在本文中,我们将带你了解phoenix报错:typeorg.apache.phoenix.schema.types.PhoenixArrayisnotsupported在这篇文章中,我们将为您详细介绍
在本文中,我们将带你了解phoenix 报错:type org.apache.phoenix.schema.types.PhoenixArray is not supported在这篇文章中,我们将为您详细介绍phoenix 报错:type org.apache.phoenix.schema.types.PhoenixArray is not supported的方方面面,并解答phoenix explain常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的Apache Kylin 和 Phoenix的区别和性能对比、Apache Phoenix 4.10 发布,HBase 的 SQL 驱动、Apache Phoenix 4.11 发布,HBase 的 SQL 驱动、Apache Phoenix 4.13 发布,HBase 的 SQL 驱动。
本文目录一览:- phoenix 报错:type org.apache.phoenix.schema.types.PhoenixArray is not supported(phoenix explain)
- Apache Kylin 和 Phoenix的区别和性能对比
- Apache Phoenix 4.10 发布,HBase 的 SQL 驱动
- Apache Phoenix 4.11 发布,HBase 的 SQL 驱动
- Apache Phoenix 4.13 发布,HBase 的 SQL 驱动
")
phoenix 报错:type org.apache.phoenix.schema.types.PhoenixArray is not supported(phoenix explain)
今天用phoenix报如下错误:

主要原因:
hbase的表中某字段类型是array,phoenix目前不支持此类型
解决方法:
复制替换phoenix包的cursor文件
# Copyright 2015 Lukas Lalinsky
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging,re
import collections
from phoenixdb.types import TypeHelper
from phoenixdb.errors import OperationalError, NotSupportedError, ProgrammingError, InternalError
from phoenixdb.calcite import common_pb2
__all__ = [''Cursor'', ''ColumnDescription'', ''DictCursor'']
logger = logging.getLogger(__name__)
# TODO see note in Cursor.rowcount()
MAX_INT = 2 ** 64 - 1
ColumnDescription = collections.namedtuple(''ColumnDescription'', ''name type_code display_size internal_size precision scale null_ok'')
"""Named tuple for representing results from :attr:`Cursor.description`."""
class Cursor(object):
"""Database cursor for executing queries and iterating over results.
You should not construct this object manually, use :meth:`Connection.cursor() <phoenixdb.connection.Connection.cursor>` instead.
"""
arraysize = 1
"""
Read/write attribute specifying the number of rows to fetch
at a time with :meth:`fetchmany`. It defaults to 1 meaning to
fetch a single row at a time.
"""
itersize = 2000
"""
Read/write attribute specifying the number of rows to fetch
from the backend at each network roundtrip during iteration
on the cursor. The default is 2000.
"""
def __init__(self, connection, id=None):
self._connection = connection
self._id = id
self._signature = None
self._column_data_types = []
self._frame = None
self._pos = None
self._closed = False
self.arraysize = self.__class__.arraysize
self.itersize = self.__class__.itersize
self._updatecount = -1
def __del__(self):
if not self._connection._closed and not self._closed:
self.close()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, traceback):
if not self._closed:
self.close()
def __iter__(self):
return self
def __next__(self):
row = self.fetchone()
if row is None:
raise StopIteration
return row
next = __next__
def close(self):
"""Closes the cursor.
No further operations are allowed once the cursor is closed.
If the cursor is used in a ``with`` statement, this method will
be automatically called at the end of the ``with`` block.
"""
if self._closed:
raise ProgrammingError(''the cursor is already closed'')
if self._id is not None:
self._connection._client.close_statement(self._connection._id, self._id)
self._id = None
self._signature = None
self._column_data_types = []
self._frame = None
self._pos = None
self._closed = True
@property
def closed(self):
"""Read-only attribute specifying if the cursor is closed or not."""
return self._closed
@property
def description(self):
if self._signature is None:
return None
description = []
for column in self._signature.columns:
description.append(ColumnDescription(
column.column_name,
column.type.name,
column.display_size,
None,
column.precision,
column.scale,
None if column.nullable == 2 else bool(column.nullable),
))
return description
def _set_id(self, id):
if self._id is not None and self._id != id:
self._connection._client.close_statement(self._connection._id, self._id)
self._id = id
def _set_signature(self, signature):
self._signature = signature
self._column_data_types = []
self._parameter_data_types = []
if signature is None:
return
for column in signature.columns:
dtype = TypeHelper.from_class(column.column_class_name)
self._column_data_types.append(dtype)
for parameter in signature.parameters:
dtype = TypeHelper.from_class(parameter.class_name)
self._parameter_data_types.append(dtype)
def _set_frame(self, frame):
self._frame = frame
self._pos = None
if frame is not None:
if frame.rows:
self._pos = 0
elif not frame.done:
raise InternalError(''got an empty frame, but the statement is not done yet'')
def _fetch_next_frame(self):
offset = self._frame.offset + len(self._frame.rows)
frame = self._connection._client.fetch(self._connection._id, self._id,
offset=offset, frame_max_size=self.itersize)
self._set_frame(frame)
def _process_results(self, results):
if results:
result = results[0]
if result.own_statement:
self._set_id(result.statement_id)
self._set_signature(result.signature if result.HasField(''signature'') else None)
self._set_frame(result.first_frame if result.HasField(''first_frame'') else None)
self._updatecount = result.update_count
def _transform_parameters(self, parameters):
typed_parameters = []
for value, data_type in zip(parameters, self._parameter_data_types):
field_name, rep, mutate_to, cast_from = data_type
typed_value = common_pb2.TypedValue()
if value is None:
typed_value.null = True
typed_value.type = common_pb2.NULL
else:
typed_value.null = False
# use the mutator function
if mutate_to is not None:
value = mutate_to(value)
typed_value.type = rep
setattr(typed_value, field_name, value)
typed_parameters.append(typed_value)
return typed_parameters
def execute(self, operation, parameters=None):
if self._closed:
raise ProgrammingError(''the cursor is already closed'')
self._updatecount = -1
self._set_frame(None)
if parameters is None:
if self._id is None:
self._set_id(self._connection._client.create_statement(self._connection._id))
results = self._connection._client.prepare_and_execute(self._connection._id, self._id,
operation, first_frame_max_size=self.itersize)
self._process_results(results)
else:
statement = self._connection._client.prepare(self._connection._id,
operation)
self._set_id(statement.id)
self._set_signature(statement.signature)
results = self._connection._client.execute(self._connection._id, self._id,
statement.signature, self._transform_parameters(parameters),
first_frame_max_size=self.itersize)
self._process_results(results)
def executemany(self, operation, seq_of_parameters):
if self._closed:
raise ProgrammingError(''the cursor is already closed'')
self._updatecount = -1
self._set_frame(None)
statement = self._connection._client.prepare(self._connection._id,
operation, max_rows_total=0)
self._set_id(statement.id)
self._set_signature(statement.signature)
for parameters in seq_of_parameters:
self._connection._client.execute(self._connection._id, self._id,
statement.signature, self._transform_parameters(parameters),
first_frame_max_size=0)
def _transform_row(self, row):
"""Transforms a Row into Python values.
:param row:
A ``common_pb2.Row`` object.
:returns:
A list of values casted into the correct Python types.
:raises:
NotImplementedError
"""
tmp_row = []
for i, column in enumerate(row.value):
if column.has_array_value:
# 修改的地方===============
column_value = str(column.value)
if ''INTEGER'' in column_value:
pattern = ''(\d+)''
elif ''string_value'' in column_value:
pattern = ''string_value: "(.+)"''
else:
raise NotImplementedError(''array types are not supported'')
value = re.findall(pattern, str(column.value))
tmp_row.append(value)
# =========================
elif column.scalar_value.null:
tmp_row.append(None)
else:
field_name, rep, mutate_to, cast_from = self._column_data_types[i]
# get the value from the field_name
value = getattr(column.scalar_value, field_name)
# cast the value
if cast_from is not None:
value = cast_from(value)
tmp_row.append(value)
return tmp_row
def fetchone(self):
if self._frame is None:
raise ProgrammingError(''no select statement was executed'')
if self._pos is None:
return None
rows = self._frame.rows
row = self._transform_row(rows[self._pos])
self._pos += 1
if self._pos >= len(rows):
self._pos = None
if not self._frame.done:
self._fetch_next_frame()
return row
def fetchmany(self, size=None):
if size is None:
size = self.arraysize
rows = []
while size > 0:
row = self.fetchone()
if row is None:
break
rows.append(row)
size -= 1
return rows
def fetchall(self):
rows = []
while True:
row = self.fetchone()
if row is None:
break
rows.append(row)
return rows
def setinputsizes(self, sizes):
pass
def setoutputsize(self, size, column=None):
pass
@property
def connection(self):
"""Read-only attribute providing access to the :class:`Connection <phoenixdb.connection.Connection>` object this cursor was created from."""
return self._connection
@property
def rowcount(self):
"""Read-only attribute specifying the number of rows affected by
the last executed DML statement or -1 if the number cannot be
determined. Note that this will always be set to -1 for select
queries."""
# TODO instead of -1, this ends up being set to Integer.MAX_VALUE
if self._updatecount == MAX_INT:
return -1
return self._updatecount
@property
def rownumber(self):
"""Read-only attribute providing the current 0-based index of the
cursor in the result set or ``None`` if the index cannot be
determined.
The index can be seen as index of the cursor in a sequence
(the result set). The next fetch operation will fetch the
row indexed by :attr:`rownumber` in that sequence.
"""
if self._frame is not None and self._pos is not None:
return self._frame.offset + self._pos
return self._pos
class DictCursor(Cursor):
"""A cursor which returns results as a dictionary"""
def _transform_row(self, row):
row = super(DictCursor, self)._transform_row(row)
d = {}
for ind, val in enumerate(row):
d[self._signature.columns[ind].column_name] = val
return d复制替换phoenix包下的types.py文件
# Copyright 2015 Lukas Lalinsky
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import sys
import time
import datetime
from decimal import Decimal
from phoenixdb.calcite import common_pb2
__all__ = [
''Date'', ''Time'', ''Timestamp'', ''DateFromTicks'', ''TimeFromTicks'', ''TimestampFromTicks'',
''Binary'', ''STRING'', ''BINARY'', ''NUMBER'', ''DATETIME'', ''ROWID'', ''BOOLEAN'',
''JAVA_CLASSES'', ''JAVA_CLASSES_MAP'', ''TypeHelper'', ''PhoenixArray''
]
def PhoenixArray(value):
print(value)
return value
def Date(year, month, day):
"""Constructs an object holding a date value."""
return datetime.date(year, month, day)
def Time(hour, minute, second):
"""Constructs an object holding a time value."""
return datetime.time(hour, minute, second)
def Timestamp(year, month, day, hour, minute, second):
"""Constructs an object holding a datetime/timestamp value."""
return datetime.datetime(year, month, day, hour, minute, second)
def DateFromTicks(ticks):
"""Constructs an object holding a date value from the given UNIX timestamp."""
return Date(*time.localtime(ticks)[:3])
def TimeFromTicks(ticks):
"""Constructs an object holding a time value from the given UNIX timestamp."""
return Time(*time.localtime(ticks)[3:6])
def TimestampFromTicks(ticks):
"""Constructs an object holding a datetime/timestamp value from the given UNIX timestamp."""
return Timestamp(*time.localtime(ticks)[:6])
def Binary(value):
"""Constructs an object capable of holding a binary (long) string value."""
return bytes(value)
def time_from_java_sql_time(n):
dt = datetime.datetime(1970, 1, 1) + datetime.timedelta(milliseconds=n)
return dt.time()
def time_to_java_sql_time(t):
return ((t.hour * 60 + t.minute) * 60 + t.second) * 1000 + t.microsecond // 1000
def date_from_java_sql_date(n):
return datetime.date(1970, 1, 1) + datetime.timedelta(days=n)
def date_to_java_sql_date(d):
if isinstance(d, datetime.datetime):
d = d.date()
td = d - datetime.date(1970, 1, 1)
return td.days
def datetime_from_java_sql_timestamp(n):
return datetime.datetime(1970, 1, 1) + datetime.timedelta(milliseconds=n)
def datetime_to_java_sql_timestamp(d):
td = d - datetime.datetime(1970, 1, 1)
return td.microseconds // 1000 + (td.seconds + td.days * 24 * 3600) * 1000
class ColumnType(object):
def __init__(self, eq_types):
self.eq_types = tuple(eq_types)
self.eq_types_set = set(eq_types)
def __eq__(self, other):
return other in self.eq_types_set
def __cmp__(self, other):
if other in self.eq_types_set:
return 0
if other < self.eq_types:
return 1
else:
return -1
STRING = ColumnType([''VARCHAR'', ''CHAR''])
"""Type object that can be used to describe string-based columns."""
BINARY = ColumnType([''BINARY'', ''VARBINARY''])
"""Type object that can be used to describe (long) binary columns."""
NUMBER = ColumnType([''INTEGER'', ''UNSIGNED_INT'', ''BIGINT'', ''UNSIGNED_LONG'', ''TINYINT'', ''UNSIGNED_TINYINT'', ''SMALLINT'', ''UNSIGNED_SMALLINT'', ''FLOAT'', ''UNSIGNED_FLOAT'', ''DOUBLE'', ''UNSIGNED_DOUBLE'', ''DECIMAL''])
"""Type object that can be used to describe numeric columns."""
DATETIME = ColumnType([''TIME'', ''DATE'', ''TIMESTAMP'', ''UNSIGNED_TIME'', ''UNSIGNED_DATE'', ''UNSIGNED_TIMESTAMP''])
"""Type object that can be used to describe date/time columns."""
ROWID = ColumnType([])
"""Only implemented for DB API 2.0 compatibility, not used."""
BOOLEAN = ColumnType([''BOOLEAN''])
"""Type object that can be used to describe boolean columns. This is a phoenixdb-specific extension."""
# XXX ARRAY
JAVA_CLASSES = {
''bool_value'': [
(''java.lang.Boolean'', common_pb2.BOOLEAN, None, None),
],
''string_value'': [
(''java.lang.Character'', common_pb2.CHARACTER, None, None),
(''java.lang.String'', common_pb2.STRING, None, None),
(''java.math.BigDecimal'', common_pb2.BIG_DECIMAL, str, Decimal),
(''java.sql.Array'', common_pb2.ARRAY, None, None),
],
''number_value'': [
(''java.lang.Integer'', common_pb2.INTEGER, None, int),
(''java.lang.Short'', common_pb2.SHORT, None, int),
(''java.lang.Long'', common_pb2.LONG, None, long if sys.version_info[0] < 3 else int),
(''java.lang.Byte'', common_pb2.BYTE, None, int),
(''java.sql.Time'', common_pb2.JAVA_SQL_TIME, time_to_java_sql_time, time_from_java_sql_time),
(''java.sql.Date'', common_pb2.JAVA_SQL_DATE, date_to_java_sql_date, date_from_java_sql_date),
(''java.sql.Timestamp'', common_pb2.JAVA_SQL_TIMESTAMP, datetime_to_java_sql_timestamp, datetime_from_java_sql_timestamp),
],
''bytes_value'': [
(''[B'', common_pb2.BYTE_STRING, Binary, None),
],
''double_value'': [
# if common_pb2.FLOAT is used, incorrect values are sent
(''java.lang.Float'', common_pb2.DOUBLE, float, float),
(''java.lang.Double'', common_pb2.DOUBLE, float, float),
]
}
"""Groups of Java classes."""
JAVA_CLASSES_MAP = dict( (v[0], (k, v[1], v[2], v[3])) for k in JAVA_CLASSES for v in JAVA_CLASSES[k] )
"""Flips the available types to allow for faster lookup by Java class.
This mapping should be structured as:
{
''java.math.BigDecimal'': (''string_value'', common_pb2.BIG_DECIMAL, str, Decimal),),
...
''<java class>'': (<field_name>, <Rep enum>, <mutate_to function>, <cast_from function>),
}
"""
class TypeHelper(object):
@staticmethod
def from_class(klass):
"""Retrieves a Rep and functions to cast to/from based on the Java class.
:param klass:
The string of the Java class for the column or parameter.
:returns: tuple ``(field_name, rep, mutate_to, cast_from)``
WHERE
``field_name`` is the attribute in ``common_pb2.TypedValue``
``rep`` is the common_pb2.Rep enum
``mutate_to`` is the function to cast values into Phoenix values, if any
``cast_from`` is the function to cast from the Phoenix value to the Python value, if any
:raises:
NotImplementedError
"""
if klass == ''org.apache.phoenix.schema.types.PhoenixArray'':
klass = "java.sql.Array"
if klass not in JAVA_CLASSES_MAP:
raise NotImplementedError(''type {} is not supported''.format(klass))
return JAVA_CLASSES_MAP[klass]改动后只支持 array里面的值是int、string例如 array(1,2,3),array(''12'',''a'',''b'')

Apache Kylin 和 Phoenix的区别和性能对比
Apache Kylin 和 Apache Phoenix 都能使用 Apache HBase 做数据存储和查询,那么,同为 HBase 上的 SQL 引擎,它们之间有什么不同呢?下面我们将从这两个项目的介绍开始为大家做个深度解读和比较。
1.Apache Kylin 和 Apache Phoenix介绍
1.1 Apache Kylin
Kylin 是一个分布式的大数据分析引擎,提供在 Hadoop 之上的 SQL 接口和多维分析能力(OLAP),可以做到在 TB 级的数据量上实现亚秒级的查询响应。

上图是 Kylin 的架构图,从图中可以看出,Kylin 利用 MapReduce/Spark 将原始数据进行聚合计算,转成了 OLAP Cube 并加载到 HBase 中,以 Key-Value 的形式存储。Cube 按照时间范围划分为多个 segment,每个 segment 是一张 HBase 表,每张表会根据数据大小切分成多个 region。Kylin 选择 HBase 作为存储引擎,是因为 HBase 具有延迟低,容量大,使用广泛,API完备等特性,此外它的 Hadoop 接口完善,用户社区也十分活跃。
1.2 Apache Phoenix
Phoenix 是一个 Hadoop 上的 OLTP 和业务数据分析引擎,为用户提供操作 HBase 的 SQL 接口,结合了具有完整 ACID 事务功能的标准 SQL 和 JDBC API,以及来自 NoSQL 的后期绑定,具有读取模式灵活的优点。
下图为 Phoenix 的架构图,从图中可以看出,Phoenix 分为 client 和 server,其中 client 又分为 thin(本质上是一个 JDBC 驱动,所依赖的第三方类较少)和非 thin (所依赖的第三方类较多)两种;server 是针对 thin client 而言的,为 standalone 模式,是由一台 Java 服务器组成,代表客户端管理 Phoenix 的连接,可以进行横向扩展,启动方式也很简单,通过 bin/queryserver.py start 即可。
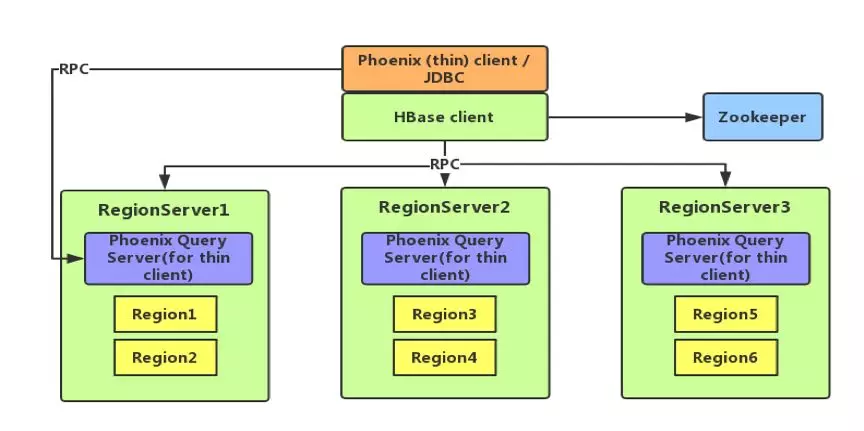
2.Apache Kylin 和 Apache Phoenix 对比
2.1优缺点对比
Kylin 的优点主要有以下几点:
1. 支持雪花/星型模型;
2. 亚秒级查询响应;
3. 支持 ANSI-SQL,可通过 ODBC,JDBC 以及 RESTful API 进行访问;
4. 支持百亿、千亿甚至万亿级别交互式分析;
5. 无缝与 BI 工具集成;
6. 支持增量刷新;
7. 既支持历史数据也支持流式数据;
8. 易用的管理页面和 API。
Phoenix 的优点则主要是以下几点:
1. 支持明细和聚合查询;
2. 支持 insert, update, delete 操作,其使用 upsert 来代替 insert 和 update;
3. 较好的利用 HBase 的优点,如 row timestamp,将其与 HBase 原生的 row timestamp 映射起来,有助于 Phoenix 利用 HBase 针对存储文件的时间范围提供的多种优化和 Phoenix 内置的各式各样的查询优化;
4. 支持多种函数:聚合、String、时间和日期、数字、数组、数学和其它函数;
5. 支持具有完整 ACID 语义的跨行及跨表事务;
6. 支持多租户;
7. 支持索引(二级索引),游标。
当然,Kylin 和 Phoenix 也都有一些还有待提升的不足之处。Kylin 的不足主要是体现在首先由于 Kylin 是一个分析引擎,只读,不支持 insert,update,delete 等 SQL 操作,用户修改数据的话需要重新批量导入(构建);其次,Kylin 用户需要预先建立模型后加载数据到 Cube 后才可进行查询;最后,使用 Kylin 的建模人员需要了解一定的数据仓库知识。
Phoenix 的不足则主要体现在:首先,其二级索引的使用有一定的限制,只有当查询中所有的列都在索引或覆盖索引中才生效且成本较高,在使用之前还需配置;其次,范围扫描的使用有一定的限制,只有当使用了不少于一个在主键约束中的先导列时才生效;最后,创建表时必须包含主键 ,对别名支持不友好。
2.2 phoenix和 Kylin存储格式对比
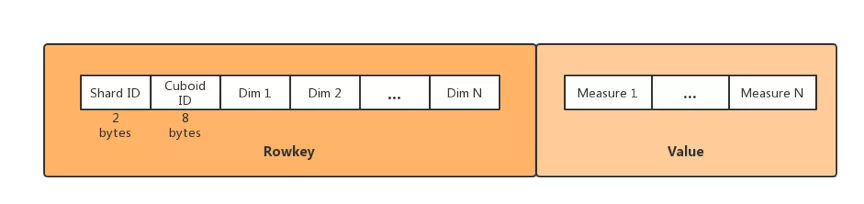
Kylin 将数据列区分成维度和度量:维度的顺序与 HBase 中的 Rowkey 建立关系从而将 Cube 数据存储,维度的值会被编码为字节,然后多个维度的值被拼接在一起组成 Rowkey,Rowkey 的格式为 Shard ID(2 字节)+ Cuboid ID(8 字节,标记有哪几个列)+ 维度值;度量的值会被序列化为字节数组,然后以 column 的方式存储;多个度量值可以放在同一个列簇中,也可以放在不同列簇中。如下图所示:
Phoenix 在列名与 HBase 列限定符之间引入了一个间接层,将 HBase 非关系型形式转换成关系型数据模型,在创建表时默认会将 PK 与 HBase 中表的 Rowkey 映射起来,PK 支持多字段组合,剩下的列可以根据需求进行选择,列簇如果未显式定义,则会被忽略,Qualifier 会转换成表的字段名。如下图所示:

2.3 phoenix和 Kylin查询方式对比
Kylin 查询时会将 SQL 通过 Apache Calcite 进行解析和优化,转化成对 HBase 的 RPC 访问。Kylin 会将计算逻辑下压到 HBase Region Server 中使用 Coprocessor 并行运行,每个 RS 返回过滤聚合后的数据给 Kylin 节点,Kylin 做最后的处理后返回给客户端。因为大量的计算在 Cube 生成的时候已经完成,因此 Kylin 的查询效率非常高,通常在毫秒到秒级。
Kylin 在 Insight 页面提供 SQL 查询窗口;也能够通过 REST API 发送请求的方式进行查询;还能够快速的与其他 BI 工具集成并使用 BI 工具自带的方式进行查询。
Phoenix 直接使用 HBase API,以及协处理器和自定义过滤器,从而使得查询的效率更好。对于查询,Phoenix 可以根据 region 的边界进行分块并在客户端并行运行以减少延迟。聚合操作将在服务器端的协处理器中完成(这点与 Kylin 类似),返回到客户端的数据量是进行过压缩的,而不是全部返回。
Phoenix 是通过命令行的方式进行查询(既可以输入单条 SQL 语句,也可以执行 SQL 文件);也可以通过界面进行查询,但需额外安装 Squirrel。
2.4 phoenix和 Kylin查询优化方式对比
Kylin 查询优化方法比较多样,既有逻辑层的维度减枝优化(层级,必须,联合,推导等),编码优化,rowkey 优化等,也有存储层的优化,如按某个维度切 shard,region 大小划分优化,segment 自动合并等,具体可以参考 Kylin 的文档。用户可以根据自己的数据特征、性能需求使用不同的策略,从而在空间和时间之间找到一个平衡点。
为了使得查询效率更高,Phoenix 可以在表上加索引,不同的索引有不同的适用场景:全局索引适用于大量读取的场景,且要求查询中引用的所有列都包含在索引中;本地索引适用于大量写入,空间有限的场景。索引会将数据的值进行拷贝,额外增加了开销,且使用二级索引还需在 HBase 的配置文件中进行相应配置。数据总不会是完美分布的,HBase 顺序写入时(行键单调递增)可能会导致热点问题,这时可以通过加盐操作来解决,Phoenix 可以为 key 自动加盐。
从上述内容可以看出:
1)Kylin 和 Phoenix 虽然同为 Hadoop/HBase 上的 SQL 引擎,两者的定位不同,一个是 OLAP,另一个是 OLTP,服务于不同的场景;
2)Phoenix 更多的是适用于以往关系型数据库的相关操作,当查询语句是点查找和小范围扫描时,Phoenix 可以比较好地满足,而它不太适合大量 scan 类型的 OLAP 查询,或查询的模式较为灵活的场景;
3)Kylin 是一个只读型的分析引擎,不适合细粒度修改数据,但适合做海量数据的交互式在线分析,通常跟数据仓库以及 BI 工具结合使用,目标用户为业务分析人员。
下面我们做一个简单的性能测试,因为 Kylin 不支持数据写入,因此我们不得不测试数据的查询性能,使用相同 HBase 集群和数据集。
2.5 phoenix和 Kylin性能对比
我们准备的测试环境为 CDH 5.15.1,1个 Master,7个 Region Server,每个节点 8 核心 58G 内存,使用 Star Schema Benchmark 数据进行测试。其中单表 Lineorder 表数据量为 3 千万,大小为 8.70 GB。Phoenix 导入时间: 7mins 9sec,Kylin 导入时间: 32mins 8sec。多表 Lineorder 数据量 750 万,大小为 10 GB。具体的 SQL 语句参见:
单表的sql 1、select lo_custkey, sum(lo_revenue) from lineorder group by lo_custkey 2、select count(*) from lineorder 3、select LINEORDER.LO_ORDERDATE, sum(LINEORDER.LO_REVENUE) as sum_lo_revenue from lineorder where LINEORDER.LO_ORDERDATE > 19960105 and LINEORDER.LO_ORDERDATE < 19960305 group by LINEORDER.LO_ORDERDATE 4、select LINEORDER.LO_CUSTKEY, LINEORDER.LO_ORDERDATE, sum(LINEORDER.LO_REVENUE) as sum_lo_revenue from lineorder where LINEORDER.LO_ORDERDATE > 19960105 and LINEORDER.LO_ORDERDATE < 19960305 group by LINEORDER.LO_ORDERDATE, LINEORDER.LO_CUSTKEY having sum_lo_revenue > 55000000 order by sum_lo_revenue desc 多表的sql: 1、select sum(lo_revenue) as revenue from lineorder left join dates on lo_orderdate = d_datekey where d_year = 1993 and lo_discount between 1 and 3 and lo_quantity < 25; 2、select sum(lo_revenue) as lo_revenue, d_year, p_brand from lineorder left join dates on lo_orderdate = d_datekey left join part on lo_partkey = p_partkey left join supplier on lo_suppkey = s_suppkey where p_brand between ''MFGR#2221'' and ''MFGR#2228'' and s_region = ''ASIA'' group by d_year, p_brand order by d_year, p_brand;
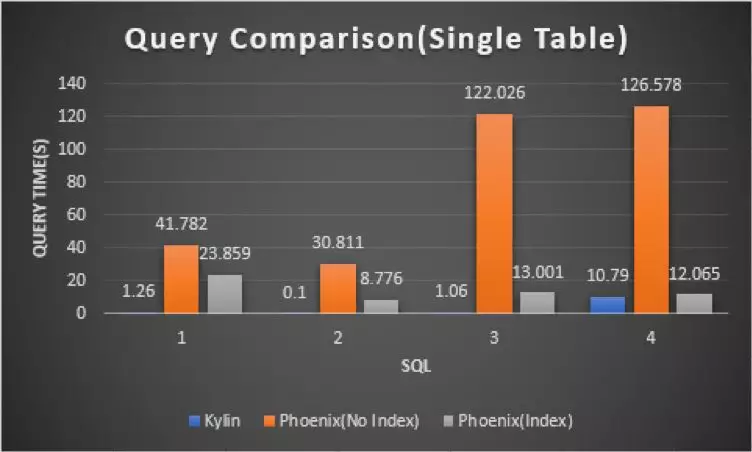
图5 单表对比图
图 5 是一个单表查询场景的分析,从上我们可以看出, 针对于一张表的查询,Phoenix 查询的耗时是 Kylin 的几十甚至是几百倍,加入索引后,Phoenix 的查询速度有了较为显著的提升,但仍然是 Kylin 的十几倍甚至几十倍,因此单表查询 Kylin 具有明显优势。
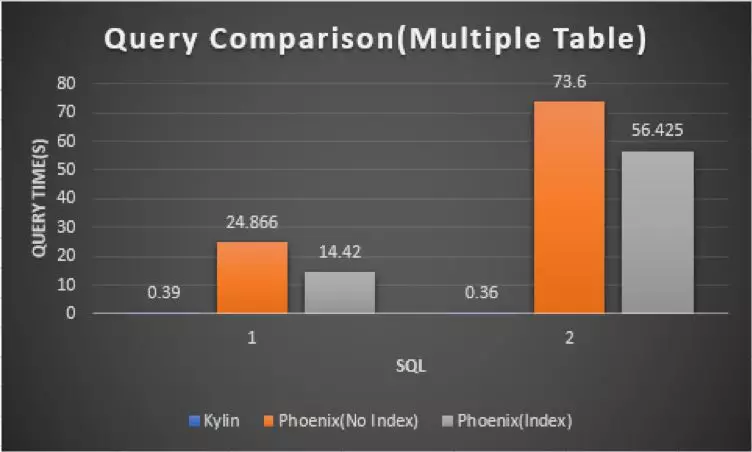
图6 多表对比图
图6是一个多表 join 查询的场景,从上图可以看出,对于多表 join 的情况,Kylin 查询依旧非常快,因为 join 在 Cube 构建阶段已经完成了;Phoenix 加入索引后时间并没有较为显著的减少,耗时仍然是 Kylin 的几十倍甚至几百倍。

Apache Phoenix 4.10 发布,HBase 的 SQL 驱动
Apache Phoenix 4.10 发布了,Apache Phoenix 是 HBase 的 SQL 驱动。Phoenix 使得 HBase 支持通过 JDBC 的方式进行访问,并将你的 SQL 查询转成 HBase 的扫描和相应的动作。
4.x 版本与 HBase 0.98/1.1/1.2 兼容。
本次发布值得关注的更新:
通过列编码减少磁盘占用空间,并优化只写入一次的数据的存储格式
在 Phoenix/Spark 集成中支持 Apache Spark 2.0
通过 Phoenix 消耗 Apache Kafka 消息
通过跨集群分布执行来提高 UPSERT SELECT 性能
改进 Hive 集成
40+ bug 修复
下载地址 和 发布主页

Apache Phoenix 4.11 发布,HBase 的 SQL 驱动
Apache Phoenix 4.11 发布了,Apache Phoenix 是 HBase 的 SQL 驱动。Phoenix 使得 HBase 支持通过 JDBC 的方式进行访问,并将你的 SQL 查询转成 HBase 的扫描和相应的动作。
更新内容:
Support for HBase 1.3.1 and above
Local index hardening and performance improvements [1]
Atomic update of data and local index rows (HBase 1.3 only) [2]
Use of snapshots for MR-based queries and async index building [3][4]
Support for forward moving cursors [5]
Chunk commit data from client based on byte size and row count [6]
Reduce load on region server hosting SYSTEM.CATALOG [7]
50+ bug fixes [8]
下载地址:
http://phoenix.apache.org/download.html

Apache Phoenix 4.13 发布,HBase 的 SQL 驱动
Apache Phoenix 4.13 已发布,Apache Phoenix 是 HBase 的 SQL 驱动。Phoenix 使得 HBase 支持通过 JDBC 的方式进行访问,并将你的 SQL 查询转成 HBase 的扫描和相应的动作。
Phoenix 4.x 与 HBase 0.98 和 1.3 兼容。
更新亮点:
修复在连接时创建 SYSTEM.CATALOG 快照的 bug
关于行删除处理的大量错误修复
统计收集改进
新增 COLLATION_KEY 函数
详情可查阅发行说明
下载地址:
http://phoenix.apache.org/download.html
关于phoenix 报错:type org.apache.phoenix.schema.types.PhoenixArray is not supported和phoenix explain的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于Apache Kylin 和 Phoenix的区别和性能对比、Apache Phoenix 4.10 发布,HBase 的 SQL 驱动、Apache Phoenix 4.11 发布,HBase 的 SQL 驱动、Apache Phoenix 4.13 发布,HBase 的 SQL 驱动的相关信息,请在本站寻找。
本文标签:




