关于使用to_categorical转换np.array时出现内存问题和np.array转换为list的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于$.store.book[?(@.ca
关于使用to_categorical转换np.array时出现内存问题和np.array转换为list的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于$.store.book[?(@.category==''fiction'')].category、AttributeError: 'Simple_Imputer' 对象在 PyCaret 中没有属性 'fill_value_categorical''、Categorical Reparameterization with Gumbel-Softmax、CATEGORICAL, ORDINAL AND INTERVAL VARIABLES等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- 使用to_categorical转换np.array时出现内存问题(np.array转换为list)
- $.store.book[?(@.category==''fiction'')].category
- AttributeError: 'Simple_Imputer' 对象在 PyCaret 中没有属性 'fill_value_categorical''
- Categorical Reparameterization with Gumbel-Softmax
- CATEGORICAL, ORDINAL AND INTERVAL VARIABLES
")
使用to_categorical转换np.array时出现内存问题(np.array转换为list)
我有一个像这样的numpy数组:
[[0. 1. 1. ... 0. 0. 1.] [0. 0. 0. ... 0. 0. 1.] [0. 0. 1. ... 0. 0. 0.] ... [0. 0. 0. ... 0. 0. 1.] [0. 0. 0. ... 0. 0. 1.] [0. 0. 0. ... 1. 0. 1.]]我这样进行转换以减少内存需求:
x_val = x_val.astype(np.int)结果是:
[[0 1 1 ... 0 0 1] [0 0 0 ... 0 0 1] [0 0 1 ... 0 0 0] ... [0 0 0 ... 0 0 1] [0 0 0 ... 0 0 1] [0 0 0 ... 1 0 1]]但是,当我这样做时:
x_val = to_categorical(x_val)我得到:
in to_categorical categorical = np.zeros((n, num_classes), dtype=np.float32)MemoryError有什么想法吗?最终,numpy数组包含用于二进制分类问题的标签。到目前为止,我已经float32像在Keras
ANN中一样使用了它,并且效果很好,并且我取得了不错的性能。那么实际上有必要跑步to_categorical吗?
答案1
小编典典您不需要使用,to_categorical因为我猜您正在执行多标签分类。为了避免一劳永逸(!),让我解释一下。
如果您正在执行 二进制分类 ,则意味着每个样本可能仅属于两个类别之一,例如猫与狗或快乐与悲伤或正面评论与负面评论,那么:
- 标签应
[0 1 0 0 1 ... 0]具有以下形状:(n_samples,)即每个样品都带有一个(例如猫)或零(例如狗)标签。 - 用于最后一层的激活函数通常是
sigmoid(或输出范围在[0,1]范围内的值的任何其他函数)。 - 通常使用的损失函数为
binary_crossentropy。
如果您要进行 多类别分类 ,这意味着每个样本只能属于许多类别之一,例如猫与狗,狮子,快乐与中性,悲伤或正面评论,中立评论,负面评论,则:
- 标签应该是一次性编码的,即
[1, 0, 0]对应于cat,[0, 1, 0]对应于dog和[0, 0, 1]对应于lion,在这种情况下,标签的形状为(n_samples, n_classes); 或者,它们可以是整数(即稀疏标签),即1对于猫,2对于狗和3对于狮子,在这种情况下,标签的形状为(n_samples,)。该to_categorical函数用于将稀疏标签转换为一键编码的标签,当然,如果您愿意的话。 - 通常使用的激活功能是
softmax。 - 所使用的损失函数取决于标签的格式:如果标签是单次热编码,
categorical_crossentropy则使用标签;如果标签是稀疏的,则使用标签sparse_categorical_crossentropy。
如果您正在执行 多标签分类 ,这意味着每个样本可能属于零,一个或多个一类,例如图像可能同时包含猫和狗,那么:
- 标签的
[[1 0 0 1 ... 0], ..., [0 0 1 0 ... 1]]形状应为(n_samples, n_classes)。例如,标签[1 1]意味着相应的样本属于两个类别(例如猫和狗)。 sigmoid因为假定每个类别都独立于另一个类别,所以使用的激活函数。- 使用的损失函数为
binary_crossentropy。
![$.store.book[?(@.category==''fiction'')].category](http://www.gvkun.com/zb_users/upload/2025/01/f691cf2b-afff-45bb-b3fc-7cf9629a2c721737684643410.jpg "$.store.book[?(@.category==''fiction'')].category")
$.store.book[?(@.category==''fiction'')].category
表达式1
$.store.book[?(@.category==''fiction'')].category
json source


{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}返回
[
"fiction",
"fiction",
"fiction"
]
表达式2
$.store.book[?(@.category==''fiction'')].title[1]
返回
[
"w",
"o",
"h"
]
表达式3
返回索引
$.store.book[0]
$.store.book
$.store.book[:]
返回
[
[
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
]
]
$.store.book[2]
谓词修饰
Inline Predicates
Inline predicates are the ones defined in the path.
List<Map<String, Object>> books = JsonPath.parse(json) .read("$.store.book[?(@.price < 10)]");You can use && and || to combine multiple predicates [?(@.price < 10 && @.category == ''fiction'')] , [?(@.category == ''reference'' || @.price > 10)].
You can use ! to negate a predicate [?(!(@.price < 10 && @.category == ''fiction''))].
表达式5 枚举
$.store.book[?(@.category==''fiction'')].author
返回:
[
"Evelyn Waugh",
"Herman Melville",
"J. R. R. Tolkien"
]
表达式6:作用域修饰
$.store.book[?(@.price < 10 && @.category == ''fiction'')]返回:
[
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
}
]
$.store.book[?(@.category == ''reference'' || @.price > 10)]返回:
[
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
]
$.store.book[?(!(@.price < 10 && @.category == ''fiction''))]返回:
[
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
]price 作用域大于10
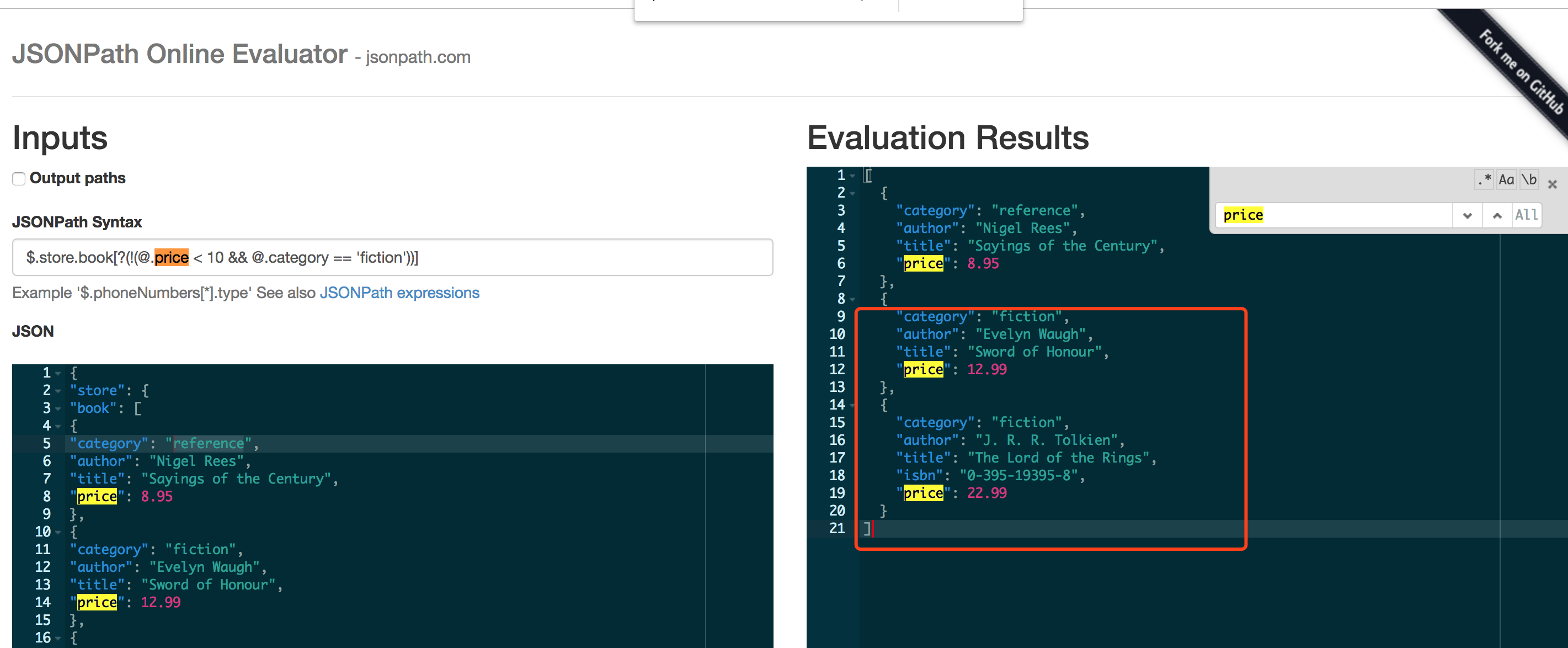
作用域!
$.store.book[?((@.price < 10 && @.category == ''fiction''))]
返回:
[
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
}
]解析{} 也就是: {子集合
$.[*]返回:


[
{
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
10,
[
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
{
"color": "red",
"price": 19.95
},
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
},
"reference",
"Nigel Rees",
"Sayings of the Century",
8.95,
"fiction",
"Evelyn Waugh",
"Sword of Honour",
12.99,
"fiction",
"Herman Melville",
"Moby Dick",
"0-553-21311-3",
8.99,
"fiction",
"J. R. R. Tolkien",
"The Lord of the Rings",
"0-395-19395-8",
22.99,
"red",
19.95
]解析
$.[*].price返回
[
19.95,
8.95,
12.99,
8.99,
22.99
]混合表达式:
[?(@.firstname == ''Bob'' || @.firstname == ''Jane'' && @.surname == ''Smith'')]"
拆分{}
$.store.[?(@.color)]返回>>>:
[
{
"color": "red",
"price": 19.95
}
]json通过正则过滤
$..book[?(@.author =~ /.*Melville/i)]返回表达式:
http://jsonpath.herokuapp.com/?path=$..book[?(@.author =~ /.*REES/i)]
[
{
"category" : "fiction",
"author" : "Herman Melville",
"title" : "Moby Dick",
"isbn" : "0-553-21311-3",
"price" : 8.99
}
]
$..book[?(@.author =~ /.*/i)]返回所有node节点


[
{
"category" : "reference",
"author" : "Nigel Rees",
"title" : "Sayings of the Century",
"price" : 8.95
},
{
"category" : "fiction",
"author" : "Evelyn Waugh",
"title" : "Sword of Honour",
"price" : 12.99
},
{
"category" : "fiction",
"author" : "Herman Melville",
"title" : "Moby Dick",
"isbn" : "0-553-21311-3",
"price" : 8.99
},
{
"category" : "fiction",
"author" : "J. R. R. Tolkien",
"title" : "The Lord of the Rings",
"isbn" : "0-395-19395-8",
"price" : 22.99
}
]特定未节点返回
http://jsonpath.herokuapp.com/?path=$..book[?(@.price =~ /.*99/i)]
$..book[?(@.price =~ /.*99/i)][
{
"category" : "fiction",
"author" : "Evelyn Waugh",
"title" : "Sword of Honour",
"price" : 12.99
},
{
"category" : "fiction",
"author" : "Herman Melville",
"title" : "Moby Dick",
"isbn" : "0-553-21311-3",
"price" : 8.99
},
{
"category" : "fiction",
"author" : "J. R. R. Tolkien",
"title" : "The Lord of the Rings",
"isbn" : "0-395-19395-8",
"price" : 22.99
}
]

AttributeError: 'Simple_Imputer' 对象在 PyCaret 中没有属性 'fill_value_categorical''
如何解决AttributeError: ''Simple_Imputer'' 对象在 PyCaret 中没有属性 ''fill_value_categorical''''?
我在使用 PyCaret 时出现错误。AttributeError: ''Simple_Imputer'' object has no attribute ''fill_value_categorical''
尝试创建一个基本实例。
!pip install pycaret==1.0
from pycaret.regression import *
exp_reg = setup(data=df,target=''Survived'',session_id=2)
解决方法
我重新安装了 pycraret (!pip install pycaret) 并且成功了;不知道发生了什么。
我在安装 pycaret 时没有其依赖项时遇到此错误。
以下情况会导致此错误:
!pip install imblearn --no-deps pycaret scikit-plot pyod lightgbm plotly
要避免此错误,请更改为:
!pip install pycaret

Categorical Reparameterization with Gumbel-Softmax

转:
Categorical Reparameterization with Gumbel-Softmax
- 概
- 主要内容
- Gumbel distribution
Jang E., Gu S. and Poole B. Categorical reparameterization with gumbel-softmax. In International Conference On Learning Representations (ICLR), 2017.
概
利用梯度反向传播训练网咯几乎是深度学习的不二法门,但是这往往要求保证梯度的存在,这在一定程度上限制了一些扩展。比如在 VAE 中,虽然当 (q_{phi}(z|x)) 是一个正态分布的时候,我们可以利用 reparameterization 来保证梯度存在,即:
但是倘若中间变量是离散变量,比如我们期望构建一个条件的 VAE, 那么我们就没法用这种方式来解决了,本文就提出了一个对离散分布的近似.
主要内容
Gumbel distribution
Gumbel distribution
由 gumbel distribution 的性质可以知道,从离散分布中采样 ([pi_1, cdots, pi_k]) 等价于
又 (arg max) 可的一个连续逼近为 softmax, 即
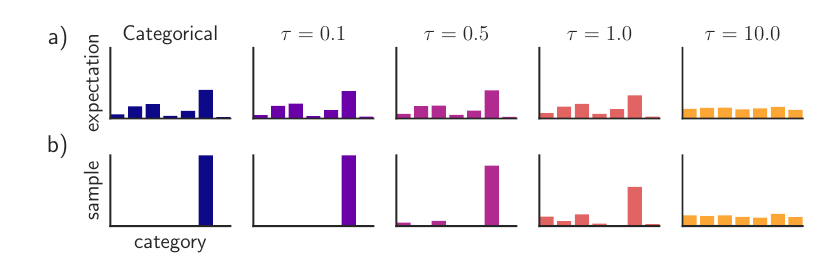
可以发现,当 (tau) 比较小的时候,Gumbel-Softmax 分布的期望和离散分布的期望是一致的,采样的情况也是相同的,我们可以选择一个较小的 (tau) 使得 Gumbel-Softmax 分布是离散分布的一个连续近似.
注:作者偏爱先取一个较大的 (tau), 再退火至一个小的 (tau=0.5).
注:作者在概率密度函数的推导过程中,即公式 (15) 出有一个小错误,应当是 (e^{-v}) 而非 (e^{x_k -v}).
转:
Categorical Reparameterization with Gumbel-Softmax
--Posted from Rpc

CATEGORICAL, ORDINAL AND INTERVAL VARIABLES
WHAT IS THE DIFFERENCE BETWEEN CATEGORICAL, ORDINAL AND INTERVAL VARIABLES?
In talking about variables, sometimes you hear variables being described as categorical (or sometimesnominal), or ordinal, or interval. Below we will define these terms and explain why they are important.
Categorical
A categorical variable (sometimes called a nominal variable) is one that has two or more categories, but there is no intrinsic ordering to the categories. For example, gender is a categorical variable having two categories (male and female) and there is no intrinsic ordering to the categories. Hair color is also a categorical variable having a number of categories (blonde, brown, brunette, red, etc.) and again, there is no agreed way to order these from highest to lowest. A purely categorical variable is one that simply allows you to assign categories but you cannot clearly order the variables. If the variable has a clear ordering, then that variable would be an ordinal variable, as described below.
Ordinal
An ordinal variable is similar to a categorical variable. The difference between the two is that there is a clear ordering of the variables. For example, suppose you have a variable, economic status, with three categories (low, medium and high). In addition to being able to classify people into these three categories, you can order the categories as low, medium and high. Now consider a variable like educational experience (with values such as elementary school graduate, high school graduate, some college and college graduate). These also can be ordered as elementary school, high school, some college, and college graduate. Even though we can order these from lowest to highest, the spacing between the values may not be the same across the levels of the variables. Say we assign scores 1, 2, 3 and 4 to these four levels of educational experience and we compare the difference in education between categories one and two with the difference in educational experience between categories two and three, or the difference between categories three and four. The difference between categories one and two (elementary and high school) is probably much bigger than the difference between categories two and three (high school and some college). In this example, we can order the people in level of educational experience but the size of the difference between categories is inconsistent (because the spacing between categories one and two is bigger than categories two and three). If these categories were equally spaced, then the variable would be an interval variable.
Interval
An interval variable is similar to an ordinal variable, except that the intervals between the values of the interval variable are equally spaced. For example, suppose you have a variable such as annual income that is measured in dollars, and we have three people who make $10,000, $15,000 and $20,000. The second person makes $5,000 more than the first person and $5,000 less than the third person, and the size of these intervals is the same. If there were two other people who make $90,000 and $95,000, the size of that interval between these two people is also the same ($5,000).
Why does it matter whether a variable is categorical, ordinal or interval?
Statistical computations and analyses assume that the variables have a specific levels of measurement. For example, it would not make sense to compute an average hair color. An average of a categorical variable does not make much sense because there is no intrinsic ordering of the levels of the categories. Moreover, if you tried to compute the average of educational experience as defined in the ordinal section above, you would also obtain a nonsensical result. Because the spacing between the four levels of educational experience is very uneven, the meaning of this average would be very questionable. In short, an average requires a variable to be interval. Sometimes you have variables that are “in between” ordinal and interval, for example, a five-point likert scale with values “strongly agree”, “agree”, “neutral”, “disagree” and “strongly disagree”. If we cannot be sure that the intervals between each of these five values are the same, then we would not be able to say that this is an interval variable, but we would say that it is an ordinal variable. However, in order to be able to use statistics that assume the variable is interval, we will assume that the intervals are equally spaced.
Does it matter if my dependent variable is normally distributed?
When you are doing a t-test or ANOVA, the assumption is that the distribution of the sample means are normally distributed. One way to guarantee this is for the distribution of the individual observations from the sample to be normal. However, even if the distribution of the individual observations is not normal, the distribution of the sample means will be normally distributed if your sample size is about 30 or larger. This is due to the “central limit theorem” that shows that even when a population is non-normally distributed, the distribution of the “sample means” will be normally distributed when the sample size is 30 or more, for example see Central limit theorem demonstration .
If you are doing a regression analysis, then the assumption is that your residuals are normally distributed. One way to make it very likely to have normal residuals is to have a dependent variable that is normally distributed and predictors that are all normally distributed, however this is not necessary for your residuals to be normally distributed. You can see
- Regression with Stata: Chapter 2 – Regression Diagnostics
- Regression with SAS: Chapter 2 -Regression Diagnostics
- Introduction to Regression with SPSS: Lesson 2 – Regression Diagnostics
我们今天的关于使用to_categorical转换np.array时出现内存问题和np.array转换为list的分享已经告一段落,感谢您的关注,如果您想了解更多关于$.store.book[?(@.category==''fiction'')].category、AttributeError: 'Simple_Imputer' 对象在 PyCaret 中没有属性 'fill_value_categorical''、Categorical Reparameterization with Gumbel-Softmax、CATEGORICAL, ORDINAL AND INTERVAL VARIABLES的相关信息,请在本站查询。
本文标签:




