2vec可以设置好词向量维度,但是一般设在100维以上。如果样本不算太大时,为了避免后续词向量维度较大造成的训练问题,可以将输出维度设置为几十维。
![Keras Seq 中的 TextVectorization:ValueError:squeeze_dims[0] 不在 [-1,1] 中对于具有输入形状的“text_vectorization/Squeeze”(操作:“Squeeze”):[?]](http://www.gvkun.com/zb_users/upload/2025/03/9ff51d57-ece2-4122-9c13-aba4332d36851742540045379.jpg "Keras Seq 中的 TextVectorization:ValueError:squeeze_dims[0] 不在 [-1,1] 中对于具有输入形状的“text_vectorization/Squeeze”(操作:“Squeeze”):[?]")
Keras Seq 中的 TextVectorization:ValueError:squeeze_dims[0] 不在 [-1,1] 中对于具有输入形状的“text_vectorization/Squeeze”(操作:“Squeeze”):[?]
如何解决Keras Seq 中的 TextVectorization:ValueError:squeeze_dims[0] 不在 [-1,1] 中对于具有输入形状的“text_vectorization/Squeeze”(操作:“Squeeze”):[?]?
我在创建 tensorflow 2.1 模型时遇到问题。我想建立一个文本分类模型。尤其是 TextVectorization-Layer 似乎会引起问题。
这是我的代码:
import tensorflow as tf
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
import numpy as np
# training data
train = np.array([
["This is the first sentence"],["this is the second sentence"]
])
vectorize_layer = TextVectorization(output_mode="int")
vectorize_layer.adapt(train)
到目前为止,一切都很好。但是,当我尝试将它与 tf.keras.Input-Instance
model = tf.keras.models.Sequential()
model.add(tf.keras.Input(shape=(),dtype=tf.string))
model.add(vectorize_layer) # <-- this causes the error
我收到一个错误:
ValueError: squeeze_dims[0] not in [-1,1). for ''text_vectorization/Squeeze'' (op: ''Squeeze'') with input shapes: [?].
有几个 SO-Posts 处理类似的错误,(例如 this one、this 或 this)。在那里,解决方案似乎使用了正确的损失函数。但是,我什至没有在 model.compile 中达到这一点,因为错误发生得更早。
那么我在这里做错了什么?我有什么误解?错误消息末尾的 [?] 是什么意思?
确切的代码在 Tensorflow 2.4.1 版中运行良好。
(抱歉,我是一个 tensorflow 初学者。)
编辑:如果我改变
tf.keras.Input(shape=(),dtype=tf.string)
到
tf.keras.Input(shape=(1,),dtype=tf.string)
通过 model.add(vectorize_layer) 添加矢量化层有效,但之后我得到一个 different error once I call model.summary()。
仍然不确定为什么它在 Tensorflow 2.4.1 中可以正常工作,而在 2.1 中却不能?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
关于scikit-learn中的TfidfVectorizer:ValueError:np.nan是无效的文档和name sklearn is not defined的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于2 python 文本特征提取 CountVectorizer, TfidfVectorizer、CountVectorizer().适合scikit-learn Python给出内存错误、CountVectorizer,Tf-idfVectorizer和word2vec构建词向量的区别、Keras Seq 中的 TextVectorization:ValueError:squeeze_dims[0] 不在 [-1,1] 中对于具有输入形状的“text_vectorization/Squeeze”(操作:“Squeeze”):[?]的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

