在本文中,我们将给您介绍关于在python中以特定顺序读取文件的详细内容,并且为您解答在python中以特定顺序读取文件的相关问题,此外,我们还将为您提供关于c#–特定顺序读取文件?、Errno13权
在本文中,我们将给您介绍关于在python中以特定顺序读取文件的详细内容,并且为您解答在python中以特定顺序读取文件的相关问题,此外,我们还将为您提供关于c# – 特定顺序读取文件?、Errno 13权限在python中读取文件时被拒绝、python 顺序读取文件夹下面的文件(自定义排序方式)、python-从文件的特定行中读取文件的知识。
本文目录一览:- 在python中以特定顺序读取文件(在python中以特定顺序读取文件)
- c# – 特定顺序读取文件?
- Errno 13权限在python中读取文件时被拒绝
- python 顺序读取文件夹下面的文件(自定义排序方式)
- python-从文件的特定行中读取文件
")
在python中以特定顺序读取文件(在python中以特定顺序读取文件)
可以说我在一个文件夹中有三个文件:file9.txt,file10.txt和file11.txt,我想按此特定顺序读取它们。谁能帮我这个?
现在我正在使用代码
import glob, osfor infile in glob.glob(os.path.join( ''*.txt'')): print "Current File Being Processed is: " + infile它先读取file10.txt,然后读取file11.txt,然后读取file9.txt。
有人可以帮助我如何获得正确的订单吗?
答案1
小编典典文件系统上的文件未排序。您可以使用sorted()函数自己对生成的文件名进行排序:
for infile in sorted(glob.glob(''*.txt'')): print "Current File Being Processed is: " + infile请注意,os.path.join您代码中的调用是无操作的;仅带有一个参数,它什么也不会做,只会使该参数保持不变。
请注意,您的文件将按字母顺序排序,该顺序位于10之前9。您可以使用自定义键功能来改善排序:
import renumbers = re.compile(r''(\d+)'')def numericalSort(value): parts = numbers.split(value) parts[1::2] = map(int, parts[1::2]) return parts for infile in sorted(glob.glob(''*.txt''), key=numericalSort): print "Current File Being Processed is: " + infile该numericalSort函数将文件名中的所有数字分开,将其转换为实际数字,然后返回结果进行排序:
>>> files = [''file9.txt'', ''file10.txt'', ''file11.txt'', ''32foo9.txt'', ''32foo10.txt'']>>> sorted(files)[''32foo10.txt'', ''32foo9.txt'', ''file10.txt'', ''file11.txt'', ''file9.txt'']>>> sorted(files, key=numericalSort)[''32foo9.txt'', ''32foo10.txt'', ''file9.txt'', ''file10.txt'', ''file11.txt'']
c# – 特定顺序读取文件?
DirectoryInfo directory = new DirectoryInfo(myPath);
FileInfo[] files = directory.GetFiles("*.txt");
所以我有一个包含所有文件的列表,我可以遍历它们(逐个阅读).
这样好吗?有没有办法重新排序列表,以便我始终在最顶层的最旧文件.这可能是一个很好的想法,因为我想开始阅读最旧的文件,最后是最新的文件.有任何想法吗?
解决方法
List<FileInfo> files = directory
.GetFiles("*.txt")
.OrderBy(f => f.LastWriteTime)
.ToList();
有关您可以订购的完整字段列表,请参阅FileInfo和FileSystemInfo.
这是VB.NET中的example

Errno 13权限在python中读取文件时被拒绝
如何解决Errno 13权限在python中读取文件时被拒绝?
我的文件夹清理包含7个文件,每个文件不包含。文档,但我的问题是权限被拒绝。 我想计算每个文件的概率 文件的概率=该文件的数量/ docs的数量
stemming = ''C:/Users/user/Desktop/Akhbarona''
with open(stemming,"r",encoding="utf-8") as auto:
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
")
python 顺序读取文件夹下面的文件(自定义排序方式)
我们在读取文件夹下面的文件时,有时是希望能够按照相应的顺序来读取,但是 file_lists=os.listdir()返回的文件名不一定是顺序的,也就是说结果是不固定的。就比如读取下面这些文件,希望能够按照图中的顺序进行读取,但是
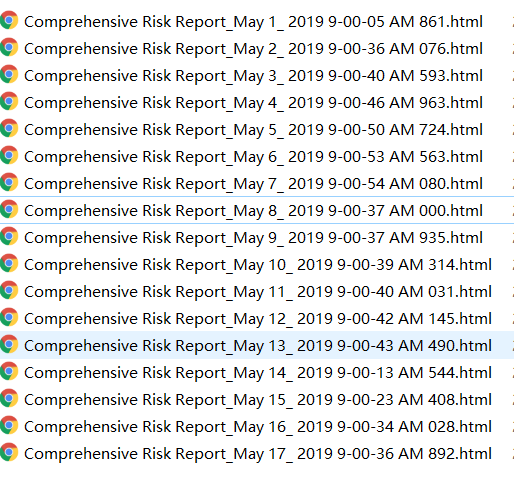
得到的结果却是这样:
[''Comprehensive Risk Report_May 10_ 2019 9-00-39 AM 314.html'',
''Comprehensive Risk Report_May 11_ 2019 9-00-40 AM 031.html'',
''Comprehensive Risk Report_May 12_ 2019 9-00-42 AM 145.html'',
''Comprehensive Risk Report_May 13_ 2019 9-00-43 AM 490.html'',
''Comprehensive Risk Report_May 14_ 2019 9-00-13 AM 544.html'',
''Comprehensive Risk Report_May 15_ 2019 9-00-23 AM 408.html'',
''Comprehensive Risk Report_May 16_ 2019 9-00-34 AM 028.html'',
''Comprehensive Risk Report_May 17_ 2019 9-00-36 AM 892.html'',
''Comprehensive Risk Report_May 1_ 2019 9-00-05 AM 861.html'',
''Comprehensive Risk Report_May 2_ 2019 9-00-36 AM 076.html'',
''Comprehensive Risk Report_May 3_ 2019 9-00-40 AM 593.html'',
''Comprehensive Risk Report_May 4_ 2019 9-00-46 AM 963.html'',
''Comprehensive Risk Report_May 5_ 2019 9-00-50 AM 724.html'',
''Comprehensive Risk Report_May 6_ 2019 9-00-53 AM 563.html'',
''Comprehensive Risk Report_May 7_ 2019 9-00-54 AM 080.html'',
''Comprehensive Risk Report_May 8_ 2019 9-00-37 AM 000.html'',
''Comprehensive Risk Report_May 9_ 2019 9-00-37 AM 935.html'']
而且在采用 file_lists.sort() 以及 sorted(file_lists()) 后,结果还是如此.
这是因为文件排序都是按字符串来的,不会特意给你分成数字,根据文件中字符在ascii码中的顺序,并且将字符串中每个字符作比较,得到结果。上面的 11和1_的问题,1相同,而后一位1在_前面,如果换成减号-那它就在1前面,或者将序号放在最后,那排序就正常了,这就是按中间字符排序会出现乱七八糟问题的原因
这时就需要自己根据文件自定义排序:
# 读取文件并进行排序
filelists = os.listdir(path)
sort_num_first = []
for file in filelists:
sort_num_first.append(int(file.split("_")[1].split(" ")[1])) # 根据 _ 分割,然后根据空格分割,转化为数字类型
sort_num_first.sort()
print(sort_num_first)
sorted_file = []
for sort_num in sort_num_first:
for file in filelists:
if str(sort_num) == file.split("_")[1].split(" ")[1]:
sorted_file .append(file)
思路很简单,就是把文件名根据 _ 和 空格 分割,得到中间的数字,然后进行排序;然后将排好的数字一一对应到相应的文件名,就得到了排好了的文件。

python-从文件的特定行中读取文件
我不是在谈论特定的行号,因为我正在读取具有相同格式但长度不同的多个文件。
说我有这个文本文件:
Something here...
... ... ...
Start #I want this block of text
a b c d e f g
h i j k l m n
End #until this line of the file
something here...
... ... ...
我希望你知道我的意思。我正在考虑遍历文件,然后使用正则表达式搜索以找到“开始”和“结束”的行号,然后使用线缓存从开始行读取到结束行。但是如何获得行号?我可以使用什么功能?
关于在python中以特定顺序读取文件和在python中以特定顺序读取文件的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于c# – 特定顺序读取文件?、Errno 13权限在python中读取文件时被拒绝、python 顺序读取文件夹下面的文件(自定义排序方式)、python-从文件的特定行中读取文件等相关内容,可以在本站寻找。
本文标签:




