想了解Scikit学习OneHotEncoder拟合和变换错误:ValueError:X的形状与拟合期间不同的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于rational拟合的相关问题,此
想了解Scikit学习OneHotEncoder拟合和变换错误:ValueError:X的形状与拟合期间不同的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于rational拟合的相关问题,此外,我们还将为您介绍关于ANN 过度拟合的问题——可能是由于 OneHotEncoder 问题、CDH 报错:UnicodeEncodeError: ''ascii'' codec can''t encode characters in position 0-11: or...、django错误:ValueError: Dependency on app with no migrations: apps、Django错误:ValueError: Dependency on app with no migrations: UserManagement的新知识。
本文目录一览:- Scikit学习OneHotEncoder拟合和变换错误:ValueError:X的形状与拟合期间不同(rational拟合)
- ANN 过度拟合的问题——可能是由于 OneHotEncoder 问题
- CDH 报错:UnicodeEncodeError: ''ascii'' codec can''t encode characters in position 0-11: or...
- django错误:ValueError: Dependency on app with no migrations: apps
- Django错误:ValueError: Dependency on app with no migrations: UserManagement
")
Scikit学习OneHotEncoder拟合和变换错误:ValueError:X的形状与拟合期间不同(rational拟合)
下面是我的代码。
我知道为什么在转换过程中会发生错误。这是因为特征列表在拟合和变换期间不匹配。我该如何解决?我如何才能将其余所有功能都设为0?
之后,我想将其用于SGD分类器的部分拟合。
Jupyter QtConsole 4.3.1Python 3.6.2 |Anaconda custom (64-bit)| (default, Sep 21 2017, 18:29:43)Type ''copyright'', ''credits'' or ''license'' for more informationIPython 6.1.0 -- An enhanced Interactive Python. Type ''?'' for help.import pandas as pdfrom sklearn.preprocessing import OneHotEncoderinput_df = pd.DataFrame(dict(fruit=[''Apple'', ''Orange'', ''Pine''], color=[''Red'', ''Orange'',''Green''], is_sweet = [0,0,1], country=[''USA'',''India'',''Asia'']))input_dfOut[1]: color country fruit is_sweet0 Red USA Apple 01 Orange India Orange 02 Green Asia Pine 1filtered_df = input_df.apply(pd.to_numeric, errors=''ignore'')filtered_df.info()# apply one hot encoderefreshed_df = pd.get_dummies(filtered_df)refreshed_df<class ''pandas.core.frame.DataFrame''>RangeIndex: 3 entries, 0 to 2Data columns (total 4 columns):color 3 non-null objectcountry 3 non-null objectfruit 3 non-null objectis_sweet 3 non-null int64dtypes: int64(1), object(3)memory usage: 176.0+ bytesOut[2]: is_sweet color_Green color_Orange color_Red country_Asia \0 0 0 0 1 01 0 0 1 0 02 1 1 0 0 1 country_India country_USA fruit_Apple fruit_Orange fruit_Pine0 0 1 1 0 01 1 0 0 1 02 0 0 0 0 1enc = OneHotEncoder()enc.fit(refreshed_df)Out[3]:OneHotEncoder(categorical_features=''all'', dtype=<class ''numpy.float64''>, handle_unknown=''error'', n_values=''auto'', sparse=True)new_df = pd.DataFrame(dict(fruit=[''Apple''], color=[''Red''], is_sweet = [0], country=[''USA'']))new_dfOut[4]: color country fruit is_sweet0 Red USA Apple 0filtered_df1 = new_df.apply(pd.to_numeric, errors=''ignore'')filtered_df1.info()# apply one hot encoderefreshed_df1 = pd.get_dummies(filtered_df1)refreshed_df1<class ''pandas.core.frame.DataFrame''>RangeIndex: 1 entries, 0 to 0Data columns (total 4 columns):color 1 non-null objectcountry 1 non-null objectfruit 1 non-null objectis_sweet 1 non-null int64dtypes: int64(1), object(3)memory usage: 112.0+ bytesOut[5]: is_sweet color_Red country_USA fruit_Apple0 0 1 1 1enc.transform(refreshed_df1)---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-6-33a6a884ba3f> in <module>()----> 1 enc.transform(refreshed_df1)~/anaconda3/lib/python3.6/site-packages/sklearn/preprocessing/data.py in transform(self, X) 2073 """ 2074 return _transform_selected(X, self._transform,-> 2075 self.categorical_features, copy=True) 2076 2077~/anaconda3/lib/python3.6/site-packages/sklearn/preprocessing/data.py in _transform_selected(X, transform, selected, copy) 1810 1811 if isinstance(selected, six.string_types) and selected == "all":-> 1812 return transform(X) 1813 1814 if len(selected) == 0:~/anaconda3/lib/python3.6/site-packages/sklearn/preprocessing/data.py in _transform(self, X) 2030 raise ValueError("X has different shape than during fitting." 2031 " Expected %d, got %d."-> 2032 % (indices.shape[0] - 1, n_features)) 2033 2034 # We use only those categorical features of X that are known using fit.ValueError: X has different shape than during fitting. Expected 10, got 4.答案1
小编典典pd.get_dummies()不需要使用LabelEncoder +
OneHotEncoder,它们可以存储原始值,然后在新数据上使用它们。
像下面那样更改代码将为您提供所需的结果。
import pandas as pdfrom sklearn.preprocessing import OneHotEncoder, LabelEncoderinput_df = pd.DataFrame(dict(fruit=[''Apple'', ''Orange'', ''Pine''], color=[''Red'', ''Orange'',''Green''], is_sweet = [0,0,1], country=[''USA'',''India'',''Asia'']))filtered_df = input_df.apply(pd.to_numeric, errors=''ignore'')# This is what you needle_dict = {}for col in filtered_df.columns: le_dict[col] = LabelEncoder().fit(filtered_df[col]) filtered_df[col] = le_dict[col].transform(filtered_df[col])enc = OneHotEncoder()enc.fit(filtered_df)refreshed_df = enc.transform(filtered_df).toarray()new_df = pd.DataFrame(dict(fruit=[''Apple''], color=[''Red''], is_sweet = [0], country=[''USA'']))for col in new_df.columns: new_df[col] = le_dict[col].transform(new_df[col])new_refreshed_df = enc.transform(new_df).toarray()print(filtered_df) color country fruit is_sweet0 2 2 0 01 1 1 1 02 0 0 2 1print(refreshed_df)[[ 0. 0. 1. 0. 0. 1. 1. 0. 0. 1. 0.] [ 0. 1. 0. 0. 1. 0. 0. 1. 0. 1. 0.] [ 1. 0. 0. 1. 0. 0. 0. 0. 1. 0. 1.]]print(new_df) color country fruit is_sweet0 2 2 0 0print(new_refreshed_df)[[ 0. 0. 1. 0. 0. 1. 1. 0. 0. 1. 0.]]
ANN 过度拟合的问题——可能是由于 OneHotEncoder 问题
如何解决ANN 过度拟合的问题——可能是由于 OneHotEncoder 问题?
我一直致力于构建一个简单的 ANN,因为我是新手,虽然我不再收到任何错误,但在第一个 epoch 之后,准确度跃升至 1.0,这表明过度拟合。我确保因变量 (y) 列不在 X 和 y 数组中。
我从 stackoverflow 上的另一篇文章中获得的一个热门编码器类,感觉可能我没有正确实现它,这导致了问题。
我认为这条线路调用课程可能有问题,但我不是 100% 确定。
任何有关如何解决过度拟合或改进模型的说明都将不胜感激。
最后,对于上下文:df(找到 https://www.kaggle.com/psvishnu/bank-direct-marketing)包含 7 个自变量的数据,这些变量描述了银行客户资料 - ei、工资、信用卡数量、债务等
y = 如果客户订阅了定期存款? (二进制:“是”,“否”)
X = multicolumnLabelEncoder(columns = [''housing'',''loan'',''default'']).fit_transform(df_ann)
完整代码片段
import numpy as np
import pandas as pd
import tensorflow as tf
#Importing Dataset
df = pd.read_csv(''bank-full.csv'',sep='';'')
df_ann = df[[''age'',''job'',''marital'',''education'',''default'',''balance'',''housing'',''y'']]
X = df_ann.iloc[:,:7].values
y = df_ann.iloc[:,-1].values
#Encoding Categorical Data
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
le = LabelEncoder()
y[:] = le.fit_transform(y[:])
class multicolumnLabelEncoder:
def __init__(self,columns = None):
self.columns = columns # array of column names to encode
def fit(self,X,y=None):
return self # not relevant here
''''''
Transforms columns of X specified in self.columns using
LabelEncoder(). If no columns specified,transforms all
columns in X.
''''''
def transform(self,X):
output = X.copy()
if self.columns is not None:
for col in self.columns:
output[col] = LabelEncoder().fit_transform(output[col])
else:
for colname,col in output.iteritems():
output[colname] = LabelEncoder().fit_transform(col)
return output
def fit_transform(self,y=None):
return self.fit(X,y).transform(X)
X = multicolumnLabelEncoder(columns = [''housing'',''default'']).fit_transform(df_ann)
#OneHotEncoder (3d+)
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[(''encoder'',OneHotEncoder(handle_unkNown=''ignore''),[''job'',''education''])],remainder=''passthrough'')
X = np.array(ct.fit_transform(X))
X = np.asarray(X).astype(''float32'')
y= np.asarray(y).astype(''float32'')
#Split to training/test
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 0)
#Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Building the ANN
#Initializing
ann = tf.keras.models.Sequential()
#Adding Input Layer
ann.add(tf.keras.layers.Dense(units=6,activation=''relu''))
#Second Hidden Layer
ann.add(tf.keras.layers.Dense(units=6,activation=''relu''))
#Output Layer
ann.add(tf.keras.layers.Dense(units=1,activation=''sigmoid''))
#Training ANN
ann.compile(optimizer = ''adam'',loss = ''binary_crossentropy'',metrics = [''accuracy''])
ann.fit(X_train,batch_size = 32,epochs = 200)
#Predicting Test Results
y_pred = ann.predict(X_test)
y_pred = (y_pred > 0.5)
print(np.concatenate((y_pred.reshape(len(y_pred),1),y_test.reshape(len(y_test),1)),1))
#Confusion Matrix
from sklearn.metrics import confusion_matrix,accuracy_score
cm = confusion_matrix(y_test,y_pred)
print(cm)
accuracy_score(y_test,y_pred)
解决方法
您可以添加 dropout 层以避免过拟合:
ann = tf.keras.models.Sequential()
ann.add(tf.keras.layers.Dense(units=6,activation=''relu''))
ann.add(tf.keras.layers.Dropout(0.2))
ann.add(tf.keras.layers.Dense(units=6,activation=''relu''))
ann.add(tf.keras.layers.Dropout(0.5))
ann.add(tf.keras.layers.Dense(units=1,activation=''sigmoid''))
并更改epochs = 10,因为对于一个简单的数据来说,200 个时期太多了。
您可以添加 l1 和 l2 正则化:
kernel_regularizer=keras.regularizers.l2(0.01))
你可以添加辍学:
dropout = tf.keras.layers.Dropout(0.2)
在这里,您还可以尝试不同的 relu 变体,例如 ELU、LeakyReLU
Monte Carlo (MC) Dropout 你也可以试试。 访问https://arxiv.org/abs/1506.02142
试试
kernel_initializer="he_uniform"
# or
kernel_initializer="he_normal"

CDH 报错:UnicodeEncodeError: ''ascii'' codec can''t encode characters in position 0-11: or...
1.在CDH集群启动Hue服务时,出现了错误,如下图:
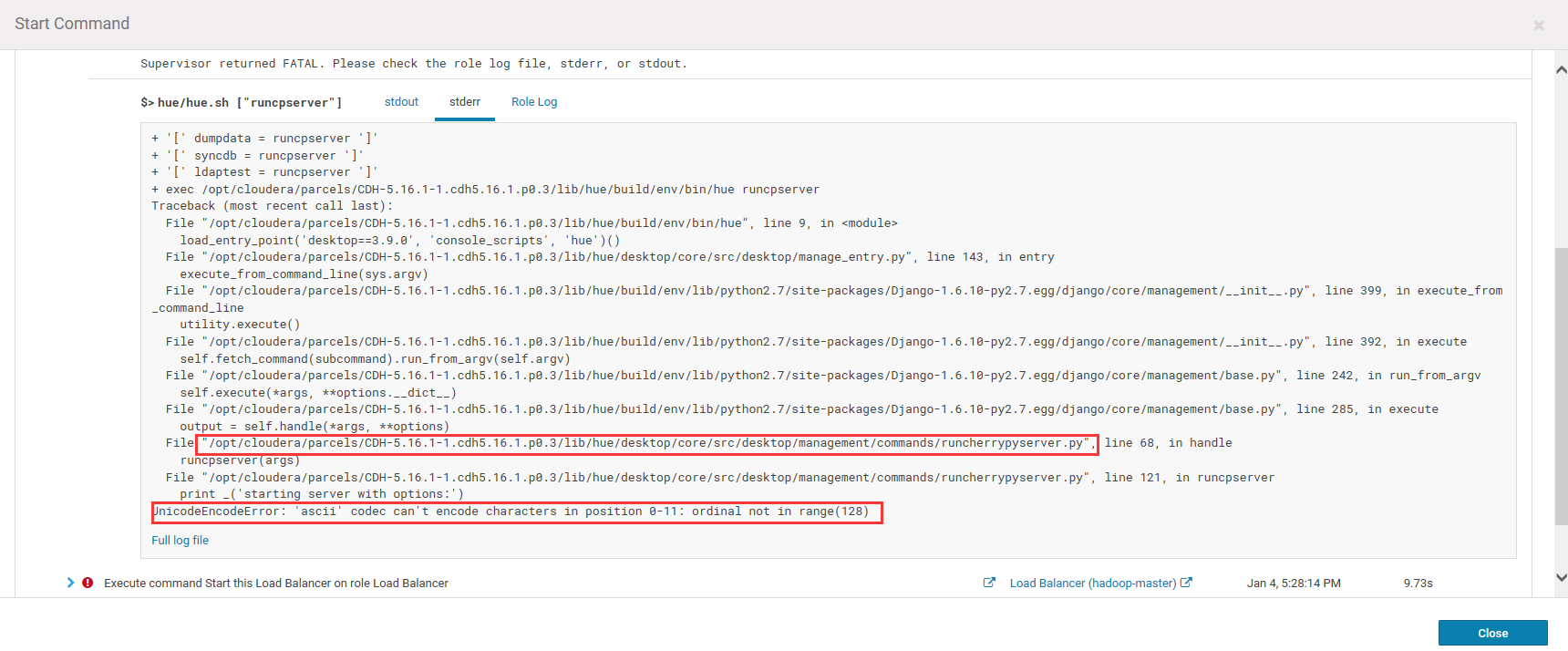
2.上图显示得知,是调用python文件(/opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hue/build/env/lib/python2.7/site-packages/Django-1.6.10-py2.7.egg/django/core/management/base.py)时出现了字符集错误。
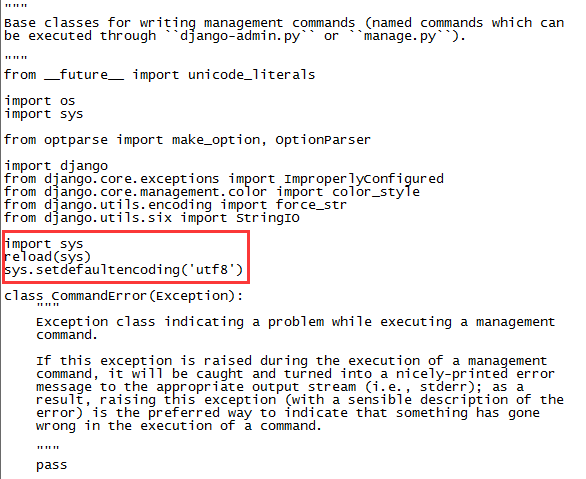
3.在master主机上修改该文件,增加py代码
import sys
reload(sys)
sys.setdefaultencoding(''utf8'')如下图:
4.重启Hue服务,问题解决。
以上。

django错误:ValueError: Dependency on app with no migrations: apps
背景:
python3.6
django=2.2
在不小心情况migrations中的文件,提示错误:
ValueError: Dependency on app with no migrations: apps
解决方法:
重新执行makemigrations,为apps应用程序创建迁移。
python manage.py makemigrations apps
执行migrate
python manage.py migrate

Django错误:ValueError: Dependency on app with no migrations: UserManagement
详细错误提示:
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/django/utils/autoreload.py", line 228, in wrapper
fn(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/django/core/management/commands/runserver.py", line 128, in inner_run
self.check_migrations()
File "/usr/local/lib/python2.7/dist-packages/django/core/management/base.py", line 422, in check_migrations
executor = MigrationExecutor(connections[DEFAULT_DB_ALIAS])
File "/usr/local/lib/python2.7/dist-packages/django/db/migrations/executor.py", line 20, in __init__
self.loader = MigrationLoader(self.connection)
File "/usr/local/lib/python2.7/dist-packages/django/db/migrations/loader.py", line 52, in __init__
self.build_graph()
File "/usr/local/lib/python2.7/dist-packages/django/db/migrations/loader.py", line 223, in build_graph
self.add_external_dependencies(key, migration)
File "/usr/local/lib/python2.7/dist-packages/django/db/migrations/loader.py", line 188, in add_external_dependencies
parent = self.check_key(parent, key[0])
File "/usr/local/lib/python2.7/dist-packages/django/db/migrations/loader.py", line 169, in check_key
raise ValueError("Dependency on app with no migrations: %s" % key[0])
ValueError: Dependency on app with no migrations: UserManagement
解决办法:
manage.py makemigrations UserManagement
为UserManagement创建迁移
相关文档介绍:https://docs.djangoproject.com/en/1.7/topics/migrations/#s-custom-fields
关于Scikit学习OneHotEncoder拟合和变换错误:ValueError:X的形状与拟合期间不同和rational拟合的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于ANN 过度拟合的问题——可能是由于 OneHotEncoder 问题、CDH 报错:UnicodeEncodeError: ''ascii'' codec can''t encode characters in position 0-11: or...、django错误:ValueError: Dependency on app with no migrations: apps、Django错误:ValueError: Dependency on app with no migrations: UserManagement等相关知识的信息别忘了在本站进行查找喔。
本文标签:




