在本文中,我们将给您介绍关于将phpregex转换为javaregex的详细内容,并且为您解答php转成java的相关问题,此外,我们还将为您提供关于C++11正则表达式详解(regex_match、
在本文中,我们将给您介绍关于将php regex转换为java regex的详细内容,并且为您解答php转成java的相关问题,此外,我们还将为您提供关于C++11正则表达式详解(regex_match、regex_search和regex_replace)、C语言用regcomp、regexec、regfree和regerror函数实现正则表达式校验、Haskell的Text.Regex.subRegex使用TDFA实现?、Javascript lastIndex regex属性为PHP regex的知识。
本文目录一览:- 将php regex转换为java regex(php转成java)
- C++11正则表达式详解(regex_match、regex_search和regex_replace)
- C语言用regcomp、regexec、regfree和regerror函数实现正则表达式校验
- Haskell的Text.Regex.subRegex使用TDFA实现?
- Javascript lastIndex regex属性为PHP regex
")
将php regex转换为java regex(php转成java)
有人可以帮助我将php regex转换为java regex吗?
太好了,如果您能帮助我,我将不胜感激,因为我对正则表达式的了解不强。
$str = preg_replace ( ''{(.)\1+}'', ''$1'', $str )$str = preg_replace ( ''{[ \''-_\(\)]}'', '''', $str )我如何理解preg_replacephp中的函数与replaceAllJava中的函数相同?。因此在Java代码中将是这样。
str = str.replaceAll("{(.)\1+}", "$1");str = str.replaceAll("{[ \''-_\(\)]}", "");但是此代码无法正常工作,因为我怎么知道php中的regex与java不同。
拜托,有人帮我!非常感谢))
更新
最终结果是
str = str.replaceAll("(.)\\1+", "$1");str = str.replaceAll("[ ''-_()]", "");答案1
小编典典对于此PHP正则表达式:
$str = preg_replace ( ''{(.)\1+}'', ''$1'', $str );$str = preg_replace ( ''{[ \''-_\(\)]}'', '''', $str )在Java中:
str = str.replaceAll("(.)\\1+", "$1");str = str.replaceAll("[ ''-_\\(\\)]", "");我建议您提供您的输入和预期的输出,然后您将可以在PHP和/或Java中获得更好的答案。
")
C++11正则表达式详解(regex_match、regex_search和regex_replace)
在C++11中引入了正则表达式。
字符规则
先来了解一下这个字符的含义吧。
| 字符 | 描述 |
|---|---|
| \ | 转义字符 |
| $ | 匹配字符行尾 |
| * | 匹配前面的子表达式任意多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次 |
| {m} | 匹配确定的m次 |
| {m,} | 匹配至少m次 |
| {m,n} | 最少匹配m次,最大匹配n次 |
| 字符 | 描述 |
|---|---|
| . | 匹配任意字符 |
| x|y | 匹配x或y |
| [xyz] | 字符集合,匹配包含的任意一个字符 |
| [^xyz] | 匹配未包含的任意字符 |
| [a-z] | 字符范围,匹配指定范围内的任意字符 |
| [^a-z] | 匹配任何不在指定范围内的任意字符 |
头文件:#include
regex_match
全文匹配,即要求整个字符串符合匹配规则,返回true或false
匹配“四个数字-一个或俩个数字”
#include <iostream>
#include <regex>
using namespace std;
int main()
{
string str;
cin >> str;
//\d 表示匹配数字 {4} 长度4个 \d{1,2}表示匹配数字长度为1-2
cout << regex_match(str, regex("\\d{4}-\\d{1,2}"));
return 0;
}匹配邮箱 “大小写字母或数字@126/163.com”
int main()
{
string str;
cout << "请输入邮箱:" << endl;
while (cin >> str)//匹配邮箱
{
if (true == regex_match(str, regex("[a-zA-Z0-9]+@1(26|63)\\.com")))
{
break;
}
cout << "输入错误,请重新输入:" << endl;
}
cout << "输入成功!" << endl;
return 0;
}regex_search
搜索匹配,即搜索字符串中存在符合规则的子字符串。
用法一:匹配单个
#include <iostream>
#include <regex>
#include <string>
using namespace std;
int main()
{
string str = "hello2019-02-03word";
smatch match;//搜索结果
regex pattern("(\\d{4})-(\\d{1,2})-(\\d{1,2})");//搜索规则 ()表示把内容拿出来
if (regex_search(str, match, pattern))
{ //提取 年 月 日
cout << "年:" << match[1] << endl;
cout << "月:" << match[2] << endl;
cout << "日:" << match[3] << endl;
//下标从1开始 下标0存的是符合这个搜索规则的起始位置和结束位置
}
return 0;
}用法二:匹配多个
#include <iostream>
#include <regex>
#include <string>
using namespace std;
int main()
{
//匹配多个符合要求的字符串
string str = "2019-08-07,2019-08-08,2019-08-09";
smatch match;
regex pattern("(\\d{4})-(\\d{1,2})-(\\d{1,2})");
string::const_iterator citer = str.cbegin();
while (regex_search(citer, str.cend(), match, pattern))//循环匹配
{
citer = match[0].second;
for (size_t i = 1; i < match.size(); ++i)
{
cout << match[i] << " ";
}
cout << endl;
}
return 0;
}regex_replace
替换匹配,即可以将符合匹配规则的子字符串替换为其他字符串。
将字符串中的-替换为/
#include <iostream>
#include <regex>
using namespace std;
int main()
{
//替换不会修改原串
cout << regex_replace("2019-08-07", regex("-"), "/") << endl;
return 0;
}匹配以逗号分隔的字符串(\S表示匹配任意显示字符)

使用正则表达式将所有信息批处理为sql的语句

使用正则表达式1999-10-7 修改为 10/7/1999
先匹配上,再拿小括号获取值 然后替换

然后就可以放在程序中
int main()
{
string str;
cin >> str;
cout << regex_replace(str, regex("(\\d{4})-(\\d{1,2})-(\\d{1,2})"), "$2/$3/$1");
return 0;
}将字符串中的/删掉

总结
到此这篇关于C++11正则表达式(regex_match、regex_search和regex_replace)的文章就介绍到这了,更多相关C++11正则表达式内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- 正则表达式简介及在C++11中的简单使用教程
- c++11中regex正则表达式示例简述

C语言用regcomp、regexec、regfree和regerror函数实现正则表达式校验
前言
首先,祝大家国庆假期玩的嗨皮!可能有的人已经在回家的路上了,是不是都看不到我的真挚祝福了?
C语言对于一些东西的封装比较少,比如正则表达式,但速度快一直使它立于不败之地,今天就要介绍如何用C封装。
一、正则表达式
1、介绍
应该都听过正则吧?主要应用在字符串匹配,而且它是通用的,各种语言都支持。例如可以用它匹配IP地址、邮箱等。举个例子说明一下正则有啥用:
例如,我在的公司,页面用PHP,后台用C,当添加用户邮箱时,我们老大就要求:PHP和C都要对用户输入的用户邮箱进行校验,这时正则表达式就派上用场了。
2、grep命令
我会用grep进行简单的举例,所以要简单介绍一下。
grep是一种查找过滤工具,正则表达式在grep中用来查找符合模式的字符串。其实正则表达式还有一个重要的应用是验证用户输入是否合法,例如用户通过网页表单提交自己的email地址,就需要用程序验证一下是不是合法的email地址,这个工作可以在网页的Javascript中做,也可以在网站后台的程序中做,例如PHP、Perl、Python、Ruby、Java或C,所有这些语言都支持正则表达式,可以说,目前不支持正则表达式的编程语言实在很少见。
egrep相当于grep -E,表示采用Extended正则表达式语法。
注意grep找的是包含某一模式的行,而不是完全匹配某一模式的行。
3、基本语法
对于正则表达式的语法,我只列出比较常见的,基本就够用了,如果有兴趣的可以再去网上学习,去深入了解。
字符类

数量限定符

位置限定符
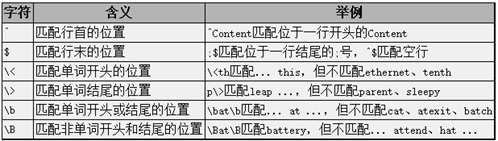
举例:查找IP的正则
用^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$查找
其它特殊字符

4、分类
大致分为两类:Basic正则和Extended正则
区别:
以上介绍的是grep正则表达式的Extended规范,Basic规范也有这些语法,只是字符?+{}|()应解释为普通字符,要表示上述特殊含义则需要加\转义。如果用grep而不是egrep,并且不加-E参数,则应该遵照Basic规范来写正则表达式。
二、正则表达式相关函数
C语言处理正则表达式常用的函数有regcomp()、regexec()、regfree()和regerror()
C语言中使用正则表达式一般分为三步:
- 编译正则表达式 regcomp()
- 匹配正则表达式 regexec()
- 释放正则表达式 regfree()
下边将对三个函数的详细解释。
1、regcomp函数
功能:这个函数把指定的正则表达式pattern编译成一种特定的数据格式compiled,这样可以使匹配更有效。
原型:int regcomp(regex_t *preg, const char *regex, int cflags);
参数说明:
regex_t 是一个结构体数据类型,用来存放编译后的正则表达式,它的成员re_nsub 用来存储正则表达式中的子正则表达式的个数,子正则表达式就是用圆括号包起来的部分表达式。
参数regex: 是指向我们写好的正则表达式的指针。
参数cflags: 有如下4个值或者是它们或运算(|)后的值:
REG_EXTENDED 以功能更加强大的扩展正则表达式的方式进行匹配。
REG_ICASE 匹配字母时忽略大小写。
REG_NOSUB 不用存储匹配后的结果,只返回是否成功匹配。如果设置该标志位,那么在regexec(在下边介绍)将忽略nmatch和pmatch两个参数。
REG_NEWLINE 识别换行符,这样''$''就可以从行尾开始匹配,''^''就可以从行的开头开始匹配。
2、regexec函数
功能:函数regexec 会使用这个数据在目标文本串中进行模式匹配。
原型:int regexec(const regex_t *preg, const char *string, size_t nmatch,regmatch_t pmatch[], int eflags);
先来介绍下参数4中的regmatch_t结构体:
regmatch_t 是一个结构体数据类型,在regex.h中定义:
typedef struct {
regoff_t rm_so;
regoff_t rm_eo;
} regmatch_t;
成员rm_so 存放匹配文本串在目标串中的开始位置,rm_eo 存放结束位置。通常我们以数组的形式定义一组这样的结构。
参数说明:
preg 是已经用regcomp函数编译好的正则表达式。
string 是目标文本串。
nmatch 是regmatch_t结构体数组的长度。
matchptr regmatch_t类型的结构体数组,存放匹配文本串的位置信息。
eflags 有两个值:
REG_NOTBOL 让特殊字符^无作用
REG_NOTEOL 让特殊字符$无作用
3、regfree函数
功能:可以用这个函数清空regex_t结构体的内容
原型:void regfree(regex_t *preg);
4、regerror函数
功能:当执行regcomp 或者regexec 产生错误的时候,就可以调用这个函数而返回一个包含错误信息的字符串。
原型:size_t regerror(int errcode, const regex_t *preg, char *errbuf,size_t errbuf_size);
参数说明:
errcode 是由regcomp 和 regexec 函数返回的错误代号。
preg 是已经用regcomp函数编译好的正则表达式,这个值可以为NULL。
errbuf 指向用来存放错误信息的字符串的内存空间。
errbuf_size 指明buffer的长度,如果这个错误信息的长度大于这个值,则regerror 函数会自动截断超出的字符串,但他仍然会返回完整的字符串的长度。所以我们可以用如下的方法先得到错误字符串的长度。
三、程序示例
输入两个参数,第一个参数:正则表达式,第二个参数:字符串,校验是否匹配,程序如下:


#include <sys/types.h>
#include <regex.h>
#include <stdio.h>
int main(int argc, char ** argv)
{
if (argc != 3) {
printf("Usage: %s RegexString Text\n", argv[0]);
return 1;
}
const char * pregexstr = argv[1];
const char * ptext = argv[2];
regex_t oregex;
int nerrcode = 0;
char szerrmsg[1024] = {0};
size_t unerrmsglen = 0;
if ((nerrcode = regcomp(&oregex, pregexstr, REG_EXTENDED|REG_NOSUB)) == 0) {
if ((nerrcode = regexec(&oregex, ptext, 0, NULL, 0)) == 0) {
printf("%s matches %s\n", ptext, pregexstr);
regfree(&oregex);
return 0;
}
}
unerrmsglen = regerror(nerrcode, &oregex, szerrmsg, sizeof(szerrmsg));
unerrmsglen = unerrmsglen < sizeof(szerrmsg) ? unerrmsglen : sizeof(szerrmsg) - 1;
szerrmsg[unerrmsglen] = ''\0'';
printf("ErrMsg: %s\n", szerrmsg);
regfree(&oregex);
return 1;
}演示匹配邮箱:
执行:./a.out "^[a-zA-Z0-9]+@[a-zA-Z0-9]+.[a-zA-Z0-9]+" "ldw@itcast.com"
演示结果如下:

总结
希望喜欢的点关注,不迷路哦!会持续更新linux C/C++相关内容,谢谢支持!

Haskell的Text.Regex.subRegex使用TDFA实现?
解决方法

Javascript lastIndex regex属性为PHP regex
我正在尝试用PHP翻译JavaScript脚本.到目前为止一切顺利,但是我偶然发现了一些毫无头绪的代码:
while (match = someRegex.exec(text)) {
m = match[0];
if (m === "-") {
var lastIndex = someRegex.lastIndex,
nextToken = someRegex.exec(parts.content);
if (nextToken) {
...
}
someRegex.lastIndex = lastIndex;
}
}
someRegex变量如下所示:
/[^\\-]+|-|\\(?:[0-3][0-7]{0,2}|[4-7][0-7]?|x[0-9A-Fa-f]{2}|u[0-9A-Fa-f]{4}|c[A-Za-z]|[\S\s]?)/g
exec应该等效于PHP中的preg_match_all:
preg_match_all($someRegex, $text, $match);
$match = $match[0]; // I get the same results so it works
foreach($match as $m){
if($m === '-'){
// here I don't kNow how to handle lastIndex and the 2nd exec :(
}
}
解决方法:
我完全不会使用lastIndex魔术-实际上,您在每个索引上执行两次正则表达式.如果确实要这样做,则需要将PREG_OFFSET_CAPTURE标志设置为preg_match_all,以便获取位置,添加捕获长度并将其用作下一个preg_match偏移量.
最好使用这样的东西:
preg_match_all($someRegex, $text, $match);
$match = $match[0]; // get all matches (no groups)
$len = count($match);
foreach($match as $i=>$m){
if ($m === '-') {
if ($i+1 < $len) {
$nextToken = $match[$i+1];
…
}
…
}
…
}
关于将php regex转换为java regex和php转成java的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于C++11正则表达式详解(regex_match、regex_search和regex_replace)、C语言用regcomp、regexec、regfree和regerror函数实现正则表达式校验、Haskell的Text.Regex.subRegex使用TDFA实现?、Javascript lastIndex regex属性为PHP regex等相关知识的信息别忘了在本站进行查找喔。
本文标签:




