想了解找出正则表达式在Python字符串中匹配多少次的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于python正则查找所有匹配的字符串的相关问题,此外,我们还将为您介绍关于python–匹
想了解找出正则表达式在Python字符串中匹配多少次的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于python正则查找所有匹配的字符串的相关问题,此外,我们还将为您介绍关于python – 匹配多个正则表达式组并删除它们、python – 正则表达式匹配字符串上的正则表达式匹配返回无、python 提取字符串中的指定字符 正则表达式、python 正则表达式与JSON字符串的新知识。
本文目录一览:- 找出正则表达式在Python字符串中匹配多少次(python正则查找所有匹配的字符串)
- python – 匹配多个正则表达式组并删除它们
- python – 正则表达式匹配字符串上的正则表达式匹配返回无
- python 提取字符串中的指定字符 正则表达式
- python 正则表达式与JSON字符串
")
找出正则表达式在Python字符串中匹配多少次(python正则查找所有匹配的字符串)
有没有办法找出Python字符串中某个正则表达式的匹配项?例如,如果我有字符串"It actually happened when it actedout of turn."
我想知道"t a"字符串中出现了多少次。在该字符串中,"t a"出现两次。我希望函数告诉我它出现了两次。这可能吗?
答案1
小编典典现有的基于解决方案的解决方案适用于findall非重叠匹配(毫无疑问是最佳的,可能是因为匹配数量巨大),尽管诸如sum(1 for m inre.finditer(thepattern,thestring))(避免在您只关心计数时实现列表)的替代方案也很可能。某种特质将使用subn并忽略结果字符串…:
def countnonoverlappingrematches(pattern, thestring): return re.subn(pattern, '''', thestring)[1]如果您只想数数最多(例如)100场比赛,那么后一种想法的唯一真正优势就将出现。那么re.subn(pattern, '''', thestring,100)[1]可能很实际(无论有100个匹配项,还是返回1000个,甚至更大的数字,都返回100)。
计算 重叠 匹配数需要您编写更多代码,因为所讨论的内置函数都集中在非重叠匹配上。还有一个定义问题,例如,pattern是''a+''and
thestring是''aa'',您会认为这只是一个匹配,还是三个(第一个a,第二个,它们两个),还是…?
举例来说,假设您希望 从字符串的不同位置开始进行 重叠的匹配(然后将为上一段中的示例提供两次匹配):
def countoverlappingdistinct(pattern, thestring): total = 0 start = 0 there = re.compile(pattern) while True: mo = there.search(thestring, start) if mo is None: return total total += 1 start = 1 + mo.start()请注意,你必须编译模式进入在这种情况下RE对象:函数re.search不接受一个start参数(起始搜索位置)的方式 方法search呢,所以你必须要切片thestring,当您去-绝对比下一次搜索从下一个可能的不同起点开始要付出更多的努力,这就是我在此功能中所做的。

python – 匹配多个正则表达式组并删除它们
LINE: 1 TOKENKIND: somedata TOKENKIND: somedata LINE: 2 TOKENKIND: somedata LINE: 3
等等…
我想要做的是删除LINE:和行号以及TOKENKIND:所以我只剩下一个字符串,其中包含’somedata somedate somedata …’
我正在使用Python来执行此操作,使用正则表达式(我不确定是否正确)来匹配我要删除的文件的位.
我的问题是,如何让Python匹配多个正则表达式组并忽略它们,将我的正则表达式与我的输出字符串不匹配的任何内容添加到我的输出字符串中?我当前的代码如下所示:
import re
import sys
ignoredTokens = re.compile('''
(?P<WHITESPACE> \s+ ) |
(?P<LINE> LINE:\s[0-9]+ ) |
(?P<TOKEN> [A-Z]+: )
''',re.VERBOSE)
tokenList = open(sys.argv[1],'r').read()
cleanedList = ''
scanner = ignoredTokens.scanner(tokenList)
for line in tokenList:
match = scanner.match()
if match.lastgroup not in ('WHITESPACE','LINE','TOKEN'):
cleanedList = cleanedList + match.group(match.lastindex) + ' '
print cleanedList
解决方法
import re
x = '''LINE: 1
TOKENKIND: somedata
TOKENKIND: somedata
LINE: 2
TOKENKIND: somedata
LINE: 3'''
junkre = re.compile(r'(\s*LINE:\s*\d*\s*)|(\s*TOKENKIND:)',re.DOTALL)
print junkre.sub('',x)

python – 正则表达式匹配字符串上的正则表达式匹配返回无
我正在为一个subreddit制作一个小机器人.为此,我从trakt.tv中删除了一些数据.报废后我跑了一点正则表达式
obituarySecondary = re.match(r"^([\w \,\.\"]+,\d{4} ?- ?\w+ \d+,?\d{4})",obituaryRaw).group(0)
我得到了Nathaniel Fisher,Sr.1943-2000所需的结果
现在我在obituarySecondary上运行了另一个正则表达式
timeline = "\n\n" + re.match(r'(\d{4} ?- ?\d{4})',obituarySecondary).group(0)
但这总是回归.
我在https://regex101.com/上运行了相同的正则表达式以确保我正确处理并且字符串匹配,但不在我的系统上.
解决方法
有关更多详细信息,请查看this StackOverflow问题

python 提取字符串中的指定字符 正则表达式
例1:
字符串: ''湖南省长沙市岳麓区麓山南路麓山门''
提取:湖南,长沙
在不用正则表达式的情况下:
address = ''湖南省长沙市岳麓区麓山南路麓山门''
address1 = address.split(''省'') # 用“省”字划分字符串,返回一个列表
address2 = address1[1].split(''市'') # 用“市”字划分address1列表的第二个元素,返回一个列表
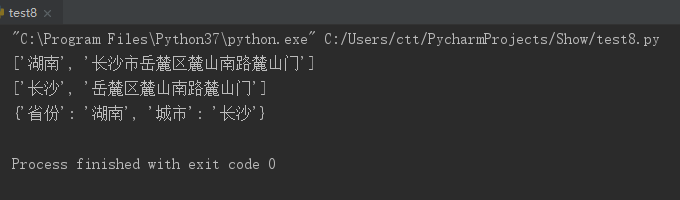
print(address1) # 输出 [''湖南'', ''长沙市岳麓区麓山南路麓山门'']
print(address2) # 输出 [''长沙'', ''岳麓区麓山南路麓山门'']
data = {
''省份'': address1[0],
''城市'': address2[0]
}
print(data) # 输出 {''省份'': ''湖南'', ''城市'': ''长沙''}
输出结果:
例二:
从一段文字中提取指定两段字符中间的字符
字符串 = ‘’师资力量学校现有教职工近4000余人,其中专任教师1800余人,教授、副教授1100余人,中国科学院院士3名,中国工程院院士3名,双聘两院院士2名,加拿大工程院院士1名,发展中国家科学院院士1名,“千人计划”53人,“万人计划”学者13人、“长江学者”15人,国家杰出青年基金获得者21人,国务院学位委员会学科评议组成员6人,入选国家百千万人才工程(“百千万人才工程”一二层次人选、新世纪百千万人才工程国家级人选)23人、国家创新人才推进计划中青年创新领军人才2人,教育部新世纪优秀人才支持计划入选者134人,湖南省“百人计划”学者64人,湖南省“芙蓉学者奖励计划”特聘教授、讲座教授17人,享受政府特殊津贴专家201人,国家教学名师4人,国家自然科学基金创新研究群体3个,教育部“长江学者与创新团队发展计划”创新团队8个,湖南省自然科学基金创新研究群体11个。(数据截止日期:2017年01月) [31] “
指定两段字符:“长江学者”与“人”,
目标字符:中间的数字“15”
正则式:
- (.+?) 惰性匹配
- \d+ 匹配多个数字
import re
s = "师资力量学校现有教职工近4000余人,其中专任教师1800余人,教授、副教授1100余人,中国科学院院士3名,中国工程院院士3名," \
"双聘两院院士2名,加拿大工程院院士1名,发展中国家科学院院士1名,“千人计划”53人,“万人计划”学者13人、“长江学者”15人," \
"国家杰出青年基金获得者21人,国务院学位委员会学科评议组成员6人,入选国家百千万人才工程(“百千万人才工程”一二层次人选、" \
"新世纪百千万人才工程国家级人选)23人、国家创新人才推进计划中青年创新领军人才2人,教育部新世纪优秀人才支持计划入选者134人," \
"湖南省“百人计划”学者64人,湖南省“芙蓉学者奖励计划”特聘教授、讲座教授17人,享受政府特殊津贴专家201人,国家教学名师4人," \
"国家自然科学基金创新研究群体3个,教育部“长江学者与创新团队发展计划”创新团队8个,湖南省自然科学基金创新研究群体11个" \
"。(数据截止日期:2017年01月) [31] " # 由于字符串过长,在编译器中会要求换行,字符“\”为换行后自动添加的,不影响字符串本身
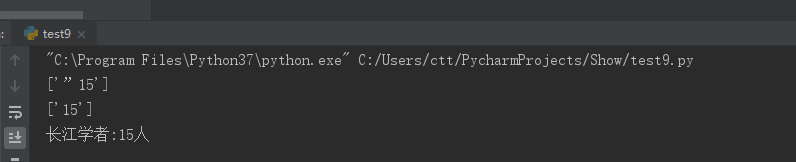
n = re.findall(r"长江学者(.+?)人", s) # 正则表达式匹配长江学者人数 提取“长江学者”和其后的“人”之间的字符,返回一个列表
print(n)
num = re.findall(''\d+'', str(n)) # 正则表达式提取数字,返回一个列表
print(num)
num = ''长江学者:''+num[0]+''人'' # 重新构建一个字符串
print(num)
运行结果:

python 正则表达式与JSON字符串
[TOC]
手册地址:
https://www.runoob.com/regexp/regexp-metachar.html
在线工具:
http://c.runoob.com/front-end/854
正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配(一个字符串是否与我们所设定这样的字符序列相匹配)。
快速检索文本,实现一些替换文本的操作
- 检查一串数字是否电话号码
- 检测一个字符串是否是email
- 把一个文本里指定的单词替换为另外一个单词
注意: 能使用底层包里自带的函数解决问题(string,strings,strcnov),首先使用库函数,其次再选择正则表达式(不好理解).
概括单字符集 匹配单字符

import re
# 概括单字符集
a = ''Python 11\t11Java&678p\nh\rp''
# \d 匹配任意数字,等价于 [0-9]。 \D 匹配任意非数字
# \w 匹配数字字母下划线 \W 匹配非数字字母下划线
# \s 匹配任意空白字符,等价于 [\t\n\r\f]。 \S 匹配任意非空字符
# . 匹配换行符之外\n的其它所有字符 - 匹配范围 a-zA-Z0-9
r1 = re.findall(''\d'',a)
r2 = re.findall(''[0-9]'',a) #匹配任何数字。类似于 [0123456789]
w1 = re.findall(''\D'',a)
w2 = re.findall(''[^0-9]'',a) #匹配除了数字外的字符
print(r1) #[''1'', ''1'', ''1'', ''1'', ''6'', ''7'', ''8'']
print(r2) #[''1'', ''1'', ''1'', ''1'', ''6'', ''7'', ''8'']
print(w1) #[''P'', ''y'', ''t'', ''h'', ''o'', ''n'', '' '', ''\t'', ''J'', ''a'', ''v'', ''a'', ''&'', ''p'', ''\n'', ''h'', ''\r'', ''p'']
print(w2) #[''P'', ''y'', ''t'', ''h'', ''o'', ''n'', '' '', ''\t'', ''J'', ''a'', ''v'', ''a'', ''&'', ''p'', ''\n'', ''h'', ''\r'', ''p'']
x1 = re.findall(''\w'',a)
x2 = re.findall(''[A-Za-z0-9_]'',a) #匹配数字字母下划线
x3 = re.findall(''\W'',a) #非匹配数字字母下划线
x4 = re.findall(''[^A-Za-z0-9_]'',a)
print(x1) # [''P'', ''y'', ''t'', ''h'', ''o'', ''n'', ''1'', ''1'', ''1'', ''1'', ''J'', ''a'', ''v'', ''a'', ''6'', ''7'', ''8'', ''p'', ''h'', ''p'']
print(x2) # [''P'', ''y'', ''t'', ''h'', ''o'', ''n'', ''1'', ''1'', ''1'', ''1'', ''J'', ''a'', ''v'', ''a'', ''6'', ''7'', ''8'', ''p'', ''h'', ''p'']
print(x3) #['' '', ''\t'', ''&'', ''\n'', ''\r'']
print(x4) #['' '', ''\t'', ''&'', ''\n'', ''\r'']
y1 = re.findall(''\s'',a)
y2 = re.findall(''\S'',a)
print(y1) #['' '', ''\t'', ''\n'', ''\r'']
print(y2) #[''P'', ''y'', ''t'', ''h'', ''o'', ''n'', ''1'', ''1'', ''1'', ''1'', ''J'', ''a'', ''v'', ''a'', ''&'', ''6'', ''7'', ''8'', ''p'', ''h'', ''p'']
匹配字符集
import re
a = ''c0c++7Java8c9Python6Javascript''
# 使用python的内置函数
print(a.find(''Python'')>-1) # 输出 True 如果没有匹配到返回-1,否则返回第一个匹配到的位置
print(''Python'' in a) # 输出 True
# 使用正规表达式
r=re.findall(''Python'',a) #[''Python'']
print(r)
if len(r)>0:
print(''ok'')
else:
print(''no'')
# 输出:
# True
# True
# [''Python'']
# ok
普通字符与元字符
- 普通字符 ''Python''
- 元字符
\d
正则表达式 - 元字符
下表包含了元字符的完整列表以及它们在正则表达式上下文中的行为:
<a href="https://www.runoob.com/regexp/regexp-metachar.html" target="_blank">https://www.runoob.com/regexp/regexp-metachar.html</a>
元字符和普通的字符的混用
a = ''abc , acc , adc , aec , afc , ahc''
- 匹配字符串中间是cf的
- 匹配字符串中间 不是cf的
- 匹配字符串中间字母 是c-f的
- 普通字符(方括号两边的)a和c是用来定界的,方括号里面的cf元字符是用来匹配的规则,cf是c或f的关系
import re
# 匹配字符串中间是cf的
a = ''abc , acc , adc , aec , afc , ahc''
r = re.findall(''a[cf]c'',a) #普通字符a和c是用来定界的,cf元字符是用来匹配的
print(r) #[''acc'', ''afc'']
# 匹配字符串中间 不是cf的
r2 = re.findall(''a[^cf]c'',a)
print(r2) #[''abc'', ''adc'', ''aec'', ''ahc'']
# 匹配字符串中间字母 是c-f的
r3 = re.findall(''a[c-f]c'',a)
print(r3) #[''acc'', ''adc'', ''aec'', ''afc'']
数量词{整数|*|+|?} 匹配多少次
| 符号 | 含义 |
|---|---|
| 整数 | 匹配指定长度的字母 |
| * | 匹配0次或者无限多次 |
| + | 匹配1次或者无限多次 |
| ? | 匹配0次或者1次 可以用来过滤单词后面不要的字母,去重 |

-
{整数} 匹配指定长度的字母
import re # 匹配指定长度的字母 a = ''Python 111\t11Java&678php66javascript\nh\rp'' r1 =re.findall(''[A-Za-z]{3}'',a) # 每次匹配3个长度的字母 print(r1) #[''Pyt'', ''hon'', ''Jav'', ''php'', ''jav'', ''asc'', ''rip''] -
{*} 匹配0次或者无限多次
-
{+} 匹配1次或者无限多次
-
{?} 匹配0次或者1次 可以用来过滤单词后面不要的字母,去重
import re # 数量词 a = ''pytho0python1pythonn2'' # * 匹配0次或者无限多次 r1 = re.findall(''python*'',a) print(r1) # 输出 [''pytho'', ''python'', ''pythonn''] # + 匹配1次或者无限多次 r2 = re.findall(''python+'',a) print(r2) # 输出 [''python'', ''pythonn''] # ? 匹配0次或者1次 r3 = re.findall(''python?'',a) print(r3) # 输出 [''pytho'', ''python'', ''python'']
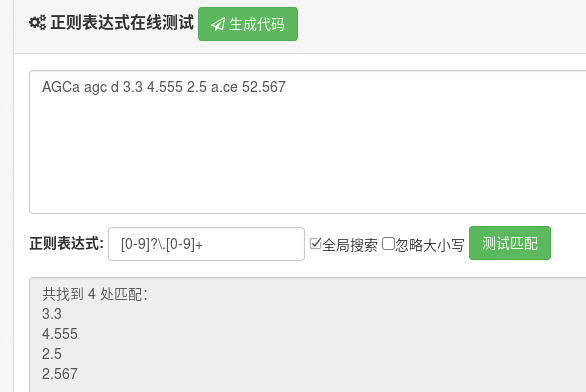
[0-9]?\.[0-9]+ 小数点前匹配0到1次,\是转义小数点,小数点后匹配1次或者无限多次
?在非贪婪模式和数量词使用时是不同的意义
- ?在
非贪婪模里是用来转换贪婪与非贪婪模式的 - ?在
数量词里是表示匹配0次或者1次
a = ''pytho0python1pythonn2''
# ? 在数量词中 匹配0次或者1次
r1 = re.findall(''python?'',a)
print(r1) # 输出 [''pytho'', ''python'', ''python'']
# ?在`非贪婪模`里
r2 = re.findall(''python{1,2}?'',a)
print(r2) #[''python'', ''python'']
# `贪婪模`
r2 = re.findall(''python{1,2}'',a)
print(r2) #[''python'', ''pythonn'']
贪婪模式 匹配指定长度的字符串
import re
# 贪婪模式
a = ''Python 111\t11Java&678php66javascript\nh\rp''
# \d 匹配任意数字,等价于 [0-9]。 \D 匹配任意非数字
# \w 匹配数字字母下划线 \W 匹配非数字字母下划线
# \s 匹配任意空白字符,等价于 [\t\n\r\f]。 \S 匹配任意非空字符
r1 =re.findall(''[A-Za-z]{3,10}'',a) #贪婪模式 每次匹配3-10个长度的字母
r2 =re.findall(''[A-Za-z]{3,}'',a) #贪婪模式 每次匹配3到任意个长度的字母
print(r1) #[''Python'', ''Java'', ''php'', ''javascript'']
print(r1) #[''Python'', ''Java'', ''php'', ''javascript'']
非贪婪模式 匹配指定长度的字符串
花括号后加上?号表示非贪婪模式
import re
# 非贪婪模式
a = ''Python 111\t11Java&678php66javascript\nh\rp''
# \d 匹配任意数字,等价于 [0-9]。 \D 匹配任意非数字
# \w 匹配数字字母下划线 \W 匹配非数字字母下划线
# \s 匹配任意空白字符,等价于 [\t\n\r\f]。 \S 匹配任意非空字符
r1 =re.findall(''[A-Za-z]{3,10}?'',a) # ?非贪婪模式 每次匹配3个长度的字母
r2 =re.findall(''[A-Za-z]{3,}?'',a) # ?非贪婪模式 每次匹配3任意个长度的字母
print(r1) #[''Pyt'', ''hon'', ''Jav'', ''php'', ''jav'', ''asc'', ''rip'']
print(r1) #[''Pyt'', ''hon'', ''Jav'', ''php'', ''jav'', ''asc'', ''rip'']
边界匹配
- ^ 边界的开始
- $ 边界的结束
# 边界匹配
import re
qq = ''100000001''
# 4~8
# ^边界的开始 $边界的结束
r = re.findall(''^\d{4,8}$'',qq)
print(r) #打印 []
r1 = re.findall(''^000'',qq)
print(r1) #打印 [] qq不是以0开头的,匹配不到
r2 = re.findall(''000$'',qq) #qq不是以0结束的,匹配不到
print(r2) #打印 []
组的概念

import re
a = ''PythonPythonPythonPythonPython''
# a里是否有三个Python
##方法一
r = re.findall(''PythonPythonPython'',a)
print(r) #打印 [''PythonPythonPython'']
##方法二
r2 = re.findall(''(Python){3}'',a) #括号表示组,是并且的关系,匹配时可以有多个组如,''(Python){3}(js)'',
print(r2) #打印 [''Python'']
##方法三
r3 = re.findall(''Python{3}'',a) #这种字法只能匹配单个字符(如:a) 不能匹配字符集(如单词:Python)
print(r3) #打印 []
参数匹配
第三个参数,|表示多种模式叠加
.点匹配换行符之外\n的其它所有字符- re.I 不区分大小写
- re.S 表示可以让
.点号匹配包括\n在内的所有字符
import re
a = ''PythonC#\nJavaPHP''
# 匹配出C#\n
r = re.findall(''c#.'',a)
print(r) #打印 []
r1 = re.findall(''c#.'', a , re.I)
print(r1) #打印 []
# .匹配换行符之外\n的其它所有字符
# re.I 不区分大小写
# re.S 表示.号匹配包括\n在内的所有字符
r1 = re.findall(''c#.'', a , re.I | re.S)
print(r1) #打印 [''C#\n'']
替换
- 方法一:内置replace函数
- 方法二:正则普通替换
- 方法三:正则用函数替换
import re
a = ''PythonC#JavaC#PHPC#''
#替换C#为GO
##方法一:内置replace函数
#字符串是不能改变的,所以要重新给变量赋值
a1 = a.replace(''C#'',''GO'',2) #参数 老的 新的 替换的次数
print(a1) #输出 PythonGOJavaGOPHPC#
##方法二:正则普通替换
a2 = re.sub(''C#'',''GO'',a,1) #参数(匹配的规则)老的 新的 原字符串 替换的次数
print(a2) #输出 PythonGOJavaC#PHPC#
##方法三:正则用函数替换
def couvert(value):
print(value)
# 输出 匹配到了三次,所以输出三次
# <re.Match object; span=(6, 8), match=''C#''>
# <re.Match object; span=(12, 14), match=''C#''>
# <re.Match object; span=(17, 19), match=''C#''>
# 每次匹配时拿到match里的值
matched = value.group()
return ''!!'' + matched + ''!!'' # 返回每次处理后的match里的值
a3 = re.sub(''C#'',couvert,a,3)
print(a3) #输出 Python!!C#!!Java!!C#!!PHP!!C#!!
关于找出正则表达式在Python字符串中匹配多少次和python正则查找所有匹配的字符串的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于python – 匹配多个正则表达式组并删除它们、python – 正则表达式匹配字符串上的正则表达式匹配返回无、python 提取字符串中的指定字符 正则表达式、python 正则表达式与JSON字符串的相关知识,请在本站寻找。
本文标签:




