本篇文章给大家谈谈ValueError:无法将输入数组从形状,以及224,224,3广播到形状的知识点,同时本文还将给你拓展1460通过翻转子数组使两个数组相等——Leetcode天天刷(2022.8
本篇文章给大家谈谈ValueError:无法将输入数组从形状,以及224,224,3广播到形状的知识点,同时本文还将给你拓展1460 通过翻转子数组使两个数组相等——Leetcode天天刷(2022.8.24)【哈希表+排序】、android sha224和python sha224之间的区别、AutoMQ 社区双周精选第九期((2024.03.11~2024.03.22)、Flash Id error.Expected 0x1cc2249,found:0x7f22449 Failed to connect.等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- ValueError:无法将输入数组从形状(224,224,3)广播到形状(224,224)(无法将值写入输出字段)
- 1460 通过翻转子数组使两个数组相等——Leetcode天天刷(2022.8.24)【哈希表+排序】
- android sha224和python sha224之间的区别
- AutoMQ 社区双周精选第九期((2024.03.11~2024.03.22)
- Flash Id error.Expected 0x1cc2249,found:0x7f22449 Failed to connect.
广播到形状(224,224)(无法将值写入输出字段)")
ValueError:无法将输入数组从形状(224,224,3)广播到形状(224,224)(无法将值写入输出字段)
我有一个列表,说temp_list具有以下属性:
len(temp_list) = 9260 temp_list[0].shape = (224,224,3)现在,当我转换为numpy数组时,
x = np.array(temp_list)我收到错误消息:
ValueError: could not broadcast input array from shape (224,224,3) into shape (224,224)有人可以帮我吗?
答案1
小编典典列表中至少有一项不是三维的,或者其第二维或第三维与其他元素不匹配。如果仅第一维不匹配,则数组仍然匹配,但是作为单独的对象,不会尝试将它们协调为新的(四维)数组。下面是一些示例:
也就是说,冒犯元件的shape != (?, 224, 3),
或ndim != 3(与?是非负整数)。
那就是给你错误的原因。
您需要解决此问题,以便将列表转换为四(或三)维数组。没有上下文,就无法说出要从3D项目中丢失尺寸还是要向2D项目添加尺寸(在第一种情况下),或者更改第二个或第三个尺寸(在第二种情况下)。
这是错误的示例:
>>> a = [np.zeros((224,224,3)), np.zeros((224,224,3)), np.zeros((224,224))]>>> np.array(a)ValueError: could not broadcast input array from shape (224,224,3) into shape (224,224)或,不同类型的输入,但相同的错误:
>>> a = [np.zeros((224,224,3)), np.zeros((224,224,3)), np.zeros((224,224,13))]>>> np.array(a)Traceback (most recent call last): File "<stdin>", line 1, in <module>ValueError: could not broadcast input array from shape (224,224,3) into shape (224,224)或者,类似但带有不同的错误消息:
>>> a = [np.zeros((224,224,3)), np.zeros((224,224,3)), np.zeros((224,100,3))]>>> np.array(a)Traceback (most recent call last): File "<stdin>", line 1, in <module>ValueError: could not broadcast input array from shape (224,224,3) into shape (224)但是,以下结果将起作用,尽管结果与预期的结果不同:
>>> a = [np.zeros((224,224,3)), np.zeros((224,224,3)), np.zeros((10,224,3))]>>> np.array(a)# long output omitted>>> newa = np.array(a)>>> newa.shape3 # oops>>> newa.dtypedtype(''O'')>>> newa[0].shape(224, 224, 3)>>> newa[1].shape(224, 224, 3)>>> newa[2].shape(10, 224, 3)>>>【哈希表+排序】")
1460 通过翻转子数组使两个数组相等——Leetcode天天刷(2022.8.24)【哈希表+排序】
1460 通过翻转子数组使两个数组相等——Leetcode天天刷(2022.8.24)【哈希表+排序】
文章目录
- 1460 通过翻转子数组使两个数组相等——Leetcode天天刷(2022.8.24)【哈希表+排序】
- 前言
- 题目描述
- 示例
- 提示
- 本地调试运行
- 输入
- 输出
- 输入样例
- 输出样例
- 解法1——哈希表
- Code(C++)
- 算法分析&&运行效率
- 解法2——排序
- Code(C++)
- 算法分析&&运行效率
前言
今天的题目,很简单,有手就行,可能是昨天的题目太难的原因,今天出的比较绿色。
看完题目就可以想到使用哈希表和排序两个解法,不过确实没想到,leetcode的执行用时属于玄学问题了,确实没想到复杂度更低的跑的更久。
题目描述
传送门
有兴趣的可以点击传送门打一下。
简单描述下题目:就是给你两个 等长数组,我们可以执行操作:选择其中一个数组的任意 非空子数组,将子数组翻转,这个操作可以执行任意次数。直到变为另外一个数组。
我们需要判断,能否使得两个数组变得一样。
示例
输入:target = [1,2,3,4], arr = [2,4,1,3]
输出:true
解释:你可以按照如下步骤使 arr 变成 target:
1- 翻转子数组 [2,4,1] ,arr 变成 [1,4,2,3]
2- 翻转子数组 [4,2] ,arr 变成 [1,2,4,3]
3- 翻转子数组 [4,3] ,arr 变成 [1,2,3,4]
上述方法并不是唯一的,还存在多种将 arr 变成 target 的方法。
输入:target = [3,7,9], arr = [3,7,11]
输出:false
解释:arr 没有数字 9 ,所以无论如何也无法变成 target 。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/make-two-arrays-equal-by-reversing-sub-arrays
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
提示

本地调试运行
输入
我们可以假定多组输入,每组先输入一个整数n,然后接下来2行,分别输入n个整数,用来表示数组的数值。
输出
每组单行输出,如果可以操作变得一样,就输出Yes, 否则就输出No。
输入样例
4
1 2 3 4
2 4 1 3
1
7
7
3
3 7 9
7 3 11
输出样例
Yes
Yes
No
解法1——哈希表
我们可以使用两个哈希表分别记录两个数组的数值出现的次数,然后再遍历一次数组比较两个哈希表。
算法比较简单,代码如下
Code(C++)
#include<iostream>
#include<vector>
#include<unordered_map>
#include<algorithm>
using namespace std;
class Solution
{
public:
// 数学,哈希表,模拟
// 可以证明:如果数组的在数值种类和数值数量上完全相同,只是可能数值顺序不同
// 那么彼此一定可以通过翻转得到
// 我们使用两个哈希表,分别记录在两个数组中的数值的个数
// 最后再遍历一次数组,比较两个哈希表
bool canBeEqual(vector<int>& target, vector<int>& arr)
{
int len1 = target.size(), len2 = arr.size(); // 获取长度
// 优化,如果长度不同,则一定不能得到!
if(len1 != len2)
{
return false;
}
unordered_map<int, int> cnt1, cnt2; // 哈希表,记录数组中数值的个数
// 循环遍历数组,记录个数
for(int i = 0; i < len1; ++i)
{
++cnt1[target[i]];
++cnt2[arr[i]];
}
// 再遍历一次数组,比较在两个数组中相同数值出现的个数
for(int i = 0; i < len1; ++i)
{
if(cnt1[target[i]] != cnt2[target[i]])
{
return false;
}
}
return true;
}
};
int main()
{
int n;
Solution *sol = new Solution();
while(~scanf("%d", &n))
{
vector<int> target(n), arr(n);
for(int i = 0; i < n; ++i)
{
scanf("%d", &target[i]);
}
for(int i = 0; i < n; ++i)
{
scanf("%d", &arr[i]);
}
if(sol->canBeEqual(target, arr))
{
printf("Yes");
}
else
{
printf("No");
}
printf("\n");
}
delete sol;
return 0;
}
算法分析&&运行效率
时间复杂度: O ( n ) O(n) O(n),遍历三次数组,n为数组长度。
空间复杂度: O ( n ) O(n) O(n),两个哈希表存储。
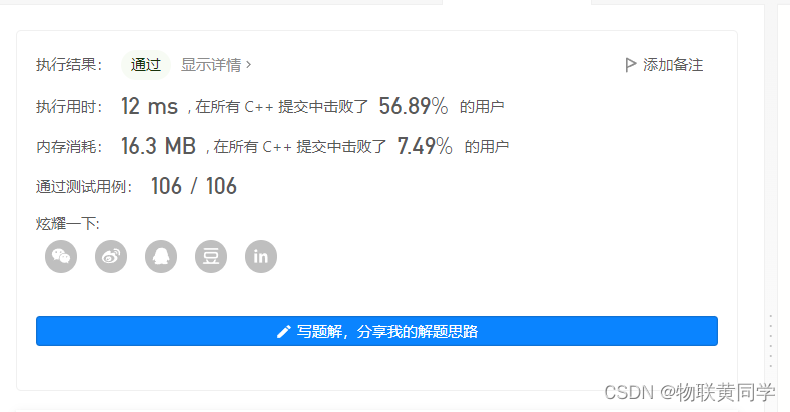
居然有点慢!
解法2——排序
排序就更简单了,直接将两个数组排好序,然后挨个比较就行了。
Code(C++)
#include<iostream>
#include<vector>
#include<unordered_map>
#include<algorithm>
using namespace std;
class Solution
{
public:
// 排序
// 可以将两个数组,然后挨个比较即可
bool canBeEqual(vector<int>& target, vector<int>& arr)
{
// 排序
sort(target.begin(), target.end());
sort(arr.begin(), arr.end());
int n = arr.size();
for(int i = 0; i < n; ++i)
{
if(arr[i] != target[i])
{
return false;
}
}
return true;
}
};
int main()
{
int n;
Solution *sol = new Solution();
while(~scanf("%d", &n))
{
vector<int> target(n), arr(n);
for(int i = 0; i < n; ++i)
{
scanf("%d", &target[i]);
}
for(int i = 0; i < n; ++i)
{
scanf("%d", &arr[i]);
}
if(sol->canBeEqual(target, arr))
{
printf("Yes");
}
else
{
printf("No");
}
printf("\n");
}
delete sol;
return 0;
}
算法分析&&运行效率
时间复杂度: O ( n log n ) O(n\log{n}) O(nlogn) ,主要是排序的时间复杂度。
空间复杂度: O ( 1 ) O(1) O(1), 没啥空间开销。
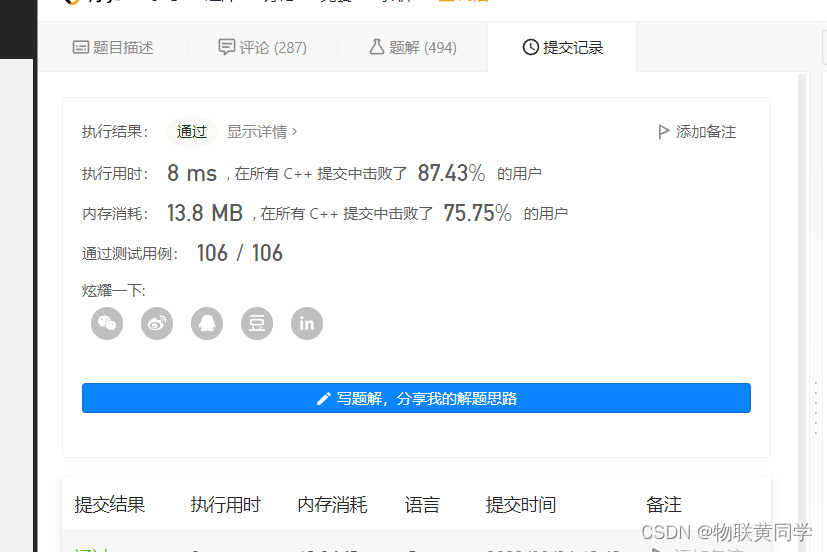
crazy!居然比哈希表快,真的玄学!

android sha224和python sha224之间的区别
对于应用程序原型,我正在创建一个简单的用户登录名.然后,将使用sha224对用户的密码进行哈希处理并将其传输到后端.我现在面临的问题如下.存储在数据库中的密码(也使用sha224进行了哈希处理)看起来与我发送的哈希略有不同.我使用以下代码创建哈希.
给定密码==测试
Python
from hashlib import sha224
sha224("test").hexdigest()
安卓
MessageDigest sha224 = MessageDigest.getInstance("SHA-224");
sha224.update(key.getBytes());
byte[] digest = sha224.digest();
StringBuffer buffer = new StringBuffer();
for(int i = 0; i < digest.length; i++) {
buffer.append(String.valueOf(Integer.toHexString(0xFF & digest[i])));
}
return buffer.toString();
现在将生成如下所示的内容,我将两个哈希值直接放在彼此下面. (第一个是python,第二个是android)
90a3ed9e32b2aaf4c61c410eb925426119e1a9dc53d4286ade99a809
90a3ed9e32b2aaf4c61c41eb925426119e1a9dc53d4286ade99a89
它们几乎相同,但是python哈希值又多了两个0.你们知道为什么吗?
解决方法:
您没有在Android上正确设置十六进制值的格式;前导0被丢弃.
buffer.append(String.format("%02x", 0xFF & digest[i]));
")
AutoMQ 社区双周精选第九期((2024.03.11~2024.03.22)
本期概要
欢迎来到 AutoMQ 第九期双周精选!
在过去两周里,@funky-eyes 为社区优化了combined 模式下的启动脚本 HELP 输出。
主干动态方面,AutoMQ 发布了 1.0.2 版本,该版本支持堆内池化和堆外池化两种策略,且 AutoMQ 主分支现已完成对 Apache Kafka 3.7.0 的分支合并。
社区贡献者名单
@funky-eyes
https://github.com/AutoMQ/automq/pull/967
该 PR 优化了 combined 模式下的启动脚本 HELP 输出
AutoMQ 主干动态
AutoMQ 1.0.2 版本发布
https://github.com/AutoMQ/automq/releases/tag/1.0.2
- 新增内存分配策略配置参数,支持堆内池化和堆外池化两种策略
- 支持 Linux 环境下的 JVM 堆大小自适应调节,支持 AutoMQ 内存相关配置自适应调节
AutoMQ 内核升级至 3.7.0
https://github.com/AutoMQ/automq/tree/mainAutoMQ
主分支现已完成对 Apache Kafka 3.7.0 的分支合并,并将在后续持续对 Apache Kafka 进行 M+1 的合并迭代
以上是第九期《双周精选》的内容,欢迎关注我们的公众号,我们会定期更新 AutoMQ 社区的进展。同时,也诚邀各位开源爱好者持续关注我们社区,跟我们一起构建云原生消息中间件!
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
GitHub 地址:https://github.com/AutoMQ/automq
官网:https://www.automq.com
B站:AutoMQ官方账号
视频号:AutoMQ
关注我们,一起学习更多云原生技术干货!

Flash Id error.Expected 0x1cc2249,found:0x7f22449 Failed to connect.

昨天J-link都用的好好的,结果今天弄了连接了很久都没有成功。
上一次也出现过这种情况,都是第二天就好了,也就没太在意这个问题。
今天在次出现这个问题,所以一定要把这个问题解决,不然到时又出现这种问题。
当面对这个问题是,一开始总是以为J-link线没接好,还是芯片烧坏了,因为习惯性的打开J-link——connect——打开bin——program,所以我们很少在意project是否有问题。
其实这个问题就是因为移动了开发板的资料,而使工程路径发生了变化,从而无法连接上。
如果你注意一下工程的配置的话,你就会发现工程的配置是有问题的。所以解决这个问题只要重新配置工程即可。
“Flash Id error.Expected 0x1cc2249,found:0x7f22449 Failed to connect.”
出现这种错误,可能会有很多方面的原因,不一定是工程出错,但是如果有这种问题,可以先考虑一下你的工程配置是否有问题。
关于ValueError:无法将输入数组从形状和224,224,3广播到形状的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于1460 通过翻转子数组使两个数组相等——Leetcode天天刷(2022.8.24)【哈希表+排序】、android sha224和python sha224之间的区别、AutoMQ 社区双周精选第九期((2024.03.11~2024.03.22)、Flash Id error.Expected 0x1cc2249,found:0x7f22449 Failed to connect.的相关信息,请在本站寻找。
本文标签:




