针对org.apache.commons.lang.StringUtils这个问题,本篇文章进行了详细的解答,同时本文还将给你拓展apachecommonsStringUtils、apachecomm
针对org.apache.commons.lang.StringUtils这个问题,本篇文章进行了详细的解答,同时本文还将给你拓展apache commons StringUtils、apache commons StringUtils介绍、apache commons StringUtils工具类使用、Apache Commons 包 StringUtils 工具类深入整理等相关知识,希望可以帮助到你。
本文目录一览:- org.apache.commons.lang.StringUtils
- apache commons StringUtils
- apache commons StringUtils介绍
- apache commons StringUtils工具类使用
- Apache Commons 包 StringUtils 工具类深入整理

org.apache.commons.lang.StringUtils
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.commons.lang;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import java.util.Locale;
import org.apache.commons.lang.text.StrBuilder;
/**
* <p>Operations on {@link java.lang.String} that are
* <code>null</code> safe.</p>
*
* <ul>
* <li><b>IsEmpty/IsBlank</b>
* - checks if a String contains text</li>
* <li><b>Trim/Strip</b>
* - removes leading and trailing whitespace</li>
* <li><b>Equals</b>
* - compares two strings null-safe</li>
* <li><b>startsWith</b>
* - check if a String starts with a prefix null-safe</li>
* <li><b>endsWith</b>
* - check if a String ends with a suffix null-safe</li>
* <li><b>IndexOf/LastIndexOf/Contains</b>
* - null-safe index-of checks
* <li><b>IndexOfAny/LastIndexOfAny/IndexOfAnyBut/LastIndexOfAnyBut</b>
* - index-of any of a set of Strings</li>
* <li><b>ContainsOnly/ContainsNone/ContainsAny</b>
* - does String contains only/none/any of these characters</li>
* <li><b>Substring/Left/Right/Mid</b>
* - null-safe substring extractions</li>
* <li><b>SubstringBefore/SubstringAfter/SubstringBetween</b>
* - substring extraction relative to other strings</li>
* <li><b>Split/Join</b>
* - splits a String into an array of substrings and vice versa</li>
* <li><b>Remove/Delete</b>
* - removes part of a String</li>
* <li><b>Replace/Overlay</b>
* - Searches a String and replaces one String with another</li>
* <li><b>Chomp/Chop</b>
* - removes the last part of a String</li>
* <li><b>LeftPad/RightPad/Center/Repeat</b>
* - pads a String</li>
* <li><b>UpperCase/LowerCase/SwapCase/Capitalize/Uncapitalize</b>
* - changes the case of a String</li>
* <li><b>CountMatches</b>
* - counts the number of occurrences of one String in another</li>
* <li><b>IsAlpha/IsNumeric/IsWhitespace/IsAsciiPrintable</b>
* - checks the characters in a String</li>
* <li><b>DefaultString</b>
* - protects against a null input String</li>
* <li><b>Reverse/ReverseDelimited</b>
* - reverses a String</li>
* <li><b>Abbreviate</b>
* - abbreviates a string using ellipsis</li>
* <li><b>Difference</b>
* - compares Strings and reports on their differences</li>
* <li><b>LevensteinDistance</b>
* - the number of changes needed to change one String into another</li>
* </ul>
*
* <p>The <code>StringUtils</code> class defines certain words related to
* String handling.</p>
*
* <ul>
* <li>null - <code>null</code></li>
* <li>empty - a zero-length string (<code>""</code>)</li>
* <li>space - the space character (<code>'' ''</code>, char 32)</li>
* <li>whitespace - the characters defined by {@link Character#isWhitespace(char)}</li>
* <li>trim - the characters <= 32 as in {@link String#trim()}</li>
* </ul>
*
* <p><code>StringUtils</code> handles <code>null</code> input Strings quietly.
* That is to say that a <code>null</code> input will return <code>null</code>.
* Where a <code>boolean</code> or <code>int</code> is being returned
* details vary by method.</p>
*
* <p>A side effect of the <code>null</code> handling is that a
* <code>NullPointerException</code> should be considered a bug in
* <code>StringUtils</code> (except for deprecated methods).</p>
*
* <p>Methods in this class give sample code to explain their operation.
* The symbol <code>*</code> is used to indicate any input including <code>null</code>.</p>
*
* <p>#ThreadSafe#</p>
* @see java.lang.String
* @author Apache Software Foundation
* @author <a href="http://jakarta.apache.org/turbine/">Apache Jakarta Turbine</a>
* @author <a href="mailto:jon@latchkey.com">Jon S. Stevens</a>
* @author Daniel L. Rall
* @author <a href="mailto:gcoladonato@yahoo.com">Greg Coladonato</a>
* @author <a href="mailto:ed@apache.org">Ed Korthof</a>
* @author <a href="mailto:rand_mcneely@yahoo.com">Rand McNeely</a>
* @author <a href="mailto:fredrik@westermarck.com">Fredrik Westermarck</a>
* @author Holger Krauth
* @author <a href="mailto:alex@purpletech.com">Alexander Day Chaffee</a>
* @author <a href="mailto:hps@intermeta.de">Henning P. Schmiedehausen</a>
* @author Arun Mammen Thomas
* @author Gary Gregory
* @author Phil Steitz
* @author Al Chou
* @author Michael Davey
* @author Reuben Sivan
* @author Chris Hyzer
* @author Scott Johnson
* @since 1.0
* @version $Id: StringUtils.java 1058365 2011-01-13 00:04:49Z niallp $
*/
//@Immutable
public class StringUtils {
// Performance testing notes (JDK 1.4, Jul03, scolebourne)
// Whitespace:
// Character.isWhitespace() is faster than WHITESPACE.indexOf()
// where WHITESPACE is a string of all whitespace characters
//
// Character access:
// String.charAt(n) versus toCharArray(), then array[n]
// String.charAt(n) is about 15% worse for a 10K string
// They are about equal for a length 50 string
// String.charAt(n) is about 4 times better for a length 3 string
// String.charAt(n) is best bet overall
//
// Append:
// String.concat about twice as fast as StringBuffer.append
// (not sure who tested this)
/**
* The empty String <code>""</code>.
* @since 2.0
*/
public static final String EMPTY = "";
/**
* Represents a failed index search.
* @since 2.1
*/
public static final int INDEX_NOT_FOUND = -1;
/**
* <p>The maximum size to which the padding constant(s) can expand.</p>
*/
private static final int PAD_LIMIT = 8192;
/**
* <p><code>StringUtils</code> instances should NOT be constructed in
* standard programming. Instead, the class should be used as
* <code>StringUtils.trim(" foo ");</code>.</p>
*
* <p>This constructor is public to permit tools that require a JavaBean
* instance to operate.</p>
*/
public StringUtils() {
super();
}
// Empty checks
//-----------------------------------------------------------------------
/**
* <p>Checks if a String is empty ("") or null.</p>
*
* <p>判断一个字符串是否为空,空格作非空处理.</p>
*
* <pre>
* StringUtils.isEmpty(null) = true
* StringUtils.isEmpty("") = true
* StringUtils.isEmpty(" ") = false
* StringUtils.isEmpty("bob") = false
* StringUtils.isEmpty(" bob ") = false
* </pre>
*
* <p>NOTE: This method changed in Lang version 2.0.
* It no longer trims the String.
* That functionality is available in isBlank().</p>
*
* @param str the String to check, may be null
* @return <code>true</code> if the String is empty or null
*/
public static boolean isEmpty(String str) {
return str == null || str.length() == 0;
}
/**
* <p>Checks if a String is not empty ("") and not null.</p>
*
* <p>判断一个字符串是否非空,空格作非空处理.</p>
*
* <pre>
* StringUtils.isNotEmpty(null) = false
* StringUtils.isNotEmpty("") = false
* StringUtils.isNotEmpty(" ") = true
* StringUtils.isNotEmpty("bob") = true
* StringUtils.isNotEmpty(" bob ") = true
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if the String is not empty and not null
*/
public static boolean isNotEmpty(String str) {
return !StringUtils.isEmpty(str);
}
/**
* <p>Checks if a String is whitespace, empty ("") or null.</p>
*
* <p>当testString为空,长度为零或者仅由空白字符(whitespace)组成时,返回True;否则返回False</p>
*
* <pre>
* StringUtils.isBlank(null) = true
* StringUtils.isBlank("") = true
* StringUtils.isBlank(" ") = true
* StringUtils.isBlank("bob") = false
* StringUtils.isBlank(" bob ") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if the String is null, empty or whitespace
* @since 2.0
*/
public static boolean isBlank(String str) {
int strLen;
if (str == null || (strLen = str.length()) == 0) {
return true;
}
for (int i = 0; i < strLen; i++) {
if ((Character.isWhitespace(str.charAt(i)) == false)) {
return false;
}
}
return true;
}
/**
* <p>Checks if a String is not empty (""), not null and not whitespace only.</p>
*
* <p>判断一个字符串是否非空,空格作空处理.</p>
*
* <pre>
* StringUtils.isNotBlank(null) = false
* StringUtils.isNotBlank("") = false
* StringUtils.isNotBlank(" ") = false
* StringUtils.isNotBlank("bob") = true
* StringUtils.isNotBlank(" bob ") = true
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if the String is
* not empty and not null and not whitespace
* @since 2.0
*/
public static boolean isNotBlank(String str) {
return !StringUtils.isBlank(str);
}
// Trim
//-----------------------------------------------------------------------
/**
* <p>Removes control characters (char <= 32) from both
* ends of this String, handling <code>null</code> by returning
* an empty String ("").</p>
*
* <pre>
* StringUtils.clean(null) = ""
* StringUtils.clean("") = ""
* StringUtils.clean("abc") = "abc"
* StringUtils.clean(" abc ") = "abc"
* StringUtils.clean(" ") = ""
* </pre>
*
* @see java.lang.String#trim()
* @param str the String to clean, may be null
* @return the trimmed text, never <code>null</code>
* @deprecated Use the clearer named {@link #trimToEmpty(String)}.
* Method will be removed in Commons Lang 3.0.
*/
public static String clean(String str) {
return str == null ? EMPTY : str.trim();
}
/**
* <p>Removes control characters (char <= 32) from both
* ends of this String, handling <code>null</code> by returning
* <code>null</code>.</p>
*
* <p>The String is trimmed using {@link String#trim()}.
* Trim removes start and end characters <= 32.
* To strip whitespace use {@link #strip(String)}.</p>
*
* <p>To trim your choice of characters, use the
* {@link #strip(String, String)} methods.</p>
*
* <pre>
* StringUtils.trim(null) = null
* StringUtils.trim("") = ""
* StringUtils.trim(" ") = ""
* StringUtils.trim("abc") = "abc"
* StringUtils.trim(" abc ") = "abc"
* </pre>
*
* @param str the String to be trimmed, may be null
* @return the trimmed string, <code>null</code> if null String input
*/
public static String trim(String str) {
return str == null ? null : str.trim();
}
/**
* <p>Removes control characters (char <= 32) from both
* ends of this String returning <code>null</code> if the String is
* empty ("") after the trim or if it is <code>null</code>.
*
* <p>The String is trimmed using {@link String#trim()}.
* Trim removes start and end characters <= 32.
* To strip whitespace use {@link #stripToNull(String)}.</p>
*
* <p>清除掉testString首尾的空白字符,如果仅testString全由空白字符(whitespace)组成则返回null</p>
*
* <pre>
* StringUtils.trimToNull(null) = null
* StringUtils.trimToNull("") = null
* StringUtils.trimToNull(" ") = null
* StringUtils.trimToNull("abc") = "abc"
* StringUtils.trimToNull(" abc ") = "abc"
* </pre>
*
* @param str the String to be trimmed, may be null
* @return the trimmed String,
* <code>null</code> if only chars <= 32, empty or null String input
* @since 2.0
*/
public static String trimToNull(String str) {
String ts = trim(str);
return isEmpty(ts) ? null : ts;
}
/**
* <p>Removes control characters (char <= 32) from both
* ends of this String returning an empty String ("") if the String
* is empty ("") after the trim or if it is <code>null</code>.
*
* <p>The String is trimmed using {@link String#trim()}.
* Trim removes start and end characters <= 32.
* To strip whitespace use {@link #stripToEmpty(String)}.</p>
*
* <pre>
* StringUtils.trimToEmpty(null) = ""
* StringUtils.trimToEmpty("") = ""
* StringUtils.trimToEmpty(" ") = ""
* StringUtils.trimToEmpty("abc") = "abc"
* StringUtils.trimToEmpty(" abc ") = "abc"
* </pre>
*
* @param str the String to be trimmed, may be null
* @return the trimmed String, or an empty String if <code>null</code> input
* @since 2.0
*/
public static String trimToEmpty(String str) {
return str == null ? EMPTY : str.trim();
}
// Stripping
//-----------------------------------------------------------------------
/**
* <p>Strips whitespace from the start and end of a String.</p>
*
* <p>This is similar to {@link #trim(String)} but removes whitespace.
* Whitespace is defined by {@link Character#isWhitespace(char)}.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.strip(null) = null
* StringUtils.strip("") = ""
* StringUtils.strip(" ") = ""
* StringUtils.strip("abc") = "abc"
* StringUtils.strip(" abc") = "abc"
* StringUtils.strip("abc ") = "abc"
* StringUtils.strip(" abc ") = "abc"
* StringUtils.strip(" ab c ") = "ab c"
* </pre>
*
* @param str the String to remove whitespace from, may be null
* @return the stripped String, <code>null</code> if null String input
*/
public static String strip(String str) {
return strip(str, null);
}
/**
* <p>Strips whitespace from the start and end of a String returning
* <code>null</code> if the String is empty ("") after the strip.</p>
*
* <p>This is similar to {@link #trimToNull(String)} but removes whitespace.
* Whitespace is defined by {@link Character#isWhitespace(char)}.</p>
*
* <pre>
* StringUtils.stripToNull(null) = null
* StringUtils.stripToNull("") = null
* StringUtils.stripToNull(" ") = null
* StringUtils.stripToNull("abc") = "abc"
* StringUtils.stripToNull(" abc") = "abc"
* StringUtils.stripToNull("abc ") = "abc"
* StringUtils.stripToNull(" abc ") = "abc"
* StringUtils.stripToNull(" ab c ") = "ab c"
* </pre>
*
* @param str the String to be stripped, may be null
* @return the stripped String,
* <code>null</code> if whitespace, empty or null String input
* @since 2.0
*/
public static String stripToNull(String str) {
if (str == null) {
return null;
}
str = strip(str, null);
return str.length() == 0 ? null : str;
}
/**
* <p>Strips whitespace from the start and end of a String returning
* an empty String if <code>null</code> input.</p>
*
* <p>This is similar to {@link #trimToEmpty(String)} but removes whitespace.
* Whitespace is defined by {@link Character#isWhitespace(char)}.</p>
*
* <pre>
* StringUtils.stripToEmpty(null) = ""
* StringUtils.stripToEmpty("") = ""
* StringUtils.stripToEmpty(" ") = ""
* StringUtils.stripToEmpty("abc") = "abc"
* StringUtils.stripToEmpty(" abc") = "abc"
* StringUtils.stripToEmpty("abc ") = "abc"
* StringUtils.stripToEmpty(" abc ") = "abc"
* StringUtils.stripToEmpty(" ab c ") = "ab c"
* </pre>
*
* @param str the String to be stripped, may be null
* @return the trimmed String, or an empty String if <code>null</code> input
* @since 2.0
*/
public static String stripToEmpty(String str) {
return str == null ? EMPTY : strip(str, null);
}
/**
* <p>Strips any of a set of characters from the start and end of a String.
* This is similar to {@link String#trim()} but allows the characters
* to be stripped to be controlled.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* An empty string ("") input returns the empty string.</p>
*
* <p>If the stripChars String is <code>null</code>, whitespace is
* stripped as defined by {@link Character#isWhitespace(char)}.
* Alternatively use {@link #strip(String)}.</p>
*
* <pre>
* StringUtils.strip(null, *) = null
* StringUtils.strip("", *) = ""
* StringUtils.strip("abc", null) = "abc"
* StringUtils.strip(" abc", null) = "abc"
* StringUtils.strip("abc ", null) = "abc"
* StringUtils.strip(" abc ", null) = "abc"
* StringUtils.strip(" abcyx", "xyz") = " abc"
* </pre>
*
* @param str the String to remove characters from, may be null
* @param stripChars the characters to remove, null treated as whitespace
* @return the stripped String, <code>null</code> if null String input
*/
public static String strip(String str, String stripChars) {
if (isEmpty(str)) {
return str;
}
str = stripStart(str, stripChars);
return stripEnd(str, stripChars);
}
/**
* <p>Strips any of a set of characters from the start of a String.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* An empty string ("") input returns the empty string.</p>
*
* <p>If the stripChars String is <code>null</code>, whitespace is
* stripped as defined by {@link Character#isWhitespace(char)}.</p>
*
* <pre>
* StringUtils.stripStart(null, *) = null
* StringUtils.stripStart("", *) = ""
* StringUtils.stripStart("abc", "") = "abc"
* StringUtils.stripStart("abc", null) = "abc"
* StringUtils.stripStart(" abc", null) = "abc"
* StringUtils.stripStart("abc ", null) = "abc "
* StringUtils.stripStart(" abc ", null) = "abc "
* StringUtils.stripStart("yxabc ", "xyz") = "abc "
* </pre>
*
* @param str the String to remove characters from, may be null
* @param stripChars the characters to remove, null treated as whitespace
* @return the stripped String, <code>null</code> if null String input
*/
public static String stripStart(String str, String stripChars) {
int strLen;
if (str == null || (strLen = str.length()) == 0) {
return str;
}
int start = 0;
if (stripChars == null) {
while ((start != strLen) && Character.isWhitespace(str.charAt(start))) {
start++;
}
} else if (stripChars.length() == 0) {
return str;
} else {
while ((start != strLen) && (stripChars.indexOf(str.charAt(start)) != INDEX_NOT_FOUND)) {
start++;
}
}
return str.substring(start);
}
/**
* <p>Strips any of a set of characters from the end of a String.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* An empty string ("") input returns the empty string.</p>
*
* <p>If the stripChars String is <code>null</code>, whitespace is
* stripped as defined by {@link Character#isWhitespace(char)}.</p>
*
* <pre>
* StringUtils.stripEnd(null, *) = null
* StringUtils.stripEnd("", *) = ""
* StringUtils.stripEnd("abc", "") = "abc"
* StringUtils.stripEnd("abc", null) = "abc"
* StringUtils.stripEnd(" abc", null) = " abc"
* StringUtils.stripEnd("abc ", null) = "abc"
* StringUtils.stripEnd(" abc ", null) = " abc"
* StringUtils.stripEnd(" abcyx", "xyz") = " abc"
* StringUtils.stripEnd("120.00", ".0") = "12"
* </pre>
*
* @param str the String to remove characters from, may be null
* @param stripChars the set of characters to remove, null treated as whitespace
* @return the stripped String, <code>null</code> if null String input
*/
public static String stripEnd(String str, String stripChars) {
int end;
if (str == null || (end = str.length()) == 0) {
return str;
}
if (stripChars == null) {
while ((end != 0) && Character.isWhitespace(str.charAt(end - 1))) {
end--;
}
} else if (stripChars.length() == 0) {
return str;
} else {
while ((end != 0) && (stripChars.indexOf(str.charAt(end - 1)) != INDEX_NOT_FOUND)) {
end--;
}
}
return str.substring(0, end);
}
// StripAll
//-----------------------------------------------------------------------
/**
* <p>Strips whitespace from the start and end of every String in an array.
* Whitespace is defined by {@link Character#isWhitespace(char)}.</p>
*
* <p>A new array is returned each time, except for length zero.
* A <code>null</code> array will return <code>null</code>.
* An empty array will return itself.
* A <code>null</code> array entry will be ignored.</p>
*
* <pre>
* StringUtils.stripAll(null) = null
* StringUtils.stripAll([]) = []
* StringUtils.stripAll(["abc", " abc"]) = ["abc", "abc"]
* StringUtils.stripAll(["abc ", null]) = ["abc", null]
* </pre>
*
* @param strs the array to remove whitespace from, may be null
* @return the stripped Strings, <code>null</code> if null array input
*/
public static String[] stripAll(String[] strs) {
return stripAll(strs, null);
}
/**
* <p>Strips any of a set of characters from the start and end of every
* String in an array.</p>
* Whitespace is defined by {@link Character#isWhitespace(char)}.</p>
*
* <p>A new array is returned each time, except for length zero.
* A <code>null</code> array will return <code>null</code>.
* An empty array will return itself.
* A <code>null</code> array entry will be ignored.
* A <code>null</code> stripChars will strip whitespace as defined by
* {@link Character#isWhitespace(char)}.</p>
*
* <pre>
* StringUtils.stripAll(null, *) = null
* StringUtils.stripAll([], *) = []
* StringUtils.stripAll(["abc", " abc"], null) = ["abc", "abc"]
* StringUtils.stripAll(["abc ", null], null) = ["abc", null]
* StringUtils.stripAll(["abc ", null], "yz") = ["abc ", null]
* StringUtils.stripAll(["yabcz", null], "yz") = ["abc", null]
* </pre>
*
* @param strs the array to remove characters from, may be null
* @param stripChars the characters to remove, null treated as whitespace
* @return the stripped Strings, <code>null</code> if null array input
*/
public static String[] stripAll(String[] strs, String stripChars) {
int strsLen;
if (strs == null || (strsLen = strs.length) == 0) {
return strs;
}
String[] newArr = new String[strsLen];
for (int i = 0; i < strsLen; i++) {
newArr[i] = strip(strs[i], stripChars);
}
return newArr;
}
// Equals
//-----------------------------------------------------------------------
/**
* <p>Compares two Strings, returning <code>true</code> if they are equal.</p>
*
* <p><code>null</code>s are handled without exceptions. Two <code>null</code>
* references are considered to be equal. The comparison is case sensitive.</p>
*
* <pre>
* StringUtils.equals(null, null) = true
* StringUtils.equals(null, "abc") = false
* StringUtils.equals("abc", null) = false
* StringUtils.equals("abc", "abc") = true
* StringUtils.equals("abc", "ABC") = false
* </pre>
*
* @see java.lang.String#equals(Object)
* @param str1 the first String, may be null
* @param str2 the second String, may be null
* @return <code>true</code> if the Strings are equal, case sensitive, or
* both <code>null</code>
*/
public static boolean equals(String str1, String str2) {
return str1 == null ? str2 == null : str1.equals(str2);
}
/**
* <p>Compares two Strings, returning <code>true</code> if they are equal ignoring
* the case.</p>
*
* <p><code>null</code>s are handled without exceptions. Two <code>null</code>
* references are considered equal. Comparison is case insensitive.</p>
*
* <pre>
* StringUtils.equalsIgnoreCase(null, null) = true
* StringUtils.equalsIgnoreCase(null, "abc") = false
* StringUtils.equalsIgnoreCase("abc", null) = false
* StringUtils.equalsIgnoreCase("abc", "abc") = true
* StringUtils.equalsIgnoreCase("abc", "ABC") = true
* </pre>
*
* @see java.lang.String#equalsIgnoreCase(String)
* @param str1 the first String, may be null
* @param str2 the second String, may be null
* @return <code>true</code> if the Strings are equal, case insensitive, or
* both <code>null</code>
*/
public static boolean equalsIgnoreCase(String str1, String str2) {
return str1 == null ? str2 == null : str1.equalsIgnoreCase(str2);
}
// IndexOf
//-----------------------------------------------------------------------
/**
* <p>Finds the first index within a String, handling <code>null</code>.
* This method uses {@link String#indexOf(int)}.</p>
*
* <p>A <code>null</code> or empty ("") String will return <code>INDEX_NOT_FOUND (-1)</code>.</p>
*
* <pre>
* StringUtils.indexOf(null, *) = -1
* StringUtils.indexOf("", *) = -1
* StringUtils.indexOf("aabaabaa", ''a'') = 0
* StringUtils.indexOf("aabaabaa", ''b'') = 2
* </pre>
*
* @param str the String to check, may be null
* @param searchChar the character to find
* @return the first index of the search character,
* -1 if no match or <code>null</code> string input
* @since 2.0
*/
public static int indexOf(String str, char searchChar) {
if (isEmpty(str)) {
return INDEX_NOT_FOUND;
}
return str.indexOf(searchChar);
}
/**
* <p>Finds the first index within a String from a start position,
* handling <code>null</code>.
* This method uses {@link String#indexOf(int, int)}.</p>
*
* <p>A <code>null</code> or empty ("") String will return <code>(INDEX_NOT_FOUND) -1</code>.
* A negative start position is treated as zero.
* A start position greater than the string length returns <code>-1</code>.</p>
*
* <pre>
* StringUtils.indexOf(null, *, *) = -1
* StringUtils.indexOf("", *, *) = -1
* StringUtils.indexOf("aabaabaa", ''b'', 0) = 2
* StringUtils.indexOf("aabaabaa", ''b'', 3) = 5
* StringUtils.indexOf("aabaabaa", ''b'', 9) = -1
* StringUtils.indexOf("aabaabaa", ''b'', -1) = 2
* </pre>
*
* @param str the String to check, may be null
* @param searchChar the character to find
* @param startPos the start position, negative treated as zero
* @return the first index of the search character,
* -1 if no match or <code>null</code> string input
* @since 2.0
*/
public static int indexOf(String str, char searchChar, int startPos) {
if (isEmpty(str)) {
return INDEX_NOT_FOUND;
}
return str.indexOf(searchChar, startPos);
}
/**
* <p>Finds the first index within a String, handling <code>null</code>.
* This method uses {@link String#indexOf(String)}.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.indexOf(null, *) = -1
* StringUtils.indexOf(*, null) = -1
* StringUtils.indexOf("", "") = 0
* StringUtils.indexOf("", *) = -1 (except when * = "")
* StringUtils.indexOf("aabaabaa", "a") = 0
* StringUtils.indexOf("aabaabaa", "b") = 2
* StringUtils.indexOf("aabaabaa", "ab") = 1
* StringUtils.indexOf("aabaabaa", "") = 0
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @return the first index of the search String,
* -1 if no match or <code>null</code> string input
* @since 2.0
*/
public static int indexOf(String str, String searchStr) {
if (str == null || searchStr == null) {
return INDEX_NOT_FOUND;
}
return str.indexOf(searchStr);
}
/**
* <p>Finds the n-th index within a String, handling <code>null</code>.
* This method uses {@link String#indexOf(String)}.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.ordinalIndexOf(null, *, *) = -1
* StringUtils.ordinalIndexOf(*, null, *) = -1
* StringUtils.ordinalIndexOf("", "", *) = 0
* StringUtils.ordinalIndexOf("aabaabaa", "a", 1) = 0
* StringUtils.ordinalIndexOf("aabaabaa", "a", 2) = 1
* StringUtils.ordinalIndexOf("aabaabaa", "b", 1) = 2
* StringUtils.ordinalIndexOf("aabaabaa", "b", 2) = 5
* StringUtils.ordinalIndexOf("aabaabaa", "ab", 1) = 1
* StringUtils.ordinalIndexOf("aabaabaa", "ab", 2) = 4
* StringUtils.ordinalIndexOf("aabaabaa", "", 1) = 0
* StringUtils.ordinalIndexOf("aabaabaa", "", 2) = 0
* </pre>
*
* <p>Note that ''head(String str, int n)'' may be implemented as: </p>
*
* <pre>
* str.substring(0, lastOrdinalIndexOf(str, "\n", n))
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @param ordinal the n-th <code>searchStr</code> to find
* @return the n-th index of the search String,
* <code>-1</code> (<code>INDEX_NOT_FOUND</code>) if no match or <code>null</code> string input
* @since 2.1
*/
public static int ordinalIndexOf(String str, String searchStr, int ordinal) {
return ordinalIndexOf(str, searchStr, ordinal, false);
}
/**
* <p>Finds the n-th index within a String, handling <code>null</code>.
* This method uses {@link String#indexOf(String)}.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.</p>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @param ordinal the n-th <code>searchStr</code> to find
* @param lastIndex true if lastOrdinalIndexOf() otherwise false if ordinalIndexOf()
* @return the n-th index of the search String,
* <code>-1</code> (<code>INDEX_NOT_FOUND</code>) if no match or <code>null</code> string input
*/
// Shared code between ordinalIndexOf(String,String,int) and lastOrdinalIndexOf(String,String,int)
private static int ordinalIndexOf(String str, String searchStr, int ordinal, boolean lastIndex) {
if (str == null || searchStr == null || ordinal <= 0) {
return INDEX_NOT_FOUND;
}
if (searchStr.length() == 0) {
return lastIndex ? str.length() : 0;
}
int found = 0;
int index = lastIndex ? str.length() : INDEX_NOT_FOUND;
do {
if(lastIndex) {
index = str.lastIndexOf(searchStr, index - 1);
} else {
index = str.indexOf(searchStr, index + 1);
}
if (index < 0) {
return index;
}
found++;
} while (found < ordinal);
return index;
}
/**
* <p>Finds the first index within a String, handling <code>null</code>.
* This method uses {@link String#indexOf(String, int)}.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A negative start position is treated as zero.
* An empty ("") search String always matches.
* A start position greater than the string length only matches
* an empty search String.</p>
*
* <pre>
* StringUtils.indexOf(null, *, *) = -1
* StringUtils.indexOf(*, null, *) = -1
* StringUtils.indexOf("", "", 0) = 0
* StringUtils.indexOf("", *, 0) = -1 (except when * = "")
* StringUtils.indexOf("aabaabaa", "a", 0) = 0
* StringUtils.indexOf("aabaabaa", "b", 0) = 2
* StringUtils.indexOf("aabaabaa", "ab", 0) = 1
* StringUtils.indexOf("aabaabaa", "b", 3) = 5
* StringUtils.indexOf("aabaabaa", "b", 9) = -1
* StringUtils.indexOf("aabaabaa", "b", -1) = 2
* StringUtils.indexOf("aabaabaa", "", 2) = 2
* StringUtils.indexOf("abc", "", 9) = 3
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @param startPos the start position, negative treated as zero
* @return the first index of the search String,
* -1 if no match or <code>null</code> string input
* @since 2.0
*/
public static int indexOf(String str, String searchStr, int startPos) {
if (str == null || searchStr == null) {
return INDEX_NOT_FOUND;
}
// JDK1.2/JDK1.3 have a bug, when startPos > str.length for "", hence
if (searchStr.length() == 0 && startPos >= str.length()) {
return str.length();
}
return str.indexOf(searchStr, startPos);
}
/**
* <p>Case in-sensitive find of the first index within a String.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A negative start position is treated as zero.
* An empty ("") search String always matches.
* A start position greater than the string length only matches
* an empty search String.</p>
*
* <pre>
* StringUtils.indexOfIgnoreCase(null, *) = -1
* StringUtils.indexOfIgnoreCase(*, null) = -1
* StringUtils.indexOfIgnoreCase("", "") = 0
* StringUtils.indexOfIgnoreCase("aabaabaa", "a") = 0
* StringUtils.indexOfIgnoreCase("aabaabaa", "b") = 2
* StringUtils.indexOfIgnoreCase("aabaabaa", "ab") = 1
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @return the first index of the search String,
* -1 if no match or <code>null</code> string input
* @since 2.5
*/
public static int indexOfIgnoreCase(String str, String searchStr) {
return indexOfIgnoreCase(str, searchStr, 0);
}
/**
* <p>Case in-sensitive find of the first index within a String
* from the specified position.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A negative start position is treated as zero.
* An empty ("") search String always matches.
* A start position greater than the string length only matches
* an empty search String.</p>
*
* <pre>
* StringUtils.indexOfIgnoreCase(null, *, *) = -1
* StringUtils.indexOfIgnoreCase(*, null, *) = -1
* StringUtils.indexOfIgnoreCase("", "", 0) = 0
* StringUtils.indexOfIgnoreCase("aabaabaa", "A", 0) = 0
* StringUtils.indexOfIgnoreCase("aabaabaa", "B", 0) = 2
* StringUtils.indexOfIgnoreCase("aabaabaa", "AB", 0) = 1
* StringUtils.indexOfIgnoreCase("aabaabaa", "B", 3) = 5
* StringUtils.indexOfIgnoreCase("aabaabaa", "B", 9) = -1
* StringUtils.indexOfIgnoreCase("aabaabaa", "B", -1) = 2
* StringUtils.indexOfIgnoreCase("aabaabaa", "", 2) = 2
* StringUtils.indexOfIgnoreCase("abc", "", 9) = 3
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @param startPos the start position, negative treated as zero
* @return the first index of the search String,
* -1 if no match or <code>null</code> string input
* @since 2.5
*/
public static int indexOfIgnoreCase(String str, String searchStr, int startPos) {
if (str == null || searchStr == null) {
return INDEX_NOT_FOUND;
}
if (startPos < 0) {
startPos = 0;
}
int endLimit = (str.length() - searchStr.length()) + 1;
if (startPos > endLimit) {
return INDEX_NOT_FOUND;
}
if (searchStr.length() == 0) {
return startPos;
}
for (int i = startPos; i < endLimit; i++) {
if (str.regionMatches(true, i, searchStr, 0, searchStr.length())) {
return i;
}
}
return INDEX_NOT_FOUND;
}
// LastIndexOf
//-----------------------------------------------------------------------
/**
* <p>Finds the last index within a String, handling <code>null</code>.
* This method uses {@link String#lastIndexOf(int)}.</p>
*
* <p>A <code>null</code> or empty ("") String will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.lastIndexOf(null, *) = -1
* StringUtils.lastIndexOf("", *) = -1
* StringUtils.lastIndexOf("aabaabaa", ''a'') = 7
* StringUtils.lastIndexOf("aabaabaa", ''b'') = 5
* </pre>
*
* @param str the String to check, may be null
* @param searchChar the character to find
* @return the last index of the search character,
* -1 if no match or <code>null</code> string input
* @since 2.0
*/
public static int lastIndexOf(String str, char searchChar) {
if (isEmpty(str)) {
return INDEX_NOT_FOUND;
}
return str.lastIndexOf(searchChar);
}
/**
* <p>Finds the last index within a String from a start position,
* handling <code>null</code>.
* This method uses {@link String#lastIndexOf(int, int)}.</p>
*
* <p>A <code>null</code> or empty ("") String will return <code>-1</code>.
* A negative start position returns <code>-1</code>.
* A start position greater than the string length searches the whole string.</p>
*
* <pre>
* StringUtils.lastIndexOf(null, *, *) = -1
* StringUtils.lastIndexOf("", *, *) = -1
* StringUtils.lastIndexOf("aabaabaa", ''b'', 8) = 5
* StringUtils.lastIndexOf("aabaabaa", ''b'', 4) = 2
* StringUtils.lastIndexOf("aabaabaa", ''b'', 0) = -1
* StringUtils.lastIndexOf("aabaabaa", ''b'', 9) = 5
* StringUtils.lastIndexOf("aabaabaa", ''b'', -1) = -1
* StringUtils.lastIndexOf("aabaabaa", ''a'', 0) = 0
* </pre>
*
* @param str the String to check, may be null
* @param searchChar the character to find
* @param startPos the start position
* @return the last index of the search character,
* -1 if no match or <code>null</code> string input
* @since 2.0
*/
public static int lastIndexOf(String str, char searchChar, int startPos) {
if (isEmpty(str)) {
return INDEX_NOT_FOUND;
}
return str.lastIndexOf(searchChar, startPos);
}
/**
* <p>Finds the last index within a String, handling <code>null</code>.
* This method uses {@link String#lastIndexOf(String)}.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.lastIndexOf(null, *) = -1
* StringUtils.lastIndexOf(*, null) = -1
* StringUtils.lastIndexOf("", "") = 0
* StringUtils.lastIndexOf("aabaabaa", "a") = 7
* StringUtils.lastIndexOf("aabaabaa", "b") = 5
* StringUtils.lastIndexOf("aabaabaa", "ab") = 4
* StringUtils.lastIndexOf("aabaabaa", "") = 8
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @return the last index of the search String,
* -1 if no match or <code>null</code> string input
* @since 2.0
*/
public static int lastIndexOf(String str, String searchStr) {
if (str == null || searchStr == null) {
return INDEX_NOT_FOUND;
}
return str.lastIndexOf(searchStr);
}
/**
* <p>Finds the n-th last index within a String, handling <code>null</code>.
* This method uses {@link String#lastIndexOf(String)}.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.lastOrdinalIndexOf(null, *, *) = -1
* StringUtils.lastOrdinalIndexOf(*, null, *) = -1
* StringUtils.lastOrdinalIndexOf("", "", *) = 0
* StringUtils.lastOrdinalIndexOf("aabaabaa", "a", 1) = 7
* StringUtils.lastOrdinalIndexOf("aabaabaa", "a", 2) = 6
* StringUtils.lastOrdinalIndexOf("aabaabaa", "b", 1) = 5
* StringUtils.lastOrdinalIndexOf("aabaabaa", "b", 2) = 2
* StringUtils.lastOrdinalIndexOf("aabaabaa", "ab", 1) = 4
* StringUtils.lastOrdinalIndexOf("aabaabaa", "ab", 2) = 1
* StringUtils.lastOrdinalIndexOf("aabaabaa", "", 1) = 8
* StringUtils.lastOrdinalIndexOf("aabaabaa", "", 2) = 8
* </pre>
*
* <p>Note that ''tail(String str, int n)'' may be implemented as: </p>
*
* <pre>
* str.substring(lastOrdinalIndexOf(str, "\n", n) + 1)
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @param ordinal the n-th last <code>searchStr</code> to find
* @return the n-th last index of the search String,
* <code>-1</code> (<code>INDEX_NOT_FOUND</code>) if no match or <code>null</code> string input
* @since 2.5
*/
public static int lastOrdinalIndexOf(String str, String searchStr, int ordinal) {
return ordinalIndexOf(str, searchStr, ordinal, true);
}
/**
* <p>Finds the first index within a String, handling <code>null</code>.
* This method uses {@link String#lastIndexOf(String, int)}.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A negative start position returns <code>-1</code>.
* An empty ("") search String always matches unless the start position is negative.
* A start position greater than the string length searches the whole string.</p>
*
* <pre>
* StringUtils.lastIndexOf(null, *, *) = -1
* StringUtils.lastIndexOf(*, null, *) = -1
* StringUtils.lastIndexOf("aabaabaa", "a", 8) = 7
* StringUtils.lastIndexOf("aabaabaa", "b", 8) = 5
* StringUtils.lastIndexOf("aabaabaa", "ab", 8) = 4
* StringUtils.lastIndexOf("aabaabaa", "b", 9) = 5
* StringUtils.lastIndexOf("aabaabaa", "b", -1) = -1
* StringUtils.lastIndexOf("aabaabaa", "a", 0) = 0
* StringUtils.lastIndexOf("aabaabaa", "b", 0) = -1
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @param startPos the start position, negative treated as zero
* @return the first index of the search String,
* -1 if no match or <code>null</code> string input
* @since 2.0
*/
public static int lastIndexOf(String str, String searchStr, int startPos) {
if (str == null || searchStr == null) {
return INDEX_NOT_FOUND;
}
return str.lastIndexOf(searchStr, startPos);
}
/**
* <p>Case in-sensitive find of the last index within a String.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A negative start position returns <code>-1</code>.
* An empty ("") search String always matches unless the start position is negative.
* A start position greater than the string length searches the whole string.</p>
*
* <pre>
* StringUtils.lastIndexOfIgnoreCase(null, *) = -1
* StringUtils.lastIndexOfIgnoreCase(*, null) = -1
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "A") = 7
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "B") = 5
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "AB") = 4
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @return the first index of the search String,
* -1 if no match or <code>null</code> string input
* @since 2.5
*/
public static int lastIndexOfIgnoreCase(String str, String searchStr) {
if (str == null || searchStr == null) {
return INDEX_NOT_FOUND;
}
return lastIndexOfIgnoreCase(str, searchStr, str.length());
}
/**
* <p>Case in-sensitive find of the last index within a String
* from the specified position.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A negative start position returns <code>-1</code>.
* An empty ("") search String always matches unless the start position is negative.
* A start position greater than the string length searches the whole string.</p>
*
* <pre>
* StringUtils.lastIndexOfIgnoreCase(null, *, *) = -1
* StringUtils.lastIndexOfIgnoreCase(*, null, *) = -1
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "A", 8) = 7
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "B", 8) = 5
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "AB", 8) = 4
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "B", 9) = 5
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "B", -1) = -1
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "A", 0) = 0
* StringUtils.lastIndexOfIgnoreCase("aabaabaa", "B", 0) = -1
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @param startPos the start position
* @return the first index of the search String,
* -1 if no match or <code>null</code> string input
* @since 2.5
*/
public static int lastIndexOfIgnoreCase(String str, String searchStr, int startPos) {
if (str == null || searchStr == null) {
return INDEX_NOT_FOUND;
}
if (startPos > (str.length() - searchStr.length())) {
startPos = str.length() - searchStr.length();
}
if (startPos < 0) {
return INDEX_NOT_FOUND;
}
if (searchStr.length() == 0) {
return startPos;
}
for (int i = startPos; i >= 0; i--) {
if (str.regionMatches(true, i, searchStr, 0, searchStr.length())) {
return i;
}
}
return INDEX_NOT_FOUND;
}
// Contains
//-----------------------------------------------------------------------
/**
* <p>Checks if String contains a search character, handling <code>null</code>.
* This method uses {@link String#indexOf(int)}.</p>
*
* <p>A <code>null</code> or empty ("") String will return <code>false</code>.</p>
*
* <pre>
* StringUtils.contains(null, *) = false
* StringUtils.contains("", *) = false
* StringUtils.contains("abc", ''a'') = true
* StringUtils.contains("abc", ''z'') = false
* </pre>
*
* @param str the String to check, may be null
* @param searchChar the character to find
* @return true if the String contains the search character,
* false if not or <code>null</code> string input
* @since 2.0
*/
public static boolean contains(String str, char searchChar) {
if (isEmpty(str)) {
return false;
}
return str.indexOf(searchChar) >= 0;
}
/**
* <p>Checks if String contains a search String, handling <code>null</code>.
* This method uses {@link String#indexOf(String)}.</p>
*
* <p>A <code>null</code> String will return <code>false</code>.</p>
*
* <pre>
* StringUtils.contains(null, *) = false
* StringUtils.contains(*, null) = false
* StringUtils.contains("", "") = true
* StringUtils.contains("abc", "") = true
* StringUtils.contains("abc", "a") = true
* StringUtils.contains("abc", "z") = false
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @return true if the String contains the search String,
* false if not or <code>null</code> string input
* @since 2.0
*/
public static boolean contains(String str, String searchStr) {
if (str == null || searchStr == null) {
return false;
}
return str.indexOf(searchStr) >= 0;
}
/**
* <p>Checks if String contains a search String irrespective of case,
* handling <code>null</code>. Case-insensitivity is defined as by
* {@link String#equalsIgnoreCase(String)}.
*
* <p>A <code>null</code> String will return <code>false</code>.</p>
*
* <pre>
* StringUtils.contains(null, *) = false
* StringUtils.contains(*, null) = false
* StringUtils.contains("", "") = true
* StringUtils.contains("abc", "") = true
* StringUtils.contains("abc", "a") = true
* StringUtils.contains("abc", "z") = false
* StringUtils.contains("abc", "A") = true
* StringUtils.contains("abc", "Z") = false
* </pre>
*
* @param str the String to check, may be null
* @param searchStr the String to find, may be null
* @return true if the String contains the search String irrespective of
* case or false if not or <code>null</code> string input
*/
public static boolean containsIgnoreCase(String str, String searchStr) {
if (str == null || searchStr == null) {
return false;
}
int len = searchStr.length();
int max = str.length() - len;
for (int i = 0; i <= max; i++) {
if (str.regionMatches(true, i, searchStr, 0, len)) {
return true;
}
}
return false;
}
// IndexOfAny chars
//-----------------------------------------------------------------------
/**
* <p>Search a String to find the first index of any
* character in the given set of characters.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A <code>null</code> or zero length search array will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.indexOfAny(null, *) = -1
* StringUtils.indexOfAny("", *) = -1
* StringUtils.indexOfAny(*, null) = -1
* StringUtils.indexOfAny(*, []) = -1
* StringUtils.indexOfAny("zzabyycdxx",[''z'',''a'']) = 0
* StringUtils.indexOfAny("zzabyycdxx",[''b'',''y'']) = 3
* StringUtils.indexOfAny("aba", [''z'']) = -1
* </pre>
*
* @param str the String to check, may be null
* @param searchChars the chars to search for, may be null
* @return the index of any of the chars, -1 if no match or null input
* @since 2.0
*/
public static int indexOfAny(String str, char[] searchChars) {
if (isEmpty(str) || ArrayUtils.isEmpty(searchChars)) {
return INDEX_NOT_FOUND;
}
int csLen = str.length();
int csLast = csLen - 1;
int searchLen = searchChars.length;
int searchLast = searchLen - 1;
for (int i = 0; i < csLen; i++) {
char ch = str.charAt(i);
for (int j = 0; j < searchLen; j++) {
if (searchChars[j] == ch) {
if (i < csLast && j < searchLast && CharUtils.isHighSurrogate(ch)) {
// ch is a supplementary character
if (searchChars[j + 1] == str.charAt(i + 1)) {
return i;
}
} else {
return i;
}
}
}
}
return INDEX_NOT_FOUND;
}
/**
* <p>Search a String to find the first index of any
* character in the given set of characters.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A <code>null</code> search string will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.indexOfAny(null, *) = -1
* StringUtils.indexOfAny("", *) = -1
* StringUtils.indexOfAny(*, null) = -1
* StringUtils.indexOfAny(*, "") = -1
* StringUtils.indexOfAny("zzabyycdxx", "za") = 0
* StringUtils.indexOfAny("zzabyycdxx", "by") = 3
* StringUtils.indexOfAny("aba","z") = -1
* </pre>
*
* @param str the String to check, may be null
* @param searchChars the chars to search for, may be null
* @return the index of any of the chars, -1 if no match or null input
* @since 2.0
*/
public static int indexOfAny(String str, String searchChars) {
if (isEmpty(str) || isEmpty(searchChars)) {
return INDEX_NOT_FOUND;
}
return indexOfAny(str, searchChars.toCharArray());
}
// ContainsAny
//-----------------------------------------------------------------------
/**
* <p>Checks if the String contains any character in the given
* set of characters.</p>
*
* <p>A <code>null</code> String will return <code>false</code>.
* A <code>null</code> or zero length search array will return <code>false</code>.</p>
*
* <pre>
* StringUtils.containsAny(null, *) = false
* StringUtils.containsAny("", *) = false
* StringUtils.containsAny(*, null) = false
* StringUtils.containsAny(*, []) = false
* StringUtils.containsAny("zzabyycdxx",[''z'',''a'']) = true
* StringUtils.containsAny("zzabyycdxx",[''b'',''y'']) = true
* StringUtils.containsAny("aba", [''z'']) = false
* </pre>
*
* @param str the String to check, may be null
* @param searchChars the chars to search for, may be null
* @return the <code>true</code> if any of the chars are found,
* <code>false</code> if no match or null input
* @since 2.4
*/
public static boolean containsAny(String str, char[] searchChars) {
if (isEmpty(str) || ArrayUtils.isEmpty(searchChars)) {
return false;
}
int csLength = str.length();
int searchLength = searchChars.length;
int csLast = csLength - 1;
int searchLast = searchLength - 1;
for (int i = 0; i < csLength; i++) {
char ch = str.charAt(i);
for (int j = 0; j < searchLength; j++) {
if (searchChars[j] == ch) {
if (CharUtils.isHighSurrogate(ch)) {
if (j == searchLast) {
// missing low surrogate, fine, like String.indexOf(String)
return true;
}
if (i < csLast && searchChars[j + 1] == str.charAt(i + 1)) {
return true;
}
} else {
// ch is in the Basic Multilingual Plane
return true;
}
}
}
}
return false;
}
/**
* <p>
* Checks if the String contains any character in the given set of characters.
* </p>
*
* <p>
* A <code>null</code> String will return <code>false</code>. A <code>null</code> search string will return
* <code>false</code>.
* </p>
*
* <pre>
* StringUtils.containsAny(null, *) = false
* StringUtils.containsAny("", *) = false
* StringUtils.containsAny(*, null) = false
* StringUtils.containsAny(*, "") = false
* StringUtils.containsAny("zzabyycdxx", "za") = true
* StringUtils.containsAny("zzabyycdxx", "by") = true
* StringUtils.containsAny("aba","z") = false
* </pre>
*
* @param str
* the String to check, may be null
* @param searchChars
* the chars to search for, may be null
* @return the <code>true</code> if any of the chars are found, <code>false</code> if no match or null input
* @since 2.4
*/
public static boolean containsAny(String str, String searchChars) {
if (searchChars == null) {
return false;
}
return containsAny(str, searchChars.toCharArray());
}
// IndexOfAnyBut chars
//-----------------------------------------------------------------------
/**
* <p>Search a String to find the first index of any
* character not in the given set of characters.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A <code>null</code> or zero length search array will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.indexOfAnyBut(null, *) = -1
* StringUtils.indexOfAnyBut("", *) = -1
* StringUtils.indexOfAnyBut(*, null) = -1
* StringUtils.indexOfAnyBut(*, []) = -1
* StringUtils.indexOfAnyBut("zzabyycdxx", new char[] {''z'', ''a''} ) = 3
* StringUtils.indexOfAnyBut("aba", new char[] {''z''} ) = 0
* StringUtils.indexOfAnyBut("aba", new char[] {''a'', ''b''} ) = -1
* </pre>
*
* @param str the String to check, may be null
* @param searchChars the chars to search for, may be null
* @return the index of any of the chars, -1 if no match or null input
* @since 2.0
*/
public static int indexOfAnyBut(String str, char[] searchChars) {
if (isEmpty(str) || ArrayUtils.isEmpty(searchChars)) {
return INDEX_NOT_FOUND;
}
int csLen = str.length();
int csLast = csLen - 1;
int searchLen = searchChars.length;
int searchLast = searchLen - 1;
outer:
for (int i = 0; i < csLen; i++) {
char ch = str.charAt(i);
for (int j = 0; j < searchLen; j++) {
if (searchChars[j] == ch) {
if (i < csLast && j < searchLast && CharUtils.isHighSurrogate(ch)) {
if (searchChars[j + 1] == str.charAt(i + 1)) {
continue outer;
}
} else {
continue outer;
}
}
}
return i;
}
return INDEX_NOT_FOUND;
}
/**
* <p>Search a String to find the first index of any
* character not in the given set of characters.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A <code>null</code> or empty search string will return <code>-1</code>.</p>
*
* <pre>
* StringUtils.indexOfAnyBut(null, *) = -1
* StringUtils.indexOfAnyBut("", *) = -1
* StringUtils.indexOfAnyBut(*, null) = -1
* StringUtils.indexOfAnyBut(*, "") = -1
* StringUtils.indexOfAnyBut("zzabyycdxx", "za") = 3
* StringUtils.indexOfAnyBut("zzabyycdxx", "") = -1
* StringUtils.indexOfAnyBut("aba","ab") = -1
* </pre>
*
* @param str the String to check, may be null
* @param searchChars the chars to search for, may be null
* @return the index of any of the chars, -1 if no match or null input
* @since 2.0
*/
public static int indexOfAnyBut(String str, String searchChars) {
if (isEmpty(str) || isEmpty(searchChars)) {
return INDEX_NOT_FOUND;
}
int strLen = str.length();
for (int i = 0; i < strLen; i++) {
char ch = str.charAt(i);
boolean chFound = searchChars.indexOf(ch) >= 0;
if (i + 1 < strLen && CharUtils.isHighSurrogate(ch)) {
char ch2 = str.charAt(i + 1);
if (chFound && searchChars.indexOf(ch2) < 0) {
return i;
}
} else {
if (!chFound) {
return i;
}
}
}
return INDEX_NOT_FOUND;
}
// ContainsOnly
//-----------------------------------------------------------------------
/**
* <p>Checks if the String contains only certain characters.</p>
*
* <p>A <code>null</code> String will return <code>false</code>.
* A <code>null</code> valid character array will return <code>false</code>.
* An empty String (length()=0) always returns <code>true</code>.</p>
*
* <pre>
* StringUtils.containsOnly(null, *) = false
* StringUtils.containsOnly(*, null) = false
* StringUtils.containsOnly("", *) = true
* StringUtils.containsOnly("ab", '''') = false
* StringUtils.containsOnly("abab", ''abc'') = true
* StringUtils.containsOnly("ab1", ''abc'') = false
* StringUtils.containsOnly("abz", ''abc'') = false
* </pre>
*
* @param str the String to check, may be null
* @param valid an array of valid chars, may be null
* @return true if it only contains valid chars and is non-null
*/
public static boolean containsOnly(String str, char[] valid) {
// All these pre-checks are to maintain API with an older version
if ((valid == null) || (str == null)) {
return false;
}
if (str.length() == 0) {
return true;
}
if (valid.length == 0) {
return false;
}
return indexOfAnyBut(str, valid) == INDEX_NOT_FOUND;
}
/**
* <p>Checks if the String contains only certain characters.</p>
*
* <p>A <code>null</code> String will return <code>false</code>.
* A <code>null</code> valid character String will return <code>false</code>.
* An empty String (length()=0) always returns <code>true</code>.</p>
*
* <pre>
* StringUtils.containsOnly(null, *) = false
* StringUtils.containsOnly(*, null) = false
* StringUtils.containsOnly("", *) = true
* StringUtils.containsOnly("ab", "") = false
* StringUtils.containsOnly("abab", "abc") = true
* StringUtils.containsOnly("ab1", "abc") = false
* StringUtils.containsOnly("abz", "abc") = false
* </pre>
*
* @param str the String to check, may be null
* @param validChars a String of valid chars, may be null
* @return true if it only contains valid chars and is non-null
* @since 2.0
*/
public static boolean containsOnly(String str, String validChars) {
if (str == null || validChars == null) {
return false;
}
return containsOnly(str, validChars.toCharArray());
}
// ContainsNone
//-----------------------------------------------------------------------
/**
* <p>Checks that the String does not contain certain characters.</p>
*
* <p>A <code>null</code> String will return <code>true</code>.
* A <code>null</code> invalid character array will return <code>true</code>.
* An empty String (length()=0) always returns true.</p>
*
* <pre>
* StringUtils.containsNone(null, *) = true
* StringUtils.containsNone(*, null) = true
* StringUtils.containsNone("", *) = true
* StringUtils.containsNone("ab", '''') = true
* StringUtils.containsNone("abab", ''xyz'') = true
* StringUtils.containsNone("ab1", ''xyz'') = true
* StringUtils.containsNone("abz", ''xyz'') = false
* </pre>
*
* @param str the String to check, may be null
* @param searchChars an array of invalid chars, may be null
* @return true if it contains none of the invalid chars, or is null
* @since 2.0
*/
public static boolean containsNone(String str, char[] searchChars) {
if (str == null || searchChars == null) {
return true;
}
int csLen = str.length();
int csLast = csLen - 1;
int searchLen = searchChars.length;
int searchLast = searchLen - 1;
for (int i = 0; i < csLen; i++) {
char ch = str.charAt(i);
for (int j = 0; j < searchLen; j++) {
if (searchChars[j] == ch) {
if (CharUtils.isHighSurrogate(ch)) {
if (j == searchLast) {
// missing low surrogate, fine, like String.indexOf(String)
return false;
}
if (i < csLast && searchChars[j + 1] == str.charAt(i + 1)) {
return false;
}
} else {
// ch is in the Basic Multilingual Plane
return false;
}
}
}
}
return true;
}
/**
* <p>Checks that the String does not contain certain characters.</p>
*
* <p>A <code>null</code> String will return <code>true</code>.
* A <code>null</code> invalid character array will return <code>true</code>.
* An empty String ("") always returns true.</p>
*
* <pre>
* StringUtils.containsNone(null, *) = true
* StringUtils.containsNone(*, null) = true
* StringUtils.containsNone("", *) = true
* StringUtils.containsNone("ab", "") = true
* StringUtils.containsNone("abab", "xyz") = true
* StringUtils.containsNone("ab1", "xyz") = true
* StringUtils.containsNone("abz", "xyz") = false
* </pre>
*
* @param str the String to check, may be null
* @param invalidChars a String of invalid chars, may be null
* @return true if it contains none of the invalid chars, or is null
* @since 2.0
*/
public static boolean containsNone(String str, String invalidChars) {
if (str == null || invalidChars == null) {
return true;
}
return containsNone(str, invalidChars.toCharArray());
}
// IndexOfAny strings
//-----------------------------------------------------------------------
/**
* <p>Find the first index of any of a set of potential substrings.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A <code>null</code> or zero length search array will return <code>-1</code>.
* A <code>null</code> search array entry will be ignored, but a search
* array containing "" will return <code>0</code> if <code>str</code> is not
* null. This method uses {@link String#indexOf(String)}.</p>
*
* <pre>
* StringUtils.indexOfAny(null, *) = -1
* StringUtils.indexOfAny(*, null) = -1
* StringUtils.indexOfAny(*, []) = -1
* StringUtils.indexOfAny("zzabyycdxx", ["ab","cd"]) = 2
* StringUtils.indexOfAny("zzabyycdxx", ["cd","ab"]) = 2
* StringUtils.indexOfAny("zzabyycdxx", ["mn","op"]) = -1
* StringUtils.indexOfAny("zzabyycdxx", ["zab","aby"]) = 1
* StringUtils.indexOfAny("zzabyycdxx", [""]) = 0
* StringUtils.indexOfAny("", [""]) = 0
* StringUtils.indexOfAny("", ["a"]) = -1
* </pre>
*
* @param str the String to check, may be null
* @param searchStrs the Strings to search for, may be null
* @return the first index of any of the searchStrs in str, -1 if no match
*/
public static int indexOfAny(String str, String[] searchStrs) {
if ((str == null) || (searchStrs == null)) {
return INDEX_NOT_FOUND;
}
int sz = searchStrs.length;
// String''s can''t have a MAX_VALUEth index.
int ret = Integer.MAX_VALUE;
int tmp = 0;
for (int i = 0; i < sz; i++) {
String search = searchStrs[i];
if (search == null) {
continue;
}
tmp = str.indexOf(search);
if (tmp == INDEX_NOT_FOUND) {
continue;
}
if (tmp < ret) {
ret = tmp;
}
}
return (ret == Integer.MAX_VALUE) ? INDEX_NOT_FOUND : ret;
}
/**
* <p>Find the latest index of any of a set of potential substrings.</p>
*
* <p>A <code>null</code> String will return <code>-1</code>.
* A <code>null</code> search array will return <code>-1</code>.
* A <code>null</code> or zero length search array entry will be ignored,
* but a search array containing "" will return the length of <code>str</code>
* if <code>str</code> is not null. This method uses {@link String#indexOf(String)}</p>
*
* <pre>
* StringUtils.lastIndexOfAny(null, *) = -1
* StringUtils.lastIndexOfAny(*, null) = -1
* StringUtils.lastIndexOfAny(*, []) = -1
* StringUtils.lastIndexOfAny(*, [null]) = -1
* StringUtils.lastIndexOfAny("zzabyycdxx", ["ab","cd"]) = 6
* StringUtils.lastIndexOfAny("zzabyycdxx", ["cd","ab"]) = 6
* StringUtils.lastIndexOfAny("zzabyycdxx", ["mn","op"]) = -1
* StringUtils.lastIndexOfAny("zzabyycdxx", ["mn","op"]) = -1
* StringUtils.lastIndexOfAny("zzabyycdxx", ["mn",""]) = 10
* </pre>
*
* @param str the String to check, may be null
* @param searchStrs the Strings to search for, may be null
* @return the last index of any of the Strings, -1 if no match
*/
public static int lastIndexOfAny(String str, String[] searchStrs) {
if ((str == null) || (searchStrs == null)) {
return INDEX_NOT_FOUND;
}
int sz = searchStrs.length;
int ret = INDEX_NOT_FOUND;
int tmp = 0;
for (int i = 0; i < sz; i++) {
String search = searchStrs[i];
if (search == null) {
continue;
}
tmp = str.lastIndexOf(search);
if (tmp > ret) {
ret = tmp;
}
}
return ret;
}
// Substring
//-----------------------------------------------------------------------
/**
* <p>Gets a substring from the specified String avoiding exceptions.</p>
*
* <p>A negative start position can be used to start <code>n</code>
* characters from the end of the String.</p>
*
* <p>A <code>null</code> String will return <code>null</code>.
* An empty ("") String will return "".</p>
*
* <pre>
* StringUtils.substring(null, *) = null
* StringUtils.substring("", *) = ""
* StringUtils.substring("abc", 0) = "abc"
* StringUtils.substring("abc", 2) = "c"
* StringUtils.substring("abc", 4) = ""
* StringUtils.substring("abc", -2) = "bc"
* StringUtils.substring("abc", -4) = "abc"
* </pre>
*
* @param str the String to get the substring from, may be null
* @param start the position to start from, negative means
* count back from the end of the String by this many characters
* @return substring from start position, <code>null</code> if null String input
*/
public static String substring(String str, int start) {
if (str == null) {
return null;
}
// handle negatives, which means last n characters
if (start < 0) {
start = str.length() + start; // remember start is negative
}
if (start < 0) {
start = 0;
}
if (start > str.length()) {
return EMPTY;
}
return str.substring(start);
}
/**
* <p>Gets a substring from the specified String avoiding exceptions.</p>
*
* <p>A negative start position can be used to start/end <code>n</code>
* characters from the end of the String.</p>
*
* <p>The returned substring starts with the character in the <code>start</code>
* position and ends before the <code>end</code> position. All position counting is
* zero-based -- i.e., to start at the beginning of the string use
* <code>start = 0</code>. Negative start and end positions can be used to
* specify offsets relative to the end of the String.</p>
*
* <p>If <code>start</code> is not strictly to the left of <code>end</code>, ""
* is returned.</p>
*
* <pre>
* StringUtils.substring(null, *, *) = null
* StringUtils.substring("", * , *) = "";
* StringUtils.substring("abc", 0, 2) = "ab"
* StringUtils.substring("abc", 2, 0) = ""
* StringUtils.substring("abc", 2, 4) = "c"
* StringUtils.substring("abc", 4, 6) = ""
* StringUtils.substring("abc", 2, 2) = ""
* StringUtils.substring("abc", -2, -1) = "b"
* StringUtils.substring("abc", -4, 2) = "ab"
* </pre>
*
* @param str the String to get the substring from, may be null
* @param start the position to start from, negative means
* count back from the end of the String by this many characters
* @param end the position to end at (exclusive), negative means
* count back from the end of the String by this many characters
* @return substring from start position to end positon,
* <code>null</code> if null String input
*/
public static String substring(String str, int start, int end) {
if (str == null) {
return null;
}
// handle negatives
if (end < 0) {
end = str.length() + end; // remember end is negative
}
if (start < 0) {
start = str.length() + start; // remember start is negative
}
// check length next
if (end > str.length()) {
end = str.length();
}
// if start is greater than end, return ""
if (start > end) {
return EMPTY;
}
if (start < 0) {
start = 0;
}
if (end < 0) {
end = 0;
}
return str.substring(start, end);
}
// Left/Right/Mid
//-----------------------------------------------------------------------
/**
* <p>Gets the leftmost <code>len</code> characters of a String.</p>
*
* <p>If <code>len</code> characters are not available, or the
* String is <code>null</code>, the String will be returned without
* an exception. An empty String is returned if len is negative.</p>
*
* <pre>
* StringUtils.left(null, *) = null
* StringUtils.left(*, -ve) = ""
* StringUtils.left("", *) = ""
* StringUtils.left("abc", 0) = ""
* StringUtils.left("abc", 2) = "ab"
* StringUtils.left("abc", 4) = "abc"
* </pre>
*
* @param str the String to get the leftmost characters from, may be null
* @param len the length of the required String
* @return the leftmost characters, <code>null</code> if null String input
*/
public static String left(String str, int len) {
if (str == null) {
return null;
}
if (len < 0) {
return EMPTY;
}
if (str.length() <= len) {
return str;
}
return str.substring(0, len);
}
/**
* <p>Gets the rightmost <code>len</code> characters of a String.</p>
*
* <p>If <code>len</code> characters are not available, or the String
* is <code>null</code>, the String will be returned without an
* an exception. An empty String is returned if len is negative.</p>
*
* <pre>
* StringUtils.right(null, *) = null
* StringUtils.right(*, -ve) = ""
* StringUtils.right("", *) = ""
* StringUtils.right("abc", 0) = ""
* StringUtils.right("abc", 2) = "bc"
* StringUtils.right("abc", 4) = "abc"
* </pre>
*
* @param str the String to get the rightmost characters from, may be null
* @param len the length of the required String
* @return the rightmost characters, <code>null</code> if null String input
*/
public static String right(String str, int len) {
if (str == null) {
return null;
}
if (len < 0) {
return EMPTY;
}
if (str.length() <= len) {
return str;
}
return str.substring(str.length() - len);
}
/**
* <p>Gets <code>len</code> characters from the middle of a String.</p>
*
* <p>If <code>len</code> characters are not available, the remainder
* of the String will be returned without an exception. If the
* String is <code>null</code>, <code>null</code> will be returned.
* An empty String is returned if len is negative or exceeds the
* length of <code>str</code>.</p>
*
* <pre>
* StringUtils.mid(null, *, *) = null
* StringUtils.mid(*, *, -ve) = ""
* StringUtils.mid("", 0, *) = ""
* StringUtils.mid("abc", 0, 2) = "ab"
* StringUtils.mid("abc", 0, 4) = "abc"
* StringUtils.mid("abc", 2, 4) = "c"
* StringUtils.mid("abc", 4, 2) = ""
* StringUtils.mid("abc", -2, 2) = "ab"
* </pre>
*
* @param str the String to get the characters from, may be null
* @param pos the position to start from, negative treated as zero
* @param len the length of the required String
* @return the middle characters, <code>null</code> if null String input
*/
public static String mid(String str, int pos, int len) {
if (str == null) {
return null;
}
if (len < 0 || pos > str.length()) {
return EMPTY;
}
if (pos < 0) {
pos = 0;
}
if (str.length() <= (pos + len)) {
return str.substring(pos);
}
return str.substring(pos, pos + len);
}
// SubStringAfter/SubStringBefore
//-----------------------------------------------------------------------
/**
* <p>Gets the substring before the first occurrence of a separator.
* The separator is not returned.</p>
*
* <p>A <code>null</code> string input will return <code>null</code>.
* An empty ("") string input will return the empty string.
* A <code>null</code> separator will return the input string.</p>
*
* <p>If nothing is found, the string input is returned.</p>
*
* <p>取得指定字符串之前的字符串.</p>
*
* <pre>
* StringUtils.substringBefore(null, *) = null
* StringUtils.substringBefore("", *) = ""
* StringUtils.substringBefore("abc", "a") = ""
* StringUtils.substringBefore("abcba", "b") = "a"
* StringUtils.substringBefore("abc", "c") = "ab"
* StringUtils.substringBefore("abc", "d") = "abc"
* StringUtils.substringBefore("abc", "") = ""
* StringUtils.substringBefore("abc", null) = "abc"
* </pre>
*
* @param str the String to get a substring from, may be null
* @param separator the String to search for, may be null
* @return the substring before the first occurrence of the separator,
* <code>null</code> if null String input
* @since 2.0
*/
public static String substringBefore(String str, String separator) {
if (isEmpty(str) || separator == null) {
return str;
}
if (separator.length() == 0) {
return EMPTY;
}
int pos = str.indexOf(separator);
if (pos == INDEX_NOT_FOUND) {
return str;
}
return str.substring(0, pos);
}
/**
* <p>Gets the substring after the first occurrence of a separator.
* The separator is not returned.</p>
*
* <p>A <code>null</code> string input will return <code>null</code>.
* An empty ("") string input will return the empty string.
* A <code>null</code> separator will return the empty string if the
* input string is not <code>null</code>.</p>
*
* <p>If nothing is found, the empty string is returned.</p>
*
* <p>取得指定字符串后的字符串.</p>
*
* <pre>
* StringUtils.substringAfter(null, *) = null
* StringUtils.substringAfter("", *) = ""
* StringUtils.substringAfter(*, null) = ""
* StringUtils.substringAfter("abc", "a") = "bc"
* StringUtils.substringAfter("abcba", "b") = "cba"
* StringUtils.substringAfter("abc", "c") = ""
* StringUtils.substringAfter("abc", "d") = ""
* StringUtils.substringAfter("abc", "") = "abc"
* </pre>
*
* @param str the String to get a substring from, may be null
* @param separator the String to search for, may be null
* @return the substring after the first occurrence of the separator,
* <code>null</code> if null String input
* @since 2.0
*/
public static String substringAfter(String str, String separator) {
if (isEmpty(str)) {
return str;
}
if (separator == null) {
return EMPTY;
}
int pos = str.indexOf(separator);
if (pos == INDEX_NOT_FOUND) {
return EMPTY;
}
return str.substring(pos + separator.length());
}
/**
* <p>Gets the substring before the last occurrence of a separator.
* The separator is not returned.</p>
*
* <p>A <code>null</code> string input will return <code>null</code>.
* An empty ("") string input will return the empty string.
* An empty or <code>null</code> separator will return the input string.</p>
*
* <p>If nothing is found, the string input is returned.</p>
*
* <p>取得最后一个指定字符串之前的字符串.</p>
*
* <pre>
* StringUtils.substringBeforeLast(null, *) = null
* StringUtils.substringBeforeLast("", *) = ""
* StringUtils.substringBeforeLast("abcba", "b") = "abc"
* StringUtils.substringBeforeLast("abc", "c") = "ab"
* StringUtils.substringBeforeLast("a", "a") = ""
* StringUtils.substringBeforeLast("a", "z") = "a"
* StringUtils.substringBeforeLast("a", null) = "a"
* StringUtils.substringBeforeLast("a", "") = "a"
* </pre>
*
* @param str the String to get a substring from, may be null
* @param separator the String to search for, may be null
* @return the substring before the last occurrence of the separator,
* <code>null</code> if null String input
* @since 2.0
*/
public static String substringBeforeLast(String str, String separator) {
if (isEmpty(str) || isEmpty(separator)) {
return str;
}
int pos = str.lastIndexOf(separator);
if (pos == INDEX_NOT_FOUND) {
return str;
}
return str.substring(0, pos);
}
/**
* <p>Gets the substring after the last occurrence of a separator.
* The separator is not returned.</p>
*
* <p>A <code>null</code> string input will return <code>null</code>.
* An empty ("") string input will return the empty string.
* An empty or <code>null</code> separator will return the empty string if
* the input string is not <code>null</code>.</p>
*
* <p>If nothing is found, the empty string is returned.</p>
*
* <p>取得最后一个指定字符串之后的字符串.</p>
*
* <pre>
* StringUtils.substringAfterLast(null, *) = null
* StringUtils.substringAfterLast("", *) = ""
* StringUtils.substringAfterLast(*, "") = ""
* StringUtils.substringAfterLast(*, null) = ""
* StringUtils.substringAfterLast("abc", "a") = "bc"
* StringUtils.substringAfterLast("abcba", "b") = "a"
* StringUtils.substringAfterLast("abc", "c") = ""
* StringUtils.substringAfterLast("a", "a") = ""
* StringUtils.substringAfterLast("a", "z") = ""
* </pre>
*
* @param str the String to get a substring from, may be null
* @param separator the String to search for, may be null
* @return the substring after the last occurrence of the separator,
* <code>null</code> if null String input
* @since 2.0
*/
public static String substringAfterLast(String str, String separator) {
if (isEmpty(str)) {
return str;
}
if (isEmpty(separator)) {
return EMPTY;
}
int pos = str.lastIndexOf(separator);
if (pos == INDEX_NOT_FOUND || pos == (str.length() - separator.length())) {
return EMPTY;
}
return str.substring(pos + separator.length());
}
// Substring between
//-----------------------------------------------------------------------
/**
* <p>Gets the String that is nested in between two instances of the
* same String.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> tag returns <code>null</code>.</p>
*
*<P>在testString中取得header和tail之间的字符串。不存在则返回空.取得两字符之间的字符串</p>
*
* <pre>
* StringUtils.substringBetween(null, *) = null
* StringUtils.substringBetween("", "") = ""
* StringUtils.substringBetween("", "tag") = null
* StringUtils.substringBetween("tagabctag", null) = null
* StringUtils.substringBetween("tagabctag", "") = ""
* StringUtils.substringBetween("tagabctag", "tag") = "abc"
* </pre>
*
* @param str the String containing the substring, may be null
* @param tag the String before and after the substring, may be null
* @return the substring, <code>null</code> if no match
* @since 2.0
*/
public static String substringBetween(String str, String tag) {
return substringBetween(str, tag, tag);
}
/**
* <p>Gets the String that is nested in between two Strings.
* Only the first match is returned.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> open/close returns <code>null</code> (no match).
* An empty ("") open and close returns an empty string.</p>
*
* <pre>
* StringUtils.substringBetween("wx[b]yz", "[", "]") = "b"
* StringUtils.substringBetween(null, *, *) = null
* StringUtils.substringBetween(*, null, *) = null
* StringUtils.substringBetween(*, *, null) = null
* StringUtils.substringBetween("", "", "") = ""
* StringUtils.substringBetween("", "", "]") = null
* StringUtils.substringBetween("", "[", "]") = null
* StringUtils.substringBetween("yabcz", "", "") = ""
* StringUtils.substringBetween("yabcz", "y", "z") = "abc"
* StringUtils.substringBetween("yabczyabcz", "y", "z") = "abc"
* </pre>
*
* @param str the String containing the substring, may be null
* @param open the String before the substring, may be null
* @param close the String after the substring, may be null
* @return the substring, <code>null</code> if no match
* @since 2.0
*/
public static String substringBetween(String str, String open, String close) {
if (str == null || open == null || close == null) {
return null;
}
int start = str.indexOf(open);
if (start != INDEX_NOT_FOUND) {
int end = str.indexOf(close, start + open.length());
if (end != INDEX_NOT_FOUND) {
return str.substring(start + open.length(), end);
}
}
return null;
}
/**
* <p>Searches a String for substrings delimited by a start and end tag,
* returning all matching substrings in an array.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> open/close returns <code>null</code> (no match).
* An empty ("") open/close returns <code>null</code> (no match).</p>
*
* <pre>
* StringUtils.substringsBetween("[a][b][c]", "[", "]") = ["a","b","c"]
* StringUtils.substringsBetween(null, *, *) = null
* StringUtils.substringsBetween(*, null, *) = null
* StringUtils.substringsBetween(*, *, null) = null
* StringUtils.substringsBetween("", "[", "]") = []
* </pre>
*
* @param str the String containing the substrings, null returns null, empty returns empty
* @param open the String identifying the start of the substring, empty returns null
* @param close the String identifying the end of the substring, empty returns null
* @return a String Array of substrings, or <code>null</code> if no match
* @since 2.3
*/
public static String[] substringsBetween(String str, String open, String close) {
if (str == null || isEmpty(open) || isEmpty(close)) {
return null;
}
int strLen = str.length();
if (strLen == 0) {
return ArrayUtils.EMPTY_STRING_ARRAY;
}
int closeLen = close.length();
int openLen = open.length();
List list = new ArrayList();
int pos = 0;
while (pos < (strLen - closeLen)) {
int start = str.indexOf(open, pos);
if (start < 0) {
break;
}
start += openLen;
int end = str.indexOf(close, start);
if (end < 0) {
break;
}
list.add(str.substring(start, end));
pos = end + closeLen;
}
if (list.isEmpty()) {
return null;
}
return (String[]) list.toArray(new String [list.size()]);
}
// Nested extraction
//-----------------------------------------------------------------------
/**
* <p>Gets the String that is nested in between two instances of the
* same String.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> tag returns <code>null</code>.</p>
*
* <pre>
* StringUtils.getNestedString(null, *) = null
* StringUtils.getNestedString("", "") = ""
* StringUtils.getNestedString("", "tag") = null
* StringUtils.getNestedString("tagabctag", null) = null
* StringUtils.getNestedString("tagabctag", "") = ""
* StringUtils.getNestedString("tagabctag", "tag") = "abc"
* </pre>
*
* @param str the String containing nested-string, may be null
* @param tag the String before and after nested-string, may be null
* @return the nested String, <code>null</code> if no match
* @deprecated Use the better named {@link #substringBetween(String, String)}.
* Method will be removed in Commons Lang 3.0.
*/
public static String getNestedString(String str, String tag) {
return substringBetween(str, tag, tag);
}
/**
* <p>Gets the String that is nested in between two Strings.
* Only the first match is returned.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> open/close returns <code>null</code> (no match).
* An empty ("") open/close returns an empty string.</p>
*
* <pre>
* StringUtils.getNestedString(null, *, *) = null
* StringUtils.getNestedString("", "", "") = ""
* StringUtils.getNestedString("", "", "tag") = null
* StringUtils.getNestedString("", "tag", "tag") = null
* StringUtils.getNestedString("yabcz", null, null) = null
* StringUtils.getNestedString("yabcz", "", "") = ""
* StringUtils.getNestedString("yabcz", "y", "z") = "abc"
* StringUtils.getNestedString("yabczyabcz", "y", "z") = "abc"
* </pre>
*
* @param str the String containing nested-string, may be null
* @param open the String before nested-string, may be null
* @param close the String after nested-string, may be null
* @return the nested String, <code>null</code> if no match
* @deprecated Use the better named {@link #substringBetween(String, String, String)}.
* Method will be removed in Commons Lang 3.0.
*/
public static String getNestedString(String str, String open, String close) {
return substringBetween(str, open, close);
}
// Splitting
//-----------------------------------------------------------------------
/**
* <p>Splits the provided text into an array, using whitespace as the
* separator.
* Whitespace is defined by {@link Character#isWhitespace(char)}.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as one separator.
* For more control over the split use the StrTokenizer class.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <p>splitChars中可以包含一系列的字符串来劈分testString,并可以设定得到数组的长度.注意设定长度arrayLength和劈分字符串间有抵触关系,建议一般情况下不要设定长度.</p>
*
* <pre>
* StringUtils.split(null) = null
* StringUtils.split("") = []
* StringUtils.split("abc def") = ["abc", "def"]
* StringUtils.split("abc def") = ["abc", "def"]
* StringUtils.split(" abc ") = ["abc"]
* </pre>
*
* @param str the String to parse, may be null
* @return an array of parsed Strings, <code>null</code> if null String input
*/
public static String[] split(String str) {
return split(str, null, -1);
}
/**
* <p>Splits the provided text into an array, separator specified.
* This is an alternative to using StringTokenizer.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as one separator.
* For more control over the split use the StrTokenizer class.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.split(null, *) = null
* StringUtils.split("", *) = []
* StringUtils.split("a.b.c", ''.'') = ["a", "b", "c"]
* StringUtils.split("a..b.c", ''.'') = ["a", "b", "c"]
* StringUtils.split("a:b:c", ''.'') = ["a:b:c"]
* StringUtils.split("a b c", '' '') = ["a", "b", "c"]
* </pre>
*
* @param str the String to parse, may be null
* @param separatorChar the character used as the delimiter
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.0
*/
public static String[] split(String str, char separatorChar) {
return splitWorker(str, separatorChar, false);
}
/**
* <p>Splits the provided text into an array, separators specified.
* This is an alternative to using StringTokenizer.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as one separator.
* For more control over the split use the StrTokenizer class.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> separatorChars splits on whitespace.</p>
*
* <pre>
* StringUtils.split(null, *) = null
* StringUtils.split("", *) = []
* StringUtils.split("abc def", null) = ["abc", "def"]
* StringUtils.split("abc def", " ") = ["abc", "def"]
* StringUtils.split("abc def", " ") = ["abc", "def"]
* StringUtils.split("ab:cd:ef", ":") = ["ab", "cd", "ef"]
* </pre>
*
* @param str the String to parse, may be null
* @param separatorChars the characters used as the delimiters,
* <code>null</code> splits on whitespace
* @return an array of parsed Strings, <code>null</code> if null String input
*/
public static String[] split(String str, String separatorChars) {
return splitWorker(str, separatorChars, -1, false);
}
/**
* <p>Splits the provided text into an array with a maximum length,
* separators specified.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as one separator.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> separatorChars splits on whitespace.</p>
*
* <p>If more than <code>max</code> delimited substrings are found, the last
* returned string includes all characters after the first <code>max - 1</code>
* returned strings (including separator characters).</p>
*
* <pre>
* StringUtils.split(null, *, *) = null
* StringUtils.split("", *, *) = []
* StringUtils.split("ab de fg", null, 0) = ["ab", "cd", "ef"]
* StringUtils.split("ab de fg", null, 0) = ["ab", "cd", "ef"]
* StringUtils.split("ab:cd:ef", ":", 0) = ["ab", "cd", "ef"]
* StringUtils.split("ab:cd:ef", ":", 2) = ["ab", "cd:ef"]
* </pre>
*
* @param str the String to parse, may be null
* @param separatorChars the characters used as the delimiters,
* <code>null</code> splits on whitespace
* @param max the maximum number of elements to include in the
* array. A zero or negative value implies no limit
* @return an array of parsed Strings, <code>null</code> if null String input
*/
public static String[] split(String str, String separatorChars, int max) {
return splitWorker(str, separatorChars, max, false);
}
/**
* <p>Splits the provided text into an array, separator string specified.</p>
*
* <p>The separator(s) will not be included in the returned String array.
* Adjacent separators are treated as one separator.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> separator splits on whitespace.</p>
*
* <pre>
* StringUtils.splitByWholeSeparator(null, *) = null
* StringUtils.splitByWholeSeparator("", *) = []
* StringUtils.splitByWholeSeparator("ab de fg", null) = ["ab", "de", "fg"]
* StringUtils.splitByWholeSeparator("ab de fg", null) = ["ab", "de", "fg"]
* StringUtils.splitByWholeSeparator("ab:cd:ef", ":") = ["ab", "cd", "ef"]
* StringUtils.splitByWholeSeparator("ab-!-cd-!-ef", "-!-") = ["ab", "cd", "ef"]
* </pre>
*
* @param str the String to parse, may be null
* @param separator String containing the String to be used as a delimiter,
* <code>null</code> splits on whitespace
* @return an array of parsed Strings, <code>null</code> if null String was input
*/
public static String[] splitByWholeSeparator(String str, String separator) {
return splitByWholeSeparatorWorker( str, separator, -1, false ) ;
}
/**
* <p>Splits the provided text into an array, separator string specified.
* Returns a maximum of <code>max</code> substrings.</p>
*
* <p>The separator(s) will not be included in the returned String array.
* Adjacent separators are treated as one separator.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> separator splits on whitespace.</p>
*
* <pre>
* StringUtils.splitByWholeSeparator(null, *, *) = null
* StringUtils.splitByWholeSeparator("", *, *) = []
* StringUtils.splitByWholeSeparator("ab de fg", null, 0) = ["ab", "de", "fg"]
* StringUtils.splitByWholeSeparator("ab de fg", null, 0) = ["ab", "de", "fg"]
* StringUtils.splitByWholeSeparator("ab:cd:ef", ":", 2) = ["ab", "cd:ef"]
* StringUtils.splitByWholeSeparator("ab-!-cd-!-ef", "-!-", 5) = ["ab", "cd", "ef"]
* StringUtils.splitByWholeSeparator("ab-!-cd-!-ef", "-!-", 2) = ["ab", "cd-!-ef"]
* </pre>
*
* @param str the String to parse, may be null
* @param separator String containing the String to be used as a delimiter,
* <code>null</code> splits on whitespace
* @param max the maximum number of elements to include in the returned
* array. A zero or negative value implies no limit.
* @return an array of parsed Strings, <code>null</code> if null String was input
*/
public static String[] splitByWholeSeparator( String str, String separator, int max ) {
return splitByWholeSeparatorWorker(str, separator, max, false);
}
/**
* <p>Splits the provided text into an array, separator string specified. </p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as separators for empty tokens.
* For more control over the split use the StrTokenizer class.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> separator splits on whitespace.</p>
*
* <pre>
* StringUtils.splitByWholeSeparatorPreserveAllTokens(null, *) = null
* StringUtils.splitByWholeSeparatorPreserveAllTokens("", *) = []
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab de fg", null) = ["ab", "de", "fg"]
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab de fg", null) = ["ab", "", "", "de", "fg"]
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab:cd:ef", ":") = ["ab", "cd", "ef"]
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab-!-cd-!-ef", "-!-") = ["ab", "cd", "ef"]
* </pre>
*
* @param str the String to parse, may be null
* @param separator String containing the String to be used as a delimiter,
* <code>null</code> splits on whitespace
* @return an array of parsed Strings, <code>null</code> if null String was input
* @since 2.4
*/
public static String[] splitByWholeSeparatorPreserveAllTokens(String str, String separator) {
return splitByWholeSeparatorWorker(str, separator, -1, true);
}
/**
* <p>Splits the provided text into an array, separator string specified.
* Returns a maximum of <code>max</code> substrings.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as separators for empty tokens.
* For more control over the split use the StrTokenizer class.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> separator splits on whitespace.</p>
*
* <pre>
* StringUtils.splitByWholeSeparatorPreserveAllTokens(null, *, *) = null
* StringUtils.splitByWholeSeparatorPreserveAllTokens("", *, *) = []
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab de fg", null, 0) = ["ab", "de", "fg"]
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab de fg", null, 0) = ["ab", "", "", "de", "fg"]
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab:cd:ef", ":", 2) = ["ab", "cd:ef"]
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab-!-cd-!-ef", "-!-", 5) = ["ab", "cd", "ef"]
* StringUtils.splitByWholeSeparatorPreserveAllTokens("ab-!-cd-!-ef", "-!-", 2) = ["ab", "cd-!-ef"]
* </pre>
*
* @param str the String to parse, may be null
* @param separator String containing the String to be used as a delimiter,
* <code>null</code> splits on whitespace
* @param max the maximum number of elements to include in the returned
* array. A zero or negative value implies no limit.
* @return an array of parsed Strings, <code>null</code> if null String was input
* @since 2.4
*/
public static String[] splitByWholeSeparatorPreserveAllTokens(String str, String separator, int max) {
return splitByWholeSeparatorWorker(str, separator, max, true);
}
/**
* Performs the logic for the <code>splitByWholeSeparatorPreserveAllTokens</code> methods.
*
* @param str the String to parse, may be <code>null</code>
* @param separator String containing the String to be used as a delimiter,
* <code>null</code> splits on whitespace
* @param max the maximum number of elements to include in the returned
* array. A zero or negative value implies no limit.
* @param preserveAllTokens if <code>true</code>, adjacent separators are
* treated as empty token separators; if <code>false</code>, adjacent
* separators are treated as one separator.
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.4
*/
private static String[] splitByWholeSeparatorWorker(String str, String separator, int max,
boolean preserveAllTokens)
{
if (str == null) {
return null;
}
int len = str.length();
if (len == 0) {
return ArrayUtils.EMPTY_STRING_ARRAY;
}
if ((separator == null) || (EMPTY.equals(separator))) {
// Split on whitespace.
return splitWorker(str, null, max, preserveAllTokens);
}
int separatorLength = separator.length();
ArrayList substrings = new ArrayList();
int numberOfSubstrings = 0;
int beg = 0;
int end = 0;
while (end < len) {
end = str.indexOf(separator, beg);
if (end > -1) {
if (end > beg) {
numberOfSubstrings += 1;
if (numberOfSubstrings == max) {
end = len;
substrings.add(str.substring(beg));
} else {
// The following is OK, because String.substring( beg, end ) excludes
// the character at the position ''end''.
substrings.add(str.substring(beg, end));
// Set the starting point for the next search.
// The following is equivalent to beg = end + (separatorLength - 1) + 1,
// which is the right calculation:
beg = end + separatorLength;
}
} else {
// We found a consecutive occurrence of the separator, so skip it.
if (preserveAllTokens) {
numberOfSubstrings += 1;
if (numberOfSubstrings == max) {
end = len;
substrings.add(str.substring(beg));
} else {
substrings.add(EMPTY);
}
}
beg = end + separatorLength;
}
} else {
// String.substring( beg ) goes from ''beg'' to the end of the String.
substrings.add(str.substring(beg));
end = len;
}
}
return (String[]) substrings.toArray(new String[substrings.size()]);
}
// -----------------------------------------------------------------------
/**
* <p>Splits the provided text into an array, using whitespace as the
* separator, preserving all tokens, including empty tokens created by
* adjacent separators. This is an alternative to using StringTokenizer.
* Whitespace is defined by {@link Character#isWhitespace(char)}.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as separators for empty tokens.
* For more control over the split use the StrTokenizer class.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.splitPreserveAllTokens(null) = null
* StringUtils.splitPreserveAllTokens("") = []
* StringUtils.splitPreserveAllTokens("abc def") = ["abc", "def"]
* StringUtils.splitPreserveAllTokens("abc def") = ["abc", "", "def"]
* StringUtils.splitPreserveAllTokens(" abc ") = ["", "abc", ""]
* </pre>
*
* @param str the String to parse, may be <code>null</code>
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.1
*/
public static String[] splitPreserveAllTokens(String str) {
return splitWorker(str, null, -1, true);
}
/**
* <p>Splits the provided text into an array, separator specified,
* preserving all tokens, including empty tokens created by adjacent
* separators. This is an alternative to using StringTokenizer.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as separators for empty tokens.
* For more control over the split use the StrTokenizer class.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.splitPreserveAllTokens(null, *) = null
* StringUtils.splitPreserveAllTokens("", *) = []
* StringUtils.splitPreserveAllTokens("a.b.c", ''.'') = ["a", "b", "c"]
* StringUtils.splitPreserveAllTokens("a..b.c", ''.'') = ["a", "", "b", "c"]
* StringUtils.splitPreserveAllTokens("a:b:c", ''.'') = ["a:b:c"]
* StringUtils.splitPreserveAllTokens("a\tb\nc", null) = ["a", "b", "c"]
* StringUtils.splitPreserveAllTokens("a b c", '' '') = ["a", "b", "c"]
* StringUtils.splitPreserveAllTokens("a b c ", '' '') = ["a", "b", "c", ""]
* StringUtils.splitPreserveAllTokens("a b c ", '' '') = ["a", "b", "c", "", ""]
* StringUtils.splitPreserveAllTokens(" a b c", '' '') = ["", a", "b", "c"]
* StringUtils.splitPreserveAllTokens(" a b c", '' '') = ["", "", a", "b", "c"]
* StringUtils.splitPreserveAllTokens(" a b c ", '' '') = ["", a", "b", "c", ""]
* </pre>
*
* @param str the String to parse, may be <code>null</code>
* @param separatorChar the character used as the delimiter,
* <code>null</code> splits on whitespace
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.1
*/
public static String[] splitPreserveAllTokens(String str, char separatorChar) {
return splitWorker(str, separatorChar, true);
}
/**
* Performs the logic for the <code>split</code> and
* <code>splitPreserveAllTokens</code> methods that do not return a
* maximum array length.
*
* @param str the String to parse, may be <code>null</code>
* @param separatorChar the separate character
* @param preserveAllTokens if <code>true</code>, adjacent separators are
* treated as empty token separators; if <code>false</code>, adjacent
* separators are treated as one separator.
* @return an array of parsed Strings, <code>null</code> if null String input
*/
private static String[] splitWorker(String str, char separatorChar, boolean preserveAllTokens) {
// Performance tuned for 2.0 (JDK1.4)
if (str == null) {
return null;
}
int len = str.length();
if (len == 0) {
return ArrayUtils.EMPTY_STRING_ARRAY;
}
List list = new ArrayList();
int i = 0, start = 0;
boolean match = false;
boolean lastMatch = false;
while (i < len) {
if (str.charAt(i) == separatorChar) {
if (match || preserveAllTokens) {
list.add(str.substring(start, i));
match = false;
lastMatch = true;
}
start = ++i;
continue;
}
lastMatch = false;
match = true;
i++;
}
if (match || (preserveAllTokens && lastMatch)) {
list.add(str.substring(start, i));
}
return (String[]) list.toArray(new String[list.size()]);
}
/**
* <p>Splits the provided text into an array, separators specified,
* preserving all tokens, including empty tokens created by adjacent
* separators. This is an alternative to using StringTokenizer.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as separators for empty tokens.
* For more control over the split use the StrTokenizer class.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> separatorChars splits on whitespace.</p>
*
* <pre>
* StringUtils.splitPreserveAllTokens(null, *) = null
* StringUtils.splitPreserveAllTokens("", *) = []
* StringUtils.splitPreserveAllTokens("abc def", null) = ["abc", "def"]
* StringUtils.splitPreserveAllTokens("abc def", " ") = ["abc", "def"]
* StringUtils.splitPreserveAllTokens("abc def", " ") = ["abc", "", def"]
* StringUtils.splitPreserveAllTokens("ab:cd:ef", ":") = ["ab", "cd", "ef"]
* StringUtils.splitPreserveAllTokens("ab:cd:ef:", ":") = ["ab", "cd", "ef", ""]
* StringUtils.splitPreserveAllTokens("ab:cd:ef::", ":") = ["ab", "cd", "ef", "", ""]
* StringUtils.splitPreserveAllTokens("ab::cd:ef", ":") = ["ab", "", cd", "ef"]
* StringUtils.splitPreserveAllTokens(":cd:ef", ":") = ["", cd", "ef"]
* StringUtils.splitPreserveAllTokens("::cd:ef", ":") = ["", "", cd", "ef"]
* StringUtils.splitPreserveAllTokens(":cd:ef:", ":") = ["", cd", "ef", ""]
* </pre>
*
* @param str the String to parse, may be <code>null</code>
* @param separatorChars the characters used as the delimiters,
* <code>null</code> splits on whitespace
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.1
*/
public static String[] splitPreserveAllTokens(String str, String separatorChars) {
return splitWorker(str, separatorChars, -1, true);
}
/**
* <p>Splits the provided text into an array with a maximum length,
* separators specified, preserving all tokens, including empty tokens
* created by adjacent separators.</p>
*
* <p>The separator is not included in the returned String array.
* Adjacent separators are treated as separators for empty tokens.
* Adjacent separators are treated as one separator.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* A <code>null</code> separatorChars splits on whitespace.</p>
*
* <p>If more than <code>max</code> delimited substrings are found, the last
* returned string includes all characters after the first <code>max - 1</code>
* returned strings (including separator characters).</p>
*
* <pre>
* StringUtils.splitPreserveAllTokens(null, *, *) = null
* StringUtils.splitPreserveAllTokens("", *, *) = []
* StringUtils.splitPreserveAllTokens("ab de fg", null, 0) = ["ab", "cd", "ef"]
* StringUtils.splitPreserveAllTokens("ab de fg", null, 0) = ["ab", "cd", "ef"]
* StringUtils.splitPreserveAllTokens("ab:cd:ef", ":", 0) = ["ab", "cd", "ef"]
* StringUtils.splitPreserveAllTokens("ab:cd:ef", ":", 2) = ["ab", "cd:ef"]
* StringUtils.splitPreserveAllTokens("ab de fg", null, 2) = ["ab", " de fg"]
* StringUtils.splitPreserveAllTokens("ab de fg", null, 3) = ["ab", "", " de fg"]
* StringUtils.splitPreserveAllTokens("ab de fg", null, 4) = ["ab", "", "", "de fg"]
* </pre>
*
* @param str the String to parse, may be <code>null</code>
* @param separatorChars the characters used as the delimiters,
* <code>null</code> splits on whitespace
* @param max the maximum number of elements to include in the
* array. A zero or negative value implies no limit
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.1
*/
public static String[] splitPreserveAllTokens(String str, String separatorChars, int max) {
return splitWorker(str, separatorChars, max, true);
}
/**
* Performs the logic for the <code>split</code> and
* <code>splitPreserveAllTokens</code> methods that return a maximum array
* length.
*
* @param str the String to parse, may be <code>null</code>
* @param separatorChars the separate character
* @param max the maximum number of elements to include in the
* array. A zero or negative value implies no limit.
* @param preserveAllTokens if <code>true</code>, adjacent separators are
* treated as empty token separators; if <code>false</code>, adjacent
* separators are treated as one separator.
* @return an array of parsed Strings, <code>null</code> if null String input
*/
private static String[] splitWorker(String str, String separatorChars, int max, boolean preserveAllTokens) {
// Performance tuned for 2.0 (JDK1.4)
// Direct code is quicker than StringTokenizer.
// Also, StringTokenizer uses isSpace() not isWhitespace()
if (str == null) {
return null;
}
int len = str.length();
if (len == 0) {
return ArrayUtils.EMPTY_STRING_ARRAY;
}
List list = new ArrayList();
int sizePlus1 = 1;
int i = 0, start = 0;
boolean match = false;
boolean lastMatch = false;
if (separatorChars == null) {
// Null separator means use whitespace
while (i < len) {
if (Character.isWhitespace(str.charAt(i))) {
if (match || preserveAllTokens) {
lastMatch = true;
if (sizePlus1++ == max) {
i = len;
lastMatch = false;
}
list.add(str.substring(start, i));
match = false;
}
start = ++i;
continue;
}
lastMatch = false;
match = true;
i++;
}
} else if (separatorChars.length() == 1) {
// Optimise 1 character case
char sep = separatorChars.charAt(0);
while (i < len) {
if (str.charAt(i) == sep) {
if (match || preserveAllTokens) {
lastMatch = true;
if (sizePlus1++ == max) {
i = len;
lastMatch = false;
}
list.add(str.substring(start, i));
match = false;
}
start = ++i;
continue;
}
lastMatch = false;
match = true;
i++;
}
} else {
// standard case
while (i < len) {
if (separatorChars.indexOf(str.charAt(i)) >= 0) {
if (match || preserveAllTokens) {
lastMatch = true;
if (sizePlus1++ == max) {
i = len;
lastMatch = false;
}
list.add(str.substring(start, i));
match = false;
}
start = ++i;
continue;
}
lastMatch = false;
match = true;
i++;
}
}
if (match || (preserveAllTokens && lastMatch)) {
list.add(str.substring(start, i));
}
return (String[]) list.toArray(new String[list.size()]);
}
/**
* <p>Splits a String by Character type as returned by
* <code>java.lang.Character.getType(char)</code>. Groups of contiguous
* characters of the same type are returned as complete tokens.
* <pre>
* StringUtils.splitByCharacterType(null) = null
* StringUtils.splitByCharacterType("") = []
* StringUtils.splitByCharacterType("ab de fg") = ["ab", " ", "de", " ", "fg"]
* StringUtils.splitByCharacterType("ab de fg") = ["ab", " ", "de", " ", "fg"]
* StringUtils.splitByCharacterType("ab:cd:ef") = ["ab", ":", "cd", ":", "ef"]
* StringUtils.splitByCharacterType("number5") = ["number", "5"]
* StringUtils.splitByCharacterType("fooBar") = ["foo", "B", "ar"]
* StringUtils.splitByCharacterType("foo200Bar") = ["foo", "200", "B", "ar"]
* StringUtils.splitByCharacterType("ASFRules") = ["ASFR", "ules"]
* </pre>
* @param str the String to split, may be <code>null</code>
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.4
*/
public static String[] splitByCharacterType(String str) {
return splitByCharacterType(str, false);
}
/**
* <p>Splits a String by Character type as returned by
* <code>java.lang.Character.getType(char)</code>. Groups of contiguous
* characters of the same type are returned as complete tokens, with the
* following exception: the character of type
* <code>Character.UPPERCASE_LETTER</code>, if any, immediately
* preceding a token of type <code>Character.LOWERCASE_LETTER</code>
* will belong to the following token rather than to the preceding, if any,
* <code>Character.UPPERCASE_LETTER</code> token.
* <pre>
* StringUtils.splitByCharacterTypeCamelCase(null) = null
* StringUtils.splitByCharacterTypeCamelCase("") = []
* StringUtils.splitByCharacterTypeCamelCase("ab de fg") = ["ab", " ", "de", " ", "fg"]
* StringUtils.splitByCharacterTypeCamelCase("ab de fg") = ["ab", " ", "de", " ", "fg"]
* StringUtils.splitByCharacterTypeCamelCase("ab:cd:ef") = ["ab", ":", "cd", ":", "ef"]
* StringUtils.splitByCharacterTypeCamelCase("number5") = ["number", "5"]
* StringUtils.splitByCharacterTypeCamelCase("fooBar") = ["foo", "Bar"]
* StringUtils.splitByCharacterTypeCamelCase("foo200Bar") = ["foo", "200", "Bar"]
* StringUtils.splitByCharacterTypeCamelCase("ASFRules") = ["ASF", "Rules"]
* </pre>
* @param str the String to split, may be <code>null</code>
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.4
*/
public static String[] splitByCharacterTypeCamelCase(String str) {
return splitByCharacterType(str, true);
}
/**
* <p>Splits a String by Character type as returned by
* <code>java.lang.Character.getType(char)</code>. Groups of contiguous
* characters of the same type are returned as complete tokens, with the
* following exception: if <code>camelCase</code> is <code>true</code>,
* the character of type <code>Character.UPPERCASE_LETTER</code>, if any,
* immediately preceding a token of type <code>Character.LOWERCASE_LETTER</code>
* will belong to the following token rather than to the preceding, if any,
* <code>Character.UPPERCASE_LETTER</code> token.
* @param str the String to split, may be <code>null</code>
* @param camelCase whether to use so-called "camel-case" for letter types
* @return an array of parsed Strings, <code>null</code> if null String input
* @since 2.4
*/
private static String[] splitByCharacterType(String str, boolean camelCase) {
if (str == null) {
return null;
}
if (str.length() == 0) {
return ArrayUtils.EMPTY_STRING_ARRAY;
}
char[] c = str.toCharArray();
List list = new ArrayList();
int tokenStart = 0;
int currentType = Character.getType(c[tokenStart]);
for (int pos = tokenStart + 1; pos < c.length; pos++) {
int type = Character.getType(c[pos]);
if (type == currentType) {
continue;
}
if (camelCase && type == Character.LOWERCASE_LETTER && currentType == Character.UPPERCASE_LETTER) {
int newTokenStart = pos - 1;
if (newTokenStart != tokenStart) {
list.add(new String(c, tokenStart, newTokenStart - tokenStart));
tokenStart = newTokenStart;
}
} else {
list.add(new String(c, tokenStart, pos - tokenStart));
tokenStart = pos;
}
currentType = type;
}
list.add(new String(c, tokenStart, c.length - tokenStart));
return (String[]) list.toArray(new String[list.size()]);
}
// Joining
//-----------------------------------------------------------------------
/**
* <p>Joins the provided elements into a single String. </p>
*
* <p>No separator is added to the joined String.
* Null objects or empty string elements are represented by
* empty strings.</p>
*
* <pre>
* StringUtils.concatenate(null) = null
* StringUtils.concatenate([]) = ""
* StringUtils.concatenate([null]) = ""
* StringUtils.concatenate(["a", "b", "c"]) = "abc"
* StringUtils.concatenate([null, "", "a"]) = "a"
* </pre>
*
* @param array the array of values to concatenate, may be null
* @return the concatenated String, <code>null</code> if null array input
* @deprecated Use the better named {@link #join(Object[])} instead.
* Method will be removed in Commons Lang 3.0.
*/
public static String concatenate(Object[] array) {
return join(array, null);
}
/**
* <p>Joins the elements of the provided array into a single String
* containing the provided list of elements.</p>
*
* <p>No separator is added to the joined String.
* Null objects or empty strings within the array are represented by
* empty strings.</p>
*
* <pre>
* StringUtils.join(null) = null
* StringUtils.join([]) = ""
* StringUtils.join([null]) = ""
* StringUtils.join(["a", "b", "c"]) = "abc"
* StringUtils.join([null, "", "a"]) = "a"
* </pre>
*
* @param array the array of values to join together, may be null
* @return the joined String, <code>null</code> if null array input
* @since 2.0
*/
public static String join(Object[] array) {
return join(array, null);
}
/**
* <p>Joins the elements of the provided array into a single String
* containing the provided list of elements.</p>
*
* <p>No delimiter is added before or after the list.
* Null objects or empty strings within the array are represented by
* empty strings.</p>
*
* <pre>
* StringUtils.join(null, *) = null
* StringUtils.join([], *) = ""
* StringUtils.join([null], *) = ""
* StringUtils.join(["a", "b", "c"], '';'') = "a;b;c"
* StringUtils.join(["a", "b", "c"], null) = "abc"
* StringUtils.join([null, "", "a"], '';'') = ";;a"
* </pre>
*
* @param array the array of values to join together, may be null
* @param separator the separator character to use
* @return the joined String, <code>null</code> if null array input
* @since 2.0
*/
public static String join(Object[] array, char separator) {
if (array == null) {
return null;
}
return join(array, separator, 0, array.length);
}
/**
* <p>Joins the elements of the provided array into a single String
* containing the provided list of elements.</p>
*
* <p>No delimiter is added before or after the list.
* Null objects or empty strings within the array are represented by
* empty strings.</p>
*
* <pre>
* StringUtils.join(null, *) = null
* StringUtils.join([], *) = ""
* StringUtils.join([null], *) = ""
* StringUtils.join(["a", "b", "c"], '';'') = "a;b;c"
* StringUtils.join(["a", "b", "c"], null) = "abc"
* StringUtils.join([null, "", "a"], '';'') = ";;a"
* </pre>
*
* @param array the array of values to join together, may be null
* @param separator the separator character to use
* @param startIndex the first index to start joining from. It is
* an error to pass in an end index past the end of the array
* @param endIndex the index to stop joining from (exclusive). It is
* an error to pass in an end index past the end of the array
* @return the joined String, <code>null</code> if null array input
* @since 2.0
*/
public static String join(Object[] array, char separator, int startIndex, int endIndex) {
if (array == null) {
return null;
}
int bufSize = (endIndex - startIndex);
if (bufSize <= 0) {
return EMPTY;
}
bufSize *= ((array[startIndex] == null ? 16 : array[startIndex].toString().length()) + 1);
StrBuilder buf = new StrBuilder(bufSize);
for (int i = startIndex; i < endIndex; i++) {
if (i > startIndex) {
buf.append(separator);
}
if (array[i] != null) {
buf.append(array[i]);
}
}
return buf.toString();
}
/**
* <p>Joins the elements of the provided array into a single String
* containing the provided list of elements.</p>
*
* <p>No delimiter is added before or after the list.
* A <code>null</code> separator is the same as an empty String ("").
* Null objects or empty strings within the array are represented by
* empty strings.</p>
*
* <pre>
* StringUtils.join(null, *) = null
* StringUtils.join([], *) = ""
* StringUtils.join([null], *) = ""
* StringUtils.join(["a", "b", "c"], "--") = "a--b--c"
* StringUtils.join(["a", "b", "c"], null) = "abc"
* StringUtils.join(["a", "b", "c"], "") = "abc"
* StringUtils.join([null, "", "a"], '','') = ",,a"
* </pre>
*
* @param array the array of values to join together, may be null
* @param separator the separator character to use, null treated as ""
* @return the joined String, <code>null</code> if null array input
*/
public static String join(Object[] array, String separator) {
if (array == null) {
return null;
}
return join(array, separator, 0, array.length);
}
/**
* <p>Joins the elements of the provided array into a single String
* containing the provided list of elements.</p>
*
* <p>No delimiter is added before or after the list.
* A <code>null</code> separator is the same as an empty String ("").
* Null objects or empty strings within the array are represented by
* empty strings.</p>
*
* <pre>
* StringUtils.join(null, *) = null
* StringUtils.join([], *) = ""
* StringUtils.join([null], *) = ""
* StringUtils.join(["a", "b", "c"], "--") = "a--b--c"
* StringUtils.join(["a", "b", "c"], null) = "abc"
* StringUtils.join(["a", "b", "c"], "") = "abc"
* StringUtils.join([null, "", "a"], '','') = ",,a"
* </pre>
*
* @param array the array of values to join together, may be null
* @param separator the separator character to use, null treated as ""
* @param startIndex the first index to start joining from. It is
* an error to pass in an end index past the end of the array
* @param endIndex the index to stop joining from (exclusive). It is
* an error to pass in an end index past the end of the array
* @return the joined String, <code>null</code> if null array input
*/
public static String join(Object[] array, String separator, int startIndex, int endIndex) {
if (array == null) {
return null;
}
if (separator == null) {
separator = EMPTY;
}
// endIndex - startIndex > 0: Len = NofStrings *(len(firstString) + len(separator))
// (Assuming that all Strings are roughly equally long)
int bufSize = (endIndex - startIndex);
if (bufSize <= 0) {
return EMPTY;
}
bufSize *= ((array[startIndex] == null ? 16 : array[startIndex].toString().length())
+ separator.length());
StrBuilder buf = new StrBuilder(bufSize);
for (int i = startIndex; i < endIndex; i++) {
if (i > startIndex) {
buf.append(separator);
}
if (array[i] != null) {
buf.append(array[i]);
}
}
return buf.toString();
}
/**
* <p>Joins the elements of the provided <code>Iterator</code> into
* a single String containing the provided elements.</p>
*
* <p>No delimiter is added before or after the list. Null objects or empty
* strings within the iteration are represented by empty strings.</p>
*
* <p>See the examples here: {@link #join(Object[],char)}. </p>
*
* @param iterator the <code>Iterator</code> of values to join together, may be null
* @param separator the separator character to use
* @return the joined String, <code>null</code> if null iterator input
* @since 2.0
*/
public static String join(Iterator iterator, char separator) {
// handle null, zero and one elements before building a buffer
if (iterator == null) {
return null;
}
if (!iterator.hasNext()) {
return EMPTY;
}
Object first = iterator.next();
if (!iterator.hasNext()) {
return ObjectUtils.toString(first);
}
// two or more elements
StrBuilder buf = new StrBuilder(256); // Java default is 16, probably too small
if (first != null) {
buf.append(first);
}
while (iterator.hasNext()) {
buf.append(separator);
Object obj = iterator.next();
if (obj != null) {
buf.append(obj);
}
}
return buf.toString();
}
/**
* <p>Joins the elements of the provided <code>Iterator</code> into
* a single String containing the provided elements.</p>
*
* <p>No delimiter is added before or after the list.
* A <code>null</code> separator is the same as an empty String ("").</p>
*
* <p>See the examples here: {@link #join(Object[],String)}. </p>
*
* @param iterator the <code>Iterator</code> of values to join together, may be null
* @param separator the separator character to use, null treated as ""
* @return the joined String, <code>null</code> if null iterator input
*/
public static String join(Iterator iterator, String separator) {
// handle null, zero and one elements before building a buffer
if (iterator == null) {
return null;
}
if (!iterator.hasNext()) {
return EMPTY;
}
Object first = iterator.next();
if (!iterator.hasNext()) {
return ObjectUtils.toString(first);
}
// two or more elements
StrBuilder buf = new StrBuilder(256); // Java default is 16, probably too small
if (first != null) {
buf.append(first);
}
while (iterator.hasNext()) {
if (separator != null) {
buf.append(separator);
}
Object obj = iterator.next();
if (obj != null) {
buf.append(obj);
}
}
return buf.toString();
}
/**
* <p>Joins the elements of the provided <code>Collection</code> into
* a single String containing the provided elements.</p>
*
* <p>No delimiter is added before or after the list. Null objects or empty
* strings within the iteration are represented by empty strings.</p>
*
* <p>See the examples here: {@link #join(Object[],char)}. </p>
*
* @param collection the <code>Collection</code> of values to join together, may be null
* @param separator the separator character to use
* @return the joined String, <code>null</code> if null iterator input
* @since 2.3
*/
public static String join(Collection collection, char separator) {
if (collection == null) {
return null;
}
return join(collection.iterator(), separator);
}
/**
* <p>Joins the elements of the provided <code>Collection</code> into
* a single String containing the provided elements.</p>
*
* <p>No delimiter is added before or after the list.
* A <code>null</code> separator is the same as an empty String ("").</p>
*
* <p>See the examples here: {@link #join(Object[],String)}. </p>
*
* @param collection the <code>Collection</code> of values to join together, may be null
* @param separator the separator character to use, null treated as ""
* @return the joined String, <code>null</code> if null iterator input
* @since 2.3
*/
public static String join(Collection collection, String separator) {
if (collection == null) {
return null;
}
return join(collection.iterator(), separator);
}
// Delete
//-----------------------------------------------------------------------
/**
* <p>Deletes all ''space'' characters from a String as defined by
* {@link Character#isSpace(char)}.</p>
*
* <p>This is the only StringUtils method that uses the
* <code>isSpace</code> definition. You are advised to use
* {@link #deleteWhitespace(String)} instead as whitespace is much
* better localized.</p>
*
* <pre>
* StringUtils.deleteSpaces(null) = null
* StringUtils.deleteSpaces("") = ""
* StringUtils.deleteSpaces("abc") = "abc"
* StringUtils.deleteSpaces(" \t abc \n ") = "abc"
* StringUtils.deleteSpaces("ab c") = "abc"
* StringUtils.deleteSpaces("a\nb\tc ") = "abc"
* </pre>
*
* <p>Spaces are defined as <code>{'' '', ''\t'', ''\r'', ''\n'', ''\b''}</code>
* in line with the deprecated <code>isSpace</code> method.</p>
*
* @param str the String to delete spaces from, may be null
* @return the String without ''spaces'', <code>null</code> if null String input
* @deprecated Use the better localized {@link #deleteWhitespace(String)}.
* Method will be removed in Commons Lang 3.0.
*/
public static String deleteSpaces(String str) {
if (str == null) {
return null;
}
return CharSetUtils.delete(str, " \t\r\n\b");
}
/**
* <p>Deletes all whitespaces from a String as defined by
* {@link Character#isWhitespace(char)}.</p>
*
* <pre>
* StringUtils.deleteWhitespace(null) = null
* StringUtils.deleteWhitespace("") = ""
* StringUtils.deleteWhitespace("abc") = "abc"
* StringUtils.deleteWhitespace(" ab c ") = "abc"
* </pre>
*
* @param str the String to delete whitespace from, may be null
* @return the String without whitespaces, <code>null</code> if null String input
*/
public static String deleteWhitespace(String str) {
if (isEmpty(str)) {
return str;
}
int sz = str.length();
char[] chs = new char[sz];
int count = 0;
for (int i = 0; i < sz; i++) {
if (!Character.isWhitespace(str.charAt(i))) {
chs[count++] = str.charAt(i);
}
}
if (count == sz) {
return str;
}
return new String(chs, 0, count);
}
// Remove
//-----------------------------------------------------------------------
/**
* <p>Removes a substring only if it is at the begining of a source string,
* otherwise returns the source string.</p>
*
* <p>A <code>null</code> source string will return <code>null</code>.
* An empty ("") source string will return the empty string.
* A <code>null</code> search string will return the source string.</p>
*
* <pre>
* StringUtils.removeStart(null, *) = null
* StringUtils.removeStart("", *) = ""
* StringUtils.removeStart(*, null) = *
* StringUtils.removeStart("www.domain.com", "www.") = "domain.com"
* StringUtils.removeStart("domain.com", "www.") = "domain.com"
* StringUtils.removeStart("www.domain.com", "domain") = "www.domain.com"
* StringUtils.removeStart("abc", "") = "abc"
* </pre>
*
* @param str the source String to search, may be null
* @param remove the String to search for and remove, may be null
* @return the substring with the string removed if found,
* <code>null</code> if null String input
* @since 2.1
*/
public static String removeStart(String str, String remove) {
if (isEmpty(str) || isEmpty(remove)) {
return str;
}
if (str.startsWith(remove)){
return str.substring(remove.length());
}
return str;
}
/**
* <p>Case insensitive removal of a substring if it is at the begining of a source string,
* otherwise returns the source string.</p>
*
* <p>A <code>null</code> source string will return <code>null</code>.
* An empty ("") source string will return the empty string.
* A <code>null</code> search string will return the source string.</p>
*
* <pre>
* StringUtils.removeStartIgnoreCase(null, *) = null
* StringUtils.removeStartIgnoreCase("", *) = ""
* StringUtils.removeStartIgnoreCase(*, null) = *
* StringUtils.removeStartIgnoreCase("www.domain.com", "www.") = "domain.com"
* StringUtils.removeStartIgnoreCase("www.domain.com", "WWW.") = "domain.com"
* StringUtils.removeStartIgnoreCase("domain.com", "www.") = "domain.com"
* StringUtils.removeStartIgnoreCase("www.domain.com", "domain") = "www.domain.com"
* StringUtils.removeStartIgnoreCase("abc", "") = "abc"
* </pre>
*
* @param str the source String to search, may be null
* @param remove the String to search for (case insensitive) and remove, may be null
* @return the substring with the string removed if found,
* <code>null</code> if null String input
* @since 2.4
*/
public static String removeStartIgnoreCase(String str, String remove) {
if (isEmpty(str) || isEmpty(remove)) {
return str;
}
if (startsWithIgnoreCase(str, remove)) {
return str.substring(remove.length());
}
return str;
}
/**
* <p>Removes a substring only if it is at the end of a source string,
* otherwise returns the source string.</p>
*
* <p>A <code>null</code> source string will return <code>null</code>.
* An empty ("") source string will return the empty string.
* A <code>null</code> search string will return the source string.</p>
*
* <pre>
* StringUtils.removeEnd(null, *) = null
* StringUtils.removeEnd("", *) = ""
* StringUtils.removeEnd(*, null) = *
* StringUtils.removeEnd("www.domain.com", ".com.") = "www.domain.com"
* StringUtils.removeEnd("www.domain.com", ".com") = "www.domain"
* StringUtils.removeEnd("www.domain.com", "domain") = "www.domain.com"
* StringUtils.removeEnd("abc", "") = "abc"
* </pre>
*
* @param str the source String to search, may be null
* @param remove the String to search for and remove, may be null
* @return the substring with the string removed if found,
* <code>null</code> if null String input
* @since 2.1
*/
public static String removeEnd(String str, String remove) {
if (isEmpty(str) || isEmpty(remove)) {
return str;
}
if (str.endsWith(remove)) {
return str.substring(0, str.length() - remove.length());
}
return str;
}
/**
* <p>Case insensitive removal of a substring if it is at the end of a source string,
* otherwise returns the source string.</p>
*
* <p>A <code>null</code> source string will return <code>null</code>.
* An empty ("") source string will return the empty string.
* A <code>null</code> search string will return the source string.</p>
*
* <pre>
* StringUtils.removeEndIgnoreCase(null, *) = null
* StringUtils.removeEndIgnoreCase("", *) = ""
* StringUtils.removeEndIgnoreCase(*, null) = *
* StringUtils.removeEndIgnoreCase("www.domain.com", ".com.") = "www.domain.com"
* StringUtils.removeEndIgnoreCase("www.domain.com", ".com") = "www.domain"
* StringUtils.removeEndIgnoreCase("www.domain.com", "domain") = "www.domain.com"
* StringUtils.removeEndIgnoreCase("abc", "") = "abc"
* StringUtils.removeEndIgnoreCase("www.domain.com", ".COM") = "www.domain")
* StringUtils.removeEndIgnoreCase("www.domain.COM", ".com") = "www.domain")
* </pre>
*
* @param str the source String to search, may be null
* @param remove the String to search for (case insensitive) and remove, may be null
* @return the substring with the string removed if found,
* <code>null</code> if null String input
* @since 2.4
*/
public static String removeEndIgnoreCase(String str, String remove) {
if (isEmpty(str) || isEmpty(remove)) {
return str;
}
if (endsWithIgnoreCase(str, remove)) {
return str.substring(0, str.length() - remove.length());
}
return str;
}
/**
* <p>Removes all occurrences of a substring from within the source string.</p>
*
* <p>A <code>null</code> source string will return <code>null</code>.
* An empty ("") source string will return the empty string.
* A <code>null</code> remove string will return the source string.
* An empty ("") remove string will return the source string.</p>
*
* <pre>
* StringUtils.remove(null, *) = null
* StringUtils.remove("", *) = ""
* StringUtils.remove(*, null) = *
* StringUtils.remove(*, "") = *
* StringUtils.remove("queued", "ue") = "qd"
* StringUtils.remove("queued", "zz") = "queued"
* </pre>
*
* @param str the source String to search, may be null
* @param remove the String to search for and remove, may be null
* @return the substring with the string removed if found,
* <code>null</code> if null String input
* @since 2.1
*/
public static String remove(String str, String remove) {
if (isEmpty(str) || isEmpty(remove)) {
return str;
}
return replace(str, remove, EMPTY, -1);
}
/**
* <p>Removes all occurrences of a character from within the source string.</p>
*
* <p>A <code>null</code> source string will return <code>null</code>.
* An empty ("") source string will return the empty string.</p>
*
* <pre>
* StringUtils.remove(null, *) = null
* StringUtils.remove("", *) = ""
* StringUtils.remove("queued", ''u'') = "qeed"
* StringUtils.remove("queued", ''z'') = "queued"
* </pre>
*
* @param str the source String to search, may be null
* @param remove the char to search for and remove, may be null
* @return the substring with the char removed if found,
* <code>null</code> if null String input
* @since 2.1
*/
public static String remove(String str, char remove) {
if (isEmpty(str) || str.indexOf(remove) == INDEX_NOT_FOUND) {
return str;
}
char[] chars = str.toCharArray();
int pos = 0;
for (int i = 0; i < chars.length; i++) {
if (chars[i] != remove) {
chars[pos++] = chars[i];
}
}
return new String(chars, 0, pos);
}
// Replacing
//-----------------------------------------------------------------------
/**
* <p>Replaces a String with another String inside a larger String, once.</p>
*
* <p>A <code>null</code> reference passed to this method is a no-op.</p>
*
* <pre>
* StringUtils.replaceOnce(null, *, *) = null
* StringUtils.replaceOnce("", *, *) = ""
* StringUtils.replaceOnce("any", null, *) = "any"
* StringUtils.replaceOnce("any", *, null) = "any"
* StringUtils.replaceOnce("any", "", *) = "any"
* StringUtils.replaceOnce("aba", "a", null) = "aba"
* StringUtils.replaceOnce("aba", "a", "") = "ba"
* StringUtils.replaceOnce("aba", "a", "z") = "zba"
* </pre>
*
* @see #replace(String text, String searchString, String replacement, int max)
* @param text text to search and replace in, may be null
* @param searchString the String to search for, may be null
* @param replacement the String to replace with, may be null
* @return the text with any replacements processed,
* <code>null</code> if null String input
*/
public static String replaceOnce(String text, String searchString, String replacement) {
return replace(text, searchString, replacement, 1);
}
/**
* <p>Replaces all occurrences of a String within another String.</p>
*
* <p>A <code>null</code> reference passed to this method is a no-op.</p>
*
* <pre>
* StringUtils.replace(null, *, *) = null
* StringUtils.replace("", *, *) = ""
* StringUtils.replace("any", null, *) = "any"
* StringUtils.replace("any", *, null) = "any"
* StringUtils.replace("any", "", *) = "any"
* StringUtils.replace("aba", "a", null) = "aba"
* StringUtils.replace("aba", "a", "") = "b"
* StringUtils.replace("aba", "a", "z") = "zbz"
* </pre>
*
* @see #replace(String text, String searchString, String replacement, int max)
* @param text text to search and replace in, may be null
* @param searchString the String to search for, may be null
* @param replacement the String to replace it with, may be null
* @return the text with any replacements processed,
* <code>null</code> if null String input
*/
public static String replace(String text, String searchString, String replacement) {
return replace(text, searchString, replacement, -1);
}
/**
* <p>Replaces a String with another String inside a larger String,
* for the first <code>max</code> values of the search String.</p>
*
* <p>A <code>null</code> reference passed to this method is a no-op.</p>
*
* <pre>
* StringUtils.replace(null, *, *, *) = null
* StringUtils.replace("", *, *, *) = ""
* StringUtils.replace("any", null, *, *) = "any"
* StringUtils.replace("any", *, null, *) = "any"
* StringUtils.replace("any", "", *, *) = "any"
* StringUtils.replace("any", *, *, 0) = "any"
* StringUtils.replace("abaa", "a", null, -1) = "abaa"
* StringUtils.replace("abaa", "a", "", -1) = "b"
* StringUtils.replace("abaa", "a", "z", 0) = "abaa"
* StringUtils.replace("abaa", "a", "z", 1) = "zbaa"
* StringUtils.replace("abaa", "a", "z", 2) = "zbza"
* StringUtils.replace("abaa", "a", "z", -1) = "zbzz"
* </pre>
*
* @param text text to search and replace in, may be null
* @param searchString the String to search for, may be null
* @param replacement the String to replace it with, may be null
* @param max maximum number of values to replace, or <code>-1</code> if no maximum
* @return the text with any replacements processed,
* <code>null</code> if null String input
*/
public static String replace(String text, String searchString, String replacement, int max) {
if (isEmpty(text) || isEmpty(searchString) || replacement == null || max == 0) {
return text;
}
int start = 0;
int end = text.indexOf(searchString, start);
if (end == INDEX_NOT_FOUND) {
return text;
}
int replLength = searchString.length();
int increase = replacement.length() - replLength;
increase = (increase < 0 ? 0 : increase);
increase *= (max < 0 ? 16 : (max > 64 ? 64 : max));
StrBuilder buf = new StrBuilder(text.length() + increase);
while (end != INDEX_NOT_FOUND) {
buf.append(text.substring(start, end)).append(replacement);
start = end + replLength;
if (--max == 0) {
break;
}
end = text.indexOf(searchString, start);
}
buf.append(text.substring(start));
return buf.toString();
}
/**
* <p>
* Replaces all occurrences of Strings within another String.
* </p>
*
* <p>
* A <code>null</code> reference passed to this method is a no-op, or if
* any "search string" or "string to replace" is null, that replace will be
* ignored. This will not repeat. For repeating replaces, call the
* overloaded method.
* </p>
*
* <pre>
* StringUtils.replaceEach(null, *, *) = null
* StringUtils.replaceEach("", *, *) = ""
* StringUtils.replaceEach("aba", null, null) = "aba"
* StringUtils.replaceEach("aba", new String[0], null) = "aba"
* StringUtils.replaceEach("aba", null, new String[0]) = "aba"
* StringUtils.replaceEach("aba", new String[]{"a"}, null) = "aba"
* StringUtils.replaceEach("aba", new String[]{"a"}, new String[]{""}) = "b"
* StringUtils.replaceEach("aba", new String[]{null}, new String[]{"a"}) = "aba"
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"w", "t"}) = "wcte"
* (example of how it does not repeat)
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"d", "t"}) = "dcte"
* </pre>
*
* @param text
* text to search and replace in, no-op if null
* @param searchList
* the Strings to search for, no-op if null
* @param replacementList
* the Strings to replace them with, no-op if null
* @return the text with any replacements processed, <code>null</code> if
* null String input
* @throws IndexOutOfBoundsException
* if the lengths of the arrays are not the same (null is ok,
* and/or size 0)
* @since 2.4
*/
public static String replaceEach(String text, String[] searchList, String[] replacementList) {
return replaceEach(text, searchList, replacementList, false, 0);
}
/**
* <p>
* Replaces all occurrences of Strings within another String.
* </p>
*
* <p>
* A <code>null</code> reference passed to this method is a no-op, or if
* any "search string" or "string to replace" is null, that replace will be
* ignored. This will not repeat. For repeating replaces, call the
* overloaded method.
* </p>
*
* <pre>
* StringUtils.replaceEach(null, *, *, *) = null
* StringUtils.replaceEach("", *, *, *) = ""
* StringUtils.replaceEach("aba", null, null, *) = "aba"
* StringUtils.replaceEach("aba", new String[0], null, *) = "aba"
* StringUtils.replaceEach("aba", null, new String[0], *) = "aba"
* StringUtils.replaceEach("aba", new String[]{"a"}, null, *) = "aba"
* StringUtils.replaceEach("aba", new String[]{"a"}, new String[]{""}, *) = "b"
* StringUtils.replaceEach("aba", new String[]{null}, new String[]{"a"}, *) = "aba"
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"w", "t"}, *) = "wcte"
* (example of how it repeats)
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"d", "t"}, false) = "dcte"
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"d", "t"}, true) = "tcte"
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"d", "ab"}, true) = IllegalArgumentException
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"d", "ab"}, false) = "dcabe"
* </pre>
*
* @param text
* text to search and replace in, no-op if null
* @param searchList
* the Strings to search for, no-op if null
* @param replacementList
* the Strings to replace them with, no-op if null
* @return the text with any replacements processed, <code>null</code> if
* null String input
* @throws IllegalArgumentException
* if the search is repeating and there is an endless loop due
* to outputs of one being inputs to another
* @throws IndexOutOfBoundsException
* if the lengths of the arrays are not the same (null is ok,
* and/or size 0)
* @since 2.4
*/
public static String replaceEachRepeatedly(String text, String[] searchList, String[] replacementList) {
// timeToLive should be 0 if not used or nothing to replace, else it''s
// the length of the replace array
int timeToLive = searchList == null ? 0 : searchList.length;
return replaceEach(text, searchList, replacementList, true, timeToLive);
}
/**
* <p>
* Replaces all occurrences of Strings within another String.
* </p>
*
* <p>
* A <code>null</code> reference passed to this method is a no-op, or if
* any "search string" or "string to replace" is null, that replace will be
* ignored.
* </p>
*
* <pre>
* StringUtils.replaceEach(null, *, *, *) = null
* StringUtils.replaceEach("", *, *, *) = ""
* StringUtils.replaceEach("aba", null, null, *) = "aba"
* StringUtils.replaceEach("aba", new String[0], null, *) = "aba"
* StringUtils.replaceEach("aba", null, new String[0], *) = "aba"
* StringUtils.replaceEach("aba", new String[]{"a"}, null, *) = "aba"
* StringUtils.replaceEach("aba", new String[]{"a"}, new String[]{""}, *) = "b"
* StringUtils.replaceEach("aba", new String[]{null}, new String[]{"a"}, *) = "aba"
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"w", "t"}, *) = "wcte"
* (example of how it repeats)
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"d", "t"}, false) = "dcte"
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"d", "t"}, true) = "tcte"
* StringUtils.replaceEach("abcde", new String[]{"ab", "d"}, new String[]{"d", "ab"}, *) = IllegalArgumentException
* </pre>
*
* @param text
* text to search and replace in, no-op if null
* @param searchList
* the Strings to search for, no-op if null
* @param replacementList
* the Strings to replace them with, no-op if null
* @param repeat if true, then replace repeatedly
* until there are no more possible replacements or timeToLive < 0
* @param timeToLive
* if less than 0 then there is a circular reference and endless
* loop
* @return the text with any replacements processed, <code>null</code> if
* null String input
* @throws IllegalArgumentException
* if the search is repeating and there is an endless loop due
* to outputs of one being inputs to another
* @throws IndexOutOfBoundsException
* if the lengths of the arrays are not the same (null is ok,
* and/or size 0)
* @since 2.4
*/
private static String replaceEach(String text, String[] searchList, String[] replacementList,
boolean repeat, int timeToLive)
{
// mchyzer Performance note: This creates very few new objects (one major goal)
// let me know if there are performance requests, we can create a harness to measure
if (text == null || text.length() == 0 || searchList == null ||
searchList.length == 0 || replacementList == null || replacementList.length == 0)
{
return text;
}
// if recursing, this shouldnt be less than 0
if (timeToLive < 0) {
throw new IllegalStateException("TimeToLive of " + timeToLive + " is less than 0: " + text);
}
int searchLength = searchList.length;
int replacementLength = replacementList.length;
// make sure lengths are ok, these need to be equal
if (searchLength != replacementLength) {
throw new IllegalArgumentException("Search and Replace array lengths don''t match: "
+ searchLength
+ " vs "
+ replacementLength);
}
// keep track of which still have matches
boolean[] noMoreMatchesForReplIndex = new boolean[searchLength];
// index on index that the match was found
int textIndex = -1;
int replaceIndex = -1;
int tempIndex = -1;
// index of replace array that will replace the search string found
// NOTE: logic duplicated below START
for (int i = 0; i < searchLength; i++) {
if (noMoreMatchesForReplIndex[i] || searchList[i] == null ||
searchList[i].length() == 0 || replacementList[i] == null)
{
continue;
}
tempIndex = text.indexOf(searchList[i]);
// see if we need to keep searching for this
if (tempIndex == -1) {
noMoreMatchesForReplIndex[i] = true;
} else {
if (textIndex == -1 || tempIndex < textIndex) {
textIndex = tempIndex;
replaceIndex = i;
}
}
}
// NOTE: logic mostly below END
// no search strings found, we are done
if (textIndex == -1) {
return text;
}
int start = 0;
// get a good guess on the size of the result buffer so it doesnt have to double if it goes over a bit
int increase = 0;
// count the replacement text elements that are larger than their corresponding text being replaced
for (int i = 0; i < searchList.length; i++) {
if (searchList[i] == null || replacementList[i] == null) {
continue;
}
int greater = replacementList[i].length() - searchList[i].length();
if (greater > 0) {
increase += 3 * greater; // assume 3 matches
}
}
// have upper-bound at 20% increase, then let Java take over
increase = Math.min(increase, text.length() / 5);
StrBuilder buf = new StrBuilder(text.length() + increase);
while (textIndex != -1) {
for (int i = start; i < textIndex; i++) {
buf.append(text.charAt(i));
}
buf.append(replacementList[replaceIndex]);
start = textIndex + searchList[replaceIndex].length();
textIndex = -1;
replaceIndex = -1;
tempIndex = -1;
// find the next earliest match
// NOTE: logic mostly duplicated above START
for (int i = 0; i < searchLength; i++) {
if (noMoreMatchesForReplIndex[i] || searchList[i] == null ||
searchList[i].length() == 0 || replacementList[i] == null)
{
continue;
}
tempIndex = text.indexOf(searchList[i], start);
// see if we need to keep searching for this
if (tempIndex == -1) {
noMoreMatchesForReplIndex[i] = true;
} else {
if (textIndex == -1 || tempIndex < textIndex) {
textIndex = tempIndex;
replaceIndex = i;
}
}
}
// NOTE: logic duplicated above END
}
int textLength = text.length();
for (int i = start; i < textLength; i++) {
buf.append(text.charAt(i));
}
String result = buf.toString();
if (!repeat) {
return result;
}
return replaceEach(result, searchList, replacementList, repeat, timeToLive - 1);
}
// Replace, character based
//-----------------------------------------------------------------------
/**
* <p>Replaces all occurrences of a character in a String with another.
* This is a null-safe version of {@link String#replace(char, char)}.</p>
*
* <p>A <code>null</code> string input returns <code>null</code>.
* An empty ("") string input returns an empty string.</p>
*
* <pre>
* StringUtils.replaceChars(null, *, *) = null
* StringUtils.replaceChars("", *, *) = ""
* StringUtils.replaceChars("abcba", ''b'', ''y'') = "aycya"
* StringUtils.replaceChars("abcba", ''z'', ''y'') = "abcba"
* </pre>
*
* @param str String to replace characters in, may be null
* @param searchChar the character to search for, may be null
* @param replaceChar the character to replace, may be null
* @return modified String, <code>null</code> if null string input
* @since 2.0
*/
public static String replaceChars(String str, char searchChar, char replaceChar) {
if (str == null) {
return null;
}
return str.replace(searchChar, replaceChar);
}
/**
* <p>Replaces multiple characters in a String in one go.
* This method can also be used to delete characters.</p>
*
* <p>For example:<br />
* <code>replaceChars("hello", "ho", "jy") = jelly</code>.</p>
*
* <p>A <code>null</code> string input returns <code>null</code>.
* An empty ("") string input returns an empty string.
* A null or empty set of search characters returns the input string.</p>
*
* <p>The length of the search characters should normally equal the length
* of the replace characters.
* If the search characters is longer, then the extra search characters
* are deleted.
* If the search characters is shorter, then the extra replace characters
* are ignored.</p>
*
* <pre>
* StringUtils.replaceChars(null, *, *) = null
* StringUtils.replaceChars("", *, *) = ""
* StringUtils.replaceChars("abc", null, *) = "abc"
* StringUtils.replaceChars("abc", "", *) = "abc"
* StringUtils.replaceChars("abc", "b", null) = "ac"
* StringUtils.replaceChars("abc", "b", "") = "ac"
* StringUtils.replaceChars("abcba", "bc", "yz") = "ayzya"
* StringUtils.replaceChars("abcba", "bc", "y") = "ayya"
* StringUtils.replaceChars("abcba", "bc", "yzx") = "ayzya"
* </pre>
*
* @param str String to replace characters in, may be null
* @param searchChars a set of characters to search for, may be null
* @param replaceChars a set of characters to replace, may be null
* @return modified String, <code>null</code> if null string input
* @since 2.0
*/
public static String replaceChars(String str, String searchChars, String replaceChars) {
if (isEmpty(str) || isEmpty(searchChars)) {
return str;
}
if (replaceChars == null) {
replaceChars = EMPTY;
}
boolean modified = false;
int replaceCharsLength = replaceChars.length();
int strLength = str.length();
StrBuilder buf = new StrBuilder(strLength);
for (int i = 0; i < strLength; i++) {
char ch = str.charAt(i);
int index = searchChars.indexOf(ch);
if (index >= 0) {
modified = true;
if (index < replaceCharsLength) {
buf.append(replaceChars.charAt(index));
}
} else {
buf.append(ch);
}
}
if (modified) {
return buf.toString();
}
return str;
}
// Overlay
//-----------------------------------------------------------------------
/**
* <p>Overlays part of a String with another String.</p>
*
* <pre>
* StringUtils.overlayString(null, *, *, *) = NullPointerException
* StringUtils.overlayString(*, null, *, *) = NullPointerException
* StringUtils.overlayString("", "abc", 0, 0) = "abc"
* StringUtils.overlayString("abcdef", null, 2, 4) = "abef"
* StringUtils.overlayString("abcdef", "", 2, 4) = "abef"
* StringUtils.overlayString("abcdef", "zzzz", 2, 4) = "abzzzzef"
* StringUtils.overlayString("abcdef", "zzzz", 4, 2) = "abcdzzzzcdef"
* StringUtils.overlayString("abcdef", "zzzz", -1, 4) = IndexOutOfBoundsException
* StringUtils.overlayString("abcdef", "zzzz", 2, 8) = IndexOutOfBoundsException
* </pre>
*
* @param text the String to do overlaying in, may be null
* @param overlay the String to overlay, may be null
* @param start the position to start overlaying at, must be valid
* @param end the position to stop overlaying before, must be valid
* @return overlayed String, <code>null</code> if null String input
* @throws NullPointerException if text or overlay is null
* @throws IndexOutOfBoundsException if either position is invalid
* @deprecated Use better named {@link #overlay(String, String, int, int)} instead.
* Method will be removed in Commons Lang 3.0.
*/
public static String overlayString(String text, String overlay, int start, int end) {
return new StrBuilder(start + overlay.length() + text.length() - end + 1)
.append(text.substring(0, start))
.append(overlay)
.append(text.substring(end))
.toString();
}
/**
* <p>Overlays part of a String with another String.</p>
*
* <p>A <code>null</code> string input returns <code>null</code>.
* A negative index is treated as zero.
* An index greater than the string length is treated as the string length.
* The start index is always the smaller of the two indices.</p>
*
* <pre>
* StringUtils.overlay(null, *, *, *) = null
* StringUtils.overlay("", "abc", 0, 0) = "abc"
* StringUtils.overlay("abcdef", null, 2, 4) = "abef"
* StringUtils.overlay("abcdef", "", 2, 4) = "abef"
* StringUtils.overlay("abcdef", "", 4, 2) = "abef"
* StringUtils.overlay("abcdef", "zzzz", 2, 4) = "abzzzzef"
* StringUtils.overlay("abcdef", "zzzz", 4, 2) = "abzzzzef"
* StringUtils.overlay("abcdef", "zzzz", -1, 4) = "zzzzef"
* StringUtils.overlay("abcdef", "zzzz", 2, 8) = "abzzzz"
* StringUtils.overlay("abcdef", "zzzz", -2, -3) = "zzzzabcdef"
* StringUtils.overlay("abcdef", "zzzz", 8, 10) = "abcdefzzzz"
* </pre>
*
* @param str the String to do overlaying in, may be null
* @param overlay the String to overlay, may be null
* @param start the position to start overlaying at
* @param end the position to stop overlaying before
* @return overlayed String, <code>null</code> if null String input
* @since 2.0
*/
public static String overlay(String str, String overlay, int start, int end) {
if (str == null) {
return null;
}
if (overlay == null) {
overlay = EMPTY;
}
int len = str.length();
if (start < 0) {
start = 0;
}
if (start > len) {
start = len;
}
if (end < 0) {
end = 0;
}
if (end > len) {
end = len;
}
if (start > end) {
int temp = start;
start = end;
end = temp;
}
return new StrBuilder(len + start - end + overlay.length() + 1)
.append(str.substring(0, start))
.append(overlay)
.append(str.substring(end))
.toString();
}
// Chomping
//-----------------------------------------------------------------------
/**
* <p>Removes one newline from end of a String if it''s there,
* otherwise leave it alone. A newline is "<code>\n</code>",
* "<code>\r</code>", or "<code>\r\n</code>".</p>
*
* <p>NOTE: This method changed in 2.0.
* It now more closely matches Perl chomp.</p>
*
*<p>去除testString尾部的换行符.</p>
*
* <pre>
* StringUtils.chomp(null) = null
* StringUtils.chomp("") = ""
* StringUtils.chomp("abc \r") = "abc "
* StringUtils.chomp("abc\n") = "abc"
* StringUtils.chomp("abc\r\n") = "abc"
* StringUtils.chomp("abc\r\n\r\n") = "abc\r\n"
* StringUtils.chomp("abc\n\r") = "abc\n"
* StringUtils.chomp("abc\n\rabc") = "abc\n\rabc"
* StringUtils.chomp("\r") = ""
* StringUtils.chomp("\n") = ""
* StringUtils.chomp("\r\n") = ""
* </pre>
*
* @param str the String to chomp a newline from, may be null
* @return String without newline, <code>null</code> if null String input
*/
public static String chomp(String str) {
if (isEmpty(str)) {
return str;
}
if (str.length() == 1) {
char ch = str.charAt(0);
if (ch == CharUtils.CR || ch == CharUtils.LF) {
return EMPTY;
}
return str;
}
int lastIdx = str.length() - 1;
char last = str.charAt(lastIdx);
if (last == CharUtils.LF) {
if (str.charAt(lastIdx - 1) == CharUtils.CR) {
lastIdx--;
}
} else if (last != CharUtils.CR) {
lastIdx++;
}
return str.substring(0, lastIdx);
}
/**
* <p>Removes <code>separator</code> from the end of
* <code>str</code> if it''s there, otherwise leave it alone.</p>
*
* <p>NOTE: This method changed in version 2.0.
* It now more closely matches Perl chomp.
* For the previous behavior, use {@link #substringBeforeLast(String, String)}.
* This method uses {@link String#endsWith(String)}.</p>
*
* <pre>
* StringUtils.chomp(null, *) = null
* StringUtils.chomp("", *) = ""
* StringUtils.chomp("foobar", "bar") = "foo"
* StringUtils.chomp("foobar", "baz") = "foobar"
* StringUtils.chomp("foo", "foo") = ""
* StringUtils.chomp("foo ", "foo") = "foo "
* StringUtils.chomp(" foo", "foo") = " "
* StringUtils.chomp("foo", "foooo") = "foo"
* StringUtils.chomp("foo", "") = "foo"
* StringUtils.chomp("foo", null) = "foo"
* </pre>
*
* @param str the String to chomp from, may be null
* @param separator separator String, may be null
* @return String without trailing separator, <code>null</code> if null String input
*/
public static String chomp(String str, String separator) {
if (isEmpty(str) || separator == null) {
return str;
}
if (str.endsWith(separator)) {
return str.substring(0, str.length() - separator.length());
}
return str;
}
/**
* <p>Remove any "\n" if and only if it is at the end
* of the supplied String.</p>
*
* @param str the String to chomp from, must not be null
* @return String without chomped ending
* @throws NullPointerException if str is <code>null</code>
* @deprecated Use {@link #chomp(String)} instead.
* Method will be removed in Commons Lang 3.0.
*/
public static String chompLast(String str) {
return chompLast(str, "\n");
}
/**
* <p>Remove a value if and only if the String ends with that value.</p>
*
* @param str the String to chomp from, must not be null
* @param sep the String to chomp, must not be null
* @return String without chomped ending
* @throws NullPointerException if str or sep is <code>null</code>
* @deprecated Use {@link #chomp(String,String)} instead.
* Method will be removed in Commons Lang 3.0.
*/
public static String chompLast(String str, String sep) {
if (str.length() == 0) {
return str;
}
String sub = str.substring(str.length() - sep.length());
if (sep.equals(sub)) {
return str.substring(0, str.length() - sep.length());
}
return str;
}
/**
* <p>Remove everything and return the last value of a supplied String, and
* everything after it from a String.</p>
*
* @param str the String to chomp from, must not be null
* @param sep the String to chomp, must not be null
* @return String chomped
* @throws NullPointerException if str or sep is <code>null</code>
* @deprecated Use {@link #substringAfterLast(String, String)} instead
* (although this doesn''t include the separator)
* Method will be removed in Commons Lang 3.0.
*/
public static String getChomp(String str, String sep) {
int idx = str.lastIndexOf(sep);
if (idx == str.length() - sep.length()) {
return sep;
} else if (idx != -1) {
return str.substring(idx);
} else {
return EMPTY;
}
}
/**
* <p>Remove the first value of a supplied String, and everything before it
* from a String.</p>
*
* @param str the String to chomp from, must not be null
* @param sep the String to chomp, must not be null
* @return String without chomped beginning
* @throws NullPointerException if str or sep is <code>null</code>
* @deprecated Use {@link #substringAfter(String,String)} instead.
* Method will be removed in Commons Lang 3.0.
*/
public static String prechomp(String str, String sep) {
int idx = str.indexOf(sep);
if (idx == -1) {
return str;
}
return str.substring(idx + sep.length());
}
/**
* <p>Remove and return everything before the first value of a
* supplied String from another String.</p>
*
* @param str the String to chomp from, must not be null
* @param sep the String to chomp, must not be null
* @return String prechomped
* @throws NullPointerException if str or sep is <code>null</code>
* @deprecated Use {@link #substringBefore(String,String)} instead
* (although this doesn''t include the separator).
* Method will be removed in Commons Lang 3.0.
*/
public static String getPrechomp(String str, String sep) {
int idx = str.indexOf(sep);
if (idx == -1) {
return EMPTY;
}
return str.substring(0, idx + sep.length());
}
// Chopping
//-----------------------------------------------------------------------
/**
* <p>Remove the last character from a String.</p>
*
* <p>If the String ends in <code>\r\n</code>, then remove both
* of them.</p>
*
* <pre>
* StringUtils.chop(null) = null
* StringUtils.chop("") = ""
* StringUtils.chop("abc \r") = "abc "
* StringUtils.chop("abc\n") = "abc"
* StringUtils.chop("abc\r\n") = "abc"
* StringUtils.chop("abc") = "ab"
* StringUtils.chop("abc\nabc") = "abc\nab"
* StringUtils.chop("a") = ""
* StringUtils.chop("\r") = ""
* StringUtils.chop("\n") = ""
* StringUtils.chop("\r\n") = ""
* </pre>
*
* @param str the String to chop last character from, may be null
* @return String without last character, <code>null</code> if null String input
*/
public static String chop(String str) {
if (str == null) {
return null;
}
int strLen = str.length();
if (strLen < 2) {
return EMPTY;
}
int lastIdx = strLen - 1;
String ret = str.substring(0, lastIdx);
char last = str.charAt(lastIdx);
if (last == CharUtils.LF) {
if (ret.charAt(lastIdx - 1) == CharUtils.CR) {
return ret.substring(0, lastIdx - 1);
}
}
return ret;
}
/**
* <p>Removes <code>\n</code> from end of a String if it''s there.
* If a <code>\r</code> precedes it, then remove that too.</p>
*
* @param str the String to chop a newline from, must not be null
* @return String without newline
* @throws NullPointerException if str is <code>null</code>
* @deprecated Use {@link #chomp(String)} instead.
* Method will be removed in Commons Lang 3.0.
*/
public static String chopNewline(String str) {
int lastIdx = str.length() - 1;
if (lastIdx <= 0) {
return EMPTY;
}
char last = str.charAt(lastIdx);
if (last == CharUtils.LF) {
if (str.charAt(lastIdx - 1) == CharUtils.CR) {
lastIdx--;
}
} else {
lastIdx++;
}
return str.substring(0, lastIdx);
}
// Conversion
//-----------------------------------------------------------------------
/**
* <p>Escapes any values it finds into their String form.</p>
*
* <p>So a tab becomes the characters <code>''\\''</code> and
* <code>''t''</code>.</p>
*
* <p>As of Lang 2.0, this calls {@link StringEscapeUtils#escapeJava(String)}
* behind the scenes.
* </p>
* @see StringEscapeUtils#escapeJava(java.lang.String)
* @param str String to escape values in
* @return String with escaped values
* @throws NullPointerException if str is <code>null</code>
* @deprecated Use {@link StringEscapeUtils#escapeJava(String)}
* This method will be removed in Commons Lang 3.0
*/
public static String escape(String str) {
return StringEscapeUtils.escapeJava(str);
}
// Padding
//-----------------------------------------------------------------------
/**
* <p>Repeat a String <code>repeat</code> times to form a
* new String.</p>
*
*<p>得到将repeatString重复count次后的字符串.</p>
*
* <pre>
* StringUtils.repeat(null, 2) = null
* StringUtils.repeat("", 0) = ""
* StringUtils.repeat("", 2) = ""
* StringUtils.repeat("a", 3) = "aaa"
* StringUtils.repeat("ab", 2) = "abab"
* StringUtils.repeat("a", -2) = ""
* </pre>
*
* @param str the String to repeat, may be null
* @param repeat number of times to repeat str, negative treated as zero
* @return a new String consisting of the original String repeated,
* <code>null</code> if null String input
*/
public static String repeat(String str, int repeat) {
// Performance tuned for 2.0 (JDK1.4)
if (str == null) {
return null;
}
if (repeat <= 0) {
return EMPTY;
}
int inputLength = str.length();
if (repeat == 1 || inputLength == 0) {
return str;
}
if (inputLength == 1 && repeat <= PAD_LIMIT) {
return padding(repeat, str.charAt(0));
}
int outputLength = inputLength * repeat;
switch (inputLength) {
case 1 :
char ch = str.charAt(0);
char[] output1 = new char[outputLength];
for (int i = repeat - 1; i >= 0; i--) {
output1[i] = ch;
}
return new String(output1);
case 2 :
char ch0 = str.charAt(0);
char ch1 = str.charAt(1);
char[] output2 = new char[outputLength];
for (int i = repeat * 2 - 2; i >= 0; i--, i--) {
output2[i] = ch0;
output2[i + 1] = ch1;
}
return new String(output2);
default :
StrBuilder buf = new StrBuilder(outputLength);
for (int i = 0; i < repeat; i++) {
buf.append(str);
}
return buf.toString();
}
}
/**
* <p>Repeat a String <code>repeat</code> times to form a
* new String, with a String separator injected each time. </p>
*
* <pre>
* StringUtils.repeat(null, null, 2) = null
* StringUtils.repeat(null, "x", 2) = null
* StringUtils.repeat("", null, 0) = ""
* StringUtils.repeat("", "", 2) = ""
* StringUtils.repeat("", "x", 3) = "xxx"
* StringUtils.repeat("?", ", ", 3) = "?, ?, ?"
* </pre>
*
* @param str the String to repeat, may be null
* @param separator the String to inject, may be null
* @param repeat number of times to repeat str, negative treated as zero
* @return a new String consisting of the original String repeated,
* <code>null</code> if null String input
* @since 2.5
*/
public static String repeat(String str, String separator, int repeat) {
if(str == null || separator == null) {
return repeat(str, repeat);
} else {
// given that repeat(String, int) is quite optimized, better to rely on it than try and splice this into it
String result = repeat(str + separator, repeat);
return removeEnd(result, separator);
}
}
/**
* <p>Returns padding using the specified delimiter repeated
* to a given length.</p>
*
* <pre>
* StringUtils.padding(0, ''e'') = ""
* StringUtils.padding(3, ''e'') = "eee"
* StringUtils.padding(-2, ''e'') = IndexOutOfBoundsException
* </pre>
*
* <p>Note: this method doesn''t not support padding with
* <a href="http://www.unicode.org/glossary/#supplementary_character">Unicode Supplementary Characters</a>
* as they require a pair of <code>char</code>s to be represented.
* If you are needing to support full I18N of your applications
* consider using {@link #repeat(String, int)} instead.
* </p>
*
* @param repeat number of times to repeat delim
* @param padChar character to repeat
* @return String with repeated character
* @throws IndexOutOfBoundsException if <code>repeat < 0</code>
* @see #repeat(String, int)
*/
private static String padding(int repeat, char padChar) throws IndexOutOfBoundsException {
if (repeat < 0) {
throw new IndexOutOfBoundsException("Cannot pad a negative amount: " + repeat);
}
final char[] buf = new char[repeat];
for (int i = 0; i < buf.length; i++) {
buf[i] = padChar;
}
return new String(buf);
}
/**
* <p>Right pad a String with spaces ('' '').</p>
*
* <p>The String is padded to the size of <code>size</code>.</p>
*
* <pre>
* StringUtils.rightPad(null, *) = null
* StringUtils.rightPad("", 3) = " "
* StringUtils.rightPad("bat", 3) = "bat"
* StringUtils.rightPad("bat", 5) = "bat "
* StringUtils.rightPad("bat", 1) = "bat"
* StringUtils.rightPad("bat", -1) = "bat"
* </pre>
*
* @param str the String to pad out, may be null
* @param size the size to pad to
* @return right padded String or original String if no padding is necessary,
* <code>null</code> if null String input
*/
public static String rightPad(String str, int size) {
return rightPad(str, size, '' '');
}
/**
* <p>Right pad a String with a specified character.</p>
*
* <p>The String is padded to the size of <code>size</code>.</p>
*
* <pre>
* StringUtils.rightPad(null, *, *) = null
* StringUtils.rightPad("", 3, ''z'') = "zzz"
* StringUtils.rightPad("bat", 3, ''z'') = "bat"
* StringUtils.rightPad("bat", 5, ''z'') = "batzz"
* StringUtils.rightPad("bat", 1, ''z'') = "bat"
* StringUtils.rightPad("bat", -1, ''z'') = "bat"
* </pre>
*
* @param str the String to pad out, may be null
* @param size the size to pad to
* @param padChar the character to pad with
* @return right padded String or original String if no padding is necessary,
* <code>null</code> if null String input
* @since 2.0
*/
public static String rightPad(String str, int size, char padChar) {
if (str == null) {
return null;
}
int pads = size - str.length();
if (pads <= 0) {
return str; // returns original String when possible
}
if (pads > PAD_LIMIT) {
return rightPad(str, size, String.valueOf(padChar));
}
return str.concat(padding(pads, padChar));
}
/**
* <p>Right pad a String with a specified String.</p>
*
* <p>The String is padded to the size of <code>size</code>.</p>
*
* <pre>
* StringUtils.rightPad(null, *, *) = null
* StringUtils.rightPad("", 3, "z") = "zzz"
* StringUtils.rightPad("bat", 3, "yz") = "bat"
* StringUtils.rightPad("bat", 5, "yz") = "batyz"
* StringUtils.rightPad("bat", 8, "yz") = "batyzyzy"
* StringUtils.rightPad("bat", 1, "yz") = "bat"
* StringUtils.rightPad("bat", -1, "yz") = "bat"
* StringUtils.rightPad("bat", 5, null) = "bat "
* StringUtils.rightPad("bat", 5, "") = "bat "
* </pre>
*
* @param str the String to pad out, may be null
* @param size the size to pad to
* @param padStr the String to pad with, null or empty treated as single space
* @return right padded String or original String if no padding is necessary,
* <code>null</code> if null String input
*/
public static String rightPad(String str, int size, String padStr) {
if (str == null) {
return null;
}
if (isEmpty(padStr)) {
padStr = " ";
}
int padLen = padStr.length();
int strLen = str.length();
int pads = size - strLen;
if (pads <= 0) {
return str; // returns original String when possible
}
if (padLen == 1 && pads <= PAD_LIMIT) {
return rightPad(str, size, padStr.charAt(0));
}
if (pads == padLen) {
return str.concat(padStr);
} else if (pads < padLen) {
return str.concat(padStr.substring(0, pads));
} else {
char[] padding = new char[pads];
char[] padChars = padStr.toCharArray();
for (int i = 0; i < pads; i++) {
padding[i] = padChars[i % padLen];
}
return str.concat(new String(padding));
}
}
/**
* <p>Left pad a String with spaces ('' '').</p>
*
* <p>The String is padded to the size of <code>size</code>.</p>
*
* <pre>
* StringUtils.leftPad(null, *) = null
* StringUtils.leftPad("", 3) = " "
* StringUtils.leftPad("bat", 3) = "bat"
* StringUtils.leftPad("bat", 5) = " bat"
* StringUtils.leftPad("bat", 1) = "bat"
* StringUtils.leftPad("bat", -1) = "bat"
* </pre>
*
* @param str the String to pad out, may be null
* @param size the size to pad to
* @return left padded String or original String if no padding is necessary,
* <code>null</code> if null String input
*/
public static String leftPad(String str, int size) {
return leftPad(str, size, '' '');
}
/**
* <p>Left pad a String with a specified character.</p>
*
* <p>Pad to a size of <code>size</code>.</p>
*
* <pre>
* StringUtils.leftPad(null, *, *) = null
* StringUtils.leftPad("", 3, ''z'') = "zzz"
* StringUtils.leftPad("bat", 3, ''z'') = "bat"
* StringUtils.leftPad("bat", 5, ''z'') = "zzbat"
* StringUtils.leftPad("bat", 1, ''z'') = "bat"
* StringUtils.leftPad("bat", -1, ''z'') = "bat"
* </pre>
*
* @param str the String to pad out, may be null
* @param size the size to pad to
* @param padChar the character to pad with
* @return left padded String or original String if no padding is necessary,
* <code>null</code> if null String input
* @since 2.0
*/
public static String leftPad(String str, int size, char padChar) {
if (str == null) {
return null;
}
int pads = size - str.length();
if (pads <= 0) {
return str; // returns original String when possible
}
if (pads > PAD_LIMIT) {
return leftPad(str, size, String.valueOf(padChar));
}
return padding(pads, padChar).concat(str);
}
/**
* <p>Left pad a String with a specified String.</p>
*
* <p>Pad to a size of <code>size</code>.</p>
*
* <pre>
* StringUtils.leftPad(null, *, *) = null
* StringUtils.leftPad("", 3, "z") = "zzz"
* StringUtils.leftPad("bat", 3, "yz") = "bat"
* StringUtils.leftPad("bat", 5, "yz") = "yzbat"
* StringUtils.leftPad("bat", 8, "yz") = "yzyzybat"
* StringUtils.leftPad("bat", 1, "yz") = "bat"
* StringUtils.leftPad("bat", -1, "yz") = "bat"
* StringUtils.leftPad("bat", 5, null) = " bat"
* StringUtils.leftPad("bat", 5, "") = " bat"
* </pre>
*
* @param str the String to pad out, may be null
* @param size the size to pad to
* @param padStr the String to pad with, null or empty treated as single space
* @return left padded String or original String if no padding is necessary,
* <code>null</code> if null String input
*/
public static String leftPad(String str, int size, String padStr) {
if (str == null) {
return null;
}
if (isEmpty(padStr)) {
padStr = " ";
}
int padLen = padStr.length();
int strLen = str.length();
int pads = size - strLen;
if (pads <= 0) {
return str; // returns original String when possible
}
if (padLen == 1 && pads <= PAD_LIMIT) {
return leftPad(str, size, padStr.charAt(0));
}
if (pads == padLen) {
return padStr.concat(str);
} else if (pads < padLen) {
return padStr.substring(0, pads).concat(str);
} else {
char[] padding = new char[pads];
char[] padChars = padStr.toCharArray();
for (int i = 0; i < pads; i++) {
padding[i] = padChars[i % padLen];
}
return new String(padding).concat(str);
}
}
/**
* Gets a String''s length or <code>0</code> if the String is <code>null</code>.
*
* @param str
* a String or <code>null</code>
* @return String length or <code>0</code> if the String is <code>null</code>.
* @since 2.4
*/
public static int length(String str) {
return str == null ? 0 : str.length();
}
// Centering
//-----------------------------------------------------------------------
/**
* <p>Centers a String in a larger String of size <code>size</code>
* using the space character ('' '').<p>
*
* <p>If the size is less than the String length, the String is returned.
* A <code>null</code> String returns <code>null</code>.
* A negative size is treated as zero.</p>
*
* <p>Equivalent to <code>center(str, size, " ")</code>.</p>
*
* <pre>
* StringUtils.center(null, *) = null
* StringUtils.center("", 4) = " "
* StringUtils.center("ab", -1) = "ab"
* StringUtils.center("ab", 4) = " ab "
* StringUtils.center("abcd", 2) = "abcd"
* StringUtils.center("a", 4) = " a "
* </pre>
*
* @param str the String to center, may be null
* @param size the int size of new String, negative treated as zero
* @return centered String, <code>null</code> if null String input
*/
public static String center(String str, int size) {
return center(str, size, '' '');
}
/**
* <p>Centers a String in a larger String of size <code>size</code>.
* Uses a supplied character as the value to pad the String with.</p>
*
* <p>If the size is less than the String length, the String is returned.
* A <code>null</code> String returns <code>null</code>.
* A negative size is treated as zero.</p>
*
* <pre>
* StringUtils.center(null, *, *) = null
* StringUtils.center("", 4, '' '') = " "
* StringUtils.center("ab", -1, '' '') = "ab"
* StringUtils.center("ab", 4, '' '') = " ab"
* StringUtils.center("abcd", 2, '' '') = "abcd"
* StringUtils.center("a", 4, '' '') = " a "
* StringUtils.center("a", 4, ''y'') = "yayy"
* </pre>
*
* @param str the String to center, may be null
* @param size the int size of new String, negative treated as zero
* @param padChar the character to pad the new String with
* @return centered String, <code>null</code> if null String input
* @since 2.0
*/
public static String center(String str, int size, char padChar) {
if (str == null || size <= 0) {
return str;
}
int strLen = str.length();
int pads = size - strLen;
if (pads <= 0) {
return str;
}
str = leftPad(str, strLen + pads / 2, padChar);
str = rightPad(str, size, padChar);
return str;
}
/**
* <p>Centers a String in a larger String of size <code>size</code>.
* Uses a supplied String as the value to pad the String with.</p>
*
* <p>If the size is less than the String length, the String is returned.
* A <code>null</code> String returns <code>null</code>.
* A negative size is treated as zero.</p>
*
* <pre>
* StringUtils.center(null, *, *) = null
* StringUtils.center("", 4, " ") = " "
* StringUtils.center("ab", -1, " ") = "ab"
* StringUtils.center("ab", 4, " ") = " ab"
* StringUtils.center("abcd", 2, " ") = "abcd"
* StringUtils.center("a", 4, " ") = " a "
* StringUtils.center("a", 4, "yz") = "yayz"
* StringUtils.center("abc", 7, null) = " abc "
* StringUtils.center("abc", 7, "") = " abc "
* </pre>
*
* @param str the String to center, may be null
* @param size the int size of new String, negative treated as zero
* @param padStr the String to pad the new String with, must not be null or empty
* @return centered String, <code>null</code> if null String input
* @throws IllegalArgumentException if padStr is <code>null</code> or empty
*/
public static String center(String str, int size, String padStr) {
if (str == null || size <= 0) {
return str;
}
if (isEmpty(padStr)) {
padStr = " ";
}
int strLen = str.length();
int pads = size - strLen;
if (pads <= 0) {
return str;
}
str = leftPad(str, strLen + pads / 2, padStr);
str = rightPad(str, size, padStr);
return str;
}
// Case conversion
//-----------------------------------------------------------------------
/**
* <p>Converts a String to upper case as per {@link String#toUpperCase()}.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.upperCase(null) = null
* StringUtils.upperCase("") = ""
* StringUtils.upperCase("aBc") = "ABC"
* </pre>
*
* <p><strong>Note:</strong> As described in the documentation for {@link String#toUpperCase()},
* the result of this method is affected by the current locale.
* For platform-independent case transformations, the method {@link #lowerCase(String, Locale)}
* should be used with a specific locale (e.g. {@link Locale#ENGLISH}).</p>
*
* @param str the String to upper case, may be null
* @return the upper cased String, <code>null</code> if null String input
*/
public static String upperCase(String str) {
if (str == null) {
return null;
}
return str.toUpperCase();
}
/**
* <p>Converts a String to upper case as per {@link String#toUpperCase(Locale)}.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.upperCase(null, Locale.ENGLISH) = null
* StringUtils.upperCase("", Locale.ENGLISH) = ""
* StringUtils.upperCase("aBc", Locale.ENGLISH) = "ABC"
* </pre>
*
* @param str the String to upper case, may be null
* @param locale the locale that defines the case transformation rules, must not be null
* @return the upper cased String, <code>null</code> if null String input
* @since 2.5
*/
public static String upperCase(String str, Locale locale) {
if (str == null) {
return null;
}
return str.toUpperCase(locale);
}
/**
* <p>Converts a String to lower case as per {@link String#toLowerCase()}.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.lowerCase(null) = null
* StringUtils.lowerCase("") = ""
* StringUtils.lowerCase("aBc") = "abc"
* </pre>
*
* <p><strong>Note:</strong> As described in the documentation for {@link String#toLowerCase()},
* the result of this method is affected by the current locale.
* For platform-independent case transformations, the method {@link #lowerCase(String, Locale)}
* should be used with a specific locale (e.g. {@link Locale#ENGLISH}).</p>
*
* @param str the String to lower case, may be null
* @return the lower cased String, <code>null</code> if null String input
*/
public static String lowerCase(String str) {
if (str == null) {
return null;
}
return str.toLowerCase();
}
/**
* <p>Converts a String to lower case as per {@link String#toLowerCase(Locale)}.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.lowerCase(null, Locale.ENGLISH) = null
* StringUtils.lowerCase("", Locale.ENGLISH) = ""
* StringUtils.lowerCase("aBc", Locale.ENGLISH) = "abc"
* </pre>
*
* @param str the String to lower case, may be null
* @param locale the locale that defines the case transformation rules, must not be null
* @return the lower cased String, <code>null</code> if null String input
* @since 2.5
*/
public static String lowerCase(String str, Locale locale) {
if (str == null) {
return null;
}
return str.toLowerCase(locale);
}
/**
* <p>Capitalizes a String changing the first letter to title case as
* per {@link Character#toTitleCase(char)}. No other letters are changed.</p>
*
* <p>For a word based algorithm, see {@link WordUtils#capitalize(String)}.
* A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.capitalize(null) = null
* StringUtils.capitalize("") = ""
* StringUtils.capitalize("cat") = "Cat"
* StringUtils.capitalize("cAt") = "CAt"
* </pre>
*
* @param str the String to capitalize, may be null
* @return the capitalized String, <code>null</code> if null String input
* @see WordUtils#capitalize(String)
* @see #uncapitalize(String)
* @since 2.0
*/
public static String capitalize(String str) {
int strLen;
if (str == null || (strLen = str.length()) == 0) {
return str;
}
return new StrBuilder(strLen)
.append(Character.toTitleCase(str.charAt(0)))
.append(str.substring(1))
.toString();
}
/**
* <p>Capitalizes a String changing the first letter to title case as
* per {@link Character#toTitleCase(char)}. No other letters are changed.</p>
*
* @param str the String to capitalize, may be null
* @return the capitalized String, <code>null</code> if null String input
* @deprecated Use the standardly named {@link #capitalize(String)}.
* Method will be removed in Commons Lang 3.0.
*/
public static String capitalise(String str) {
return capitalize(str);
}
/**
* <p>Uncapitalizes a String changing the first letter to title case as
* per {@link Character#toLowerCase(char)}. No other letters are changed.</p>
*
* <p>For a word based algorithm, see {@link WordUtils#uncapitalize(String)}.
* A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.uncapitalize(null) = null
* StringUtils.uncapitalize("") = ""
* StringUtils.uncapitalize("Cat") = "cat"
* StringUtils.uncapitalize("CAT") = "cAT"
* </pre>
*
* @param str the String to uncapitalize, may be null
* @return the uncapitalized String, <code>null</code> if null String input
* @see WordUtils#uncapitalize(String)
* @see #capitalize(String)
* @since 2.0
*/
public static String uncapitalize(String str) {
int strLen;
if (str == null || (strLen = str.length()) == 0) {
return str;
}
return new StrBuilder(strLen)
.append(Character.toLowerCase(str.charAt(0)))
.append(str.substring(1))
.toString();
}
/**
* <p>Uncapitalizes a String changing the first letter to title case as
* per {@link Character#toLowerCase(char)}. No other letters are changed.</p>
*
* @param str the String to uncapitalize, may be null
* @return the uncapitalized String, <code>null</code> if null String input
* @deprecated Use the standardly named {@link #uncapitalize(String)}.
* Method will be removed in Commons Lang 3.0.
*/
public static String uncapitalise(String str) {
return uncapitalize(str);
}
/**
* <p>Swaps the case of a String changing upper and title case to
* lower case, and lower case to upper case.</p>
*
* <ul>
* <li>Upper case character converts to Lower case</li>
* <li>Title case character converts to Lower case</li>
* <li>Lower case character converts to Upper case</li>
* </ul>
*
* <p>For a word based algorithm, see {@link WordUtils#swapCase(String)}.
* A <code>null</code> input String returns <code>null</code>.</p>
*
* <pre>
* StringUtils.swapCase(null) = null
* StringUtils.swapCase("") = ""
* StringUtils.swapCase("The dog has a BONE") = "tHE DOG HAS A bone"
* </pre>
*
* <p>NOTE: This method changed in Lang version 2.0.
* It no longer performs a word based algorithm.
* If you only use ASCII, you will notice no change.
* That functionality is available in WordUtils.</p>
*
* @param str the String to swap case, may be null
* @return the changed String, <code>null</code> if null String input
*/
public static String swapCase(String str) {
int strLen;
if (str == null || (strLen = str.length()) == 0) {
return str;
}
StrBuilder buffer = new StrBuilder(strLen);
char ch = 0;
for (int i = 0; i < strLen; i++) {
ch = str.charAt(i);
if (Character.isUpperCase(ch)) {
ch = Character.toLowerCase(ch);
} else if (Character.isTitleCase(ch)) {
ch = Character.toLowerCase(ch);
} else if (Character.isLowerCase(ch)) {
ch = Character.toUpperCase(ch);
}
buffer.append(ch);
}
return buffer.toString();
}
/**
* <p>Capitalizes all the whitespace separated words in a String.
* Only the first letter of each word is changed.</p>
*
* <p>Whitespace is defined by {@link Character#isWhitespace(char)}.
* A <code>null</code> input String returns <code>null</code>.</p>
*
* @param str the String to capitalize, may be null
* @return capitalized String, <code>null</code> if null String input
* @deprecated Use the relocated {@link WordUtils#capitalize(String)}.
* Method will be removed in Commons Lang 3.0.
*/
public static String capitaliseAllWords(String str) {
return WordUtils.capitalize(str);
}
// Count matches
//-----------------------------------------------------------------------
/**
* <p>Counts how many times the substring appears in the larger String.</p>
*
* <p>A <code>null</code> or empty ("") String input returns <code>0</code>.</p>
*
*<p>取得seqString在testString中出现的次数,未发现则返回零</p>
*
* <pre>
* StringUtils.countMatches(null, *) = 0
* StringUtils.countMatches("", *) = 0
* StringUtils.countMatches("abba", null) = 0
* StringUtils.countMatches("abba", "") = 0
* StringUtils.countMatches("abba", "a") = 2
* StringUtils.countMatches("abba", "ab") = 1
* StringUtils.countMatches("abba", "xxx") = 0
* </pre>
*
* @param str the String to check, may be null
* @param sub the substring to count, may be null
* @return the number of occurrences, 0 if either String is <code>null</code>
*/
public static int countMatches(String str, String sub) {
if (isEmpty(str) || isEmpty(sub)) {
return 0;
}
int count = 0;
int idx = 0;
while ((idx = str.indexOf(sub, idx)) != INDEX_NOT_FOUND) {
count++;
idx += sub.length();
}
return count;
}
// Character Tests
//-----------------------------------------------------------------------
/**
* <p>Checks if the String contains only unicode letters.</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>true</code>.</p>
*
*<p>如果testString全由字母组成返回True.</p>
*
* <pre>
* StringUtils.isAlpha(null) = false
* StringUtils.isAlpha("") = true
* StringUtils.isAlpha(" ") = false
* StringUtils.isAlpha("abc") = true
* StringUtils.isAlpha("ab2c") = false
* StringUtils.isAlpha("ab-c") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains letters, and is non-null
*/
public static boolean isAlpha(String str) {
if (str == null) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if (Character.isLetter(str.charAt(i)) == false) {
return false;
}
}
return true;
}
/**
* <p>Checks if the String contains only unicode letters and
* space ('' '').</p>
*
* <p><code>null</code> will return <code>false</code>
* An empty String (length()=0) will return <code>true</code>.</p>
*
*<p>如果testString全由字母或空格组成返回True</p>
*
* <pre>
* StringUtils.isAlphaSpace(null) = false
* StringUtils.isAlphaSpace("") = true
* StringUtils.isAlphaSpace(" ") = true
* StringUtils.isAlphaSpace("abc") = true
* StringUtils.isAlphaSpace("ab c") = true
* StringUtils.isAlphaSpace("ab2c") = false
* StringUtils.isAlphaSpace("ab-c") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains letters and space,
* and is non-null
*/
public static boolean isAlphaSpace(String str) {
if (str == null) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if ((Character.isLetter(str.charAt(i)) == false) && (str.charAt(i) != '' '')) {
return false;
}
}
return true;
}
/**
* <p>Checks if the String contains only unicode letters or digits.</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>true</code>.</p>
*
*<p>如果testString全由数字或数字组成返回True</p>
*
* <pre>
* StringUtils.isAlphanumeric(null) = false
* StringUtils.isAlphanumeric("") = true
* StringUtils.isAlphanumeric(" ") = false
* StringUtils.isAlphanumeric("abc") = true
* StringUtils.isAlphanumeric("ab c") = false
* StringUtils.isAlphanumeric("ab2c") = true
* StringUtils.isAlphanumeric("ab-c") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains letters or digits,
* and is non-null
*/
public static boolean isAlphanumeric(String str) {
if (str == null) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if (Character.isLetterOrDigit(str.charAt(i)) == false) {
return false;
}
}
return true;
}
/**
* <p>Checks if the String contains only unicode letters, digits
* or space (<code>'' ''</code>).</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>true</code>.</p>
*
* <pre>
* StringUtils.isAlphanumeric(null) = false
* StringUtils.isAlphanumeric("") = true
* StringUtils.isAlphanumeric(" ") = true
* StringUtils.isAlphanumeric("abc") = true
* StringUtils.isAlphanumeric("ab c") = true
* StringUtils.isAlphanumeric("ab2c") = true
* StringUtils.isAlphanumeric("ab-c") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains letters, digits or space,
* and is non-null
*/
public static boolean isAlphanumericSpace(String str) {
if (str == null) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if ((Character.isLetterOrDigit(str.charAt(i)) == false) && (str.charAt(i) != '' '')) {
return false;
}
}
return true;
}
/**
* <p>Checks if the string contains only ASCII printable characters.</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>true</code>.</p>
*
* <pre>
* StringUtils.isAsciiPrintable(null) = false
* StringUtils.isAsciiPrintable("") = true
* StringUtils.isAsciiPrintable(" ") = true
* StringUtils.isAsciiPrintable("Ceki") = true
* StringUtils.isAsciiPrintable("ab2c") = true
* StringUtils.isAsciiPrintable("!ab-c~") = true
* StringUtils.isAsciiPrintable("\u0020") = true
* StringUtils.isAsciiPrintable("\u0021") = true
* StringUtils.isAsciiPrintable("\u007e") = true
* StringUtils.isAsciiPrintable("\u007f") = false
* StringUtils.isAsciiPrintable("Ceki G\u00fclc\u00fc") = false
* </pre>
*
* @param str the string to check, may be null
* @return <code>true</code> if every character is in the range
* 32 thru 126
* @since 2.1
*/
public static boolean isAsciiPrintable(String str) {
if (str == null) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if (CharUtils.isAsciiPrintable(str.charAt(i)) == false) {
return false;
}
}
return true;
}
/**
* <p>Checks if the String contains only unicode digits.
* A decimal point is not a unicode digit and returns false.</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>true</code>.</p>
*
*<p>如果testString全由数字组成返回True.</p>
*
* <pre>
* StringUtils.isNumeric(null) = false
* StringUtils.isNumeric("") = true
* StringUtils.isNumeric(" ") = false
* StringUtils.isNumeric("123") = true
* StringUtils.isNumeric("12 3") = false
* StringUtils.isNumeric("ab2c") = false
* StringUtils.isNumeric("12-3") = false
* StringUtils.isNumeric("12.3") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains digits, and is non-null
*/
public static boolean isNumeric(String str) {
if (str == null) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if (Character.isDigit(str.charAt(i)) == false) {
return false;
}
}
return true;
}
/**
* <p>Checks if the String contains only unicode digits or space
* (<code>'' ''</code>).
* A decimal point is not a unicode digit and returns false.</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>true</code>.</p>
*
* <pre>
* StringUtils.isNumeric(null) = false
* StringUtils.isNumeric("") = true
* StringUtils.isNumeric(" ") = true
* StringUtils.isNumeric("123") = true
* StringUtils.isNumeric("12 3") = true
* StringUtils.isNumeric("ab2c") = false
* StringUtils.isNumeric("12-3") = false
* StringUtils.isNumeric("12.3") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains digits or space,
* and is non-null
*/
public static boolean isNumericSpace(String str) {
if (str == null) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if ((Character.isDigit(str.charAt(i)) == false) && (str.charAt(i) != '' '')) {
return false;
}
}
return true;
}
/**
* <p>Checks if the String contains only whitespace.</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>true</code>.</p>
*
* <pre>
* StringUtils.isWhitespace(null) = false
* StringUtils.isWhitespace("") = true
* StringUtils.isWhitespace(" ") = true
* StringUtils.isWhitespace("abc") = false
* StringUtils.isWhitespace("ab2c") = false
* StringUtils.isWhitespace("ab-c") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains whitespace, and is non-null
* @since 2.0
*/
public static boolean isWhitespace(String str) {
if (str == null) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if ((Character.isWhitespace(str.charAt(i)) == false)) {
return false;
}
}
return true;
}
/**
* <p>Checks if the String contains only lowercase characters.</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>false</code>.</p>
*
* <pre>
* StringUtils.isAllLowerCase(null) = false
* StringUtils.isAllLowerCase("") = false
* StringUtils.isAllLowerCase(" ") = false
* StringUtils.isAllLowerCase("abc") = true
* StringUtils.isAllLowerCase("abC") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains lowercase characters, and is non-null
* @since 2.5
*/
public static boolean isAllLowerCase(String str) {
if (str == null || isEmpty(str)) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if (Character.isLowerCase(str.charAt(i)) == false) {
return false;
}
}
return true;
}
/**
* <p>Checks if the String contains only uppercase characters.</p>
*
* <p><code>null</code> will return <code>false</code>.
* An empty String (length()=0) will return <code>false</code>.</p>
*
* <pre>
* StringUtils.isAllUpperCase(null) = false
* StringUtils.isAllUpperCase("") = false
* StringUtils.isAllUpperCase(" ") = false
* StringUtils.isAllUpperCase("ABC") = true
* StringUtils.isAllUpperCase("aBC") = false
* </pre>
*
* @param str the String to check, may be null
* @return <code>true</code> if only contains uppercase characters, and is non-null
* @since 2.5
*/
public static boolean isAllUpperCase(String str) {
if (str == null || isEmpty(str)) {
return false;
}
int sz = str.length();
for (int i = 0; i < sz; i++) {
if (Character.isUpperCase(str.charAt(i)) == false) {
return false;
}
}
return true;
}
// Defaults
//-----------------------------------------------------------------------
/**
* <p>Returns either the passed in String,
* or if the String is <code>null</code>, an empty String ("").</p>
*
* <pre>
* StringUtils.defaultString(null) = ""
* StringUtils.defaultString("") = ""
* StringUtils.defaultString("bat") = "bat"
* </pre>
*
* @see ObjectUtils#toString(Object)
* @see String#valueOf(Object)
* @param str the String to check, may be null
* @return the passed in String, or the empty String if it
* was <code>null</code>
*/
public static String defaultString(String str) {
return str == null ? EMPTY : str;
}
/**
* <p>Returns either the passed in String, or if the String is
* <code>null</code>, the value of <code>defaultStr</code>.</p>
*
* <pre>
* StringUtils.defaultString(null, "NULL") = "NULL"
* StringUtils.defaultString("", "NULL") = ""
* StringUtils.defaultString("bat", "NULL") = "bat"
* </pre>
*
* @see ObjectUtils#toString(Object,String)
* @see String#valueOf(Object)
* @param str the String to check, may be null
* @param defaultStr the default String to return
* if the input is <code>null</code>, may be null
* @return the passed in String, or the default if it was <code>null</code>
*/
public static String defaultString(String str, String defaultStr) {
return str == null ? defaultStr : str;
}
/**
* <p>Returns either the passed in String, or if the String is
* whitespace, empty ("") or <code>null</code>, the value of <code>defaultStr</code>.</p>
*
* <pre>
* StringUtils.defaultIfBlank(null, "NULL") = "NULL"
* StringUtils.defaultIfBlank("", "NULL") = "NULL"
* StringUtils.defaultIfBlank(" ", "NULL") = "NULL"
* StringUtils.defaultIfBlank("bat", "NULL") = "bat"
* StringUtils.defaultIfBlank("", null) = null
* </pre>
* @param str the String to check, may be null
* @param defaultStr the default String to return
* if the input is whitespace, empty ("") or <code>null</code>, may be null
* @return the passed in String, or the default
* @see StringUtils#defaultString(String, String)
* @since 2.6
*/
public static String defaultIfBlank(String str, String defaultStr) {
return StringUtils.isBlank(str) ? defaultStr : str;
}
/**
* <p>Returns either the passed in String, or if the String is
* empty or <code>null</code>, the value of <code>defaultStr</code>.</p>
*
* <pre>
* StringUtils.defaultIfEmpty(null, "NULL") = "NULL"
* StringUtils.defaultIfEmpty("", "NULL") = "NULL"
* StringUtils.defaultIfEmpty("bat", "NULL") = "bat"
* StringUtils.defaultIfEmpty("", null) = null
* </pre>
*
* @param str the String to check, may be null
* @param defaultStr the default String to return
* if the input is empty ("") or <code>null</code>, may be null
* @return the passed in String, or the default
* @see StringUtils#defaultString(String, String)
*/
public static String defaultIfEmpty(String str, String defaultStr) {
return StringUtils.isEmpty(str) ? defaultStr : str;
}
// Reversing
//-----------------------------------------------------------------------
/**
* <p>Reverses a String as per {@link StrBuilder#reverse()}.</p>
*
* <p>A <code>null</code> String returns <code>null</code>.</p>
*
*<p>得到testString中字符颠倒后的字符串.</p>
*
* <pre>
* StringUtils.reverse(null) = null
* StringUtils.reverse("") = ""
* StringUtils.reverse("bat") = "tab"
* </pre>
*
* @param str the String to reverse, may be null
* @return the reversed String, <code>null</code> if null String input
*/
public static String reverse(String str) {
if (str == null) {
return null;
}
return new StrBuilder(str).reverse().toString();
}
/**
* <p>Reverses a String that is delimited by a specific character.</p>
*
* <p>The Strings between the delimiters are not reversed.
* Thus java.lang.String becomes String.lang.java (if the delimiter
* is <code>''.''</code>).</p>
*
* <pre>
* StringUtils.reverseDelimited(null, *) = null
* StringUtils.reverseDelimited("", *) = ""
* StringUtils.reverseDelimited("a.b.c", ''x'') = "a.b.c"
* StringUtils.reverseDelimited("a.b.c", ".") = "c.b.a"
* </pre>
*
* @param str the String to reverse, may be null
* @param separatorChar the separator character to use
* @return the reversed String, <code>null</code> if null String input
* @since 2.0
*/
public static String reverseDelimited(String str, char separatorChar) {
if (str == null) {
return null;
}
// could implement manually, but simple way is to reuse other,
// probably slower, methods.
String[] strs = split(str, separatorChar);
ArrayUtils.reverse(strs);
return join(strs, separatorChar);
}
/**
* <p>Reverses a String that is delimited by a specific character.</p>
*
* <p>The Strings between the delimiters are not reversed.
* Thus java.lang.String becomes String.lang.java (if the delimiter
* is <code>"."</code>).</p>
*
* <pre>
* StringUtils.reverseDelimitedString(null, *) = null
* StringUtils.reverseDelimitedString("",*) = ""
* StringUtils.reverseDelimitedString("a.b.c", null) = "a.b.c"
* StringUtils.reverseDelimitedString("a.b.c", ".") = "c.b.a"
* </pre>
*
* @param str the String to reverse, may be null
* @param separatorChars the separator characters to use, null treated as whitespace
* @return the reversed String, <code>null</code> if null String input
* @deprecated Use {@link #reverseDelimited(String, char)} instead.
* This method is broken as the join doesn''t know which char to use.
* Method will be removed in Commons Lang 3.0.
*
*/
public static String reverseDelimitedString(String str, String separatorChars) {
if (str == null) {
return null;
}
// could implement manually, but simple way is to reuse other,
// probably slower, methods.
String[] strs = split(str, separatorChars);
ArrayUtils.reverse(strs);
if (separatorChars == null) {
return join(strs, '' '');
}
return join(strs, separatorChars);
}
// Abbreviating
//-----------------------------------------------------------------------
/**
* <p>Abbreviates a String using ellipses. This will turn
* "Now is the time for all good men" into "Now is the time for..."</p>
*
* <p>Specifically:
* <ul>
* <li>If <code>str</code> is less than <code>maxWidth</code> characters
* long, return it.</li>
* <li>Else abbreviate it to <code>(substring(str, 0, max-3) + "...")</code>.</li>
* <li>If <code>maxWidth</code> is less than <code>4</code>, throw an
* <code>IllegalArgumentException</code>.</li>
* <li>In no case will it return a String of length greater than
* <code>maxWidth</code>.</li>
* </ul>
* </p>
*
* <p>在给定的width内取得testString的缩写,当testString的长度小于width则返回原字符串.</p>
*
* <pre>
* StringUtils.abbreviate(null, *) = null
* StringUtils.abbreviate("", 4) = ""
* StringUtils.abbreviate("abcdefg", 6) = "abc..."
* StringUtils.abbreviate("abcdefg", 7) = "abcdefg"
* StringUtils.abbreviate("abcdefg", 8) = "abcdefg"
* StringUtils.abbreviate("abcdefg", 4) = "a..."
* StringUtils.abbreviate("abcdefg", 3) = IllegalArgumentException
* </pre>
*
* @param str the String to check, may be null
* @param maxWidth maximum length of result String, must be at least 4
* @return abbreviated String, <code>null</code> if null String input
* @throws IllegalArgumentException if the width is too small
* @since 2.0
*/
public static String abbreviate(String str, int maxWidth) {
return abbreviate(str, 0, maxWidth);
}
/**
* <p>Abbreviates a String using ellipses. This will turn
* "Now is the time for all good men" into "...is the time for..."</p>
*
* <p>Works like <code>abbreviate(String, int)</code>, but allows you to specify
* a "left edge" offset. Note that this left edge is not necessarily going to
* be the leftmost character in the result, or the first character following the
* ellipses, but it will appear somewhere in the result.
*
* <p>In no case will it return a String of length greater than
* <code>maxWidth</code>.</p>
*
* <pre>
* StringUtils.abbreviate(null, *, *) = null
* StringUtils.abbreviate("", 0, 4) = ""
* StringUtils.abbreviate("abcdefghijklmno", -1, 10) = "abcdefg..."
* StringUtils.abbreviate("abcdefghijklmno", 0, 10) = "abcdefg..."
* StringUtils.abbreviate("abcdefghijklmno", 1, 10) = "abcdefg..."
* StringUtils.abbreviate("abcdefghijklmno", 4, 10) = "abcdefg..."
* StringUtils.abbreviate("abcdefghijklmno", 5, 10) = "...fghi..."
* StringUtils.abbreviate("abcdefghijklmno", 6, 10) = "...ghij..."
* StringUtils.abbreviate("abcdefghijklmno", 8, 10) = "...ijklmno"
* StringUtils.abbreviate("abcdefghijklmno", 10, 10) = "...ijklmno"
* StringUtils.abbreviate("abcdefghijklmno", 12, 10) = "...ijklmno"
* StringUtils.abbreviate("abcdefghij", 0, 3) = IllegalArgumentException
* StringUtils.abbreviate("abcdefghij", 5, 6) = IllegalArgumentException
* </pre>
*
* @param str the String to check, may be null
* @param offset left edge of source String
* @param maxWidth maximum length of result String, must be at least 4
* @return abbreviated String, <code>null</code> if null String input
* @throws IllegalArgumentException if the width is too small
* @since 2.0
*/
public static String abbreviate(String str, int offset, int maxWidth) {
if (str == null) {
return null;
}
if (maxWidth < 4) {
throw new IllegalArgumentException("Minimum abbreviation width is 4");
}
if (str.length() <= maxWidth) {
return str;
}
if (offset > str.length()) {
offset = str.length();
}
if ((str.length() - offset) < (maxWidth - 3)) {
offset = str.length() - (maxWidth - 3);
}
if (offset <= 4) {
return str.substring(0, maxWidth - 3) + "...";
}
if (maxWidth < 7) {
throw new IllegalArgumentException("Minimum abbreviation width with offset is 7");
}
if ((offset + (maxWidth - 3)) < str.length()) {
return "..." + abbreviate(str.substring(offset), maxWidth - 3);
}
return "..." + str.substring(str.length() - (maxWidth - 3));
}
/**
* <p>Abbreviates a String to the length passed, replacing the middle characters with the supplied
* replacement String.</p>
*
* <p>This abbreviation only occurs if the following criteria is met:
* <ul>
* <li>Neither the String for abbreviation nor the replacement String are null or empty </li>
* <li>The length to truncate to is less than the length of the supplied String</li>
* <li>The length to truncate to is greater than 0</li>
* <li>The abbreviated String will have enough room for the length supplied replacement String
* and the first and last characters of the supplied String for abbreviation</li>
* </ul>
* Otherwise, the returned String will be the same as the supplied String for abbreviation.
* </p>
*
* <pre>
* StringUtils.abbreviateMiddle(null, null, 0) = null
* StringUtils.abbreviateMiddle("abc", null, 0) = "abc"
* StringUtils.abbreviateMiddle("abc", ".", 0) = "abc"
* StringUtils.abbreviateMiddle("abc", ".", 3) = "abc"
* StringUtils.abbreviateMiddle("abcdef", ".", 4) = "ab.f"
* </pre>
*
* @param str the String to abbreviate, may be null
* @param middle the String to replace the middle characters with, may be null
* @param length the length to abbreviate <code>str</code> to.
* @return the abbreviated String if the above criteria is met, or the original String supplied for abbreviation.
* @since 2.5
*/
public static String abbreviateMiddle(String str, String middle, int length) {
if (isEmpty(str) || isEmpty(middle)) {
return str;
}
if (length >= str.length() || length < (middle.length()+2)) {
return str;
}
int targetSting = length-middle.length();
int startOffset = targetSting/2+targetSting%2;
int endOffset = str.length()-targetSting/2;
StrBuilder builder = new StrBuilder(length);
builder.append(str.substring(0,startOffset));
builder.append(middle);
builder.append(str.substring(endOffset));
return builder.toString();
}
// Difference
//-----------------------------------------------------------------------
/**
* <p>Compares two Strings, and returns the portion where they differ.
* (More precisely, return the remainder of the second String,
* starting from where it''s different from the first.)</p>
*
* <p>For example,
* <code>difference("i am a machine", "i am a robot") -> "robot"</code>.</p>
*
* <pre>
* StringUtils.difference(null, null) = null
* StringUtils.difference("", "") = ""
* StringUtils.difference("", "abc") = "abc"
* StringUtils.difference("abc", "") = ""
* StringUtils.difference("abc", "abc") = ""
* StringUtils.difference("ab", "abxyz") = "xyz"
* StringUtils.difference("abcde", "abxyz") = "xyz"
* StringUtils.difference("abcde", "xyz") = "xyz"
* </pre>
*
* @param str1 the first String, may be null
* @param str2 the second String, may be null
* @return the portion of str2 where it differs from str1; returns the
* empty String if they are equal
* @since 2.0
*/
public static String difference(String str1, String str2) {
if (str1 == null) {
return str2;
}
if (str2 == null) {
return str1;
}
int at = indexOfDifference(str1, str2);
if (at == INDEX_NOT_FOUND) {
return EMPTY;
}
return str2.substring(at);
}
/**
* <p>Compares two Strings, and returns the index at which the
* Strings begin to differ.</p>
*
* <p>For example,
* <code>indexOfDifference("i am a machine", "i am a robot") -> 7</code></p>
*
* <pre>
* StringUtils.indexOfDifference(null, null) = -1
* StringUtils.indexOfDifference("", "") = -1
* StringUtils.indexOfDifference("", "abc") = 0
* StringUtils.indexOfDifference("abc", "") = 0
* StringUtils.indexOfDifference("abc", "abc") = -1
* StringUtils.indexOfDifference("ab", "abxyz") = 2
* StringUtils.indexOfDifference("abcde", "abxyz") = 2
* StringUtils.indexOfDifference("abcde", "xyz") = 0
* </pre>
*
* @param str1 the first String, may be null
* @param str2 the second String, may be null
* @return the index where str2 and str1 begin to differ; -1 if they are equal
* @since 2.0
*/
public static int indexOfDifference(String str1, String str2) {
if (str1 == str2) {
return INDEX_NOT_FOUND;
}
if (str1 == null || str2 == null) {
return 0;
}
int i;
for (i = 0; i < str1.length() && i < str2.length(); ++i) {
if (str1.charAt(i) != str2.charAt(i)) {
break;
}
}
if (i < str2.length() || i < str1.length()) {
return i;
}
return INDEX_NOT_FOUND;
}
/**
* <p>Compares all Strings in an array and returns the index at which the
* Strings begin to differ.</p>
*
* <p>For example,
* <code>indexOfDifference(new String[] {"i am a machine", "i am a robot"}) -> 7</code></p>
*
* <pre>
* StringUtils.indexOfDifference(null) = -1
* StringUtils.indexOfDifference(new String[] {}) = -1
* StringUtils.indexOfDifference(new String[] {"abc"}) = -1
* StringUtils.indexOfDifference(new String[] {null, null}) = -1
* StringUtils.indexOfDifference(new String[] {"", ""}) = -1
* StringUtils.indexOfDifference(new String[] {"", null}) = 0
* StringUtils.indexOfDifference(new String[] {"abc", null, null}) = 0
* StringUtils.indexOfDifference(new String[] {null, null, "abc"}) = 0
* StringUtils.indexOfDifference(new String[] {"", "abc"}) = 0
* StringUtils.indexOfDifference(new String[] {"abc", ""}) = 0
* StringUtils.indexOfDifference(new String[] {"abc", "abc"}) = -1
* StringUtils.indexOfDifference(new String[] {"abc", "a"}) = 1
* StringUtils.indexOfDifference(new String[] {"ab", "abxyz"}) = 2
* StringUtils.indexOfDifference(new String[] {"abcde", "abxyz"}) = 2
* StringUtils.indexOfDifference(new String[] {"abcde", "xyz"}) = 0
* StringUtils.indexOfDifference(new String[] {"xyz", "abcde"}) = 0
* StringUtils.indexOfDifference(new String[] {"i am a machine", "i am a robot"}) = 7
* </pre>
*
* @param strs array of strings, entries may be null
* @return the index where the strings begin to differ; -1 if they are all equal
* @since 2.4
*/
public static int indexOfDifference(String[] strs) {
if (strs == null || strs.length <= 1) {
return INDEX_NOT_FOUND;
}
boolean anyStringNull = false;
boolean allStringsNull = true;
int arrayLen = strs.length;
int shortestStrLen = Integer.MAX_VALUE;
int longestStrLen = 0;
// find the min and max string lengths; this avoids checking to make
// sure we are not exceeding the length of the string each time through
// the bottom loop.
for (int i = 0; i < arrayLen; i++) {
if (strs[i] == null) {
anyStringNull = true;
shortestStrLen = 0;
} else {
allStringsNull = false;
shortestStrLen = Math.min(strs[i].length(), shortestStrLen);
longestStrLen = Math.max(strs[i].length(), longestStrLen);
}
}
// handle lists containing all nulls or all empty strings
if (allStringsNull || (longestStrLen == 0 && !anyStringNull)) {
return INDEX_NOT_FOUND;
}
// handle lists containing some nulls or some empty strings
if (shortestStrLen == 0) {
return 0;
}
// find the position with the first difference across all strings
int firstDiff = -1;
for (int stringPos = 0; stringPos < shortestStrLen; stringPos++) {
char comparisonChar = strs[0].charAt(stringPos);
for (int arrayPos = 1; arrayPos < arrayLen; arrayPos++) {
if (strs[arrayPos].charAt(stringPos) != comparisonChar) {
firstDiff = stringPos;
break;
}
}
if (firstDiff != -1) {
break;
}
}
if (firstDiff == -1 && shortestStrLen != longestStrLen) {
// we compared all of the characters up to the length of the
// shortest string and didn''t find a match, but the string lengths
// vary, so return the length of the shortest string.
return shortestStrLen;
}
return firstDiff;
}
/**
* <p>Compares all Strings in an array and returns the initial sequence of
* characters that is common to all of them.</p>
*
* <p>For example,
* <code>getCommonPrefix(new String[] {"i am a machine", "i am a robot"}) -> "i am a "</code></p>
*
* <pre>
* StringUtils.getCommonPrefix(null) = ""
* StringUtils.getCommonPrefix(new String[] {}) = ""
* StringUtils.getCommonPrefix(new String[] {"abc"}) = "abc"
* StringUtils.getCommonPrefix(new String[] {null, null}) = ""
* StringUtils.getCommonPrefix(new String[] {"", ""}) = ""
* StringUtils.getCommonPrefix(new String[] {"", null}) = ""
* StringUtils.getCommonPrefix(new String[] {"abc", null, null}) = ""
* StringUtils.getCommonPrefix(new String[] {null, null, "abc"}) = ""
* StringUtils.getCommonPrefix(new String[] {"", "abc"}) = ""
* StringUtils.getCommonPrefix(new String[] {"abc", ""}) = ""
* StringUtils.getCommonPrefix(new String[] {"abc", "abc"}) = "abc"
* StringUtils.getCommonPrefix(new String[] {"abc", "a"}) = "a"
* StringUtils.getCommonPrefix(new String[] {"ab", "abxyz"}) = "ab"
* StringUtils.getCommonPrefix(new String[] {"abcde", "abxyz"}) = "ab"
* StringUtils.getCommonPrefix(new String[] {"abcde", "xyz"}) = ""
* StringUtils.getCommonPrefix(new String[] {"xyz", "abcde"}) = ""
* StringUtils.getCommonPrefix(new String[] {"i am a machine", "i am a robot"}) = "i am a "
* </pre>
*
* @param strs array of String objects, entries may be null
* @return the initial sequence of characters that are common to all Strings
* in the array; empty String if the array is null, the elements are all null
* or if there is no common prefix.
* @since 2.4
*/
public static String getCommonPrefix(String[] strs) {
if (strs == null || strs.length == 0) {
return EMPTY;
}
int smallestIndexOfDiff = indexOfDifference(strs);
if (smallestIndexOfDiff == INDEX_NOT_FOUND) {
// all strings were identical
if (strs[0] == null) {
return EMPTY;
}
return strs[0];
} else if (smallestIndexOfDiff == 0) {
// there were no common initial characters
return EMPTY;
} else {
// we found a common initial character sequence
return strs[0].substring(0, smallestIndexOfDiff);
}
}
// Misc
//-----------------------------------------------------------------------
/**
* <p>Find the Levenshtein distance between two Strings.</p>
*
* <p>This is the number of changes needed to change one String into
* another, where each change is a single character modification (deletion,
* insertion or substitution).</p>
*
* <p>The previous implementation of the Levenshtein distance algorithm
* was from <a href="http://www.merriampark.com/ld.htm">http://www.merriampark.com/ld.htm</a></p>
*
* <p>Chas Emerick has written an implementation in Java, which avoids an OutOfMemoryError
* which can occur when my Java implementation is used with very large strings.<br>
* This implementation of the Levenshtein distance algorithm
* is from <a href="http://www.merriampark.com/ldjava.htm">http://www.merriampark.com/ldjava.htm</a></p>
*
* <pre>
* StringUtils.getLevenshteinDistance(null, *) = IllegalArgumentException
* StringUtils.getLevenshteinDistance(*, null) = IllegalArgumentException
* StringUtils.getLevenshteinDistance("","") = 0
* StringUtils.getLevenshteinDistance("","a") = 1
* StringUtils.getLevenshteinDistance("aaapppp", "") = 7
* StringUtils.getLevenshteinDistance("frog", "fog") = 1
* StringUtils.getLevenshteinDistance("fly", "ant") = 3
* StringUtils.getLevenshteinDistance("elephant", "hippo") = 7
* StringUtils.getLevenshteinDistance("hippo", "elephant") = 7
* StringUtils.getLevenshteinDistance("hippo", "zzzzzzzz") = 8
* StringUtils.getLevenshteinDistance("hello", "hallo") = 1
* </pre>
*
* @param s the first String, must not be null
* @param t the second String, must not be null
* @return result distance
* @throws IllegalArgumentException if either String input <code>null</code>
*/
public static int getLevenshteinDistance(String s, String t) {
if (s == null || t == null) {
throw new IllegalArgumentException("Strings must not be null");
}
/*
The difference between this impl. and the previous is that, rather
than creating and retaining a matrix of size s.length()+1 by t.length()+1,
we maintain two single-dimensional arrays of length s.length()+1. The first, d,
is the ''current working'' distance array that maintains the newest distance cost
counts as we iterate through the characters of String s. Each time we increment
the index of String t we are comparing, d is copied to p, the second int[]. Doing so
allows us to retain the previous cost counts as required by the algorithm (taking
the minimum of the cost count to the left, up one, and diagonally up and to the left
of the current cost count being calculated). (Note that the arrays aren''t really
copied anymore, just switched...this is clearly much better than cloning an array
or doing a System.arraycopy() each time through the outer loop.)
Effectively, the difference between the two implementations is this one does not
cause an out of memory condition when calculating the LD over two very large strings.
*/
int n = s.length(); // length of s
int m = t.length(); // length of t
if (n == 0) {
return m;
} else if (m == 0) {
return n;
}
if (n > m) {
// swap the input strings to consume less memory
String tmp = s;
s = t;
t = tmp;
n = m;
m = t.length();
}
int p[] = new int[n+1]; //''previous'' cost array, horizontally
int d[] = new int[n+1]; // cost array, horizontally
int _d[]; //placeholder to assist in swapping p and d
// indexes into strings s and t
int i; // iterates through s
int j; // iterates through t
char t_j; // jth character of t
int cost; // cost
for (i = 0; i<=n; i++) {
p[i] = i;
}
for (j = 1; j<=m; j++) {
t_j = t.charAt(j-1);
d[0] = j;
for (i=1; i<=n; i++) {
cost = s.charAt(i-1)==t_j ? 0 : 1;
// minimum of cell to the left+1, to the top+1, diagonally left and up +cost
d[i] = Math.min(Math.min(d[i-1]+1, p[i]+1), p[i-1]+cost);
}
// copy current distance counts to ''previous row'' distance counts
_d = p;
p = d;
d = _d;
}
// our last action in the above loop was to switch d and p, so p now
// actually has the most recent cost counts
return p[n];
}
// startsWith
//-----------------------------------------------------------------------
/**
* <p>Check if a String starts with a specified prefix.</p>
*
* <p><code>null</code>s are handled without exceptions. Two <code>null</code>
* references are considered to be equal. The comparison is case sensitive.</p>
*
* <pre>
* StringUtils.startsWith(null, null) = true
* StringUtils.startsWith(null, "abc") = false
* StringUtils.startsWith("abcdef", null) = false
* StringUtils.startsWith("abcdef", "abc") = true
* StringUtils.startsWith("ABCDEF", "abc") = false
* </pre>
*
* @see java.lang.String#startsWith(String)
* @param str the String to check, may be null
* @param prefix the prefix to find, may be null
* @return <code>true</code> if the String starts with the prefix, case sensitive, or
* both <code>null</code>
* @since 2.4
*/
public static boolean startsWith(String str, String prefix) {
return startsWith(str, prefix, false);
}
/**
* <p>Case insensitive check if a String starts with a specified prefix.</p>
*
* <p><code>null</code>s are handled without exceptions. Two <code>null</code>
* references are considered to be equal. The comparison is case insensitive.</p>
*
* <pre>
* StringUtils.startsWithIgnoreCase(null, null) = true
* StringUtils.startsWithIgnoreCase(null, "abc") = false
* StringUtils.startsWithIgnoreCase("abcdef", null) = false
* StringUtils.startsWithIgnoreCase("abcdef", "abc") = true
* StringUtils.startsWithIgnoreCase("ABCDEF", "abc") = true
* </pre>
*
* @see java.lang.String#startsWith(String)
* @param str the String to check, may be null
* @param prefix the prefix to find, may be null
* @return <code>true</code> if the String starts with the prefix, case insensitive, or
* both <code>null</code>
* @since 2.4
*/
public static boolean startsWithIgnoreCase(String str, String prefix) {
return startsWith(str, prefix, true);
}
/**
* <p>Check if a String starts with a specified prefix (optionally case insensitive).</p>
*
* @see java.lang.String#startsWith(String)
* @param str the String to check, may be null
* @param prefix the prefix to find, may be null
* @param ignoreCase inidicates whether the compare should ignore case
* (case insensitive) or not.
* @return <code>true</code> if the String starts with the prefix or
* both <code>null</code>
*/
private static boolean startsWith(String str, String prefix, boolean ignoreCase) {
if (str == null || prefix == null) {
return (str == null && prefix == null);
}
if (prefix.length() > str.length()) {
return false;
}
return str.regionMatches(ignoreCase, 0, prefix, 0, prefix.length());
}
/**
* <p>Check if a String starts with any of an array of specified strings.</p>
*
* <pre>
* StringUtils.startsWithAny(null, null) = false
* StringUtils.startsWithAny(null, new String[] {"abc"}) = false
* StringUtils.startsWithAny("abcxyz", null) = false
* StringUtils.startsWithAny("abcxyz", new String[] {""}) = false
* StringUtils.startsWithAny("abcxyz", new String[] {"abc"}) = true
* StringUtils.startsWithAny("abcxyz", new String[] {null, "xyz", "abc"}) = true
* </pre>
*
* @see #startsWith(String, String)
* @param string the String to check, may be null
* @param searchStrings the Strings to find, may be null or empty
* @return <code>true</code> if the String starts with any of the the prefixes, case insensitive, or
* both <code>null</code>
* @since 2.5
*/
public static boolean startsWithAny(String string, String[] searchStrings) {
if (isEmpty(string) || ArrayUtils.isEmpty(searchStrings)) {
return false;
}
for (int i = 0; i < searchStrings.length; i++) {
String searchString = searchStrings[i];
if (StringUtils.startsWith(string, searchString)) {
return true;
}
}
return false;
}
// endsWith
//-----------------------------------------------------------------------
/**
* <p>Check if a String ends with a specified suffix.</p>
*
* <p><code>null</code>s are handled without exceptions. Two <code>null</code>
* references are considered to be equal. The comparison is case sensitive.</p>
*
* <pre>
* StringUtils.endsWith(null, null) = true
* StringUtils.endsWith(null, "def") = false
* StringUtils.endsWith("abcdef", null) = false
* StringUtils.endsWith("abcdef", "def") = true
* StringUtils.endsWith("ABCDEF", "def") = false
* StringUtils.endsWith("ABCDEF", "cde") = false
* </pre>
*
* @see java.lang.String#endsWith(String)
* @param str the String to check, may be null
* @param suffix the suffix to find, may be null
* @return <code>true</code> if the String ends with the suffix, case sensitive, or
* both <code>null</code>
* @since 2.4
*/
public static boolean endsWith(String str, String suffix) {
return endsWith(str, suffix, false);
}
/**
* <p>Case insensitive check if a String ends with a specified suffix.</p>
*
* <p><code>null</code>s are handled without exceptions. Two <code>null</code>
* references are considered to be equal. The comparison is case insensitive.</p>
*
* <pre>
* StringUtils.endsWithIgnoreCase(null, null) = true
* StringUtils.endsWithIgnoreCase(null, "def") = false
* StringUtils.endsWithIgnoreCase("abcdef", null) = false
* StringUtils.endsWithIgnoreCase("abcdef", "def") = true
* StringUtils.endsWithIgnoreCase("ABCDEF", "def") = true
* StringUtils.endsWithIgnoreCase("ABCDEF", "cde") = false
* </pre>
*
* @see java.lang.String#endsWith(String)
* @param str the String to check, may be null
* @param suffix the suffix to find, may be null
* @return <code>true</code> if the String ends with the suffix, case insensitive, or
* both <code>null</code>
* @since 2.4
*/
public static boolean endsWithIgnoreCase(String str, String suffix) {
return endsWith(str, suffix, true);
}
/**
* <p>Check if a String ends with a specified suffix (optionally case insensitive).</p>
*
* @see java.lang.String#endsWith(String)
* @param str the String to check, may be null
* @param suffix the suffix to find, may be null
* @param ignoreCase inidicates whether the compare should ignore case
* (case insensitive) or not.
* @return <code>true</code> if the String starts with the prefix or
* both <code>null</code>
*/
private static boolean endsWith(String str, String suffix, boolean ignoreCase) {
if (str == null || suffix == null) {
return (str == null && suffix == null);
}
if (suffix.length() > str.length()) {
return false;
}
int strOffset = str.length() - suffix.length();
return str.regionMatches(ignoreCase, strOffset, suffix, 0, suffix.length());
}
/**
* <p>
* Similar to <a
* href="http://www.w3.org/TR/xpath/#function-normalize-space">http://www.w3.org/TR/xpath/#function-normalize
* -space</a>
* </p>
* <p>
* The function returns the argument string with whitespace normalized by using
* <code>{@link #trim(String)}</code> to remove leading and trailing whitespace
* and then replacing sequences of whitespace characters by a single space.
* </p>
* In XML Whitespace characters are the same as those allowed by the <a
* href="http://www.w3.org/TR/REC-xml/#NT-S">S</a> production, which is S ::= (#x20 | #x9 | #xD | #xA)+
* <p>
* See Java''s {@link Character#isWhitespace(char)} for which characters are considered whitespace.
* <p>
* The difference is that Java''s whitespace includes vertical tab and form feed, which this functional will also
* normalize. Additonally <code>{@link #trim(String)}</code> removes control characters (char <= 32) from both
* ends of this String.
* </p>
*
* @see Character#isWhitespace(char)
* @see #trim(String)
* @see <ahref="http://www.w3.org/TR/xpath/#function-normalize-space">
* http://www.w3.org/TR/xpath/#function-normalize-space</a>
* @param str the source String to normalize whitespaces from, may be null
* @return the modified string with whitespace normalized, <code>null</code> if null String input
*
* @since 2.6
*/
public static String normalizeSpace(String str) {
str = strip(str);
if(str == null || str.length() <= 2) {
return str;
}
StrBuilder b = new StrBuilder(str.length());
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (Character.isWhitespace(c)) {
if (i > 0 && !Character.isWhitespace(str.charAt(i - 1))) {
b.append('' '');
}
} else {
b.append(c);
}
}
return b.toString();
}
/**
* <p>Check if a String ends with any of an array of specified strings.</p>
*
* <pre>
* StringUtils.endsWithAny(null, null) = false
* StringUtils.endsWithAny(null, new String[] {"abc"}) = false
* StringUtils.endsWithAny("abcxyz", null) = false
* StringUtils.endsWithAny("abcxyz", new String[] {""}) = true
* StringUtils.endsWithAny("abcxyz", new String[] {"xyz"}) = true
* StringUtils.endsWithAny("abcxyz", new String[] {null, "xyz", "abc"}) = true
* </pre>
*
* @param string the String to check, may be null
* @param searchStrings the Strings to find, may be null or empty
* @return <code>true</code> if the String ends with any of the the prefixes, case insensitive, or
* both <code>null</code>
* @since 2.6
*/
public static boolean endsWithAny(String string, String[] searchStrings) {
if (isEmpty(string) || ArrayUtils.isEmpty(searchStrings)) {
return false;
}
for (int i = 0; i < searchStrings.length; i++) {
String searchString = searchStrings[i];
if (StringUtils.endsWith(string, searchString)) {
return true;
}
}
return false;
}
}
apache commons StringUtils
StringUtils方法的操作对象是java.lang.String类型的对象,是JDK提供的String类型操作方法的补充,并且是null安全的(即如果输入参数String为null则不会抛出NullPointerException,而是做了相应处理,例如,如果输入为null则返回也是null等,具体可以查看源代码)。
除了构造器,StringUtils中一共有130多个方法,并且都是static的,所以我们可以这样调用StringUtils.xxx()
1. public static boolean isEmpty(String str)
判断某字符串是否为空,为空的标准是str==null或str.length()==0
下面是StringUtils判断是否为空的示例:
StringUtils.isEmpty(null) = true
StringUtils.isEmpty("") = true
StringUtils.isEmpty(" ") = false //注意在StringUtils中空格作非空处理
StringUtils.isEmpty(" ") = false
StringUtils.isEmpty("bob") = false
StringUtils.isEmpty(" bob ") = false
2. public static boolean isNotEmpty(String str)
判断某字符串是否非空,等于!isEmpty(String str)
下面是示例:
StringUtils.isNotEmpty(null) = false
StringUtils.isNotEmpty("") = false
StringUtils.isNotEmpty(" ") = true
StringUtils.isNotEmpty(" ") = true
StringUtils.isNotEmpty("bob") = true
StringUtils.isNotEmpty(" bob ") = true
3. public static boolean isBlank(String str)
判断某字符串是否为空或长度为0或由空白符(whitespace)构成
下面是示例:
StringUtils.isBlank(null) = true
StringUtils.isBlank("") = true
StringUtils.isBlank(" ") = true
StringUtils.isBlank(" ") = true
StringUtils.isBlank("/t /n /f /r") = true //对于制表符、换行符、换页符和回车符StringUtils.isBlank()均识为空白符
StringUtils.isBlank("/b") = false //"/b"为单词边界符
StringUtils.isBlank("bob") = false
StringUtils.isBlank(" bob ") = false
4. public static boolean isNotBlank(String str)
判断某字符串是否不为空且长度不为0且不由空白符(whitespace)构成,等于!isBlank(String str)
下面是示例:
StringUtils.isNotBlank(null) = false
StringUtils.isNotBlank("") = false
StringUtils.isNotBlank(" ") = false
StringUtils.isNotBlank(" ") = false
StringUtils.isNotBlank("/t /n /f /r") = false
StringUtils.isNotBlank("/b") = true
StringUtils.isNotBlank("bob") = true
StringUtils.isNotBlank(" bob ") = true
5. public static String trim(String str)
去掉字符串两端的控制符(control characters, char <= 32),如果输入为null则返回null
下面是示例:
StringUtils.trim(null) = null
StringUtils.trim("") = ""
StringUtils.trim(" ") = ""
StringUtils.trim(" /b /t /n /f /r ") = ""
StringUtils.trim(" /n/tss /b") = "ss"
StringUtils.trim(" d d dd ") = "d d dd"
StringUtils.trim("dd ") = "dd"
StringUtils.trim(" dd ") = "dd"
6. public static String trimToNull(String str)
去掉字符串两端的控制符(control characters, char <= 32),如果变为null或"",则返回null
下面是示例:
StringUtils.trimToNull(null) = null
StringUtils.trimToNull("") = null
StringUtils.trimToNull(" ") = null
StringUtils.trimToNull(" /b /t /n /f /r ") = null
StringUtils.trimToNull(" /n/tss /b") = "ss"
StringUtils.trimToNull(" d d dd ") = "d d dd"
StringUtils.trimToNull("dd ") = "dd"
StringUtils.trimToNull(" dd ") = "dd"
7. public static String trimToEmpty(String str)
去掉字符串两端的控制符(control characters, char <= 32),如果变为null或"",则返回""
下面是示例:
StringUtils.trimToEmpty(null) = ""
StringUtils.trimToEmpty("") = ""
StringUtils.trimToEmpty(" ") = ""
StringUtils.trimToEmpty(" /b /t /n /f /r ") = ""
StringUtils.trimToEmpty(" /n/tss /b") = "ss"
StringUtils.trimToEmpty(" d d dd ") = "d d dd"
StringUtils.trimToEmpty("dd ") = "dd"
StringUtils.trimToEmpty(" dd ") = "dd"
8. public static String strip(String str)
去掉字符串两端的空白符(whitespace),如果输入为null则返回null
下面是示例(注意和trim()的区别):
StringUtils.strip(null) = null
StringUtils.strip("") = ""
StringUtils.strip(" ") = ""
StringUtils.strip(" /b /t /n /f /r ") = "/b"
StringUtils.strip(" /n/tss /b") = "ss /b"
StringUtils.strip(" d d dd ") = "d d dd"
StringUtils.strip("dd ") = "dd"
StringUtils.strip(" dd ") = "dd"
9. public static String stripToNull(String str)
去掉字符串两端的空白符(whitespace),如果变为null或"",则返回null
下面是示例(注意和trimToNull()的区别):
StringUtils.stripToNull(null) = null
StringUtils.stripToNull("") = null
StringUtils.stripToNull(" ") = null
StringUtils.stripToNull(" /b /t /n /f /r ") = "/b"
StringUtils.stripToNull(" /n/tss /b") = "ss /b"
StringUtils.stripToNull(" d d dd ") = "d d dd"
StringUtils.stripToNull("dd ") = "dd"
StringUtils.stripToNull(" dd ") = "dd"
10. public static String stripToEmpty(String str)
去掉字符串两端的空白符(whitespace),如果变为null或"",则返回""
下面是示例(注意和trimToEmpty()的区别):
StringUtils.stripToNull(null) = ""
StringUtils.stripToNull("") = ""
StringUtils.stripToNull(" ") = ""
StringUtils.stripToNull(" /b /t /n /f /r ") = "/b"
StringUtils.stripToNull(" /n/tss /b") = "ss /b"
StringUtils.stripToNull(" d d dd ") = "d d dd"
StringUtils.stripToNull("dd ") = "dd"
StringUtils.stripToNull(" dd ") = "dd"

apache commons StringUtils介绍
apache commons StringUtils介绍
org.apache.commons.lang.StringUtils
StringUtils是apache commons lang库(http://commons.apache.org/lang)旗下的一个工具类,提供了很多有用的处理字符串的方法,本文不打算把所有的方法都介绍一遍,我会介绍一些精选的常用的给大家。
目前StringUtils有两个版本可用,分别是较新的org.apache.commons.lang3.StringUtils和较老的org.apache.commons.lang.StringUtils,他们有比较大的区别,前者需要JAVA 5,我想这个应该是我们希望使用的。
1)public static boolean equals(CharSequence str1,CharSequence str2)
我们就先从最简单的方法equals开始,和你想的一样,他需要两个字符串参数,当相同的时候返回true,否则返回false。
但是java.lang.String已经有现成的比较完美的equals方法了,为何我们还需要一个第三方的实现呢?
这个问题很好,让我们来看看下面这些代码,看看有何问题?
Java代码 
public void doStuffWithString(String stringParam) {
if(stringParam.equals("MyStringValue")) {
// do stuff }
}
这个可能有NullPointerException出现,那么有几个办法处理:
Java代码
public void safeDoStuffWithString1(String stringParam) {
if(stringParam != null &&
stringParam.equals("MyStringValue")) {
// do stuff
}
}
public void safeDoStuffWithString2(String stringParm) {
if("MyStringValue".equals(stringParam))
{
// do stuff
}
}
我本人不喜欢上面的两个方法,第一个看起来太臃肿,第二个看起来像错误的。这里我们就可以用一些StringUtils类了,这个类提供的equals方法是空指针安全的,不用担心传递给他的是什么参数,他不会抛出空指针异常,这样写:
Java代码
public void safeDoStuffWithString3(String stringParam) {
if(StringUtils.equals(stringParam,"MyStringValue))
{
// do stuff
}
}
这个是我个人的喜好,但是这个确实看起来比较简单易读。前面的两个方法虽然么有什么问题,但是我想StringUtils.equals还是值得考虑的。
2)isEmpty,isNotEmpty,isBlank,isNotBlank
和前面一样,这些方法相对于jdk提供的isEmpty方法来说,多了一个“空指针安全”,即不用考虑传递参数的空值问题,让我们来看一个例子:
Java代码
if(myString != null && !myString.isEmpty()) {
// 有点臃肿是把?
// Do stuff with myString
}
if(StringUtils.isNotEmpty(myString)) { // 好多了吧
// Do stuff with myString
}
Blank和empty的区别
isBlank将在字符串含有空白字符的时候,返回true,例如:
Java代码
String someWhiteSpace = " \t \n";
StringUtils.isEmpty(someWhiteSpace); // false
StringUtils.isBlank(someWhiteSpace); // true
3)public static String[] split(String str,String separatorChars)
当然,这个方法相对于String.split也是空指针安全的,当你尝试split一个null字符串的时候,将返回Null,一个Null的分隔符将按照空白字符分隔字符串,但是,还有一个理由让你可考虑使用StringUtils.split()方法,就是jdk自带的String.split由于支持正则表达式进行分隔,所以可能带来意想不到的后果,例如:
Java代码
public void possiblyNotWhatYouWant() {
String contrivedExampleString = "one.two.three.four";
String[] result = contrivedExampleString.split(".");
System.out.println(result.length); // 0
}
上面很明显你希望按照.分隔,但是jdk理解的“.”是正则表达式的任意字符,导致字符串内任意字符都匹配,返回一个size=0的字符串数组。其实你只要传递"\\."就行了,但是这个确实是一个问题。
这样,使用StringUtils.split就简单多了,另外,我测试还发现StringUtils.split比jdk自带的split要快四倍。
4)public static String join(Iterable iterable,String separator)
这个方法确实很实用,因为jdk自身没有提供,简单使用方法:
Java代码
String[] numbers = {"one", "two", "three"};
StringUtils.join(numbers,","); // returns "one,two,three"
当然你可以传递一个数字或者迭代序列iterators.
好了,我确信,这个库确实是一个比较实用的库,推荐大家使用。
API请参考:http://commons.apache.org/lang/api-3.1/org/apache/commons/lang3/StringUtils.html

apache commons StringUtils工具类使用
StringUtils是apache commons lang库(http://commons.apache.org/lang)旗下的一个工具类,提供了很多有用的处理字符串的方法。
org.apache.commons.lang.StringUtils中方法的操作对象是java.lang.String类型的对象,是JDK提供的String类型操作方法的补充,用的最多的还是非空判断,“”、null、“ ”等,很实用的一个工具类
详见博客:http://blog.sina.com.cn/s/blog_4550f3ca0100qrsd.html

Apache Commons 包 StringUtils 工具类深入整理
注:
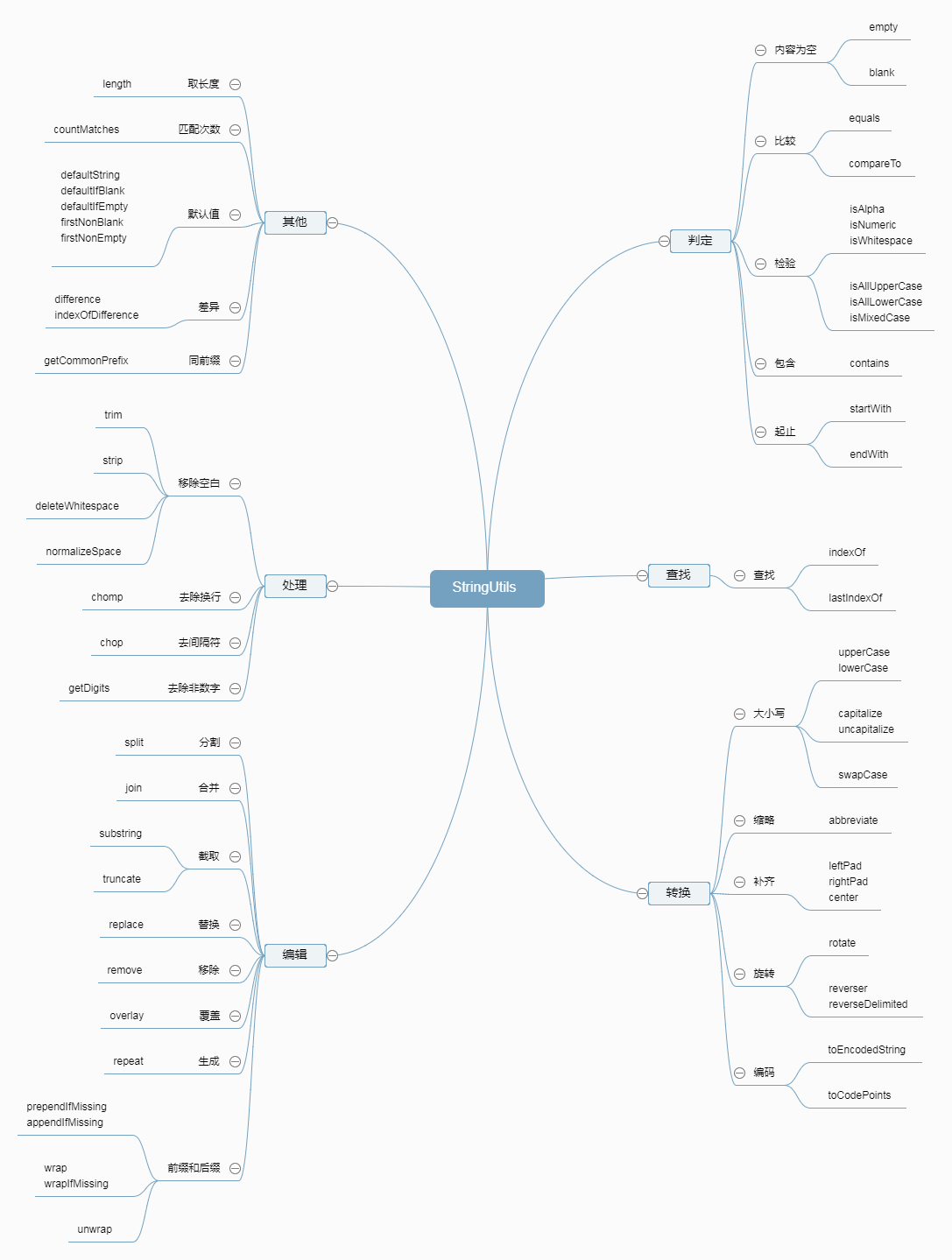
1.3 检验字符串
通过一系列实现好的方法,来快速返回是否符合特定规则
// 判断是否只包含 unicode 字符(注意:汉字也是 unicode 字符)
public static boolean isAlpha(CharSequence cs)
// 判断是否只包含 unicode 字符及空格
public static boolean isAlphaSpace(CharSequence cs)
// 判断是否只包含 unicode 字符及数字
public static boolean isAlphanumeric(CharSequence cs)
// 判断是否只包含 unicode 字符、数字及空格
public static boolean isAlphanumericSpace(CharSequence cs)
// 判断是否只包含数字及空格
public static boolean isNumericSpace(CharSequence cs)
// 判断是否只包含可打印的 ascii 码字符(注意,空格不属于范围内)
public static boolean isAsciiPrintable(CharSequence cs)
// 判断是否为数字(注意:小数点和正负号,都会判定为 false)
public static boolean isNumeric(CharSequence cs)
// 判定是否只包括空白字符
public static boolean isWhitespace(CharSequence cs)
// 判定是否全部为大写
public static boolean isAllUpperCase(CharSequence cs)
// 判定是否全部为小写
public static boolean isAllLowerCase(CharSequence cs)
// 判定是否混合大小写(注意:包含其他字符,如空格,不影响结果判定)
public static boolean isMixedCase(CharSequence cs)
1.4 包含字符串
contains,同 jdk
public static boolean contains(CharSequence seq,int searchChar)
public static boolean contains(CharSequence seq,CharSequence searchSeq)
扩展:
// 忽略大小写
public static boolean containsIgnoreCase(CharSequence str,CharSequence searchStr)
// 是否包含空白字符
public static boolean containsWhitespace(CharSequence seq)
// 只包含指定字符
public static boolean containsOnly(CharSequence cs,char... searchChars)
public static boolean containsOnly(CharSequence cs,CharSequence searchChars)
// 批量判断包含任意一个
public static boolean containsAny(CharSequence cs,char... searchChars)
public static boolean containsAny(CharSequence cs,CharSequence searchChars)
// 批量判断不包含任何一个
public static boolean containsNone(CharSequence cs,char... searchChars)
public static boolean containsNone(CharSequence cs,CharSequence searchChars)
1.5 起止字符判定
//startWith
public static boolean startsWith(CharSequence str,CharSequence prefix)
public static boolean startsWithIgnoreCase(CharSequence str,CharSequence prefix)
public static boolean startsWithAny(CharSequence sequence,CharSequence... searchStrings)
//endWith
public static boolean endsWith(CharSequence str,CharSequence suffix)
public static boolean endsWithIgnoreCase(CharSequence str,CharSequence suffix)
public static boolean endsWithAny(CharSequence sequence,CharSequence... searchStrings)
2 处理字符串
不改变字符串实质内容,对首尾以及中间的空白字符进行处理
// 批量操作
public static String[] stripAll(String... strs)
public static String[] stripAll(String[] strs,String stripChars)
2.2 去除换行
去除结尾的一处换行符,包括三种情况 \r \n \r\n
public static String chomp(String str)
示例
StringUtils.chomp("\r") = ""
StringUtils.chomp("\n") = ""
StringUtils.chomp("\r\n") = ""
StringUtils.chomp("abc \r") = "abc "
StringUtils.chomp("abc\n") = "abc"
StringUtils.chomp("abc\r\n") = "abc"
StringUtils.chomp("abc\r\n\r\n") = "abc\r\n"
StringUtils.chomp("abc\n\r") = "abc\n"
StringUtils.chomp("abc\n\rabc") = "abc\n\rabc"
2.3 去除间隔符
去除末尾一个字符,常见使用场景是通过循环处理使用间隔符拼装的字符串,去除间隔符
注意:使用时需确保最后一位一定是间隔符,否则有可能破坏正常数据
public static String chop(String str)
示例:
StringUtils.chop("1,2,3,") = "1,2,3"
StringUtils.chop("a") = ""
StringUtils.chop("abc") = "ab"
StringUtils.chop("abc\nabc") = "abc\nab"
// 此外,末尾的换行符也视为字符,如果结尾是 \r\n,则一块去除,建议使用专用的 chomp, 以免造成非预期的结果
StringUtils.chop("\r") = ""
StringUtils.chop("\n") = ""
StringUtils.chop("\r\n") = ""
2.4 去除非数字
去除所有非数字字符,将剩余的数字字符拼接成字符串
public static String getDigits(String str)
示例:
StringUtils.getDigits("abc") = ""
StringUtils.getDigits("1000$") = "1000"
StringUtils.getDigits("1123~45") = "112345"
StringUtils.getDigits("(541) 754-3010") = "5417543010"
public static int indexOf(CharSequence seq,CharSequence searchSeq)
public static int indexOf(CharSequence seq,CharSequence searchSeq,int startPos)
// 增加忽略大小写控制
public static int indexOfIgnoreCase(CharSequence str,CharSequence searchStr)
// 返回第 n 次匹配的所在的索引数。
public static int ordinalIndexOf(CharSequence str,CharSequence searchStr,int ordinal)
// 同时查找多个字符
public static int indexOfAny(CharSequence cs,char... searchChars)
// 返回不在搜索字符范围内的第一个索引位置
public static int indexOfAnyBut(CharSequence cs,char... searchChars)
jdk 中的 split 使用正则表达式匹配,而字符串分割最常用场景是如下这种根据间隔符分割
String str="he,ll,o";
String [] reuslt=str.split(",");
虽然 split 的方式也能实现效果,但是还有有点别扭,而在 StringUtils,就是通过字符串匹配,而不是正则表达式
// 不设置间隔符,默认使用空白字符分割
public static String[] split(String str)
// 根据间隔符分割
public static String[] splitByWholeSeparator(String str,String separator)
// 限定返回,贪婪匹配
public static String[] splitByWholeSeparator(String str,String separator,int max),
示例:
StringUtils.splitByWholeSeparator("ab-!-cd-!-ef", "-!-", 5) = ["ab", "cd", "ef"]
StringUtils.splitByWholeSeparator("ab-!-cd-!-ef", "-!-", 2) = ["ab", "cd-!-ef"]
// 空白字符作为一个数组元素返回(其他方法默认去除空白字符元素)
public static String[] splitPreserveAllTokens(String str)
示例:
StringUtils.splitPreserveAllTokens("abc def") = ["abc", "def"]
StringUtils.splitPreserveAllTokens("abc def") = ["abc", "", "def"]
StringUtils.splitPreserveAllTokens(" abc ") = ["", "abc", ""]
// 特定场景,根据字符类型分割,同一类划为一个数组元素,驼峰命名情况下,最后一个大写字母归属后面元素而不是前面
public static String[] splitByCharacterTypeCamelCase(String str)
示例:
StringUtils.splitByCharacterTypeCamelCase("ab de fg") = ["ab", " ", "de", " ", "fg"]
StringUtils.splitByCharacterTypeCamelCase("ab de fg") = ["ab", " ", "de", " ", "fg"]
StringUtils.splitByCharacterTypeCamelCase("ab:cd:ef") = ["ab", ":", "cd", ":", "ef"]
StringUtils.splitByCharacterTypeCamelCase("number5") = ["number", "5"]
StringUtils.splitByCharacterTypeCamelCase("fooBar") = ["foo", "Bar"]
StringUtils.splitByCharacterTypeCamelCase("foo200Bar") = ["foo", "200", "Bar"]
StringUtils.splitByCharacterTypeCamelCase("ASFRules") = ["ASF", "Rules"]
4.2 合并字符串
jdk 使用 concat 方法,StringUtils 使用 join,这是一个泛型方法,建议实际使用过程中,还是只对 String 使用,不要对数值类型进行合并,会导致代码可读性降低
// 默认合并,注意:自动去除空白字符或 null 元素
public static <T> String join(T... elements)
示例:
StringUtils.join(null) = null
StringUtils.join([]) = ""
StringUtils.join([null]) = ""
StringUtils.join(["a", "b", "c"]) = "abc"
StringUtils.join([null, "", "a"]) = "a"
// 使用指定间隔符合并,注意:保留空白字符或 null 元素
public static String join(Object[] array,char separator)
示例:
StringUtils.join(["a", "b", "c"], '';'') = "a;b;c"
StringUtils.join([null, "", "a"], '';'') = ";;a"
// 拼接数值
public static String join(long[] array,char separator)
public static String join(int[] array,char separator)
示例:
StringUtils.join([1, 2, 3], '';'') = "1;2;3"
StringUtils.join([1, 2, 3], null) = "123"
(注意:实测与官网文档不符,StringUtils.join (new int []{1, 2, 3}, null); 返回结果是一个很奇怪的字符串 [I@77a82f1;使用 StringUtils.join (new Object []{1, 2, 3}, null)),才会返回期望的 “123”
相关方法:
//joinWith,基本就是把数组参数和间隔符的位置颠倒了一下,意义不大,建议弃用
StringUtils.joinWith(",", {"a", "b"}) = "a,b"
此外,还有大量重载函数,进一步指定起始元素和结束元素,实用性较低,不建议使用。
相关方法有多个,substring 和 truncate 基本用法同 jdk,内部处理异常
public static String substring(String str,int start)
public static String substring(String str,int start,int end)
public static String truncate(String str,int maxWidth);
public static String truncate(String str,int offset,int maxWidth)
扩展:
// 直接实现从左侧、右侧或中间截取指定位数,实用性高
public static String left(String str,int len)
public static String right(String str,int len)
public static String mid(String str,int pos,int len)
// 直接实现特定规则,但总体来说适用场景不多
// 截取第一个指定字符前 / 后的字符串返回
public static String substringBefore(String str,String separator)
public static String substringAfter(String str,String separator)
// 截取最后一个指定字符前 / 后的字符串返回
public static String substringBeforeLast(String str,String separator)
public static String substringAfterLast(String str,String separator)
// 截取特定字符串中间部分
public static String substringBetween(String str,String tag)
示例:StringUtils.substringBetween ("tagabctag", "tag") = "abc"
// 返回起止字符串中间的字符串,且只返回第一次匹配结果
public static String substringBetween(String str,String open,String close)
// 返回起止字符串中间的字符串,返回所有匹配结果
public static String[] substringBetween(String str,String open,String close)
4.4 替换字符串
jdk 中使用 replace,StringUtils 使用同样名字,默认替换掉所有匹配项,扩展实现了忽略大小写、只替换一次、指定最大替换次数等
public static String replace(String text,String searchString,String replacement)
public static String replaceChars(String str,char searchChar,char replaceChar)
扩展:
// 忽略大小写
public static String replaceIgnoreCase(String text,String searchString,String replacement)
// 只替换一次
public static String replaceOnce(String text,String searchString,String replacement)
public static String replaceOnceIgnoreCase(String text,String searchString,String replacement)
// 最大替换次数
public static String replace(String text,String searchString,String replacement,int max)
示例:
StringUtils.replace("abaa", "a", "z", 0) = "abaa"
StringUtils.replace("abaa", "a", "z", 1) = "zbaa"
StringUtils.replace("abaa", "a", "z", 2) = "zbza"
StringUtils.replace("abaa", "a", "z", -1) = "zbzz"
注意:
max 是替换次数,0 代表不做替换,-1 代表替换所有,从代码可读性考虑,建议按照常规思维模式使用,别使用这些 0 或者 - 1 比较变态的用法
// 扩展批量,过于复杂,执行结果难以预期,不建议使用
public static String replaceEach(String text,String[] searchList,String[] replacementList)
public static String replaceEachRepeatedly(String text,String[] searchList,String[] replacementList)
public static String replaceChars(String str,String searchChars,String replaceChars)
4.5. 移除字符串
remove,移除字符
public static String remove(String str,char remove)
public static String remove(String str,String remove)
示例:
StringUtils.remove("queued", "ue") = "qd"
(注意,是第二个参数中所有字符,而不是匹配整个字符串)
扩展:
// 忽略大小写
public static String removeIgnoreCase(String str,String remove)
// 移除指定位置
public static String removeStart(String str,String remove)
public static String removeEnd(String str,String remove)
// 指定位置且忽略大小写
public static String removeStartIgnoreCase(String str,String remove)
public static String removeEndIgnoreCase(String str,String remove)
public static String overlay(String str,String overlay,int start,int end)
典型应用场景,隐藏字符串如证件号码、地址或手机号码中部分字符
示例::
StringUtils.overlay("13712345678","****",3,7)=“137****5678”
注意:实现时做了不少防止异常的处理,比如后面两个参数为止可以调换,会自动判断哪个数字小,哪个就是起始值,然后,如果是负数,则表示添加到开始,如果超出字符串自身长度,添加到末尾,但这些奇特的用法尽量避免使用,否则代码可读性会很差。
4.7 生成字符串
根据指定信息产生字符串
public static String repeat(String str,int repeat)
示例:
StringUtils.repeat("a", 3) = "aaa"
StringUtils.repeat("ab", 2) = "abab"
扩展:
// 指定间隔符
public static String repeat(String str,String separator,int repeat)
示例
StringUtils.repeat("?", ", ", 3) = "?, ?, ?"
4.8 前缀和后缀
// 追加前缀,如只有两个参数,则是无条件追加,超过两个参数,是在不匹配 prefixes 任何情况下才追加
public static String prependIfMissing(String str,CharSequence prefix,CharSequence... prefixes)
public static String prependIfMissingIgnoreCase(String str,CharSequence prefix,CharSequence... prefixes)
/ 追加后缀,如只有两个参数,则是无条件追加,超过两个参数,是在不匹配 suffixes 任何情况下才追加
public static String appendIfMissing(String str,CharSequence suffix,CharSequence... suffixes)
public static String appendIfMissingIgnoreCase(String str,CharSequence suffix,CharSequence... suffixes)
// 无条件同时增加前缀和后缀
public static String wrap(String str,char wrapWith)
public static String wrap(String str,String wrapWith)
// 有条件同时增加前缀和后缀
public static String wrapIfMissing(String str,char wrapWith)
public static String wrapIfMissing(String str,String wrapWith)
// 去除前缀和后缀
public static String unwrap(String str,char wrapChar)
public static String unwrap(String str,String wrapToken)
5. 字符串转换
字符串内容意义不变,形式变化
5.1 大小写转换
转换字符串至大写或小写状态
// 转换大写
public static String upperCase(String str)
public static String upperCase(String str,Locale locale)
// 转换小写
public static String lowerCase(String str)
public static String lowerCase(String str,Locale locale)
// 首字母大写
public static String capitalize(String str)
// 首字母小写
public static String uncapitalize(String str)
// 大小写交换,即大写变小写,小写变大写
public static String swapCase(String str)
5.2 字符串缩略
将字符串缩减为指定宽度
public static String abbreviate(String str,int maxWidth)
注意,maxWidth 必须 >=4,否则抛异常
如果字符长度小于 maxWidth,直接返回该字符串,否则缩减效果为 substring (str, 0, max-3) + "..."
示例:
StringUtils.abbreviate("abcdefg", 4) = "a..."
扩展:
// 可指定缩减字符的省略符号
public static String abbreviate(String str,String abbrevMarker,int maxWidth)
示例:
StringUtils.abbreviate("abcdefg", "..", 4) = "ab.."
StringUtils.abbreviate("abcdefg", "..", 3) = "a.."
另有其他重载函数,可指定起始位置,实现..ab.. 效果,同样过于复杂,会导致代码可读性变差,不建议使用
5.3 补齐字符串
自动补齐至指定宽度,可指定字符,如不指定,默认补空格,有三个,center、leftPad 和 rightPad
使用场景:
1) 显示时补充数据宽度一致使其对齐,更美观
2) 单据流水号,宽度固定,左侧补 0
public static String center(String str,int size)
public static String center(String str,int size,char padChar)
public static String center(String str,int size,String padStr)
public static String leftPad(String str,int size)
public static String leftPad(String str,int size,char padChar)
public static String leftPad(String str,int size,String padStr)
public static String rightPad(String str,int size)
public static String rightPad(String str,int size,char padChar)
public static String rightPad(String str,int size,String padStr)
5.4 旋转字符串
//shift 大于 0 则右旋,小于 0 则左旋
public static String rotate(String str,int shift)
示例:
StringUtils.rotate("abcdefg", 2) = "fgabcde"
StringUtils.rotate("abcdefg", -2) = "cdefgab"
// 完全颠倒字符串顺序
public static String reverse(String str)
// 颠倒字符串顺序,以间隔符为单位进行,单个元素内部不颠倒位置
public static String reverseDelimited(String str,char separatorChar)
示例:
StringUtils.reverseDelimited("a.bc.d",''.'')=“d.bc.a”
5.5 编码转换
// 将字节数组转换为指定编码的字符串
public static String toEncodedString(byte[] bytes,Charset charset)
应用场景:系统间交互时,字符编码不一致,如对方传递的参数编码为 GB2312, 我方编码为 UTF-8,可通过该方法进行转换
// 转换 unicode 位码
public static int[] toCodePoints(CharSequence str)
6 其他
难以归类的一些功能性方法
6.1 取字符串长度
public static int length(CharSequence cs)
6.2. 计算匹配次数
public static int countMatches(CharSequence str,CharSequence sub)
public static int countMatches(CharSequence str,char ch)
6.3 默认值处理
// 获取默认字符串,null 及空格将会返回 “”,其他情况返回原始字符串
public static String defaultString(String str)
// 获取默认字符串,第一个参数为 null 及空格将会返回第二个参数指定值,其他情况返回原始字符串
public static String defaultString(String str,String defaultStr)
// 其他处理,如果为空白或空,返回指定值
public static <T extends CharSequence> T defaultIfBlank(T str,T defaultStr)
public static <T extends CharSequence> T defaultIfEmpty(T str,T defaultStr)
// 其他处理,返回数组中第一个不为空白或不为空的元素
public static <T extends CharSequence> T firstNonBlank(T... values)
public static <T extends CharSequence> T firstNonEmpty(T... values)
6.4. 字符串差异
// 返回字符串差异部分,实用性差,不建议使用
public static String difference(String str1,String str2)
// 返回字符串差异的索引位置
public static int indexOfDifference(CharSequence cs1,CharSequence cs2)
public static int indexOfDifference(CharSequence... css)
6.5 取字符串相同前缀
public static String getCommonPrefix(String... strs)
示例:
StringUtils.getCommonPrefix(new String[] {"abcde", "abxyz"}) = "ab"
原文出处:https://www.cnblogs.com/sealy321/p/10227131.html
关于org.apache.commons.lang.StringUtils的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于apache commons StringUtils、apache commons StringUtils介绍、apache commons StringUtils工具类使用、Apache Commons 包 StringUtils 工具类深入整理的相关信息,请在本站寻找。
本文标签:




