对于想了解使用Python的multiprocessing.Process类的读者,本文将是一篇不可错过的文章,我们将详细介绍pythonmultiprocessingprocess,并且为您提供关于
对于想了解使用Python的multiprocessing.Process类的读者,本文将是一篇不可错过的文章,我们将详细介绍python multiprocessing process,并且为您提供关于Python 3.2 Multiprocessing.Process没有运行目标函数、Python multiprocessing、Python multiprocessing 使用手记 [1] – 进程模型、python multiprocessing 模块 Process 类的 target 函数的有价值信息。
本文目录一览:- 使用Python的multiprocessing.Process类(python multiprocessing process)
- Python 3.2 Multiprocessing.Process没有运行目标函数
- Python multiprocessing
- Python multiprocessing 使用手记 [1] – 进程模型
- python multiprocessing 模块 Process 类的 target 函数
")
使用Python的multiprocessing.Process类(python multiprocessing process)
这是一个新手问题:
类是一个对象,因此我可以创建一个名为的类,pippo()并在此add函数和参数内部,我不知道pippo在分配时是内部函数是从上向下执行x=pippo()还是必须以x.dosomething()外部调用pippo。
使用Python的多处理程序包,是更好的方法是定义一个大函数并使用target调用中的参数创建对象Process(),或者通过从Process类继承来创建自己的流程类?
答案1
小编典典我经常想知道为什么Python的有关多处理的doc页面仅显示“功能性”方法(使用target参数)。可能是因为简洁的代码段最适合用于说明目的。对于适合一个功能的小任务,我可以看到这是首选的方式,ala:
from multiprocessing import Processdef f(): print(''hello'')p = Process(target=f)p.start()p.join()但是,当您需要更大的代码组织(用于复杂的任务)时,创建自己的类是可行的方法:
from multiprocessing import Processclass P(Process): def __init__(self): super(P, self).__init__() def run(self): print(''hello'')p = P()p.start()p.join()请记住,每个生成的进程都使用主进程的内存占用量副本进行初始化。而且构造函数代码(即内部的东西__init__())是在主进程中执行的-
只有内部的代码run()在单独的进程中执行。
因此,如果某个进程(主进程或生成的进程)更改了其成员变量,则该更改将不会反映在其他进程中。这,当然,是唯一真正的储存卡,在类型,如bool,string,list,等。但是,您可以导入“特殊”的数据结构,从multiprocessing其中将被透明的过程(见之间共享模块进程间共享状态。)或者,您可以创建自己的IPC(进程间通信)渠道,例如multiprocessing.Pipe和multiprocessing.Queue。

Python 3.2 Multiprocessing.Process没有运行目标函数
我有一个问题,我无法弄清楚是什么问题。 embedded式代码(3.2文档中最简单的示例代码,只是为了debugging)不会运行目标函数。 该过程完成后,程序导入并运行没有错误,正确安装Python 3.2和目录添加到Path环境variables。 我正在使用f5运行IDLE程序,其他所有代码都可以正常工作,但目标函数f(在这种情况下)中的代码很简单,不会运行。 如你所知,这是令人沮丧的。 这个代码不会打印,并且目标函数(以及任何函数)内的每个testing打印都不会执行; 它被简单地跳过。
#!/usr/bin/env python from multiprocessing import Process def f(name): print('hello',name) if __name__ == '__main__': p = Process(target=f,args=('bob',)) p.start()
有什么想法吗? 我在Windows 7系统上运行Python 3.2,并且使用Python 2.7在我的系统上成功运行了多处理(尽pipe我的项目需要我在3.2中进行开发)。 对不起,我认为这样一个简单的问题肯定是一些path问题,但我不确定我可能需要做什么来完成这个工作,并且找不到Google提供的任何解决scheme,因为Python肯定会识别这个包拼错时失败); 它只是行为不正确。 感谢您的任何帮助/build议!
Python:用于检测物理非HT cpu的跨平台解决scheme?
python中map.pool的用法是什么?
为什么在python pool.map不起作用
Python多处理内存使用情况
如何设置优先级来获取C / C ++中的互斥量
多处理和IDLE不能很好地协同工作。 确保它在IDLE之外运行,如果是的话,那就很好。
我自己不使用IDE,所以我没有别的东西可以提供给你,但是如何使用简单的print来进行调试真是太棒了。

Python multiprocessing
 

推荐教程
- 官方文档
- multiprocess各个模块较详细介绍
- 廖雪峰教程--推荐
- Pool中apply, apply_async的区别联系
- (推荐)python多进程的理解 multiprocessing Process join run
multiprocessing.Manager.Queuue vs multiprocessing.Queuue
| 队列 | 说明 |
|---|---|
| multiprocessing.Queuue | 只应通过继承在进程之间共享 Queue 对象 |
| multiprocessing.Manager.Queue | 如上所述,在进行并发编程时,通常最好尽量避免使用共享状态。使用多个进程时尤其如此。但是,如果您确实需要使用某些共享数据,那么多处理提供了两种方法。其中一种就是使用 Manager |
范例一
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 17:24
# @Author : wangbin
# @FileName: demo06.py
# @mail : bupt_wangbin@163.com
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print(''Process to write: %s'' % os.getpid())
for value in range(8):
print(''Put %s to queue...'' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print(''Process to read: %s'' % os.getpid())
while True:
if not q.empty():
value = q.get(True)
print(''Get %s from queue.'' % value)
time.sleep(random.random())
else:
break
if __name__ == ''__main__'':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
p = Pool()
pw = Process(target=write, args=(q,))
pw.start()
time.sleep(0.5)
pr = p.apply(read, args=(q,))
p.close()
p.join()
pw.join()
报错: Queue objects should only be shared between processes through inheritance(只应通过继承在进程之间共享 Queue 对象, 即为只可以父进程和子进程之间共享 Queue 对象)
 

范例二
一下方式可以使用
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 15:45
# @Author : wangbin
# @FileName: demo04.py
# @mail : bupt_wangbin@163.com
"""
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。
Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
"""
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print(''Process to write: %s'' % os.getpid())
for value in range(10):
# print(''Put %s to queue...'' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print(''Process to read: %s'' % os.getpid())
while True:
value = q.get(True)
print(''Get %s from queue.'' % value)
if __name__ == ''__main__'':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr1 = Process(target=read, args=(q,))
pr2 = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr1.start()
pr2.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr1.terminate()
pr2.terminate()
上述程序由于都是死循环, pr1 和 pr2如果有一个调用 join 方法的话, 程序就会一直在 block 住. 如果使用 Pool 会比较好管理, 而之前第一个范例说明, Pool 与 Produce 之间使用 multiprocessing.Queue 会出现错误, 所以, 如果使用 Pool 来产生多个进程用于生产者或者消费者, 用 Pool 很简单. 所以, 当要共享数据时候, 使用Manager.Queue() 准没错
总结: 如果使用进程共享数据的话, 就使用 Manager.Queue()
范例三
下面是使用进程池来做的
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 15:45
# @Author : wangbin
# @FileName: demo04.py
# @mail : bupt_wangbin@163.com
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print(''Process to write: %s'' % os.getpid())
for value in range(3):
print(''Put %s to queue...'' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print(''Process to read: %s'' % os.getpid())
while True:
value = q.get(True)
print(''Get %s from queue.'' % value)
if __name__ == ''__main__'':
# 父进程创建Queue,并传给各个子进程:
with Manager() as manager:
with Pool(processes=8) as pool:
# 启动子进程pr,读取:
q = manager.Queue()
for i in range(3):
pool.apply_async(func=write, args=(q,))
pool.apply_async(func=read, args=(q,)).get()
pool.close()
pool.join()
pool.terminate()
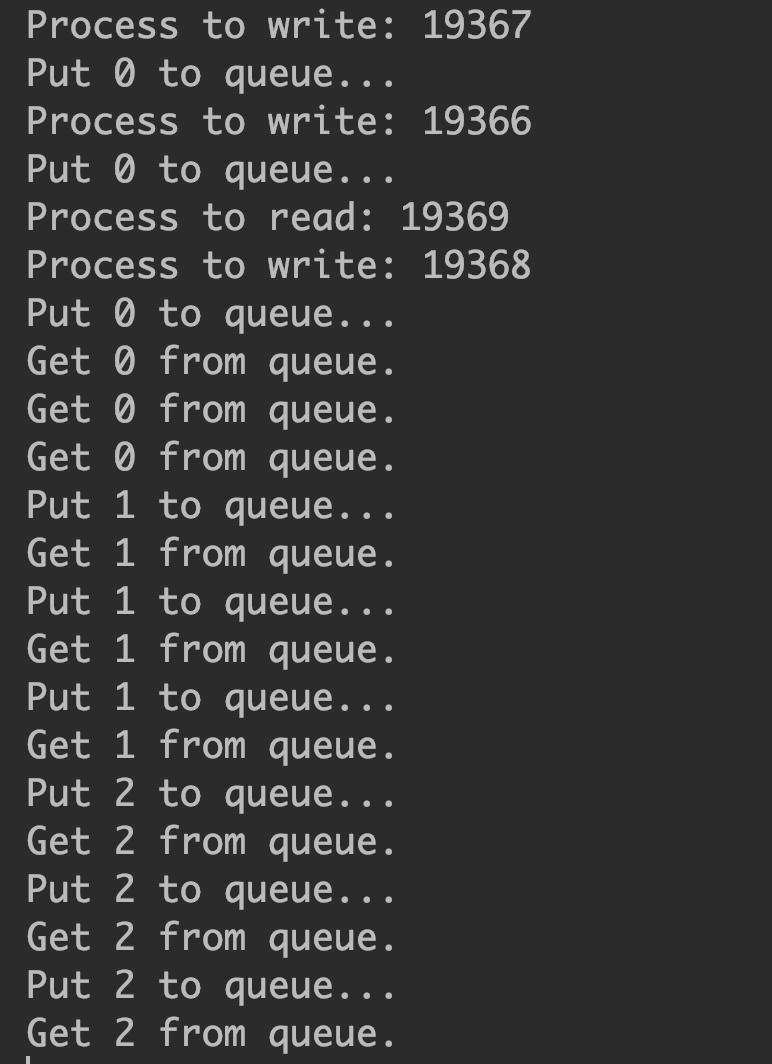 

由此可以看出, 每个进程中, 每个程序都会跑一边. 所以炼丹测试时, 验证集数据集只能使用一个进程跑, 而读取的进程需要多设置几个
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print(''Run task %s (%s)...'' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print(''Task %s runs %0.2f seconds.'' % (name, (end - start)))
if __name__==''__main__'':
print(''Parent process %s.'' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print(''Waiting for all subprocesses done...'')
p.close()
p.join()
print(''All subprocesses done.'')
执行结果如下:
Parent process 669.
Waiting for all subprocesses done...
Run task 0 (671)...
Run task 1 (672)...
Run task 2 (673)...
Run task 3 (674)...
Task 2 runs 0.14 seconds.
Run task 4 (673)...
Task 1 runs 0.27 seconds.
Task 3 runs 0.86 seconds.
Task 0 runs 1.41 seconds.
Task 4 runs 1.91 seconds.
All subprocesses done.
代码解读:
-
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
-
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:p = Pool(5), 就可以同时跑5个进程。
-
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
![Python multiprocessing 使用手记 [1] – 进程模型](http://www.gvkun.com/zb_users/upload/2025/02/55b21d10-df2a-43e4-9671-bd75441125aa1739076802245.jpg "Python multiprocessing 使用手记 [1] – 进程模型")
Python multiprocessing 使用手记 [1] – 进程模型
首先从 multiprocessing 的进程模型开始看。
multiprocessing 的目的是创建一个接口和 python.threading 类似接口的库,用多进程的方式来并发处理。因此创建一个新的进程的的方法也和 python.threading 很像:
import multiprocessing
def dosomething(a,b,c): pass
p = multiprocessing.Process(target=dosomething, args=(1,2,3)) p.start() p.join()创建的这个新的进程在 * nix 上面使用的是 fork,这意味着子进程开始执行的时候具有与父进程相同的全部内容。请记住这点,这个将是下面我们讨论基于继承的对象共享的基础。所谓基于继承的对象共享,是说在创建子进程之前由父进程初始化的某些对象可以在子进程当中直接访问到。在 Windows 平台上,因为没有 fork 语义的系统调用,基于继承的共享对象比 * nix 有更多的限制,最主要就是体现在要求 Process 的__init__当中的参数必须可以 Pickle。
但是,并不是所有的对象都是可以通过继承来共享,只有 multiprocessing 库当中的某些对象才可以。例如 Queue,同步对象,共享变量,Manager 等等。
在一个 multiprocessing 库的典型使用场景下,所有的子进程都是由一个父进程启动起来的,这个父进程称为 master 进程。这个父进程非常重要,它会管理一系列的对象状态,一旦这个进程退出,子进程很可能会处于一个很不稳定的状态,因为它们共享的状态也许已经被损坏掉了。因此,这个进程最好尽可能做最少的事情,以便保持其稳定性。
继续写关于 Python multiprocessing 的使用手记,继上次的进程模型之后,这次展开讨论一下 multiprocessing 当中的跨进程对象共享的问题。
在 mp 库当中,跨进程对象共享有三种方式,第一种仅适用于原生机器类型,即 python.ctypes 当中的类型,这种在 mp 库的文档当中称为 shared memory 方式,即通过共享内存共享对象;另外一种称之为 server process,即有一个服务器进程负责维护所有的对象,而其他进程连接到该进程,通过代理对象操作服务器进程当中的对象;最后一种在 mp 文档当中没有单独提出,但是在其中多次提到,而且是 mp 库当中最重要的一种共享方式,称为 inheritance,即继承,对象在父进程当中创建,然后在父进程是通过 multiprocessing.Process 创建子进程之后,子进程自动继承了父进程当中的对象,并且子进程对这些对象的操作都是反映到了同一个对象。
这三者共享方式各有特色,在这里进行一些简单的比较。
首先是共享方式所应对的对象类型,看这个表:
| 共享方式 | 支持的类型 |
| Shared memory | ctypes 当中的类型,通过 RawValue,RawArray 等包装类提供 |
| Inheritance | 系统内核对象,以及基于这些对象实现的对象。包括 Pipe, Queue, JoinableQueue, 同步对象 (Semaphore, Lock, RLock, Condition, Event 等等) |
| Server process | 所有对象,可能需要自己手工提供代理对象 (Proxy) |
这个表总结了三种不同的共享方式所支持的类型,下面一个个展开讨论。
其中最单纯简单的就是 shared memory 这种方式,只有 ctypes 当中的数据类型可以通过这种方式共享。由于 mp 库本身缺少命名的机制,即在一个进程当中创建的对象,无法在另外一个进程当中通过名字来引用,因此,这种共享方式依赖于继承,对象应该由父进程创建,然后由子进程引用。关于这种机制的例子,可以参见 Python 文档当中的例子 Synchronization types like locks, conditions and queues,参考其中的 test_sharedvalues 函数。
然后是继承方式。首先关于继承方式需要有说明,继承本质上并不是一种对象共享的机制,对象共享只是其副作用。子进程从父进程继承来的对象并不一定是共享的。继承本质上是父进程 fork 出的子进程自动继承父进程的内存状态和对象描述符。因此,实际上子进程复制了一份父进程的对象,只不过,当这个对象包装了一些系统内核对象的描述符的时候,拷贝这个对象(及其包装的描述符)实现了对象的共享。因此,在上面的表当中,只有系统内核对象,和基于这些对象实现的对象,才能够通过继承来共享。通过继承共享的对象在 linux 平台上没有任何限制,但是在 Windows 上面由于没有 fork 的实现,因此有一些额外的限制条件,因此,在 Windows 上面,继承方式是几乎无法用的。
最后就是 Server Process 这种方式。这种方式可以支持的类型比另外两种都多,因为其模型是这样的:

server process 模型
在这个模型当中,有一个 manager 进程,负责管理实际的对象。真正的对象也是在 manager 进程的内存空间当中。所有需要访问该对象的进程都需要先连接到该管理进程,然后获取到对象的一个代理对象(Proxy object),通常情况下,这个代理对象提供了实际对象的公共函数的代理,将函数参数进行 pickle,然后通过连接传送到管理进程当中,管理进程将参数 unpickle 之后,转发给相应的实际对象的函数,返回值(或者异常)同样经过管理进程 pickle 之后,通过连接传回到客户进程,再由 proxy 对象进行 unpickle,返回给调用者或者抛出异常。
很明显,这个模型是一个典型的 RPC(远程过程调用)的模型。因为每个客户进程实际上都是在访问 manager 进程当中的对象,因此完全可以通过这个实现对象共享。
manager 和 proxy 之间的连接可以是基于 socket 的网络连接,也可以是 unix pipe。如果是使用基于 socket 的连接方式,在使用 proxy 之前,需要调用 manager 对象的 connect 函数与远程的 manager 进程建立连接。由于 manager 进程会打开端口接收该连接,因此必要的身份验证是需要的,否则任何人都可以连上 manager 弄乱你的共享对象。mp 库通过 authkey 的方式来进行身份验证。
在实现当中,manager 进程通过 multiprocessing.Manager 类或者 BaseManager 的子类实现。BaseManager 提供了函数 register 注册一个函数来获取共享对象的 proxy。这个函数会被客户进程调用,然后在 manager 进程当中执行。这个函数可以返回一个共享的对象(对所有的调用返回同一个对象),或者可以为每一个调用创建一个新的对象,通过前者就可以实现多个进程共享一个对象。关于这个的用法可以参考 Python 文档当中的例子 “Demonstration of how to create and use customized managers and proxies”。
典型的导出一个共享对象的代码是:
ObjectType object_class ObjectManager(multiprocessing.managers.BaseManager): pass ObjectManager.register("object", lambda: object_)注意上面介绍 proxy 对象的时候,我提到的 “公共函数” 四个字。每个 proxy 对象只会导出实际对象的公共函数。这里面有两个含义,一个是 “公共”,即所有非下划线开头的成员,另一个是 “函数”,即所有 callable 的成员。这就带来一些限制,一是无法导出属性,二是无法导出一些公共的特殊函数,例如__get__, __next__等等。对于这个 mp 库有一套处理,即自定义 proxy 对象。首先是 BaseManager 的 register 可以提供一个 proxy_type 作为第三个参数,这个参数指定了哪些成员需要被导出。详细的使用方法可以参见文档当中的第一个例子。
另外 manager 还有一些细节的问题需要注意。由于 Proxy 对象不是线程安全的,因此如果需要在一个多线程程序当中使用 proxy,mp 库会为每个线程创建一个 proxy 对象,而每个 proxy 对象都会对 server process 创建一个连接,而 manager 那边对于每个连接都创建一个单独的线程来为其服务。这样带来的问题就是,如果客户进程有很多线程,很容易会导致 manager 进程的 fd 数目达到 ulimit 的限制,即使没有达到限制,也会因为 manager 进程当中有太多线程而严重影响 manager 的性能。解决方案可以是一个进程内 cache,只有一个单独的线程可以创建 proxy 对象访问共享对象,其余线程只能访问该进程当中的 cache。
一旦 manager 因为达到 ulimit 限制或者其他异常,manager 会直接退出,遗憾的是,这时候已经建立的 proxy 会试图重新连接 manager – 但是它已经不存在了。这个会导致客户进程 hang 在对 proxy 的函数调用上,这个时候,目前除了杀掉进程没有找到别的办法。
另外 proxy 使用 socket 的方式比较 tricky,因此和内置的 socket 库有很多冲突,比如 socket.setdefaulttimeout(Python Issue 6056 )。在 setdefaulttimeout 调用了之后,进程当中所有通过 socket 模块建立的 socket 都是被设置为 unblock 模式的,但是 mp 库并不知道这一点,而且它总是假设 socket 都是 block 模式的,于是,一旦调用了 setdefaulttimeout,所有对于 proxy 的函数调用都会抛出 OSError,错误代码为 11,错误原因是非常有误导性的 “Resource temporarily unavailable”,实际上就是 EAGAIN。这个错误可以通过我提供的一个 patch 来补救(这个 patch 当中还包含其他的一些修复,所以请自行查看并修改该 patch)。
由于以上的一些原因,server process 模式作为一个对象的共享模式,能够提供最为灵活的共享方式,但是也有最多的问题。这个在使用过程当中就靠自己去衡量了。目前我们的系统对于数据可靠性方面要求不高,丢失数据是可以接受的,但是也只用这种模式来维护统计值,不敢用来维护更多的东西。
关于跨进程共享对象的问题就写到这里,后面内容待续……
继续讨论 Python multiprocessing,这次讨论的主要内容是 mp 库的核心组件之一的 Queue。
Queue 是 mp 库当中用来提供多进程对象交换的方式。对象交换和上一部分当中提到的对象共享都是使多个进程访问同一个对象的方式,两者的区别就是,对象共享是多个进程访问同一个对象,对象交换则是将对象从一个进程传输的另一个进程。
multiprocessing 当中的 Queue 使用方式和 Python 内置的 threading.Queue 对象很像,它支持一个 put 操作,将对象放入 Queue,也支持一个 get 操作,将对象从 Queue 当中读出。和 threading.Queue 不同的是,mp.Queue 默认不支持 join () 和 task_done 操作,这两个支持需要使用 mp.JoinableQueue 对象。
由于 Queue 对象负责进程之间的对象传输,因此第一个问题就是如何在两个进程之间共享这个 Queue 对象本身。在上一部分所言的三种共享方式当中,Queue 对象只能使用继承(inheritance)的方式共享。这是因为 Queue 本身基于 unix 的 Pipe 对象实现,而 Pipe 对象的共享需要通过继承。因此,在一个典型的应用实现模型当中,应该是父进程创建 Queue,然后创建子进程共享该 Queue,由父进程和子进程分别读写。例如下面的这个例子:
import multiprocessing
q = multiprocessing.Queue() def reader_proc():
print q.get()
reader = multiprocessing.Process(target=reader_proc) reader.start()
q.put(100) reader.join()另一种实现方式是父进程创建 Queue,创建多个子进程,有的子进程读 Queue,有的子进程写 Queue,例如:
import multiprocessing
q = multiprocessing.Queue() def writer_proc():
q.put(100) def reader_proc():
print q.get()
reader = multiprocessing.Process(target=reader_proc) reader.start() writer = multiprocessing.Process(target=writer_proc) writer.start()
reader.join() writer.join()由于使用继承的方式共享 Queue,因此代码当中并没有明显的传输 Queue 对象本身的代码,看起来似乎只要将 multiprocessing 当中的对象换成 threading 当中的对象,程序仍然能够工作。反之,拿到一个现有的多线程程序,是不是将 threading 改成 multiprocessing 就可以工作呢?也许可以,但是更可能的情况是你会遇到很多问题。
第一个问题就是 mp 的 Queue 需要考虑多进程之间的对象传输,因此所传输的对象必须是可以 pickle 的。否则,在 Queue 的 put 操作上会抛出 PicklingError。
其他的一些差异表现在一些技术细节上,这些不是任何高层逻辑可以抽象掉的,不知道这些差异会导致一些潜在的错误,例如死锁。在总结这些潜在的犯错的可能的同时,我们会简单看一下 mp 当中 Queue 的实现方式,以便能够方便的理解为什么会有这样的行为。这些实现问题仅仅针对 Linux,Windows 上面的实现和出现的问题在这里不涉及。
mp.Queue 建构在系统的 Pipe 之上,但是实际上进程并不是直接将对象写入到 Pipe 里面,而是先写入一个本地的 buffer,再由一个专门的 feed 线程将其放入 Pipe 当中。读取端则是直接从 Pipe 当中读出对象。之所以有这样一个 feed 线程,是为了能够提供 Queue 接口函数所需要的 put 的超时控制。但是由于这个 feed 线程的存在,mp.Queue 提供了几个额外的函数来控制它,一个函数 close 来停止该线程,以及 join_thread 来 join 该线程。close 同时负责把所有在 buffer 当中的对象刷新到 Pipe 当中。
但是这个 feed 线程也是个麻烦制造者,为了保证所有被放入 Queue 的东西最终都能够到达另外一端的进程,mp 库注册了一个 atexit 的处理函数,用来在进程退出的时候自动 close 并且 join 该 feed 线程。这个 join 动作带来了很多问题,比如潜在的死锁。考虑下面一种状况:一个父进程创建了两个子进程,一个子进程读,另一个子进程写。当需要停止这些进程的时候,父进程如果先把读进程结束,但是同时写进程已经将太多的对象写入 Queue,导致后继的对象等待在 buffer 当中,则这个进程将无法终止,因为 atexit 的处理函数等待把所有 buffer 当中的对象放入 Pipe,但是 Pipe 已经满了,然后陷入了死锁。
有人可能会问,那只要保证总是按照数据流的顺序来停止进程不就行。问题是在很多复杂的系统流程当中,可能存在一个环形的数据流,这种情况下,无论按照什么顺序停止进程,终究有一个进程可能陷入这种情景当中。
幸运的是,Queue 对象还提供了一个成员函数 cancel_join_thread,这个函数可以使得在进程停止的时候不进行 join 操作,这样可以避免死锁,代价就是这个时候尚未刷新到 Pipe 当中的对象都会丢失。鉴于即使调用了 join_thread,残留在 Pipe 当中的对象仍然可能丢失,所以一旦选择使用 mp 的 Queue 对象,就不要假设不会在流程当中丢对象了。
另外一个可能的方案是使用 mp 库当中的 SimpleQueue 对象。这个对象在文档当中没有提及,但是在 multiprocessing.queue 模块当中有定义。这个对象就是去掉了 buffer 的 Queue 对象,因此可能能够避免上面说的问题的。但是 SimpleQueue 没有提供 put 和 get 的超时处理,两个动作都是阻塞的。
除了使用 multiprocessing.Queue,还可以使用 multiprocessing.Pipe 进行通信。mp.Pipe 是 Queue 的底层结构,但是没有 feed 线程和 put/get 的超时控制。一定程度上和 SimpleQueue 很像。需要注意的是 Pipe 带有一个参数 duplex,当设置为 True(默认)的时候,Pipe 并不是使用系统的 pipe 来实现,而是通过 socketpair,即 Unix Domain Socket 来实现。这个和 pipe 相比有些微的性能差异。
另外一个使用 Queue 的方式不是 mp 库内置的。这种方式使用上一篇文章当中提到的 server process 的方式来共享一个 Queue 对象。这个 Queue 对象实际上在 server process 当中,所有的子进程通过 socket 连接到 server process 获取该 Queue 的代理对象进行操作。说到这有人会想起来 mp 库有一个内置的 SyncManager 对象,可以通过 multiprocess.Manager 函数获取到,通过该对象的 Queue 方法可以获取一个 Queue 的代理对象。不幸的是,这个方法不是正确的获取 Queue 的方式,原因正如上一篇文章所说,SyncManager.Queue 方法的每次调用获取到的是一个新建对象的代理对象,而不是一个共享对象。正确的使用 server process 当中的 Queue 的方式是:
共同部分:
import multiprocessing.managers as mpmimport Queue class SharedQueueManager(mpm.BaseManager): pass q = Queue.Queue() SharedQueueManager.register(''Queue'', lambda: q)服务进程:
mgr = SharedQueueManager(address=('''', 12345)) server = mgr.get_server() server.serve_forever()客户进程:
mgr = SharedQueueManager(address=(''localhost'', 12345)) mgr.connect() q = mgr.Queue() # 这里q就是共享的Queue对象的代理对象这种方式比起 mp 库内置的 Queue,有一些性能上的影响,因为毕竟牵涉到多次网络通讯,但是带来的好处是没有 feed 线程带来的一系列问题,而且理论上不会存在丢数据的问题,除非 server process 崩溃。但是正如上一篇所说,server process 本身就不是很靠谱的,因此这里也只是 “理论上” 不会丢数据而已。
说到性能,这里就列两个性能数据,以前在 twitter 上面提到过的(这两个连接无法访问的请联系我):
操作对象为 pickle 后 512 字节的对象,通过 proxy 操作 Queue 的性能大约是 7000 次 / 秒(本机)或 1100 次 / 秒(多机),如果使用 multiprocessing.Queue,效率可达 54000 次 / 秒。

python multiprocessing 模块 Process 类的 target 函数
在最近在学python的进程,因为一直在linux下学的,今天到win下测试了一下,发下了个问题代码如下
import multiprocessing as mp
import time
import os
def th():
print("我的父亲是%d" % os.getppid())
time.sleep(2)
while True:
time.sleep(2)
print("我是儿子!")
print("我的父亲是%d" % os.getppid())
p = mp.Process(target=th)
p.daemon = False
p.start()
time.sleep(1)
print("爸爸我over了!", os.getpid())
这段代码在linux运行无错误但是在win下
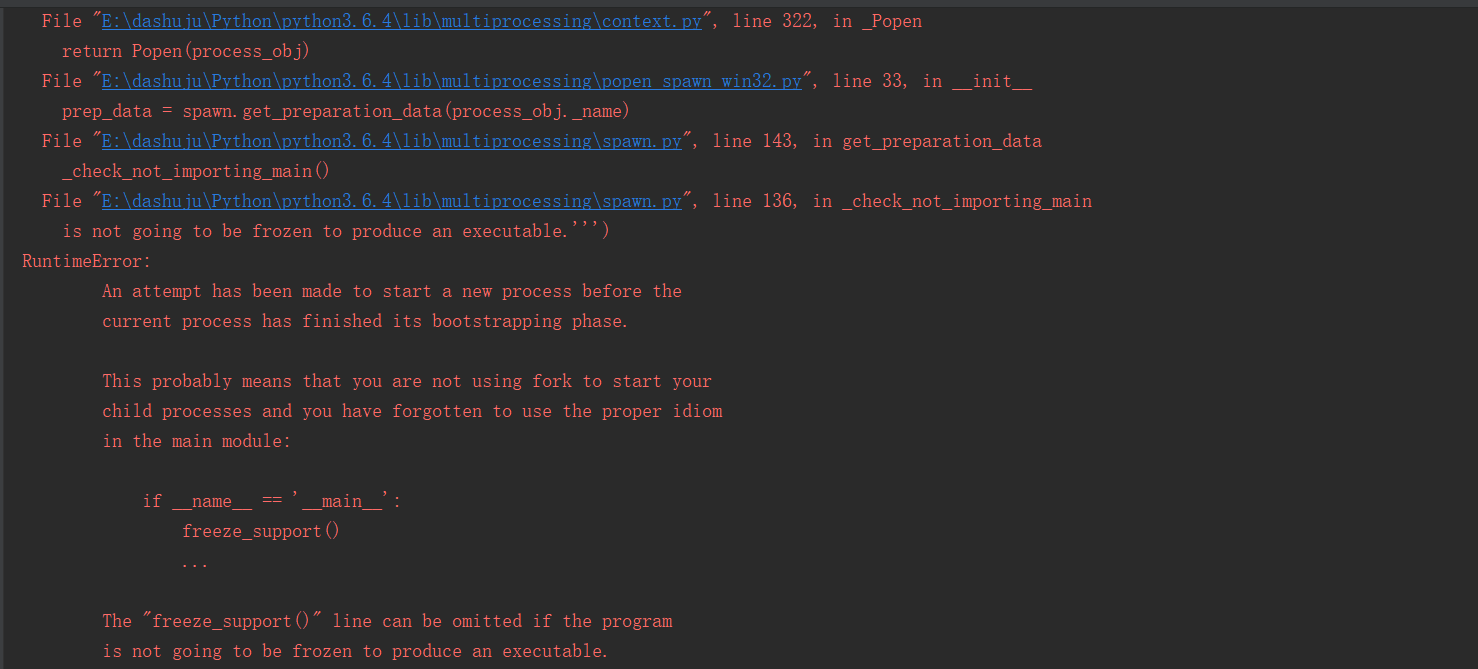
后来我发现在代码里面加一个逻辑控制的 if __name__ == ''main''就可以解决了
欢迎大牛批评教导,解决疑惑,谢谢
今天的关于使用Python的multiprocessing.Process类和python multiprocessing process的分享已经结束,谢谢您的关注,如果想了解更多关于Python 3.2 Multiprocessing.Process没有运行目标函数、Python multiprocessing、Python multiprocessing 使用手记 [1] – 进程模型、python multiprocessing 模块 Process 类的 target 函数的相关知识,请在本站进行查询。
本文标签:




