我正在使用AWS Lex Chat bot,并且设法使用Lambda设置了响应卡。我遇到的问题是响应卡的图像出现,但是''attachmentLinkUrl''无法正常工作。我应该能够单击该图像并将其重定向到附加的链接。但是在测试机器人中,这似乎不起作用。
有谁知道可能出什么问题了?

BD|Hortonworks 本地虚拟机之旅
Mac系统
首先安装VMWare Fusion 8
然后下载http://zh.hortonworks.com/downloads/下的Download for VMWare
这个虚拟机包含了几乎所有大数据开发相关的软件及依赖
教程:http://zh.hortonworks.com/tutorials/

Cloudera CDH 、Hortonworks DHP和MapR比较
目前啊,都知道,大数据集群管理方式分为手工方式(Apache hadoop)和工具方式(Ambari + hdp 和Cloudera Manger + CDH)。
手工部署呢,需配置太多参数,但是,好理解其原理,建议初学这样做,能学到很多。该方式啊,均得由用户执行,细节太多,切当设计多个组件时,用户须自己解决组件间版本兼容问题。
工具部署呢,比如Ambari或Cloudera Manger。(当前两大最主流的集群管理工具,前者是Hortonworks公司,后者是Cloudera公司)使用工具来,可以说是一键操作,难点都在工具Ambari或Cloudera Manger本身部署上。
手工方式 工具方式
难易度 难,几乎不可能成功 简单,易行
兼容性 自己解决组件兼容性问题 自动安装兼容组件
组件支持数 支持全部组件 支持常用组件
优点 对组件和集群管理深刻 简单、容易、可行
缺点 太复杂,不可能成功 屏蔽太多细节,妨碍对组件理解
工具名 所属机构 开源性 社区支持性 易用性、稳定性 市场占有率
Cloudera Manger Cloudera 商用 不支持 易用、稳定 高
Ambari Hortonwork 开源 支持 较易用、较稳定 较高
常见的情况是,Cloudera Manger 去部署CDH
Ambari去部署HDP,
当然,两者也可以互相,也可以去部署Apache Hadoop
Cloudera Manager安装之利用parcels方式安装3节点集群(包含最新稳定版本或指定版本的安装)(添加服务)
Ambari安装之部署3个节点的HA分布式集群
Hadoop在大数据领域的应用前景很大,不过因为是开源技术,实际应用过程中存在很多问题。于是出现了各种Hadoop发行版,国外目前主要是三家创业公司在做这项业务:Cloudera、Hortonworks和MapR
Cloudera和MapR的发行版是收费的,他们基于开源技术,提高稳定性,同时强化了一些功能,定制化程度较高,核心技术是不公开的,营收主要来自软件收入。
这类公司,如果一直保持技术领先性,那么软件收入溢价空间很大。但一旦技术落后于开源社区,整个产品需要进行较大调整。
Hortonworks则走向另一条路,他们将核心技术完全公开,用于推动Hadoop社区的发展。这样做的好处是,如果开源技术有很大提升,他们受益最大,因为定制化程度较少,自身不会受到技术提升的冲击。
cdh
(1)CDH3版本是基于Apache hadoop 0.20.2改进的,并融入了最新的patch,CDH4版本是基于Apache hadoop 2.X改进的,CDH总
是并应用了最新Bug修复或者Feature的Patch,并比Apache hadoop同功能版本提早发布,更新速度比Apache官方快。
(2)安全CDH支持Kerberos安全认证,apache hadoop则使用简陋的用户名匹配认证
(3)CDH文档清晰,很多采用Apache版本的用户都会阅读CDH提供的文档,包括安装文档、升级文档等。
(4)CDH支持Yum/Apt包,Tar包,RPM
包,Cloudera Manager四种方式安装,Apache hadoop
只支持Tar包安装。
1、联网安装、升级,非常方便
2、自动下载依赖软件包
3、Hadoop生态系统包自动匹配,不需要你寻找与当前Hadoop匹配的Hbase,Flume,Hive等软件,Yum/Apt会根据当前安装Hadoop版本自动寻找匹配版本的软件包,并保证兼容性。
4、自动创建相关目录并软链到合适的地方(如conf和logs等目录);自动创建hdfs, mapred用户,hdfs用户是HDFS的最高权限用户,mapred用户则负责mapreduce执行过程中相关目录的权限。
hortonworks
Hortonworks这个名字源自儿童书中一只叫Horton的大象。雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks。
Hortonworks有两款核心产品:HDP和HDF
Hortonworks没有对产品收费,而是将这两款产品完全开放,将核心技术放在Hadoop开源社区中,每个人都可以看到并使用这两款产品
企业客户自己开发难度较大的话,就会选择合作。这就是Hortonworks的盈利模式,通过提供支持服务和后期维护,向企业级客户收费。
支持服务主要是通过订阅的方式,客户需要就某些功能预定一年或者几年的服务,提前付费。支持服务覆盖整个周期,从最初的开发和POC阶段,到中间的质量测试,直至产品交付。维护服务主要是对企业级客户的培训和一些咨询业务。
mapr
Marp是一个比现有Hadoop分布式文件系统还要快三倍的产品,并且也是开源的。Mapr配备了快照,并号称不会出现SPOF单节点故障,且被认为是与现有HDFS的API兼容。因此非常容易替换原有的系统。
原文:https://www.dezyre.com/article/cloudera-vs-hortonworks-vs-mapr-hadoop-distribution-comparison-/190
(译文):
对于企业而言,不管过去是否曾使用过Hadoop,正确选择Hadoop商业发行版都很重要。当企业准备投入巨大的财力在Hadoop平台的硬件和解决方案上时,选择某个商业版的Hadoop系统就变得特别重要了。根据业务需要选择正确的Hadoop商业发行版可以带来更多的数据解决方案并且可以获得业界专业人士的认可。这篇文章将从成本、技术细节、部署和维护等几个方面比较Cloudera、Hortonworks和MapR发布的Hadoop版本。
Hadoop 是一个开源项目,先后有许多公司在其框架基础上进行了增强并且发布了商业版本。Hadoop项目的最大诱惑在于使用者可以根据自身的业务需要定制差异化的功能。在Apache开源社区,Hadoop把所有的相关项目组成一个完整的生态系统,用户几乎不费吹灰之力就可以通过搭配一些组件来实现一个完整功能。
哪些人需要Hadoop分布式系统?
l 需要学习和临时使用Hadoop的各行业专业人士
l 需要在大数据的背景下推进业务解决方案演进的各类机构
l 需要在Hadoop生态系统中开发新工具的人员
商业版本的Hadoop有哪些改进?
Hadoop商业发行版的提供者们通过优化核心代码、增强易用性、提供技术支持和持续版本升级为Hadoop平台实现了许多新功能。市场上受认可的Hadoop商业发行版的提供者主要有Cloudera,MapR和Hortonworks。 他们发行的Hadoop商业版本都能与Apache社区开源版本兼容,但它们之间有哪些区别呢?
l 框架核心:Cloudera,MapR和Hortonworks这三家公司都把Hadoop核心框架打包到了他们的商业版本中;在这基础上,他们都提供了技术支持服务和定制化开发服务。
l 系统集成:MapR 的商业版Hadoop可靠地支持一系列功能,包括:实时流数据处理,与已有系统集成的内嵌的连接器,数据安全保护,企业级工程品质。
l 系统管控:Cloudera和MapR 商业发行版中都包含了为系统管理员提供了配置、监控和优化的管控平台。
Cloudera,Hortonworks和MapR异同之处分析
| 版本 |
优点 |
缺点 |
| CDH |
CDH有一个友好的用户界面及一些实用的工具,比如:Impala |
CDH相对MapR Hadoop来说,运行效率显著降低 |
| MapR Hadoop |
运行效率高;节点之间可以通过NFS直接访问 |
MapR Hadoop没有像CDH那样的用户界面 |
| HDP |
唯一一个能运行在Windows上的Haoop系统 |
Ambari管控界面功能比较简单,不够丰富 |
相似性:
l Cloudera, Hortonworks 和MapR三家公司都专注于Hadoop平台开发,商业版本的Hadoop系统是他们的全部收入来源。
l 这三家公司都是中等规模的公司,都拥有一些优质客户和来自其他行业的投资伙伴。
l 这三家公司都提供了免费版本的下载,不同的是,MapR和Cloudera 还为付费客户提供功能增强版本。
l 这三家公司都建立了技术支持社区帮助用户解决遇到的问题以及在用户需要时提供系统演示。
l 这三家公司都通过测试保证发行版本满足用户业务对稳定性和安全性需求。
下面我们会在对比每一个商业版本功能的基础上分析其差异性:
Cloudera — CDH
Cloudera 是Hadoop领域知名的公司和市场领导者,提供了市场上第一个Hadoop商业发行版本。它拥有350多个客户并且活跃于Hadoop生态系统开源社区。在多个创新工具的贡献着排行榜中,它都名列榜首。它的系统管控平台——Cloudera Manager,易于使用、界面清晰,拥有丰富的信息内容。Cloudera 专属的集群管控套件能自动化安装部署集群并且提供了许多有用的功能,比如:实时显示节点个数,缩短部署时间等。同时,Cloudera 也提供咨询服务来解决各类机构关于在数据管理方案中如何使用Hadoop技术以及开源社区有哪些新内容等疑虑。美国电商“高朋”公司是CDH的用户。
CDH的主要特性:
l 在线不停机添加新组件
l 多集群统一管理
l 提供差异化配置的节点模板。用户不必使用单一配置的Hadoop集群,可以依此创建差异化配置的集群。
l Hortonworks 和Cloudera都依赖于HDFS的DataNode 和NameNode架构来做数据切分。
MapR — Hadoop
MapR的Hadoop商业发行版紧盯市场需求,能更快反应市场需要。一些行业巨头如思科、埃森哲、波音、谷歌、亚马逊都是MapR的Hadoop的用户。与Cloudera和Hortonworks不同的是, MapR Hadoop不依赖于Linux文件系统,也不依赖于HDFS,而是在MapRFS文件系统上把元数据保存在计算节点,快速进行数据的存储和处理。
MapR Hadoop的主要特性:
l 由于它基于MapRFS,它是唯一一个能不依赖于Java而提供Pig,Hive和Sqoop的Hadoop。
l MapR Hadoop是最适合应用于生产环境的Hadoop版本,它包含了许多易用性、高效和可信赖的增强功能。
l MapR Hadoop集群节点可以通过NFS直接访问,因此用户可以像使用Linux文件系统一样在NFS上直接挂载MapR文件。
l MapR Hadoop提供了完整的数据保护,方便使用并且没有单点故障。
l MapR Hadoop被认为是运行最快的Hadoop版本。
尽管从集群规模来说,MapR Hadoop还不如Hortonworks 和Cloudera,只能暂列第三,但相对其它版本的Hadoop来说,它易用性最强,运行最快。因此,如果用户想选择带有足够创意和学习资料的Hadoop,那么MapR Hadoop将是不二之选。
Hortonworks — HDP
Hortonworks是由一些雅虎的工程师创立的公司,提供针对Hadoop的技术服务。与其它公司不同的是,它提供完全开源的Hadoop数据平台并且用户可以免费使用。用户可以很方便得下载Hortonworks 的Hadoop发行版HDP并把它集成到各种应用中。Ebay、三星、彭博、Spotify 都是HDP的用户。Hortonworks 也是第一个基于Hadoop 2.0提供满足生产环境需要的Hadoop版本。尽管CDH在其早期的版本中包含了Hadoop 2.0的部分功能,但这些功能无法满足生产环境需要。HDP 也是目前唯一能支持Windows的Hadoop版本。用户可以在Azure 上通过HDInsight 服务部署Windows上的 Hadoop。
HDP的主要特性:
l HDP 通过Stinger项目提升了Hive的性能
l HDP 通过新的Hadoop分支来避免用户被厂商绑定
l 聚焦于提升Hadoop平台的实用性
通过对Hadoop市场上的这三家公司的产品战略和功能分析后,我们很难简单说谁更胜一筹。各类机构需要根据自身业务程度需要来选择Hadoop商业版本。回答下面这些问题可以帮助用户做出选择:
1. 是否会使系统管理员工作更加高效?
2. 是否便于Hadoop开发人员和业务分析人员访问数据?
3. 是否满足机构内部关于数据安全的规章制度要求?
4. 是否适合机构内部的系统运行环境?
5. 是否需要Hadoop提供的所有组件和能力?
6. 是否需要大数据的整体解决方案来支撑业务盈利?以及是否需要紧跟开源以减少被厂商绑定?
7. 系统可靠性、技术支持、扩展功能等是否非常重要?
用户如果期望得到一个像样的产品,那选择MapR Hadoop比较适合;如果需要紧跟开源,那么就应该选择Hortonworks;如果用户的业务需求需要介于二者之间,那么Cloudera 就是个不错的选择了。
如何选择Hadoop发行版完全取决于用户在实施Hadoop平台中遇到了什么样的困难。Hadoop商业发行版可以帮助用户把Hadoop平台和其他异构数据分析平台灵活、可靠、可视化地连接起来。每个Hadoop发行版都有其各自的优点和缺点。在选择时,不仅要平衡风险和成本,也要考虑各种发行版的附加功能是否符合实际业务场景需要。
一、Hadoop版本综述
目前Hadoop发行版非常多,有华为发行版、Intel发行版、Cloudera发行版(CDH)等,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,完全是由Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并作为开源或商业产品发布/销售。(http://www.apache.org/licenses/LICENSE-2.0)。
国内绝大多数公司发行版是收费的,比如Intel发行版、华为发行版等,尽管这些发行版增加了很多开源版本没有的新feature,但绝大多数公司选择Hadoop版本时会将把是否收费作为重要指标,不收费的Hadoop版本主要有三个(均是国外厂商),分别是:
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)、
Apache基金会hadoop、
Hortonworks版本(Hortonworks Data Platform,简称“HDP”)--------按顺序代表了,在国内的使用率,CDH和HDP虽然是收费版本,但是他们是开源的,只是收取服务费用。
对于国内而言,绝大多数选择CDH版本,主要理由如下:
(1) CDH对Hadoop版本的划分非常清晰,只有两个系列的版本(现在已经更新到CDH5.20了,基于hadoop2.x),分别是cdh3和cdh4,分别对应第一代Hadoop(Hadoop 1.0)和第二代Hadoop(Hadoop 2.0),相比而言,Apache版本则混乱得多;
(2) CDH文档清晰,很多采用Apache版本的用户都会阅读cdh提供的文档,包括安装文档、升级文档等。
CDH与Apache版本的对应:
cdh3版本是基于apache hadoop 0.20.2
cdh3u6对应到apache hadoop最新版本(Hadoop 1.x)
cdh4对应apache hadoop 2.x
HDP版本是比较新的版本,目前与apache基本同步,因为Hortonworks内部大部分员工都是apache代码贡献者,尤其是Hadoop 2.0的贡献者。
二、社区版本与第三方发行版本的比较
1.Apache社区版本
优点:
完全开源免费。
社区活跃
文档、资料详实
缺点:
----复杂的版本管理。版本管理比较混乱的,各种版本层出不穷,让很多使用者不知所措。
----复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。
----复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,如ganglia,nagois等,运维难度较大。
----复杂的生态环境。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
2.第三方发行版本(如CDH,HDP,MapR等)
优点:
----基于Apache协议,100%开源。
----版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。
----比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
----版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
----基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
----提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。
----运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
----涉及到厂商锁定的问题。(可以通过技术解决)
三、第三方发行版本的比较
Cloudera:最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。Cloudera开发并贡献了可实时处理大数据的Impala项目。

Hortonworks:不拥有任何私有(非开源)修改地使用了100%开源Apache Hadoop的唯一提供商。Hortonworks是第一家使用了Apache HCatalog的元数据服务特性的提供商。并且,它们的Stinger开创性地极大地优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Windows Server和Windows Azure在内的Microsft Windows平台上本地运行。

MapR:与竞争者相比,它使用了一些不同的概念,特别是为了获取更好的性能和易用性而支持本地Unix文件系统而不是HDFS(使用非开源的组件)。可以使用本地Unix命令来代替Hadoop命令。除此之外,MapR还凭借诸如快照、镜像或有状态的故障恢复之类的高可用性特性来与其他竞争者相区别。该公司也领导着Apache Drill项目,本项目是Google的Dremel的开源项目的重新实现,目的是在Hadoop数据上执行类似SQL的查询以提供实时处理。
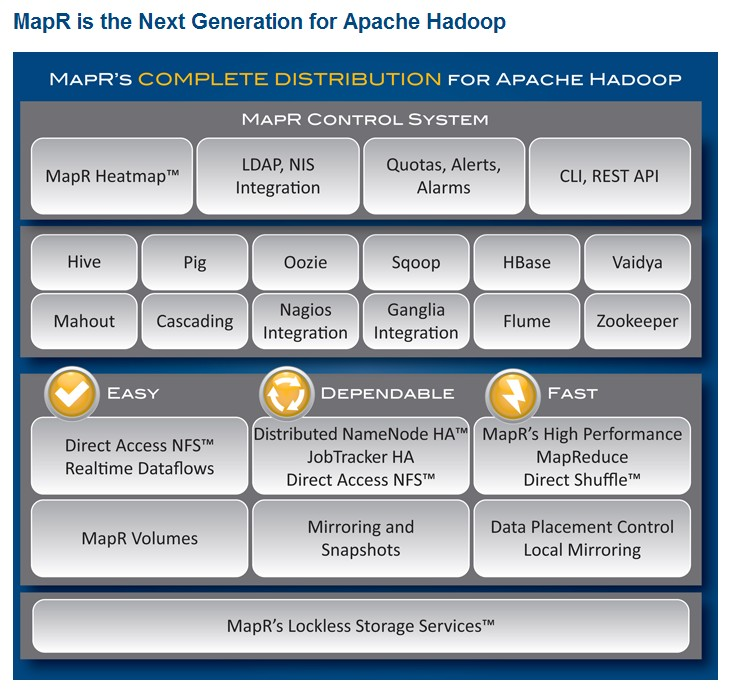
四、版本选择
当我们决定是否采用某个软件用于开源环境时,通常需要考虑以下几个因素:
(1)是否为开源软件,即是否免费。
(2) 是否有稳定版,这个一般软件官方网站会给出说明。
(3) 是否经实践验证,这个可通过检查是否有一些大点的公司已经在生产环境中使用知道。
(4) 是否有强大的社区支持,当出现一个问题时,能够通过社区、论坛等网络资源快速获取解决方法。
题外篇:
市场,场景,策略及上市的步调不同
三家马车中,Hortonwork和Cloudera先后上市,MapR也加快了上市步伐。
2014年,Hortonworks成功IPO在纳斯达克上市。该公司以每股16美元的价格发行625万股股票,募集1亿美元资金,开盘首日上涨幅度达到60%,市值接近11亿美元。

2017年4月底,Cloudera以每股15美元的定价在纽约证券交易所上市,股价一日上涨超20%至18.09美元。这一价格也超出了此前公司12到14美元的预期范围。Cloudera目前市值约为23亿美元,远低于2014年英特尔给出的41亿美元估值。
MapR于2009年成立,曾在五轮风险投资里拿到1.14亿美元。公司的风投支持者通常希望看到两个结果,其一是上市,另一个是被收购。但是媒体2017年6月报道,公司MapR的首席执行官米尔斯说不愿说上市的日期,但表示上市已提到议事日程上。米尔斯表示,“我想上市,但我也想尊重上市的步骤。”
赢利还是亏损
三大公司的营收情况怎么样?这可以说是Hadoop 商业化世界的一个风向标。

Hortonworks于2017年5月公布的消息现实,公司2017年第一季度收入5600万美元,同比增长35%,利润率更高,经营亏损收窄。但是目前依然是亏损。
Cloudera的收入正在增长,截止到1月份的上一财年营收达到2.61亿美元,亏损为1.86亿美元;2015财年营收为1.66亿美元,亏损2.03亿美元。Cloudera的多数营收都来自订阅收入,订阅期通常为1至3年,但他们还通过服务获取营收,包括专业服务、培训和教育等。
MapR公司的CEO米尔斯认为,MapR的销售额在不断增长,平均交易规模大于10万美元,但他不愿评论成本或亏损。
商业模式
同样基于开源的Hadoop,但是三大公司所采用的商业模式却各有不同。
Cloudera采用发布Hadoop商业版和发布商用工具的模式。所谓的Hadoop发行商,有点类似于Linux世界里的RedHat。公司通过开源软件的包装,整合稳定的版本形成一个套餐。通过让企业用户购买套餐来实现盈利。所以,Cloudera给所有使用了其Hadoop的套餐的用户提供收费技术支持。
同时,Cloudera也提供免费的版,用户可以在网站上随便下载免费使用的。但是Cloudera同时又提供如Cloudera Manager的企业管理组件,在最初三个月试用之后就要收费的。
MapR走的和Cloudera类似的商业模式,但是它是以发布商业化工具产品为主,同时提供发行版。
Hortonworks提供的软件都是100%开源免费下载,将核心技术放在Hadoop开源社区中,每个人都可以看到并使用。对于企业客户来说有了源代码,如何与自己系统相结合、增强功能、调试故障、对接应用等都是问题。企业客户如果想用这项技术,自己开发难度较大的话,就会选择合作。这就是Hortonworks的盈利模式,通过提供支持服务和后期维护,向企业级客户收费。
支持服务主要是通过订阅的方式,客户需要就某些功能预定一年或者几年的服务,提前付费。支持服务覆盖整个周期,从最初的开发和POC阶段,到中间的质量测试,直至产品交付。维护服务主要是对企业级客户的培训和一些咨询业务。
敢兴趣了解下 :Cloudera和Hortonworks的开源(撒逼)之战
Cloudera与Hortonworks谁能一骑绝尘?
关于Hortonworks沙盒HDP 3.0 URL不起作用和沙盒错误的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于/url 页面中的 Javascript 功能在使用 history.push(/url) onlick 后不起作用、Amazon Lex Bot响应卡附件链接URL不起作用、BD|Hortonworks 本地虚拟机之旅、Cloudera CDH 、Hortonworks DHP和MapR比较的相关信息,请在本站寻找。
本文将带您了解关于我的Django Python代码未更改数据库记录的新内容,同时我们还将为您解释python代码不能修改的相关知识,另外,我们还将为您提供关于django之分页,纯python代码、Python Django 数据库基础、Python Django 数据库查询优化 事务、python django 数据库查询方法总结的实用信息。
本文目录一览:")
我的Django Python代码未更改数据库记录(python代码不能修改)
query2 = NewPost.objects.filter(title = title).first().update(price = newBid)
update方法仅适用于一个查询集(一个以上的实例),请删除.first()并使用新价格更新该标题的所有NetPost。
像这样:NewPost.objects.filter(title = title).update(price = newBid)
,
我没有将Bid模型导入views.py

django之分页,纯python代码
Django中分页
py文件代码
"""
自定义分页组件
可以返回分页的数据和分页的HTML代码
"""
from django.http import QueryDict
class Pagination(object):
def __init__(self, current_page, total_count, url_prefix, query_dict=QueryDict(mutable=True), per_page=10,
show_page=9):
"""
初始化分分页器
:param url_prefix: a标签的URL前缀
:param current_page: 当前页码数
:param total_count: 数据总数
:param query_dict: 空的QueryDict()对象,并且是可修改的
:param per_page: 每一页显示多少数据, 默认值是10
:param show_page: 页面显示的页码数, 默认值是9
"""
# 0.分页的URL前缀
self.url_prefix = url_prefix
self.query_dict = query_dict
# 1. 每一页显示10条数据
self.per_page = per_page
assert per_page > 0
# 2. 计算需要多少页
total_page, more = divmod(total_count, per_page)
if more:
total_page += 1
self.total_page = total_page
# 3. 当前页码
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
current_page = total_page if current_page > total_page else current_page
# 页码必须是大于0的数
if current_page < 1:
current_page = 1
self.current_page = current_page
# 4. 页面最多显示的页码数
self.show_page = show_page
# 5. 最多显示页码的一半
self.half_show_page = self.show_page // 2
@property
def start(self):
# 数据切片的开始位置
return self.per_page * (self.current_page - 1)
@property
def end(self):
# 数据切片的结束为止
return self.current_page * self.per_page
# 定义一个返回HTML代码的方法
def page_html(self):
# 如果总页码数小于最大要显示的页码数
if self.total_page < self.show_page:
show_page_start = 1
show_page_end = self.total_page
# 左边越界
elif self.current_page - self.half_show_page < 1:
show_page_start = 1
show_page_end = self.show_page
# 右边越界
elif self.current_page + self.half_show_page > self.total_page:
show_page_end = self.total_page
show_page_start = self.total_page - self.show_page + 1
else:
show_page_start = self.current_page - self.half_show_page
# 页面显示页码的结束
show_page_end = self.current_page + self.half_show_page
# 生成分页的HTML代码
page_list = []
# 添加分页代码的前缀
page_list.append(''<nav aria-label="Page navigation"><ul>'')
# 添加首页
self.query_dict[''page''] = 1
page_list.append(f''<li><a href="{self.url_prefix}?{self.query_dict.urlencode()}">首页</a></li>'')
# 添加上一页
if self.current_page - 1 < 1: # 已经到头啦,不让点上一页啦
page_list.append(
''<li><a href="" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'')
else:
self.query_dict[''page''] = self.current_page - 1
page_list.append(
f''<li><a href="{self.url_prefix}?{self.query_dict.urlencode()}" aria-label="Previous">''
f''<span aria-hidden="true">«</span></a></li>''
)
for i in range(show_page_start, show_page_end + 1):
self.query_dict[''page''] = i
if i == self.current_page:
s = f''<li><a href="{self.url_prefix}?{self.query_dict.urlencode()}">{i}</a></li>''
else:
s = f''<li><a href="{self.url_prefix}?{self.query_dict.urlencode()}">{i}</a></li>''
page_list.append(s)
# 添加下一页
if self.current_page + 1 > self.total_page:
page_list.append(
''<li><a href="" aria-label="Next"><span aria-hidden="true">»</span></a></li>'')
else:
self.query_dict[''page''] = self.current_page + 1
page_list.append(
f''<li><a href="{self.url_prefix}?{self.query_dict.urlencode()}" aria-label="Next">''
f''<span aria-hidden="true">»</span></a></li>''
)
# 添加尾页
self.query_dict[''page''] = self.total_page
page_list.append(f''<li><a href="{self.url_prefix}?{self.query_dict.urlencode()}">尾页</a></li>'')
# 添加分页代码的后缀
page_list.append(''</ul></nav>'')
page_html = ''''.join(page_list)
return page_html
实例化对象
-
def dashboard(request):
# 获取当前网页路径
url_prefix = request.path_info
# 获取当前页码数
current_page = request.GET.get(''page'', 1)
# 获取所有客户的信息
customer_list = Customer.objects.all()
# 实例分页代码
pagination = Pagination(current_page=current_page, total_count=customer_list.count(), url_prefix=url_prefix, per_page=8)
# 获取当前页的数据
data = customer_list[pagination.start:pagination.end]
page_html = pagination.page_html()
return render(request, "Dashboard.html", {''customer_list'': data, "page_html": page_html})
前端代码
-
<div>
{{ page_html|safe }}
</div>
使用django脚本去创建数据
- 批量创建数据
- 使用Django脚本去创建数据
- bulk_create()

- 分页
- 纯Python基础写的,
- django里面获取当前url
- request.path_info 获取当前路径
- request.get_full_path 获取全路径
实际样式


Python Django 数据库基础




对数据库的操作可以直接使用SQL语句,也可以使用图形界面工具。这些一般是DBA(数据库管理人员)做的。开发人员是使用代码链接数据库,对数据库进行操作。






下面进行Python Django框架ORM创建数据库




Python Django 数据库查询优化 事务
一 数据库优化查询
1.惰性查询:orm内的所有语句操作,只有你真正需要数据的时候才会对数据库进行操作,如果只是单单写orm语句不会走数据库。这样的好处是减轻数据库压力。
2.only
res = models.Book.objects.only(‘title‘)
print(res)
for r in res:
print(r.title) # 只走一次数据库查询
print(r.price) # 当你点击一个不是only括号内指定的字段的时候 不会报错 而是会频繁的走数据库查询
3.defer
res1 = models.Book.objects.defer(‘title‘) # defer与only是相反的
for r in res1: # defer会将不是括号内的所有的字段信息 全部查询出来封装对象中
# # 一旦你点击了括号内的字段 那么会频繁的走数据库查询
print(r.price)
4.select_related:一对一,一对多
select_related帮你直接连表操作 查询数据 括号内只能放外键字段
res = models.Book.objects.all().select_related(‘publish‘)
for r in res:
print(r.publish.name)
res = models.Book.objects.all().select_related(‘publish__xxx__yyy__ttt‘)
print(res)
res = models.Book.objects.all()
"""
select_related:会将括号内外键字段所关联的那张表 直接全部拿过来(可以一次性拿多张表)跟当前表拼接操作
从而降低你跨表查询 数据库的压力
注意select_related括号只能放外键字段(一对一和一对多)
res = models.Book.objects.all().select_related(‘外键字段1__外键字段2__外键字段3__外键字段4‘)
总结:直接查连表
5.prefetch_related :不主动连表
res = models.Book.objects.prefetch_related(‘publish‘)
"""
不主动连表操作(但是内部给你的感觉像是连表操作了) 而是将book表中的publish全部拿出来 在取publish表中将id对应的所有的数据取出
res = models.Book.objects.prefetch_related(‘publish‘)
括号内有几个外键字段 就会走几次数据库查询操作
for r in res:
print(r.publish.name)
总结:先查一张表,在查另一张表
6.事务:它会自动回滚
from django.db import transaction
with transaction.atomic():
"""数据库操作
在该代码块中书写的操作 同属于一个事务
"""
models.Book.objects.create()
models.Publish.objects.create()
# 添加书籍和出版社 就是同一个事务 要么一起成功要么一起失败
print(‘出了 代码块 事务就结束‘)

python django 数据库查询方法总结
__exact 精确等于 like ‘aaa’
__iexact 精确等于 忽略大小写 ilike ‘aaa’
__contains 包含 like ‘%aaa%’
__icontains 包含 忽略大小写 ilike ‘%aaa%’,但是对于sqlite来说,contains的作用效果等同于icontains。
__gt 大于
__gte 大于等于
__lt 小于
__lte 小于等于
__in 存在于一个list范围内
__startswith 以…开头
__istartswith 以…开头 忽略大小写
__endswith 以…结尾
__iendswith 以…结尾,忽略大小写
__range 在…范围内
__year 日期字段的年份
__month 日期字段的月份
__day 日期字段的日
__isnull=True/False
__isnull=True 与 __exact=None的区别
class Blog(models.Model):
name = models.CharField(max_length=100)
tagline = models.TextField()
def __unicode__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=50)
email = models.EmailField()
def __unicode__(self):
return self.name
class Entry(models.Model):
blog = models.ForeignKey(Blog)
headline = models.CharField(max_length=255)
body_text = models.TextField()
pub_date = models.DateTimeField()
authors = models.ManyToManyField(Author)
def __unicode__(self):
return self.headline
这是model,有blog,author,以及entry;其中entry分别与blog与author表关 联,entry与blog表是通过 外键(models.ForeignKey())相连,属于一对多的关系,即一个entry对应多个blog,entry与author是多对多的关系, 通过modles.ManyToManyField()实现。
一、插入数据库,用save()方法实现,如下:
>>> from mysite.blog.models import Blog
>>> b = Blog(name=’Beatles Blog’, tagline=’All the latest Beatles news.’)
>>> b.save()
二、更新数据库,也用save()方法实现,如下:
>> b5.name = ‘New name’
>> b5.save()
保存外键和多对多关系的字段,如下例子:
更新外键字段和普通的字段一样,只要指定一个对象的正确类型。
>>> cheese_blog = Blog.objects.get(name=”Cheddar Talk”)
>>> entry.blog = cheese_blog
>>> entry.save()
更新多对多字段时又一点不太一样,使用add()方法添加相关联的字段的值。
>> joe = Author.objects.create(name=”Joe”)
>> entry.authors.add(joe)
三、检索对象
>>> Blog.objects
>>> b = Blog(name=’Foo’, tagline=’Bar’)
>>> b.objects
Traceback:
…
AttributeError: “Manager isn’t accessible via Blog instances.”
1、检索所有的对象
>>> all_entries = Entry.objects.all()
使用all()方法返回数据库中的所有对象。
2、检索特定的对象
使用以下两个方法:
fileter(**kwargs)
返回一个与参数匹配的QuerySet,相当于等于(=).
exclude(**kwargs)
返回一个与参数不匹配的QuerySet,相当于不等于(!=)。
Entry.objects.filter(pub_date__year=2006)
不使用Entry.objects.all().filter(pub_date__year=2006),虽然也能运行,all()最好再获取所有的对象时使用。
上面的例子等同于的sql语句:
slect * from entry where pub_date_year=’2006′
链接过滤器:
>>> Entry.objects.filter(
… headline__startswith=’What’
… ).exclude(
… pub_date__gte=datetime.now()
… ).filter(
… pub_date__gte=datetime(2005, 1, 1)
… )
最后返回的QuerySet是headline like ‘What%’ and put_date2005-01-01
另外一种方法:
>> q1 = Entry.objects.filter(headline__startswith=”What”)
>> q2 = q1.exclude(pub_date__gte=datetime.now())
>> q3 = q1.filter(pub_date__gte=datetime.now())
这种方法的好处是可以对q1进行重用。
QuerySet是延迟加载
只在使用的时候才会去访问数据库,如下:
>>> q = Entry.objects.filter(headline__startswith=”What”)
>>> q = q.filter(pub_date__lte=datetime.now())
>>> q = q.exclude(body_text__icontains=”food”)
>>> print q
在print q时才会访问数据库。
其他的QuerySet方法
>>> Entry.objects.all()[:5]
这是查找前5个entry表里的数据
>>> Entry.objects.all()[5:10]
这是查找从第5个到第10个之间的数据。
>>> Entry.objects.all()[:10:2]
这是查询从第0个开始到第10个,步长为2的数据。
>>> Entry.objects.order_by(‘headline’)[0]
这是取按headline字段排序后的第一个对象。
>>> Entry.objects.order_by(‘headline’)[0:1].get()
这和上面的等同的。
>>> Entry.objects.filter(pub_date__lte=’2006-01-01′)
等同于SELECT * FROM blog_entry WHERE pub_date <= ’2006-01-01′; >>> Entry.objects.get(headline__exact=”Man bites dog”)
等同于SELECT … WHERE headline = ‘Man bites dog’;
>>> Blog.objects.get(id__exact=14) # Explicit form
>>> Blog.objects.get(id=14) # __exact is implied
这两种方式是等同的,都是查找id=14的对象。
>>> Blog.objects.get(name__iexact=”beatles blog”)
查找name=”beatles blog”的对象,不去饭大小写。
Entry.objects.get(headline__contains=’Lennon’)
等同于SELECT … WHERE headline LIKE ‘%Lennon%’;
startswith 等同于sql语句中的 name like ‘Lennon%’,
endswith等同于sql语句中的 name like ‘%Lennon’.
>>> Entry.objects.filter(blog__name__exact=’Beatles Blog’)
查找entry表中外键关系blog_name=’Beatles Blog’的Entry对象。
>>> Blog.objects.filter(entry__headline__contains=’Lennon’)
查找blog表中外键关系entry表中的headline字段中包含Lennon的blog数据。
Blog.objects.filter(entry__author__name=’Lennon’)
查找blog表中外键关系entry表中的author字段中包含Lennon的blog数据。
Blog.objects.filter(entry__author__name__isnull=True)
Blog.objects.filter(entry__author__isnull=False,entry__author__name__isnull=True)
查询的是author_name为null的值
Blog.objects.filter(entry__headline__contains=’Lennon’,entry__pub_date__year=2008)
Blog.objects.filter(entry__headline__contains=’Lennon’).filter( entry__pub_date__year=2008)
这两种查询在某些情况下是相同的,某些情况下是不同的。第一种是限制所有的blog数据的,而第二种情况则是第一个filter是
限制blog的,而第二个filter则是限制entry的
>>> Blog.objects.get(id__exact=14) # Explicit form
>>> Blog.objects.get(id=14) # __exact is implied
>>> Blog.objects.get(pk=14) # pk implies id__exact
等同于select * from where id=14
# Get blogs entries with id 1, 4 and 7
>>> Blog.objects.filter(pk__in=[1,4,7])
等同于select * from where id in{1,4,7}
# Get all blog entries with id > 14
>>> Blog.objects.filter(pk__gt=14)
等同于select * from id>14
>>> Entry.objects.filter(blog__id__exact=3) # Explicit form
>>> Entry.objects.filter(blog__id=3) # __exact is implied
>>> Entry.objects.filter(blog__pk=3) # __pk implies __id__exact
这三种情况是相同的
>>> Entry.objects.filter(headline__contains=’%'')
等同于SELECT … WHERE headline LIKE ‘%\%%’;
Caching and QuerySets
>>> print [e.headline for e in Entry.objects.all()]
>>> print [e.pub_date for e in Entry.objects.all()]
应改写为:
>> queryset = Poll.objects.all()
>>> print [p.headline for p in queryset] # Evaluate the query set.
>>> print [p.pub_date for p in queryset] # Re-use the cache from the evaluation.、
这样利用缓存,减少访问数据库的次数。
四、用Q对象实现复杂的查询
Q(question__startswith=’Who’) | Q(question__startswith=’What’)
等同于WHERE question LIKE ‘Who%’ OR question LIKE ‘What%’
Poll.objects.get(
Q(question__startswith=’Who’),
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
等同于SELECT * from polls WHERE question LIKE ‘Who%’ AND (pub_date = ’2005-05-02′ OR pub_date = ’2005-05-06′)
Poll.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
question__startswith=’Who’)
等同于Poll.objects.get(question__startswith=’Who’, Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)))
五、比较对象
>>> some_entry == other_entry
>>> some_entry.id == other_entry.id
六、删除
Entry.objects.filter(pub_date__year=2005).delete()
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
Entry.objects.all().delete()
删除所有
七、一次更新多个值
# Update all the headlines with pub_date in 2007.
Entry.objects.filter(pub_date__year=2007).update(headline=’Everything is the same’)
>>> b = Blog.objects.get(pk=1)
# Change every Entry so that it belongs to this Blog.
>>> Entry.objects.all().update(blog=b)
如果用save()方法,必须一个一个进行保存,需要对其就行遍历,如下:
for item in my_queryset:
item.save()
关联对象
one-to-many
>>> e = Entry.objects.get(id=2)
>>> e.blog # Returns the related Blog object.
>>> e = Entry.objects.get(id=2)
>>> e.blog = some_blog
>>> e.save()
>>> e = Entry.objects.get(id=2)
>>> e.blog = None
>>> e.save() # “UPDATE blog_entry SET blog_id = NULL …;”
>>> e = Entry.objects.get(id=2)
>>> print e.blog # Hits the database to retrieve the associated Blog.
>>> print e.blog # Doesn’t hit the database; uses cached version.
>>> e = Entry.objects.select_related().get(id=2)
>>> print e.blog # Doesn’t hit the database; uses cached version.
>>> print e.blog # Doesn’t hit the database; uses cached version
>>> b = Blog.objects.get(id=1)
>>> b.entry_set.all() # Returns all Entry objects related to Blog.
# b.entry_set is a Manager that returns QuerySets.
>>> b.entry_set.filter(headline__contains=’Lennon’)
>>> b.entry_set.count()
>>> b = Blog.objects.get(id=1)
>>> b.entries.all() # Returns all Entry objects related to Blog.
# b.entries is a Manager that returns QuerySets.
>>> b.entries.filter(headline__contains=’Lennon’)
>>> b.entries.count()
You cannot access a reverse ForeignKey Manager from the class; it must be accessed from an instance:
>>> Blog.entry_set
add(obj1, obj2, …)
Adds the specified model objects to the related object set.
create(**kwargs)
Creates a new object, saves it and puts it in the related object set. Returns the newly created object.
remove(obj1, obj2, …)
Removes the specified model objects from the related object set.
clear()
Removes all objects from the related object set.
many-to-many类型:
e = Entry.objects.get(id=3)
e.authors.all() # Returns all Author objects for this Entry.
e.authors.count()
e.authors.filter(name__contains=’John’)
a = Author.objects.get(id=5)
a.entry_set.all() # Returns all Entry objects for this Author.
one-to-one 类型:
class EntryDetail(models.Model):
entry = models.OneToOneField(Entry)
details = models.TextField()
ed = EntryDetail.objects.get(id=2)
ed.entry # Returns the related Entry object
使用sql语句进行查询:
def my_custom_sql(self):
from django.db import connection
cursor = connection.cursor()
cursor.execute(“SELECT foo FROM bar WHERE baz = %s”, [self.baz])
row = cursor.fetchone()
return row
今天的关于我的Django Python代码未更改数据库记录和python代码不能修改的分享已经结束,谢谢您的关注,如果想了解更多关于django之分页,纯python代码、Python Django 数据库基础、Python Django 数据库查询优化 事务、python django 数据库查询方法总结的相关知识,请在本站进行查询。
最近很多小伙伴都在问python dash应用程序中的交互式英国县地图这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展Azure Python 函数应用程序中的 HTTP 请求、Flask-Login:Python web应用程序中的用户身份验证、Flask和PyCharm集成: Python web应用程序中的开发技巧、IPython 1.0发布,强大的Python交互式Shell等相关知识,下面开始了哦!
本文目录一览:
python dash应用程序中的交互式英国县地图
如何解决python dash应用程序中的交互式英国县地图?
我花了很长时间试图找出一种在Python Dash应用程序上放置交互式英国县地图的方法。
该地图将显示我在sqlite数据库中拥有的twitter开发人员api的tweet的位置。
我曾经尝试过使用folium,但是尝试从海量的GeoJSON文件中加载县区很麻烦,而且需要很长时间,而且我只能找到英国县区的GeoJSON文件。我还需要苏格兰和北爱尔兰。我确实不希望地图能够移动,但我意识到由于放大或缩小,可能不得不接受这一点。我只希望用户能够单击一个县并在网页的单独部分中显示Twitter数据。我还想在我的sqlite数据库中将有关推文的标记放在相关县中,这些推文具有位置数据。然后,用户可以单击标记并显示该推文的文本。
我知道amcharts有uk-counties.svg图表,但是:
a)我无法理解如何将其嵌入到Dash网页中,并且
b)如果确实在网页上获取了该信息,那么我是否可以显示位置数据,如果可以,那么如何显示?
我看过MapBox,openstreetmap和google地图,但是对于我想做的事情,它们似乎都过于复杂。
任何帮助/建议将不胜感激。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

Azure Python 函数应用程序中的 HTTP 请求
针对此问题,请检查该功能是否及时显示日志。请点击“监控”查看日志,但不要在“日志”窗口查看日志,因为日志有时不会显示在“日志”窗口中。顺便说一下,登录“监控”可能会延迟大约 5 分钟。

然后请检查您的功能是否超时。消费计划中的函数默认设置超时值为5分钟。因此,如果您的请求在函数中存在多个请求,并且每个请求都需要数十秒,请set functionTimeout 在“host.json”中使用 00:10:00(functionTimeout 的最大值在消费计划中是 10 分钟)。
如果该函数仍然不起作用,请检查您是否在您的定时器触发函数中请求了其他 HttpTrigger 函数 url(并且 HttpTrigger 函数与您的定时器触发函数在同一个函数应用程序中)。如果是这样,可能会导致一些问题,您可以参考这个post,我过去发现了类似的问题。解决这个问题,只需要另外创建一个函数应用,将定时器触发函数和http触发函数分开即可。

Flask-Login:Python web应用程序中的用户身份验证
flask-login:python web应用程序中的用户身份验证
在基于Python的Web应用程序开发中,安全性和用户身份验证是不可或缺的一部分。Flask-Login是一个优秀的Python库,可以帮助开发人员轻松地将身份验证功能添加到他们的Flask应用程序中,并提供了一个简单而灵活的方式来处理用户登录和注销。
本文将向您介绍Flask-Login的基本功能和用法,并说明为什么它是Python web应用程序中的身份验证首选之一。
Flask-Login的基本功能
Flask-Login是一个允许开发人员快速而可靠地实现用户身份验证和管理的Python库。它提供了以下主要功能:
立即学习“Python免费学习笔记(深入)”;
- 用户登录和注销
通过Flask-Login,您可以轻松地设置用户登录和注销的路由,并管理用户会话。这意味着您的应用程序可以跟踪已经登录的用户,并在必要时使他们注销。
- 用户会话管理
Flask-Login使用一个名为“Sessions”的管理器来处理用户会话。这个管理器可以自动将用户ID存储在加密cookie中,并在需要时检索它。
- 访问控制
Flask-Login使开发人员能够轻松地配置哪些部分需要身份验证,并提供了一些基本的访问控制功能。例如,您可以配置哪些页面只允许已登录的用户访问,并防止未经授权的访问。
- 身份验证流程
Flask-Login还提供了内置的身份验证流程。这使开发人员可以轻松地将自己的用户验证逻辑添加到应用程序中。
使用Flask-Login进行用户身份验证
现在我们已经介绍了Flask-Login的基本功能,那么让我们看看如何在Flask应用程序中使用它来进行用户身份验证。
首先,您需要安装Flask-Login库。您可以使用pip命令进行安装:
pip install flask-login
登录后复制
一旦您安装了Flask-Login,就可以开始使用它了。最简单的方法是将它导入到您的应用程序中:
from flask_login import LoginManager, UserMixin, login_required, login_user, logout_user, current_user
登录后复制
这些导入将使您能够使用Flask-Login的主要功能。
下一步是创建一个Flask应用程序,并初始化LoginManager。您可以像这样创建一个名为app的Flask应用程序:
from flask import Flask
app = Flask(__name__)
app.secret_key = ''your secret key''
login_manager = LoginManager()
login_manager.init_app(app)
登录后复制
在这里,我们创建了一个名为app的Flask应用程序,并为应用程序提供了一个密钥,以便Flask可以加密会话cookie。随后,我们创建了一个名为login_manager的LoginManager对象,并通过init_app()方法将其初始化。
有些时候,您的应用程序可能需要自定义用户模型。在这种情况下,您需要创建一个扩展UserMixin的用户模型,并实现一些必要的方法(例如get_id())。
以下是一个简单的自定义用户模型示例:
class User(UserMixin):
pass登录后复制
现在,让我们假设您已经设置了自己的用户模型,并且希望让用户登录到您的应用程序中。
首先创建一个用于管理员控制面板的路由,并配置仅允许已登录的用户访问:
@app.route(''/admin'')
@login_required
def admin():
return ''Welcome to the admin panel!''登录后复制
这个路由将只允许已登录的用户访问。如果未登录的用户尝试访问此路由,他们将被重定向到登录页面。
接下来创建一个用于处理用户登录页面的路由:
@app.route(''/login'', methods=[''GET'', ''POST''])
def login():
if request.method == ''POST'':
username = request.form[''username'']
password = request.form[''password'']
# Your authentication logic goes here
user = User()
user.id = username
# Login the user
login_user(user)
return redirect(url_for(''admin''))
return render_template(''login.html'')登录后复制
在这个路由中,我们首先检查请求的方法是否为POST。如果是,我们检索提交的用户名和密码,并执行自己的身份验证逻辑。然后,我们创建一个新的User对象,并将其登录到我们的应用程序中。如果验证成功,我们将重定向到我们的管理员控制面板。
最后创建一个路由用于处理用户注销:
@app.route(''/logout'')
def logout():
logout_user()
return redirect(url_for(''index''))登录后复制
Logout路由简单地调用logout_user()函数,并将用户重定向到主页。
结论
本文介绍了Flask-Login的基本功能和如何使用它进行用户身份验证。Flask-Login是一个简单而灵活的Python库,可以轻松地将身份验证功能添加到您的Flask应用程序中,并提供了许多有用的功能,如会话管理、访问控制和内置的身份验证流程等。
如果您正在开发基于Python的Web应用程序,并需要对用户进行身份验证,那么Flask-Login是值得考虑的首选。
以上就是Flask-Login:Python web应用程序中的用户身份验证的详细内容,更多请关注php中文网其它相关文章!

Flask和PyCharm集成: Python web应用程序中的开发技巧
python是一门非常流行的编程语言,可以用于各种不同的任务,包括web开发。在python中,有许多web框架可供选择,其中flask是最受欢迎的之一。flask是一个轻量级的、可靠的、灵活的web框架,它具有简单易用的api和强大的模板引擎。而在flask的开发过程中,pycharm是一个非常好用的集成开发环境(ide)。本文将介绍如何将flask和pycharm集成起来,以便您更轻松地开发python web应用程序。
为什么选择Flask?
在选择Python web框架时,有许多不同的选择。Flask之所以受欢迎,是因为它非常灵活。Flask的核心非常小,但它提供了许多可选的扩展,这些扩展可以根据需要添加到项目中。此外,许多开发人员喜欢使用Flask的原因是它具有简单易用的API、强大的模板引擎以及与数据库集成的能力。总之,Flask是一个非常流行的Python web框架,值得一试。
为什么选择PyCharm?
PyCharm是一个非常好用的Python集成开发环境,它提供了许多有用的功能,可以帮助开发人员更轻松地开发Python应用程序。PyCharm支持Python语言的所有功能,并提供了强大的调试、测试和代码分析工具。此外,PyCharm还提供了许多第三方扩展,可以帮助开发人员更轻松地与其他工具集成。总之,如果您正在使用Python进行开发,那么PyCharm是一个很好的选择。
立即学习“Python免费学习笔记(深入)”;
Flask和PyCharm集成的步骤
- 创建一个Flask应用程序
首先,我们需要创建一个新的Flask应用程序。可以在PyCharm中使用Flask模板创建新的应用程序。要创建新的Flask应用程序,请按照以下步骤操作:
- 在PyCharm的主菜单中,选择“File”->“New Project”
- 在新项目对话框中,选择“Flask”项目类型
- 在项目设置对话框中,输入项目名称和项目路径
- 单击“Create”按钮,即可创建新项目
- 配置PyCharm中的Flask解释器
在PyCharm中,可以使用不同的解释器来运行Python应用程序。我们需要配置一个新的Flask解释器,以便PyCharm可以在调试和运行应用程序时正确识别Flask的API。要配置新的Flask解释器,请按照以下步骤操作:
- 在PyCharm的主菜单中,选择“File”->“Settings”
- 在设置对话框中,选择“Project”->“Project Interpreter”
- 单击齿轮图标,然后选择“Add”
- 在添加解释器对话框中,选择“Virtualenv Environment”和“New Environment”
- 选择要创建虚拟环境的位置和解释器版本
- 单击“OK”按钮,即可创建新的虚拟环境
- 设置Flask配置变量
在Flask应用程序中,可以使用配置变量来控制应用程序的行为。配置变量可以使应用程序更加灵活,并允许开发人员在部署不同环境时轻松地更改应用程序的行为。要设置Flask配置变量,请编辑app.py文件,并添加以下代码:
app.config.from_object(''config'')登录后复制
这将使用config.py文件中的变量来配置Flask应用程序。
- 配置PyCharm中的调试器
在PyCharm中,可以使用不同的调试器来调试Python应用程序。我们需要为Flask应用程序配置一个新的调试器,以便在调试时可以轻松地识别请求和变量。要配置新的调试器,请按照以下步骤操作:
- 在PyCharm的主菜单中,选择“Run”->“Edit Configurations”
- 在配置对话框中,单击“+”按钮,然后选择“Python”
- 在新的Python配置中,输入配置名称和项目路径
- 在“Script path”字段中,输入Flask应用程序的入口文件(通常为app.py)
- 在“Parameters”字段中,输入“runserver --debugger --reload”
- 将解释器设置为之前创建的虚拟环境
- 单击“OK”按钮,即可保存新配置
- 运行Flask应用程序
现在,我们可以在PyCharm中运行Flask应用程序了。要运行Flask应用程序,请按照以下步骤操作:
- 单击“Run”->“Run xxxx”(配置的名称)
- PyCharm将启动调试器,并在浏览器中打开应用程序
如果一切正常,您应该可以在浏览器中看到Flask应用程序的欢迎页面。此外,在PyCharm中,您可以使用调试器来检查请求和变量,并在出现错误时轻松地调试应用程序。
总结
在Python web应用程序的开发过程中,Flask是一个非常流行的web框架,PyCharm是一个非常好用的集成开发环境(IDE)。通过将Flask和PyCharm集成起来,您可以更轻松地开发Python web应用程序,并使用强大的调试和测试工具来调试应用程序。如果您正在使用Python进行开发,并且想要尝试Flask和PyCharm集成,那么本文中的步骤应该可以帮助您开始。
以上就是Flask和PyCharm集成: Python web应用程序中的开发技巧的详细内容,更多请关注php中文网其它相关文章!

IPython 1.0发布,强大的Python交互式Shell
在今年年初颁布的“2012年度自由软件奖”中,开发者Fernando Perez凭借IPython这一项目获得了2012年度自由软件推动奖。
今天IPython项目终于发布了1.0版本。
IPython是一个Python交互式Shell,提供了一个强大的交互式计算架构。支持变量自动补全、自动缩进,且支持 bash shell 命令,内置了许多很有用的功能和函数,比默认的Python Shell 好用得多。
IPython提供了丰富的工具包,以帮助你尽可能地交互式地使用Python。其主要组件包括:
强大的交互式的Python shells(基于终端和基于Qt方式)。一个基于Web的交互式笔记环境,拥有所有shell功能,以及支持嵌入式图形、动画和富媒体。支持交互式数据可视化,支持使用GUI工具包。灵活、可嵌入的解释器,可加载到自己的项目中。一个高性能库,可用于多核心系统、集群、超级计算和云场景中的高级、交互式并行计算。IPython是一个增强版的Python shell,其shell方面的主要特性如下:
全面的对象自省机制。跨会话、持久的历史输入记录。在会话期间对输出结果进行缓存,并自动生成引用。扩展标签自动完成。默认支持Python变量、关键字、文件名和函数关键字的自动完成。一个丰富的配置系统,可以在不同的设置之间轻松切换。会话记录和重载。针对特殊用途的扩展语法处理功能。可通过扩展的别名系统来访问系统shell。可轻松嵌入到其他Python程序和GUI中。集成访问PDB调试器和Python分析器的功能。IPython还是一个交互式并行计算架构,主要特性如下:
从一个交互式的Python/IPython会话中快速并行化Python代码。一个灵活、动态的处理模型,可被部署到从多核心工作站到超级计算机等的任何系统中。一个支持多种不同并行风格(从消息传递到任务处理)的架构。阻塞和完全异步接口。高级别API,只需几行代码就可以将许多事情并行化处理。可与其他用户安全地共享实时并行作业。动态负载均衡任务放牧(task farming)系统。强大的并行代码错误处理功能。详细信息:IPython 1.0.0
官方网站:http://ipython.org/
项目地址:https://github.com/ipython
国内镜像地址:https://code.csdn.net/OS_Mirror/ipython
我们今天的关于python dash应用程序中的交互式英国县地图的分享就到这里,谢谢您的阅读,如果想了解更多关于Azure Python 函数应用程序中的 HTTP 请求、Flask-Login:Python web应用程序中的用户身份验证、Flask和PyCharm集成: Python web应用程序中的开发技巧、IPython 1.0发布,强大的Python交互式Shell的相关信息,可以在本站进行搜索。
")
 onlick 后不起作用")





