本篇文章给大家谈谈SparkStandalone提交模式,以及sparkstandalone提交任务的知识点,同时本文还将给你拓展04、SparkStandalone集群搭建、JavaWeb提交任务到
本篇文章给大家谈谈Spark Standalone 提交模式,以及spark standalone提交任务的知识点,同时本文还将给你拓展04、Spark Standalone集群搭建、Java Web 提交任务到 Spark Standalone 集群并监控、Scala进阶之路-Spark独立模式(Standalone)集群部署、Spark - Standalone模式等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- Spark Standalone 提交模式(spark standalone提交任务)
- 04、Spark Standalone集群搭建
- Java Web 提交任务到 Spark Standalone 集群并监控
- Scala进阶之路-Spark独立模式(Standalone)集群部署
- Spark - Standalone模式
")
Spark Standalone 提交模式(spark standalone提交任务)
一.Client提交模式
提交命令:
./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadooop2.6.0.jar 100
等价【默认为client】:
./spark-submit --master spark://node1:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadooop2.6.0.jar 100
执行流程:
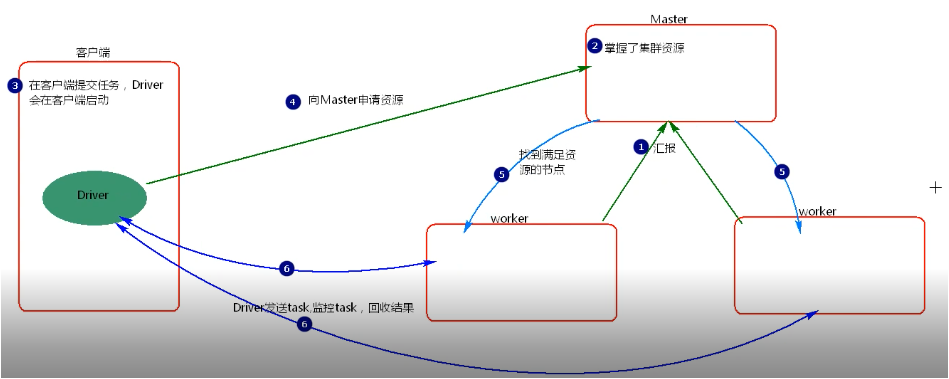
分析:
standalone-client模式提交任务,会在客户端看到task的执行情况和结果。当在客户端提交多个application时,每个application会启动自己的dirver,driver与集群worker有大量的通信,会造成客户端网卡流量激增的问题,这种模式适用于测试而不适应于生产环境。
二.Cluster提交模式
提交命令:
./spark-submit --master spark://node1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadooop2.6.0.jar 100
执行流程:
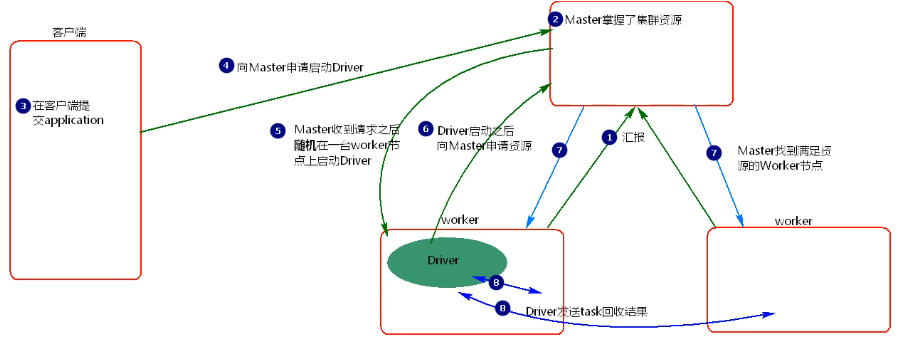
分析:
standalone-cluster模式提交任务driver会在集群中的随机选择一个worker上启动,如果提交多个application,那么每个application的driver会分散到集群的各个worker节点,相当于将client模式的客户端网卡流量激增问题分散到集群的各个节点中。这种模式适用于生产环境。

04、Spark Standalone集群搭建
04、Spark Standalone集群搭建
4.1 集群概述
独立模式是Spark集群模式之一,需要在多台节点上安装spark软件包,并分别启动master节点和worker节点。master节点是管理节点,负责和各worker节点通信,完成worker的注册与注销。worker节点是任务执行节点,通过worker节点孵化出执行器子进程来执行任务。
4.2 集群规划
这里使用4台主机部署Spark集群,主机名称分别是s101、s102、s103和s104。
s101 #Master节点
s102 #Worker节点
s103 #Worker节点
s104 #Worker节点
4.3 集群搭建
4.3.1 安装Spark软件包
按照前文安装spark软件包的方式分别在以上四台主机上安装Spark,注意目录和权限尽量保持一致,以便集群容易维护和管理。也可以将之前的Spark安装目录和环境变量文件分发到以上四台主机。具体安装步骤略。
4.3.2 配置hadoop软连接
在以上四台机的spark配置目录下,创建core-site.xml和hdfs-site.xml软连接文件指向hadoop的配置文件。
#进入配置目录
$>cd /soft/spark/conf
#创建软连接
$>ln -s /soft/hadoop/etc/hadoop/core-site.xml core-site.xml
$>ln -s /soft/hadoop/etc/hadoop/hdfs-site.xml hdfs-site.xml
创建完成后,如下图所示:

4.3.3 修改slaves文件
只需要在master节点对该文件进行修改即可,但为了保持所有节点配置一致性,我们对所有节点都进行修改,或者修改后进行分发。slaves文件内容如下:
#使用如下命令进入slaves文件编辑模式
$>nano /soft/spark/conf/slaves
#输入如下内容,列出所有worker节点。
s102
s103
s104
4.3.4 配置JAVA_HOME环境变量
修改配置目录下spark-env.sh文件,指定JAVA_HOME环境变量。
#使用如下命令进入spark-env.sh文件编辑模式
$>nano /soft/spark/conf/spark-env.sh
#添加如下内容
...
export JAVA_HOME=/soft/jdk
...
编辑内容如下图所示:
4.4 启动集群
启动spark集群时,如果配置了hadoop配置文件,需要先启动hadoop集群,然后再启动Spark集群。由于Spark Standalone集群模式只是从hdfs读取文件,并不需要yarn的支持,因此只需要启动hadoop的hdfs相关进程即可。
#启动hadoop hdfs
$>/soft/hadoop/sbin/start-dfs.sh
#启动Spark集群
$>/soft/spark/sbin/start-all.sh
注意:Spark和Hadoop都有启动所有进程的脚本,并且都叫start-all.sh,因此再使用时一定要使用绝对路径。
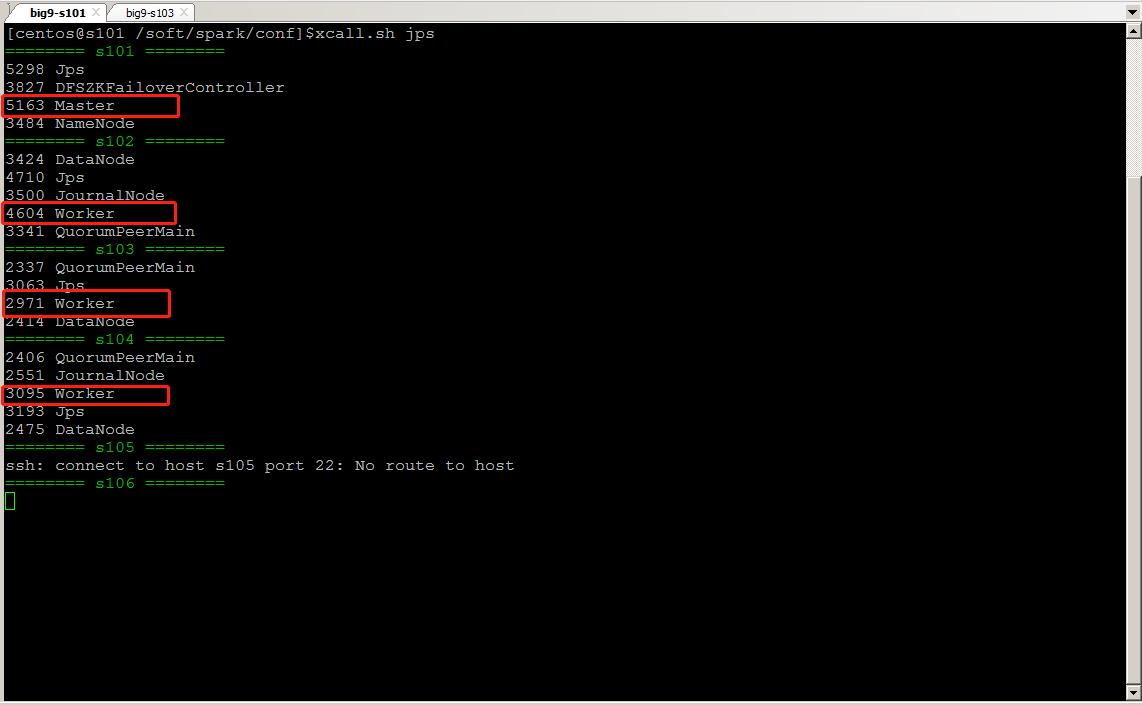
查看进程结果如图:
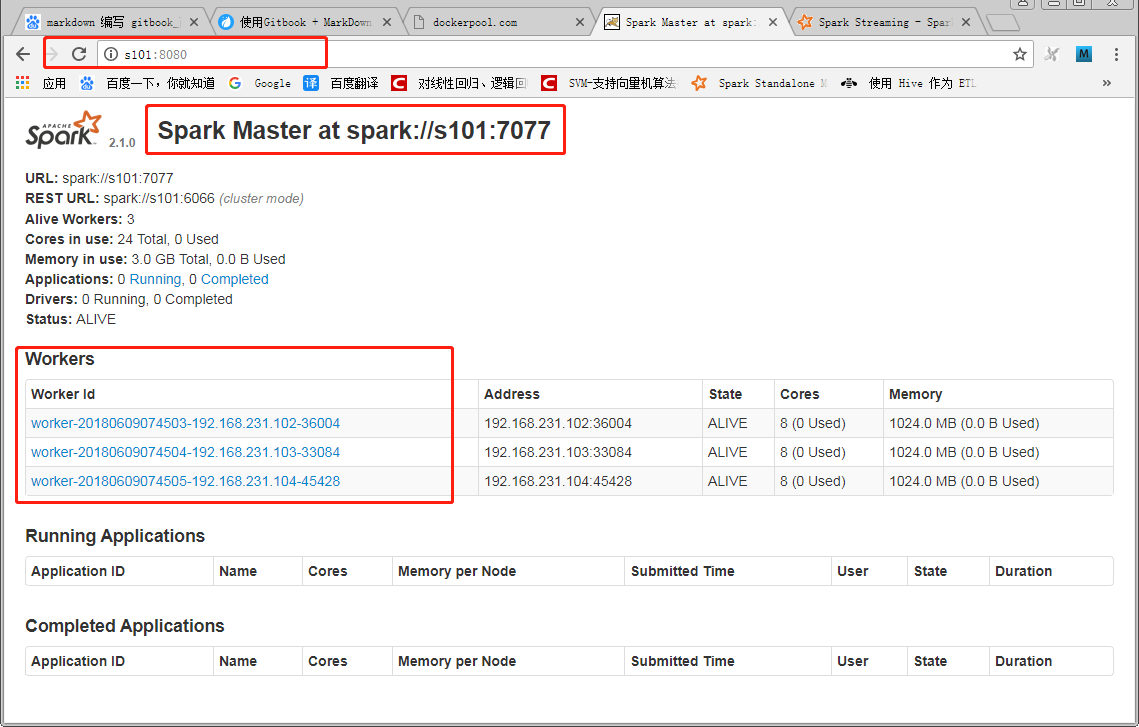
4.5 查看webui
通过如下url地址访问spark webui:
http://s101:8080/
打开页面如下图所示:

Java Web 提交任务到 Spark Standalone 集群并监控

Java Web 提交任务到 Spark Standalone 集群并监控
环境
工程下载路径
Spark 任务提交流程
问题及问题解决
后记
Java Web 提交任务到 Spark Standalone 集群并监控
1. 环境
软件 版本 备注
IDEA 14.1.5
JDK 1.8
Spark 1.6.0 工程 maven 引用
Spark cdh5.7.3-spark1.6.0 实际集群 5.7.3-1.cdh5.7.3.p0.5
Hadoop 2.6.4 工程 Maven 引用
Hadoop 2.6.0-cdh5.7.3 实际集群参数
Maven 3.3
2. 工程下载路径
工程在 GitHub 上地址为: javaweb_spark_standalone_monitor
3. Spark 任务提交流程
之前做过相关的工作,知道可以通过下面的方式来提交任务到 Spark Standalone 集群:
String[] arg0=new String[]{
"--master","spark://server2.tipdm.com:6066",
"--deploy-mode","cluster",
"--name",appName,
"--class",className,
"--executor-memory","2G",
"--total-executor-cores","10",
"--executor-cores","2",
path,
"/user/root/a.txt",
"/tmp/"+System.currentTimeMillis()
};
SparkSubmit.main(arg0);
1
2
3
4
5
6
7
8
9
10
11
12
13
1. 这里要注意的是,这里使用的模式是 cluster,而非 client,也就是说 driver 程序也是运行在集群中的,而非提交的客户端,也就是我 Win10 本地。
2. 如果需要使用 client 提交,那么需要注意本地资源是否足够;同时因为这里使用的是 cluster,所以需要确保集群资源同时可以运行一个 driver 以及 executor(即,最少需要同时运行两个 Container)
3. 其中的 path,也就是打的 jar 包需要放到集群各个 slave 节点中的对应位置。比如 lz 集群中有 node1,node2,node3 ,那么就需要把 wc.jar 放到这三个节点上,比如放到 /tmp/wc.jar ,那么 path 的设置就要设置为 file:/opt/wc.jar , 如果直接使用 /opt/wc.jar 那么在进行参数解析的时候会被解析成 file:/c:/opt/wc.jar (因为 lz 使用的是 win10 运行 Tomcat),从而报 jar 包文件找不到的错误!
进入 SparkSubmit.main 源码,可以看到如下代码:
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
代码里面是通过 submit 来提交任务的,顺着这条线往下,则最终是通过
mainMethod.invoke 是通过反射来调用的,通过 debug 可以得到,这里反射调用的其实是:RestSubmissionClient 的 main 函数提交任务的。
所以这里可以模仿 RestSubmissionClient 来提交任务。程序如下:
public static String submit(String appResource,String mainClass,String ...args){
SparkConf sparkConf = new SparkConf();
// 下面的是参考任务实时提交的 Debug 信息编写的
sparkConf.setMaster(MASTER);
sparkConf.setAppName(APPNAME+" "+ System.currentTimeMillis());
sparkConf.set("spark.executor.cores","2");
sparkConf.set("spark.submit.deployMode","cluster");
sparkConf.set("spark.jars",appResource);
sparkConf.set("spark.executor.memory","2G");
sparkConf.set("spark.cores.max","2");
sparkConf.set("spark.driver.supervise","false");
Map<String,String> env = filterSystemEnvironment(System.getenv());
CreateSubmissionResponse response = null;
try {
response = (CreateSubmissionResponse)
RestSubmissionClient.run(appResource, mainClass, args, sparkConf, toScalaMap(env));
}catch (Exception e){
e.printStackTrace();
return null;
}
return response.submissionId();
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
如果不加其中的
sparkConf.set
…
则程序运行会有问题,第一个错误就是:
java.lang.IllegalArgumentException: Invalid environment variable name: “=::”
这个错误是因为模式设置不对(没有设置 cluster 模式),所以在进行参数匹配的时候异常。可以看到的参数如下图所示:
这里面对应的参数,其实就是 SparkSubmit 提交任务所对应的值了。
4. 问题及问题解决
问题提出:
1. 最近一段时间,在想运行 Spark 的任务的时候为什么要提交到 YARN 上,而且通过实践发现,提交到 YARN 上程序运行比 Spark Standalone 运行要慢的多,所以是否能直接提交任务到 Spark Standalone 集群呢?
2. 提交任务到 Spark Standalone 集群后,如何获得任务的 id,方便后面的监控呢?
3. 获得任务 id 后,怎么监控?
针对这三个问题,解答如下:
1. 第一个问题,应该是见仁见智的问题了,使用 SparkONYARN 的方式可以统一生态圈什么的;
2. 在上面的代码中已经可以提交任务,并且获取任务 ID 了。不过需要注意的是,通过:
response = (CreateSubmissionResponse)
RestSubmissionClient.run(appResource, mainClass, args, sparkConf, toScalaMap(env));
获取的 response 需要转型为 CreateSubmissionResponse,才能获得 submittedId,但是要访问 CreateSubmissionResponse,那么需要在某些包下面才行,所以 lz 的 SparkEngine 类才会定义在 org.apache.spark.deploy.rest 包中。
第三:
监控,监控就更简单了,可以参考:
private def requestStatus(args: SparkSubmitArguments): Unit = {
new RestSubmissionClient(args.master)
.requestSubmissionStatus(args.submissionToRequestStatusFor)
}
1
2
3
4
这里就是监控的代码了,lz 参考这段代码写了个监控,详见 GitHub。
后记
在提交任务到 Spark Standalone 的时候,lz 发现 driver 和实际的任务是分开的,如下:
发现是 driver 调用 app,本来想着,driver 是不是提交后,就 Over 了,结果发现 driver 会一直监控 app 的状态,如果 app 运行成功结束,那么 driver 状态就会返回 FINISHED,如果失败,则 driver 状态也是 ERROR。所以可以直接监控 driver 来监控整个任务。
使用 Spark Standalone 来运行 Spark 程序,确实比 Spark On YARN 快的多了!
————————————————
https://blog.csdn.net/fansy1990/article/details/78551986
https://github.com/fansy1990
https://blog.csdn.net/fansy1990/article/details/78551986
集群部署")
Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS分布式文件系统存储,而计算采用MapReduce框架进行计算,当你在学习MapReduce的操作时,尤其是Hive的时候(因为Hive底层其实仍然调用的MapReduce)是不是觉得MapReduce运行的特别慢?因此目前很多人都转型学习Spark,今天我们就一起学习部署Spark集群吧。
一.准备环境
如果你的服务器还么没有部署Hadoop集群,可以参考我之前写的关于部署Hadoop高可用的笔记:https://www.cnblogs.com/yinzhengjie/p/9154265.html
1>.启动HDFS分布式文件系统


[yinzhengjie@s101 download]$ more `which xzk.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com
#判断用户是否传参
if [ $# -ne 1 ];then
echo "无效参数,用法为: $0 {start|stop|restart|status}"
exit
fi
#获取用户输入的命令
cmd=$1
#定义函数功能
function zookeeperManger(){
case $cmd in
start)
echo "启动服务"
remoteExecution start
;;
stop)
echo "停止服务"
remoteExecution stop
;;
restart)
echo "重启服务"
remoteExecution restart
;;
status)
echo "查看状态"
remoteExecution status
;;
*)
echo "无效参数,用法为: $0 {start|stop|restart|status}"
;;
esac
}
#定义执行的命令
function remoteExecution(){
for (( i=102 ; i<=104 ; i++ )) ; do
tput setaf 2
echo ========== s$i zkServer.sh $1 ================
tput setaf 9
ssh s$i "source /etc/profile ; zkServer.sh $1"
done
}
#调用函数
zookeeperManger
[yinzhengjie@s101 download]$ 

[yinzhengjie@s101 download]$ more `which xcall.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com
#判断用户是否传参
if [ $# -lt 1 ];then
echo "请输入参数"
exit
fi
#获取用户输入的命令
cmd=$@
for (( i=101;i<=105;i++ ))
do
#使终端变绿色
tput setaf 2
echo ============= s$i $cmd ============
#使终端变回原来的颜色,即白灰色
tput setaf 7
#远程执行命令
ssh s$i $cmd
#判断命令是否执行成功
if [ $? == 0 ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 download]$ 

[yinzhengjie@s101 download]$ more `which xrsync.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com
#判断用户是否传参
if [ $# -lt 1 ];then
echo "请输入参数";
exit
fi
#获取文件路径
file=$@
#获取子路径
filename=`basename $file`
#获取父路径
dirpath=`dirname $file`
#获取完整路径
cd $dirpath
fullpath=`pwd -P`
#同步文件到DataNode
for (( i=102;i<=105;i++ ))
do
#使终端变绿色
tput setaf 2
echo =========== s$i %file ===========
#使终端变回原来的颜色,即白灰色
tput setaf 7
#远程执行命令
rsync -lr $filename `whoami`@s$i:$fullpath
#判断命令是否执行成功
if [ $? == 0 ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 download]$ 

[yinzhengjie@s101 download]$ xzk.sh start
启动服务
========== s102 zkServer.sh start ================
ZooKeeper JMX enabled by default
Using config: /soft/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
========== s103 zkServer.sh start ================
ZooKeeper JMX enabled by default
Using config: /soft/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
========== s104 zkServer.sh start ================
ZooKeeper JMX enabled by default
Using config: /soft/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ xcall.sh jps
============= s101 jps ============
2603 Jps
命令执行成功
============= s102 jps ============
2316 Jps
2287 QuorumPeerMain
命令执行成功
============= s103 jps ============
2284 QuorumPeerMain
2319 Jps
命令执行成功
============= s104 jps ============
2305 Jps
2276 QuorumPeerMain
命令执行成功
============= s105 jps ============
2201 Jps
命令执行成功
[yinzhengjie@s101 download]$ 

[yinzhengjie@s101 download]$ start-dfs.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Starting namenodes on [s101 s105]
s101: starting namenode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-namenode-s101.out
s105: starting namenode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-namenode-s105.out
s103: starting datanode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-datanode-s103.out
s104: starting datanode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-datanode-s104.out
s102: starting datanode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-datanode-s102.out
Starting journal nodes [s102 s103 s104]
s104: starting journalnode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-journalnode-s104.out
s102: starting journalnode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-journalnode-s102.out
s103: starting journalnode, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-journalnode-s103.out
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Starting ZK Failover Controllers on NN hosts [s101 s105]
s101: starting zkfc, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-zkfc-s101.out
s105: starting zkfc, logging to /soft/hadoop-2.7.3/logs/hadoop-yinzhengjie-zkfc-s105.out
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ xcall.sh jps
============= s101 jps ============
7909 Jps
7526 NameNode
7830 DFSZKFailoverController
命令执行成功
============= s102 jps ============
2817 QuorumPeerMain
4340 JournalNode
4412 Jps
4255 DataNode
命令执行成功
============= s103 jps ============
4256 JournalNode
2721 QuorumPeerMain
4328 Jps
4171 DataNode
命令执行成功
============= s104 jps ============
2707 QuorumPeerMain
4308 Jps
4151 DataNode
4236 JournalNode
命令执行成功
============= s105 jps ============
4388 DFSZKFailoverController
4284 NameNode
4446 Jps
命令执行成功
[yinzhengjie@s101 download]$ 2>.上传测试数据到HDFS集群中


[yinzhengjie@s101 download]$ cat temp
0029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
0029029070999991902010113004+64333+023450FM-12+000599999V0202901N008219999999N0000001N9+00721+99999102001ADDGF104991999999999999999999
0029029070999991903010120004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9-00941+99999102001ADDGF108991999999999999999999
0029029070999991904010206004+64333+023450FM-12+000599999V0201801N008219999999N0000001N9-00611+99999101831ADDGF108991999999999999999999
0029029070999991905010213004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9-00561+99999101761ADDGF108991999999999999999999
0029029070999991906010220004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9+00281+99999101751ADDGF108991999999999999999999
0029029070999991907010306004+64333+023450FM-12+000599999V0202001N009819999999N0000001N9-00671+99999101701ADDGF106991999999999999999999
0029029070999991908010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
0029029070999991909010113004+64333+023450FM-12+000599999V0202901N008219999999N0000001N9-00721+99999102001ADDGF104991999999999999999999
0029029070999991910010120004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9+00941+99999102001ADDGF108991999999999999999999
0029029070999991911010206004+64333+023450FM-12+000599999V0201801N008219999999N0000001N9-00611+99999101831ADDGF108991999999999999999999
0029029070999991912010213004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9+00561+99999101761ADDGF108991999999999999999999
0029029070999991913010220004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9+00281+99999101751ADDGF108991999999999999999999
0029029070999991914010306004+64333+023450FM-12+000599999V0202001N009819999999N0000001N9+00671+99999101701ADDGF1069919999999999999999990029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
0029029070999991915010113004+64333+023450FM-12+000599999V0202901N008219999999N0000001N9-00721+99999102001ADDGF104991999999999999999999
0029029070999991916010120004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9+00941+99999102001ADDGF108991999999999999999999
0029029070999991917010206004+64333+023450FM-12+000599999V0201801N008219999999N0000001N9+00611+99999101831ADDGF108991999999999999999999
0029029070999991918010213004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9+00561+99999101761ADDGF108991999999999999999999
0029029070999991919010220004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9-00281+99999101751ADDGF108991999999999999999999
0029029070999991920010306004+64333+023450FM-12+000599999V0202001N009819999999N0000001N9+00671+99999101701ADDGF1069919999999999999999990029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
0029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
0029029070999991902010113004+64333+023450FM-12+000599999V0202901N008219999999N0000001N9+00721+99999102001ADDGF104991999999999999999999
0029029070999991903010120004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9-00941+99999102001ADDGF108991999999999999999999
0029029070999991904010206004+64333+023450FM-12+000599999V0201801N008219999999N0000001N9+00611+99999101831ADDGF108991999999999999999999
0029029070999991905010213004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9+00561+99999101761ADDGF108991999999999999999999
0029029070999991906010220004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9+00281+99999101751ADDGF108991999999999999999999
0029029070999991907010306004+64333+023450FM-12+000599999V0202001N009819999999N0000001N9-00671+99999101701ADDGF106991999999999999999999
0029029070999991908010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9+00781+99999102001ADDGF108991999999999999999999
0029029070999991909010113004+64333+023450FM-12+000599999V0202901N008219999999N0000001N9-00721+99999102001ADDGF104991999999999999999999
0029029070999991910010120004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9+00941+99999102001ADDGF108991999999999999999999
0029029070999991911010206004+64333+023450FM-12+000599999V0201801N008219999999N0000001N9+00611+99999101831ADDGF108991999999999999999999
0029029070999991912010213004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9-00561+99999101761ADDGF108991999999999999999999
0029029070999991913010220004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9+00281+99999101751ADDGF108991999999999999999999
0029029070999991914010306004+64333+023450FM-12+000599999V0202001N009819999999N0000001N9+00671+99999101701ADDGF1069919999999999999999990029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
0029029070999991915010113004+64333+023450FM-12+000599999V0202901N008219999999N0000001N9+00721+99999102001ADDGF104991999999999999999999
0029029070999991916010120004+64333+023450FM-12+000599999V0209991C000019999999N0000001N9-00941+99999102001ADDGF108991999999999999999999
0029029070999991917010206004+64333+023450FM-12+000599999V0201801N008219999999N0000001N9+00611+99999101831ADDGF108991999999999999999999
0029029070999991918010213004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9-00561+99999101761ADDGF108991999999999999999999
0029029070999991919010220004+64333+023450FM-12+000599999V0201801N009819999999N0000001N9+00281+99999101751ADDGF108991999999999999999999
0029029070999991920010306004+64333+023450FM-12+000599999V0202001N009819999999N0000001N9+00671+99999101701ADDGF1069919999999999999999990029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
[yinzhengjie@s101 download]$ 

[yinzhengjie@s101 download]$ hdfs dfs -mkdir -p /home/yinzhengjie/data
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ hdfs dfs -ls -R /
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
drwxr-xr-x - yinzhengjie supergroup 0 2018-07-27 03:44 /home
drwxr-xr-x - yinzhengjie supergroup 0 2018-07-27 03:44 /home/yinzhengjie
drwxr-xr-x - yinzhengjie supergroup 0 2018-07-27 03:44 /home/yinzhengjie/data
[yinzhengjie@s101 download]$ 

[yinzhengjie@s101 download]$ hdfs dfs -put temp /home/yinzhengjie/data
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$
[yinzhengjie@s101 download]$ hdfs dfs -ls -R /
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
drwxr-xr-x - yinzhengjie supergroup 0 2018-07-27 04:50 /home
drwxr-xr-x - yinzhengjie supergroup 0 2018-07-27 04:50 /home/yinzhengjie
drwxr-xr-x - yinzhengjie supergroup 0 2018-07-27 04:51 /home/yinzhengjie/data
-rw-r--r-- 3 yinzhengjie supergroup 5936 2018-07-27 04:51 /home/yinzhengjie/data/temp
[yinzhengjie@s101 download]$ 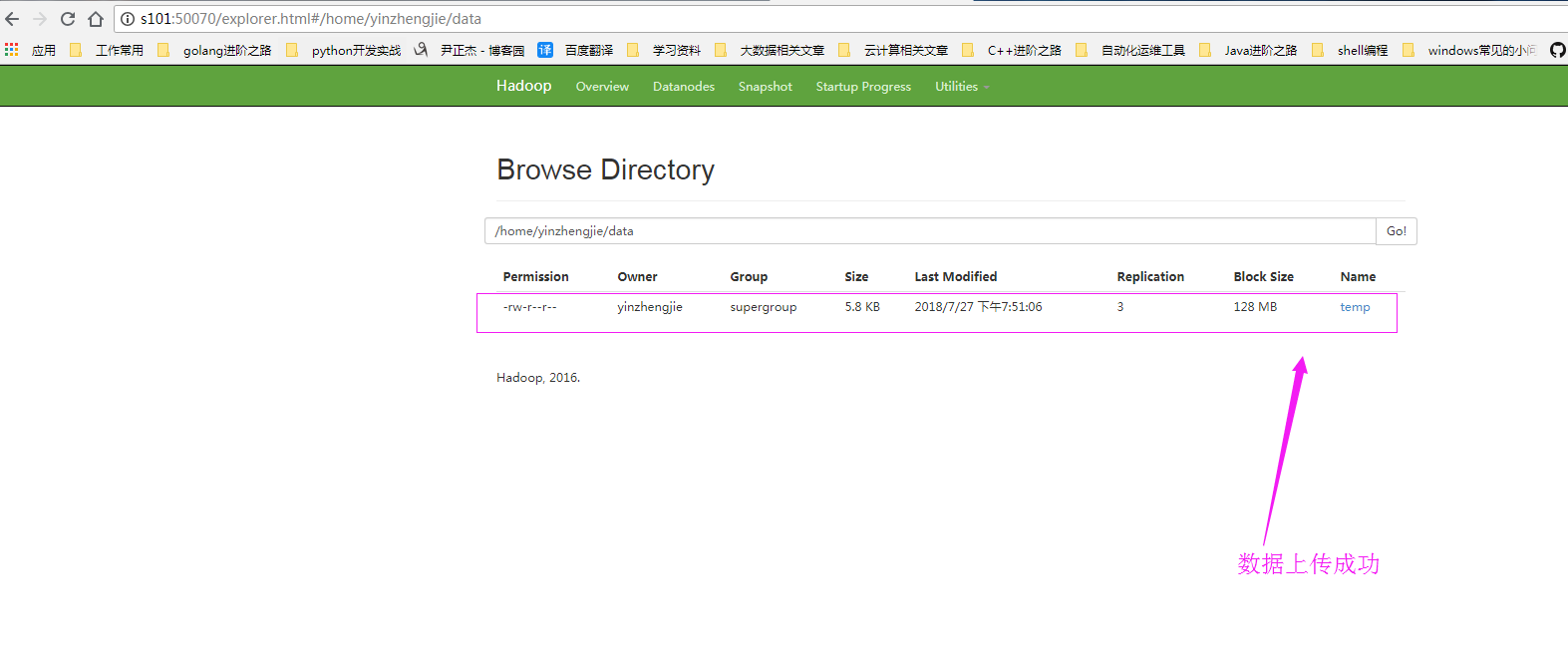
二.部署Spark集群
1>.创建slaves文件
[yinzhengjie@s101 ~]$ cp /soft/spark/conf/slaves.template /soft/spark/conf/slaves
[yinzhengjie@s101 ~]$ more /soft/spark/conf/slaves | grep -v ^# | grep -v ^$
s102
s103
s104
[yinzhengjie@s101 ~]$2>.修改spark-env.sh配置文件
[yinzhengjie@s101 ~]$ cp /soft/spark/conf/spark-env.sh.template /soft/spark/conf/spark-env.sh
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ echo export JAVA_HOME=/soft/jdk >> /soft/spark/conf/spark-env.sh
[yinzhengjie@s101 ~]$ echo SPARK_MASTER_HOST=s101 >> /soft/spark/conf/spark-env.sh
[yinzhengjie@s101 ~]$ echo SPARK_MASTER_PORT=7077 >> /soft/spark/conf/spark-env.sh
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ grep -v ^# /soft/spark/conf/spark-env.sh | grep -v ^$
export JAVA_HOME=/soft/jdk
SPARK_MASTER_HOST=s101
SPARK_MASTER_PORT=7077
[yinzhengjie@s101 ~]$
3>.将s101机器上的spark环境进行分发
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark
spark/ spark-2.1.0-bin-hadoop2.7/
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark
spark/ spark-2.1.0-bin-hadoop2.7/
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark/
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
=========== s105 %file ===========
命令执行成功
[yinzhengjie@s101 ~]$ xrsync.sh /soft/spark-2.1.0-bin-hadoop2.7/
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
=========== s105 %file ===========
命令执行成功
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ su root
Password:
[root@s101 yinzhengjie]#
[root@s101 yinzhengjie]# xrsync.sh /etc/profile
=========== s102 %file ===========
命令执行成功
=========== s103 %file ===========
命令执行成功
=========== s104 %file ===========
命令执行成功
=========== s105 %file ===========
命令执行成功
[root@s101 yinzhengjie]#
[root@s101 yinzhengjie]# exit
exit
[yinzhengjie@s101 ~]$4>.在所有的spark节点的conf/目录创建core-site.xml和hdfs-site.xml软连接文件
[yinzhengjie@s101 ~]$ xcall.sh "ln -s /soft/hadoop/etc/hadoop/core-site.xml /soft/spark/conf/core-site.xml"
============= s101 ln -s /soft/hadoop/etc/hadoop/core-site.xml /soft/spark/conf/core-site.xml ============
命令执行成功
============= s102 ln -s /soft/hadoop/etc/hadoop/core-site.xml /soft/spark/conf/core-site.xml ============
命令执行成功
============= s103 ln -s /soft/hadoop/etc/hadoop/core-site.xml /soft/spark/conf/core-site.xml ============
命令执行成功
============= s104 ln -s /soft/hadoop/etc/hadoop/core-site.xml /soft/spark/conf/core-site.xml ============
命令执行成功
============= s105 ln -s /soft/hadoop/etc/hadoop/core-site.xml /soft/spark/conf/core-site.xml ============
命令执行成功
[yinzhengjie@s101 ~]$ xcall.sh "ln -s /soft/hadoop/etc/hadoop/hdfs-site.xml /soft/spark/conf/hdfs-site.xml"
============= s101 ln -s /soft/hadoop/etc/hadoop/hdfs-site.xml /soft/spark/conf/hdfs-site.xml ============
命令执行成功
============= s102 ln -s /soft/hadoop/etc/hadoop/hdfs-site.xml /soft/spark/conf/hdfs-site.xml ============
命令执行成功
============= s103 ln -s /soft/hadoop/etc/hadoop/hdfs-site.xml /soft/spark/conf/hdfs-site.xml ============
命令执行成功
============= s104 ln -s /soft/hadoop/etc/hadoop/hdfs-site.xml /soft/spark/conf/hdfs-site.xml ============
命令执行成功
============= s105 ln -s /soft/hadoop/etc/hadoop/hdfs-site.xml /soft/spark/conf/hdfs-site.xml ============
命令执行成功
[yinzhengjie@s101 ~]$5>.启动Spark集群
[yinzhengjie@s101 ~]$ /soft/spark/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.master.Master-1-s101.out
s102: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s102.out
s104: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s104.out
s103: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/logs/spark-yinzhengjie-org.apache.spark.deploy.worker.Worker-1-s103.out
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
7766 NameNode
8070 DFSZKFailoverController
8890 Master
8974 Jps
命令执行成功
============= s102 jps ============
4336 DataNode
4114 QuorumPeerMain
4744 Worker
4218 JournalNode
4795 Jps
命令执行成功
============= s103 jps ============
4736 Worker
4787 Jps
4230 JournalNode
4121 QuorumPeerMain
4347 DataNode
命令执行成功
============= s104 jps ============
7489 Worker
7540 Jps
6983 JournalNode
7099 DataNode
6879 QuorumPeerMain
命令执行成功
============= s105 jps ============
7456 DFSZKFailoverController
8038 Jps
7356 NameNode
命令执行成功
[yinzhengjie@s101 ~]$6>.启动spark-shell连接到spark集群


[yinzhengjie@s101 ~]$ spark-shell --master spark://s101:7077
Using Spark''s default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/07/27 05:19:08 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/07/27 05:19:12 WARN General: Plugin (Bundle) "org.datanucleus.api.jdo" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/soft/spark-2.1.0-bin-hadoop2.7/jars/datanucleus-api-jdo-3.2.6.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/soft/spark/jars/datanucleus-api-jdo-3.2.6.jar."
18/07/27 05:19:12 WARN General: Plugin (Bundle) "org.datanucleus" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/soft/spark/jars/datanucleus-core-3.2.10.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/soft/spark-2.1.0-bin-hadoop2.7/jars/datanucleus-core-3.2.10.jar."
18/07/27 05:19:12 WARN General: Plugin (Bundle) "org.datanucleus.store.rdbms" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/soft/spark-2.1.0-bin-hadoop2.7/jars/datanucleus-rdbms-3.2.9.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/soft/spark/jars/datanucleus-rdbms-3.2.9.jar."
18/07/27 05:19:22 ERROR ObjectStore: Version information found in metastore differs 2.1.0 from expected schema version 1.2.0. Schema verififcation is disabled hive.metastore.schema.verification so setting version.
18/07/27 05:19:22 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
18/07/27 05:19:26 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://172.30.100.101:4040
Spark context available as ''sc'' (master = spark://s101:7077, app id = app-20180727051910-0000).
Spark session available as ''spark''.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ ''_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>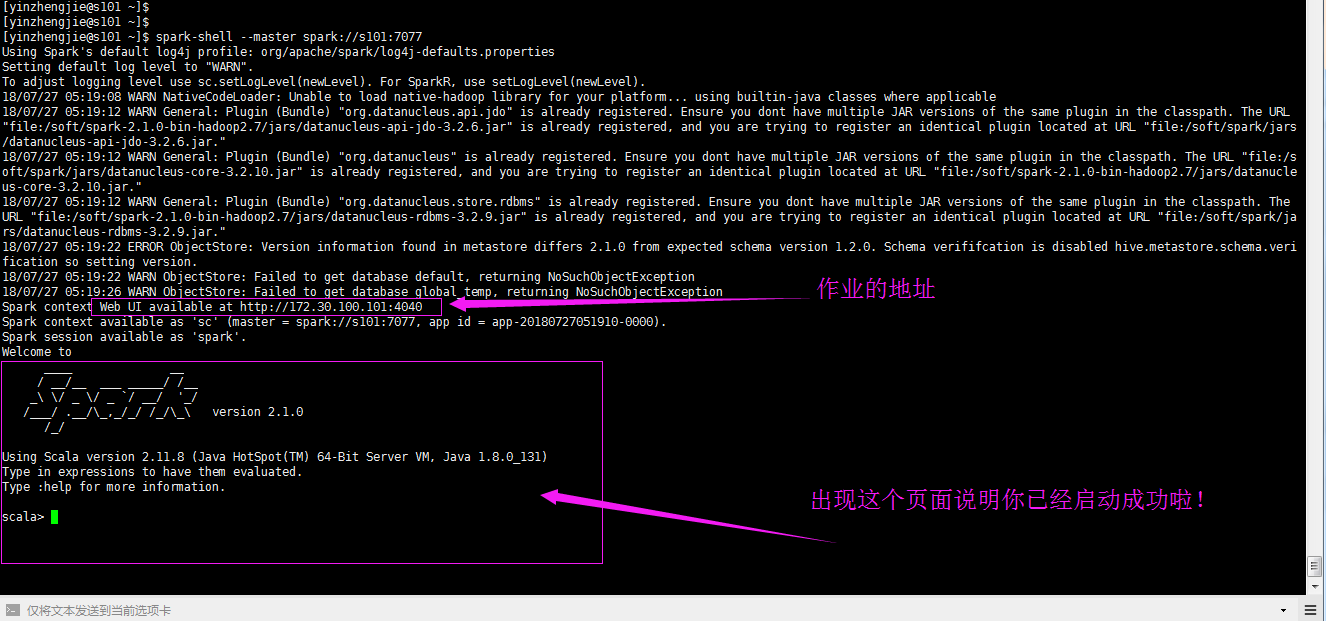
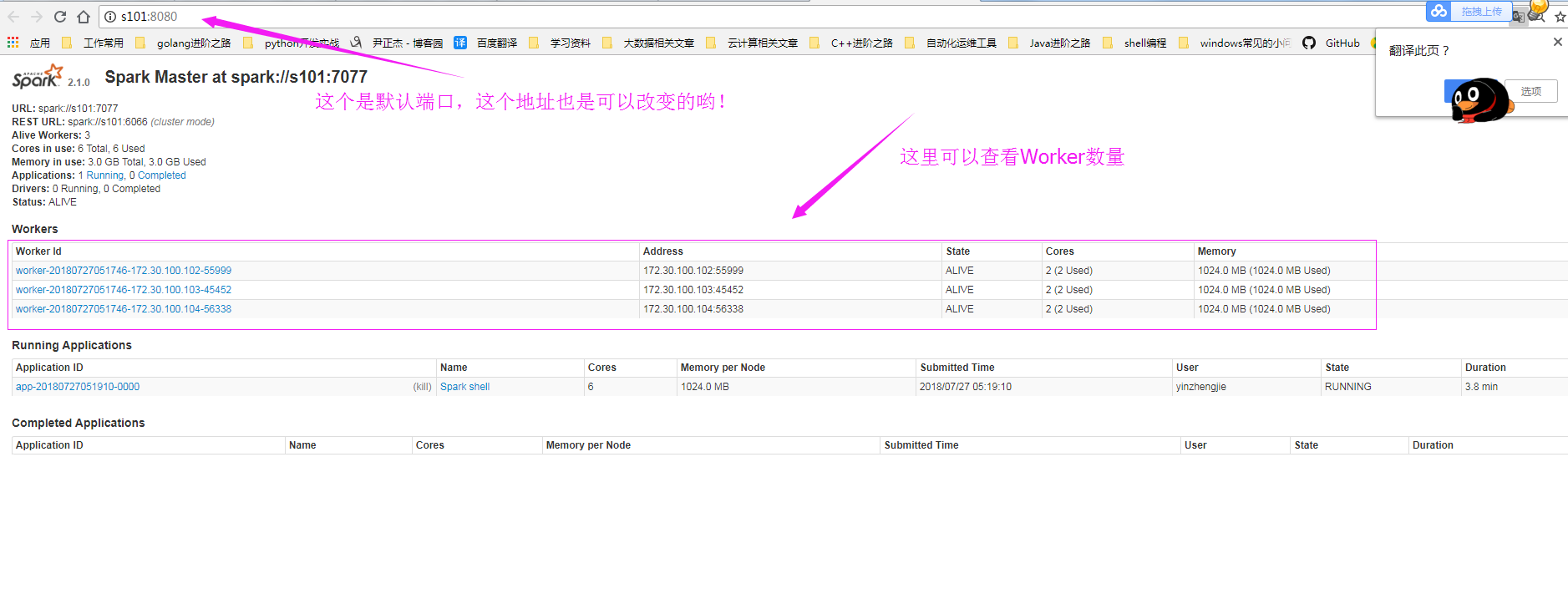
7>.查看WebUI界面
8>.编写程序在Spark集群上实现WordCount
val rdd1 = sc.parallelize(Array[String]("hello world1" , "hello world2" , "hello world3"))
rdd1.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect.sortBy(t=> -t._2 )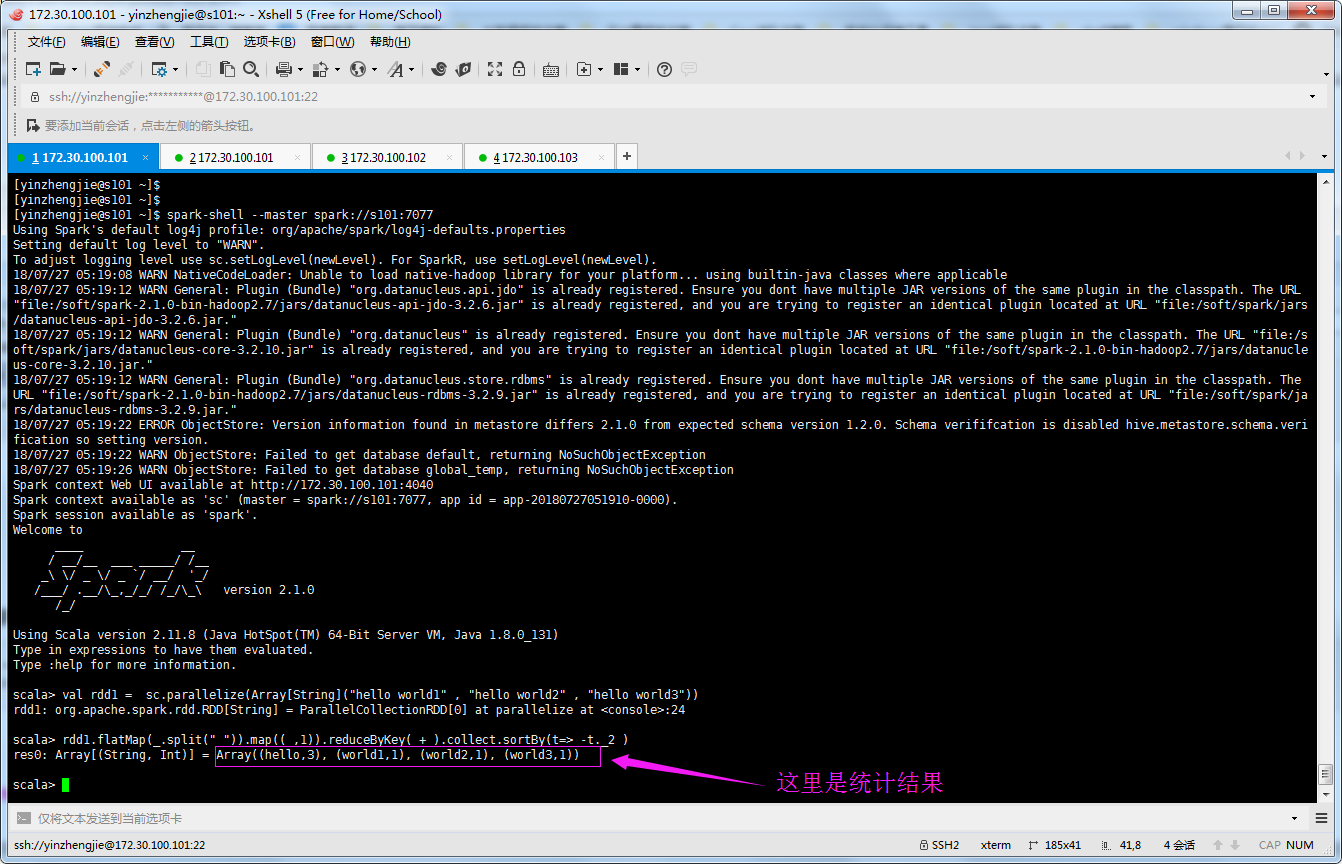
三.在Spark集群中执行代码
1>.Create JAR from Moudles
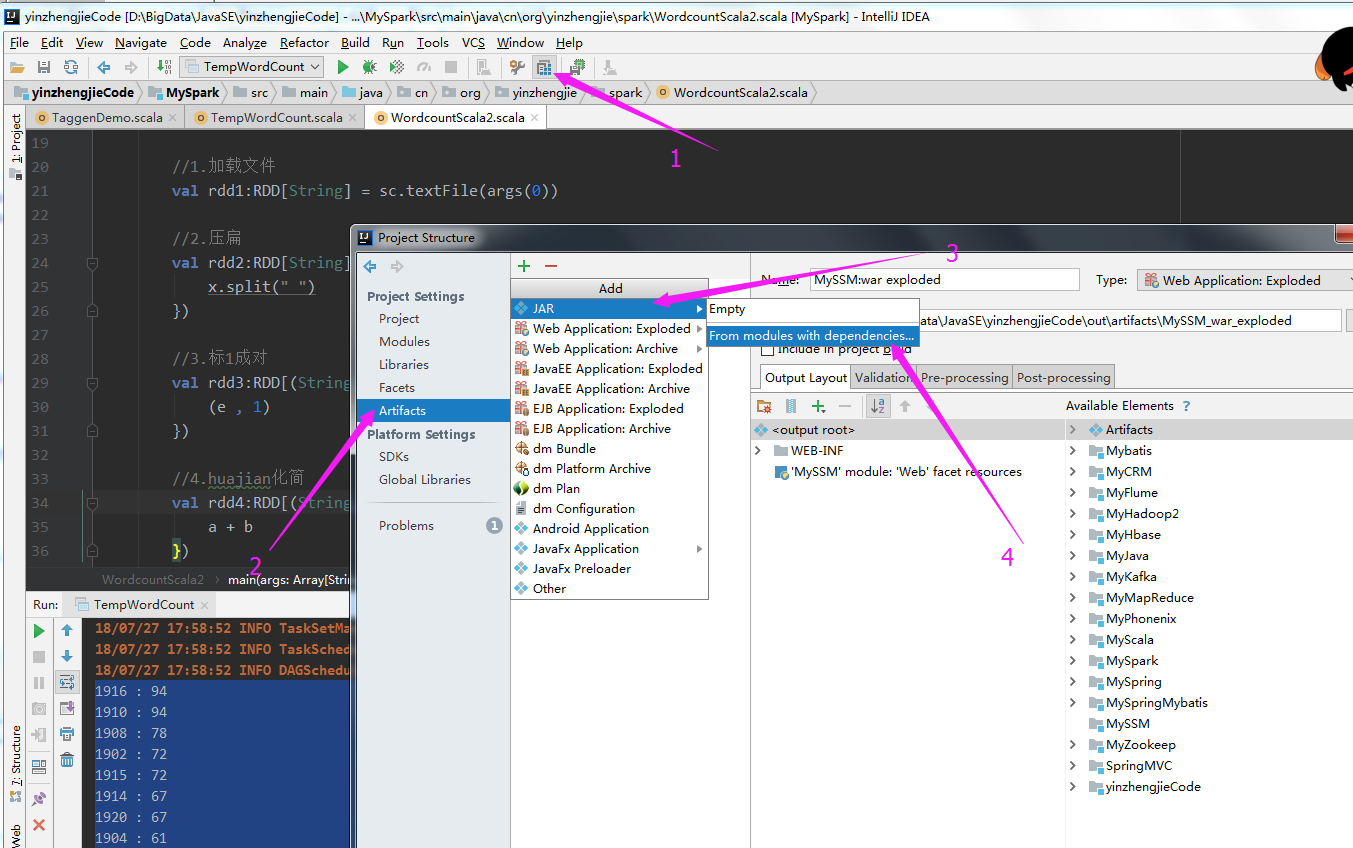
2>.选择需要打包的项目
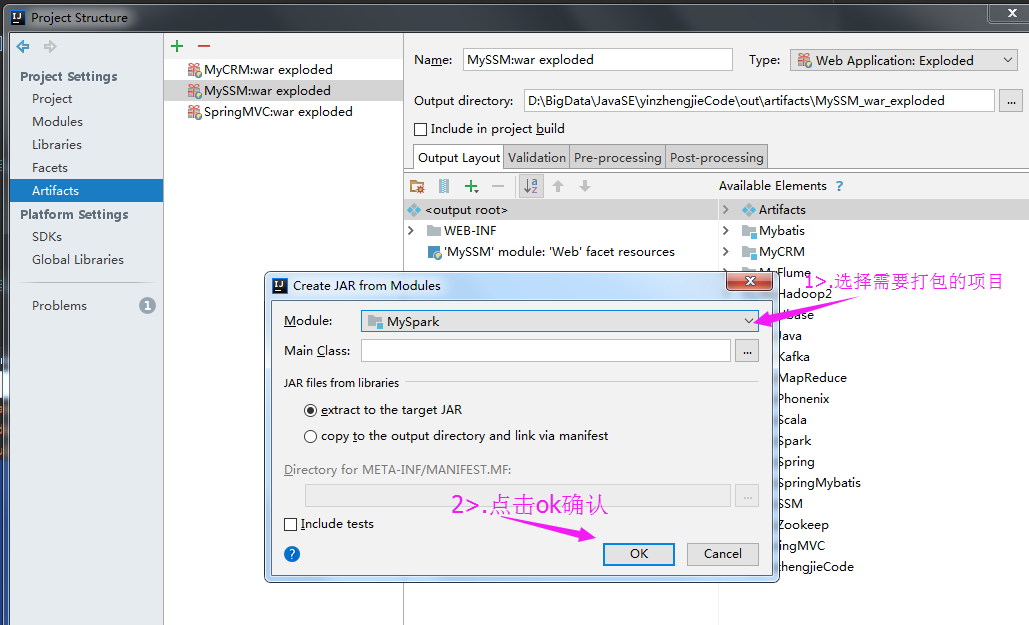
3>.删除第三方类库
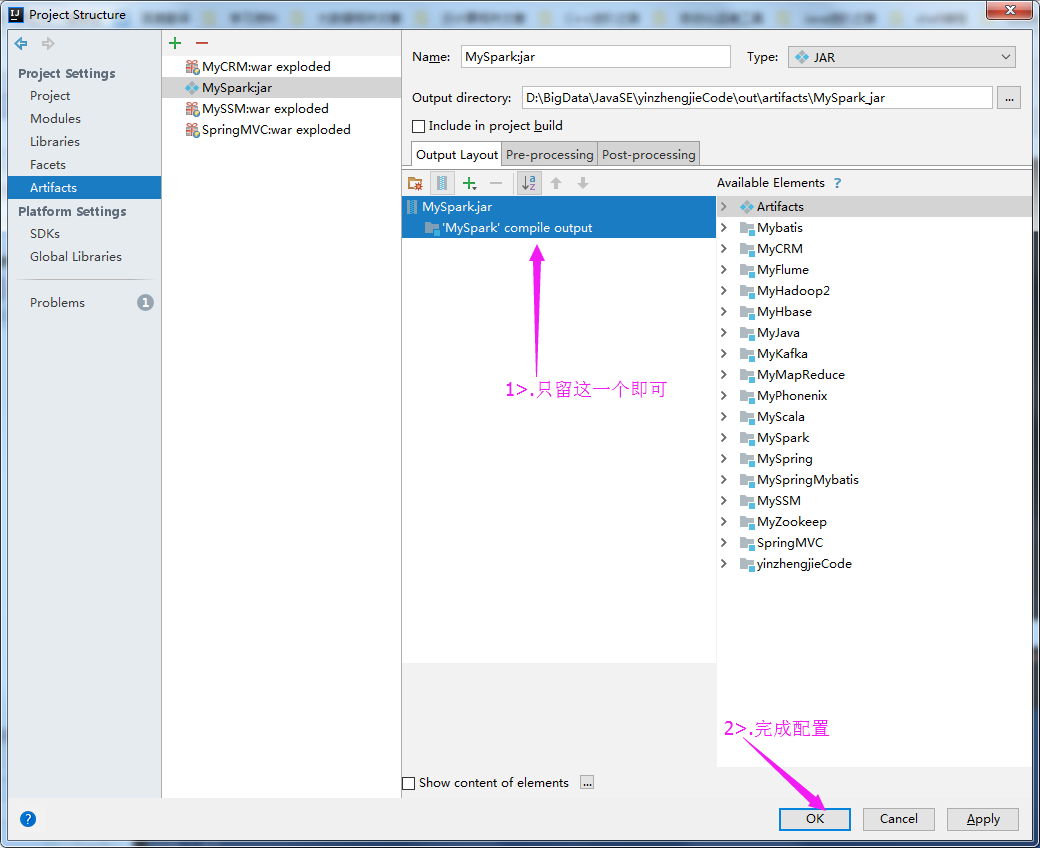
4>.点击Build Artifacts....
5>.选择build
6>.查看编译后的文件
7>.将编译后的文件上传到服务器上
8>.

Spark - Standalone模式
Spark
Spark的部分内容和之前Spark系列重合,但是有些细节之前没有深入。
Master启动
基于高可用的考虑,Master会启动多个,但是只能有一个Master是提供服务的(ALIVE状态),其他Master都是STANDBY状态。
zookeeper集群的左右,一个是用来选举,另外一个是保存持久化Application、Driver、Executor的信息,便于恢复。

Worker启动
Worker在启动的时候,就会向Master进行注册,注册时需要上传workid,host,端口以及cup核心数,内存大小。
由于Master是高可用的,所以刚开始Worker并不知道ALIVE节点是哪个,于是他就会把注册请求发送给每一个Master节点。

Worker只有注册成功,才会被Master调用,所以为了保证注册成功,Worker会进行不断的尝试。
一共尝试的次数是16次,为了避免所有的Worker同一时间发送心跳,给Master造成压力,所以发送心跳的间隔时间是随机的。
前面6次的心跳间隔时间是5~15s之间,后面10次的心跳间隔时间是30~90s之间。
如果在这16次内注册成功,那就会取消尝试。如果16次都没成功,那这个Worker也没必要启动了,直接退出Worker进程。
这里重试的和刚开始注册的时候,有些不同。有可能因为某些原因导致重试,但是这个时候Worker是有Master的ALIVE节点信息,那Worker注册的时候,就直接往ALIVE节点注册就好了,不用每个Master都发送注册请求。
Master接收注册时,会看看自己是不是ALIVE节点,如果是STANDBY节点,那直接跟Worker说我是STANDBY节点,Worker知道他是STANDBY节点,就不做任何处理。

然后Master就会看这个Worker是否注册过了(根据worker注册提供的workid),如果注册过了,就跟Worker说,注册失败了。
Worker接收到注册失败的信息,就会看看我有木有注册成功啊(注册成功会有变量保存),如果注册成功,就忽略这条消息,知道自己是重复注册。
如果发现自己没注册成功,Master也说没注册成功,那就是没注册成功,所以退出Worker进程。

如果既不是STANDBY节点,Worker也没注册过,那就保存Worker的相应的信息,进行持久化,然后告知Worker已经注册成功。

Worker接收到成功后,就会把变量更改为注册成功(上面判断有用到),然后记录Master的地址(后面请求直接发这个地址了),取消注册的重试任务(已经成功了就不需要再尝试注册了)。
最后会发状态给Master,由于刚开始注册,Worker中并没有Driver和Executor,所以Master不会处理。
Master如何知道Worker存活
Worker注册成功后,还有一个非常重要的事情,就是发送心跳,维持状态。发送心跳的时候,直接发送workerid就好。
Master接收请求后,先看看是否注册过,如果没有注册过,就会让Worker重新注册,就会重复上面的注册流程。如果注册过,就修改Worker最后的心跳时间。

Master会有一个每隔60s的定时任务,对超过60s没有发送的Worker进行处理,会把这个Worker标记为DEAD状态,并移除其他相关内存(idToWorker用于映射workerid和Worker的关系,addressToWorker用于映射地址和Worker的关系)。
如果Worker已经是DEAD状态了,那超过960s就把Worker信息也移除。
比如60s没发心跳,此时Master会移除相关内容,然后在960s内,Worker重启后进行注册,那就会把Worker中为DEAD状态的Worker删除,再重新加新的Worker信息。

Driver启动
Driver在启动后需要向Master注册Application信息,和Worker注册Master一样,Driver也不知道哪个是ALIVE节点,所以他也向所有的Master进行注册。
注册信息包括Application的名称,Application需要的最大内核数,每个Executor所需要的内存大小,每个Executor所需的内核数,执行Executor的命令等信息。
这里的注册也有重试次数,最大重试3次,每次间隔20s,注册成功后,就会取消重试。
Master收到请求后,如果是STANDBY节点,那不做处理,也不回复任何信息(这个和Worker注册不一样,Wokrer那边回回复信息,但是Worker不处理)。
如果不是STANDBY节点,那就会把Application信息保存内存中,并做持久化。

接着就会给Driver发送已经注册成功的消息,Driver接收到消息,就会记录Master的信息,以及内部标识已经注册成功,不需要再重试。

Master如何知道Driver存活
Driver和Master之间并没有心跳,不像Worker会定时发送心跳,Master根据心跳移除过期的Worker,那Master怎么知道Driver是否退出呢?
第一种方式是Driver主动告知Master,第二种方式是Driver不正常退出,Master一旦监听到Driver退出了。这两种方式都会取消Application的注册。
Master接收到取消注册Application的消息后,就会移除缓存的Application及Application相关的Driver信息。
对于Driver,有可能还存在运行的Executor,就会发消息给Driver,让他杀死Executor,Driver收到消息后就会停止Application。

对应Worker,Master会群发给所有的Worker,告知这个Application已完成,Worker收到消息后,会清理Driver的临时文件。

最后把Application的信息持久化,并且告知其他Worker这个Application已完成。
Executor启动
Master在资源调度的时候,会让Worker启动Executor。
Worker接收到消息后,会判断是否是STANDBY节点的Master发送的消息,如果不是则忽略。
如果是,Worker就会创建一个线程,用来启动一个Executor的进程,启动Executor的进程后会回复Master说Executor已经启动成功。
Master知道Executor启动成功,也会告知Driver,你的Executor我已经帮你启动了。由于Executor并没有结束,Driver并没有做其他处理。

Executor启动后,就会向Driver进行注册,Driver先判断是否已经注册过或者在黑名单里,如果是,返回失败,如果不是,则保存这个Executor的信息,并告知Executor已经注册成功。
Driver在Executor注册时,还做了一件事,就是把注册信息发送给事件总线。Driver里还有有一个心跳接收器,用于管理Executor状态的。
这个心跳接收器会对总线的事件进行监听,当发现有Executor新增的时候,就会记录这个Executor的id和时间。

Worker如何知道Executor存活
Worker创建线程用来启动Executor进程的时候,这个线程创建完并不会直接退出,而是一直等待获取Executor进程的退出状态。
获取后就会把状态发送给Worker,Worker再把状态转发给Master,并更改自身的内存、CPU信息。
Master发现Executor执行完了(不管失败还是成功),就会更新内存信息,并且把状态转发给Driver。
Driver收到状态后,发现Executor执行完了,会发移除Executor的事件给事件总线。
心跳接收器会对总线的事件进行监听,当发现有Executor移除的时候,就会移除Executor。

Executor如何知道Worker存活
Executor有一个WorkerWatcher,当Worker进程退出、连接断开、网络出错时,就会被WorkerWatcher监听到,进而终止Executor的进程。

Driver如何知道Executor存活
Executor收到Drvier注册成功的消息后,就开始创建Executor对象,这个对象实例化后,就会开始对Driver的心跳请求,由于可能会多个Executor启动,所以为了避免同一时间请求过多,这里的延时时间会加一个随机值。
心跳接收器接收到心跳请求后,先看看这个Executor是否已经注册了,如果没有,让Executor重新注册,如果注册过了,则更新时间。
心跳接收器有一个定时任务,会扫描每个Executor最后上报的时间,如果Executor已经超过一定时间没有发心跳了,就会把这个Executor的信息从内存中移除,并且提交“杀死”Executor的任务。
这个任务最后会发送到ClientEndpoint,ClientEndpoint再转发给Master。
今天关于Spark Standalone 提交模式和spark standalone提交任务的分享就到这里,希望大家有所收获,若想了解更多关于04、Spark Standalone集群搭建、Java Web 提交任务到 Spark Standalone 集群并监控、Scala进阶之路-Spark独立模式(Standalone)集群部署、Spark - Standalone模式等相关知识,可以在本站进行查询。
本文标签:




