本文将带您了解关于php–为什么要使用MySQLDB缓存?的新内容,同时我们还将为您解释php为什么要用框架的相关知识,另外,我们还将为您提供关于2023-05-24:为什么要使用Redis做缓存?、
本文将带您了解关于php – 为什么要使用MySQL DB缓存?的新内容,同时我们还将为您解释php为什么要用框架的相关知识,另外,我们还将为您提供关于2023-05-24:为什么要使用Redis做缓存?、MySQL InnoDB缓存、MySQL 社区经理:MySQL 8.4 InnoDB 参数默认值为什么要这么改?、MySQL为什么要使用B+树索引的实用信息。
本文目录一览:- php – 为什么要使用MySQL DB缓存?(php为什么要用框架)
- 2023-05-24:为什么要使用Redis做缓存?
- MySQL InnoDB缓存
- MySQL 社区经理:MySQL 8.4 InnoDB 参数默认值为什么要这么改?
- MySQL为什么要使用B+树索引
")
php – 为什么要使用MySQL DB缓存?(php为什么要用框架)
我目前正在开发两个严重依赖MySQL数据库的iOS应用程序.它们每个都有自己的API,由相应的应用程序请求,它运行从MysqL数据库请求数据的相关查询.
查询不同于简单,用户或“对象”:
SELECT `username`, `id`, `full_name` FROM `users` WHERE `id` = 1
INSERT INTO `users` (`full_name`, `username`, `email`, `password`, `signup_method`, `latitude`, `longitude`) VALUES (?, ?, ?, ?, ?, ?, ?)"
SELECT q.*, (SELECT COUNT(a.qid) FROM answers as a WHERE qid=q.id) AS a_count FROM questions as q ORDER BY a_count DESC LIMIT 1, 10
基于位置:
SELECT ( 6371 * acos( cos( radians(?) ) * cos( radians( latitude ) ) * cos( radians( longitude ) - radians(?) ) + sin( radians(?) ) * sin( radians( latitude ) ) ) ) AS distance FROM `users` HAVING distance <= 5 ORDER BY points DESC
SELECT * , (6371 * acos(cos(radians(latitude)) * cos(radians({$values['latitude']})) * cos(radians({$values['longitude']}) - radians(longitude)) + sin(radians(latitude)) * sin(radians({$values['latitude']})))) AS distance FROM `questions` HAVING distance <= ? ORDER by distance LIMIT ?,?
这些查询显然需要时间.特别是后者由于其引起的性能强度.
许多服务在其数据库旁边使用缓存层来提高性能.例如:
> Memcachd
> Redis
>等等.
我的问题是,在查询方面,何时应该使用缓存,以及使用缓存有什么好处?
谢谢,
麦克斯!
解决方法:
当缓存比从头开始生成结果更便宜时,您应该缓存.
这笔费用取决于:
>各种服务器和软件的处理能力.也许您的数据库服务器容量有限,但另一台服务器上的容量过剩.
>钱:购买更强大的硬件比建立缓存系统更便宜吗?
>从头开始生成结果的cpu成本与缓存的RAM成本.大多数情况下,DB服务器受cpu限制,而缓存服务器受内存限制.这是你决定在你的情况下升级哪个更便宜.
>从缓存中检索的速度与从db检索的速度.如果,正如您所说,查询是耗时的,并且从缓存中获取它们更便宜,缓存将加快您的请求.
>您的缓存项目需要刷新的频率.如果他们只持续几秒钟,那可能不值得麻烦.
>有一个方法来过期和刷新缓存的项目.这通常是一个非常棘手的问题.
>拥有管理额外复杂性的技术知识和时间.
但总是从源头开始.您是否检查了MysqL的慢查询日志,以查看哪些查询成本高昂?它可以帮助您查看缺少重要索引的位置以及哪些查询意外地长时间查看.来自Percona-Toolkit的[pt-query-digest] 1可以通过总结这个日志文件来提供帮助.在开始缓存之前优化数据库.
查看您的查询类型,在我看来,缓存结果甚至预加热缓存是值得的.
缓存的选择当然是重要的.我假设你已经在使用MysqL的内置查询缓存了吗?确保它已启用并且已分配足够的内存.像’SELECT username’这样的简单查询无论如何都很便宜,但也很容易被MysqL本身缓存.虽然内置查询缓存有很多限制,但很多原因都是查询未缓存或缓存被刷新.例如,简单地跳过具有函数的查询(例如基于位置的查询).阅读文档.
使用像Redis这样的缓存可以更好地控制缓存内容,缓存时间以及如何使其过期.关于如何实现这一点有很多想法,它们也取决于您的应用程序.看看网络.
我建议启用查询缓存,因为它简单又便宜并且有所帮助,我肯定会考虑为您的数据库实现内存缓存层.也许索引服务器,如Solr,具有基于位置的查询的内置方法,值得考虑.我们将它与MysqL一起使用.
Memcached和Redis是缓存的不错选择.我个人会选择Redis,因为它有更多的用例和可选的磁盘持久性,但这完全取决于你.也许你的选择框架有一些你可以在你的应用程序中使用的现有组件.
另一个提示:衡量一切.如果您知道什么需要时间,您只知道要优化或缓存的内容.此外,只有再次测量时,优化的结果才会明确.实现类似statsd的功能,并测量应用程序中的各种事件和时间.比不够好太多了.绘制结果图并随时间进行分析.出现了什么,你会感到惊讶.

2023-05-24:为什么要使用Redis做缓存?
2023-05-24:为什么要使用Redis做缓存?
答案2023-05-24:
缓存的好处
买啤酒和喝啤酒的例子可以帮助我们理解缓存的好处。
假设你在超市里买了一箱啤酒,如果你需要每次想喝啤酒就去超市购买,无疑会浪费很多时间和精力。而如果你将一部分啤酒放在家中的冰箱里,每次想喝啤酒时就从冰箱里取出来,那么就不需要频繁前往超市,提高了生活效率。
同样地,对于计算机系统来说,很多应用程序需要频繁地读取和写入数据,访问数据库等存储设备是一个比较耗时的过程。通过使用缓存技术,可以将常用的数据存储在内存中,在下一次访问时直接从缓存中获取,避免了频繁的 IO 操作,提高了系统的性能和响应速度。就像在家里放置了一部分啤酒,缓存能够为系统提供更快的访问速度和更高的效率,同时减少了数据库等存储设备的负载,降低了系统的成本和风险。
1.使用缓存的目的就是提升读写性能。实际业务场景下,更多的是为了提升读性能,带来更好的性能,带来更高的并发量。Redis 的读写性能比 Mysql 好的多,我们就可以把 Mysql 中的热点数据缓存到 Redis 中,提升读取性能,同时也减轻了 Mysql 的读取压力。缓存可以将常用的数据存储在内存中,以加快数据的读取速度,减少数据库等存储设备的读取次数,从而降低系统的响应时间。
2.减轻服务器负担:通过使用缓存,可以减少服务器对数据库等存储设备的访问,降低服务器的负载,提高服务器的吞吐量。
3.改善用户体验:由于缓存可以加速数据的读取,因此可以大大改善用户的体验,提升网站的访问速度和稳定性。
4.降低成本:通过缓存可以降低数据库等存储设备的读写次数,从而延长存储设备的使用寿命,降低维护成本和硬件成本。
5.提高可靠性:通过使用缓存可以将重要的数据备份到多个节点上,提高系统的可靠性和容错性。
6.实现分布式架构:缓存可以作为分布式架构中的关键组件,实现数据的共享、负载均衡和水平扩展等功能,提高系统的可扩展性和灵活性。
Redis的好处
1.读取速度快,因为数据存在内存中,所以数据获取快,单机轻松10W+并发,相对于传统数据库,Redis 的读取速度可以提高几十倍甚至上百倍。
2.支持多种数据结构,包括字符串、列表、集合、有序集合、哈希等,可以满足不同场景的需求。
3.还拥有其他丰富的功能,主从复制、集群、数据持久化、pipeline、 事务等。
4.可以实现其他丰富的功能,消息队列、分布式锁、分布式ID ( 数据异构)、排行榜、计数器、页面缓存、会话管理等。


MySQL InnoDB缓存
1. 背景
对于各种用户数据、索引数据等各种数据都是需要持久化存储到磁盘,然后以“页”为单位进行读写。
相对于直接读写缓存,磁盘IO的成本相当高昂。
对于读取的页面数据,并不是使用完就释放掉,而是放到缓冲区,因为下一次操作有可能还需要读区该页面。
对于修改过的页面数据,也不是马上同步到磁盘,也是放到缓冲区,因为下一次有可能还会修改该页面的数据。
但是缓存的空间是有大小限制的,不可能无限扩充。
对于缓冲区的数据,需要有合理的页面淘汰算法,将未来使用概率较小的页面释放或者同步到磁盘,
给当下需要存放到缓存的页面腾出位置。
2. 存储器性能差异
寄存器:cpu暂存指令、数据的小型存储区域,速度快,容量小。
cpu高速缓存(cpu Cache):用于减少cpu访问内存所需平均时间的部件。
内存:用于暂时存放cpu中的运算数据,以及与硬盘等外部存储器交换的数据。
硬盘:分为固态硬盘(SSD)和机械硬盘(HHD),是非易失性存储器。
下图是各种缓存器的价格和性能差距,
从下图可以看出,SSD的随机访问延时在微妙级别,而内存的的随机访问延时在纳秒级别,内存比SSD大概快1000倍左右。

图片来自 小林Coding
3. Buffer Pool
一个缓冲池(缓冲池)是向操作系统申请的一块内存空间,这块内存空间由多个chunk组成,每个chunk均包含多个控制块和对应的缓冲页。
chunk是向操作系统申请内存的最小单位,缓冲页大小与InnoDB表空间使用的页面大小一致。
Buffer Pool的示意图如下

每一个控制块都对应一个缓冲页,控制块包含该缓冲页所属的表空间编号、页号、在Buffer Pool中的地址、链表结点信息等等。
当刚读取一个页面时,需要知道缓冲区有哪些空闲页面,当修改过后缓冲页后,需要记录该缓冲页需要持久化到磁盘,
当缓冲区没有空闲页面了,需要有页面淘汰算法来将缓冲页移出缓冲区,
以上涉及到Free链表、Flush链表、LRU链表,下面注意说明。
4. Free链表
Free链表是由空闲的缓冲页对应的控制块组成的链表,通过Free链表就获取到空闲的缓冲页及其在缓冲区中的地址。
每当需要从磁盘加载一个页面到缓冲区时,从该Free链表取出一个控制块结点,从Free链表移除该结点,并加入LRU链表。
如果这个缓冲区页面被修改过,那么会被加入到Flush链表中。
5. Flush链表
如果一修改缓冲页的数据之后就刷新到磁盘,这种频繁的IO操作势必影响程序等整体性能。
试想一下,先后修改1000次同一缓冲区页面的一字节数据,每次修改都刷新到磁盘,与修改1000次后再将最终结果刷新磁盘,节省了999次刷新磁盘的操作。
因此,当页面的数据被修改之后,需要将改页面放到Flush链表,排队等候写入磁盘。
这既可以减少在用户进程中刷新磁盘的次数,也从整体上减少了磁盘IO到次数。
6. LRU链表
内存空间有限,不可能将所有数据都缓存在内存当中,因此需要有一定的算法将内存中页面淘汰掉(修改过的页面持久化到磁盘)。
LRU(Least Recently Used)链表主要用于辅助实现内存页面淘汰,故名思义,最先淘汰的是最近最少使用的缓冲页。
LRU链表的结果如下图所示

将LRU链表分为young区域和old区域。
对于初次加载到缓冲区的页面,会放到LRU链表old区域的头部,这主要避免了预读的页面被放到了LRU链表的首部。
当第二次访问缓冲页且时间间隔超过innodb_old_blocks_time(默认1s)时,才将该页面移动到LRU链表的首部。
进一步,为了避免频繁的移动链表结点,当某个缓冲页已经在young区域的前3/4时,则不会移动该结点到首部。
7. 其它
如何定位页面是否被缓冲呢?
表空间号和页号可以唯一识别缓冲页,因此InnoDB引擎建立了以表空间号+页号为key,以缓冲页控制块地址为value的哈希表,
从而快速判断页面是否被缓冲,快速定位到数据所在地址。

MySQL 社区经理:MySQL 8.4 InnoDB 参数默认值为什么要这么改?
MySQL 8.4 LTS 版本,我们一共修改了 20 个 InnoDB 变量的默认值。
本文和封面来源:https://lefred.be,爱可生开源社区翻译。
本文约 2400 字,预计阅读需要 8 分钟。
2024 年 4 月 30 日,MySQL 8.4(第一个 LTS 版)正式发布,也验证了 Oracle 官方在之前宣布的 MySQL 版本发布节奏。
什么是 LTS 版?目前还有哪些版本?
目前,MySQL 的发布模型分为两个主要路径:LTS 版(长期支持)和创新版。所有 LTS 和创新版本都包含错误和安全修复,并被视为生产级质量。更多MySQL 版本介绍
")
什么情况适合 LTS 版?
- 需要稳定的功能和更长的支持期。
- 除了第一个 LTS 版本删除了一些功能,其他版本仅包含必要的修复,不在删除功能。
- LTS 版本遵循 Oracle 终身支持政策(5 年主要支持和 3 年延长支持)。
什么情况适合创新版?
- 想了解最新功能、改进。适合快节奏开发环境中的开发和 DBA,具有更高水平的自动化测试和现代持续集成技术,可实现更快的升级周期。
- 除新功能外,随着代码重构、删除不推荐功能以及修改 MySQL 使其更符合 SQL 标准(在 LTS 版本中不会发生)。
- 支持至下一个创新版。
MySQL 各版本的生命周期
")
请参考 Oracle 官方提供的 MySQL 各版本生命周期计划(20240430),以更好地安排您生产环境的 MySQL 版本选择。
以下内容为 MySQL 社区经理 Frederic Descamps 对该版本中 InnoDB 参数默认值修改的详细介绍。
发布于当地时间 2024 年 5 月 1 日
")
昨天(4/30),MySQL 的第一个 LTS 版本 MySQL 8.4 发布了。
许多弃用的内容最终被删除,并且几个 InnoDB 变量默认值已被修改以匹配当前的工作负载和硬件规格。
有 20 个 InnoDB 变量的默认值已被修改!
让我们看一下这些变量并解释这样修改的原因:
被修改默认值的 InnoDB 变量
innodb_buffer_pool_in_core_file
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | ON |
| 8.4 LTS | 如果支持 MADV_DONTDUMP 为 OFF,否则 ON |
MADV_DONTDUMP 是 Linux 3.4 及更高版本中支持的宏(存在“ sys/mman.h”头文件并包含符号 MADV_DONTDUMP,一个 madvise() 的 non-POSIX 扩展),Windows 系统或大多数 MacOS 系统不支持此宏。
总之,这意味着默认情况下,在 Linux 系统上,缓冲池的内容不会转储到核心文件中。
innodb_buffer_pool_instances
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 8(如果 BP < 1 GB,则为 1) |
| 8.4 LTS | 如果 BP <= 1 GB:1 如果 BP > 1 GB:则为 1-64 范围内的最小值: a. (innodb_buffer_pool_size / innodb_buffer_pool_chunk_size) / 2 b. 1/4 可用逻辑处理器 |
旧值 8 在某些系统上可能太大。手册中包含 BP 大小计算的好示例,请参阅 配置 InnoDB 缓冲池大小。
innodb_change_buffering
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | all |
| 8.4 LTS | none |
Change Buffer 是一种通过延迟对二级索引的写入操作来支持顺序 I/O 的技术。在最新的硬件上,随机 I/O 不再是问题。
innodb_dedicated_server
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | OFF |
| 8.4 LTS | OFF |
从 MySQL 8.0 开始,当 MySQL 运行在可供数据库使用的所有资源的专用服务器上时,我们建议启用此变量,并且不要手动修改 InnoDB 设置。
该变量的默认值是相同的,但是通过启用 innodb_dedicated_server 控制的变量是不同的。
innodb_buffer_pool_size
- 128MB 是服务器内存小于 1GB。
- 如果服务器内存在 1GB 到 4GB 之间,则检测到的服务器内存 * 0.5。
- 如果服务器内存超过 4GB,则检测到的服务器内存 * 0.75。
- innodb_redo_log_capacity:(可用逻辑处理器数量/2)GB,最大 16GB。
当 innodb_dedicated_server 启用时,innodb_flush_method 不会自动配置。
innodb_adaptive_hash_index
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | ON |
| 8.4 LTS | OFF |
AHI(InnoDB 自适应哈希索引)长期以来一直是一些性能问题的原因。每个经验丰富的 DBA 总是建议禁用它,就像旧的查询缓存一样。我很惊讶没有像 Domas Mituzas 的查询缓存调优器那样的 AHI 调优器
当没有数据发生更改并且完全缓存在缓冲池中时,AHI 可能会对读查询 (SELECT) 提供一些好处。一旦有写入操作,或者系统负载较高,或者读取所需的所有数据都无法缓存,自适应哈希索引就会成为巨大的瓶颈。
为了获得更可预测的响应时间,建议禁用它。
innodb_doublewrite_files
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | innodb_buffer_pool_instances * 2 |
| 8.4 LTS | 2 |
之前默认值是根据缓冲池的数量计算的,为了简化,现在默认为 2。
相关文档 指出该值定义每个缓冲池的双写文件数。但我的印象是,它是全局的,与缓冲池实例的数量无关。
从 MySQL 错误日志来看:
2024-05-01T05:43:03.226604Z 1 [Note] [MY-012955] [InnoDB] Initializing buffer pool, total size = 2.000000G, instances = 2, chunk size =128.000000M
[...]
2024-05-01T05:43:03.288068Z 1 [Note] [MY-013532] [InnoDB] Using ''./#ib_16384_0.dblwr'' for doublewrite
2024-05-01T05:43:03.295917Z 1 [Note] [MY-013532] [InnoDB] Using ''./#ib_16384_1.dblwr'' for doublewrite
2024-05-01T05:43:03.317319Z 1 [Note] [MY-013532] [InnoDB] Using ''./#ib_16384_0.bdblwr'' for doublewrite
2024-05-01T05:43:03.317398Z 1 [Note] [MY-013566] [InnoDB] Double write buffer files: 2
2024-05-01T05:43:03.317410Z 1 [Note] [MY-013565] [InnoDB] Double write buffer pages per instance: 128
2024-05-01T05:43:03.317423Z 1 [Note] [MY-013532] [InnoDB] Using ''./#ib_16384_0.dblwr'' for doublewrite
2024-05-01T05:43:03.317436Z 1 [Note] [MY-013532] [InnoDB] Using ''./#ib_16384_1.dblwr'' for doublewrite我们看到我们有 2 个缓冲池实例,但仍然只有 2 个双写缓冲文件。根据文档,我期望 4 。第三个文件 #ib_16384_0.bdblwr 是在 innodb_doublewrite 设置为 DETECT_ONLY 时创建的。
使用 DETECT_ONLY 时,只有元数据会写入双写缓冲区。数据库页内容不会写入双写缓冲区,并且恢复不会使用双写缓冲区来修复不完整的页写入。此轻量级设置仅用于检测不完整的页面写入。
innodb_doublewrite_pages
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | innodb_write_io_threads(默认为 4) |
| 8.4 LTS | 128 |
从测试结果和出于对性能的角度考虑,我们意识到默认值越大越好,经常建议增加它。
innodb_flush_method
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | fsync |
| 8.4 LTS | O_DIRECT (或 fsync) |
当支持时,O_DIRECT 始终是首选值,我们建议使用它绕过文件系统缓存,将 InnoDB 更改刷新到磁盘(对于数据文件和日志文件)。
如果不支持 O_DIRECT,我们使用旧的 fsync 方法。这是针对 Unix 的,在 Windows 上,默认值是 unbuffered。
innodb_io_capacity
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 200 |
| 8.4 LTS | 10000 |
对于最近的系统(RAID、SSD 等),默认 I/O 容量太低。由于该变量定义了 InnoDB 后台操作可用的 IOPS 数量,因此值太低会限制性能。
innodb_io_capacity_max
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 2 * innodb_io_capacity(最小 2000) |
| 8.4 LTS | 2 * innodb_io_capacity |
如果 InnoDB 需要更积极地刷新,则此变量定义 InnoDB 可用于执行后台操作的最大 IOPS 数。新的默认值更简单,因为它只是 innodb_io_capacity 的两倍。
innodb_log_buffer_size
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 16MB |
| 8.4 LTS | 64MB |
我们增加了默认值,因为大的日志缓冲区允许大型事务运行,而无需在事务提交之前将日志写入磁盘。
innodb_numa_interleave
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | OFF |
| 8.4 LTS | ON |
当系统支持 NUMA 时,新的默认值在分配 InnoDB 缓冲池期间将 mysqld 的 NUMA 内存策略设置为 MPOL_INTERLEAVE 。此操作随机平衡所有 NUMA 节点的内存分配,从而在这些节点之间实现更好的分布。
当然,只有当您的系统具有多个 NUMA 节点时,您才能从中受益。
这是验证节点数量的方法:
$ numactl --hardware
available: 2 nodes (0-1)
node 0 size: 16160 MB
node 0 free: 103 MB
node 1 size: 16130 MB
node 1 free: 83 MB
node distances:
node 0 1
0: 10 20
1: 20 10在上面的例子中,我们可以看到 CPU 有两个节点。
您还可以使用 lstopo 显示架构并显示 NUMA 核心。这是另一个例子:

innodb_page_cleaners
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 4 |
| 8.4 LTS | innodb_buffer_pool_instances |
新的默认设置是使用与缓冲池实例一样多的线程从缓冲池实例中刷新脏页。
innodb_parallel_read_threads
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 4 |
| 8.4 LTS | 逻辑处理器 / 8(最少 4 个) |
出于性能原因,在具有大量逻辑 CPU 的系统上,用于并行聚集索引读取的线程数会自动增加。
innodb_purge_threads
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 4 |
| 8.4 LTS | 如果逻辑处理器 <= 16,则为 1,否则为 4 |
对于具有大量 (>=16) vCPU 的系统,此变量也会以某种方式自动配置。但我们也意识到,在某些较小的系统上拥有 4 个清除线程可能会出现问题。对于这样的系统,我们将默认值减少到 1。
innodb_read_io_threads
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 4 |
| 8.4 LTS | 逻辑处理器 / 2(最少 4 个) |
如果系统有超过 8 个 vCPU,该变量也会自动增加。
innodb_use_fdatasync
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | OFF |
| 8.4 LTS | ON |
在支持它的系统上,除非需要,否则 fdatasync() 的调用不会刷新对文件元数据的更改。这提供了性能优势。
temptable_max_ram
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 1GB |
| 8.4 LTS | 总内存的 3%(1-4GB 范围内) |
如果系统受益于大量内存,默认值现在会自动增加。但默认上限为 4GB。因此,对于内存超过 132GB 的系统,默认情况下 temptable_max_ram 的值将设置为 4GB。
temptable_max_mmap
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | 1GB |
| 8.4 LTS | 0(禁用) |
新的默认设置禁止从内存映射临时文件分配内存(不在 tmpdir 中创建文件)。
temptable_use_mmap
| 版本 | 默认值 |
|---|---|
| 8.4 之前 | ON |
| 8.4 LTS | OFF |
当 temptable_use_mmap 被禁用(新默认设置)时,TempTable 存储引擎会使用 InnoDB 磁盘上的内部临时表,而不是在 temptable_max_ram 变量定义的限制被超过时,在 tmpdir 中为内部内存临时表分配空间作为内存映射的临时文件。
总结
通过这个全新版本的 MySQL(第一个 LTS),我们有机会更改某些 InnoDB 变量的默认值,使它们更符合生产服务器的实际情况。
有些现在可以自动调整以更好地匹配 MySQL 运行的系统。
享受 MySQL 并享受新的默认设置!

MySQL为什么要使用B+树索引
搞懂这个问题之前,我们首先来看一下MySQL表的存储结构,再分别对比二叉树、多叉树、B树和B+树的区别就都懂了。
MySQL的存储结构
表存储结构
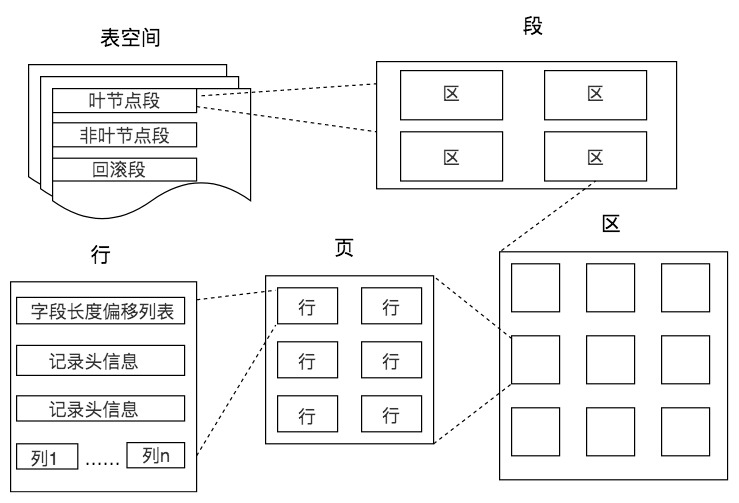
单位:表>段>区>页>行
在数据库中, 不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说存储空间的基本单位是页。
一个页就是一棵树B+树的节点,数据库I/O操作的最小单位是页,与数据库相关的内容都会存储在页的结构里。
B+树索引结构
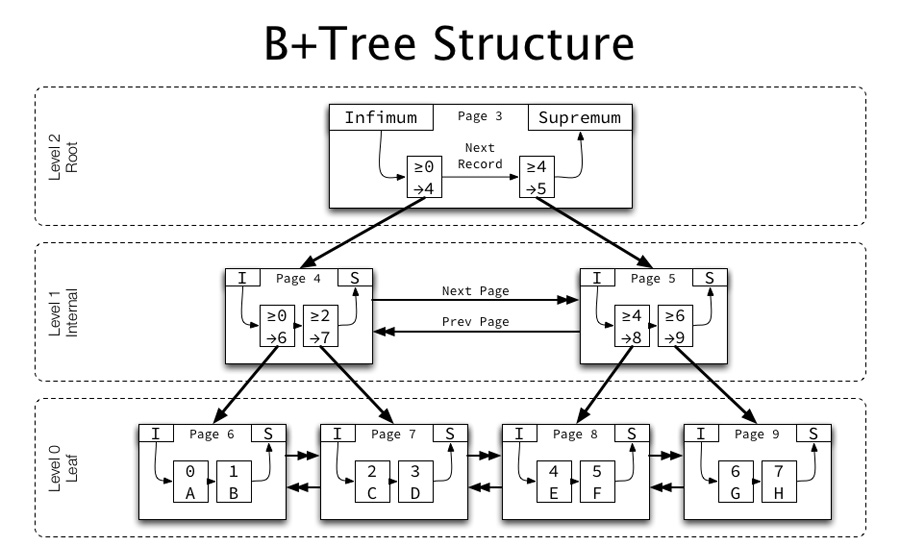
在一棵B+树中,每个节点为都是一个页,每次新建节点的时候,就会申请一个页空间
同一层的节点为之间,通过页的结构构成了一个双向链表
非叶子节点为,包括了多个索引行,每个索引行里存储索引键和指向下一层页面的指针
叶子节点为,存储了关键字和行记录,在节点内部(也就是页结构的内部)记录之间是一个单向的链表
B+树页节点结构

有以下几个特点
将所有的记录分成几个组, 每组会存储多条记录,
页目录存储的是槽(slot),槽相当于分组记录的索引,每个槽指针指向了不同组的最后一个记录
我们通过槽定位到组,再查看组中的记录
页的主要作用是存储记录,在页中记录以单链表的形式进行存储。
单链表优点是插入、删除方便,缺点是检索效率不高,最坏的情况要遍历链表所有的节点。因此页目录中提供了二分查找的方式,来提高记录的检索效率。
B+树的检索过程
我们再来看下B+树的检索过程
从B+树的根开始,逐层找到叶子节点。
找到叶子节点为对应的数据页,将数据叶加载到内存中,通过页目录的槽采用二分查找的方式先找到一个粗略的记录分组。
在分组中通过链表遍历的方式进行记录的查找。
为什么要用B+树索引
数据库访问数据要通过页,一个页就是一个B+树节点,访问一个节点相当于一次I/O操作,所以越快能找到节点,查找性能越好。
B+树的特点就是够矮够胖,能有效地减少访问节点次数从而提高性能。
下面,我们来对比一个二叉树、多叉树、B树和B+树。
二叉树
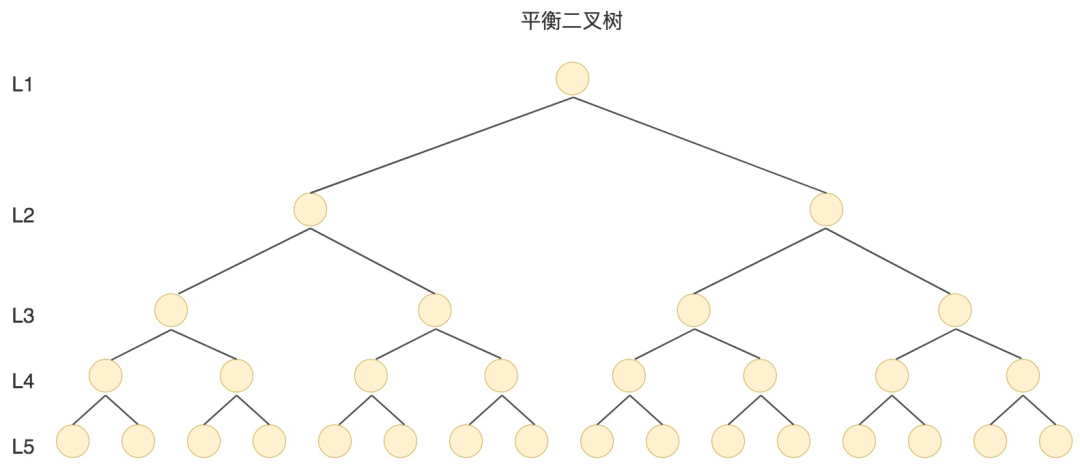
二叉树是一种二分查找树,有很好的查找性能,相当于二分查找。
但是当N比较大的时候,树的深度比较高。数据查询的时间主要依赖于磁盘IO的次数,二叉树深度越大,查找的次数越多,性能越差。
最坏的情况是退化成了链表,如下图
为了让二叉树不至于退化成链表,人们发明了AVL树(平衡二叉搜索树):任何结点的左子树和右子树高度最多相差1
多叉树
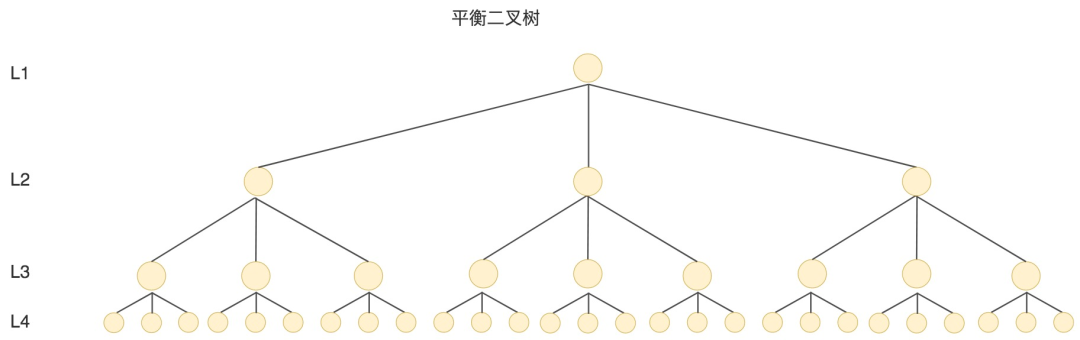
多叉树就是节点可以是M个,能有效地减少高度,高度变小后,节点变少I/O自然少,性能比二叉树好了
B树

B树简单地说就是多叉树,每个叶子会存储数据,和指向下一个节点的指针。
例如要查找9,步骤如下
我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
B+树
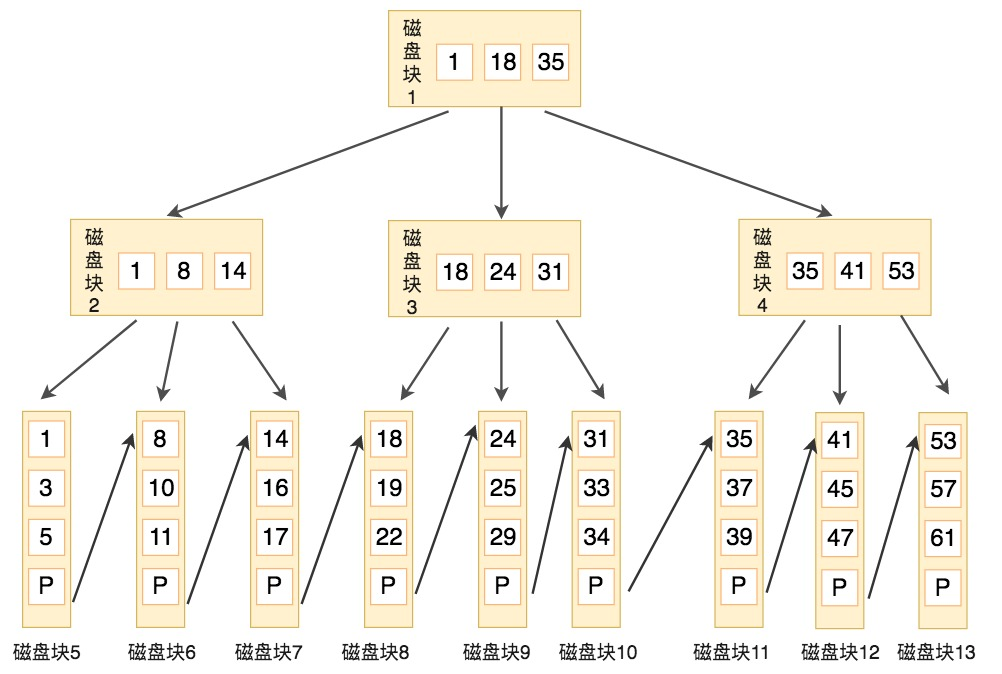
B+树是B树的改进,简单地说是:只有叶子节点才存数据,非叶子节点是存储的指针;所有叶子节点构成一个有序链表
B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了
例如要查找关键字16,步骤如下
与根节点的关键字 (1,18,35) 进行比较,16 在 1 和 18 之间,得到指针 P1(指向磁盘块 2)
找到磁盘块 2,关键字为(1,8,14),因为 16 大于 14,所以得到指针 P3(指向磁盘块 7)
找到磁盘块 7,关键字为(14,16,17),然后我们找到了关键字 16,所以可以找到关键字 16 所对应的数据。
B+树与B树的不同:
B+树非叶子节点不存在数据只存索引,B树非叶子节点存储数据
B+树查询效率更高。B+树使用双向链表串连所有叶子节点,区间查询效率更高(因为所有数据都在B+树的叶子节点,扫描数据库 只需扫一遍叶子结点就行了),但是B树则需要通过中序遍历才能完成查询范围的查找。
B+树查询效率更稳定。B+树每次都必须查询到叶子节点才能找到数据,而B树查询的数据可能不在叶子节点,也可能在,这样就会造成查询的效率的不稳定
B+树的磁盘读写代价更小。B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,通常B+树矮更胖,高度小查询产生的I/O更少。
source:https://www.cnblogs.com/chenqionghe/p/14295404.html

喜欢,在看
本文分享自微信公众号 - JAVA乐园(happyhuangjinjin88)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
今天关于php – 为什么要使用MySQL DB缓存?和php为什么要用框架的分享就到这里,希望大家有所收获,若想了解更多关于2023-05-24:为什么要使用Redis做缓存?、MySQL InnoDB缓存、MySQL 社区经理:MySQL 8.4 InnoDB 参数默认值为什么要这么改?、MySQL为什么要使用B+树索引等相关知识,可以在本站进行查询。
本文标签:




