在这里,我们将给大家分享关于在python中模拟按值传递行为的知识,让您更了解在python中模拟按值传递行为的方法的本质,同时也会涉及到如何更有效地python中的值传递和引用传递、python中,
在这里,我们将给大家分享关于在python中模拟按值传递行为的知识,让您更了解在python中模拟按值传递行为的方法的本质,同时也会涉及到如何更有效地python中的值传递和引用传递、python中,函数参数的传递是值传递还是引用传递?、Python多重处理:按值传递对象?、Python进阶:值传递,引用传递?不存在的,是赋值传递的内容。
本文目录一览:- 在python中模拟按值传递行为(在python中模拟按值传递行为的方法)
- python中的值传递和引用传递
- python中,函数参数的传递是值传递还是引用传递?
- Python多重处理:按值传递对象?
- Python进阶:值传递,引用传递?不存在的,是赋值传递
")
在python中模拟按值传递行为(在python中模拟按值传递行为的方法)
我想模拟python中的按值传递行为。换句话说,我想绝对确保我编写的函数不会修改用户提供的数据。
一种可能的方法是使用深层复制:
from copy import deepcopydef f(data): data = deepcopy(data) #do stuff有没有更有效或更 Python的 方法来实现此目标,对传递的对象进行尽可能少的假设(例如.clone()方法)
编辑
我知道技术上python中的所有内容都是按值传递的。我对 模拟
行为很感兴趣,即确保我不会弄乱传递给函数的数据。我猜最一般的方法是使用其自身的克隆机制或Deepcopy来克隆所讨论的对象。
答案1
小编典典没有Python的方法可以做到这一点。
Python提供很少的设施来 强制执行
诸如私有或只读数据之类的事情。python的哲学是“我们都是成年人”:在这种情况下,这意味着“该功能不应更改数据”是规范的一部分,但未在代码中强制执行。
如果要复制数据,则可以找到最接近的解决方案。但是copy.deepcopy,除了是低效的,也有注意事项,例如:
因为深层副本会复制所有内容,所以它可能会复制过多,例如,即使在副本之间也应共享的管理数据结构。
[…]
该模块不复制诸如模块,方法,堆栈跟踪,堆栈框架,文件,套接字,窗口,数组或任何类似类型的类型。
因此,仅当您知道您正在处理内置的Python类型或您自己的对象时(如果您可以通过定义__copy__/__deepcopy__特殊方法自定义复制行为,而无需定义自己的clone()方法),我才建议这样做。

python中的值传递和引用传递
Python中的变量是没有类型的,我们可以把它看做一个(*void)类型的指针,变量是可以指向任何对象的,而对象才是有类型的。
Python中的对象有可变对象(number,string,tuple等)和不可变对象之分(list,dict等)。
值传递(passl-by-value)过程中,被调函数的形式参数作为被调函数的局部变量处理,即在堆栈中开辟了内存空间以存放由主调函数放进来的实参的值,从而成为了实参的一个副本。值传递的特点是被调函数对形式参数的任何操作都是作为局部变量进行,不会影响主调函数的实参变量的值。(被调函数新开辟内存空间存放的是实参的副本值)
引用传递(pass-by-reference)过程中,被调函数的形式参数虽然也作为局部变量在堆栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,即通过堆栈中存放的地址访问主调函数中的实参变量。正因为如此,被调函数对形参做的任何操作都影响了主调函数中的实参变量。(被调函数新开辟内存空间存放的是实参的地址)
1. 不可变对象作为函数参数,相当于C语言的值传递。
1 def test(c):
2 print("test before ")
3 print(id(c)) #一开始传递进来的是对不可变数据类型a(数字类型)的引用
4 c += 2 #数字改变后有一个新的指针指向3所在内存空间,但原来指向2的指针a(内存地址空间依旧存在)未改变
5 print("test after ")
6 print(id(c)) #故c的内存地址改变
7 return c
8
9
10 if __name__ == "__main__":
11 a = 2
12 print(id(a))
13 n = test(a) #4
14 print(a) #2
15 print(id(a))1 最终
2 输出的值为
3 1547916096
4 test before
5 1547916096
6 test after
7 1547916160
8 2
9 1547916096
2. 可变对象作为函数参数,相当于C语言的引用传递。(因列表是可变数据类型,作为参数传递实则是传递对列表的引用,修改更新列表值后依旧引用不变)
1 def test(list2):
2 print("test before ")
3 print(id(list2)) #221
4 list2[1] = 30
5 print("test after ")
6 print(id(list2)) #221
7 return list2
8
9 if __name__ == "__main__":
10 list1 = ["loleina", 25, ''female'']
11 print(id(list1)) #221
12 list3 = test(list1)
13 print(list1) #["loleina",30, ''female'']
14 print(id(list1)) #221
15 print(id(list3))1 17192136
2 test before
3 17192136
4 test after
5 17192136
6 [''loleina'', 30, ''female'']
7 17192136
8 17192136

python中,函数参数的传递是值传递还是引用传递?
要理解上述问题,需要明白,在Python中一切皆对象。所以函数的参数在传递过程中,传递的都是对象的引用,而引用是指向内存中的地址的(id()查看的是当前变量的地址值)。
所以上述问题本身都不是特别的严谨,那么为什么还有上述的问题呢?我猜想面试想问的是:python中,函数参数为基本数据类型时,传递的是值传递还是引用传递?
这个是因为在实际使用时,不同的数据类型表现出来的现象是不一样的,但是本质上都是传递的是对象的引用。在实际使用时,因为不可变数据类型是不能改变其内存中的值的,所以表现出来的现象,好像是给不可变数据类型复制了一份再进行传递的,但事实上只是两个不同的变量指向了同一块内存中的地址而已。可变数据类型,因为其在内存中的值是可以改变的,所以在函数内改变可变数据类型的值,是会影响到函数外的变量,因为这两个参数是指向的同一块内存地址的。
题外话:python中,整型(int)值为0-256时是共享内存的(python3.6 windows7 | python3.5 ubuntu18.4 在上面环境上测试,256之后就不再共享地址了,其他机型不知道是不是这样 ),这样做有什么用呢?我的理解是:对于常用整型数据,可以节省内存开销。
l = [1, 2, 3]
t = (1, 2, 3)
b = 2
print(''id(l):{}''.format(id(l)))
print(''id(l[1]):{}''.format(id(l[1])))
print(''id(t[1]):{}''.format(id(t[1])))
print(''id(b):{}''.format(id(b)))
print(''--------------'')
def aaa():
l = [1, 2, 3]
t = (1, 2, 3)
b = 2
print(''id(l):{}''.format(id(l)))
print(''id(l[1]):{}''.format(id(l[1])))
print(''id(t[1]):{}''.format(id(t[1])))
print(''id(b):{}''.format(id(b)))
aaa()
第一次写博客,如果有写错的地方,请指教!
.jpg")

Python多重处理:按值传递对象?
我一直在尝试以下方法:
from multiprocessing import Pool
def f(some_list):
some_list.append(4)
print 'Child process: new list = ' + str(some_list)
return True
if __name__ == '__main__':
my_list = [1,2,3]
pool = Pool(processes=4)
result = pool.apply_async(f,[my_list])
result.get()
print 'Parent process: new list = ' + str(my_list)
我得到的是:
Child process: new list = [1,3,4]
Parent process: new list = [1,3]
因此,这意味着 my_list 是按值传递的,因为它没有突变。那么,是否将规则传递给另一个进程时确实按值传递规则呢?谢谢。

Python进阶:值传递,引用传递?不存在的,是赋值传递
Python的变量及其赋值
a = 1
b = a
print(id(a),id(b)) #140723344823328 140723344823328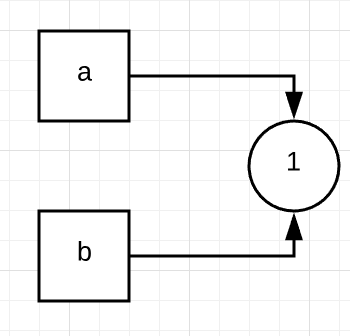
a = a + 1
print(b) #1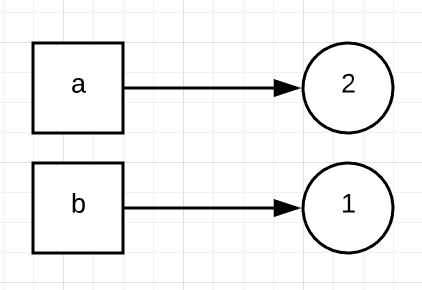
列表的例子
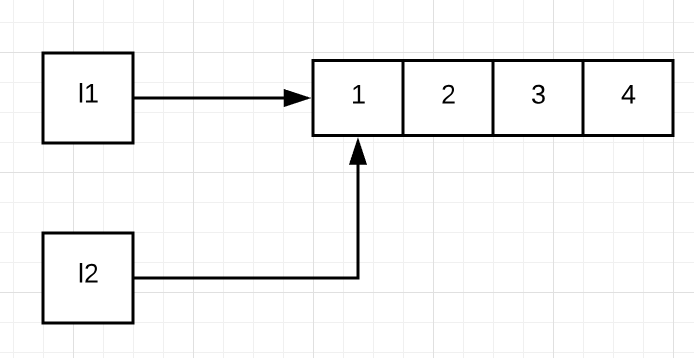
l1 = [1, 2, 3]
l2 = l1
l1.append(4)
print(l1) #[1, 2, 3, 4]
print(l2) #[1, 2, 3, 4]由于l1是可变类型,因此l1.append(4)不会创建新对象,会在原列表中插入4,而l1与l2都是指向这个列表,所以值都为[1,2,3,4]
l = [1, 2, 3]
del l #l被删除,对象[1,2,3]仍然存在Python 函数的参数传递
1)
def my_func1(b):
b = 2
a = 1
my_func1(a)
print(a) #1这里参数传递后 b与a 同时指向 值为1这个对象,接着b=2,系统建立2这个对象,并把b指向2,因此a还是指向值为1的对象
2) return让 a 指向 b指向的 值为2的对象def my_func2(b):
b = 2
return b
a = 1
a = my_func2(a)
print(a) #23)
def my_func3(l2):
l2.append(4)
l1 = [1, 2, 3]
my_func3(l1)
print(l1) #[1, 2, 3, 4]def my_func4(l2):
l2 = l2 + [4]
l1 = [1, 2, 3]
my_func4(l1)
print(l1)#[1, 2, 3]l2=l2+[4] 会创建一个新的列表对象[1,2,3,4]并把l2指向这个新对象,因此l1不会受影响
def my_func5(l2):
l2 = l2 + [4]
return l2
l1 = [1, 2, 3]
l1 = my_func5(l1)
print(l1) #[1, 2, 3, 4]第3)与第5的作用是一样的,但实际中一般会使用return语句,语义会更加清晰
总结
- Python中参数的传递既不是值传递,也不是引用传递,而是赋值传递,或者是叫对象的引用传递,指向一个具体的对象
- 如果对象是可变的,当其改变时,所有指向这个对象的变量都会改变。
- 如果对象不可变,简单的赋值只能改变其中一个变量的值,其余变量则不受影响。
参考
极客时间 《Python核心技术与实战》专栏
关于在python中模拟按值传递行为和在python中模拟按值传递行为的方法的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于python中的值传递和引用传递、python中,函数参数的传递是值传递还是引用传递?、Python多重处理:按值传递对象?、Python进阶:值传递,引用传递?不存在的,是赋值传递的相关信息,请在本站寻找。
本文标签:




