如果您想了解使用Python将图像添加到文档的相关知识,那么本文是一篇不可错过的文章,我们将对.docx中的特定位置吗?进行全面详尽的解释,并且为您提供关于python–如何将图像添加到PyPi自述文
如果您想了解使用Python将图像添加到文档的相关知识,那么本文是一篇不可错过的文章,我们将对.docx中的特定位置吗?进行全面详尽的解释,并且为您提供关于python – 如何将图像添加到PyPi自述文件(适用于GitHub)?、Python 实现 PDF 到 Word 文档(DOC、DOCX)的高效转换、python-docx操作word文件(*.docx)、python操作docx文档(转)的有价值的信息。
本文目录一览:- 使用Python将图像添加到文档(.docx)中的特定位置吗?(python怎么把图片放入文件)
- python – 如何将图像添加到PyPi自述文件(适用于GitHub)?
- Python 实现 PDF 到 Word 文档(DOC、DOCX)的高效转换
- python-docx操作word文件(*.docx)
- python操作docx文档(转)
中的特定位置吗?(python怎么把图片放入文件)")
使用Python将图像添加到文档(.docx)中的特定位置吗?(python怎么把图片放入文件)
我使用Python-docx生成Microsoft
Word文档。用户在编写以下内容时希望这样做:“大家早上好,这是我的%(profile_img)s,您喜欢吗?”
在一个HTML字段,我创建一个Word文档,我recuper用户的图片从数据库和i。由所述用户的图片替换键字%(profile_img)■
不能在文件的结尾 。对于Python-docx,我们使用以下指令添加图片:
document.add_picture(''profile_img.png'', width=Inches(1.25))图片添加到文档,但是在文档末尾添加了问题。使用python在Microsoft
Word文档中的特定位置添加图片是不可能的吗?我没有在网上找到任何答案,但是看到人们在其他地方提出同样的问题,却没有解决方案。
谢谢(注意:我不是一个经验丰富的程序员,除了这个笨拙的部分,其余的代码将非常基础)
答案1
小编典典引用python-docx文档:
Document.add_picture()方法将指定的图片添加到文档末尾的自己的段落中。但是,通过更深入地了解API,您可以将文本放置在图片段落的任一侧,或同时放置在这两者中。
当我们“更深入地研究”时,我们发现了Run.add_picture()API。
这是其用法示例:
from docx import Documentfrom docx.shared import Inchesdocument = Document()p = document.add_paragraph()r = p.add_run()r.add_text(''Good Morning every body,This is my '')r.add_picture(''/tmp/foo.jpg'')r.add_text('' do you like it?'')document.save(''demo.docx'')?")
python – 如何将图像添加到PyPi自述文件(适用于GitHub)?
在我关于GitHub的自述文件中,我在项目的源代码树中有几个图像,我用指令成功引用了这些图像.
.. image:: ./doc/source/_static/figs/moon_probe.png
我还希望在PyPi中生成相同的自述文件时显示这些图像.
我如何(a)确保PyPi上存在图像以供自述文件访问,以及(b)制定.. image ::指令以访问它们?
解决方法:
PyPI不会读取图像的包分布.您必须使用图像的外部链接,例如:
.. image:: https://raw.githubusercontent.com/greyli/flask-share/master/images/demo.png
在这里,我使用Github托管的图像,真正的演示是在PyPI.
附:要在Github上获取图像的原始链接,请左键单击该图像,然后选择在新选项卡中打开图像.
的高效转换")
Python 实现 PDF 到 Word 文档(DOC、DOCX)的高效转换

PDF(Portable Document Format)已成为一种广泛使用的电子文档格式。PDF 的主要优势是跨平台,可以在不同设备上呈现一致的外观。然而,当我们需要对文件内容进行编辑或修改,直接编辑 PDF 文件会非常困难,而且效果也不理想。将 PDF 文件转换为 Word 文档(doc、docx)再进行编辑是一个更好的选择。 本文将介绍如何使用 Python 编程语言,结合库和工具,将 PDF 文件转换为可编辑的 Word 文档,使文档的编辑变得方便高效。本文包含以下及个方面:
- PDF 文件转 Word 文档的优势
- 通过 Python 将 PDF 文件转换为 Word 文档(Doc 和 Docx)
- 通过 Python 将 PDF 文档转换为 Docx 文件并设置文档属性
本文所介绍的方法需要用到 Spire.PDF for Python,可从官网下载或通过 PyPI 安装:pip install Spire.PDF。
PDF 文件转 Word 文档的优势
将 PDF 文件转换为 Word 文档可以带来诸多优势,包括以下几个常见方面:
- 便于编辑和修改:PDF 文件通常适合阅读及打印,直接编辑会非常困难,且难以达到理想的效果。将 PDF 转换为 Word 文档可以方便进行修改、添加或删除文本、更改格式等诸多操作。
- 便于协作编辑:使用 Word 文档进行协作编辑是共同创作的理想解决方案。许多协作编辑平台支持实时更新编辑内容,为内容创作带来极大的便利。而 PDF 文件想要利用这些方便的协作编辑特性,就需要转换为 Word 文档。
- 数据提取:有时候我们需要从 PDF 文件中提取特定的数据或文本内容。将 PDF 转换为 Word 文档可以更轻松地提取所需的信息,并进行进一步的数据处理和分析。
通过 Python 将 PDF 文件转为 Word 文档(Doc 和 Docx)
PdfDocument 类代表一个 PDF 文档,使用其下的 LoadFromFile() 方法即可从文件载入 PDF 文档。在载入文档后,我们可以使用 PdfDocument 类下的 SaveToFile() 方法将 PDF 文档转换为其他格式的文件并保存,包括 Doc、Docx、HTML、SVG 等格式。在使用 SaveToFile () 方法时,只需要将保存路径和 FileFormat 枚举类型作为参数传递给该方法即可。
下面是操作步骤介绍:
- 导入模块。
- 创建 PdfDocument 类的实例。
- 使用 LoadFromFile () 方法载入 PDF 文件。
- 使用 SaveToFile () 方法将 PDF 文档转换为 DOC 或 DOCX 格式的 Word 文档,并关闭实例。
代码示例:
from spire.pdf import PdfDocument
from spire.pdf import FileFormat
# 创建PdfDocument类的实例
pdf = PdfDocument()
# 载入PDF文件
pdf.LoadFromFile("示例.pdf")
# 将PDF文件直接转换为Doc文件并保存
pdf.SaveToFile("output/PDF转DOC", FileFormat.DOC)
# 将PDF文件直接转换为Docx文件并保存
pdf.SaveToFile("output/PDF转DOCX", FileFormat.DOCX)
# 关闭实例
pdf.Close()
原 PDF 文档: 
转换结果: 
通过 Python 将 PDF 文档转换为 Docx 文件并设置文档属性
除了上述方法外,还可以使用 PdfToDocConverter 类并将文件路径作为参数创建转换实例。使用此类进行转换时,还可以对文件属性进行设置。此方法只能转换为 DOC 和 DOCX 文件。 下面是操作步骤介绍:
- 创建 PdfToDocConverter 的实例。
- 通过 PdfToDocConverter.DocxOptions 属性下的属性对转换出的 Word 文档的文档属性进行设置。
- SaveToFile() 将 PDF 文件保存为 DOC 或 DOCX 文件,参数为 True 表示转换为 DOCX 文件,参数为 False 则表示转换为 DOC 文件。
代码示例:
from spire.pdf import PdfToDocConverter
# 创建PdfToDocConverter类的实例
converter = PdfToDocConverter("G:/文档/示例21.pdf")
# 设置转换出的Word文档的文档属性
converter.DocxOptions.Title = "企业计划"
converter.DocxOptions.Subject = "企业管理及运营的计划草案。"
converter.DocxOptions.Tags = "企业, 企业管理, 工作计划"
converter.DocxOptions.Categories = "工作计划"
converter.DocxOptions.Commments = "本计划为草案,制定了工作计划的大致内容,需要进一步讨论确定详细内容。"
converter.DocxOptions.Authors = "李莉"
converter.DocxOptions.LastSavedBy = "王银"
converter.DocxOptions.Revision = 8
converter.DocxOptions.Version = "V4.0"
converter.DocxOptions.ProgramName = "Python"
converter.DocxOptions.Company = "企业名"
converter.DocxOptions.Manager = "企业名"
# 将PDF文件直接转换为Doc文件并保存
converter.SaveToDocx("output/PDF转DOC设置属性.doc", False)
# 将PDF文件直接转换为Doc文件并保存
converter.SaveToDocx("output/PDF转DOCX设置属性.docx", True)
转换出的 Word 文档的文档属性: 
总结
以上文章展示了如何通过 Python 代码将 PDF 文件转换为 Word 文档,包括转换为 DOC 格式和 DOCX 格式,以及在转换时设置结果文档的文档属性。Spire.PDF for Python 还支持转换 PDF 文件为其他诸多格式,包括网页文件(HTML)、SVG、JPEG 和 PNG 图片、Tiff、RTF 等格式,请前往 Spire.PDF for Python 教程查看详情。****
")
python-docx操作word文件(*.docx)
[TOC]
基础操作
from docx import Document
from docx.shared import Inches
# 创建空文档
document = Document()
# 添加标题,设置级别level,0为Title,1或省略为Heading 1,0<=level<=9
document.add_heading(''Document Title'', 0)
# 添加段落,参数为text=''''和style=None
p = document.add_paragraph(''A plain paragraph having some '')
# 添加run对象,参数为text=None和style=None,
# run对象有bold(加粗)和italic(斜体)这两个属性
p.add_run(''bold'').bold = True
p.add_run('' and some '')
p.add_run(''italic.'').italic = True
document.add_heading(''Heading, level 1'', level=1)
document.add_paragraph(''Intense quote'',Intense Quote'')
document.add_paragraph(
''first item in unordered list'',List Bullet''
)
document.add_paragraph(
''first item in ordered list'',List Number''
)
# 添加图片
document.add_picture(''monty-truth.png'', width=Inches(1.25))
# 添加表格
records = (
(3, ''101'', ''Spam''),
(7, ''422'', ''Eggs''),
(4, ''631'', ''Spam, spam, eggs, and spam'')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = ''Qty''
hdr_cells[1].text = ''Id''
hdr_cells[2].text = ''Desc''
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
对象关系
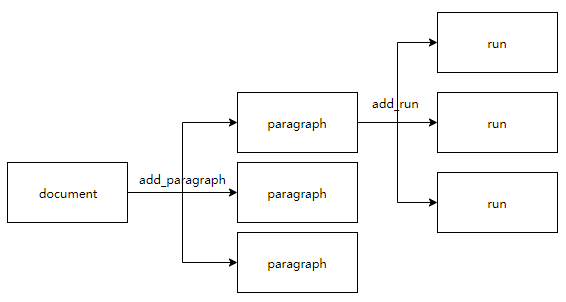
document.add_paragraph()之后,默认paragraph的内容到第一个run中。
添加样式
中文字体微软雅黑,西文字体Times New Roman
import docx
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.oxml.ns import qn
from docx.shared import Cm, Pt
document = Document()
# 设置一个空白样式
style = document.styles[''Normal'']
# 设置西文字体
style.font.name = ''Times New Roman''
# 设置中文字体
style.element.rPr.rFonts.set(qn(''w:eastAsia''), ''微软雅黑'')
首行缩进
# 获取段落样式
paragraph_format = style.paragraph_format
# 首行缩进0.74厘米,即2个字符
paragraph_format.first_line_indent = Cm(0.74)
单独设置标题样式
# 设置标题
title_ = document.add_heading(level=0)
# 标题居中
title_.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 添加标题内容
title_run = title_.add_run(title)
# 设置标题字体大小
title_run.font.size = Pt(14)
# 设置标题西文字体
title_run.font.name = ''Times New Roman''
# 设置标题中文字体
title_run.element.rPr.rFonts.set(qn(''w:eastAsia''), ''微软雅黑'')
设置超链接
def add_hyperlink(paragraph, url, text, color, underline):
"""
A function that places a hyperlink within a paragraph object.
:param paragraph: The paragraph we are adding the hyperlink to.
:param url: A string containing the required url
:param text: The text displayed for the url
:return: The hyperlink object
"""
# This gets access to the document.xml.rels file and gets a new relation id value
part = paragraph.part
r_id = part.relate_to(url, docx.opc.constants.RELATIONSHIP_TYPE.HYPERLINK, is_external=True)
# Create the w:hyperlink tag and add needed values
hyperlink = docx.oxml.shared.OxmlElement(''w:hyperlink'')
hyperlink.set(docx.oxml.shared.qn(''r:id''), r_id, )
# Create a w:r element
new_run = docx.oxml.shared.OxmlElement(''w:r'')
# Create a new w:rPr element
rPr = docx.oxml.shared.OxmlElement(''w:rPr'')
# Add color if it is given
if not color is None:
c = docx.oxml.shared.OxmlElement(''w:color'')
c.set(docx.oxml.shared.qn(''w:val''), color)
rPr.append(c)
# Remove underlining if it is requested
if not underline:
u = docx.oxml.shared.OxmlElement(''w:u'')
u.set(docx.oxml.shared.qn(''w:val''), ''none'')
rPr.append(u)
# Join all the xml elements together add add the required text to the w:r element
new_run.append(rPr)
new_run.text = text
hyperlink.append(new_run)
paragraph._p.append(hyperlink)
return hyperlink
document = docx.Document()
p = document.add_paragraph()
#add a hyperlink with the normal formatting (blue underline)
hyperlink = add_hyperlink(p, ''http://www.google.com'', ''Google'', None, True)
#add a hyperlink with a custom color and no underline
hyperlink = add_hyperlink(p, ''http://www.google.com'', ''Google'', ''FF8822'', False)
document.save(''demo.docx'')
上面的函数是对整段内容直接添加链接,日常使用的时候,超链接多为关键词,或<a>标签的格式,用paragraph和run这两个对象的关系来解决。
比如有文本内容如下,将其中的<a>标签换为超链接:
"""I am trying to add an hyperlink in a MS Word document using docx module for <a href="python.org">Python</a>. Just do it."""
# 判断字段是否为链接
def is_text_link(text):
for i in [''http'', ''://'', ''www.'', ''.com'', ''.org'', ''.cn'', ''.xyz'', ''.htm'']:
if i in text:
return True
else:
return False
# 对段落中的链接加上超链接
def add_text_link(document, text):
paragraph = document.add_paragraph()
# 根据<a>标签拆分文本内容
text = re.split(r''<a href="|">|</a>'',text)
keyword = None
for i in range(len(text)):
# 对非链接和非关键词的内容,通过run直接加入段落中
if not is_text_link(text[i]):
if text[i] != keyword:
paragraph.add_run(text[i])
# 对链接和关键词,使用add_hyperlink插入超链接
elif i + 1<len(text):
url=text[i]
keyword=text[i + 1]
add_hyperlink(paragraph, url, keyword, None, True)
参考文档
- https://python-docx.readthedocs.io/en/latest/index.html
- https://github.com/python-openxml/python-docx/issues/74
- http://www.warmeng.com/2018/12/02/auto_report/
")
python操作docx文档(转)
python操作docx文档
关于python操作docx格式文档,我用到了两个python包,一个便是python-docx包,另一个便是python-docx-template;,同时我也用到了很出名的一个工具"pandoc,下面我会对他们各自进行介绍。
- 首先便是python-docx包,这是一个很强大的包,可以用来创建docx文档,包含段落、分页符、表格、图片、标题、样式等几乎所有的word文档中能常用的功能都包含了,这个包的主要功能便是用来创建文档,相对来说用来修改功能不是很强大,关于文档请查看他的"官网;
- 再然后便是python-docx-template这个包了,他可以用来对docx文档进行修改,诸如对文档中的 文本、图片、富文本、等几乎所有存在与文档中的他都能替换,而且他操作起来就如同很多web框架中的模板语言一样,因为他是和jinjia2模板语言结合使用的,所以最好希望使用之前对模板语言有一定了解;
- 关于pandoc,这个包在许多需要进行文本转换的地方用处很强大,他可以把许多如今存在的文档格式转换问另一种文档格式,如html、markdown、docbook、latex、docx等转换为xml、latex、markdown、pdf,总之很强大,这是官网,有兴趣的可以去了解下。
下面便会相应介绍他们各自的大概的用法。还是按照上面的顺序进行介绍, :
:
-
关于python-docx这个包我觉得最好还是引用他官网的一段代码解释最为合适了,因为这里面基本情况都被包含了,
- from docx import Document
- from docx.shared import Inches
- document = Document() # 首先这是包的主要接口,这应该是利用的设计模式的一种,用来创建docx文档,里面也可以包含文档路径(d:\\2.docx)
- document.add_heading(''Document Title'', 0) # 这里是给文档添加一个标题,0表示 样式为title,1则为忽略,其他则是Heading{level},具体可以去<a href="https://python-docx.readthedocs.io/en/latest/user/styles-understanding.html" target="_blank">官网</a>查;
- p = document.add_paragraph(''A plain paragraph having some '') # 这里是添加一个段落
- p.add_run(''bold'').bold = True # 这里是在这个段落p里文字some后面添加bold字符
- p.add_run('' and some '')
- p.add_run(''italic.'').italic = True
- document.add_heading(''Heading, level 1'', level=1) # 这里是添加标题1
- document.add_paragraph(''Intense quote'', style=''IntenseQuote'') # 这里是添加段落,style后面则是样式
- document.add_paragraph(
- ''first item in unordered list'', style=''ListBullet'' # 添加段落,样式为unordered list类型
- )
- document.add_paragraph(
- ''first item in ordered list'', style=''ListNumber'' # 添加段落,样式为ordered list数字类型
- )
- document.add_picture(''monty-truth.png'', width=Inches(1.25)) # 添加图片
- table = document.add_table(rows=1, cols=3) # 添加一个表格,每行三列
- hdr_cells = table.rows[0].cells # 表格第一行的所含有的所有列数
- hdr_cells[0].text = ''Qty'' # 第一行的第一列,给这行里面添加文字
- hdr_cells[1].text = ''Id''
- hdr_cells[2].text = ''Desc''
- for item in recordset:
- row_cells = table.add_row().cells # 这是在这个表格第一行 (称作最后一行更好) 下面再添加新的一行
- row_cells[0].text = str(item.qty)
- row_cells[1].text = str(item.id)
- row_cells[2].text = item.desc
- document.add_page_break() # 添加分页符
- document.save(''demo.docx'') # 保存这个文档
具体样式请看:
 关于更多细节希望大家还是去他的官网python-docx;看,介绍的还是很详细
关于更多细节希望大家还是去他的官网python-docx;看,介绍的还是很详细
-
然后便是python-docx-template包了,他用起来就向python中的模板语言一样,有上下文,有模板,然后进行变量的替换
关于python-docx-template,他的官网名称便是“像jinjia2一样来操作docx文档”,因此这个包对于用来进行文档修改时很强大的下面是一个简单例子:
- from docxtpl import DocxTemplate
- doc = DocxTemplate("1.docx") # 对要操作的docx文档进行初始化
- context = { ''company_name'' : "World company" } # company_name 是存在于1.docx文档里面的变量,就像这样{{company_name}},直接放在1.docx文件的明确位置就行
- doc.render(context) # 这里是有jinjia2的模板语言进行变量的替换,然后便可以在1.docx文档里面看到{{company_name}}变成了World company
- doc.save("generated_doc.docx") # 保存
- 当然,这个包的功能远远不止上面例子中的一些,可以包含图片
- myimage = InlineImage(doc,''test_files/python_logo.png'',width=Mm(20)) # tpl便是上面例子中的doc对象
- 也可以包含另一个docx文档,
- sub = doc.new_subdoc()
- sub.subdocx = Document(''d:\\2.docx'')
- doc.render({''sub'': sub})
关于更多的特性,可以访问官网的example,里面涵盖了几乎所有的特性,地址是https://github.com/elapouya/python-docx-template/tree/master/tests
-
最后便是pandoc了,我在这次用到的功能主要是,用来把html文件直接转换为markdow格式文件,然后再转换为txt文件,最后将txt文件内容和格式一同插入到docx文档中,当然,也可以直接把html文件转换为docx文件,格式基本一致
这是用到的命令,而由于使用pandoc是在控制台下cmd或者shell使用的,因此要用到python的另一个包subprocess
- import subprocess
- subprocess.call(''pandoc --latex-engine=xelatex temp.html -o temp.text'', cwd=''d:\\python'', shell=True)
- subprocess.call(''pandoc --latex-engine=xelatex temp.text -o t1.text'', cwd=''d:\\python'', shell=True)
- <span style="background-color:rgb(153,153,255);">subprocess.call(''pandoc temp.html -o temp.docx'', cwd=''d:\\python'', shell=True)</span>
我们今天的关于使用Python将图像添加到文档和.docx中的特定位置吗?的分享已经告一段落,感谢您的关注,如果您想了解更多关于python – 如何将图像添加到PyPi自述文件(适用于GitHub)?、Python 实现 PDF 到 Word 文档(DOC、DOCX)的高效转换、python-docx操作word文件(*.docx)、python操作docx文档(转)的相关信息,请在本站查询。
本文标签:




