本文将分享ELK学习笔记之基于kakfa(confluent)搭建ELK的详细内容,并且还将对elk+kafka+filebeat进行详尽解释,此外,我们还将为大家带来关于Centos7+kafka+
本文将分享ELK 学习笔记之基于 kakfa (confluent) 搭建 ELK的详细内容,并且还将对elk+kafka+filebeat进行详尽解释,此外,我们还将为大家带来关于Centos7+kafka+ELK6.5.x安装搭建、Confluent kafka rest 实战、DataPipeline联合Confluent Kafka Meetup上海站、ELK - Fluentd 日志收集(官方文档 部署安装 配置文件 详解)的相关知识,希望对你有所帮助。
本文目录一览:- ELK 学习笔记之基于 kakfa (confluent) 搭建 ELK(elk+kafka+filebeat)
- Centos7+kafka+ELK6.5.x安装搭建
- Confluent kafka rest 实战
- DataPipeline联合Confluent Kafka Meetup上海站
- ELK - Fluentd 日志收集(官方文档 部署安装 配置文件 详解)
 搭建 ELK(elk+kafka+filebeat)")
ELK 学习笔记之基于 kakfa (confluent) 搭建 ELK(elk+kafka+filebeat)
0x00 概述
测试搭建一个使用 kafka 作为消息队列的 ELK 环境,数据采集转换实现结构如下:
F5 HSL–>logstash (流处理)–> kafka –>elasticsearch
测试中的 elk 版本为 6.3, confluent 版本是 4.1.1
希望实现的效果是 HSL 发送的日志胫骨 logstash 进行流处理后输出为 json,该 json 类容原样直接保存到 kafka 中,kafka 不再做其它方面的格式处理。
0x01 测试
192.168.214.138: 安装 logstash,confluent 环境
192.168.214.137: 安装 ELK 套件(停用 logstash,只启动 es 和 kibana)
confluent 安装调试备忘:
-
- 像安装 elk 环境一样,安装 java 环境先
- 首先在不考虑 kafka 的情形下,实现 F5 HSL—Logstash–ES 的正常运行,并实现简单的正常 kibana 的展现。后面改用 kafka 时候直接将这里 output 修改为 kafka plugin 配置即可。
此时 logstash 的相关配置
input {
udp {
port => 8514
type => ''f5-dns''
}
}
filter {
if [type] == ''f5-dns'' {
grok {
match => { "message" => "%{HOSTNAME:F5hostname} %{IP:clientip} %{POSINT:clientport} %{IP:svrip} %{NUMBER:qid} %{HOSTNAME:qname} %{GREEDYDA
TA:qtype} %{GREEDYDATA:status} %{GREEDYDATA:origin}" }
}
geoip {
source => "clientip"
target => "geoip"
}
}
}
output {
#stdout{ codec => rubydebug }
#elasticsearch {
# hosts => ["192.168.214.137:9200"]
# index => "f5-dns-%{+YYYY.MM.dd}"
#template_name => "f5-dns"
#}
kafka {
codec => json
bootstrap_servers => "localhost:9092"
topic_id => "f5-dns-kafka"
}
}发一些测试流量,确认 es 正常收到数据,查看 cerebro 上显示的状态。(截图是调试完毕后截图)
# cd /usr/share/cerebro/cerebro-0.8.1/
# /bin/cerebro -Dhttp.port=9110 -Dhttp.address=0.0.0.0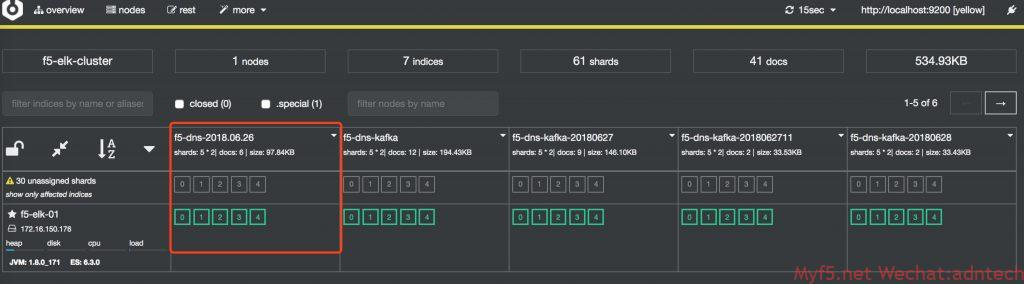
安装 confluent,由于是测试环境,直接 confluent 官方网站下载压缩包,解压后使用。位置在 /root/confluent-4.1.1 / 下
由于是测试环境,直接用 confluent 的命令行来启动所有相关服务,发现 kakfa 启动失败
[root@kafka-logstash bin]# ./confluent start
Using CONFLUENT_CURRENT: /tmp/confluent.dA0KYIWj
Starting zookeeper
zookeeper is [UP]
Starting kafka
/Kafka failed to start
kafka is [DOWN]
Cannot start Schema Registry, Kafka Server is not running. Check your deployment检查发现由于虚机内存给太少了,导致 java 无法分配足够内存给 kafka
[root@kafka-logstash bin]# ./kafka-server-start ../etc/kafka/server.properties
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error=''Cannot allocate memory'' (errno=12)扩大虚拟机内存,并将 logstash 的 jvm 配置中设置的内存调小
kafka server 配置文件
[root@kafka-logstash kafka]# pwd
/root/confluent-4.1.1/etc/kafka
[root@kafka-logstash kafka]# egrep -v "^#|^$" server.properties
broker.id=0
listeners=PLAINTEXT://localhost:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=6000
confluent.support.metrics.enable=true
confluent.support.customer.id=anonymous
group.initial.rebalance.delay.ms=0connect 配置文件,此配置中,将原来的 avro converter 替换成了 json,同时关闭了 key vlaue 的 schema 识别。因为我们输入的内容是直接的 json 类容,没有相关 schema,这里只是希望 kafka 原样解析 logstash 输出的 json 内容到 es
[root@kafka-logstash kafka]# pwd
/root/confluent-4.1.1/etc/kafka
[root@kafka-logstash kafka]# egrep -v "^#|^$" connect-standalone.properties
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
plugin.path=share/java如果不做上述修改,connect 总会在将日志 sink 到 ES 时提示无法反序列化,magic byte 错误等。如果使用 confluent status 命令查看,会发现 connect 会从 up 变为 down
[root@kafka-logstash confluent-4.1.1]# ./bin/confluent status
ksql-server is [DOWN]
connect is [DOWN]
kafka-rest is [UP]
schema-registry is [UP]
kafka is [UP]
zookeeper is [UP]schema-registry 相关配置
[root@kafka-logstash schema-registry]# pwd
/root/confluent-4.1.1/etc/schema-registry
[root@kafka-logstash schema-registry]# egrep -v "^#|^$"
connect-avro-distributed.properties connect-avro-standalone.properties log4j.properties schema-registry.properties
[root@kafka-logstash schema-registry]# egrep -v "^#|^$" connect-avro-standalone.properties
bootstrap.servers=localhost:9092
key.converter.schema.registry.url=http://localhost:8081
value.converter.schema.registry.url=http://localhost:8081
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
plugin.path=share/java
[root@kafka-logstash schema-registry]# egrep -v "^#|^$" schema-registry.properties
listeners=http://0.0.0.0:8081
kafkastore.connection.url=localhost:2181
kafkastore.topic=_schemas
debug=falsees-connector 的配置文件
[root@kafka-logstash kafka-connect-elasticsearch]# pwd
/root/confluent-4.1.1/etc/kafka-connect-elasticsearch
[root@kafka-logstash kafka-connect-elasticsearch]# egrep -v "^#|^$" quickstart-elasticsearch.properties
name=f5-dns
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
topics=f5-dns-kafka
key.ignore=true
value.ignore=true
schema.ignore=true
connection.url=http://192.168.214.137:9200
type.name=doc
transforms=MyRouter
transforms.MyRouter.type=org.apache.kafka.connect.transforms.TimestampRouter
transforms.MyRouter.topic.format=${topic}-${timestamp}
transforms.MyRouter.timestamp.format=yyyyMMdd上述配置中 topics 配置是希望传输到 ES 的 topic,通过设置 transform 的 timestamp router 来实现将 topic 按天动态映射为 ES 中的 index,这样可以让 ES 每天产生一个 index。注意需要配置 schema.ignore=true, 否则 kafka 无法将受收到的数据发送到 ES 上,connect 的 connect.stdout 日志会显示:
[root@kafka-logstash connect]# pwd
/tmp/confluent.dA0KYIWj/connect
Caused by: org.apache.kafka.connect.errors.DataException: Cannot infer mapping without schema.
at io.confluent.connect.elasticsearch.Mapping.inferMapping(Mapping.java:84)
at io.confluent.connect.elasticsearch.jest.JestElasticsearchClient.createMapping(JestElasticsearchClient.java:221)
at io.confluent.connect.elasticsearch.Mapping.createMapping(Mapping.java:66)
at io.confluent.connect.elasticsearch.ElasticsearchWriter.write(ElasticsearchWriter.java:260)
at io.confluent.connect.elasticsearch.ElasticsearchSinkTask.put(ElasticsearchSinkTask.java:162)
at org.apache.kafka.connect.runtime.WorkerSinkTask.deliverMessages(WorkerSinkTask.java:524)配置修正完毕后,向 logstash 发送数据,发现日志已经可以正常发送到了 ES 上,且格式和没有 kafka 时是一致的。
没有 kafka 时:
{
"_index": "f5-dns-2018.06.26",
"_type": "doc",
"_id": "KrddO2QBXB-i0ay0g5G9",
"_version": 1,
"_score": 1,
"_source": {
"message": "localhost.lan 202.202.102.100 53777 172.16.199.136 42487 www.test.com A NOERROR GTM_REWRITE ",
"F5hostname": "localhost.lan",
"qid": "42487",
"clientip": "202.202.102.100",
"geoip": {
"region_name": "Chongqing",
"location": {
"lon": 106.5528,
"lat": 29.5628
},
"country_code2": "CN",
"timezone": "Asia/Shanghai",
"country_name": "China",
"region_code": "50",
"continent_code": "AS",
"city_name": "Chongqing",
"country_code3": "CN",
"ip": "202.202.102.100",
"latitude": 29.5628,
"longitude": 106.5528
},
"status": "NOERROR",
"qname": "www.test.com",
"clientport": "53777",
"@version": "1",
"@timestamp": "2018-06-26T09:12:21.585Z",
"host": "192.168.214.1",
"type": "f5-dns",
"qtype": "A",
"origin": "GTM_REWRITE ",
"svrip": "172.16.199.136"
}
}有 kafka 时:
{
"_index": "f5-dns-kafka-20180628",
"_type": "doc",
"_id": "f5-dns-kafka-20180628+0+23",
"_version": 1,
"_score": 1,
"_source": {
"F5hostname": "localhost.lan",
"geoip": {
"city_name": "Chongqing",
"timezone": "Asia/Shanghai",
"ip": "202.202.100.100",
"latitude": 29.5628,
"country_name": "China",
"country_code2": "CN",
"continent_code": "AS",
"country_code3": "CN",
"region_name": "Chongqing",
"location": {
"lon": 106.5528,
"lat": 29.5628
},
"region_code": "50",
"longitude": 106.5528
},
"qtype": "A",
"origin": "DNSX ",
"type": "f5-dns",
"message": "localhost.lan 202.202.100.100 53777 172.16.199.136 42487 www.myf5.net A NOERROR DNSX ",
"qid": "42487",
"clientport": "53777",
"@timestamp": "2018-06-28T09:05:20.594Z",
"clientip": "202.202.100.100",
"qname": "www.myf5.net",
"host": "192.168.214.1",
"@version": "1",
"svrip": "172.16.199.136",
"status": "NOERROR"
}
}相关 REST API 输出
http://192.168.214.138:8083/connectors/elasticsearch-sink/tasks
[
{
"id": {
"connector": "elasticsearch-sink",
"task": 0
},
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type.name": "doc",
"value.ignore": "true",
"tasks.max": "1",
"topics": "f5-dns-kafka",
"transforms.MyRouter.topic.format": "${topic}-${timestamp}",
"transforms": "MyRouter",
"key.ignore": "true",
"schema.ignore": "true",
"transforms.MyRouter.timestamp.format": "yyyyMMdd",
"task.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkTask",
"name": "elasticsearch-sink",
"connection.url": "http://192.168.214.137:9200",
"transforms.MyRouter.type": "org.apache.kafka.connect.transforms.TimestampRouter"
}
}
]
http://192.168.214.138:8083/connectors/elasticsearch-sink/
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type.name": "doc",
"value.ignore": "true",
"tasks.max": "1",
"topics": "f5-dns-kafka",
"transforms.MyRouter.topic.format": "${topic}-${timestamp}",
"transforms": "MyRouter",
"key.ignore": "true",
"schema.ignore": "true",
"transforms.MyRouter.timestamp.format": "yyyyMMdd",
"name": "elasticsearch-sink",
"connection.url": "http://192.168.214.137:9200",
"transforms.MyRouter.type": "org.apache.kafka.connect.transforms.TimestampRouter"
},
"tasks": [
{
"connector": "elasticsearch-sink",
"task": 0
}
],
"type": "sink"
}
http://192.168.214.138:8083/connectors/elasticsearch-sink/status
{
"name": "elasticsearch-sink",
"connector": {
"state": "RUNNING",
"worker_id": "172.16.150.179:8083"
},
"tasks": [
{
"state": "RUNNING",
"id": 0,
"worker_id": "172.16.150.179:8083"
}
],
"type": "sink"
}http://192.168.214.138:8082/brokers
{
"brokers": [
0
]
}
http://192.168.214.138:8082/topics
[
"__confluent.support.metrics",
"_confluent-ksql-default__command_topic",
"_schemas",
"connect-configs",
"connect-offsets",
"connect-statuses",
"f5-dns-2018.06",
"f5-dns-2018.06.27",
"f5-dns-kafka",
"test-elasticsearch-sink"
]
http://192.168.214.138:8082/topics/f5-dns-kafka
{
"name": "f5-dns-kafka",
"configs": {
"file.delete.delay.ms": "60000",
"segment.ms": "604800000",
"min.compaction.lag.ms": "0",
"retention.bytes": "-1",
"segment.index.bytes": "10485760",
"cleanup.policy": "delete",
"follower.replication.throttled.replicas": "",
"message.timestamp.difference.max.ms": "9223372036854775807",
"segment.jitter.ms": "0",
"preallocate": "false",
"segment.bytes": "1073741824",
"message.timestamp.type": "CreateTime",
"message.format.version": "1.1-IV0",
"max.message.bytes": "1000012",
"unclean.leader.election.enable": "false",
"retention.ms": "604800000",
"flush.ms": "9223372036854775807",
"delete.retention.ms": "86400000",
"leader.replication.throttled.replicas": "",
"min.insync.replicas": "1",
"flush.messages": "9223372036854775807",
"compression.type": "producer",
"min.cleanable.dirty.ratio": "0.5",
"index.interval.bytes": "4096"
},
"partitions": [
{
"partition": 0,
"leader": 0,
"replicas": [
{
"broker": 0,
"leader": true,
"in_sync": true
}
]
}
]
}测试中 kafka 的配置基本都为确实配置,没有考虑任何的内存优化,kafka 使用磁盘的大小考虑等
测试参考:
https://docs.confluent.io/current/installation/installing_cp.html
https://docs.confluent.io/current/connect/connect-elasticsearch/docs/elasticsearch_connector.html
https://docs.confluent.io/current/connect/connect-elasticsearch/docs/configuration_options.html
存储机制参考 https://blog.csdn.net/opensure/article/details/46048589
kafka 配置参数参考 https://blog.csdn.net/lizhitao/article/details/25667831
更多 kafka 原理 https://blog.csdn.net/ychenfeng/article/details/74980531
confluent CLI:
confluent: A command line interface to manage Confluent services
Usage: confluent <command> [<subcommand>] [<parameters>]
These are the available commands:
acl Specify acl for a service.
config Configure a connector.
current Get the path of the data and logs of the services managed by the current confluent run.
destroy Delete the data and logs of the current confluent run.
list List available services.
load Load a connector.
log Read or tail the log of a service.
start Start all services or a specific service along with its dependencies
status Get the status of all services or the status of a specific service along with its dependencies.
stop Stop all services or a specific service along with the services depending on it.
top Track resource usage of a service.
unload Unload a connector.
''confluent help'' lists available commands. See ''confluent help <command>'' to read about a
specific command.confluent platform 服务端口表

参考

Centos7+kafka+ELK6.5.x安装搭建
Centos7+kafka+ELK6.5.x安装搭建
1 数据的流向
数据源端使用logstash收集udp 514日志输出到kafka中做测试(可选择filebeat,比较轻量级、对CPU负载不大、不占用太多资源;选择rsyslog对 kafka的支持是 v8.7.0版本及之后版本)。如下流程:
logstash(udp 514) => kafka(zookeeper) 集群=> logstash(grok) => elasticsearch集群 => kibana
Logstash(grok)因每条日志需做正则匹配比较消耗资源,所以中间加了kafka(zookeeper)集群做消息队列。
2 数据源端配置
2.1 安装Logstash(udp 514)
1) 安装jdk
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
2) yum安装logstash
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cat >> /etc/yum.repos.d/logstash-6.x.repo << ''EOF''
[logstash-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
yum install -y logstash
3) 配置
修改内存大小
vim /etc/logstash/jvm.options
-Xms2g
-Xmx2g
cp /etc/logstash/logstash-sample.conf /etc/logstash/conf.d/logstash514.conf
vim /etc/logstash/conf.d/logstash514.conf
#############################
input {
syslog {
type => "syslog"
port => "514"
}
}
output {
kafka {
codec => "json" #一定要加上,不然输出没有host等字段
bootstrap_servers => "192.168.89.11:9092,192.168.89.12:9092,192.168.89.13:9092"
topic_id => "SyslogTopic"
}
}
#############################
4) 测试配置
/usr/share/logstash/bin/logstash --path.settings /etc/logstash/ -t
-t: 测试配置文件
--path.settings: 单独测试需要指定配置文件路径,否则会找不到配置
5) 启动logstash并设置开机启动(配置好zookeeper+kafka再启动)
Logstash监听小于1024的端口号使用logstash权限启动会失败,需要修改root权限启动
vim /etc/systemd/system/logstash.service #修改以下两项
##################
User=root
Group=root
##################
启动服务
systemctl daemon-reload
systemctl start logstash
systemctl enable logstash
6) 可以使用logger生成日志
例:logger -n 服务器IP "日志信息"
3 收集端配置
3.1 安装zookeeper+kafka集群
请看https://www.cnblogs.com/longBlogs/p/10340251.html
4 安装logstash(grok)并配置重要数据写入mysql数据库
需要安装logstash-output-jdbc输出到mysql数据库(请看https://www.cnblogs.com/longBlogs/p/10340252.html)
4.1 安装logstash
安装步骤请参考“数据源端配置”-“安装Logstash(udp 514)”上的安装步骤
4.2 配置
1)设置日志匹配目录和格式
mkdir -p /data/logstash/patterns # 创建额外格式目录
自定义匹配类型
vim /data/logstash/patterns/logstash_grok
============================================
#num formats
num [1][0-9]{9,} #匹配1开头至少10位的数字
=================================================
2)配置logstash(grok):
修改内存大小
vim /etc/logstash/jvm.options
-Xms2g
-Xmx2g
配置conf文件
cp /etc/logstash/logstash-sample.conf /etc/logstash/conf.d/logstash_syslog.conf
vim /etc/logstash/conf.d/logstash514.conf
#############################
input {
kafka {
bootstrap_servers => "192.168.89.11:9092,192.168.89.12:9092,192.168.89.13:9092"
topics => "SyslogTopic"
codec => "json" #一定要加上,不然输出没有host等字段
group_id => "logstash_kafka" #多个logstash消费要相同group_id,不然会重复消费
client_id => "logstash00" #client_id唯一
consumer_threads => 3 #线程数
}
}
filter {
grok {
patterns_dir => ["/data/logstash/patterns/"]
match => {
"message" => ".*?%{NUM:num}.*?"
}
}
}
#输出到elasticsearch
#这里不输出到mysql ,把输出到mysql注释掉
output {
elasticsearch {
hosts => ["192.168.89.20:9200","192.168.89.21:9200"] #是集群可写多个
index => "log-%{+YYYY.MM.dd}" # 按日期分index,-前面必须小写
}
#jdbc {
#driver_jar_path => "/etc/logstash/jdbc/mysql-connector-java-5.1.47/mysql-connector-java-5.1.47-bin.jar"
#driver_class => "com.mysql.jdbc.Driver"
#connection_string => "jdbc:mysql://mysql服务器ip:端口/数据库?user=数据库用户名&password=数据库密码"
#statement => [ "insert into 数据表 (TIME ,IP,MESSAGES) values (?,?,?)","%{@timestamp}" ,"%{host}","%{message}" ]
#}
}
################################################
3)启动logstash并设置开机启动(配置好elasticsearch再启动)
如果Logstash监听小于1024的端口号使用logstash权限启动会失败,需要修改root权限启动
vim /etc/systemd/system/logstash.service #修改以下两项
##################
User=root
Group=root
##################
启动服务
systemctl daemon-reload
systemctl start logstash
systemctl enable logstash
5 elasticsearch数据库端配置
5.1 安装elasticsearch(192.168.89.20与192.168.89.21)
1) 安装java环境
yum install –y java-1.8.0-openjdk java-1.8.0-openjdk-devel
2) 设置yum源
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cat >> /etc/yum.repos.d/elasticsearch-6.x.repo << ''EOF''
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
3) 安装
yum install -y elasticsearch
4) 配置
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: syslog_elasticsearch # 集群名称,同一集群需要一致
node.name: es_89.20 # 节点名称,同一集群不同主机不能一致
path.data: /data/elasticsearch # 数据存放目录
path.logs: /data/elasticsearch/log # 日志存放目录
network.host: 0.0.0.0 # 绑定ip
discovery.zen.ping.unicast.hosts: ["192.168.89.20", "192.168.89.21"] # 集群成员,不指定host.master则是自由选举
#discovery.zen.minimum_master_nodes: 1 # 这个参数默认值1,控制的是,一个节点需要看到的具有master节点资格的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量(情况是3,这个参数设置为2,但对于只有2个节点的情况,设置为2就有些问题了,一个节点DOWN掉后,你肯定连不上2台服务器了,这点需要注意)。
修改了elasticsearch.yml的data、log等目录,请在这里也修改
#vim /usr/lib/systemd/system/elasticsearch.service
LimitMEMLOCK=infinity
#systemctl daemon-reload
5) 创建目录并属主、属组为一个非root账户,否则启动会有以下错误
mkdir -p /data/elasticsearch/log
出现报错:
main ERROR Unable to create file /data/log/elasticsearch/syslog_elasticsearch.log java.io.IOException: Permission denied
将ElasticSearch的安装目录及其子目录改为另外一个非root账户
chown -R elasticsearch:elasticsearch /data/elasticsearch/
6) 启动
systemctl restart elasticsearch
systemctl enable elasticsearch
7) 测试
- 查询集群状态方法1
curl -XGET ''http://192.168.89.20:9200/_cat/nodes''

后面添加?v代表详细
curl -XGET ''http://192.168.89.20:9200/_cat/nodes?v''

- 查询集群状态方法2
curl -XGET ''http://192.168.89.20:9200/_cluster/state/nodes?pretty''
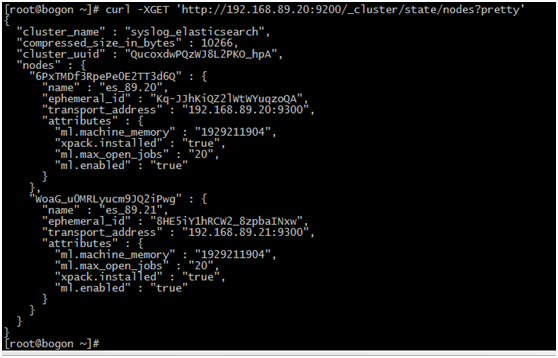
- 查询集群健康状况

6 分析展示端配置
6.1 安装kibana
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cat >> /etc/yum.repos.d/kibana-6.x.repo << ''EOF''
[kibana-6.x]
name=Kibana repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
yum install -y kibana
配置文件
cat /etc/kibana/kibana.yml |egrep -v "^#|^$"
###############################################
server.port: 5601 #要使用5601端口,使用nginx转80端口访问
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.89.20:9200"
###############################################
systemctl start kibana
systemctl enable kibana
访问
http://192.168.89.15:5601
汉化
先停止服务
systemctl stop kibana
做汉化
github上有汉化的项目,地址:https://github.com/anbai-inc/Kibana_Hanization
yum install unzip
解压在kibana的安装目录
unzip Kibana_Hanization-master.zip
cd Kibana_Hanization-master
python main.py kibana安装目录(可以python main.py /)
启动服务
systemctl start kibana
6.2 安装nginx
nginx主要作用是添加登录密码,因为kibana并没有登录功能,除非es开启密码。
1) 安装
rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
yum install -y nginx
安装Apache密码生产工具:
yum install httpd-tools
2) 配置
生成密码文件:
mkdir -p /etc/nginx/passwd
htpasswd -c -b /etc/nginx/passwd/kibana.passwd admin admin
cp /etc/nginx/conf.d/default.conf /etc/nginx/conf.d/default.conf.backup
vim /etc/nginx/conf.d/default.conf
####################################
server {
listen 192.168.89.15:80;
server_name localhost;
auth_basic "Kibana Auth";
auth_basic_user_file /etc/nginx/passwd/kibana.passwd;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
proxy_pass http://127.0.0.1:5601;
proxy_redirect off;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
##################################
修改Kibana配置文件:
vim /etc/kibana/kibana.yml
server.host: "localhost"
重启服务
systemctl restart kibana
systemctl restart nginx
systemctl enable nginx
访问
http://192.168.89.15:80

Confluent kafka rest 实战
Confluent platform 是个什么东西?
是由 LinkedIn 开发出 Apache Kafka 的团队成员,基于这项技术创立了新公司 Confluent,Confluent 的产品也是围绕着 Kafka 做的。基本架构如下:
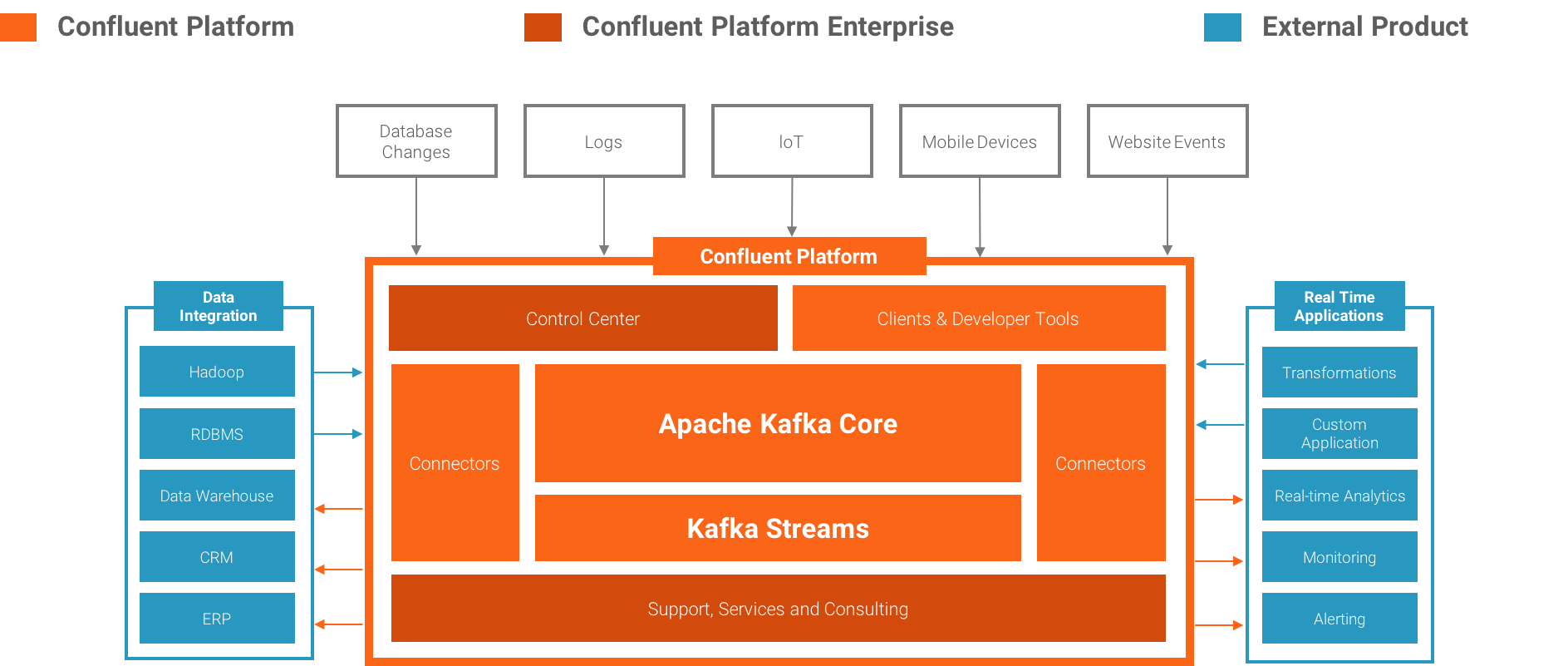
可以免费使用的组件:
Confluent Kafka Brokers (开源)
Confluent Kafka Connectors(开源)
Confluent Kafka Clients(开源)
Confluent Kafka REST Proxy(开源)
Confluent Schema Registry(开源)
我们的关注:
本次我们主要使用 REST Proxy,当然底层的 broker 也是使用 confluent 的 kafka 组件。
实验平台:CentOS release 6.7 (Final)
kafka 版本:confluent-kafka-2.11-0.10.1.0-1
rest proxy 版本:confluent-kafka-rest-3.1.1-1
添加 Yum 仓库:
本地添加 confluent 的 repo 仓库即可
[Confluent.dist]
name=Confluent repository (dist)
baseurl=http://packages.confluent.io/rpm/3.1/6
gpgcheck=1
gpgkey=http://packages.confluent.io/rpm/3.1/archive.key
enabled=1
[Confluent]
name=Confluent repository
baseurl=http://packages.confluent.io/rpm/3.1
gpgcheck=1
gpgkey=http://packages.confluent.io/rpm/3.1/archive.key
enabled=1安装:
yum clean all
yum makecache
yum install confluent-kafka confluent-kafka-rest -y配置:
zookeeper:/etc/kafka/zookeeper.properties
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0kafka broker:/etc/kafka/server.properties
broker.id=50
delete.topic.enable=true
listeners=PLAINTEXT://10.205.51.50:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/var/lib/kafka
num.partitions=1
num.recovery.threads.per.data.dir=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.205.51.50:2181
zookeeper.connection.timeout.ms=6000
confluent.support.metrics.enable=true
confluent.support.customer.id=anonymousrest proxy:/etc/kafka-rest/kafka-rest.properties
id=kafka-rest-server
zookeeper.connect=10.205.51.50:2181schema registry:/etc/schema-registry/schema-registry.properties
listeners=http://0.0.0.0:8081
kafkastore.connection.url=10.205.51.50:2181
kafkastore.topic=_schemas
debug=false启动:
启动 zookeeper:
zookeeper-server-start -daemon /etc/kafka/zookeeper.properties 
启动 kafka broker
kafka-server-start -daemon /etc/kafka/server.properties 
启动 rest proxy
kafka-rest-start -daemon /etc/kafka-rest/kafka-rest.properties
启动 schema registry
schema-registry-start -daemon /etc/schema-registry/schema-registry.properties
实验过程:
rest proxy 支持 avro、json、binary 数据格式,本文以 avro、json 格式为例进行实战。
查看当前 topics:
curl http://10.205.51.50:8082/topics 
查看集群的 brokers:
curl http://10.205.51.50:8082/brokers 
创建 topic test2,存放 avro 格式的数据:
kafka-topics --create --zookeeper 10.205.51.50:2181 --partitions 1 --replication-factor 1 --topic test2
通过 rest 接口向 test2 push 数据:
curl -i -X POST -H "Content-Type: application/vnd.kafka.avro.v1+json" --data ''{"value_schema": "{\"type\": \"record\", \"name\": \"User\", \"fields\": [{\"name\": \"username\", \"type\": \"string\"}]}","records": [{"value": {"username": "testUser"}},{"value": {"username": "testUser2"}}]}'' http://10.205.51.50:8082/topics/test2
注册 consumer group:
curl -i -X POST -H "Content-Type: application/vnd.kafka.v1+json" --data ''{"format": "avro", "auto.offset.reset": "smallest"}'' http://10.205.51.50:8082/consumers/my_avro_consumer
通过 rest 接口消费数据:
curl -i -X GET -H "Accept: application/vnd.kafka.avro.v1+json" http://10.205.51.50:8082/consumers/my_avro_consumer/instances/rest-consumer-kafka-rest-server-25354850-1a4e-4503-bce2-75b9d9a6fd1a/topics/test2
删除注册的 consumer 实例:
curl -i -X DELETE http://10.205.51.50:8082/consumers/my_avro_consumer/instances/rest-consumer-kafka-rest-server-25354850-1a4e-4503-bce2-75b9d9a6fd1a
创建 topic test3,存放 json 格式的数据:
kafka-topics --create --zookeeper 10.205.51.50:2181 --topic test3 --replication-factor 1 --partitions 1
通过 rest 接口向 test3 push 数据:
curl -i -X POST -H "Content-Type: application/vnd.kafka.json.v1+json" --data ''{"records": [{"key": "somekey","value": {"foo": "bar"}},{"value": [ "foo", "bar" ],"partition": 0}]}'' http://10.205.51.50:8082/topics/test3
注册 consumer group:
curl -i -X POST -H "Content-Type: application/vnd.kafka.v1+json" --data ''{"name": "test3","format": "json", "auto.offset.reset": "smallest"}'' http://10.205.51.50:8082/consumers/my_json_consumer
通过 rest 接口消费数据:
curl -i -X GET -H "Accept: application/vnd.kafka.json.v1+json" http://10.205.51.50:8082/consumers/my_json_consumer/instances/test3/topics/test3
删除 consumer 实例
curl -i -X DELETE http://10.205.51.50:8082/consumers/my_json_consumer/instances/test3
可以看到整个过程还是比较麻烦的,依赖多个服务。

DataPipeline联合Confluent Kafka Meetup上海站

Confluent作为国际数据“流”处理技术领先者,提供实时数据处理解决方案,在市场上拥有大量企业客户,帮助企业轻松访问各类数据。DataPipeline作为国内首家原生支持Kafka解决方案的“iPaaS+AI”一站式大数据融合服务提供商,在零售、金融、互联网和制造等行业拥有着丰富实践经验和解决方案能力。
此次上海DataPipeline & Confluent Kafka Meetup,我们邀请到了Confluent流数据处理系统架构师和技术负责人王国璋、DataPipeline架构师吕鹏、携程大数据平台实时计算平台负责人潘国庆、阿里巴巴实时计算平台高级技术专家秦江杰、网易云大数据平台架构师欧阳武林等大数据领域六位行业大咖分享Kafka最新研究成果以及行业应用案例。
活动流程

演讲嘉宾

王国璋
Confluent流数据处理系统架构师和技术负责人
Apache Kafka PMC,Kafka Streams 作者。于康奈尔大学计算机系取得博士学位,主要研究方向为数据库管理和分布式数据系统。现就职于Confluent,任流数据处理系统架构师和技术负责人。此前曾就职于 LinkedIn 数据架构组,主要负责实时数据处理平台,包括 Apache Kafka 和 Apache Samza 系统的开发与维护。
演讲主题:《Apache Kafka,从0.7到2.0:那些年我们踩过的坑》
自从 2011年被捐献给Apache基金会到现在,Kafka项目已经走过了七个年头。从最早的“分布式消息系统”,到现在集成了分发、存储和计算的“流式数据平台”,Kafka经历了哪些挑战?又经过了什么样的演进变化?
1. 从硬件的发展趋势,展现 Kafka 架构的演进过程;
2. 从Kafka开发和维护经验,分享分布式系统工程实践的通理;
3. 开源数据系统的开发经验,如何维护和发展一个开源社区。

潘国庆
携程大数据平台实时计算平台负责人
携程大数据平台实时计算平台负责人,2016年加入携程,主要从事携程实时计算平台的构建与演进、以及携程实时特征平台的搭建,在实时计算领域拥有丰富的实战经验。
演讲主题:《携程实时计算平台架构与实践》
1. 携程实时计算平台的演进之路;
2. 实时架构设计与曾经踩过的坑;
3. 实时计算在携程的实践;
4. 未来规划。

吕鹏
DataPipeline 架构师
吕鹏,目前担任DataPipeline架构师一职,负责数据传输和ETL方面的架构和优化工作。曾就职于Talend和销售易大数据部,拥有5余年大数据平台和数据仓库架构搭建经验,在ETL 领域拥有丰富的实战经验。
演讲主题:《DataPipeline在大数据平台的实时数据流实践》
1. 大数据时代下企业级数据面临的主要问题和挑战;
2. kafka connect 在大数据时代的数据流的优势和不足;
3. 大数据平台上的kafka connect 实践案例:
1)kafka connect 下数据仓库greenplum 同步实践以及优化策略;
2)kafka connect 下 hive 同步实践;
4. DataPipeline 做了哪些大数据相关工作,遇到的坑以及相应的解决方案;
5. 总结以及DataPipeline 未来在大数据领域的相关工作。

张勇华
唯品会消息平台架构师
毕业于武汉大学,目前担任唯品会消息平台架构师。从事消息系统的设计和研发有4年多的时间,对Kafka、RabbitMQ、RocketMQ等消息中间件产品拥有较丰富的实践经验。
演讲主题:《基于Kafka1.0建立企业级消息系统平台的思考及实现》
1. 随着业务系统接入增多,对集群和元数据资源(Topic/Group)的管理显得尤为重要,急需建立统一平台来管理系统资源及认证授权接入服务;
2. 提升并发消费场景下的高可靠,及消费异常后如何优雅解决消费重试问题;
3. 如何实现延时消息的投递功能,改善延时精度的方式;
4. 原生kafka支持组间广播对动态增长的业务组申请造成困境,如何实现组内广播来改善现状;
5. 集群故障时如何快速有效迁移服务等问题介绍。

秦江杰
阿里巴巴实时计算平台高级技术专家
秦江杰,阿里巴巴实时计算平台高级技术专家。硕士毕业于卡耐基梅隆大学,曾任职于LinkedIn参与Apache Kafka开发,Apache Kafka PMC member。
演讲主题:《详解Flink基于Kafka事务的严格一次语义实现》
在流处理系统中,端到端的严格一次的语义只有当输出的Sink支持时才可以实现。在Kafka 0.11中增加了对事物的支持,使得其他系统可以利用这一特性实现严格一次的语义。本次分享将详细介绍Flink是如何利用这Kafka一特性来实现端到端的严格一次语义的。

欧阳武林
网易大数据平台架构师
曾就职于中国移动、51信用卡,主要从事云计算平台开发相关工作。目前就职于网易,主要从事大数据平台开发。
演讲主题:《Kafka 在网易云上的实践》
1.Kafka上云面临的挑战和机遇;
2.网易云Kafka架构实现;
3.网易云Kafka的关键问题解决之法;
4.未来规划。
时间&地点
时间:2018年10月21日,13:30签到
详细地址:上海市长宁区金钟路968号凌空SOHO12号楼11层
活动报名
添加DataPipeline君微信:datapipeline2018,拉你进现场活动群。
")
ELK - Fluentd 日志收集(官方文档 部署安装 配置文件 详解)
官网地址:
| 1 |
|
下载地址:
| 1 |
|
Fluentd文档地址:
| 1 |
|
Fluentd Bit文档地址:
| 1 |
|
Fluentd 和 Fluent Bit:
Fluentd 和 Fluent Bit 的区别在于Fluent Bit 适用于对资源需求非常敏感的情况下且没有依赖,更节省资源只要450KB的内存就可运行,缺点是插件少,只负责收集和转发。Fluentd 内存需求约为40M,拥有更丰富的插件,支持大吞吐量,多输入并路由到不同的输出。

可以查考部署的yaml文件:
fluentd-es-ds.yaml
| 1 |
|
fluent-bit-ds.yaml
| 1 |
|
安装前配置:
文件描述符:
| 1 2 3 4 5 6 |
|
查看:
| 1 |
|
sysctl.conf
| 1 2 3 |
|
查看:
| 1 |
|
安装Fluentd:
导入gpg key:
| 1 |
|
配置yum源:
| 1 2 3 4 5 6 7 |
|
安装:
| 1 |
|
启动:
| 1 |
|
测试:
| 1 2 3 |
|
配置:
source:定义输入,数据的来源,input方向。
match:定义输出,下一步的去向,如写入文件,或者发送到指定软件存储。output方向。
filter:定义过滤,也即事件处理流水线,一般在输入和输出之间运行,可减少字段,也可丰富信息。
system:系统级别的设置,如日志级别、进程名称。
label:定义一组操作,从而实现复用和内部路由。
@include:引入其他文件,和Java、python的import类似。
输出调试:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
收集Nginx日志配置:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
检查配置文件:
| 1 |
|
tag
tag的用作:Fluentd 内部路由引擎的方向。
tag的使用:<match tag>、<filter tag>,如:<match Nginx.web>、<filter Nginx.*>
语法:
*:匹配单个 tag 部分
例:a.*,匹配 a.b,但不匹配 a 或者 a.b.c
**:匹配 0 或 多个 tag 部分
例:a.**,匹配 a、a.b 和 a.b.c
{X,Y,Z}:匹配 X、Y 或 Z,其中 X、Y 和 Z 是匹配模式。可以和 * 和 ** 模式组合使用
例 1:{a, b},匹配 a 和 b,但不匹配 c
例 2:a.{b,c}. 和 a.{b,c.*}
多模式:当多个模式列在一个 <match> 标签(由一个或多个空格分隔)内时,它匹配任何列出的模式。
例如:
<match a b>:匹配 a 和 b
<match a.** b.*>:匹配 a、a.b、a.b.c 和 b.d
过滤插件
record_transformer:
将收集来的信息通过增删改的方式来处理,也就是说这个插件可以将收集来的信息往里面增加字段、删除字段、修改字段。这个插件内核中自带不用安装。
增加字段:下面这段配置中向原有的字段中增加了hostname 和 tag 两个字段。
| 1 2 3 4 5 6 7 |
|
由:
| 1 |
|
变为:
| 1 |
|
用法二:可在配置里面搞点计算,使用Ruby的语法。
| 1 2 3 4 5 6 7 |
|
由:
| 1 |
|
变为:
| 1 |
|
用法三:将tag中的第二部分值加入字段中。
| 1 2 3 4 5 6 |
|
由:
| 1 |
|
变为:
| 1 |
|
基本使用语法:
如果输入的记录为:{"total":100, "count":10}
我们可以在<record>标签里面使用 record["total"]=100,record["count"]=10 来取值。还有其他的值time、hostname等。
<record>
field: ${record["total"] / record["count"]}
tag: ${tag}
hostname "#{Socket.gethostname}"
</record>
<record>里面的键值必须是新的字段。
标签tag的用法:
tag_parts[N] 标签的第N部分
tag_prefix[N] 从开始到N的部分
tag_suffix[N] 从N到结尾的部分
例:标签为 debug.my.app
tag_prefix[0] = debug
tag_prefix[1] = debug.my
tag_prefix[2] = debug.my.app
tag_suffix[0] = debug.my.app
tag_suffix[1] = my.app
tag_suffix[2] = app
其他参数:record是在filter指令内的
| 1 2 3 4 5 6 7 8 |
|
parser:
解析器,解析日志,将日志格式化成json。
| 1 2 3 4 5 6 7 8 9 |
|
由:
| 1 2 3 4 |
|
解析为:
| 1 2 3 4 |
|
在<filter>中的可用参数:详见 https://docs.fluentd.org/filter/parser
本文转自:Fluentd 日志收集 来源:原创 时间:2019-08-08 作者:脚本小站 分类:Linux
今天关于ELK 学习笔记之基于 kakfa (confluent) 搭建 ELK和elk+kafka+filebeat的分享就到这里,希望大家有所收获,若想了解更多关于Centos7+kafka+ELK6.5.x安装搭建、Confluent kafka rest 实战、DataPipeline联合Confluent Kafka Meetup上海站、ELK - Fluentd 日志收集(官方文档 部署安装 配置文件 详解)等相关知识,可以在本站进行查询。
本文标签:




