如果您对kubernetes.v1.11.0感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解kubernetes.v1.11.0的各种细节,此外还有关于centos7下kubernetes(11
如果您对kubernetes.v1.11.0感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解kubernetes.v1.11.0的各种细节,此外还有关于centos7下kubernetes(11。kubernetes-运行一次性任务)、kubeadm 安装 kubernetes-v1.13.1、kubeadm 部署 kubernetes v1.14.1 高可用集群、kubeadm安装kubernetes(v18.8.8)的实用技巧。
本文目录一览:- kubernetes.v1.11.0
- centos7下kubernetes(11。kubernetes-运行一次性任务)
- kubeadm 安装 kubernetes-v1.13.1
- kubeadm 部署 kubernetes v1.14.1 高可用集群
- kubeadm安装kubernetes(v18.8.8)

kubernetes.v1.11.0
环境要求
Kubernetes的版本为 V1.11.0
kube-apiserver
kube-scheduler
kube-controller-manager
etcd
kubectl
kubelet
kube-proxy
etcd 版本为 V3.3.8
docker 版本 18.03.1-ce
kubernetes 1.11.0
安装版本地址:
https://github.com/kubernetes/kubernetes/releases/tag/v1.11.0
二进制下载地址:
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.11.md#v1110
wget https://dl.k8s.io/v1.11.0/kubernetes-server-linux-amd64.tar.gz
sha256 b8a8a88afd8a40871749b2362dbb21295c6a9c0a85b6fc87e7febea1688eb99e
tar xvf kubernetes-server-linux-amd64.tar.gz
服务器上需要的二进制文件并不在下载的 tar 包中,需要解压tar包,然后执行cluster/get-kube-binaries.sh。
系统初始化
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld
vi /etc/sysconfig/selinux
SELINUX=disabled
swapoff -a
vi /etc/fstab
#/swap none swap sw 0 0
# 配置sysctl.conf
vi /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
# 执行以下命令使修改生效
modprobe br_netfilter
sysctp -p
master
etcd 下载
https://github.com/etcd-io/etcd/blob/master/CHANGELOG-3.2.md
wget https://github.com/etcd-io/etcd/releases/download/v3.3.13/etcd-v3.3.13-linux-amd64.tar.gz
wget https://github.com/etcd-io/etcd/releases/download/v3.2.11/etcd-v3.2.11-linux-amd64.tar.gz
tar xvf etcd-v3.2.11-linux-amd64.tar.gz
cd etcd-v3.2.11-linux-amd64
cp etcd etcdctl /usr/bin/
vi /usr/lib/systemd/system/etcd.service
[Unit]
Description=etcd.service
[Service]
Type=notify
TimeoutStartSec=0
Restart=always
WorkingDirectory=/var/lib/etcd
EnvironmentFile=-/etc/etcd/etcd.conf
ExecStart=/usr/bin/etcd
[Install]
WantedBy=multi-user.target
mkdir -p /var/lib/etcd && mkdir -p /etc/etcd/
vi /etc/etcd/etcd.conf
ETCD_NAME=ETCD Server
ETCD_DATA_DIR="/var/lib/etcd/"
ETCD_LISTEN_CLIENT_URLS=http://0.0.0.0:2379
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.101:2379"
# 启动etcd
systemctl daemon-reload
systemctl start etcd.service
systemctl enable etcd.service
systemctl status etcd.service
查看etcd状态是否正常
etcdctl cluster-health
member 8e9e05c52164694d is healthy: got healthy result from http://127.0.0.1:2379
cluster is healthy
创建 etcd 网络
etcdctl mk /atomic.io/network/config ''{"Network":"172.17.0.0/16"}
master kube-apiserver
添加配置文件
vi /usr/lib/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
After=etcd.service
Wants=etcd.service
[Service]
EnvironmentFile=/etc/kubernetes/apiserver
ExecStart=/usr/bin/kube-apiserver \
$KUBE_ETCD_SERVERS \
$KUBE_API_ADDRESS \
$KUBE_API_PORT \
$KUBE_SERVICE_ADDRESSES \
$KUBE_ADMISSION_CONTROL \
$KUBE_API_LOG \
$KUBE_API_ARGS
Restart=on-failure
Type=notify
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
# 创建配置文件
cp -r kube-apiserver /usr/bin/
vi /etc/kubernetes/apiserver
KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0"
KUBE_API_PORT="--port=8080"
KUBELET_PORT="--kubelet-port=10250"
KUBE_ETCD_SERVERS="--etcd-servers=http://192.168.0.101:2379" # 先改成 127.0.0.1 启动正常后 再使用 IP
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.0.0.0/24"
KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ResourceQuota"
KUBE_API_ARGS=""
# 启动服务
systemctl daemon-reload
systemctl start kube-apiserver.service
systemctl enable kube-apiserver.service
systemctl status kube-apiserver.service
# 查看启动是否成功
netstat -tnlp | grep kube
tcp6 0 0 :::6443 :::* LISTEN 27378/kube-apiserve
tcp6 0 0 :::8080 :::* LISTEN 10144/kube-apiserve
master 安装kube-controller-manager
vi /usr/lib/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Scheduler
After=kube-apiserver.service
Requires=kube-apiserver.service
[Service]
EnvironmentFile=-/etc/kubernetes/controller-manager
ExecStart=/usr/bin/kube-controller-manager \
$KUBE_MASTER \
$KUBE_CONTROLLER_MANAGER_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
# 创建配置文件
cp -r kube-controller-manager /usr/bin/
vi /etc/kubernetes/controller-manager
KUBE_MASTER="--master=http://192.168.0.101:8080"
KUBE_CONTROLLER_MANAGER_ARGS=" "
# 启动服务
systemctl daemon-reload
systemctl restart kube-controller-manager.service
systemctl enable kube-controller-manager.service
systemctl status kube-controller-manager.service
# 验证服务状态
netstat -lntp | grep kube-controll
tcp6 0 0 :::10252 :::* LISTEN 10163/kube-controll
master 安装 kube-scheduler
vi /usr/lib/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
After=kube-apiserver.service
Requires=kube-apiserver.service
[Service]
User=root
EnvironmentFile=/etc/kubernetes/scheduler
ExecStart=/usr/bin/kube-scheduler \
$KUBE_MASTER \
$KUBE_SCHEDULER_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
# 修改配置
cp -r kube-scheduler /usr/bin/
vi /etc/kubernetes/scheduler
KUBE_MASTER="--master=http://192.168.0.101:8080"
KUBE_SCHEDULER_ARGS="--logtostderr=true --log-dir=/home/log/kubernetes --v=2"
# 启动服务
systemctl daemon-reload
systemctl start kube-scheduler.service
systemctl enable kube-scheduler.service
systemctl status kube-scheduler.service
# 验证服务状态
netstat -lntp | grep kube-schedule
tcp6 0 0 :::10251 :::* LISTEN 10179/kube-schedule
查看状态
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
到这里Master节点就配置完毕。
配置集群网络
Flannel可以使整个集群的docker容器拥有唯一的内网IP,并且多个node之间的docker0可以互相访问。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml
集群验证
kubectl get nodes
NAME STATUS ROLES AGE VERSION
localhost.localdomain Ready <none> 37m v1.11.0
node
node 环境配置
docker-ce-1.18.1
kubelet
kube-proxy
node 配置
1.拷贝kubelet kube-proxy
cp kubernetes/server/bin/kubelet /usr/bin/
cp kubernetes/server/bin/kube-proxy /usr/bin/
2.安装kube-proxy 服务
vi /usr/lib/systemd/system/kube-proxy.service
[Unit]
Description=Kubernetes Proxy
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
EnvironmentFile=/etc/kubernetes/config
EnvironmentFile=/etc/kubernetes/proxy
ExecStart=/usr/bin/kube-proxy \
$KUBE_LOGTOSTDERR \
$KUBE_LOG_LEVEL \
$KUBE_MASTER \
$KUBE_PROXY_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
mkdir -p /etc/kubernetes
vi /etc/kubernetes/proxy
KUBE_PROXY_ARGS=""
vi /etc/kubernetes/config
KUBE_LOGTOSTDERR="--logtostderr=true"
KUBE_LOG_LEVEL="--v=0"
KUBE_ALLOW_PRIV="--allow_privileged=false"
KUBE_MASTER="--master=http://192.168.3.8:8080"
# 启动服务
systemctl daemon-reload
systemctl start kube-proxy.service
systemctl enable kube-proxy.service
systemctl status kube-proxy.service
netstat -lntp | grep kube-proxy
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 26899/kube-proxy
tcp6 0 0 :::10256 :::* LISTEN 26899/kube-proxy
node kubelet 服务
vi /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=docker.service
Requires=docker.service
[Service]
WorkingDirectory=/var/lib/kubelet
EnvironmentFile=/etc/kubernetes/kubelet
ExecStart=/usr/bin/kubelet $KUBELET_ARGS
Restart=on-failure
KillMode=process
[Install]
WantedBy=multi-user.target
mkdir -p /var/lib/kubelet
vi /etc/kubernetes/kubelet
KUBELET_ADDRESS="--address=0.0.0.0"
KUBELET_HOSTNAME="--hostname-override=127.0.0.1-node"
KUBELET_API_SERVER="--api-servers=http://127.0.0.1:8080"
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.cn-shenzhen.aliyuncs.com/pod-infrastructure-1/pod-infrastructure:latest"
KUBELET_ARGS="--enable-server=true --enable-debugging-handlers=true --fail-swap-on=false --kubeconfig=/var/lib/kubelet/kubeconfig"
# 创建配置文件
vi /var/lib/kubelet/kubeconfig
apiVersion: v1
kind: Config
users:
- name: kubelet
clusters:
- name: kubernetes
cluster:
server: http://127.0.0.1:8080
contexts:
- context:
cluster: kubernetes
user: kubelet
name: service-account-context
current-context: service-account-context
# 启动kubelet并进习验证
swapoff -a
systemctl daemon-reload
systemctl start kubelet.service
systemctl enable kubelet.service
systemctl status kubelet.service
netstat -tnlp | grep kubelet
tcp 0 0 127.0.0.1:45094 0.0.0.0:* LISTEN 27003/kubelet
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 27003/kubelet
tcp6 0 0 :::10250 :::* LISTEN 27003/kubelet
tcp6 0 0 :::10255 :::* LISTEN 27003/kubelet
")
centos7下kubernetes(11。kubernetes-运行一次性任务)
容器按照持续运行的时间可以分为两类:服务类容器和工作类容器
服务类容器:持续提供服务
工作类容器:一次性任务,处理完后容器就退出
Deployment,replicaset和daemonset都用于管理服务类容器,
对于工作类的容器,我们用job
编辑一个简单的job类型的yml文件
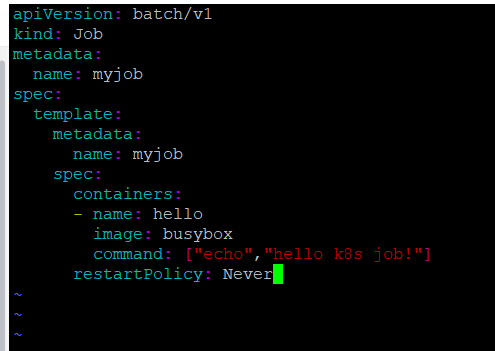
1.apiversion:当前job的apiversion是batch/v1
2.kind:当前的资源类型是job
3.restartpolicy指定什么情况下需要重启容器。对于job只能设置为never或者onfailure
对于其他的controller(比如deployment,replicaset等)可以设置为always
创建job应用

通过kubectl get job进行查看

显示destire为1,成功1
说明是按照预期启动了一个pod,并且成功执行
查看pod的状态

由于myjob的pod处于completed的状态,所以需要加--show-all参数才能显示出来
通过kubectl logs 查看pod标准输出

如果job没有执行成功,怎么办?
修改job.yml文件,故意引起一个错误,然后重新启动myjob
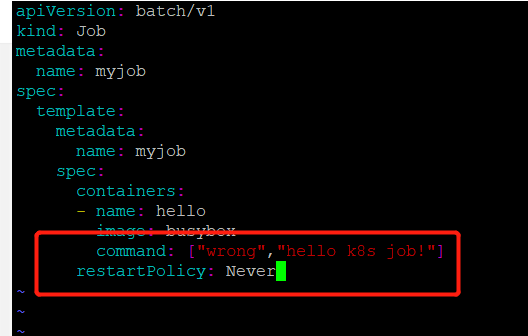
先将原来的job删除

然后重新启动一个新的job
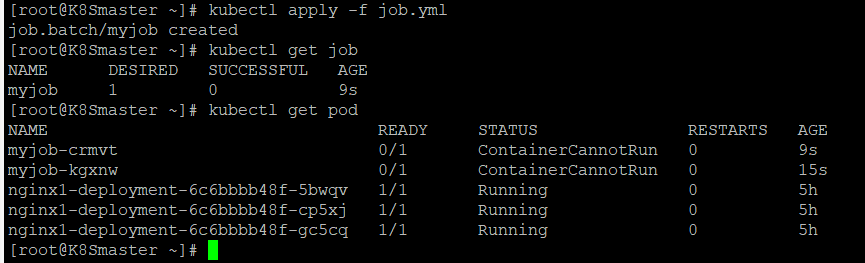
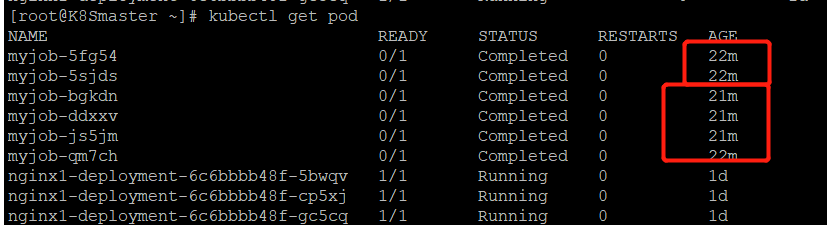
重新启动一个job,我们发现有一个未成功的job,查看pod的时候竟然有两个job相关的pod,目标job只有1个啊,为什么??
我们再次查看一下
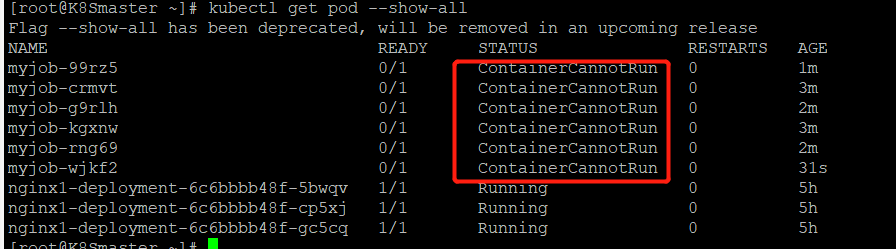
目前达到了6个
原因是:当地一个pod启动时,容器失败退出,根据restartPolicy:Never,此失败容器不会被重启,但是job destired的pod是1,目前successful为1。由于我们的命令是错误的,successful永远不能到1,
job contorller会一直创建新的pod达到job得期望状态,最多重新创建6次,因为K8S为job提供了spec.bakcofflimits来限制重试次数,默认为6.
如果将restartpolicy设置为OnFailure会怎么样?我们来实验一下
修改job.yml文件
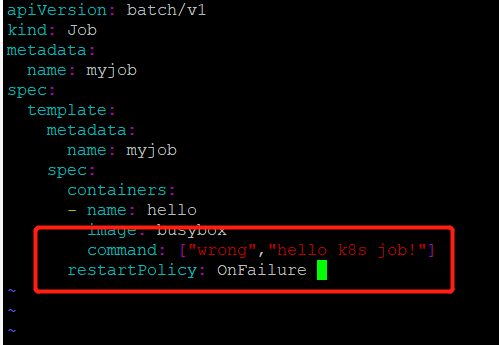
将restartpolicy修改为OnFailure
重新启动job.yml

pod数量只有1,job为失败得状态
但是pod得restart得次数在变化,说明onfailure生效,容器失败后会自动重启
并行执行job
之前我们得实验都是一次运行一个job里只有一个pod,当我们同时运行多个pod得时候,怎么进行设置呢?
可以通过:parallelism设置
修改job.yml文件
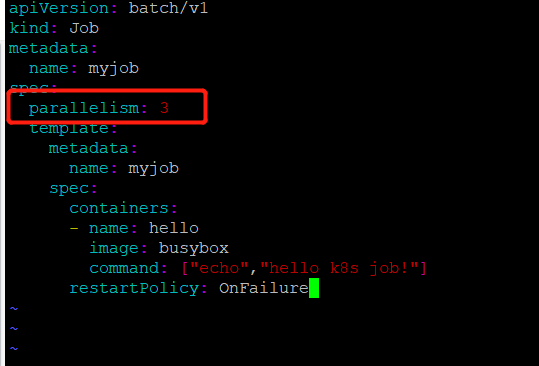
此次我们执行一个job同时运行3个pod
kubectl apply -f job.yml
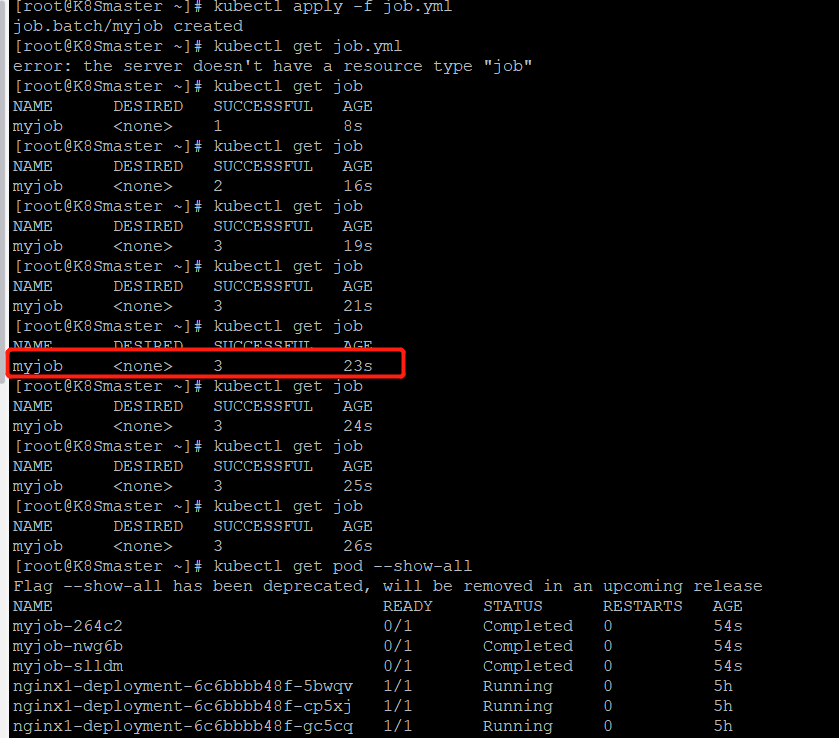
job一共启动了3个pod,而且AGE相同,说明是并行运行得。
还可以通过completions设置job成功完成pod的总数;
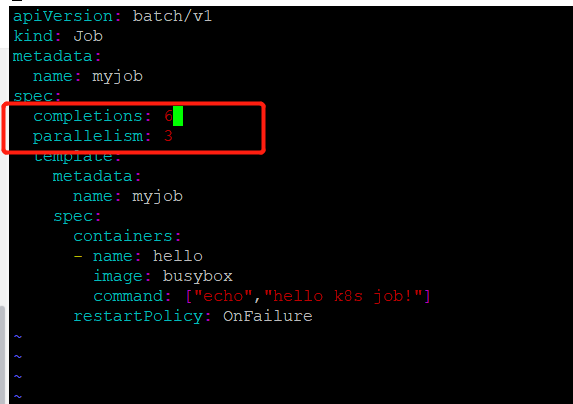
配置含义:每次运行3个pod,知道运行了6个结束
重新执行一下
kubectl apply -f job.yml
也不是很准,但是确实不是同时并行启动的
定时执行job
kubernetes提供了类似crontab定时执行任务的功能
首先修改apiserver使api支持cronjob
vim /etc/kubernetes/manifests/kube-apiserver.yaml
- --runtime-config=batch/v1beta1=true 加入这一行
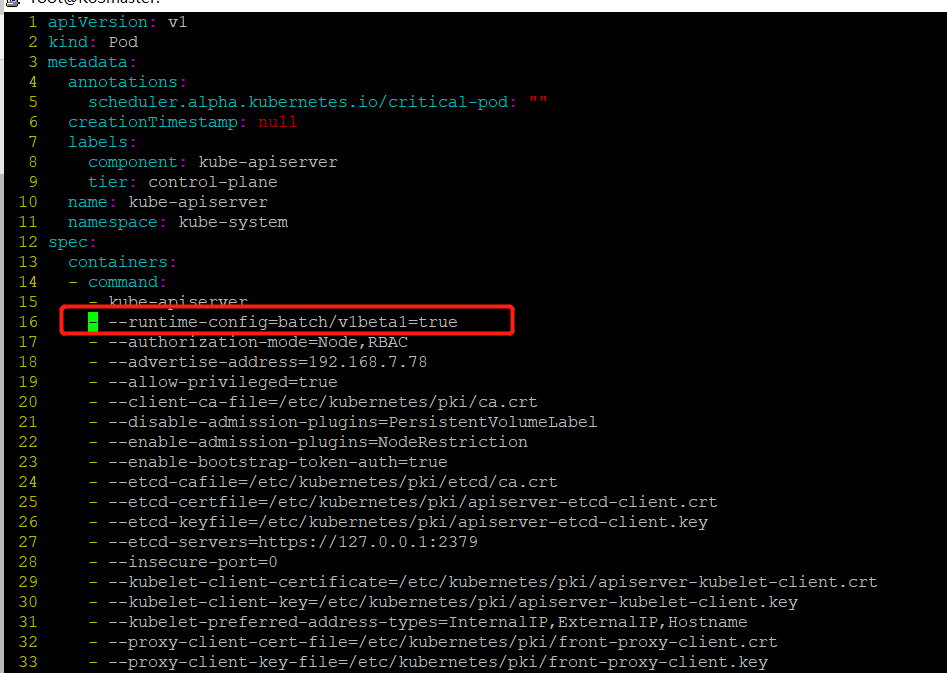
保存退出
kubectl apiversions 查看api版本(如果这里没有生效的话,需要重启kubelet这个服务)
systemctl restart kubelet.service
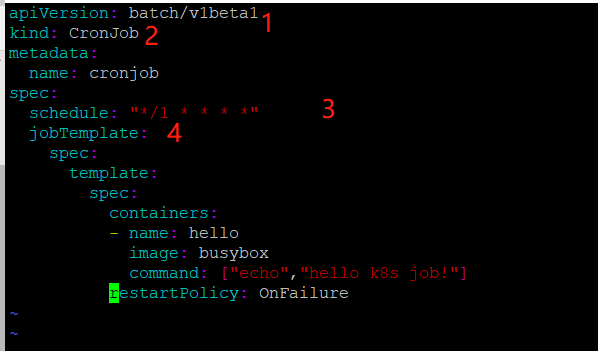
修改yml文件如下:
apiVersion: batch/v1beta1 batch/v1beta1当前cronjob的apiserver
kind: CronJob 当前资源类型为cronjob
metadata:
name: cronjob
spec:
schedule: "*/1 * * * *" 指定什么时候运行job,格式与linux中的计划任务一致
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["echo","hello k8s job!"]
restartPolicy: OnFailure
~
运行这个job
kubectl apply -f job.yml
如果出现一下错误请一定要检查yml文件的内容,进行修改

正常运行如下:

查看cronjob
kubectl get cronjob

查看job,通过时间间隔可以看到,每1分种创建一个pod
kubectl get job

查看pod日志

删除cronjob
kubectl delete cronjob cronjob


kubeadm 安装 kubernetes-v1.13.1
#kubeadm 安装 kubernetes-v1.13.1 centos 虚拟机使用 kubeadm 安装 k8s-v1.13.1。
机器信息如下:
| 主机名 | ip |
|---|---|
| master | 192.168.239.200 |
| node1 | 192.168.239.201 |
| node2 | 192.168.239.202 |
## 环境准备
设置主机名
192.168.239.200 master
192.168.239.201 node1
192.168.239.202 node2
关闭 swap
swapoff -a
sed -i ''s/.*swap.*/#&/'' /etc/fstab
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
关闭 selinux
setenforce 0
配置相关参数
net.ipv4.ip_forward=1
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
vm.swappiness=0
sysctl -p
##docker 安装
安装 docker 的 yum 源
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
查看 docker 版本
yum list docker-ce.x86_64 --showduplicates |sort -r
docker-ce.x86_64 3:18.09.0-3.el7 docker-ce-stable
docker-ce.x86_64 18.06.1.ce-3.el7 docker-ce-stable
docker-ce.x86_64 18.06.1.ce-3.el7 @docker-ce-stable
docker-ce.x86_64 18.06.0.ce-3.el7 docker-ce-stable
docker-ce.x86_64 18.03.1.ce-1.el7.centos docker-ce-stable
docker-ce.x86_64 18.03.0.ce-1.el7.centos docker-ce-stable
docker-ce.x86_64 17.12.1.ce-1.el7.centos docker-ce-stable
docker-ce.x86_64 17.12.0.ce-1.el7.centos docker-ce-stable
docker-ce.x86_64 17.09.1.ce-1.el7.centos docker-ce-stable
docker-ce.x86_64 17.09.0.ce-1.el7.centos docker-ce-stable
docker-ce.x86_64 17.06.2.ce-1.el7.centos docker-ce-stable
安装 docker
yum install -y --setopt=obsoletes=0 docker-ce-18.06.1.ce-3.el7
systemctl start docker
systemctl enable docker
## 安装 kubeadm 等
配置阿里云源
vim /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
node 结点不用安装 kubectl
yum install -y kubelet kubeadm kubectl
systemctl enable kubelet
systemctl start kubelet
## 安装 master 结点 国内无法访问 google 的镜像源,需要自己生成放到 docker hub。
如何自己生成镜像放到 docker hub 请看 Docker Hub 上自动制做 Docker 镜像
下载自己生成的镜像源
vim pull-kube-image.sh
#!/bin/bash
images=(kube-scheduler:v1.13.1
kube-proxy:v1.13.1
kube-controller-manager:v1.13.1
kube-apiserver:v1.13.1
pause:3.1
coredns:1.2.6
etcd:3.2.24)
for imagename in ${images[@]}; do
docker pull mathlsj/$imagename
docker tag mathlsj/$imagename k8s.gcr.io/$imagename
docker rmi mathlsj/$imagename
done
docker pull quay.io/coreos/flannel:v0.10.0-amd64
查看镜像源
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-scheduler v1.13.1 9bf9c8fb24af 7 days ago 79.6MB
k8s.gcr.io/kube-proxy v1.13.1 6fbfd87ede1f 7 days ago 80.2MB
k8s.gcr.io/kube-controller-manager v1.13.1 f5e8b3a9a6bf 7 days ago 146MB
k8s.gcr.io/kube-apiserver v1.13.1 14219a09a24c 7 days ago 181MB
k8s.gcr.io/pause 3.1 68112c580347 8 days ago 742kB
k8s.gcr.io/coredns 1.2.6 75ca836e805a 8 days ago 40MB
k8s.gcr.io/etcd 3.2.24 c10486f7ea38 9 days ago 220MB
k8s.gcr.io/kubernetes-dashboard-amd64 v1.8.3 0c60bcf89900 11 months ago 102MB
quay.io/coreos/flannel v0.10.0-amd64 f0fad859c909 11 months ago 44.6MB
节点初始化
kubeadm init --kubernetes-version=v1.13.1 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.239.200
看到 Your Kubernetes master has initialized successfully! 就表示初始化成功了。
要使用 kubectl 需要以下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看初始化情况
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 3d1h v1.13.2
kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-86c58d9df4-2nhd5 0/1 Pending 0 35m
kube-system coredns-86c58d9df4-l2wt9 0/1 Pending 0 35m
kube-system etcd-master 1/1 Running 0 34m
kube-system kube-apiserver-master 1/1 Running 0 34m
kube-system kube-controller-manager-master 1/1 Running 0 34m
kube-system kube-proxy-fqjvp 1/1 Running 0 35m
kube-system kube-scheduler-master 1/1 Running 0 34m
安装 flannel 网络
wget https://raw.githubusercontent.com/coreos/flannel/bc79dd1505b0c8681ece4de4c0d86c5cd2643275/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
## 安装 node 结点 在安装前,先完成前面的环境准备,docker 安装和安装 kubeadm 等。
下载镜像源
vim pull-kube-image.sh
#!/bin/bash
images=(kube-proxy:v1.13.1
pause:3.1
coredns:1.2.6)
for imagename in ${images[@]}; do
docker pull mathlsj/$imagename
docker tag mathlsj/$imagename k8s.gcr.io/$imagename
docker rmi mathlsj/$imagename
done
docker pull quay.io/coreos/flannel:v0.10.0-amd64
查看镜像
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-proxy v1.13.1 6fbfd87ede1f 7 days ago 80.2MB
k8s.gcr.io/pause 3.1 68112c580347 8 days ago 742kB
k8s.gcr.io/coredns 1.2.6 75ca836e805a 8 days ago 40MB
quay.io/coreos/flannel v0.10.0-amd64 f0fad859c909 11 months ago 44.6MB
查看 token, 在 master 结点上看
kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
km7adp.vu3fugeopqgyj8rk 23h 2019-01-15T09:22:48-05:00 authentication,signing The default bootstrap token generated by ''kubeadm init''. system:bootstrappers:kubeadm:default-node-token
加入节点
kubeadm join --discovery-token km7adp.vu3fugeopqgyj8rk --discovery-token-ca-cert-hash sha256:4e05312726ad565688309951d6c8afb2965e1ce80f736d0123b4363581fcb106 192.168.239.200:6443
在 master 上查看状态
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 92m v1.13.2
node1 Ready <none> 41m v1.13.2
kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-86c58d9df4-2nhd5 1/1 Running 0 84m 10.244.1.2 node1 <none> <none>
kube-system coredns-86c58d9df4-l2wt9 1/1 Running 0 84m 10.244.1.3 node1 <none> <none>
kube-system etcd-master 1/1 Running 0 83m 192.168.239.200 master <none> <none>
kube-system kube-apiserver-master 1/1 Running 0 83m 192.168.239.200 master <none> <none>
kube-system kube-controller-manager-master 1/1 Running 0 83m 192.168.239.200 master <none> <none>
kube-system kube-flannel-ds-amd64-786l8 1/1 Running 0 16m 192.168.239.200 master <none> <none>
kube-system kube-flannel-ds-amd64-pc4fp 1/1 Running 0 16m 192.168.239.201 node1 <none> <none>
kube-system kube-proxy-fqjvp 1/1 Running 0 84m 192.168.239.200 master <none> <none>
kube-system kube-proxy-skndl 1/1 Running 0 33m 192.168.239.201 node1 <none> <none>
kube-system kube-scheduler-master 1/1 Running 0 83m 192.168.239.200 master <none> <none>
参考文档
- http://blog.51cto.com/lullaby/2150610?utm_source=oschina-app
- https://my.oschina.net/u/2601623/blog/1634641
- https://kubernetes.io/docs/setup/independent/install-kubeadm/
原文出处:https://www.cnblogs.com/mathli/p/10289840.html

kubeadm 部署 kubernetes v1.14.1 高可用集群
第 1 章 高可用简介
kubernetes 高可用部署参考:
https://kubernetes.io/docs/setup/independent/high-availability/
https://github.com/kubernetes-sigs/kubespray
https://github.com/wise2c-devops/breeze
https://github.com/cookeem/kubeadm-ha
1.1 拓扑选择
配置高可用(HA)Kubernetes 集群,有以下两种可选的 etcd 拓扑:
- 集群 master 节点与 etcd 节点共存,etcd 也运行在控制平面节点上
- 使用外部 etcd 节点,etcd 节点与 master 在不同节点上运行
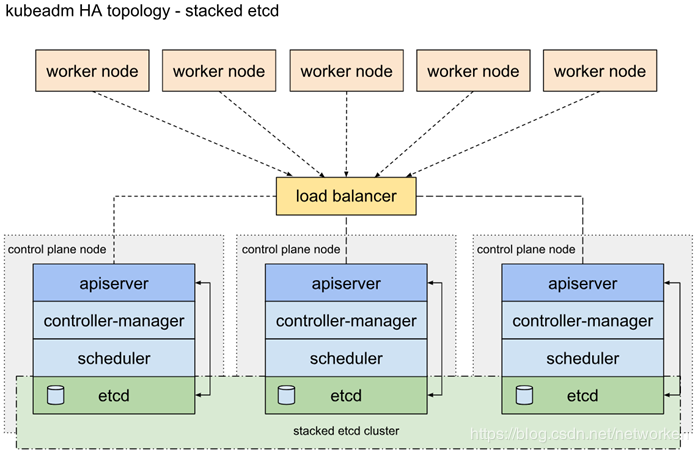
1.1.1 堆叠的 etcd 拓扑
堆叠 HA 集群是这样的拓扑,其中 etcd 提供的分布式数据存储集群与由 kubeamd 管理的运行 master 组件的集群节点堆叠部署。
每个 master 节点运行 kube-apiserver,kube-scheduler 和 kube-controller-manager 的一个实例。kube-apiserver 使用负载平衡器暴露给工作节点。
每个 master 节点创建一个本地 etcd 成员,该 etcd 成员仅与本节点 kube-apiserver 通信。这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例。
该拓扑将 master 和 etcd 成员耦合在相同节点上。比设置具有外部 etcd 节点的集群更简单,并且更易于管理复制。
但是,堆叠集群存在耦合失败的风险。如果一个节点发生故障,则 etcd 成员和 master 实例都将丢失,并且冗余会受到影响。您可以通过添加更多 master 节点来降低此风险。
因此,您应该为 HA 群集运行至少三个堆叠的 master 节点。
这是 kubeadm 中的默认拓扑。使用 kubeadm init 和 kubeadm join --experimental-control-plane 命令时,在 master 节点上自动创建本地 etcd 成员。
1.1.2 外部 etcd 拓扑
具有外部 etcd 的 HA 集群是这样的拓扑,其中由 etcd 提供的分布式数据存储集群部署在运行 master 组件的节点形成的集群外部。
像堆叠 ETCD 拓扑结构,在外部 ETCD 拓扑中的每个 master 节点运行一个 kube-apiserver,kube-scheduler 和 kube-controller-manager 实例。并且 kube-apiserver 使用负载平衡器暴露给工作节点。但是,etcd 成员在不同的主机上运行,每个 etcd 主机与 kube-apiserver 每个 master 节点进行通信。
此拓扑将 master 节点和 etcd 成员分离。因此,它提供了 HA 设置,其中丢失 master 实例或 etcd 成员具有较小的影响并且不像堆叠的 HA 拓扑那样影响集群冗余。
但是,此拓扑需要两倍于堆叠 HA 拓扑的主机数。具有此拓扑的 HA 群集至少需要三个用于 master 节点的主机和三个用于 etcd 节点的主机。

1.2 部署要求
使用 kubeadm 部署高可用性 Kubernetes 集群的两种不同方法:
- 使用堆叠 master 节点。这种方法需要较少的基础设施,etcd 成员和 master 节点位于同一位置。
- 使用外部 etcd 集群。这种方法需要更多的基础设施, master 节点和 etcd 成员是分开的。
在继续之前,您应该仔细考虑哪种方法最能满足您的应用程序和环境的需求。
部署要求
- 至少 3 个 master 节点
- 至少 3 个 worker 节点
- 所有节点网络全部互通(公共或私有网络)
- 所有机器都有 sudo 权限
- 从一个设备到系统中所有节点的 SSH 访问
- 所有节点安装 kubeadm 和 kubelet,kubectl 是可选的。
- 针对外部 etcd 集群,你需要为 etcd 成员额外提供 3 个节点
1.3 负载均衡
部署集群前首选需要为 kube-apiserver 创建负载均衡器。
注意:负载平衡器有许多中配置方式。可以根据你的集群要求选择不同的配置方案。在云环境中,您应将 master 节点作为负载平衡器 TCP 转发的后端。此负载平衡器将流量分配到其目标列表中的所有健康 master 节点。apiserver 的运行状况检查是对 kube-apiserver 侦听的端口的 TCP 检查(默认值:6443)。
负载均衡器必须能够与 apiserver 端口上的所有 master 节点通信。它还必须允许其侦听端口上的传入流量。另外确保负载均衡器的地址始终与 kubeadm 的 ControlPlaneEndpoint 地址匹配。
haproxy/nignx+keepalived 是其中可选的负载均衡方案,针对公有云环境可以直接使用运营商提供的负载均衡产品。
部署时首先将第一个 master 节点添加到负载均衡器并使用以下命令测试连接:
# nc -v LOAD_BALANCER_IP PORT由于 apiserver 尚未运行,因此预计会出现连接拒绝错误。但是,超时意味着负载均衡器无法与 master 节点通信。如果发生超时,请重新配置负载平衡器以与 master 节点通信。将剩余的 master 节点添加到负载平衡器目标组。
第 2 章 部署集群
本次使用 kubeadm 部署 kubernetes v1.14.1 高可用集群,包含 3 个 master 节点和 1 个 node 节点,部署步骤以官方文档为基础,负载均衡部分采用 haproxy+keepalived 容器方式实现。所有组件版本以 kubernetes v1.14.1 为准,其他组件以当前最新版本为准。
2.1 基本配置
节点信息:
以下操作在所有节点执行
#配置主机名
hostnamectl set-hostname k8s-master01
hostnamectl set-hostname k8s-master02
hostnamectl set-hostname k8s-master03
hostnamectl set-hostname k8s-node01
#修改/etc/hosts
cat >> /etc/hosts << EOF
192.168.92.10 k8s-master01
192.168.92.11 k8s-master02
192.168.92.12 k8s-master03
192.168.92.13 k8s-node01
EOF
# 开启firewalld防火墙并允许所有流量
systemctl start firewalld && systemctl enable firewalld
firewall-cmd --set-default-zone=trusted
firewall-cmd --complete-reload
# 关闭selinux
sed -i ''s/^SELINUX=enforcing$/SELINUX=disabled/'' /etc/selinux/config && setenforce 0
#关闭swap
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak | grep -v swap > /etc/fstab配置时间同步
使用 chrony 同步时间,centos7 默认已安装,这里修改时钟源,所有节点与网络时钟源同步:
# 安装chrony:
yum install -y chrony
cp /etc/chrony.conf{,.bak}
# 注释默认ntp服务器
sed -i ''s/^server/#&/'' /etc/chrony.conf
# 指定上游公共 ntp 服务器
cat >> /etc/chrony.conf << EOF
server 0.asia.pool.ntp.org iburst
server 1.asia.pool.ntp.org iburst
server 2.asia.pool.ntp.org iburst
server 3.asia.pool.ntp.org iburst
EOF
# 设置时区
timedatectl set-timezone Asia/Shanghai
# 重启chronyd服务并设为开机启动:
systemctl enable chronyd && systemctl restart chronyd
#验证,查看当前时间以及存在带*的行
timedatectl && chronyc sources加载 IPVS 模块
在所有的Kubernetes节点执行以下脚本(若内核大于4.19替换nf_conntrack_ipv4为nf_conntrack):
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
#执行脚本
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
#安装相关管理工具
yum install ipset ipvsadm -y配置内核参数
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1
vm.swappiness=0
EOF
sysctl --system
2.2 安装 docker
CRI 安装参考:https://kubernetes.io/docs/setup/cri/
要在 Pod 中运行容器,Kubernetes 使用容器运行时。以下是可选的容器运行时。
- Docker
- CRI-O
- Containerd
- Other CRI runtimes: frakti
2.2.1 Cgroup 驱动程序简介
当 systemd 被选为 Linux 发行版的 init 系统时,init 进程会生成并使用根控制组(cgroup)并充当 cgroup 管理器。Systemd 与 cgroup 紧密集成,并将为每个进程分配 cgroup。可以配置容器运行时和要使用的 kubelet cgroupfs。cgroupfs 与 systemd 一起使用意味着将有两个不同的 cgroup 管理器。
Control groups 用于约束分配给进程的资源。单个 cgroup 管理器将简化正在分配的资源的视图,并且默认情况下将具有更可靠的可用和使用资源视图。
当我们有两个 managers 时,我们最终会得到两个这些资源的视图。我们已经看到了现场的情况,其中配置 cgroupfs 用于 kubelet 和 Docker systemd 的节点以及在节点上运行的其余进程在资源压力下变得不稳定。
更改设置,使容器运行时和 kubelet systemd 用作 cgroup 驱动程序,从而使系统稳定。请注意 native.cgroupdriver=systemd 下面 Docker 设置中的选项。
2.2.2 安装并配置 docker
以下操作在所有节点执行。
# 安装依赖软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加Docker repository,这里改为国内阿里云yum源
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce
yum update -y && yum install -y docker-ce
## 创建 /etc/docker 目录
mkdir /etc/docker
# 配置 daemon.
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"registry-mirrors": ["https://uyah70su.mirror.aliyuncs.com"]
}
EOF
#注意,由于国内拉取镜像较慢,配置文件最后追加了阿里云镜像加速配置。
mkdir -p /etc/systemd/system/docker.service.d
# 重启docker服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
2.3 安装负载均衡
kubernetes master 节点运行如下组件:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
kube-scheduler 和 kube-controller-manager 可以以集群模式运行,通过 leader 选举产生一个工作进程,其它进程处于阻塞模式。
kube-apiserver 可以运行多个实例,但对其它组件需要提供统一的访问地址,该地址需要高可用。本次部署使用 keepalived+haproxy 实现 kube-apiserver VIP 高可用和负载均衡。
haproxy+keepalived 配置 vip,实现了 api 唯一的访问地址和负载均衡。keepalived 提供 kube-apiserver 对外服务的 VIP。haproxy 监听 VIP,后端连接所有 kube-apiserver 实例,提供健康检查和负载均衡功能。
运行 keepalived 和 haproxy 的节点称为 LB 节点。由于 keepalived 是一主多备运行模式,故至少两个 LB 节点。
本次部署复用 master 节点的三台机器,在所有 3 个 master 节点部署 haproxy 和 keepalived 组件,以达到更高的可用性,haproxy 监听的端口 (6444) 需要与 kube-apiserver 的端口 6443 不同,避免冲突。
keepalived 在运行过程中周期检查本机的 haproxy 进程状态,如果检测到 haproxy 进程异常,则触发重新选主的过程,VIP 将飘移到新选出来的主节点,从而实现 VIP 的高可用。
所有组件(如 kubeclt、apiserver、controller-manager、scheduler 等)都通过 VIP +haproxy 监听的 6444 端口访问 kube-apiserver 服务。
负载均衡架构图如下:

2.4 运行 HA 容器
使用的容器镜像为睿云智合开源项目 breeze 相关镜像,具体使用方法请访问:
https://github.com/wise2c-devops
其他选择:haproxy 镜像也可以使用 dockerhub 官方镜像,但 keepalived 未提供官方镜像,可自行构建或使用 dockerhub 他人已构建好的镜像,本次部署全部使用 breeze 提供的镜像。
在 3 个 master 节点以容器方式部署 haproxy,容器暴露 6444 端口,负载均衡到后端 3 个 apiserver 的 6443 端口,3 个节点 haproxy 配置文件相同。
以下操作在 master01 节点执行。
2.4.1 创建 haproxy 启动脚本
编辑 start-haproxy.sh 文件,修改 Kubernetes Master 节点 IP 地址为实际 Kubernetes 集群所使用的值(Master Port 默认为 6443 不用修改):
mkdir -p /data/lb
cat > /data/lb/start-haproxy.sh << "EOF"
#!/bin/bash
MasterIP1=192.168.92.10
MasterIP2=192.168.92.11
MasterIP3=192.168.92.12
MasterPort=6443
docker run -d --restart=always --name HAProxy-K8S -p 6444:6444 \
-e MasterIP1=$MasterIP1 \
-e MasterIP2=$MasterIP2 \
-e MasterIP3=$MasterIP3 \
-e MasterPort=$MasterPort \
wise2c/haproxy-k8s
EOF2.4.2 创建 keepalived 启动脚本
编辑 start-keepalived.sh 文件,修改虚拟 IP 地址 VIRTUAL_IP、虚拟网卡设备名 INTERFACE、虚拟网卡的子网掩码 NETMASK_BIT、路由标识符 RID、虚拟路由标识符 VRID 的值为实际 Kubernetes 集群所使用的值。(CHECK_PORT 的值 6444 一般不用修改,它是 HAProxy 的暴露端口,内部指向 Kubernetes Master Server 的 6443 端口)
cat > /data/lb/start-keepalived.sh << "EOF"
#!/bin/bash
VIRTUAL_IP=192.168.92.30
INTERFACE=ens33
NETMASK_BIT=24
CHECK_PORT=6444
RID=10
VRID=160
MCAST_GROUP=224.0.0.18
docker run -itd --restart=always --name=Keepalived-K8S \
--net=host --cap-add=NET_ADMIN \
-e VIRTUAL_IP=$VIRTUAL_IP \
-e INTERFACE=$INTERFACE \
-e CHECK_PORT=$CHECK_PORT \
-e RID=$RID \
-e VRID=$VRID \
-e NETMASK_BIT=$NETMASK_BIT \
-e MCAST_GROUP=$MCAST_GROUP \
wise2c/keepalived-k8s
EOF复制启动脚本到其他 2 个 master 节点
[root@k8s-master02 ~]# mkdir -p /data/lb
[root@k8s-master03 ~]# mkdir -p /data/lb
[root@k8s-master01 ~]# scp start-haproxy.sh start-keepalived.sh 192.168.92.11:/data/lb/
[root@k8s-master01 ~]# scp start-haproxy.sh start-keepalived.sh 192.168.92.12:/data/lb/分别在 3 个 master 节点运行脚本启动 haproxy 和 keepalived 容器:
sh /data/lb/start-haproxy.sh && sh /data/lb/start-keepalived.sh2.4.3 验证 HA 状态
查看容器运行状态
[root@k8s-master01 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c1d1901a7201 wise2c/haproxy-k8s "/docker-entrypoint.…" 5 days ago Up 3 hours 0.0.0.0:6444->6444/tcp HAProxy-K8S
2f02a9fde0be wise2c/keepalived-k8s "/usr/bin/keepalived…" 5 days ago Up 3 hours Keepalived-K8S查看网卡绑定的 vip 为 192.168.92.30
[root@k8s-master01 ~]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.92.10/24 brd 192.168.92.255 scope global noprefixroute ens33
inet 192.168.92.30/24 scope global secondary ens33查看监听端口为 6444
[root@k8s-master01 ~]# netstat -tnlp | grep 6444
tcp6 0 0 :::6444 :::* LISTEN 11695/docker-proxykeepalived 配置文件中配置了 vrrp_script 脚本,使用 nc 命令对 haproxy 监听的 6444 端口进行检测,如果检测失败即认定本机 haproxy 进程异常,将 vip 漂移到其他节点。
所以无论本机 keepalived 容器异常或 haproxy 容器异常都会导致 vip 漂移到其他节点,可以停掉 vip 所在节点任意容器进行测试。
[root@k8s-master01 ~]# docker stop HAProxy-K8S
HAProxy-K8S
#可以看到vip漂移到k8s-master02节点
[root@k8s-master02 ~]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.92.11/24 brd 192.168.92.255 scope global noprefixroute ens33
inet 192.168.92.30/24 scope global secondary ens33也可以在本地执行该 nc 命令查看结果
[root@k8s-master02 ~]# yum install -y nc
[root@k8s-master02 ~]# nc -v -w 2 -z 127.0.0.1 6444 2>&1 | grep ''Connected to'' | grep 6444
Ncat: Connected to 127.0.0.1:6444.关于 haproxy 和 keepalived 配置文件可以在 github 源文件中参考 Dockerfile,或使用 docker exec -it xxx sh 命令进入容器查看,容器中的具体路径:
- /etc/keepalived/keepalived.conf
- /usr/local/etc/haproxy/haproxy.cfg
负载均衡部分配置完成后即可开始部署 kubernetes 集群。
2.5 安装 kubeadm
以下操作在所有节点执行。
#由于官方源国内无法访问,这里使用阿里云 yum 源进行替换:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#安装kubeadm、kubelet、kubectl,注意这里默认安装当前最新版本v1.14.1:
yum install -y kubeadm kubelet kubectl
systemctl enable kubelet && systemctl start kubelet
2.6 初始化 master 节点
初始化参考:
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta1
创建初始化配置文件
可以使用如下命令生成初始化配置文件
kubeadm config print init-defaults > kubeadm-config.yaml根据实际部署环境修改信息:
[root@k8s-master01 kubernetes]# vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta1
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.92.10
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.92.30:6444"
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.14.1
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
配置说明:
- controlPlaneEndpoint:为 vip 地址和 haproxy 监听端口 6444
- imageRepository: 由于国内无法访问 google 镜像仓库 k8s.gcr.io,这里指定为阿里云镜像仓库 registry.aliyuncs.com/google_containers
- podSubnet: 指定的 IP 地址段与后续部署的网络插件相匹配,这里需要部署 flannel 插件,所以配置为 10.244.0.0/16
- mode: ipvs: 最后追加的配置为开启 ipvs 模式。
在集群搭建完成后可以使用如下命令查看生效的配置文件:
kubectl -n kube-system get cm kubeadm-config -oyaml2.7 初始化 Master01 节点
这里追加 tee 命令将初始化日志输出到 kubeadm-init.log 中以备用(可选)。
kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log
该命令指定了初始化时需要使用的配置文件,其中添加–experimental-upload-certs 参数可以在后续执行加入节点时自动分发证书文件。
初始化示例
[root@k8s-master01 ~]# kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log
[init] Using Kubernetes version: v1.14.1
[preflight] Running pre-flight checks
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using ''kubeadm config images pull''
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.92.10 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.92.10 127.0.0.1 ::1]
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.92.10 192.168.92.30]
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 19.020444 seconds
[upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.14" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Storing the certificates in ConfigMap "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
11def25d624a2150b57715e21b0c393695bc6a70d932e472f75d24f747eb657e
[mark-control-plane] Marking the node k8s-master01 as control-plane by adding the label "node-role.kubernetes.io/master=''''"
[mark-control-plane] Marking the node k8s-master01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: abcdef.0123456789abcdef
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:7b232b343577bd5fac312996b9fffb3c88f8f8bb39f46bf865ac9f9f52982b82 \
--experimental-control-plane --certificate-key 11def25d624a2150b57715e21b0c393695bc6a70d932e472f75d24f747eb657e
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --experimental-upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:7b232b343577bd5fac312996b9fffb3c88f8f8bb39f46bf865ac9f9f52982b82
kubeadm init 主要执行了以下操作:
- [init]:指定版本进行初始化操作
- [preflight] :初始化前的检查和下载所需要的 Docker 镜像文件
- [kubelet-start]:生成 kubelet 的配置文件”/var/lib/kubelet/config.yaml”,没有这个文件 kubelet 无法启动,所以初始化之前的 kubelet 实际上启动失败。
- [certificates]:生成 Kubernetes 使用的证书,存放在 /etc/kubernetes/pki 目录中。
- [kubeconfig] :生成 KubeConfig 文件,存放在 /etc/kubernetes 目录中,组件之间通信需要使用对应文件。
- [control-plane]:使用 /etc/kubernetes/manifest 目录下的 YAML 文件,安装 Master 组件。
- [etcd]:使用 /etc/kubernetes/manifest/etcd.yaml 安装 Etcd 服务。
- [wait-control-plane]:等待 control-plan 部署的 Master 组件启动。
- [apiclient]:检查 Master 组件服务状态。
- [uploadconfig]:更新配置
- [kubelet]:使用 configMap 配置 kubelet。
- [patchnode]:更新 CNI 信息到 Node 上,通过注释的方式记录。
- [mark-control-plane]:为当前节点打标签,打了角色 Master,和不可调度标签,这样默认就不会使用 Master 节点来运行 Pod。
- [bootstrap-token]:生成 token 记录下来,后边使用 kubeadm join 往集群中添加节点时会用到
- [addons]:安装附加组件 CoreDNS 和 kube-proxy
说明:无论是初始化失败或者集群已经完全搭建成功,你都可以直接执行 kubeadm reset 命令清理集群或节点,然后重新执行 kubeadm init 或 kubeadm join 相关操作即可。
2.8 配置 kubectl 命令
无论在 master 节点或 node 节点,要能够执行 kubectl 命令必须进行以下配置:
root 用户执行以下命令
cat << EOF >> ~/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source ~/.bashrc普通用户执行以下命令(参考 init 时的输出结果)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config等集群配置完成后,可以在所有 master 节点和 node 节点进行以上配置,以支持 kubectl 命令。针对 node 节点复制任意 master 节点 /etc/kubernetes/admin.conf 到本地。
查看当前状态
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady master 81s v1.14.1
[root@k8s-master01 ~]# kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
coredns-8686dcc4fd-cbrc5 0/1 Pending 0 64s
coredns-8686dcc4fd-wqpwr 0/1 Pending 0 64s
etcd-k8s-master01 1/1 Running 0 16s
kube-apiserver-k8s-master01 1/1 Running 0 13s
kube-controller-manager-k8s-master01 1/1 Running 0 25s
kube-proxy-4vwbb 1/1 Running 0 65s
kube-scheduler-k8s-master01 1/1 Running 0 4s
[root@k8s-master01 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}由于未安装网络插件,coredns 处于 pending 状态,node 处于 notready 状态。
2.9 安装网络插件
kubernetes 支持多种网络方案,这里简单介绍常用的 flannel 和 calico 安装方法,选择其中一种方案进行部署即可。
以下操作在 master01 节点执行即可。
2.9.1 安装 flannel 网络插件:
由于 kube-flannel.yml 文件指定的镜像从 coreos 镜像仓库拉取,可能拉取失败,可以从 dockerhub 搜索相关镜像进行替换,另外可以看到 yml 文件中定义的网段地址段为 10.244.0.0/16。
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
cat kube-flannel.yml | grep image
cat kube-flannel.yml | grep 10.244
sed -i ''s#quay.io/coreos/flannel:v0.11.0-amd64#willdockerhub/flannel:v0.11.0-amd64#g'' kube-flannel.yml
kubectl apply -f kube-flannel.yml再次查看 node 和 Pod 状态,全部为 Running
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready master 9m8s v1.14.1
[root@k8s-master01 ~]# kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
coredns-8686dcc4fd-cbrc5 1/1 Running 0 8m53s
coredns-8686dcc4fd-wqpwr 1/1 Running 0 8m53s
etcd-k8s-master01 1/1 Running 0 8m5s
kube-apiserver-k8s-master01 1/1 Running 0 8m2s
kube-controller-manager-k8s-master01 1/1 Running 0 8m14s
kube-flannel-ds-amd64-vtppf 1/1 Running 0 115s
kube-proxy-4vwbb 1/1 Running 0 8m54s
kube-scheduler-k8s-master01 1/1 Running 0 7m53s2.9.2 安装 calico 网络插件(可选):
安装参考:https://docs.projectcalico.org/v3.6/getting-started/kubernetes/
kubectl apply -f \
https://docs.projectcalico.org/v3.6/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml注意该 yaml 文件中默认 CIDR 为 192.168.0.0/16,需要与初始化时 kube-config.yaml 中的配置一致,如果不同请下载该 yaml 修改后运行。
2.10 加入 master 节点
从初始化输出或 kubeadm-init.log 中获取命令
kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:c0a1021e5d63f509a0153724270985cdc22e46dc76e8e7b84d1fbb5e83566ea8 \
--experimental-control-plane --certificate-key 52f64a834454c3043fe7a0940f928611b6970205459fa19cb1193b33a288e7cc依次将 k8s-master02 和 k8s-master03 加入到集群中,示例
[root@k8s-master02 ~]# kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:7b232b343577bd5fac312996b9fffb3c88f8f8bb39f46bf865ac9f9f52982b82 \
> --experimental-control-plane --certificate-key 11def25d624a2150b57715e21b0c393695bc6a70d932e472f75d24f747eb657e
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with ''kubectl -n kube-system get cm kubeadm-config -oyaml''
[preflight] Running pre-flight checks before initializing the new control plane instance
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using ''kubeadm config images pull''
[download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master02 localhost] and IPs [192.168.92.11 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master02 localhost] and IPs [192.168.92.11 127.0.0.1 ::1]
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master02 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.92.11 192.168.92.30]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.14" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Wrote Static Pod manifest for a local etcd member to "/etc/kubernetes/manifests/etcd.yaml"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
[upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[mark-control-plane] Marking the node k8s-master02 as control-plane by adding the label "node-role.kubernetes.io/master=''''"
[mark-control-plane] Marking the node k8s-master02 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run ''kubectl get nodes'' to see this node join the cluster.
2.11 加入 node 节点
从 kubeadm-init.log 中获取命令
kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:c0a1021e5d63f509a0153724270985cdc22e46dc76e8e7b84d1fbb5e83566ea8示例
[root@k8s-node01 ~]# kubeadm join 192.168.92.30:6444 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:7b232b343577bd5fac312996b9fffb3c88f8f8bb39f46bf865ac9f9f52982b82
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with ''kubectl -n kube-system get cm kubeadm-config -oyaml''
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.14" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run ''kubectl get nodes'' on the control-plane to see this node join the cluster.2.12 验证集群状态
查看 nodes 运行情况
[root@k8s-master01 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master01 Ready master 10h v1.14.1 192.168.92.10 <none> CentOS Linux 7 (Core) 3.10.0-957.10.1.el7.x86_64 docker://18.9.5
k8s-master02 Ready master 10h v1.14.1 192.168.92.11 <none> CentOS Linux 7 (Core) 3.10.0-957.10.1.el7.x86_64 docker://18.9.5
k8s-master03 Ready master 10h v1.14.1 192.168.92.12 <none> CentOS Linux 7 (Core) 3.10.0-957.10.1.el7.x86_64 docker://18.9.5
k8s-node01 Ready <none> 10h v1.14.1 192.168.92.13 <none> CentOS Linux 7 (Core) 3.10.0-957.10.1.el7.x86_64 docker://18.9.5查看 pod 运行情况
[root@k8s-master03 ~]# kubectl -n kube-system get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-8686dcc4fd-6ttgv 1/1 Running 1 22m 10.244.2.3 k8s-master03 <none> <none>
coredns-8686dcc4fd-dzvsx 1/1 Running 0 22m 10.244.3.3 k8s-node01 <none> <none>
etcd-k8s-master01 1/1 Running 1 6m23s 192.168.92.10 k8s-master01 <none> <none>
etcd-k8s-master02 1/1 Running 0 37m 192.168.92.11 k8s-master02 <none> <none>
etcd-k8s-master03 1/1 Running 1 36m 192.168.92.12 k8s-master03 <none> <none>
kube-apiserver-k8s-master01 1/1 Running 1 48m 192.168.92.10 k8s-master01 <none> <none>
kube-apiserver-k8s-master02 1/1 Running 0 37m 192.168.92.11 k8s-master02 <none> <none>
kube-apiserver-k8s-master03 1/1 Running 2 36m 192.168.92.12 k8s-master03 <none> <none>
kube-controller-manager-k8s-master01 1/1 Running 2 48m 192.168.92.10 k8s-master01 <none> <none>
kube-controller-manager-k8s-master02 1/1 Running 1 37m 192.168.92.11 k8s-master02 <none> <none>
kube-controller-manager-k8s-master03 1/1 Running 1 35m 192.168.92.12 k8s-master03 <none> <none>
kube-flannel-ds-amd64-d86ct 1/1 Running 0 37m 192.168.92.11 k8s-master02 <none> <none>
kube-flannel-ds-amd64-l8clz 1/1 Running 0 36m 192.168.92.13 k8s-node01 <none> <none>
kube-flannel-ds-amd64-vtppf 1/1 Running 1 42m 192.168.92.10 k8s-master01 <none> <none>
kube-flannel-ds-amd64-zg4z5 1/1 Running 1 37m 192.168.92.12 k8s-master03 <none> <none>
kube-proxy-4vwbb 1/1 Running 1 49m 192.168.92.10 k8s-master01 <none> <none>
kube-proxy-gnk2v 1/1 Running 0 37m 192.168.92.11 k8s-master02 <none> <none>
kube-proxy-kqm87 1/1 Running 0 36m 192.168.92.13 k8s-node01 <none> <none>
kube-proxy-n5mdh 1/1 Running 2 37m 192.168.92.12 k8s-master03 <none> <none>
kube-scheduler-k8s-master01 1/1 Running 2 48m 192.168.92.10 k8s-master01 <none> <none>
kube-scheduler-k8s-master02 1/1 Running 1 37m 192.168.92.11 k8s-master02 <none> <none>
kube-scheduler-k8s-master03 1/1 Running 2 36m 192.168.92.12 k8s-master03 <none> <none>
查看 service
[root@k8s-master03 ~]# kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 51m2.13 验证 IPVS
查看 kube-proxy 日志,第一行输出 Using ipvs Proxier.
[root@k8s-master01 ~]# kubectl -n kube-system logs -f kube-proxy-4vwbb
I0426 16:05:03.156092 1 server_others.go:177] Using ipvs Proxier.
W0426 16:05:03.156501 1 proxier.go:381] IPVS scheduler not specified, use rr by default
I0426 16:05:03.156788 1 server.go:555] Version: v1.14.1
I0426 16:05:03.166269 1 conntrack.go:52] Setting nf_conntrack_max to 131072
I0426 16:05:03.169022 1 config.go:202] Starting service config controller
I0426 16:05:03.169103 1 controller_utils.go:1027] Waiting for caches to sync for service config controller
I0426 16:05:03.169182 1 config.go:102] Starting endpoints config controller
I0426 16:05:03.169200 1 controller_utils.go:1027] Waiting for caches to sync for endpoints config controller
I0426 16:05:03.269760 1 controller_utils.go:1034] Caches are synced for endpoints config controller
I0426 16:05:03.270123 1 controller_utils.go:1034] Caches are synced for service config controller
I0426 16:05:03.352400 1 graceful_termination.go:160] Trying to delete rs: 10.96.0.1:443/TCP/192.168.92.11:6443
I0426 16:05:03.352478 1 graceful_termination.go:174] Deleting rs: 10.96.0.1:443/TCP/192.168.92.11:6443
......查看代理规则
[root@k8s-master01 ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 192.168.92.10:6443 Masq 1 3 0
-> 192.168.92.11:6443 Masq 1 0 0
-> 192.168.92.12:6443 Masq 1 0 0
TCP 10.96.0.10:53 rr
-> 10.244.0.5:53 Masq 1 0 0
-> 10.244.0.6:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.0.5:9153 Masq 1 0 0
-> 10.244.0.6:9153 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.0.5:53 Masq 1 0 0
-> 10.244.0.6:53 Masq 1 0 0
2.14 etcd 集群
执行以下命令查看 etcd 集群状态
kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl \
--endpoints=https://192.168.92.10:2379 \
--ca-file=/etc/kubernetes/pki/etcd/ca.crt \
--cert-file=/etc/kubernetes/pki/etcd/server.crt \
--key-file=/etc/kubernetes/pki/etcd/server.key cluster-health示例
[root@k8s-master01 ~]# kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl \
> --endpoints=https://192.168.92.10:2379 \
> --ca-file=/etc/kubernetes/pki/etcd/ca.crt \
> --cert-file=/etc/kubernetes/pki/etcd/server.crt \
> --key-file=/etc/kubernetes/pki/etcd/server.key cluster-health
member a94c223ced298a9 is healthy: got healthy result from https://192.168.92.12:2379
member 1db71d0384327b96 is healthy: got healthy result from https://192.168.92.11:2379
member e86955402ac20700 is healthy: got healthy result from https://192.168.92.10:2379
cluster is healthy
2.15 验证 HA
在 master01 上执行关机操作,建议提前在其他节点配置 kubectl 命令支持。
[root@k8s-master01 ~]# shutdown -h now在任意运行节点验证集群状态,master01 节点 NotReady,集群可正常访问:
[root@k8s-master02 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady master 19m v1.14.1
k8s-master02 Ready master 11m v1.14.1
k8s-master03 Ready master 10m v1.14.1
k8s-node01 Ready <none> 9m21s v1.14.1查看网卡,vip 自动漂移到 master03 节点
[root@k8s-master03 ~]# ip a |grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.92.12/24 brd 192.168.92.255 scope global noprefixroute ens33
inet 192.168.92.30/24 scope global secondary ens33
————————————————
版权声明:本文为 CSDN 博主「willblog」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://www.cnblogs.com/sandshell/p/11570458.html#auto_id_0
https://blog.csdn.net/networken/article/details/89599004
")
kubeadm安装kubernetes(v18.8.8)
1. 前言
kubernetes版本更新迭代非常快,上一篇写kubernetes搭建时,版本还是v1.15.0,现在已经更新到v1.18。看kubernetes在github的官方仓库,8月14日小版本已经到了v1.18.8。本篇文章基于kubeadm搭建kubernetes v1.18.8版。
本篇文章与上篇文章几点不同之处:
- 操作系统采用CentOS。
- master采用单节点,如果要搭建多master高可用集群可以参考上篇文章。
- 解决无法访问kubernetes官方容器镜像仓库问题,上篇文章直接从kubernetes官方拉取镜像。
- docker加速,解决从dockerhub拉镜像慢问题。
- kube-proxy开启ivps,使用ipvs替代iptables转发流量。
- 给出了一些常见的错误及排错思路。
话不多说,那就直奔主题,走起~~~
2. 环境准备
| 机器名称 | 机器配置 | 机器系统 | IP地址 | 角色 |
|---|---|---|---|---|
| master1 | 2C4G | centos7.6 | 10.13.1.11 | 主节点 |
| node1 | 2C4G | centos7.6 | 10.13.1.15 | 工作节点1 |
| node2 | 2C4G | centos7.6 | 10.13.1.16 | 工作节点2 |
说明:
硬件配置要求:2C2G +;
操作系统要求:CentOS7 +
防火墙说明:如果使用的是云厂商的虚拟机,主节点安全组需放行tcp端口6443、2379-2380、10250-12025,工作节点安全组需放行tcp端口:10250、30000-32767
3. 实操过程
3.1 关闭防火墙和selinux
[root@master1 ~]# systemctl stop firewalld
[root@master1 ~]# setenforce 0
[root@master1 ~]# sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config3.2 关闭交换分区
[root@master1 ~]# swapoff -a
永久关闭,修改/etc/fstab,注释掉swap一行3.3 修改hosts文件
[root@master1 ~]# cat >> /etc/hosts << EOF
10.13.1.11 master1
10.13.1.15 node1
10.13.1.16 node23.4 时间同步
[root@master1 ~]# yum install chrony -y
[root@master1 ~]# systemctl start chronyd
[root@master1 ~]# systemctl enable chronyd
[root@master1 ~]# chronyc sources3.5 修改内核参数
让iptables能查看桥接流量
[root@master1 ~]# cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
[root@master1 ~]# sysctl --system3.6 加载ipvs模块
[root@master1 ~]# modprobe -- ip_vs
[root@master1 ~]# modprobe -- ip_vs_rr
[root@master1 ~]# modprobe -- ip_vs_wrr
[root@master1 ~]# modprobe -- ip_vs_sh
[root@master1 ~]# modprobe -- nf_conntrack_ipv4
[root@master1 ~]# lsmod | grep ip_vs
[root@master1 ~]# lsmod | grep nf_conntrack_ipv4
[root@master1 ~]# yum install -y ipvsadm3.7 安装并配置docker
3.7.1 修改docker的yum源为阿里源
[root@master1 ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
或者
[root@master1 ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo3.7.2 安装docker
[root@master1 ~]# yum install -y docker-ce
[root@master1 ~]# docker --version
[root@master1 ~]# systemctl enable docker
[root@master1 ~]# systemctl start docker3.7.3 配置docker加速并修改驱动
网上有很多大佬无私地提供了一些dockerhub加速地址,可以选择几个使用。
[root@master1 ~]# cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://1nj0zren.mirror.aliyuncs.com",
"https://kfwkfulq.mirror.aliyuncs.com",
"https://2lqq34jg.mirror.aliyuncs.com",
"https://pee6w651.mirror.aliyuncs.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"http://f1361db2.m.daocloud.io",
"https://registry.docker-cn.com"
]
}
[root@master1 ~]# systemctl restart docker
[root@master1 ~]# docker info | grep "Cgroup Driver"
Cgroup Driver: systemdkubernetes官方建议docker驱动采用systemd,当然可以不修改,只是kubeadm init时会有warning([WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/)
可以忽略,生产环境建议修改,因为更稳定。
3.8 安装kubernents组件
3.8.1 配置kubernentes的yum源为阿里源
因为国内无法访问kubernents的官方yum源,所以需要修改
[root@master1 ~]# cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg3.8.2 安装组件
[root@master1 ~]# yum -y install kubelet kubeadm kubectl
[root@master1 ~]# kubelet --version
Kubernetes v1.18.8
[root@master1 ~]# systemctl start kubelet此时kubelet处于不断重启状态,因为集群还没有初始化,kubelet等待kubeadm初始化完成后运行状态正常。
3.9 初始化集群
3.9.1 查看初始化需要的镜像
[root@master1 ~]# kubeadm config images list
W0822 15:58:54.182176 25602 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
k8s.gcr.io/kube-apiserver:v1.18.8
k8s.gcr.io/kube-controller-manager:v1.18.8
k8s.gcr.io/kube-scheduler:v1.18.8
k8s.gcr.io/kube-proxy:v1.18.8
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.73.9.2 kubeadm init介绍
初始化集群需使用kubeadm init命令,可以指定具体参数初始化,也可以指定配置文件初始化。
可选参数:
--apiserver-advertise-address apiserver的监听地址,有多块网卡时需要指定
--apiserver-bind-port apiserver的监听端口,默认是6443
--cert-dir 通讯的ssl证书文件,默认/etc/kubernetes/pki
--control-plane-endpoint 控制台平面的共享终端,可以是负载均衡的ip地址或者dns域名,高可用集群时需要添加
--image-repository 拉取镜像的镜像仓库,默认是k8s.gcr.io
--kubernetes-version 指定kubernetes版本
--pod-network-cidr pod资源的网段,需与pod网络插件的值设置一致
--service-cidr service资源的网段
--service-dns-domain service全域名的后缀,默认是cluster.local
3.9.3 kubeadm指定具体参数初始化
因为以上镜像都需要从kubernetes官方镜像仓库拉取,国内无法访问,所以需要设置国内的阿里镜像仓库。
但是目前至发稿位置,阿里的kube-apiserver、kube-controller、proxy镜像只更新到v1.18.6所以无法拉取到v1.18.8版镜像。
如果你需要安装的kubernetes版本是v1.18.6及以下那么请继续往下走,如果是v1.18.7及以上请跳过这一步进入下一步。
3.9.3.1 初始化
[root@master1 ~]# kubeadm init --kubernetes-version=v1.18.6 --apiserver-advertise-address 0.0.0.0 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr 192.168.0.0/16 --service-cidr 10.10.0.0/16
--kubernetes-version 请指定为你需要安装的v1.18.6及以下的版本。初始化成功后会出现如下信息

3.9.3.2 开启ipvs
修改kube-proxy的configmap
[root@master1 ~]# kubectl edit cm kube-proxy -n=kube-system
修改mode: ipvs3.9.4 kubeadm指定配置文件初始化
3.9.4.1 下载kubernetes所需的全部镜像
dockerhub上面已经有大佬已经上传了最新的1.18.8镜像,这里我们直接下载下来即可。
编写下载脚本
[root@master1 ~]# vim images.txt
kube-apiserver:v1.18.8 # node节点不需要
kube-controller-manager:v1.18.8 # node节点不需要
kube-scheduler:v1.18.8 # node节点不需要
kube-proxy:v1.18.8
pause:3.2
etcd:3.4.3-0 # node节点不需要
coredns:1.6.7 # node节点不需要
[root@master1 ~]# vim images.sh
for image in `cat images.txt`
do
docker pull gotok8s/$image
docker tag gotok8s/$image k8s.gcr.io/$image
docker rmi gotok8s/$image
done
[root@master1 ~]# sh images.sh3.9.4.2 配置初始化文件
[root@master1 ~]# kubeadm config print init-defaults > kubeadm.yaml
[root@master1 ~]# vim kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 0.0.0.0 # 修改为本机IP地址,多块网卡可以指定具体ip
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: coredns
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesversion: v1.18.8 # 修改为最新版本
networking:
dnsDomain: cluster.local
servicesubnet: 10.10.0.0/16 # service网段
podsubnet: 192.168.0.0/16 # pod网段,需与网络插件网段一致
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs # 开启ipvs
[root@master1 ~]# kubeadm init --config=kubeadm.yaml可以看到久违的成功

3.9.4.3 配置kubectl与api-server交互
[root@master1 ~]# mkdir -p $HOME/.kube
[root@master1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
至此可以使用kubectl查看集群节点状态了
[root@master1 ~]# kubectl get nodes
3.9.5 安装网络组件
[root@master1 ~]# wget https://docs.projectcalico.org/v3.14/manifests/calico.yaml
[root@master1 ~]# kubectl apply -f calico.yaml此时再来看节点状态,已经正常

[root@master1 ~]# kubectl get cs
3.10 worker节点加入集群
[root@node1 ~]# kubeadm join 10.13.1.11:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:c214cf4c42766dd3d4ab2842c11efbefd54aa445993708ccdbdb8f111658445e
同样的第二个worker节点加入集群
此次查看集群状态
[root@master1 ~]# kubectl get nodes
[root@master1 ~]# kubectl get pods -A
[root@master1 ~]# kubeadm token create --print-join-command可以看到节点和个组件的pod状态均正常,至此集群搭建完毕!
4. trouble shooting
出现了问题不可怕,因为如果不非常仔细,按照文档敲下来很有可能会出错。可怕的是,出错了连去网上多搜索一下都懒得搜,甚至开始抱怨。kubernets已经很成熟了,网上的资料非常多,出现的问题很多人也遇到过,在网上基本都有大佬给出回答。
4.1 初始化集群长期卡住,最终报错
拉镜像失败
[ERROR ImagePull]: Failed to pull image k8s.gcr.io/kube-apiserver:v1.18.8: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
, error: exit status 1
执行拉镜像脚本
[root@master1 ~]# sh images.sh4.2 网桥报错
W0822 17:05:25.135752 3367 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.18.8
[preflight] Running pre-flight checks
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
error execution phase preflight: [preflight] Some Fatal errors occurred:
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
[preflight] If you kNow what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
检查前面的内核参数是否修改
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
4.3 kubelet-check报错健康问题检查
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' Failed with error: Get http://localhost:10248/healthz: dial tcp: lookup localhost on 198.18.254.40:53: no such host.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' Failed with error: Get http://localhost:10248/healthz: dial tcp: lookup localhost on 198.18.254.40:53: no such host.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' Failed with error: Get http://localhost:10248/healthz: dial tcp: lookup localhost on 198.18.254.40:53: no such host.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' Failed with error: Get http://localhost:10248/healthz: dial tcp: lookup localhost on 198.18.254.40:53: no such host.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' Failed with error: Get http://localhost:10248/healthz: dial tcp: lookup localhost on 198.18.254.40:53: no such host.

检查hosts文件,本机地址解析是否被删除了
127.0.0.1 localhost
4.4 查看组件处于不健康状态
[root@master1 ~]# kubectl get cs

发现controller-manager和scheduler状态是不健康
如果节点都处于Ready后,实际上该状态是不影响的。
因为kubeadm v1.18.6及以后的版本,是默认不开启controller-manager的10252和scheduler的10251端口的,一般10251和10252是监听在http上面,不需要证书认证,属于不安全的端口。
查看机器监听端口,发现默认这两个端口没有监听

可以将/etc/kubernetes/manifests/kube-controller-manager.yaml、/etc/kubernetes/manifests/kube-scheduler.yaml中--port=0注释掉,再次kubect get cs组件状态,这时都是ok了。
默认不监听http端口,但是客户端查看组件状态有默认是检查http端口,不知道这算不算是kuberadm的一个小bug呢,哈哈~~~
4.5 worker节点加入集群后长期处于NotReady
查看node

查看pod状态,kube-proxy一直处于创建状态,网络组建caclio一直处于初始化

kubect describe pod查看报错:FailedCreatePodSandBox

说明节点没有pull基础镜像pause,到相应节点上面去拉取pause镜像即可。
4.6 node节点运行一段时间后出现错误
查看pod状态

查看报错的pod,发现cgroup报错

到node节点查看kubelet也在报错

原因是docker的驱动改为了systemd,但是kubelet的驱动没有改
kubelet的驱动是在kubeadm join初始化的时候与docker保持一致的,docker修改了,kubelet也需要修改
[root@node2 ~]# sed -i 's/--cgroup-driver=cgroupfs/--cgroup-driver=systemd/g' /var/lib/kubelet/kubeadm-flags.env
[root@node2 ~]# systemctl restart kubelet
同样如果node节点处于NotReady,kubelet一直在重启,也需要检查kubelet的cgroup驱动是否和docker的一致。


4.7 worker节点加入节点后,网络组件一直不ready,一直重启
该pod一直处于Running和CrashLoopBackOff交替状态

查看pod日志,发现有大量的健康检查错误

到node节点上查看hosts文件,本机地址解析是否被删除了
127.0.0.1 localhost
参考文档
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
全剧终
我们今天的关于kubernetes.v1.11.0的分享就到这里,谢谢您的阅读,如果想了解更多关于centos7下kubernetes(11。kubernetes-运行一次性任务)、kubeadm 安装 kubernetes-v1.13.1、kubeadm 部署 kubernetes v1.14.1 高可用集群、kubeadm安装kubernetes(v18.8.8)的相关信息,可以在本站进行搜索。
本文标签:




