本篇文章给大家谈谈Python-什么是“第一类”对象?,以及python中类方法的第一个参数的知识点,同时本文还将给你拓展(转)什么是“第一方Cookie”、“第三方Cookie”、java–从集合中
本篇文章给大家谈谈Python-什么是“第一类”对象?,以及python中类方法的第一个参数的知识点,同时本文还将给你拓展(转)什么是“第一方Cookie”、“第三方Cookie”、java – 从集合中删除“第一个”对象、python – Ruby中的第一类函数、Python 为什么会有个奇怪的“...”对象?等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- Python-什么是“第一类”对象?(python中类方法的第一个参数)
- (转)什么是“第一方Cookie”、“第三方Cookie”
- java – 从集合中删除“第一个”对象
- python – Ruby中的第一类函数
- Python 为什么会有个奇怪的“...”对象?
")
Python-什么是“第一类”对象?(python中类方法的第一个参数)
在给定的编程语言中,什么时候将对象或其他东西称为“一流”,为什么?它们与没有语言的语言有何不同?
编辑。当一个人说“一切都是对象”时(就像在Python中一样),他的确表示“一切都是一流的”吗?
答案1
小编典典简而言之,这意味着对对象的使用没有任何限制。它与任何其他对象相同。
第一类对象是可以动态创建,销毁,传递给函数,作为值返回并具有编程语言中其他变量所具有的所有权利的实体。
根据语言,这可能意味着:
- 可表示为匿名文字值
- 可存储在变量中
- 可存储在数据结构中
- 具有固有身份(独立于任何给定名称)
- 在与其他实体平等方面具有可比性
- 可作为参数传递给过程/功能
- 由于过程/功能可退还
- 在运行时可构造
- 可打印
- 易读
- 在分布式过程中可传播
- 在外部运行过程中可存储
但是,在C ++函数中,它们本身不是一流的对象:
- 你可以覆盖’()’运算符,以使它具有对象函数(第一类)成为可能。
- 函数指针是一流的。
- boost bind,lambda和function确实提供了一流的功能
在C ++中,类不是第一类对象,但是这些类的实例是。在Python中,类和对象都是一流的对象。(有关将类作为对象的更多详细信息,请参见此答案)。
这是Javascript一流函数的示例:
// f: function that takes a number and returns a number// deltaX: small positive number// returns a function that is an approximate derivative of ffunction makeDerivative( f, deltaX ){ var deriv = function(x) { return ( f(x + deltaX) - f(x) )/ deltaX; } return deriv;}var cos = makeDerivative( Math.sin, 0.000001);// cos(0) ~> 1// cos(pi/2) ~> 0不是第一类对象的实体称为第二类对象。C ++中的函数是第二类,因为它们不能动态创建。
关于编辑:
编辑。当一个人说“一切都是对象”时(就像在Python中一样),他的确表示“一切都是一流的”吗?
术语“对象”可以宽松地使用,并不意味着是一流的。将整个概念称为“一流实体”可能更有意义。但是在Python中,它们的目标是使所有东西都达到一流。我相信发表你讲话的人的意图是一流的。
什么是“第一方Cookie”、“第三方Cookie”")
(转)什么是“第一方Cookie”、“第三方Cookie”
在了解什么是“第一方Cookies”、“第三方Cookies”之前,我们应该先了解一下,什么叫Cookie?
什么叫Cookie?
Cookie是网站存放在客户端的一小段数据。一般的,网站为了提升用户体验,在客户的客户端中保存用户的历史信息,以备用户再次访问时网站能提供 更方便,更有针对性的服务。比如,网站可以记住你的登录状态,只要登录一次下次访问就不用在登录;购物网能记住你浏览过的产品,保留你购物车中的物品。这些都有Cookie的功劳。
Cookie是如何工作的?
比如,我们访问一个网站,来到了登录的页面。页面需要我们输入用户名和密码,同时下面有一个选项,叫“保留我的登录状态”,如果输入了用户名,密 码。为了下次在来这个网站,不用再重新输入,我们激活了保留状态的选项。最后点了提交。这时,我们的浏览器就会和网站服务器之间通过HTTP协议进行链 接,提交刚才输入的内容和选择。服务器收到以后,会判断这个用户名密码是否正确,因为我们需要保留状态,就需要设置Cookie来记录状态。那服务器会在 返回的HTTP数据包的头部包含SetCookie这个指令来告诉浏览器要保存的Cookie。浏览器收到以后会把这个Cookie加密存储到电脑上。这 个Cookie记录的一般是用户在这个网站的唯一的ID。之后,只要每次访问这个网站(只要还是这个域名),我们的浏览器在请求这个网站服务器数据的时 候,都会在HTTP请求数据包的头部增加一条包含Cookie数据的信息,比如这里会告诉服务器:“我是你的用户,我的ID是9527。”那服务器收到这 个信息,就不会再提示登录,而我们就已经是登录的状态了。
Cookie的生命周期
Cookie的生命周期有两种,一种是整个会话的,一种是永久 的。也就是说,一种是临时性的Cookie,用户关掉浏览器,这个Cookie也就失效了。一种是永久的Cookie,可以持续存在的。一般网站分析工具 判断Unique Visitor使用的是后者。
所谓“第一方Cookie”,指的是来自当前正在访问的网站,储存了一定信息的Cookie;所谓“第三方Cookie”,指的是来自当前访问网站以外的站点,最常见的就是那些在被访问站点放置广告的第三方站点,这第三方站点可能正在使用Cookie;所谓“会话Cookie”,就是当前浏览时存储的一些信息,在关闭IE的同时,这些Cookie也同时被删除,它一般没什么危害。
第一方和第三方Cookie的区别
第一方Cookie和第三方Cookie,都是网站在客户端上存放的一小块数据。他们都由某个域存放,只能被这个域访问。他们的区别其实并不是技术 上的区别,而是使用方式上的区别。比如,访问www.a.com这个网站,这个网站设置了一个Cookie,这个Cookie也只能被www.a.com 这个域下的网页读取,这就是第一方Cookie。如果还是访问www.a.com这个网站,网页里有用到www.b.com网站的一张图片,浏览器在 www.b.com请求图片的时候,www.b.com设置了一个Cookie,那这个Cookie只能被www.b.com这个域访问,反而不能被 www.a.com这个域访问,因为对我们来说,我们实际是在访问www.a.com这个网站被设置了一个www.b.com这个域下的Cookie,所 以叫第三方Cookie。
上面这么多看完还没有绕晕的请继续。
第一方Cookie的优势和应用
第一方Cookie的最大优势是接受率高。一般主流的浏览器的都会有隐私的设置,可以让用户设置是否接受Cookie,接受哪些Cookie。除了 完全不接受Cookie这个设置以外,其他情况下,第一方Cookie都是会被用户接受的(不接受的话,是没办法把那小块数据保存下来的)。所以,如果没 有特殊要求,使用第一方Cookie会比第三方Cookie,我们通过分析工具得到的数据会更准确。
第三方Cookie的优势和应用
第三方Cookie的接受率不如第一方Cookie(不过主流的浏览器默认的设置下也接受带P3P协议的第三方Cookie,我的经验是接受率能达 到90%,甚至95%以上),但在某些特定情况下可以实现第一方Cookie无法实现的功能。比如,当我们有多个域名的网站需要跟踪,我们希望了解到用户 点击某个广告到达域名A下的网页,然后可能浏览了不论那个域名下的页面,最后在域名B下的网页完成注册的情况。广告可以在域名A下的网页被跟踪到,而注册 可以在域名B下的网页跟踪到。如果我们使用第一方Cookie,会为域名A建立一个Cookie,为域名B再建立一个Cookie,他们可以关联各自域名 下网页上的行为,但是无法关联起来。而使用第三方Cookie,那么无论多少个域,都只有一个Cookie,一个属于第三方域的Cookie,网站下所有 域都能共享这个Cookie,那么所有的行为都能被关联起来分析。
其实大部分的浏览器都会支持跨域Cookie的,现在的门户网站,等其他网站里面都是前套着不同的域加载而形成的数据。
但是记录数据的时候,会同时产生多条记录,一个网站下,每一个域一条记录。这样就需要清洗数据了。
网站分析是以数据为基础的,而数据的采集需要借助网站 分析工具。主流的网站分析工具主要分两种类型:日志型和页面脚本型。这两种类型工具的一个区别就在于对Unique Visitor的区分很判断。当网站有很多次访问的记录的时候,如何判断那些访问来至同一个用户。日志型的分析工具,一般通过访问的来源IP地址进行判 断,通过相同IP地址的访问被认为来至同一个用户。页面脚本型的分析工具,就需要根据Cookie的记录来判断不同的访问是否来至不同的用户。这类的工具 会在Cookie中存放用来标识唯一用户的ID,每个浏览器得到的ID都是不同的。用户访问时检查Cookie中的ID,ID相同的访问被认为来至同一个 用户,否则,则是不同用户的访问。
Unique Visitor的判断对于网站分析来说非常重要,以致于分析工具在Cookie中存储的其他信息都显得不那么重要了。Unique Visitor并不仅仅是一个Metric,更重要的是,Unique Visitor把跨越多次访问的事件联系在一起。想象一下,一个访客通过一个广告来到网站,在这次访问离开前没有进行任何购买,但有把网站的网址加入到书 签。过了几天,这个访客通过点击书签,又访问了我们的网站,最后购买了一些商品。这时,如果没有Unique Visitor来关联,那点击广告和购买商品的行为是没有任何关联的,我们无法知道访客点击的广告为最后的购买所做的贡献。可见,Cookie对网站分析 是多么重要,通过Cookie,才能将多次访问中的事件串联起来。
总结:对于通过脚本型的网站分析工具来获取数据
Cookie是必须的,离开Cookie我们什么也分析不了。
第一方Cookie接受率高,更准确,没有特殊需要就用他。
第三方Cookie可以跨域跟踪,特别需求可以应用。

java – 从集合中删除“第一个”对象
LinkedHashSet实现,这使得简单:只是摆脱集合迭代器返回的第一个元素:
Set<Foo> mySet = new LinkedHashSet<Foo>();
// do stuff...
if (mySet.size() >= MAX_SET_SIZE)
{
Iterator<Foo> iter = mySet.iterator();
iter.next();
iter.remove();
}
这是丑陋的:3行做一些我可以做的1行,如果我使用SortedSet(由于其他原因,SortedSet不是一个选项)
if (/*stuff*/)
{
mySet.remove(mySet.first());
}
那么有没有更清洁的方法呢?
>改变Set的实现,或者
写一个静态的实用方法?
使用Guava的任何解决方案都是可以的.
我完全知道集合没有固有的顺序.我要求删除由迭代顺序定义的第一个条目.
解决方法
Set<String> set = Collections.newSetFromMap(new LinkedHashMap<String,Boolean>(){
protected boolean removeEldestEntry(Map.Entry<String,Boolean> eldest) {
return size() > MAX_ENTRIES;
}
});

python – Ruby中的第一类函数
我正在通过这篇关于函数式编程的文章(https://codewords.recurse.com/issues/one/an-introduction-to-functional-programming)并试图用Ruby做练习.
一个练习定义了两个函数,零和一个. Zero接受一个字符串参数并返回字符串索引1 – 如果第一个字符为0则结束,One执行相同的操作但仅当第一个字符为1时.
以下是ruby实现:
def zero(s)
if s[0] == "0"
return s[1..(s.length)]
end
end
def one(s)
if s[0] == "1"
return s[1..(s.length)]
end
end
问题要求你编写一个名为rule_sequence的方法,给定一个字符串和一个函数数组,返回结果,以便一次调用一个函数 – 第一个函数在整个字符串中被调用,第二个函数被调用关于该字符串的返回值等.如果在任何时候,其中一个函数返回nil,则返回nil.
Python实现是:
def rule_sequence(s, rules):
if s == None or not rules:
return s
else:
return rule_sequence(rules[0](s), rules[1:])
但是,由于Ruby似乎不支持高阶函数,我能想出的最优雅的解决方案如下:
def rule_sequence(string, rules)
if rules.length == 0 or string.nil?
return string
else
return rule_sequence(rules[0].call(string), rules[1..rules.length])
end
end
puts rule_sequence('0101', [lambda { |s| zero(s) }, lambda { |s| one(s) }, lambda { |s| zero(s) } ])
任何人都可以提出比传递或调用lambdas更简洁的东西吗?
解决方法:
我将以此练习为契机,展示Ruby如何支持更高阶的函数.
让我们退后一步,重写零 – 一个功能.
你可以注意到他们有很多共同之处.
让我们尝试通过编写一个可以生成两者的lambda来利用它
tail_on_prefix = lambda {|prefix|
lambda {|str| str[1..-1] if str[0] == prefix}
}
我们现在可以轻松定义零和一
zero = tail_on_prefix.("0")
one = tail_on_prefix.("1")
到rule_sequence吧!
rule_sequence = lambda {|str, rules|
if (str.nil? or rules.empty?)
str
else
rule_sequence.(rules[0].(str), rules[1..-1])
end
}
现在调用rule_sequence看起来好一点,不是吗
rule_sequence.("100101", [one, zero, zero]) # => "101"

Python 为什么会有个奇怪的“...”对象?
本文出自“Python为什么”系列,请查看全部文章
在写上一篇《Python 为什么要有 pass 语句?》时,我想到一种特别的写法,很多人会把它当成 pass 语句的替代。在文章发布后,果然有三条留言提及了它。
所谓特别的写法就是下面这个:
# 用 ... 替代 pass
def foo():
...
它是中文标点符号的半个省略号,也即由英文的 3 个点组成。如果你是第一次看到,很可能会觉得奇怪:这玩意是怎么回事?PS:如果你知道它,仔细看过本文后,你同样可能会觉得奇怪!
1、认识一下“...”内置常量
事实上,它是 Python 3 中的一个内置对象,有个正式的名字叫作——Ellipsis,翻译成中文就是“省略号”。
更准确地说,它是一个内置常量(Built-in Constant),是 6 大内置常量之一(另外几个是 None、False、True、NotImplemented、__debug__)。
关于这个对象的基础性质,下面给出了一张截图,你们应该能明白我的意思:

“...“并不神秘,它只是一个可能不多见的符号型对象而已。用它替换 pass,在语法上并不会报错,因为 Python 允许一个对象不被赋值引用。
严格来说, 这是旁门左道,在语义上站不住脚——把“...”或其它常量或已被赋值的变量放在一个空的缩进代码块中,它们是与动作无关的,只能表达出“这有个没用的对象,不用管它”。
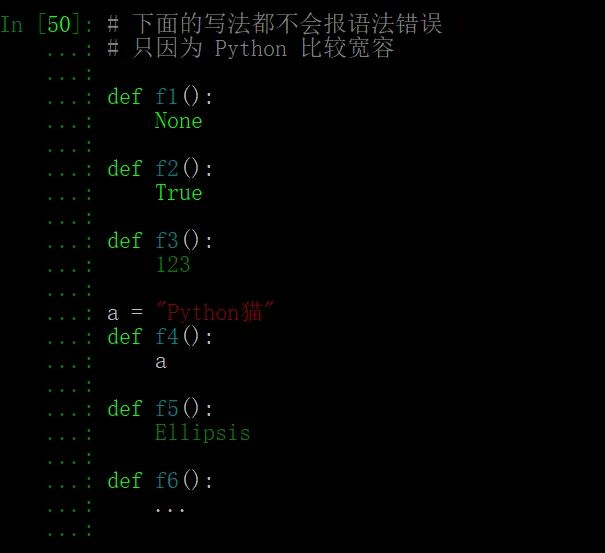
Python 允许这些不被实际使用的对象存在,然而聪明的 IDE 应该会有所提示(我用的是Pycharm),比如告诉你:Statement seems to have no effect 。
但是“...”这个常量似乎受到了特殊对待,我的 IDE 上没有作提示。
很多人已经习惯上把它当成 pass 那样的空操作来用了(在最早引入它的邮件组讨论中,就是举了这种用法的例子)。但我本人还是倾向于使用 pass,不知道你是怎么想的呢?
2、奇怪的 Ellipsis 和 ...
... 在 PEP-3100 中被引入,最早合入在 Python 3.0 版本,而 Ellipsis 则在更早的版本中就已包含。
虽然官方说它们是同一个对象的两种写法,而且说成是单例的(singleton),但我还发现一个非常奇怪的现象,与文档的描述是冲突的:

如你所见,赋值给 ... 时会报错SyntaxError: cannot assign to Ellipsis ,然而 Ellipsis 却可以被赋值,它们的行为根本就不同嘛!被赋值之后,Ellipsis 的内存地址以及类型属性都改变了,它成了一个“变量”,不再是常量。
作为对比,给 True 或 None 之类的常量赋值时,会报错SyntaxError: cannot assign to XXX,但是给 NotImplemented 常量赋值时不会报错。
众所周知,在 Python 2 中也可以给布尔对象(True/False)赋值,然而 Python 3 已经把它们改造成不可修改的。
所以有一种可能的解释:Ellipsis 和 NotImplemented 是 Python 2 时代的遗留产物,为了兼容性或者只是因为核心开发者遗漏了,所以它们在当前版本(3.8)中还可以被赋值修改。
... 出生在 Python 3 的时代,或许在将来会完全取代 Ellipsis。目前两者共存,它们不一致的行为值得我们注意。我的建议:只使用"..."吧,就当 Ellipsis 已经被淘汰了。
3、为什么要使用“...”对象?
接下来,让我们回到标题的问题:Python 为什么要使用“...”对象?
这里就只聚焦于 Python 3 的“...”了,不去追溯 Ellipsis 的历史和现状。
之所以会问这个问题,我的意图是想知道:它有什么用处,能够解决什么问题?从而窥探到 Python 语言设计中的更多细节。
大概有如下的几种答案:
(1)扩展切片语法
官方文档中给出了这样的说明:
Special value used mostly in conjunction with extended slicing syntax for user-defined container data types.
这是个特殊的值,通常跟扩展的切片语法相结合,用在自定义的数据类型容器上。
文档中没有给出具体实现的例子,但用它结合__getitem__() 和 slice() 内置函数,可以实现类似于 [1, ..., 7] 取出 7 个数字的切片片段的效果。
由于它主要用在数据操作上,可能大部分人很少接触。听说 Numpy 把它用在了一些语法糖用法上,如果你在用 Numpy 的话,可以探索一下都有哪些玩法?
(2)表达“未完成的代码”语义
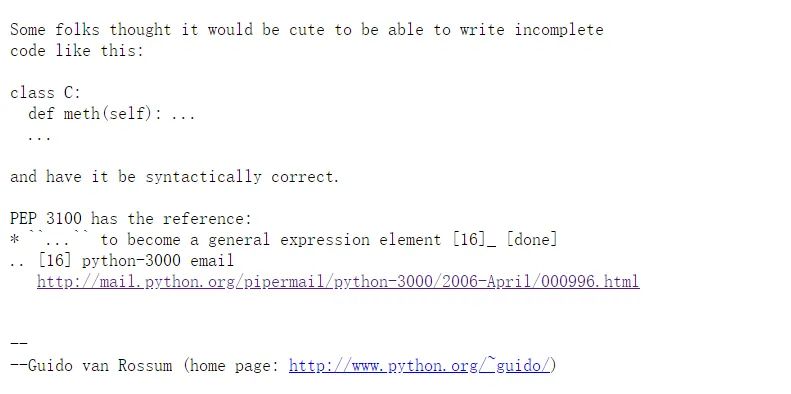
... 可以被用作占位符,也就是我在《Python 为什么要有 pass 语句?》中提到 pass 的作用。前文中对此已有部分分析。
有人觉得这样很 cute,这种想法获得了 Python 之父 Guido 的支持 :
(3)Type Hint 用法
Python 3.5 引入的 Type Hint 是“...”的主要使用场合。
它可以表示不定长的参数,比如Tuple[int, ...] 表示一个元组,其元素是 int 类型,但数量不限。
它还可以表示不确定的变量类型,比如文档中给出的这个例子:
from typing import TypeVar, Generic
T = TypeVar(''T'')
def fun_1(x: T) -> T: ... # T here
def fun_2(x: T) -> T: ... # and here could be different
fun_1(1) # This is OK, T is inferred to be int
fun_2(''a'') # This is also OK, now T is str
T 在函数定义时无法确定,当函数被调用时,T 的实际类型才被确定。
在 .pyi 格式的文件中,... 随处可见。这是一种存根文件(stub file),主要用于存放 Python 模块的类型提示信息,给 mypy、pytype 之类的类型检查工具 以及 IDE 来作静态代码检查。
(4)表示无限循环
最后,我认为有一个非常终极的原因,除了引入“...”来表示,没有更好的方法。
先看看两个例子:
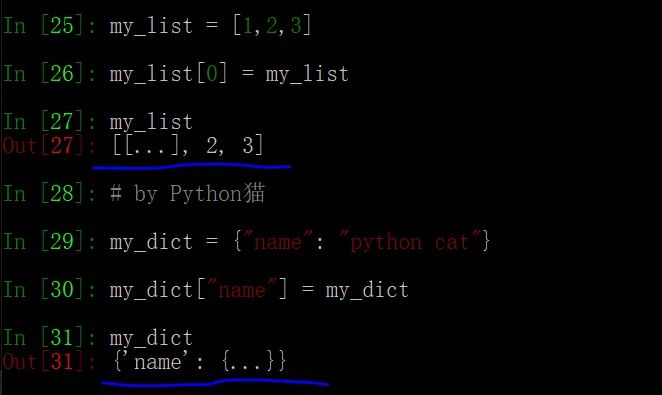
两个例子的结果中都出现了“...”,它表示的是什么东西呢?
对于列表和字典这样的容器,如果其内部元素是可变对象的话,则存储的是对可变对象的引用。那么,当其内部元素又引用容器自身时,就会递归地出现无限循环引用。
无限循环是无法穷尽地表示出来的,Python 中用 ... 来表示,比较形象易懂,除了它,恐怕没有更好的选择。
最后,我们来总结一下本文的内容:
-
... 是 Python 3 中的一个内置常量,它是一个单例对象,虽然是 Python 2 中就有的 Ellipsis 的别称,但它的性质已经跟旧对象分道扬镳 -
... 可以替代 pass 语句作为占位符使用,但是它作为一个常量对象,在占位符语义上并不严谨。很多人已经在习惯上接受它了,不妨一用 -
... 在 Python 中不少的使用场景,除了占位符用法,还可以支持扩展切片语法、丰富 Type Hint 类型检查,以及表示容器对象的无限循环 -
... 对大多数人来说,可能并不多见(有人还可能因为它是一种符号特例而排斥它),但它的存在,有些时候能够带来便利。希望本文能让更多人认识它,那么文章的目的也就达成了~
如果你觉得本文分析得不错,那你应该会喜欢这些文章:
1、Python为什么使用缩进来划分代码块?
2、Python 的缩进是不是反人类的设计?
3、Python 为什么不用分号作语句终止符?
4、Python 为什么没有 main 函数?为什么我不推荐写 main 函数?
5、Python 为什么推荐蛇形命名法?
6、Python 为什么不支持 i++ 自增语法,不提供 ++ 操作符?
7、Python 为什么只需一条语句“a,b=b,a”,就能直接交换两个变量?
8、Python 为什么用 # 号作注释符?
9、Python 为什么要有 pass 语句?
本文属于“Python为什么”系列(Python猫出品),该系列主要关注 Python 的语法、设计和发展等话题,以一个个“为什么”式的问题为切入点,试着展现 Python 的迷人魅力。所有文章将会归档在 Github 上,项目地址:https://github.com/chinesehuazhou/python-whydo

优质文章,推荐阅读:
C++ 模板沉思录(上)
编程语言之问:何时该借用,何时该创造?
深入探讨 Python 的 import 机制:实现远程导入模块
不使用 if-elif 语句,如何优雅地判断某个数字所属的等级?
本文分享自微信公众号 - Python猫(python_cat)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
关于Python-什么是“第一类”对象?和python中类方法的第一个参数的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于(转)什么是“第一方Cookie”、“第三方Cookie”、java – 从集合中删除“第一个”对象、python – Ruby中的第一类函数、Python 为什么会有个奇怪的“...”对象?等相关内容,可以在本站寻找。
本文标签:




