这篇文章主要围绕DOCKER学习笔记9Kubernetes(K8s)弹性伸缩容器下和rancher弹性伸缩展开,旨在为您提供一份详细的参考资料。我们将全面介绍DOCKER学习笔记9Kubernetes
这篇文章主要围绕DOCKER 学习笔记 9 Kubernetes (K8s) 弹性伸缩容器 下和rancher 弹性伸缩展开,旨在为您提供一份详细的参考资料。我们将全面介绍DOCKER 学习笔记 9 Kubernetes (K8s) 弹性伸缩容器 下的优缺点,解答rancher 弹性伸缩的相关问题,同时也会为您带来docker kubernetes Swarm 容器编排 k8s CICD 部署 麦兜、Docker Kubernetes 容器扩容与缩容、Docker Kubernetes(K8s)简介、DOCKER 学习笔记9 Kubernetes (K8s) 生产级容器编排 上的实用方法。
本文目录一览:- DOCKER 学习笔记 9 Kubernetes (K8s) 弹性伸缩容器 下(rancher 弹性伸缩)
- docker kubernetes Swarm 容器编排 k8s CICD 部署 麦兜
- Docker Kubernetes 容器扩容与缩容
- Docker Kubernetes(K8s)简介
- DOCKER 学习笔记9 Kubernetes (K8s) 生产级容器编排 上
 弹性伸缩容器 下(rancher 弹性伸缩)")
DOCKER 学习笔记 9 Kubernetes (K8s) 弹性伸缩容器 下(rancher 弹性伸缩)
前言
从上一篇看来,我们已经对于 Kubernetes , 通过 minikube 建立集群,而后使用 kubectl 进行交互,对 Deployment 部署以及服务的暴露等。这节,将学习弹性的将服务部署到多个节点上。
检查
检查部署情况 kubectl get deployments
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
mynode 1/1 1 1 10m
- READY 显示当前 / 所需副本的比率
- UP-TO-DATE 最新显示已更新以达到所需状态的副本数
- 显示应用程序有多少副本可供用户使用。
- AGE 启动时间
kubectl get nodes 检查当前可用节点数
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready master 39m v1.17.2
增加副本数量
kubectl scale deployment <name> --replicas=?
将部署的副本数量调节至指定大小
mrc@mrc-linux:~$ kubectl scale deployment mynode --replicas=4
deployment.apps/mynode scaled
kubectl get pods 可以查看当前 POD 的数量
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mynode-5479db549c-6n6wt 1/1 Running 0 31m
mynode-5479db549c-hvpnr 1/1 Running 0 4m39s
mynode-5479db549c-mzmht 1/1 Running 0 4m39s
mynode-5479db549c-zwg6k 1/1 Running 0 4m39s
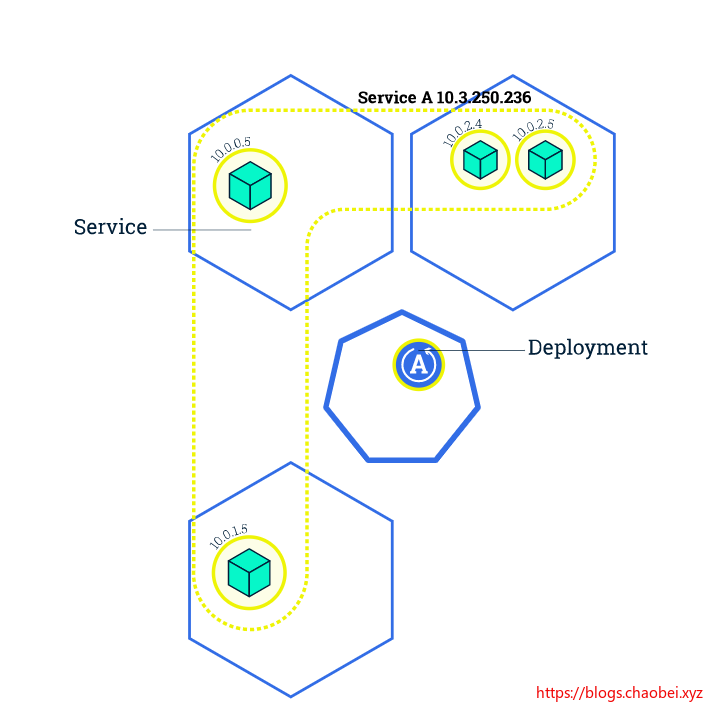
查看部署创建的复制集合
kubectl get rs
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
mynode-5479db549c 4 4 4 10h
我们扩容到了四个,所以这里展示的有四个
查看服务状态
$ kubectl get service mynginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
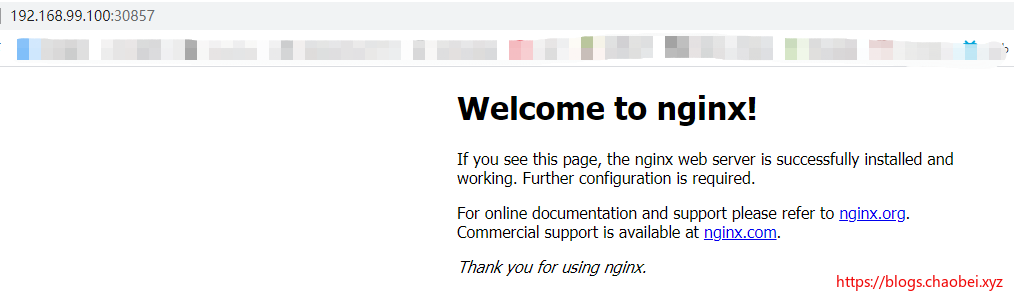
mynginx NodePort 10.111.8.25 <none> 80:30857/TCP 5m33s
这里原有的服务就是将 nginx 应用 80 端口暴露到虚拟机 30857 端口下
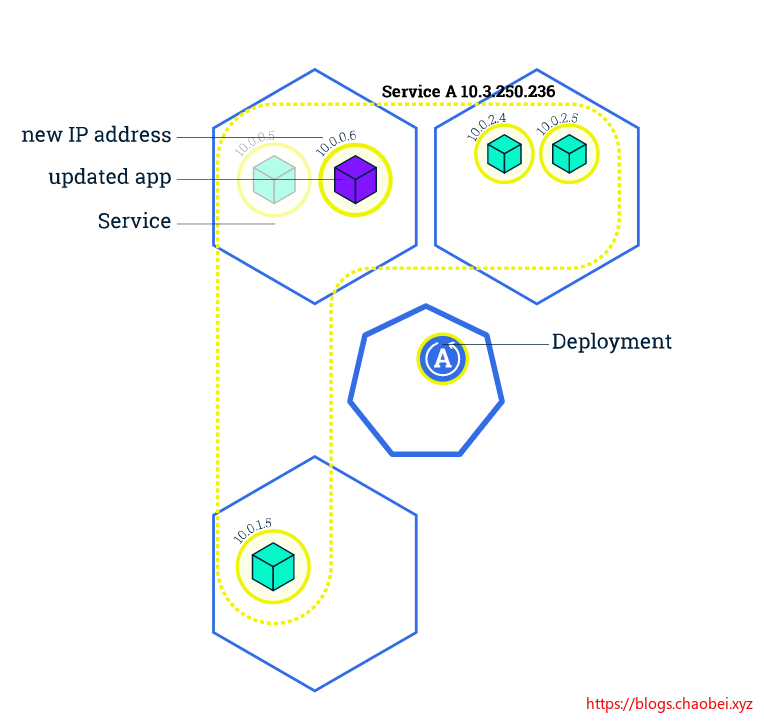
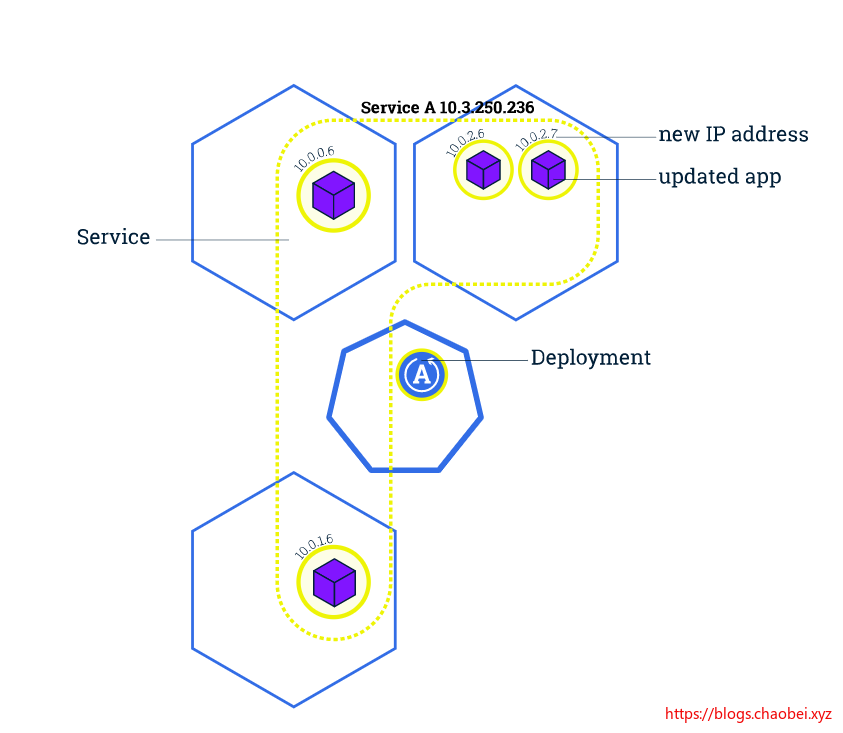
更新应用
在 Kubernetes 中,这些是通过滚动更新(Rolling Updates)完成的。 滚动更新 允许通过使用新的实例逐步更新 Pod 实例,零停机进行 Deployment 更新。新的 Pod 将在具有可用资源的节点上进行调度。
更新镜像
vi Dockerfile
FROM nginx
RUN echo ''<h1>Update Kubernetes</h1>'' > /usr/share/nginx/html/index.html
重新打包
docker build -t mynginx:v1 .
更换部署镜像
$ kubectl.exe set image deployment <deployment> oldimage=newimage
- deployment 表示需要修改的应用实例
- oldimage 原本的镜像名称
- newimage 新的镜像名称
$ kubectl.exe set image deployment/mynginx mynginx=mynginx:v1 deployment.apps/mynginx image updated
查看 POD
kubectl.exe get pods
我们会发现多出来两个 POD , 当然这两个 POD 是新的,将要替换掉原来老旧的 POD
$ kubectl.exe get pods NAME READY STATUS RESTARTS AGE
mynginx-54fdcfb5dd-h7wwl 1/1 Running 0 11s
mynginx-54fdcfb5dd-jk4n4 1/1 Running 0 9s
mynginx-54fdcfb5dd-m9x45 1/1 Running 0 9s
mynginx-54fdcfb5dd-wbrpz 1/1 Running 0 11s
mynginx-6579cc57f7-pkvgv 0/1 Terminating 0 39m
mynginx-6579cc57f7-zlwzj 0/1 Terminating 0 64m
检查更新结果
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45h
mynginx NodePort 10.111.8.25 <none> 80:30857/TCP 125m
获取到暴露出的端口号:30857
回滚
其实回滚和更新是一个操作,是需要将镜像版本进行修改即可完成回滚
小结
到这里,基本上 docker 学习就先到一段落吧,从最开始的 docker 入门开始,到接触到编排 compose 以及建立虚拟机 docker-machine 再到使用官网的 docker swarm 进行集群的创建,任务的部署。走过很大段的一条路。最后我们尝试着接触一些企业里面流行的生产化容器编排 k8S
革命尚未成功,同志任需努力!

docker kubernetes Swarm 容器编排 k8s CICD 部署 麦兜
1docker 版本
docker 17.09
https://docs.docker.com/
appledeAir:~ apple$ docker version
Client: Docker Engine - Community
Version: 18.09.0
API version: 1.39
Go version: go1.10.4
Git commit: 4d60db4
Built: Wed Nov 7 00:47:43 2018
OS/Arch: darwin/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 18.09.0
API version: 1.39 (minimum version 1.12)
Go version: go1.10.4
Git commit: 4d60db4
Built: Wed Nov 7 00:55:00 2018
OS/Arch: linux/amd64
Experimental: false
vagrant
创建 linux 虚拟机
创建一个目录
mkdir centos7
vagrant init centos/7 #会创建一个 vagrant file
vagrant up # 启动
vagrant ssh # 进入虚拟机
vagrant status
vagrant halt # 停机
vagrant destroy 删除机器
docker machine 自动在虚拟机安装 docker 的工具
docker-machine create demo virtualbox 里会自动运行一台虚拟机
docker-machine ls 显示有哪些虚拟机在运行
docker-machine ssh demo 进入机器
docker-machine create demo1 创建第二台有 docker 的虚拟机
docker-machine stop demo1
docker playground https://labs.play-with-docker.com/
运行 docker
docker run -dit ubuntu /bin/bash
执行不退出
docker exec -it 33 /bin/bash
把普通用户添加到 docker 组,不用 sudo
sudo gpasswd -a alex docker
/etc/init.d/docker restart
重新登录 shell exit
验证 docker version
创建自己的 image
from scratch
ADD app.py /
CMD ["/app.py"]
build 自己的 image
docker build -t alex/helloworld .
显示当前正在运行的容器
docker container ls
docker container ls -a
显示状态为退出的容器
docker container ls -f "status=exited" -q
删除容器
docker container rm 89123
docker rm 89123
或者一次性删除全部容器
docker rm $(docker container ls -aq)
删除退出状态的容器
docker rm $(docker container ls -f "status=exited" -q)
删除不用的 image
docker rmi 98766
把 container,commit 成为一个新的 image
docker commit 12312312 alexhe/changed_a_lot:v1.0
docker image ls
docker history 901923123 (image 的 id)
Dockerfile 案例:
cat Dockerfile
FROM centos
ENV name Docker
CMD echo "hello $name"
用 dockerfile 建立 image
docker build -t alexhe/firstblood:latest .
从 registry 拉取
docker pull ubuntu:18.04
Dockerfile 案例:
cat Dockerfile
FROM centos
RUN yum install -y vim
Dockerfile 案例:
FROM ubuntu
RUN apt-get update && apt-get install -y python
Dockerfile 语法梳理及最佳实践
From ubuntu:18.04
LABEL maintainer="alex@alexhe.net"
LABEL version="1.0"
LABEL description="This is comment"
RUN yum update && yum instlal -y vim \
python-dev # 每运行一次 run,增加一层 layer,需要合并起来
WORKDIR /root # 进入目录,如果没有目录会自动创建目录
WORKDIR demo #进入了 /root/demo
ADD hello /
ADD test.tar.gz/ # 添加到根目录并解压
WORKDIR /root
ADD hello test/ # /root/test/hello
WORKDIR /root
COPY hello test/ #
大部分情况,copy 优于 add,add 除了 copy 还有额外功能(解压),添加远程文件 / 目录请使用 curl 或者 wget
ENV MYSQL_VERSION 5.6 # 设置常亮
RUN apt-get install -y mysql-server="${MYSQL_VERSION}" && rm -rf /var/lib/apt/lists/* #引用常量
RUN vs CMD vs ENTRYPOINT
run: 执行命令并创建新的 image layer
cmd:设置容器启动后默认执行的命令和参数
entrypoint: 设置容器启动时运行的命令
shell 格式
RUN apt-get install -y vim
CMD echo "hello docker"
ENTRYPOINT echo "hello docker"
Exec 格式
RUN ["apt-get","install","-y","vim"]
CMD ["/bin/echo","hello docker"]
ENTRYPOINT ["/bin/echo","hello docker"]
例子:注意
FROM centos
ENV name Docker
ENTRYPOINT ["/bin/bash","-c","echo","hello $name"] #这样正解 如果 ["echo","hello $name"],这样运行了以后还是显示 hello $name,没有变量替换。用 exec 格式,执行的是 echo 这个命令,而不是 shell,所以没办法把变量替换掉。
和上面的区别
FROM centos
ENV name Docker
ENTRYPOINT echo "hello $name" # 正常 可以显示 hello Docker 会用 shell 执行命令,识别变量
CMD:
容器启动时默认执行的命令,如果 docker run 指定了其他命令,CMD 命令被忽略。如果定义了多个 CMD,只有最后一个会执行。
ENTRYPOINT:
让容器以应用程序或者服务的形式运行。不会被忽略,一定会执行。最佳实践:下一个 shell 脚本作为 entrypoint
COPY docker-entrypoint.sh /usr/local/bin/
ENTRYPOINT ["docker-entrypoint.sh"]
EXPOSE 27017
CMD ["mongod"]
镜像发布
docker login
docker push alexhe/hello-world:latest
docker rmi alexhe/hello-world # 删掉
docker pull alexhe/hello-world:latest # 再拉回来
本地 registry private repository
https://docs.docker.com/v17.09/registry/
1. 启动私有 registry
docker run -d -p 5000:5000 -v /opt/registry:/var/lib/registry --restart always --name registry registry:2
2. 其他机器测试 telnet x.x.x.x 5000
3. 往私有 registry push
3.1 先用 dockerfile build 和打 tag
docker build -t x.x.x.x:5000/hello-world .
3.2 设置允许不安全的私有库
vim /etc/docker/daemon.json
{
"insecure-registries" : ["x.x.x.x:5000"] }
vim /lib/systemd/service/docker.service
EnvirmentFile=/etc/docker/daemon.json
/etc/init.d/docker restart
3.3 开始 push
docker push x.x.x.x:5000/hello-world
3.4 验证
registry 有 api https://docs.docker.com/v17.09/registry/spec/api/#listing-repositories
GET /v2/_catalogdocker pull x.x.x.x:5000/helloworld
Dockerfile github 很多示例 https://github.com/docker-library/docs https://docs.docker.com/engine/reference/builder/#add
Dockerfile 案例:安装 flask 复制目录中的 app.py 到 /app/ 进入 app 目录 暴露 5000 端口 执行 app.py
cat Dockerfile
FROM python:2.7
LABEL maintainer="alex he<alex@alexhe.net>"
RUN pip install flask
COPY app.py /app/
WORKDIR /app
EXPOSE 5000
CMD ["python", "app.py"]
cat app.py
from flask import Flask
app = Flask(__name__)
@app.route(''/'')
def hello():
return "hello docker"
if __name__ == ''__main__'':
app.run(host="0.0.0.0", port=5000)
docker build -t alexhe/flask-hello-world . # 打包
如果打包时出错
docker run -it 报错时的第几步 id /bin/bash
进入以后看看哪里报错
最后 docker run -d alexhe/flask-hello-world # 让容器在后台运行
在运行中的容器,执行命令:
docker exec -it xxxxxx /bin/bash
显示 ip 地址:
docker exec -it xxxx ip a
docker inspect xxxxxxid
显示容器运行产生的输出:
docker logs xxxxx
dockerfile 案例:
linux 的 stress 工具
cat Dockerfile
FROM ubuntu
RUN apt-get update && apt-get install -y stress
ENTRYPOINT ["/usr/bin/stress"] #使用 entrypoint 加 cmd 配合使用,cmd 为空的,用 docker run 来接收请求参数
CMD []
使用:
docker build alexhe/ubuntu-stress .
#dokcer run -it alexhe/ubuntu-stress # 无任何参数运行,类似于打印
docker run -it alexhe/ubuntu-stress -vm 1 --verbose # 类似于运行 stress -vm 1 --verbose
容器资源限制,cpu,ram
docker run --memory=200M alexhe/ubuntu-stress -vm 1 --vm-bytes=500M --verbose # 直接报错,内存不够。因为给了容器 200m,压力测试占用 500m
docker run --cpu-shares=10 --name=test1 alexhe/ubuntu-stress -vm1 # 和下面一起启动,他的 cpu 占用率为 66%
docker run --cpu-shares=5 --name=test2 alexhe/ubuntu-stress -vm1 # 一起启动,他的 cpu 占用率 33%
容器网络
单机:bridge,host,none
多机:Overlay
linux 中的网络命名空间
docker run -dit --name test1 busybox /bin/sh -c "while true;do sleep 3600;done"
docker exec -it xxxxx /bin/sh
ip a 显示网络接口
exit
进入 host , 执行 ip a ,显示 host 的接口
container 和 host 的网络 namespace 是隔离开的
docker run -dit --name test2 busybox /bin/sh -c "while true;do sleep 3600;done"
docker exec xxxxx ip a # 看第二台机器的网络
同一台机器,container 之间的网络是相通的。
以下是 linux 中的网络命名空间端口互通的原理实现(docker 的和他类似):
host 中执行 ip netns list 查看本机的 network namespace
ip netns delete test1
ip netns add test1 #创建 network namespace
ip netns add test2 # 创建 network namespace
在 test1 的 network namespace 中执行 ip link
ip netns exec test1 ip link # 目前状态是 down 的
ip netns exec test1 ip link set dev lo up # 状态变成了 unknown,要两端都连通,他才会变成 up
创建一对 veth,一个放入 test1 的 namespace,另一个放入 test2 的 namespace。
创建一对 veth:
ip link add veth-test1 type veth peer name veth-test2
把 veth-test1 放入 test1 的 namespace:
ip link set veth-test1 netns test1
看看 test1 的 namespace 里的情况:
ip netns exec test1 ip link #test1 的 namespace 多了一个 veth,状态为 down
看看本地的 ip link:
ip link #少了一个,说明这一个已经加到了 test1 的 namespace
把 veth-test2 放入 test2 的 namespace:
ip link set veth-test2 netns test2
看看本地的 ip link:
ip link # 又少了一个,说明已经加入到了 test2 的 namespace
看看 test2 的 namespace
ip netns exec test2 ip link #test2 的 namespace 多了一个 veth,状态为 down
给两个 veth 端口添加 ip 地址:
ip netns exec test1 ip addr add 192.168.1.1/24 dev veth-test1
ip netns exec test2 ip addr add 192.168.1.2/24 dev veth-test2
查看 test1 和 test2 的 ip link
ip netns exec test1 ip link # 发现没有 ip 地址,并且端口状态是 down
ip netns exec test2 ip link # 发现没有 ip 地址,并且端口状态是 down
把两个端口 up 起来
ip netns exec test1 ip link set dev veth-test1 up
ip netns exec test2 ip link set dev veth-test2 up
查看 test1 和 test2 的 ip link
ip netns exec test1 ip link # 发现有 ip 地址,并且端口状态是 up
ip netns exec test2 ip link # 发现有 ip 地址,并且端口状态是 up
从 test1 的 namespace 里的 veth-test1 执行 ping test2 的 namespace 中的 veth-test2
ip netns exec test1 ping 192.168.1.2
ip netns exec test2 ping 192.168.1.1
docker 的 bridge docker0 网络:
两个容器 test1 和 test2 能互相 ping 通,说明两个 network namespace 是连接在一起的。
目前系统只有一个 test1 的容器,删除 test2 容器
显示 docker 网络:
docker network ls
NETWORK ID NAME DRIVER SCOPE
9d133c1c82ff bridge bridge local
e44acf9eff90 host host local
bc660dbbb8b6 none null local
显示 bridge 网络的详情:
docker network inspect xxxxxx (上面显示 bridge 网络的 id)
host 上的 veth 和容器里的 eth0 是一对儿 veth
ip link #veth6aa1698@if18
docker exec test1 ip link #18: eth0@if19
这一对儿 veth pair 连接到了 host 上的 docker0 上面。
yum install bridge-utils
brctl show #主机上的 veth6aa 连接在 docker0 上
新开一个 test2 的容器:
docker run -dit --name test2 busybox /bin/sh -c "while true;do sleep 3600;done"
看看 docker 的网络:
docker network inspect bridge
看到 container 多了一个,地址都有
在 host 运行 ip a,又多了一个 veth。
运行 brctl show,docker0 上有两个接口
docker 容器之间的互联 link
目前只有一个容器 test1
现在创建第二个容器 test2
docker run -d --name test2 --link test1 busybox /bin/sh -c "while true;do sleep 3600;done"
docker exec -it test2 /bin/sh
进入 test2 后,去 ping test1 的 ip 地址,通,ping test1 的名字 ,也通。
进入 test1 里,去 ping test2 的 ip 地址,通,ping test2 的名字,不通。
自己建一个 docker network bridge,并让容器连接他。
docker network create -d bridge my-bridge
创建一个容器,test3
docker run -d --name test3 --network my-bridege busybox /bin/sh -c "while true;do sleep 3600;done"
通过 brctl show 来查看。
把 test2 的网络换成 my-bridge
docker network connect my-bridge test2,当连接进来后,test2 就有了 2 个 ip 地址。
注意:如果用户自己创建自定义的 network,并让一些容器连接进来,这些容器,是能通过名字来互相 ping 连接的。而默认的 bridge 不行,就像上面测试一样。
docker 的端口映射
创建一个 nginx 的 container
docker run --name web -d -p 80:80 nginx
docker 的 host 和 none 网络
none network:
docker run -d --name test1 --network none busybox /bin/sh -c "while true;do sleep 3600;done"
docker network inspect none # 可以看到 none 的 network 连接了一个 container
进入容器:
docker exec -it test1 /bin/sh # 进入看看网络,无任何 ip 网络
host network:
docker run -d --name test1 --network host busybox /bin/sh -c "while true;do sleep 3600;done"
docker network inspect host
进入容器:
docker exec -it test1 /bin/sh #查看 ip a 网络,容器的 ip 和主机的 ip 完全一样,他没有自己独立的 namespace
多容器复杂应用的部署:
Flask+redis, flask 的 container 访问 redis 的 container
cat app.py
from flask import Flask
from redis import Redis
import os
import socket
app = Flask(__name__)
redis = Redis(host=os.environ.get(''REDIS_HOST'', ''127.0.0.1''), port=6379)
@app.route(''/'')
def hello():
redis.incr(''hits'')
return ''Hello Container World! I have been seen %s times and my hostname is %s.\n'' % (redis.get(''hits''),socket.gethostname())
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=True)
cat Dockerfile
FROM python:2.7
LABEL maintaner="Peng Xiao xiaoquwl@gmail.com"
COPY . /app
WORKDIR /app
RUN pip install flask redis
EXPOSE 5000
CMD [ "python", "app.py" ]
1. 创建 redis 的 container:
docker run -d --name redis redis
2. dokcer build -t alexhe/flask-redis .
3. 创建 container
docker run -d -p 5000:5000 --link redis --name flask-redis -e REDIS_HOST=redis alexhe/flask-redis #和上面源码的相对应
4. 进入上面的 container, 并执行 env 看一下:
docker exec -it flask-redis /bin/bash
env # 环境变量
ping redis # 在容器里可以 ping redis
5. 在主机访问 curl 127.0.0.1:5000。可以访问到
多主机间,多 container 互相通信
docker 网络的 overlay 和 underlay:
两台 linux 主机 192.168.205.10 192.168.205.11
vxlan 数据包(google 搜 vxlan 概念)
cat multi-host-network.md
# Mutil-host networking with etcd
## setup etcd cluster
在docker-node1上
```
vagrant@docker-node1:~$ wget https://github.com/coreos/etcd/releases/download/v3.0.12/etcd-v3.0.12-linux-amd64.tar.gz
vagrant@docker-node1:~$ tar zxvf etcd-v3.0.12-linux-amd64.tar.gz
vagrant@docker-node1:~$ cd etcd-v3.0.12-linux-amd64
vagrant@docker-node1:~$ nohup ./etcd --name docker-node1 --initial-advertise-peer-urls http://192.168.205.10:2380 \
--listen-peer-urls http://192.168.205.10:2380 \
--listen-client-urls http://192.168.205.10:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://192.168.205.10:2379 \
--initial-cluster-token etcd-cluster \
--initial-cluster docker-node1=http://192.168.205.10:2380,docker-node2=http://192.168.205.11:2380 \
--initial-cluster-state new&
```
在docker-node2上
```
vagrant@docker-node2:~$ wget https://github.com/coreos/etcd/releases/download/v3.0.12/etcd-v3.0.12-linux-amd64.tar.gz
vagrant@docker-node2:~$ tar zxvf etcd-v3.0.12-linux-amd64.tar.gz
vagrant@docker-node2:~$ cd etcd-v3.0.12-linux-amd64/
vagrant@docker-node2:~$ nohup ./etcd --name docker-node2 --initial-advertise-peer-urls http://192.168.205.11:2380 \
--listen-peer-urls http://192.168.205.11:2380 \
--listen-client-urls http://192.168.205.11:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://192.168.205.11:2379 \
--initial-cluster-token etcd-cluster \
--initial-cluster docker-node1=http://192.168.205.10:2380,docker-node2=http://192.168.205.11:2380 \
--initial-cluster-state new&
```
检查cluster状态
```
vagrant@docker-node2:~/etcd-v3.0.12-linux-amd64$ ./etcdctl cluster-health
member 21eca106efe4caee is healthy: got healthy result from http://192.168.205.10:2379
member 8614974c83d1cc6d is healthy: got healthy result from http://192.168.205.11:2379
cluster is healthy
```
## 重启docker服务
在docker-node1上
```
$ sudo service docker stop
$ sudo /usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-store=etcd://192.168.205.10:2379 --cluster-advertise=192.168.205.10:2375&
```
在docker-node2上
```
$ sudo service docker stop
$ sudo /usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-store=etcd://192.168.205.11:2379 --cluster-advertise=192.168.205.11:2375&
```
## 创建overlay network
在docker-node1上创建一个demo的overlay network
```
vagrant@docker-node1:~$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
0e7bef3f143a bridge bridge local
a5c7daf62325 host host local
3198cae88ab4 none null local
vagrant@docker-node1:~$ sudo docker network create -d overlay demo
3d430f3338a2c3496e9edeccc880f0a7affa06522b4249497ef6c4cd6571eaa9
vagrant@docker-node1:~$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
0e7bef3f143a bridge bridge local
3d430f3338a2 demo overlay global
a5c7daf62325 host host local
3198cae88ab4 none null local
vagrant@docker-node1:~$ sudo docker network inspect demo
[
{
"Name": "demo",
"Id": "3d430f3338a2c3496e9edeccc880f0a7affa06522b4249497ef6c4cd6571eaa9",
"Scope": "global",
"Driver": "overlay",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "10.0.0.0/24",
"Gateway": "10.0.0.1/24"
}
]
},
"Internal": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
```
我们会看到在node2上,这个demo的overlay network会被同步创建
```
vagrant@docker-node2:~$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
c9947d4c3669 bridge bridge local
3d430f3338a2 demo overlay global
fa5168034de1 host host local
c2ca34abec2a none null local
```
通过查看etcd的key-value, 我们获取到,这个demo的network是通过etcd从node1同步到node2的
```
vagrant@docker-node2:~/etcd-v3.0.12-linux-amd64$ ./etcdctl ls /docker
/docker/network
/docker/nodes
vagrant@docker-node2:~/etcd-v3.0.12-linux-amd64$ ./etcdctl ls /docker/nodes
/docker/nodes/192.168.205.11:2375
/docker/nodes/192.168.205.10:2375
vagrant@docker-node2:~/etcd-v3.0.12-linux-amd64$ ./etcdctl ls /docker/network/v1.0/network
/docker/network/v1.0/network/3d430f3338a2c3496e9edeccc880f0a7affa06522b4249497ef6c4cd6571eaa9
vagrant@docker-node2:~/etcd-v3.0.12-linux-amd64$ ./etcdctl get /docker/network/v1.0/network/3d430f3338a2c3496e9edeccc880f0a7affa06522b4249497ef6c4cd6571eaa9 | jq .
{
"addrSpace": "GlobalDefault",
"enableIPv6": false,
"generic": {
"com.docker.network.enable_ipv6": false,
"com.docker.network.generic": {}
},
"id": "3d430f3338a2c3496e9edeccc880f0a7affa06522b4249497ef6c4cd6571eaa9",
"inDelete": false,
"ingress": false,
"internal": false,
"ipamOptions": {},
"ipamType": "default",
"ipamV4Config": "[{\"PreferredPool\":\"\",\"SubPool\":\"\",\"Gateway\":\"\",\"AuxAddresses\":null}]",
"ipamV4Info": "[{\"IPAMData\":\"{\\\"AddressSpace\\\":\\\"GlobalDefault\\\",\\\"Gateway\\\":\\\"10.0.0.1/24\\\",\\\"Pool\\\":\\\"10.0.0.0/24\\\"}\",\"PoolID\":\"GlobalDefault/10.0.0.0/24\"}]",
"labels": {},
"name": "demo",
"networkType": "overlay",
"persist": true,
"postIPv6": false,
"scope": "global"
}
```
## 创建连接demo网络的容器
在docker-node1上
```
vagrant@docker-node1:~$ sudo docker run -d --name test1 --net demo busybox sh -c "while true; do sleep 3600; done"
Unable to find image ''busybox:latest'' locally
latest: Pulling from library/busybox
56bec22e3559: Pull complete
Digest: sha256:29f5d56d12684887bdfa50dcd29fc31eea4aaf4ad3bec43daf19026a7ce69912
Status: Downloaded newer image for busybox:latest
a95a9466331dd9305f9f3c30e7330b5a41aae64afda78f038fc9e04900fcac54
vagrant@docker-node1:~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a95a9466331d busybox "sh -c ''while true; d" 4 seconds ago Up 3 seconds test1
vagrant@docker-node1:~$ sudo docker exec test1 ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:0A:00:00:02
inet addr:10.0.0.2 Bcast:0.0.0.0 Mask:255.255.255.0
inet6 addr: fe80::42:aff:fe00:2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:15 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1206 (1.1 KiB) TX bytes:648 (648.0 B)
eth1 Link encap:Ethernet HWaddr 02:42:AC:12:00:02
inet addr:172.18.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe12:2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:648 (648.0 B) TX bytes:648 (648.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
vagrant@docker-node1:~$
```
在docker-node2上
```
vagrant@docker-node2:~$ sudo docker run -d --name test1 --net demo busybox sh -c "while true; do sleep 3600; done"
Unable to find image ''busybox:latest'' locally
latest: Pulling from library/busybox
56bec22e3559: Pull complete
Digest: sha256:29f5d56d12684887bdfa50dcd29fc31eea4aaf4ad3bec43daf19026a7ce69912
Status: Downloaded newer image for busybox:latest
fad6dc6538a85d3dcc958e8ed7b1ec3810feee3e454c1d3f4e53ba25429b290b
docker: Error response from daemon: service endpoint with name test1 already exists. #已经用过不能再用
vagrant@docker-node2:~$ sudo docker run -d --name test2 --net demo busybox sh -c "while true; do sleep 3600; done"
9d494a2f66a69e6b861961d0c6af2446265bec9b1d273d7e70d0e46eb2e98d20
```
验证连通性。
```
vagrant@docker-node2:~$ sudo docker exec -it test2 ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:0A:00:00:03
inet addr:10.0.0.3 Bcast:0.0.0.0 Mask:255.255.255.0
inet6 addr: fe80::42:aff:fe00:3/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:208 errors:0 dropped:0 overruns:0 frame:0
TX packets:201 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:20008 (19.5 KiB) TX bytes:19450 (18.9 KiB)
eth1 Link encap:Ethernet HWaddr 02:42:AC:12:00:02
inet addr:172.18.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe12:2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:648 (648.0 B) TX bytes:648 (648.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
vagrant@docker-node1:~$ sudo docker exec test1 sh -c "ping 10.0.0.3"
PING 10.0.0.3 (10.0.0.3): 56 data bytes
64 bytes from 10.0.0.3: seq=0 ttl=64 time=0.579 ms
64 bytes from 10.0.0.3: seq=1 ttl=64 time=0.411 ms
64 bytes from 10.0.0.3: seq=2 ttl=64 time=0.483 ms
^C
vagrant@docker-node1:~$
```
docker 的持久化存储和数据共享:
持久化有两种方式:1,Data Volume 2,Bind Mounting
第一种 Data Volume:
容器产生数据,比如日志,数据库,想保留这些数据
例如 https://hub.docker.com/_/mysql
docker run -d -e MYSQL_ALLOW_EMPTY_PASSWORD=yes --name mysql1 mysql
查看 volume:
docker volume ls
删除 volume
docker volume rm xxxxxxxxxx
查看细节:
docker volume inspect xxxxxxxxx
创建第二个 mysql container
docker run -d -e MYSQL_ALLOW_EMPTY_PASSWORD=yes --name mysql2 mysql
查看细节:
docker volume inspect xxxxxxxxx
删除 container,volume 是不会删除的:
docker stop mysql1 mysql2
docker rm mysql1 mysql2
docker volume ls # 数据还在
重新创建 mysql1:
docker run -d -v mysq:/var/lib/mysql -e MYSQL_ALLOW_EMPTY_PASSWORD=yes --name mysql1 mysql # 这里的 mysq 是 volume 的名字
docker volume ls # 会显示 mysq
进入 mysql1 的 container
创建一个新的数据库
create database docker;
退出容器,把 mysql1 container 删除
docker rm -f mysql1 # 强制停止和删除 mysql1 这个 container
查看 volume:
docker volume ls # 还在
创建一个新的 mysql2 container,但是 volume 使用之前的 mysq
docker run -d -v mysq:/var/lib/mysql -e MYSQL_ALLOW_EMPTY_PASSWORD=yes --name mysql2 mysql
进入 mysql2 的容器里,看看数据库在不在
show database #数据库还在
第二种持久化方式:bind mounting
和第一种方式区别是什么?如果用 data volume 方式,需要在 dockerfile 里定义创建的 volume,bind mounting 不需要,bind mouting 只需要在运行时指定本地目录和容器目录一一对应的关系。
然后通过这种方式去做一个同步,就是说本地系统中的文件和容器中的文件是同步的。本地文件做了修改,容器目录中的文件也会做修改。
cat Dockerfile
# this same shows how we can extend/change an existing official image from Docker Hub
FROM nginx:latest
# highly recommend you always pin versions for anything beyond dev/learn
WORKDIR /usr/share/nginx/html
# change working directory to root of nginx webhost
# using WORKDIR is prefered to using ''RUN cd /some/path''
COPY index.html index.html
# I don''t have to specify EXPOSE or CMD because they''re in my FROM
index.html 随便整一个
docker build -t alexhe/my-nginx .
docker run -d -p 80:80 -v $(pwd):/usr/shar/nginx/html --name web alexhe/my-nginx
bind mount 其他案例:
cat Dockerfile
FROM python:2.7
LABEL maintainer="alexhe<alex@alexhe.net>"
COPY . /skeleton
WORKDIR /skeleton
RUN pip install -r requirements.txt
EXPOSE 5000
ENTRYPOINT ["scripts/dev.sh"]
开始 build image
docker build -t alexhe/flask-skeleton
docker run -d -p 80:5000 -v $(pwd):/skeleton --name flask alexhe/flask-skeleton
其他源码在
/Users/apple/temp/docker-k8s-devops-master/chapter5/labs/flask-skeleton
部署一个 WordPress:
docker run -d -v mysql-data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=root -e MYSQL_DATABASE=wordpress --name mysql mysql
docker run -d -e WORDPRESS_DB_HOST=mysql:3306 -e WORDPRESS_DB_PASSWORD=root --link mysql -p 8080:80 wordpress
docker compose:
官网介绍 https://docs.docker.com/compose/overview/
通过一个 yml 文件定义多容器的 docker 应用
通过一条命令就可以根据 yml 文件的定义去创建或者管理这多个容器
docker compose 的三大概念:Services,Networks,Volumes
v2 可以运行在单机,v3 可以运行在多机
services:一个 service 代表一个 container,这个 container 可以从 dokcerhub 的 image 来创建,或者从本地的 dockerfile build 出来的 image 来创建
service 的启动,类似 docker run,我们可以给其制定 network 和 volume,所以可以给 service 指定 network 和 volume 的引用。
例子:
services:
db: (container 的名字叫 db)
image:postgres:9.4(docker hub 拉取的)
volumes:
- "db-data:/var/lib/postgresql/data"
networks:
- back-tier
就像这样:
docker run -d --network back-tier -v db-data:/var/lib/postgresql/data postgres:9.4
例子:
services:
worker: (container 的名字)
build: ./worker (不是从 dockerhub 取,而是从本地 build)
links:
- db
- redis
networks:
- back-tier
例子:
cat docker-compose.yml
version: ''3''
services:
wordpress:
image: wordpress
ports:
- 8080:80
environment:
WORDPRESS_DB_HOST: mysql
WORDPRESS_DB_PASSWORD: root
networks:
- my-bridge
mysql:
image: mysql
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: wordpress
volumes:
- mysql-data:/var/lib/mysql
networks:
- my-bridge
volumes:
mysql-data:
networks:
my-bridge:
driver: bridge
docker-compose 的安装和基本使用:
安装:https://docs.docker.com/compose/install/
curl -L "https://github.com/docker/compose/releases/download/1.23.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
docker-compose version 1.23.2, build 1110ad01
使用:
用上面的 docker-compose.yml
docker-compose up #在当前文件夹的 docker-compose.yml,启动. 1. 创建 bridge 网络 wordpress_my-bridge. 2. 创建 2 个 service wordpress_wordpress_1 和 wordpress_mysql_1,并且启动 container
docker-compose -f xxxx/docker-compose.yml # 在调用指定文件夹中的 docker-compose.yml
docker-compose ps # 显示目前的 service
docker-compose stop
docker-compose down #stop and remove, 但是不会删除 image
docker-compose start
docker-compose up -d # 后台执行,不显示日志
docker-compose images #显示 yml 中定义的 container 和使用的 image
docker-compose exec mysql bash #mysql 是 yml 中定义的 service,进入 mysql 这台 container 的 bash
案例:docker-compose 调用 Dockerfile 来创建
源码在 /Users/apple/temp/docker-k8s-devops-master/chapter6/labs/flask-redis
cat docker-compose.yml
version: "3"
services:
redis:
image: redis
web:
build:
context: . #dockerfile 的位置
dockerfile: Dockerfile # 调用目录中的 Dockerfile
ports:
- 8080:5000
environment:
REDIS_HOST: redis
cat Dockerfile
FROM python:2.7
LABEL maintaner="alexhe alex@alexhe.net"
COPY . /app
WORKDIR /app
RUN pip install flask redis
EXPOSE 5000
CMD [ "python", "app.py" ]
使用:docker-compose up -d #如果不使用 - d 会一直停在那里 web 信息输出在前端
docker-compose 中的 scale
docker-compose up # 用上面的 yml
docker-compose up --scale web=3 -d # 会报错,报 8080 已经被占用,需要把上面的 ports: - 8000:5000 删除
删除后再执行上面的。会启动 3 个 container,并监听了容器本地的 5000。可用 docker-compose ps 查看
但这样不行,容器本地的 5000 端口我们访问不到。我们需要在 yml 里新增 haproxy
cat docker-compose.yml
version: "3"
services:
redis:
image: redis
web:
build:
context: .
dockerfile: Dockerfile
environment:
REDIS_HOST: redis
lb:
image: dockercloud/haproxy
links:
- web
ports:
- 8080:80
volumes:
- /var/run/docker.sock:/var/run/docker.sock
cat Dockerfile
FROM python:2.7
LABEL maintaner="alex alex@alexhe.net"
COPY . /app
WORKDIR /app
RUN pip install flask redis
EXPOSE 80
CMD [ "python", "app.py" ]
cat app.py
from flask import Flask
from redis import Redis
import os
import socket
app = Flask(__name__)
redis = Redis(host=os.environ.get(''REDIS_HOST'', ''127.0.0.1''), port=6379)
@app.route(''/'')
def hello():
redis.incr(''hits'')
return ''Hello Container World! I have been seen %s times and my hostname is %s.\n'' % (redis.get(''hits''),socket.gethostname())
if __name__ == "__main__":
app.run(host="0.0.0.0", port=80, debug=True)
docker-compose up -d
curl 127.0.0.1:8080
docker-compose up --scale web=3 -d
案例:部署一个复杂的应用,投票系统,
源码:
/Users/apple/temp/docker-k8s-devops-master/chapter6/labs/example-voting-app
python 前端 + redis+java worker+ pg database + results app
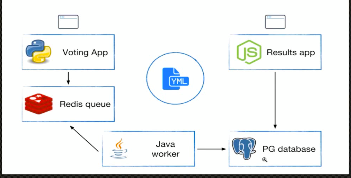
cat docker-compose.yml
version: "3"
services:
voting-app:
build: ./voting-app/.
volumes:
- ./voting-app:/app
ports:
- "5000:80"
links:
- redis
networks:
- front-tier
- back-tier
result-app:
build: ./result-app/.
volumes:
- ./result-app:/app
ports:
- "5001:80"
links:
- db
networks:
- front-tier
- back-tier
worker:
build: ./worker
links:
- db
- redis
networks:
- back-tier
redis:
image: redis
ports: ["6379"]
networks:
- back-tier
db:
image: postgres:9.4
volumes:
- "db-data:/var/lib/postgresql/data"
networks:
- back-tier
volumes:
db-data:
networks:
front-tier: # 没指明 driver,默认为 bridge
back-tier:
docker-compose up
浏览器通过 5000 端口投票,5001 查看投票结果
docker-compose build #可以事先 build image, 而用 up 会先 build 再做 start。
docker swarm
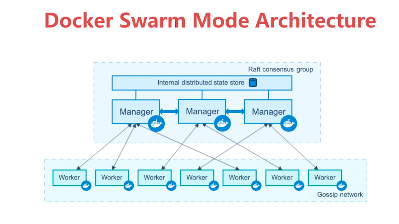
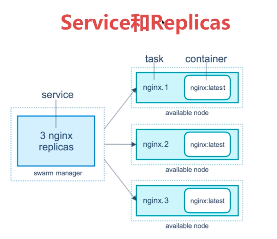
创建一个 3 节点的 swarm cluster
manager 192.168.205.10
worker1 192.168.205.11
worker2 192.168.205.12
manager:
docker swarm init --advertise-addr=192.168.205.10
worker1 and 2:
docker swarm join xxxxx
manager:
docker node ls # 查看所有节点
docker service create --name demo busybox sh -c "while true;do sleep 3600;done"
docker service ls
docker service ps demo # 看 service 在哪台机器上
docker service scale demo=5 #扩展成 5 台
如果在 work2 上,强制删除了一个 container, docker rm -f xxxxxxxxx.
这时候如果 docker service ls,会显示 REPLICAS 4/5, 过一会儿会显示 5/5,在 docker service ls 里会显示有状态为 shutdown 的 container
docker service rm demo # 删除整个 service
docker service ps demo
swarm service 部署 WordPress
docker network create -d overlay demo # 创建 overlay 的网络,docker network ls
docker service create --name mysql --env MYSQL_ROOT_PASSWORD=root --env MYSQL_DATABASE=wordpress --network demo --mount type=volume,source=mysql-data,destination=/var/lib/mysql mysql #service 中 - v 是这样的 mount 格式,名字叫 mysql-data,挂载地址在 /var/lib/mysql
docker service ls
docker service ps mysql
docker service create --name wordpress -p 80:80 --env WORDPRESS_DB_PASSWORD=root --env WORDPRESS_DB_HOST=mysql --network demo wordpress
docker service ps wordpress
访问 manager 或者 worker 的 http 地址,都能访问到 wordpress
集群服务间通信之 RoutingMesh
swam 有内置服务发现的功能。通过 service 访问,是连到了 overlay 的网络。 用到了 vip。
首先要有 demo 的 overlay 网络。
docker service create --name whoami -p 8000:8000 --network demo -d jwilder/whoami
docker service ls
docker service ps whoami #运行在 manager 节点
curl 127.0.0.1:8000
再创建一个 busybox service
docker service create --name client -d --network demo busybox sh -c "while true;do sleep 3600;done"
docker service ls
docker service ps client #运行在 work1 节点
首先进到 swarm 的 worker1 节点
docker exec -it xxxx sh 进入这个 busybox container
ping whoami #ping service 的 name, 10.0.0.7, 这个其实是一个 vip,通过 lvs 创建的
docker service scale whoami=2 # 扩展到 2 台
docker service ps whoami #有一台运行在 work1,一台在 work2
进入 worker1 的节点
docker exec -it xxx sh #进入 busybox container
ping whoami # 还是不变
nslookup whoami # 10.0.0.7 虚拟 ip
nslookup tasks.whoami # 有 2 个地址。这才是具体 container 的真实地址
iptables -t mangle -nL DOCKER-INGRESS 里做了转发
Routing Mesh 的两种体现
Internal:在网络中,container 和 container 是通过 overlay 网络来进行通信。
Ingress:如果服务有绑定接口,则此服务可以通过任意 swarm 节点的响应接口访问。服务端口被暴露到每个 swarm 节点
docker stack 部署 wordpress
compose yml 的 reference:https://docs.docker.com/compose/compose-file/
官方例子:
version: "3.3"
services:
wordpress:
image: wordpress
ports:
- "8080:80"
networks:
- overlay
deploy:
mode: replicated
replicas: 2
endpoint_mode: vip #vip指service互访的时候,往外暴露的是虚拟的ip,底层通过lvs,负载均衡到后端服务器。默认为vip模式。
mysql:
image: mysql
volumes:
- db-data:/var/lib/mysql/data
networks:
- overlay
deploy:
mode: replicated
replicas: 2
endpoint_mode: dnsrr #dnsrr,直接使用service的ip地址,当横向扩展了以后,可能有三个或者四个IP地址,循环调用。
volumes:
db-data:
networks:
overlay:还有 labels:打标签
mode:global 和 replicated,global 代表全 cluster 只有一个,不能做横向扩展。replicated,mode 的默认值,可以通过 docker service scale 做横向扩展。
placement:设定 service 的限定条件。比如:
version: ''3.3''
services:
db:
image: postgres
deploy:
placement:
constraints:
- node.role == manager #db这个service一定会部署到manager这个节点,并且系统环境一定是ubuntu 14.04
- engine.labels.operatingsystem == ubuntu 14.04
preferences:
- spread: node.labels.zonereplicas:如果设置了模式为 replicted,可以设置这个值
resources:资源占用和保留。
restart_policy: 重启条件,延迟,重启次数
update_config: 配置更新时的参数,比如可以同时更新 2 个,要等 10 秒才更新第二个。
cat docker-compose.yml
version: ''3''
services:
web: #这个 service 叫 web
image: wordpress
ports:
- 8080:80
environment:
WORDPRESS_DB_HOST: mysql
WORDPRESS_DB_PASSWORD: root
networks:
- my-network
depends_on:
- mysql
deploy:
mode: replicated
replicas: 3
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
update_config:
parallelism: 1
delay: 10s
mysql: #这个 service 叫 mysql
image: mysql
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: wordpress
volumes:
- mysql-data:/var/lib/mysql
networks:
- my-network
deploy:
mode: global #指能创建一台,不允许 replicated
placement:
constraints:
- node.role == manager
volumes:
mysql-data:
networks:
my-network:
driver: overlay # 默认为 bridge,但是我们在多机集群里,要改成 overlay。
发布:
docker stack deploy wordpress --compose-file=docker-compose.yml #stack 的名字为 wordpress
查看:
docker stack ls
docker stack ps wordpress
docker stack services wordpress #显示 services replicas 的情况。
访问:随便挑一台 node 的 ip 8080 端口
注意:docker swarm 不能使用上面投票系统中的 build,所以要自己 build image
投票系统,使用 docker swarm 部署:
cat docker-compose.yml
version: "3"
services:
redis:
image: redis:alpine
ports:
- "6379"
networks:
- frontend
deploy:
replicas: 2
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
db:
image: postgres:9.4
volumes:
- db-data:/var/lib/postgresql/data
networks:
- backend
deploy:
placement:
constraints: [node.role == manager]
vote:
image: dockersamples/examplevotingapp_vote:before
ports:
- 5000:80
networks:
- frontend
depends_on:
- redis
deploy:
replicas: 2
update_config:
parallelism: 2
restart_policy:
condition: on-failure
result:
image: dockersamples/examplevotingapp_result:before
ports:
- 5001:80
networks:
- backend
depends_on:
- db
deploy:
replicas: 1
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
worker:
image: dockersamples/examplevotingapp_worker
networks:
- frontend
- backend
deploy:
mode: replicated
replicas: 1
labels: [APP=VOTING]
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 3
window: 120s
placement:
constraints: [node.role == manager]
visualizer:
image: dockersamples/visualizer:stable
ports:
- "8080:8080"
stop_grace_period: 1m30s
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
deploy:
placement:
constraints: [node.role == manager]
networks:
frontend: # 在 swarm 模式下默认是 overlay 的
backend:
volumes:
db-data:
启动:
docker stack deploy voteapp --compose-file=docker-compose.yml
docker secret 管理
internal distributed store 是存储在所有 swarm manager 节点上的,所以 manager 节点推荐 2 台以上。存在 swarm manger 节点的 raft database 里。
secret 可以 assign 给一个 service,这个 service 就能看到这个 secret
在 container 内部 secret 看起来像文件,但是实际是在内存中。
secret 创建,从文件创建:
vim alexpasswd
admin123
docker secret create my-pw alexpasswd #给这个 secret 起个名字叫 my-pw
查看:
docker secret ls
从标准输入创建:
echo "adminadmin" | docker secret create my-pw2 - # 从标准输入创建
删除:
docker secret rm my-pw2
把一个 secret 暴露给 service
docker service create --name client --secret my-pw busybox sh -c while true;do sleep 3600;done"
查看 container 在哪个节点上:
docker service ps client
进入这个 container:
docker exec -it ccee sh
cd /run/secret/my-pw # 这里就能看到我们的密码 secret
例如 mysql 的 docker:
docker service create --name db --secret my-pw -e MYSQL_ROOT_PASSWORD_FILE=/run/secrets/my-pw mysql
secret 在 stack 中使用:
有个密码文件:
cat password
adminadmin
docker-compose.yml 文件:
version: ''3''
services:
web:
image: wordpress
ports:
- 8080:80
secrets:
- my-pw
environment:
WORDPRESS_DB_HOST: mysql
WORDPRESS_DB_PASSWORD_FILE: /run/secrets/my-pw
networks:
- my-network
depends_on:
- mysql
deploy:
mode: replicated
replicas: 3
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
update_config:
parallelism: 1
delay: 10s
mysql:
image: mysql
secrets:
- my-pw
environment:
MYSQL_ROOT_PASSWORD_FILE: /run/secrets/my-pw
MYSQL_DATABASE: wordpress
volumes:
- mysql-data:/var/lib/mysql
networks:
- my-network
deploy:
mode: global
placement:
constraints:
- node.role == manager
volumes:
mysql-data:
networks:
my-network:
driver: overlay
# secrets:
# my-pw:
# file: ./password
使用:
docker stack deploy wordpress -c=docker-compose.yml
service 的更新:
首先建立源 service:
docker service create --name web --publish 8080:5000 --network demo alexhe/python-flask-demo:1.0
开始扩展,至少 2 个:
docker service scale web=2
检查服务 curl 127.0.0.1:8080
while true;do curl 127.0.0.1:8080 && sleep 1;done
更新服务:
可以更新 secret,publish port,image 等等
docker service update --image alexhe/python-flask-demo:2.0 web
更新端口:
docker service update --publish-rm 8080:5000 --publish-add 8088:5000 web
k8s 版本

Docker Kubernetes 容器扩容与缩容
Docker Kubernetes 容器扩容与缩容
环境:
- 系统:Centos 7.4 x64
- Docker 版本:18.09.0
- Kubernetes 版本:v1.8
- 管理节点:192.168.1.79
- 工作节点:192.168.1.78
- 工作节点:192.168.1.77
创建环境:
- 1、Deployment 名称:nginx-deployment
- 2、pods 副本数为:3
- 3、image 镜像:nginx1.9
管理节点:扩容或缩容 deploymnet 的 pod 副本数。
kubectl scale deployment nginx-deployment --replicas=10

kubectl scale 资源类型 资源名称 --replicas=扩容副本数管理节点:设置扩容或缩容添加阀值范围。
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80

kubectl autoscale 资源类型 资源名称 --max=最大值 --最小值 --cpu-percent=cpu百分比以内

NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa/nginx-deployment Deployment/nginx-deployment <unknown> / 80% 10 15 5 41s
简介")
Docker Kubernetes(K8s)简介
入职了新公司,使用了Docker和K8s,需要有一个基础的了解,对网络上相关信息进行了简单总结。
一Docker
###1简介: Docker 将应用程序与该程序的依赖,打包在一个文件里面。运行这个文件,就会生成一个虚拟容器。程序在这个虚拟容器里运行,就好像在真实的物理机上运行一样。 ###2功能: 虚拟化解决了应用运行环境的复杂,硬件管理的问题,提供可移植性。 ###3架构: Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。 Docker 客户端(clients)会与 Docker 守护进程进行通信。 Docker 守护进程(daemon)和容器运行在一台主机上。用户并不直接和守护进程进行交互,而是通过 Docker 客户端间接和其通信。 Docker 容器和文件夹很类似,一个Docker容器包含了所有的某个应用运行所需要的环境。每一个 Docker 容器都是从 Docker 镜像(image)创建的。 Docker仓库(repsitory)用来保存镜像。 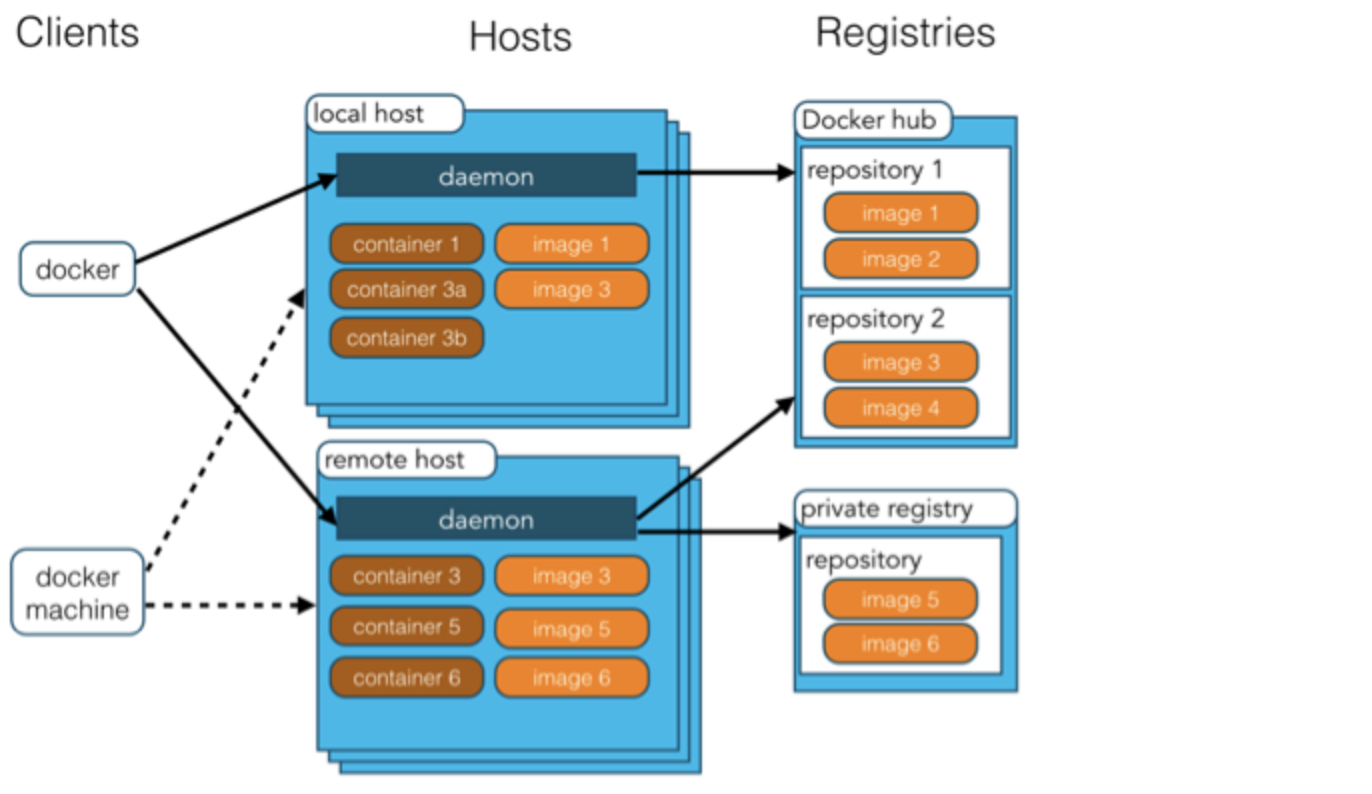
###4应用场景: 1)提供一次性的环境 2)提供弹性的云服务 3)组建微服务架构
二K8s
###1简介: 全新的基于容器技术的分布式架构领先方案。Kubernetes(k8s)是Google开源的容器集群管理系统(谷歌内部:Borg)。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。 ###2功能: Kubernetes内奸的透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否会由于发生故障而重新部署到其他机器,都不会影响我们队服务的正常调用。 ###3架构: Master:集群控制管理节点,所有的命令都经由master处理。 Node:是kubernetes集群的工作负载节点。Master为其分配工作,当某个Node宕机时,Master会将其工作负载自动转移到其他节点。负责Pod对应容器的创建暂停等任务。 kubelet:运行在每个计算节点上,作为agent,接受分配该节点的Pods任务及管理容器,周期性获取容器状态,反馈给kube-apiserver。 Pod:Pod是Kurbernetes进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得部署和管理更加灵活。一个Pod可以包含一个容器或者多个相关容器。 在Kubenetes中,所有的容器均在Pod中运行,一个Pod可以承载一个或者多个相关的容器,同一个Pod中的容器会部署在同一个物理机器上并且能够共享资源。 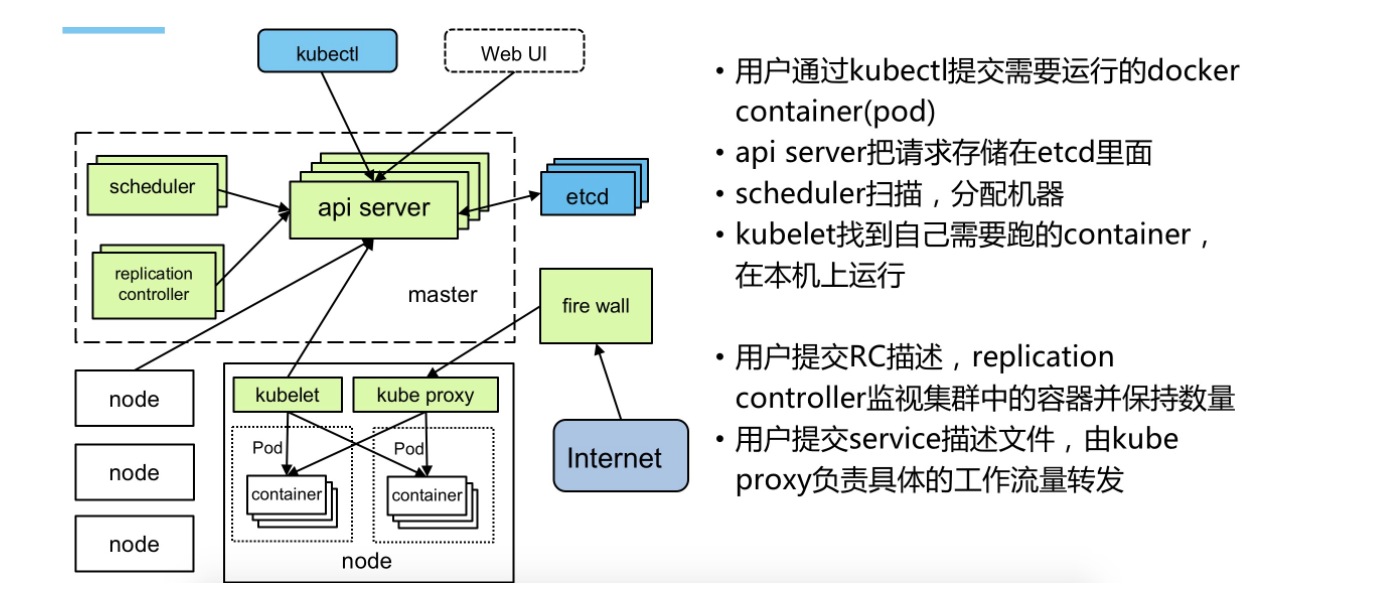 ###核心组件: etcd保存了整个集群的状态; apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制; controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等; scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上; kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理; Container runtime负责镜像管理以及Pod和容器的真正运行(CRI); kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
###核心组件: etcd保存了整个集群的状态; apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制; controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等; scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上; kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理; Container runtime负责镜像管理以及Pod和容器的真正运行(CRI); kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
 生产级容器编排 上")
DOCKER 学习笔记9 Kubernetes (K8s) 生产级容器编排 上
前言
在上一节的学习中。我们已经可以通过最基本的 Docker Swarm 创建集群,然后在集群里面加入我们需要运行的任务 以及任务的数量 这样我们就创建了一个服务。 当然,这样的方式在我们本地虚拟机的情况下,完全适用,并且对于
- 容器
- 虚拟主机
- swarm 创建节点组成集群
有一个很好的理解作用。本节将继续学习关于 Kubernetes (K8s) 的内容。
Kubernetes 建立在 Google 15年的生产工作负载管理经验的基础上,结合了来自社区的最佳理念和实践。
Kubernetes (K8s)
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。 在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
节点与管理节点
在K8s 集群包括两种类型的资源
- 普通节点 Node 一般用于服务
- 管理节点 Master 用于管理其他节点
Master 管理节点
Master 负责管理集群。 主服务器协调集群中的所有活动,例如调度应用程序、维护应用程序的期望状态、缩放应用程序和推出新的更新。
Node 服务节点
Node 是作为 Kubernetes 集群中的工作机器的 VM 或物理计算机。 每个节点都有一个 Kubelet,它是管理节点和与 kubernets 主节点通信的代理。 节点还应该具有处理容器操作的工具,如 Docker
这个还是和在上一节当中学习的Swarm 虚拟机中通过 docker swarm init xx 其实还是有类似的地方的。
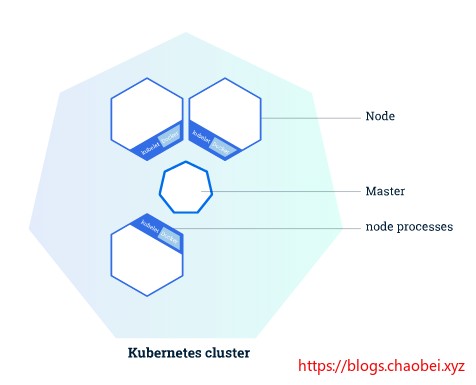
服务执行过程
当您在 Kubernetes 上部署应用程序时,您告诉主控程序启动应用程序容器。 主服务器安排容器在集群节点上运行。 节点使用主服务器公开的 Kubernetes API 与主服务器通信。 最终用户还可以直接使用 Kubernetes API 与集群交互。
windows 安装 kubectl 以及 minikube
若没有安装 Docker-toolbox 的同学请参考并安装:
https://blogs.chaobei.xyz/archives/docker6
下载 kubectl
Kubernetes 命令行工具 kubectl 允许您针对 Kubernetes 集群运行命令。 您可以使用 kubectl 部署应用程序、检查和管理集群资源以及查看日志。
https://storage.googleapis.com/kubernetes-release/release/v1.17.0/bin/windows/amd64/kubectl.exe
修改名称为 kubectl.exe
复制到和docker-toolbox 一样的目录下,方便执行
$ kubectl.exe version
Client Version: version.Info{Major:"1", Minor:"17", GitVersion:"v1.17.0", GitCommit:"70132b0f130acc0bed193d9ba59dd186f0e634cf", GitTreeState:"clean", BuildDate:"2019-12-07T21:20:10Z", GoVersion:"go1.13.4", Compiler:"gc", Platform:"windows/amd64"}
下载 minikube
https://github.com/kubernetes/minikube/releases/
选择合适的版本后,下载,并且修改名称为 minikube.exe 放到与上面一样的位置下。
$ minikube.exe version minikube version: v1.7.2
commit: 50d543b5fcb0e1c0d7c27b1398a9a9790df09dfb
使用 minikube 创建集群
minikube start --image-repository=registry.aliyuncs.com/google_containers --registry-mirror=https://fime0zji.mirror.aliyuncs.com --iso-url=https://kubernetes.oss-cn-hangzhou.aliyuncs.com/minikube/iso/minikube-v1.7.0.iso
--image-repository指定使用国内的镜像仓库--registry-mirror将指定的地址传递给虚拟机docker 作为拉取镜像的地址--iso-url指定minikubo 镜像的地址。
因为国内防火墙的限制,所以需要将发部分指定为国内地址才可以正常进行。
$ minikube start --image-repository=registry.aliyuncs.com/google_containers --registry-mirror=https://fime0zji.mirror.aliyuncs.com
* Microsoft Windows 10 Pro 10.0.18363 Build 18363 上的 minikube v1.7.2
* Automatically selected the virtualbox driver
* 正在使用镜像存储库 registry.aliyuncs.com/google_containers
* 正在创建 virtualbox 虚拟机(CPUs=2,Memory=2000MB, Disk=20000MB)...
* 找到的网络选项:
- NO_PROXY=192.168.99.100,192.168.99.102,192.168.99.103
- no_proxy=192.168.99.100,192.168.99.102,192.168.99.103
* 正在 Docker 19.03.5 中准备 Kubernetes v1.17.2…
- env NO_PROXY=192.168.99.100,192.168.99.102,192.168.99.103
- env NO_PROXY=192.168.99.100,192.168.99.102,192.168.99.103
* 正在启动 Kubernetes ...
* Enabling addons: default-storageclass, storage-provisioner
* 等待集群上线...
* 完成!kubectl 已经配置至 "minikube"
官网在线测试环境 https://kubernetes.io/docs/tutorials/kubernetes-basics/create-cluster/cluster-interactive/
可能遇到的问题
* 正在下载 kubectl v1.17.2
* 正在下载 kubeadm v1.17.2
* 正在下载 kubelet v1.17.2
它可能一直在下载,真的是一直在下,我第一次使用的时候,我足足等了一个小时,现在想起来真的是 MMP
解决方案
- 找到其所下载的版本
- 通过FQ的方式下载到本地,放到cache 缓存文件夹下。
kubeadm https://storage.googleapis.com/kubernetes-release/release/v1.17.2/bin/linux/amd64/kubeadm kubelet https://storage.googleapis.com/kubernetes-release/release/v1.17.2/bin/linux/amd64/kubelet kubectl.http://mirror.azure.cn/kubernetes/kubectl/v1.17.2/bin/linux/amd64/kubectl
从上面的下载地址里面修改版本号即可下载你想要的版本。
需要FQ上网才能下载,你懂得
Kubernetes仪表板
minikube dashboard
$ minikube dashboard
* 正在开启 dashboard ...
* Verifying dashboard health ...
* Launching proxy ...
* Verifying proxy health ...
* Opening http://127.0.0.1:63230/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ in your default browser...
集群状态
kubectl cluster-info
因为我们已经安装了与之交互的 kubectl
$ kubectl.exe cluster-info
Kubernetes master is running at https://192.168.99.113:8443
KubeDNS is running at https://192.168.99.113:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use ''kubectl cluster-info dump''.
可以了解到 Kubernets 主节点运行地址以及 Kube 的DNS
获取所有的节点信息
$ kubectl.exe get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready master 31m v1.17.2
创建APP 镜像
构建一个node 应用
这个应用需要创建在你的minikube 虚拟机内。而不是本地docker
## 创建一个文件夹
mkdir -p nodetest
## 创建自定义镜像文件并加入以下内容
vi Dockerfile
FROM nginx
RUN echo ''<h1>Hello, Docker!</h1>'' > /usr/share/nginx/html/index.html
构建测试镜像
docker build -t mynginx:test .
尝试运行测试镜像
$ docker run --name mynginx-d -p 8080:80 mynginx:test
测试访问
因为我们的的镜像是跑在虚拟机当中的,获取其网卡地址后,用8080访问
使用kubectl创建部署
Kubernetes Pod 是一组由一个或多个容器组成的组,为了管理和联网的目的而连接在一起。
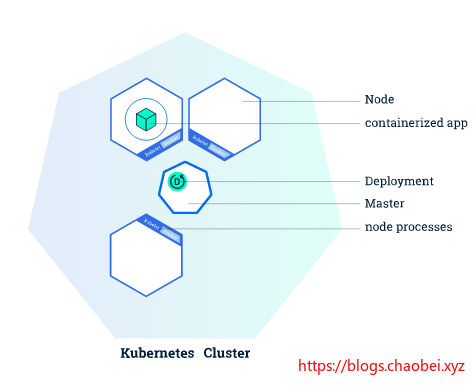
当我们在 Kubernetes 上创建一个 Deployment 时,Deployment 会创建包含容器的 Pods (而不是直接创建容器)。 每个 Pod 都绑定到节点的预定位置,直到终止(根据重新启动策略)或删除为止。 如果节点出现故障,则在集群中的其他可用节点上调度相同的 Pods。
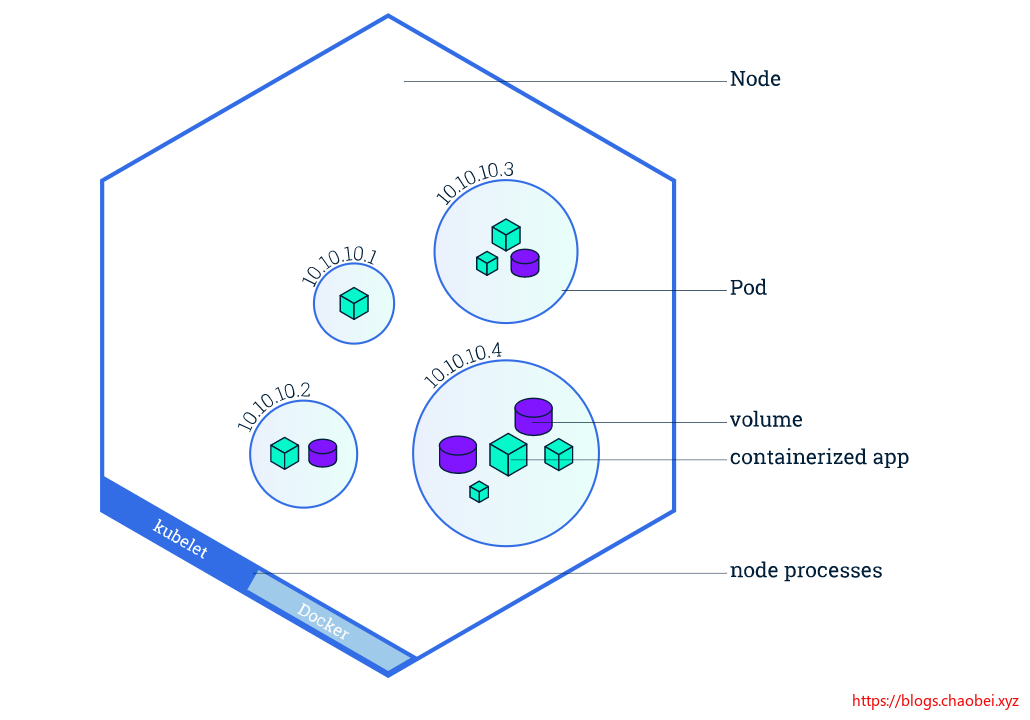
一个 Pod 总是在一个 Node 上运行。 Node 是 Kubernetes 的工作机器,根据集群的不同,它可以是虚拟机,也可以是物理机器。 每个节点由主节点管理。 一个 Node 可以有多个POD,Kubernetes 主机自动处理跨集群中的 Node 的POD调度。 主机的自动调度考虑到了每个节点上的可用资源。
创建一个POD
Pod 是一组或多个应用程序容器(如 Docker 或 rkt) ,包括共享存储(卷)、 IP 地址和有关如何运行它们的信息。
kubectl create deployment mynode --image=mynginx:test
使用 kubectl create 命令创建一个管理 Pod 的 Deployment。 Pod 基于所提供的 Docker 图像运行一个容器。
查看部署
$ kubectl.exe get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
mynode 1/1 1 1 10s
查看POD
kubectl.exe get pods
$ kubectl.exe get pods NAME READY STATUS RESTARTS AGE
mynode-5479db549c-fm4qk 1/1 Running 0 9m33s
集群事件
kubectl get events
kubectl 配置
kubectl config view
$ kubectl.exe config view apiVersion: v1
clusters:
- cluster:
certificate-authority: C:\Users\17639\.minikube\ca.crt
server: https://192.168.99.100:8443
name: minikube
contexts:
- context:
cluster: minikube
user: minikube
name: minikube
current-context: minikube
kind: Config
preferences: {}
users:
- name: minikube
user:
client-certificate: C:\Users\17639\.minikube\client.crt
client-key: C:\Users\17639\.minikube\client.key
创建一个服务暴露你的应用
默认情况下,Pod 只能通过它在 Kubernetes 集群中的内部 IP 地址访问。 要使 hello-node Container 可以从 Kubernetes 虚拟网络外部访问,必须将 Pod 公开为 Kubernetes 服务。
Kubernetes 的服务是一个抽象概念,它定义了一组逻辑 Pods 和一个访问它们的策略。 服务允许独立的Pods 之间的松散耦合。 服务是使用 YAML (首选)或 JSON 定义的,就像所有的 Kubernetes 对象一样。
尽管每个 Pod 都有一个唯一的 IP 地址,但是如果没有 Service,这些 IP 不会在集群之外公开。 服务允许应用程序接收流量。 通过在 ServiceSpec 中指定类型,可以以不同的方式公开服务:
- ClusterIP (default) 公开集群中内部 IP 上的服务。 此类型使服务只能从集群内部访问
- NodePort 使用 NAT 公开集群中每个选定节点的同一端口上的服务
- LoadBalancer 负载均衡器,创建一个负载均衡器,并且为服务分配固定IP
- ExternalName
服务以及标签
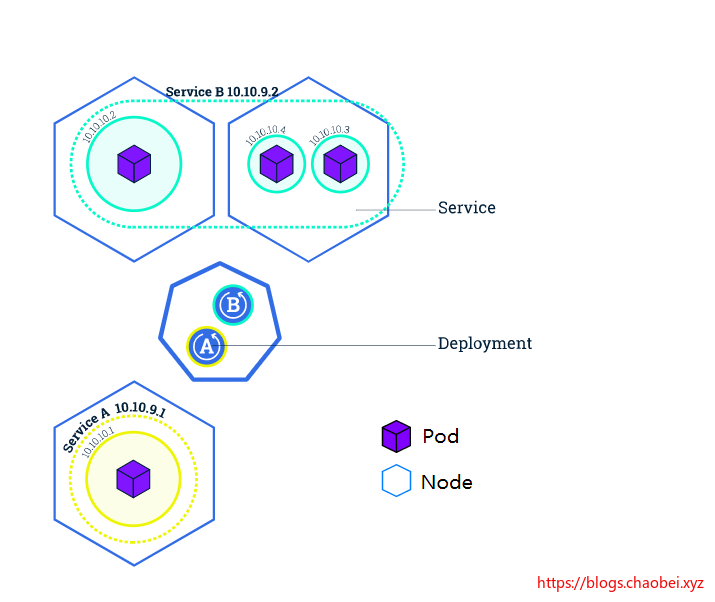
一组PODS 组成一个服务。服务是一种抽象,它允许POD 在节点关闭时候死亡,以及复制。而不会影响到服务的运行。服务内部依赖的PODS 之间的发现和关联都是由Kubernets Service 来处理的。
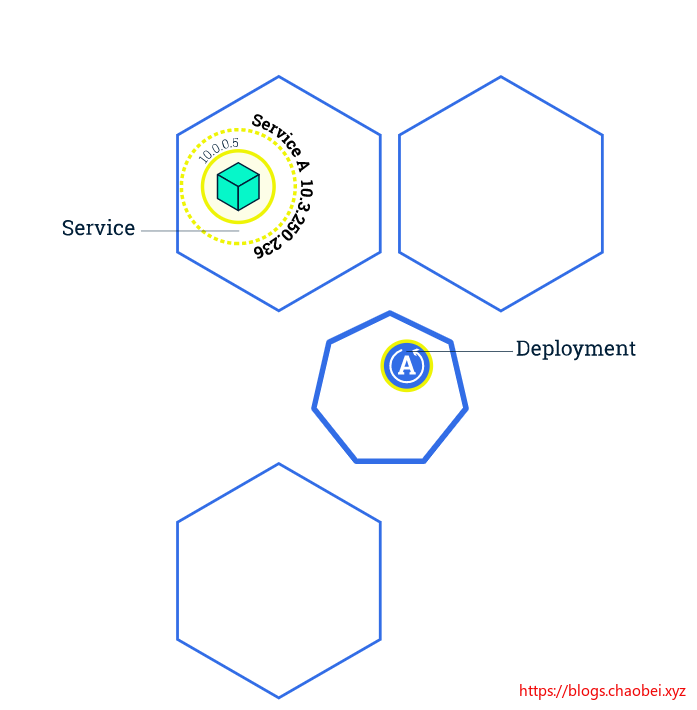
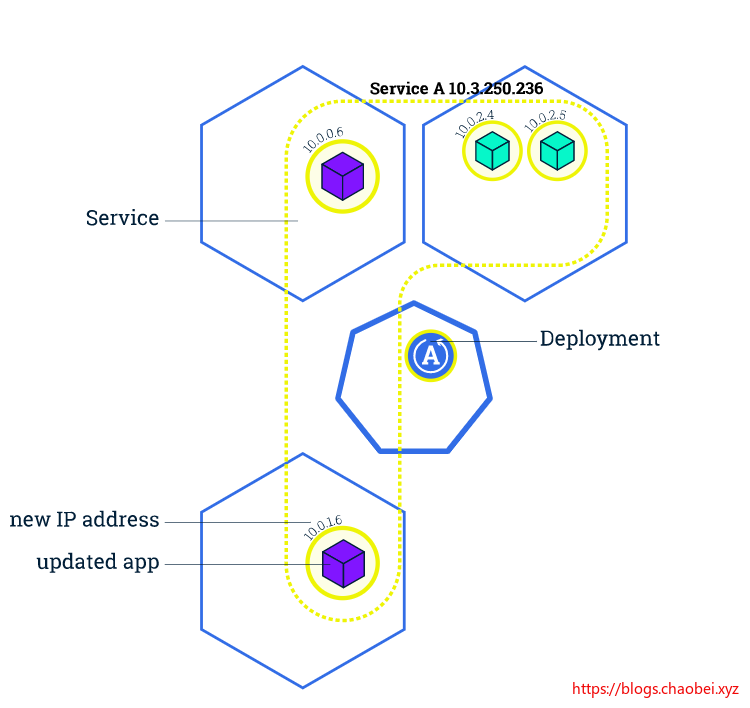
服务使用标签和选择器来匹配一组PODS
标签是附加在对象上的键值对,可以以任何方式使用。
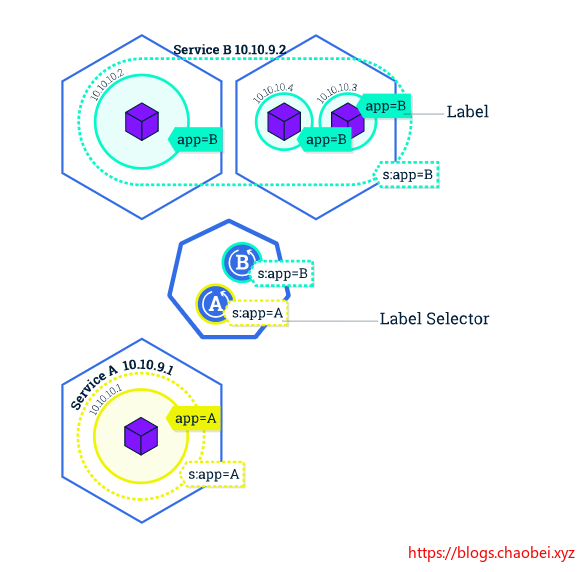
这个图里面我们可以发现,在管理节点里面部署了两个应用。每个应用分别将标签app=B app=A 的所有POD 整理起来组成服务。
创建服务
kubectl get pods查看当前所有的PODkubectl get service查看当前所有服务
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mynode-5479db549c-lgtfv 1/1 Running 0 56m
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h
kubectl expose deployment mynode --type=NodePort --port=80 将一个deployment 通过服务的方式暴露出去,暴露端口80,也就是我们容器内部的80端口,mynode 是我们已经部署过的一个应用(资源)。
$ kubectl.exe get service mynginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mynode NodePort 10.111.8.25 <none> 80:30857/TCP 5s
这里发现其将我们的服务暴露到了30857下。
此服务的类型:ClusterIP、NodePort、LoadBalancer或ExternalName。默认值为“ClusterIP”。
$ kubectl get deployment NAME READY UP-TO-DATE AVAILABLE AGE
mynode 1/1 1 1 64m
nodePort
外部机器可访问的端口。 比如一个Web应用需要被其他用户访问,那么需要配置type=NodePort,而且配置nodePort=30001,那么其他机器就可以通过浏览器访问scheme://node:30001访问到该服务,例如http://node:30001。 例如MySQL数据库可能不需要被外界访问,只需被内部服务访问,那么不必设置NodePort
targetPort
容器的端口(最根本的端口入口),与制作容器时暴露的端口一致(DockerFile中EXPOSE),例如docker.io官方的nginx暴露的是80端口。 docker.io官方的nginx容器的DockerFile参考https://github.com/nginxinc/docker-nginx
port
kubernetes中的服务之间访问的端口,尽管mysql容器暴露了3306端口(参考https://github.com/docker-library/mysql/的DockerFile),但是集群内其他容器需要通过33306端口访问该服务,外部机器不能访问mysql服务,因为他没有配置NodePort类型
参考:https://www.cnblogs.com/devilwind/p/8881201.html
通过标签的方式查询
kubectl describe <type> <name> 可以查询到我们想看的信息,若不填写名称,则默认管理节点。
$ kubectl describe deployment
Name: mynode
Namespace: default
CreationTimestamp: Sun, 16 Feb 2020 12:52:50 +0800
Labels: app=mynode
.....
可以看到我们部署的资源的标签 app=mynode
kubectl get pods -l app=mynode 加入-l 进行标签查询。
删除服务
kubectl delete service <name> 通过名称删除一个服务
删除 POD deployment
先删除POD 而后删除 Deployment
## 查看所有POD
kubectl get pods
## 查看所有部署
kubectl get deployment
kubectl delete pod <name>
kubectl delete deployment <name>
参考
- 官网:https://kubernetes.io/docs/tutorials/kubernetes-basics/deploy-app/deploy-intro/
- 例子:https://minikube.sigs.k8s.io/docs/examples/
遇到的坑
未使用国内镜像仓库
E0215 13:06:36.509035 15568 cache.go:62] save image to file "gcr.io/k8s-minikube/storage-provisioner:v1.8.1" -> "C:\\Users\\17639\\.minikube\\cache\\images\\gcr.io\\k8s-minikube\\storage-provisioner_v1.8.1" failed: nil image for gcr.io/k8s-minikube/storage-provisioner:v1.8.1: Get https://gcr.io/v2/: dial tcp [2404:6800:4008:c03::52]:443: connectex: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond.
原文出处:https://www.cnblogs.com/ChromeT/p/12316817.html
今天关于DOCKER 学习笔记 9 Kubernetes (K8s) 弹性伸缩容器 下和rancher 弹性伸缩的分享就到这里,希望大家有所收获,若想了解更多关于docker kubernetes Swarm 容器编排 k8s CICD 部署 麦兜、Docker Kubernetes 容器扩容与缩容、Docker Kubernetes(K8s)简介、DOCKER 学习笔记9 Kubernetes (K8s) 生产级容器编排 上等相关知识,可以在本站进行查询。
本文标签:




