本篇文章给大家谈谈Python-sklearn.pipeline.Pipeline到底是什么?,以及pipelinepython的知识点,同时本文还将给你拓展2023-06-03:redis中pipe
本篇文章给大家谈谈Python-sklearn.pipeline.Pipeline到底是什么?,以及pipeline python的知识点,同时本文还将给你拓展2023-06-03:redis中pipeline有什么好处,为什么要用 pipeline?、Azure Pipeline python 脚本环境变量、azure-pipelines-release-pipeline – 如何在使用VSTS Api获取提交列表时返回完整注释?、controller ceilometer.pipeline: Pipeline config file: None等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- Python-sklearn.pipeline.Pipeline到底是什么?(pipeline python)
- 2023-06-03:redis中pipeline有什么好处,为什么要用 pipeline?
- Azure Pipeline python 脚本环境变量
- azure-pipelines-release-pipeline – 如何在使用VSTS Api获取提交列表时返回完整注释?
- controller ceilometer.pipeline: Pipeline config file: None
")
Python-sklearn.pipeline.Pipeline到底是什么?(pipeline python)
我不知道如何sklearn.pipeline.Pipeline工作。
文档中有一些解释。例如,它们的意思是:
带有最终估算器的变换管线。
为了使我的问题更清楚,什么是steps?它们如何工作?
编辑
由于有了答案,我可以使我的问题更清楚:
当我调用管道并通过时,需要两个转换器和一个估计器,例如:
pipln = Pipeline([("trsfm1",transformer_1), ("trsfm2",transformer_2), ("estmtr",estimator)])我叫这个怎么办?
pipln.fit()ORpipln.fit_transform()我不知道估算器如何成为变压器以及如何装配变压器。
答案1
小编典典*scikit-learn中的 *Transformer- 一些具有fit和transform方法或fit_transform方法的类。
预测器 -具有fit和预测方法或fit_predict方法的某些类。
管道
只是一个抽象概念,它不是现有的ml算法。在ML任务中,通常需要在应用最终估计量之前对原始数据集执行不同变换的序列(查找特征集,生成新特征,仅选择一些良好特征)。
这是管道使用的一个很好的例子。管道为您提供了用于转换的所有三个步骤和结果估计器的单一界面。它在内部封装了转换器和预测变量,现在您可以执行以下操作:
vect = CountVectorizer() tfidf = TfidfTransformer() clf = SGDClassifier() vX = vect.fit_transform(Xtrain) tfidfX = tfidf.fit_transform(vX) predicted = clf.fit_predict(tfidfX) # Now evaluate all steps on test set vX = vect.fit_transform(Xtest) tfidfX = tfidf.fit_transform(vX) predicted = clf.fit_predict(tfidfX)只是:
pipeline = Pipeline([ (''vect'', CountVectorizer()), (''tfidf'', TfidfTransformer()), (''clf'', SGDClassifier()),])predicted = pipeline.fit(Xtrain).predict(Xtrain)# Now evaluate all steps on test setpredicted = pipeline.predict(Xtest)使用管道,您可以轻松地针对该元估计器的每个步骤对一组参数执行网格搜索。如以上链接中所述。除最后一个步骤外,所有步骤都必须是转换步骤,最后一个步骤可以是转换器或预测值。
编辑答案
:致电时pipln.fit()-管道内的每个变压器都将安装在先前变压器的输出上(从原始数据集获悉第一个变压器)。最后一个估计器可以是转换器或预测器,仅当您的最后一个估计器是转换器(可以实现fit_transform或分别转换和拟合方法)时,才可以在管道上调用fit_transform(),只有在以下情况下,才可以在管道上调用fit_predict()或predict():您的最后一个估算器是预测器。因此,您无法调用fit_transform或在管道上进行转换,后者的最后一步是预测变量。

2023-06-03:redis中pipeline有什么好处,为什么要用 pipeline?
2023-06-03:redis中pipeline有什么好处,为什么要用 pipeline?
答案2023-06-03:
Redis客户端执行一条命令通常包括以下四个阶段:
1.发送命令:客户端将要执行的命令发送到Redis服务器。
2.命令排队:Redis服务器将收到的命令放入队列中,按照先进先出(FIFO)的原则等待执行。
3.命令执行:当Redis服务器轮到该命令时,执行该命令并返回结果。在执行期间,Redis服务器可能会读取或修改数据库中的数据,或者执行其他操作。
4.返回结果:Redis服务器将结果返回给客户端,客户端可以使用该结果进行后续的操作。
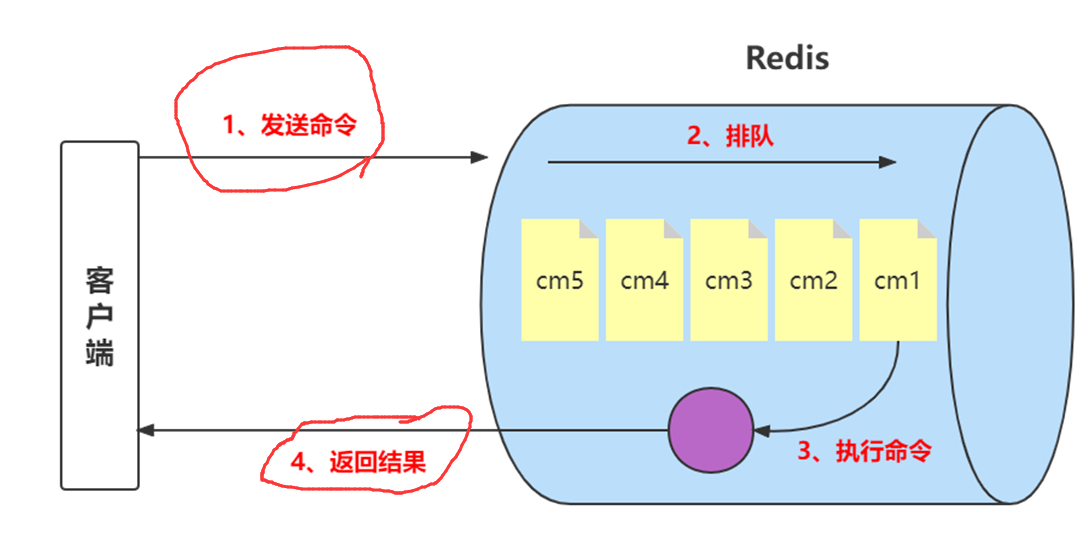
其中,第1步和第4步所需的时间被称为往返时间(Round Trip Time,RTT),即指数据在网络上传输的来回时间。
Redis提供了批量操作命令(例如 mget、mset 等),这些命令允许客户端一次发送多个命令或数据,并且将结果一次性返回给客户端,有效地节约了往返时间(RTT)。
但是需要注意的是,虽然 Redis 提供了批量操作命令,但并不是所有命令都支持批量操作。例如,如果需要执行 n 次 hgetall 命令,因为没有 mhgetall 命令等价于 MGET 命令,所以需要执行 n 次单独的 hgetall 命令,这将会消耗 n 次 RTT。
举例:Redis的客户端和服务端可能部署在不同的机器上。例如客户端在本地,Redis服务器在阿里云的广州,两地直线距离约为800公里,那么1次RTT时间=800 x2/ ( 300000×2/3 ) =8毫秒,(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3 )。而Redis命令真正执行的时间通常在微秒(1000微妙=1毫秒)级别,所以才会有Redis 性能瓶颈是网络这样的说法。
为了解决这种需要频繁与 Redis 服务器通信的问题,Redis 提供了 Pipeline(流水线)机制。Pipeline 可以将一组 Redis 命令进行组装,在一次 RTT 中将它们发送给 Redis,再将这组 Redis 命令的执行结果按顺序返回给客户端。相比于单独执行每个命令并每个命令都需要一次 RTT 的方式,使用 Pipeline 可以大幅减少网络延迟的数量。没有使用Pipeline执行了n条命令,整个过程需要n次RTT。
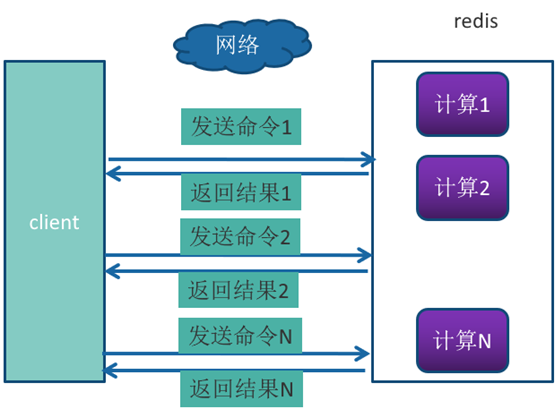
使用Pipeline 执行了n次命令,整个过程只需要1次RTT。
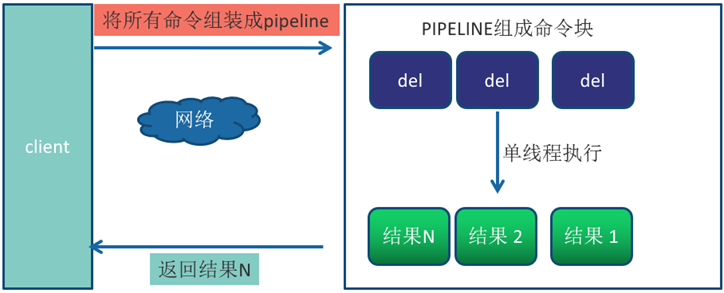
Pipeline 并不是一个新的技术或机制,而是一种已经被广泛使用的技术。在其他技术中,例如数据库、消息队列和分布式系统等领域,也有类似的机制用于减少网络延迟。
此外,在不同的网络环境下,往返时间(RTT)可能会有所不同。例如,在同一数据中心内的机器之间进行通信时,由于网络延迟较低,RTT 时间通常会更快。而当两个机器在不同的地理位置且距离较远时,RTT 时间可能会更长。
Redis 命令行客户端 redis-cli 的 --pipe 选项实际上就是使用 Pipeline 机制,允许用户一次性发送多个 Redis 命令,并一次性接收多个命令的返回结果。这样可以有效地减少网络延迟数量,并提高 Redis 的性能和可靠性。
但在大多数情况下,我们更倾向于使用 Java 语言的 Redis 客户端中的 Pipeline。这是因为 Java 客户端可以很方便地集成到应用程序的代码中,并且提供了更多的功能和灵活性。例如,Java 客户端通常支持异步操作、连接池管理、失败重试等特性,可以帮助开发者轻松地构建高性能的 Redis 应用程序。
总的来说,在不同网络环境下非Pipeline和Pipeline执行10000次set操作的效果,在执行时间上的比对如下:

差距有100多倍。在不同网络环境下,执行 10000 次 set 操作时,使用 Pipeline 和逐条执行的速度差异可能会非常大。例如,在网络延时较大的情况下,Pipeline 的效果尤为明显。据此可以得到如下两个结论:
1.使用 Pipeline 执行多个 Redis 命令,通常比逐条执行要快。这是因为 Pipeline 可以将多个命令一次性发送给 Redis 服务器,并一次性接收多个命令的返回结果,从而减少了网络传输和等待时间,提高了 Redis 的性能和响应速度。
2.客户端和服务端之间的网络延迟越大,Pipeline 的优势越明显。这是因为在网络延迟较大的情况下,每个命令执行完成后需要等待很长时间才能执行下一个命令。而使用 Pipeline,客户端可以将多个命令一次性发送给 Redis 服务器,并一次性接收多个命令的返回结果,从而减少了等待时间,提高了 Redis 的性能和可靠性。

Azure Pipeline python 脚本环境变量
如何解决Azure Pipeline python 脚本环境变量?
我有一个 python 脚本,它有 2 行代码,其中包含我的用户名和密码,出于显而易见的原因,我不想将它们推送到 GitHub,但它们对于我的 azure DevOps 管道成功运行很重要。根据一些文档,我在 python 脚本中设置 òs.environ.get` 以便能够从环境变量中检索值。
我的代码看起来像这样。
test$predProbRF = predict(rf,type="prob",newdata=test)[,2]
这是第一步,在此问题开始之后。我有一个看起来像这样的天蓝色管道。
import os
username = os.environ.get(''USERNAME'')
password = os.environ.get(''PASSWORD'')
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,"div[class$=''visible-lg''] input#signInFormUsername"))).send_keys(username)
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,"div[class$=''visible-lg''] input#signInFormPassword"))).send_keys(password)
我尝试以我知道的所有方式传递环境变量。
上面的管道是最新的,我试图将变量存储在 azure DevOps 管道中,但它失败了,因为我的 python 脚本在环境变量中找不到 trigger: none
pool:
vmImage: ''windows-latest''
stages:
- stage:
jobs:
- job: Test1
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: ''3.x''
addToPath: true
- script: |
python -m pip install --upgrade pip
pip install selenium
- task: PythonScript@0
inputs:
scriptSource: ''filePath''
scriptPath: ''./script1.py''
- job: Test2
dependsOn: test1
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: ''3.x''
addToPath: true
- script: |
python -m pip install --upgrade pip
pip install selenium
- task: PythonScript@0
inputs:
scriptSource: ''filePath''
scriptPath: ''./script2.py''
值。
我尝试使用 GitHub 机密和环境,但它失败了,因为它没有重新调整密钥 username
能否请你们中的任何人帮助我了解如何在运行时在我的管道虚拟机上设置环境变量?
编辑: 我尝试了 bazetto 的所有解决方案建议(非常感谢您的帮助),但仍然面临同样的问题。

如您所见,管道为我的变量返回了正确的值,但这些值并未传递给 python 脚本。 即使错误指向找不到 css 选择器,我也很确定 Web 驱动程序正在工作,因为在获取用户名和密码之前,有不同的按钮可以单击等。所以我的猜测是,当它来传递用户名和密码,因为变量没有从我的配置中读取,selenium 脚本超时。
对此有什么建议吗?
解决方法
由于管理员权限,您可能会遇到与环境变量相关的问题。
我的建议是用一个文件替换它,比如
config.json
{
"username": "","password": ""
}
在您的管道中,添加一个步骤来填充它:
- stage: temp
jobs:
- job: temp
displayName: temp
variables:
- name: USERNAME
value: "USER1"
- name: PASSWORD
value: "MYPWD1"
steps:
- checkout: self
- task: PowerShell@2
displayName: "Set configuration"
inputs:
targetType: "inline"
script: |
#read config
$config = Get-Content (Get-Item .\config.json) -Raw -Encoding UTF8 | ConvertFrom-Json
#set the credentials
$config.username = "$(USERNAME)" #assuming that you already have it
$config.password = "$(PASSWORD)" #assuming that you already have it
#update the file
$config | ConvertTo-Json | Set-Content .\config.json
- task: PowerShell@2
displayName: "show configuration"
inputs:
targetType: "inline"
script: |
#debug
cat config.json
配置步骤必须显示如下内容:

在你的 python 应用程序中类似:
import json
f = open(''config.json'',)
data = json.load(f)
username = data[''username'']
password = data[''password'']
#debug
print(data)

azure-pipelines-release-pipeline – 如何在使用VSTS Api获取提交列表时返回完整注释?
回复如下:
我显然可以遍历每个提交ID并通过为每个ID调用api来获取完整的注释,但是由于这个脚本将成为我们发布过程的一部分,我希望它尽可能快,所有这些额外的调用将会为脚本添加不必要的时间.
从我所看到的,在获取提交列表时无法获得完整的评论,但我希望有人可以帮我这个?
谢谢

controller ceilometer.pipeline: Pipeline config file: None
在配置ceilometer和Swift结合解决了pkg_resources.distributionNotFound:ceilometer bug后,又遇到了另一个bug:
controller ceilometer.pipeline: Pipeline config file: None,
原来是安装的ceilometer没有pipeline.yaml,所以从计算机点上复制一份过来:
在计算节点上:
scppipeline.yaml root@192.168.152.191:/etc/ceilometer/
在控制节点上:
chown-R swift.swift /etc/ceilometer
good luck!
关于Python-sklearn.pipeline.Pipeline到底是什么?和pipeline python的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于2023-06-03:redis中pipeline有什么好处,为什么要用 pipeline?、Azure Pipeline python 脚本环境变量、azure-pipelines-release-pipeline – 如何在使用VSTS Api获取提交列表时返回完整注释?、controller ceilometer.pipeline: Pipeline config file: None的相关知识,请在本站寻找。
本文标签:




