本篇文章给大家谈谈在ReactJS中使用onClick复制组件,以及react点击复制的知识点,同时本文还将给你拓展javascript–如何强制组件在React中使用钩子重新渲染?、onclick–
本篇文章给大家谈谈在React JS中使用onClick复制组件,以及react点击复制的知识点,同时本文还将给你拓展javascript – 如何强制组件在React中使用钩子重新渲染?、onclick – 如何在React子组件中设置事件处理程序、onClick 按钮触发所有组件打开 - Reactjs、onClick可以工作,但是onDoubleClick在React组件上被忽略等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- 在React JS中使用onClick复制组件(react点击复制)
- javascript – 如何强制组件在React中使用钩子重新渲染?
- onclick – 如何在React子组件中设置事件处理程序
- onClick 按钮触发所有组件打开 - Reactjs
- onClick可以工作,但是onDoubleClick在React组件上被忽略
")
在React JS中使用onClick复制组件(react点击复制)
一般的工作流程是将组件数据(或仅标识符)存储在状态中的数组中。然后,您可以在数组上映射以呈现Component列表。该按钮将新的标识符/数据集添加到数组。
const App = () => {
const [list,setList] = useState([0]);
const addComponent = () => {
setList([...list,list.length]);
};
return (
<>
{list.map(id => <Component key={id} />)}
<button onClick={addComponent}>Add New Component</button>
</>
)
};
这是一个非常简单的示例。实际上,您可能希望为这些键分配唯一的ID,并可能将其与更多数据打包在一起作为对象,但是您明白了。

javascript – 如何强制组件在React中使用钩子重新渲染?
import { useState } from 'react';
function Example() {
const [count,setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
基本上我们使用this.forceUpdate()方法强制组件立即在React类组件中重新渲染,如下例所示
class Test extends Component{
constructor(props){
super(props);
this.state = {
count:0,count2: 100
}
this.setCount = this.setCount.bind(this);//how can I do this with hooks in functional component
}
setCount(){
let count = this.state.count;
count = count+1;
let count2 = this.state.count2;
count2 = count2+1;
this.setState({count});
this.forceUpdate();
//before below setState the component will re-render immediately when this.forceUpdate() is called
this.setState({count2: count
}
render(){
return (<div>
<span>Count: {this.state.count}></span>.
<button onClick={this.setCount}></button>
</div>
}
}
但我的查询是如何强制上面的功能组件立即用钩子重新渲染?
解决方法
let [,updateState] = React.useState(); ... updateState();
forceUpdate不适合在正常情况下使用,仅用于测试或其他未完成的情况.可以以更传统的方式解决这种情况.
setCount是未正确使用的forceUpdate的示例.由于性能原因,setState是异步的,因为状态更新没有正确执行,所以不应该强制它是同步的.如果状态依赖于先前设置的状态,则应使用updater function完成,
If you need to set the state based on the prevIoUs state,read about the updater argument below.
<…>
Both state and props received by the updater function are guaranteed
to be up-to-date. The output of the updater is shallowly merged with
state.
setCount可能不是一个说明性的例子,因为它的目的不明确,但更新程序功能就是这种情况:
setCount(){
this.setState(({count}) => ({ count: count + 1 }));
this.setState(({count2}) => ({ count2: count + 1 }));
this.setState(({count}) => ({ count2: count + 1 }));
}

onclick – 如何在React子组件中设置事件处理程序
[ANN]<click ... [ANN] ... [BOB]<click ... [BOB]
[Ann] [Ann]
[Bob]<click + ajax [Bob]
[Cal] [Cal]
最终目标是根据用户的选择异步地更改页面内容。点击Bob应该触发handleClick,但不是。
作为一个附注,我对组件DidMount调用this.handleClick()的方式感到非常高兴,但它现在可以作为从服务器获取初始菜单内容的一种方式。
/** @jsx React.DOM */
var CurrentSelection = React.createClass({
componentDidMount: function() {
this.handleClick();
},handleClick: function(event) {
alert('clicked');
// Ajax details ommitted since we never get here via onClick
},getinitialState: function() {
return {title: "Loading items...",items: []};
},render: function() {
var itemNodes = this.state.items.map(function (item) {
return <li key={item}><a href='#' onClick={this.handleClick}>{item}</a></li>;
});
return <ul className='nav'>
<li className='dropdown'>
<a href='#' className='dropdown-toggle' data-toggle='dropdown'>{this.state.title}</a>
<ul className='dropdown-menu'>{itemNodes}</ul>
</li>
</ul>;
}
});
$(document).ready(function() {
React.renderComponent(
CurrentSelection(),document.getElementById('item-selection')
);
});
我几乎是积极的,我对javascript范围的朦胧理解是责怪的,但是我迄今尝试的一切都失败了(包括尝试通过道具传递处理程序)。
var itemNodes = this.state.items.map(function (item) {
return <li key={item}><a href='#' onClick={this.handleClick}>{item}</a></li>;
}.bind(this));
或者创建一个这样的副本,并使用它:
var _this = this,itemNodes = this.state.items.map(function (item) {
return <li key={item}><a href='#' onClick={_this.handleClick}>{item}</a></li>;
})

onClick 按钮触发所有组件打开 - Reactjs
如何解决onClick 按钮触发所有组件打开 - Reactjs?
我实现了一个卡片组件,并基本上根据一些输入数据生成了一堆卡片。我在每张卡片上的按钮点击上绑定了一个 setter 函数,它基本上可以展开和折叠它。即使在将唯一键放入 div 之后也会触发所有卡片一次打开。
代码如下:
import React,{ useState } from ''react'';
import PrettyPrintJson from ''./PrettyPrintJson'';
import ''./Card.scss'';
import ''../App.scss'';
const Card = (props) => {
const { data } = props;
const [collapse,toggleCollapse] = useState(true);
return (<div className="card-group">
{data.map((obj,idx)=>{
return <div className="card" key={`${idx}_${obj?.lastModifiedOn}`}>
<div className="card-header">
<h4 className="card-title">{`fId: ${obj?.fId}`}</h4>
<h6 className="card-title">{`name: ${obj?.name}`}</h6>
<h6 className="card-title">{`status: ${obj?.status}`}</h6>
<div className="heading-elements">
<button className="btn btn-primary" onClick={() => toggleCollapse(!collapse)}>Show Json</button>
</div>
</div>
<div className={`card-content ${!collapse ? ''collapse show'' : ''collapsing''}`}>
<div className="card-body">
<div className="row">
<PrettyPrintJson data={ obj } />
</div>
</div>
</div>
</div>
})}
</div>
);
}
export default Card;
解决方法
创建一个管理自己状态的组件并渲染该组件。
const CardItem = ({ obj }) => {
const [collapse,toggleCollapse] = useState(true);
return (<div className="card">
<div className="card-header">
<h4 className="card-title">{`fId: ${obj?.fId}`}</h4>
<h6 className="card-title">{`name: ${obj?.name}`}</h6>
<h6 className="card-title">{`status: ${obj?.status}`}</h6>
<div className="heading-elements">
<button className="btn btn-primary" onClick={() => toggleCollapse(!collapse)}>Show Json</button>
</div>
</div>
<div className={`card-content ${!collapse ? ''collapse show'' : ''collapsing''}`}>
<div className="card-body">
<div className="row">
<PrettyPrintJson data={ obj } />
</div>
</div>
</div>
</div>)
}
然后渲染它
{data.map((obj,idx)=> (<CardItem obj={obj} key={idx} />))}
我认为您可以声明一个 int 类型的状态。之后就可以使用index(idx)和state的if语句了。
像这样:
const [collapsedCardNumbers,toggleCollapseCard] = useState([]);
const addCardNumber = (idx,prevState) => {
const arr_cardNum = prevState
!arr_cardNum .includes(idx) && arr_cardNum .push(idx)
return arr_cardNum
}
...
{data.map((obj,idx)=>{
return <div className="card" key={`${idx}_${obj?.lastModifiedOn}`}>
<div className="card-header">
<h4 className="card-title">{`fId: ${obj?.fId}`}</h4>
<h6 className="card-title">{`name: ${obj?.name}`}</h6>
<h6 className="card-title">{`status: ${obj?.status}`}</h6>
<div className="heading-elements">
<button className="btn btn-primary" onClick={() => toggleCollapseCard(prevState => addCardNumber(idx,prevState))}>Show Json</button>
</div>
</div>
<div className={`card-content ${collapsedCardNumbers.includes(idx) ? ''collapse show'' : ''collapsing''}`}>
<div className="card-body">
<div className="row">
<PrettyPrintJson data={ obj } />
</div>
</div>
</div>
</div>
})}

onClick可以工作,但是onDoubleClick在React组件上被忽略
如何解决onClick可以工作,但是onDoubleClick在React组件上被忽略?
这不是React的限制,而是DOMclick和dblclick事件的限制。根据Quirksmode的点击文档的建议:
不要在同一元素上注册click和dblclick事件:不可能将单击事件与导致dblclick事件的单击事件区分开。
有关更多最新文档,该dblclick事件的W3C规范指出:
当定点设备的主按钮在某个元素上单击两次时,用户代理必须调度此事件。
双击事件必然在两次单击事件之后发生。
:
建议阅读的另一本书是jQuery的dblclick处理程序:
将处理程序绑定到同一元素的click和dblclick事件都是不可取的。触发事件的顺序因浏览器而异,其中一些事件在dblclick之前收到两个click事件,其他事件仅收到一个。双击灵敏度(检测为两次单击之间的最长间隔时间)可能因操作系统和浏览器而异,并且通常可由用户配置。
解决方法
我正在使用React构建Minesweeper游戏,并且希望在单击单元格或双击单元格时执行其他操作。当前,该onDoubleClick功能永远不会触发,onClick显示来自的警报。如果我删除onClick处理程序,则onDoubleClick可以工作。为什么两个事件都不起作用?是否可以在一个元素上同时存在两个事件?
/** @jsx React.DOM */
var Mine = React.createClass({
render: function(){
return (
<div className="mineBox" id={this.props.id} onDoubleClick={this.props.onDoubleClick} onClick={this.props.onClick}></div>
)
}
});
var MineRow = React.createClass({
render: function(){
var width = this.props.width,row = [];
for (var i = 0; i < width; i++){
row.push(<Mine id={String(this.props.row + i)} boxClass={this.props.boxClass} onDoubleClick={this.props.onDoubleClick} onClick={this.props.onClick}/>)
}
return (
<div>{row}</div>
)
}
})
var MineSweeper = React.createClass({
handleDoubleClick: function(){
alert(''Double Clicked'');
},handleClick: function(){
alert(''Single Clicked'');
},render: function(){
var height = this.props.height,table = [];
for (var i = 0; i < height; i++){
table.push(<MineRow width={this.props.width} row={String.fromCharCode(97 + i)} onDoubleClick={this.handleDoubleClick} onClick={this.handleClick}/>)
}
return (
<div>{table}</div>
)
}
})
var bombs = [''a0'',''b1'',''c2''];
React.renderComponent(<MineSweeper height={5} width={5} bombs={bombs}/>,document.getElementById(''content''));
关于在React JS中使用onClick复制组件和react点击复制的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于javascript – 如何强制组件在React中使用钩子重新渲染?、onclick – 如何在React子组件中设置事件处理程序、onClick 按钮触发所有组件打开 - Reactjs、onClick可以工作,但是onDoubleClick在React组件上被忽略等相关内容,可以在本站寻找。
在本文中,我们将详细介绍当转义字符为quote的各个方面,并为您提供关于“时,Pyspark读取的csv不会读取整列的相关解答,同时,我们也将为您带来关于Java Spark读取ElasticSearch数据,并分析、java-CSV内容被Spark读取为null、Jupyter Notebook读取csv文件出现问题如何解决、Pycharm不会读取Python文件而不会出现错误的有用知识。
本文目录一览:- 当转义字符为quote(“)时,Pyspark读取的csv不会读取整列(转义字符不被处理)
- Java Spark读取ElasticSearch数据,并分析
- java-CSV内容被Spark读取为null
- Jupyter Notebook读取csv文件出现问题如何解决
- Pycharm不会读取Python文件而不会出现错误
时,Pyspark读取的csv不会读取整列(转义字符不被处理)")
当转义字符为quote(“)时,Pyspark读取的csv不会读取整列(转义字符不被处理)
它适用于这个设置
from pyspark.sql import SparkSession
tx = '''id,name,address,city,country
"1","",",1ST,""Round Street""",UK
"1"," ",UK
"id-1","name-1","city-1",UK'''
with open('temp.csv','wt') as file:
file.writelines(tx)
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option","some-value") \
.getOrCreate()
df = spark.read.format("csv")\
.option("sep",")\
.option("quote",'"')\
.option("escape",'"')\
.option("inferSchema","true")\
.option("header","true")\
.load('temp.csv').rdd.toDF()
df.select('address').show()
df.show()
运行
>>> from pyspark.sql import SparkSession
>>>
>>> tx = '''id,country
... "1",UK
... "1",UK
... "id-1",UK'''
>>>
>>> with open('temp.csv','wt') as file:
... file.writelines(tx)
...
>>> spark = SparkSession \
... .builder \
... .appName("Python Spark SQL basic example") \
... .config("spark.some.config.option","some-value") \
... .getOrCreate()
>>>
>>> df = spark.read.format("csv")\
... .option("sep",")\
... .option("quote",'"')\
... .option("escape",'"')\
... .option("inferSchema","true")\
... .option("header","true")\
... .load('temp.csv').rdd.toDF()
>>>
>>>
>>> df.show()
+----+------+--------------------+------+-------+
| id| name| address| city|country|
+----+------+--------------------+------+-------+
| 1| null|,"Round Str...| null| UK|
| 1| |,"Round Str...| null| UK|
|id-1|name-1|,"Round Str...|city-1| UK|
+----+------+--------------------+------+-------+
>>> df.select('address').show()
+--------------------+
| address|
+--------------------+
|,"Round Str...|
|,"Round Str...|
+--------------------+
测试版本
Python 3.6.12
pyspark==3.0.1
spark==0.2.1
我认为您使用的escape=参数与预期不符。
escape – sets a single character used for escaping quotes inside an already quoted value. If None is set,it uses the default value,\.
没有escape,您将获得所需的输出。

Java Spark读取ElasticSearch数据,并分析
直接在ES服务器上获取的数据如下所示
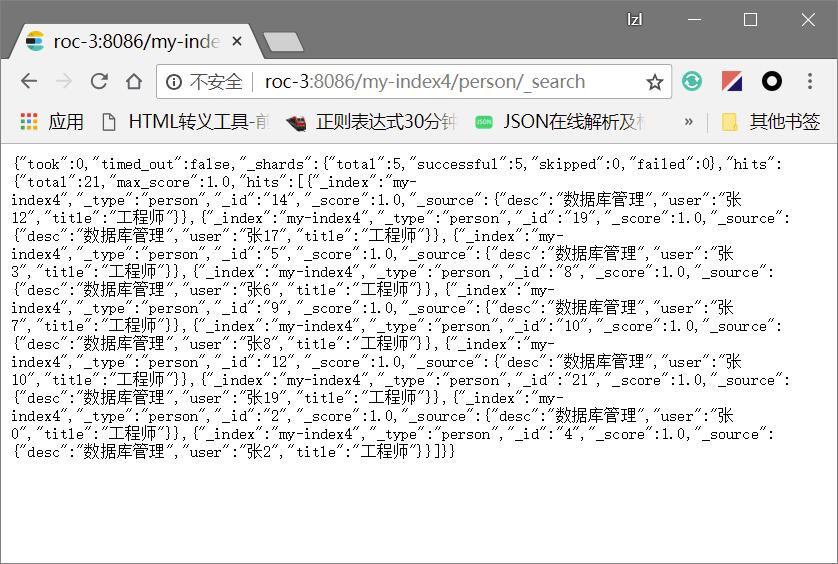
使用的java代码如下所示(可以看到数据都被封装成了tuple):
package mainPackage;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.SparkSession;
import org.elasticsearch.spark.rdd.api.java.JavaEsSpark;
import scala.Tuple2;
import java.util.Map;
public class MainClass {
public static void main(String[] args){
run1();
}
private static void run1(){
SparkConf conf = new SparkConf();
conf.setMaster("local[1]");
conf.setAppName("SPARK ES");
conf.set("es.index.auto.create", "true");
conf.set("es.nodes", "roc-3");
conf.set("es.port", "8086");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("ERROR");
JavaPairRDD<String, Map<String, Object>> esRDD =
JavaEsSpark.esRDD(sc, "my-index4/person");
for(Tuple2 tuple:esRDD.collect()){
System.out.print(tuple._1()+"----------");
System.out.println(tuple._2());
}
}
}运行的语句如下:
spark2-submit --master local[*] --packages org.elasticsearch:elasticsearch-hadoop:6.4.0 --class mainPackage.MainClass --repositories http://maven.aliyun.com/nexus/content/groups/public,http://conjars.org/repo/ AID-1.0-SNAPSHOT.jar如果读取的数据十分巨大,可以用下面的执行语句
spark2-submit --master local[*] --executor-memory 16G --driver-memory 32G --packages org.elasticsearch:elasticsearch-hadoop:6.4.0 --class mainPackage.MainClass --repositories http://maven.aliyun.com/nexus/content/groups/public,http://conjars.org/repo/ --conf spark.yarn.executor.memoryOverhead=8196 --conf spark.rpc.message.maxSize=2000 --conf spark.driver.maxResultSize=32g --conf spark.kryoserializer.buffer.max.mb=2040 --conf spark.debug.maxToStringFields=200 AID-1.0-SNAPSHOT.jar设置repository可以使用指定的资源库下载jar
最终结果数据
Using Spark''s default log4j profile: org/apache/spark/log4j-defaults.properties
18/09/07 19:19:21 INFO SparkContext: Running Spark version 2.0.0
……
省略N行
……
18/09/07 19:19:23 INFO MemoryStore: MemoryStore started with capacity 893.1 MB
18/09/07 19:19:23 INFO SparkEnv: Registering OutputCommitCoordinator
18/09/07 19:19:23 INFO Utils: Successfully started service ''SparkUI'' on port 4040.
18/09/07 19:19:23 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://10.116.16.141:4040
18/09/07 19:19:23 INFO Executor: Starting executor ID driver on host localhost
18/09/07 19:19:23 INFO Utils: Successfully started service ''org.apache.spark.network.netty.NettyBlockTransferService'' on port 10681.
18/09/07 19:19:23 INFO NettyBlockTransferService: Server created on 10.116.16.141:10681
18/09/07 19:19:23 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 10.116.16.141, 10681)
18/09/07 19:19:23 INFO BlockManagerMasterEndpoint: Registering block manager 10.116.16.141:10681 with 893.1 MB RAM, BlockManagerId(driver, 10.116.16.141, 10681)
18/09/07 19:19:23 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 10.116.16.141, 10681)
1----------{desc=数据库管理, user=张三, title=工程师}
7----------{desc=数据库管理, user=张5, title=工程师}
13----------{desc=数据库管理, user=张11, title=工程师}
16----------{desc=数据库管理, user=张14, title=工程师}
18----------{desc=数据库管理, user=张16, title=工程师}
2----------{desc=数据库管理, user=张0, title=工程师}
4----------{desc=数据库管理, user=张2, title=工程师}
6----------{desc=数据库管理, user=张4, title=工程师}
15----------{desc=数据库管理, user=张13, title=工程师}
20----------{desc=数据库管理, user=张18, title=工程师}
14----------{desc=数据库管理, user=张12, title=工程师}
19----------{desc=数据库管理, user=张17, title=工程师}
5----------{desc=数据库管理, user=张3, title=工程师}
8----------{desc=数据库管理, user=张6, title=工程师}
9----------{desc=数据库管理, user=张7, title=工程师}
10----------{desc=数据库管理, user=张8, title=工程师}
12----------{desc=数据库管理, user=张10, title=工程师}
21----------{desc=数据库管理, user=张19, title=工程师}
3----------{desc=数据库管理, user=张1, title=工程师}
11----------{desc=数据库管理, user=张9, title=工程师}
17----------{desc=数据库管理, user=张15, title=工程师}
Process finished with exit code 0
一些bug,配置版本和jackon时候需要注意,如果配置成如下就会出问题:
2.4.4。
而用这个版本就没事儿
默认es6.4.0版本会使用2.6.5版本的jackson来解析json数据,这样就OK
实验证明6.4.0版本es连接6.3.1取数不会遇到版本不兼容问题
最终成功的maven文件配置:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>SparkReadES</groupId>
<artifactId>AID</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>central</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<spark.version>2.0.0</spark.version>
<elasticsearch.version>6.4.0</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-spark-20_2.11</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<encoding>utf-8</encoding><!-- 指定项目源文件编码 -->
<source>${maven.compiler.source}</source><!-- 指定项目源文件jdk版本 -->
<target>${maven.compiler.target}</target><!-- 指定项目生成目标文件的jdk版本 -->
</configuration>
</plugin>
</plugins>
</build>
</project>
Done

java-CSV内容被Spark读取为null
我正在尝试读取CSV文件,以便可以使用Spark SQL查询它. CSV如下所示:
16;10;9/6/2018
CSV文件不包含标题,但是我们知道第一列是部门代码,第二列是建筑代码,第三列是格式为m / d / YYYY的日期.
我编写了以下代码以使用自定义架构加载CSV文件:
StructType sch = DataTypes.createStructType(new StructField[] {
DataTypes.createStructField("department",DataTypes.IntegerType,true),DataTypes.createStructField("building",false),DataTypes.createStructField("date",DataTypes.DateType,});
Dataset<Row> csvLoad = sparkSession.read().format("csv")
.option("delimiter",";")
.schema(sch)
.option("header","false")
.load(somefilePath);
csvLoad.show(2);
当我使用csvLoad.show(2)时,仅显示以下输出:
|department|building|date|
+----------+---------+---+
|null |null |null |
|null |null |null |
谁能告诉我代码中有什么问题吗?我正在使用spark 2.4版本.
Dataset<Row> csvLoad = sparkSession.read().format("csv")
.option("delimiter",";")
.schema(sch)
.option("header","false")
.option("dateFormat","m/d/YYYY")
.load(somefilePath);
这将导致输出:
+----------+--------+----------+
|department|building| date|
+----------+--------+----------+
| 16| 10|2018-01-06|
+----------+--------+----------+

Jupyter Notebook读取csv文件出现问题如何解决
这篇文章主要介绍“Jupyter Notebook读取csv文件出现问题如何解决”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Jupyter Notebook读取csv文件出现问题如何解决”文章能帮助大家解决问题。
Jupyter Notebook读取csv文件失败
1.IndentationError: expected an indented block
缩进错误,在报错代码块前加一个空格。

在data前加一个空格。

2.No such file or directory: ‘weatherdata.csv’
找不到文件,我的weatherdata.csv文件放在D盘文件夹里,在文件名前加上文件位置路径。

3.SyntaxError: invalid Syntax
多打了或者缺了某个符号。

多了一个冒号,删除。

Excel跨表使用注意事项(包含jupyter读取csv)
(1)问题
如何将所得数据文件上传至jupyter notebook使用csv格式 ?
思路:excel表格保存格式由xls转换为csv,并将编码格式转换为UTF-8
具体方法:
1.首先将文件打开,其次另存为,格式选择更多,找到 .csv格式,保存至目的路径
2.再将文件以记事本的方式打开,再次另存为,此时选择下方编码格式,由ANSI格式转换为UTF-8格式
3.在jupyter notebook中Upload即可打开并且使用。
(2)问题
如何只复制粘贴数据而不粘贴公式 ?
在复制粘贴表格时,难免会跨表进行交互,而公式中又难免会出现Sheet1,Sheet2的使用
这时直接的复制粘贴就会出现问题,比如出现 #N/A
具体方法:这时可以使用粘贴中的更多-->选择性粘贴
里面有只粘贴公式或者只粘贴数值。这样就可以获得想要的excel了。
(3)问题
如何跨表进行相匹配数据的列增加(数据增加)
思路:相同文件格式下,完全复制另一表格数据粘贴至统一表格中,分别为Sheet1,Sheet2。使用VLOOKUP
公式进行数据搜索、匹配以及增加。
关于“Jupyter Notebook读取csv文件出现问题如何解决”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注小编行业资讯频道,小编每天都会为大家更新不同的知识点。

Pycharm不会读取Python文件而不会出现错误
如何解决Pycharm不会读取Python文件而不会出现错误?
当我创建一个项目并运行脚本时,该脚本应该打印出一些内容,但我什么也没得到:
C:\Users\mahfo\AppData\Local\Programs\Python\python38-32\python.exe C:/Users/mahfo/PycharmProjects/pythonProject1/main.py
Process finished with exit code 0
main.py文件内容:
print(''wef'')
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f''Hi,{name}'') # Press Ctrl+F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == ''__main__'':
print_hi(''PyCharm'')
当我检查sys.prefix == sys.base_prefix时,输出为:True,
和sys.prefix输出:''C:\\Users\\mahfo\\AppData\\Local\\Programs\\Python\\python38-32''
这是我第一次在Windows上尝试。你知道为什么会这样吗?任何帮助表示赞赏。
编辑:
我尝试直接从命令提示符下运行文件,并且该文件可以使用python正确运行,但不能使用python3正确运行。因此Pycharm无法识别文件(无错误),因为该文件只能用python2读取。我不明白为什么,因为pycharm环境设置在python3上。
编辑2:
我安装了已删除的Python 2.7。 当我运行时,Pycharm仍然没有打印,但是它在调试控制台上打印。我真的不明白为什么。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
我们今天的关于当转义字符为quote和“时,Pyspark读取的csv不会读取整列的分享就到这里,谢谢您的阅读,如果想了解更多关于Java Spark读取ElasticSearch数据,并分析、java-CSV内容被Spark读取为null、Jupyter Notebook读取csv文件出现问题如何解决、Pycharm不会读取Python文件而不会出现错误的相关信息,可以在本站进行搜索。
在本文中,我们将详细介绍如何获得Kotlin Common的测试覆盖率?的各个方面,并为您提供关于kotlin test的相关解答,同时,我们也将为您带来关于Android-jacoco代码覆盖率:单元测试覆盖率+功能测试覆盖率、golang 框架的新特性如何提高测试覆盖率?、golang框架的测试覆盖率监控实践、Go的测试覆盖率的有用知识。
本文目录一览:- 如何获得Kotlin Common的测试覆盖率?(kotlin test)
- Android-jacoco代码覆盖率:单元测试覆盖率+功能测试覆盖率
- golang 框架的新特性如何提高测试覆盖率?
- golang框架的测试覆盖率监控实践
- Go的测试覆盖率
")
如何获得Kotlin Common的测试覆盖率?(kotlin test)
当前(Kotlin IDEA插件1.4.10)代码覆盖不适用于MPP(多平台)项目的通用源集。这是一个已知的限制,请投票给https://youtrack.jetbrains.com/issue/KT-31983。

Android-jacoco代码覆盖率:单元测试覆盖率+功能测试覆盖率
参考:https://docs.gradle.org/current/dsl/org.gradle.testing.jacoco.tasks.JacocoCoverageVerification.html
gradle库下载:https://maven.aliyun.com/mvn/view
案例参考来源:https://www.jianshu.com/p/1a4a81f09526
https://www.jianshu.com/p/1a4a81f09526
其他:https://testerhome.com/topics/8329
这几天折腾了很久,主要是现在的案例都是基于gradle3.1.3版本,我不想用旧版本的,查了一些资料,自己改了下代码,可以用了。
前情:
之前听说Android可以用jacoco+monkey做代码覆盖率测试,以前只做过一个spring的jacoco的单元测试覆盖率的demo,没想过Android可以将功能和jacoco联合在一起,这几天很闲就搞了一下。
准备工作:
要有Android项目源码,不用修改项目主体的核心代码,但是需要写一些jacoco的代码,主要是利用instrument在acitivity结束时记录代码覆盖率;
具体内容分两块:
一,Android项目的单元测试代码覆盖率:
利用AndroidStudio自带的task来查看当前AndroidTest文件夹下的单元测试用例覆盖率情况
编辑build.gradle
android {
...
defaultConfig {
...
testInstrumentationRunnerArguments clearPackageData: ''true''
// 执行instrumentation测试时清除缓存
}
buildTypes {
debug {
testCoverageEnabled = true
/**打开覆盖率统计开关
*/
}
}
安装debug包
执行AndroidTest的覆盖率测试并输出报告

执行日志是这样的:
这里摘取的是执行AndroidTest单元测试的片段,通过adb发送instrument命令到手机,执行测试,获取覆盖率数据,并从手机中down下来:
Executing tasks: [createDebugAndroidTestCoverageReport]
...
> Task :app:connectedDebugAndroidTest
...
05:40:39 V/ddms: execute: running am instrument -w -r -e coverageFile /data/data/com.patech.testApp/coverage.ec -e coverage true -e clearPackageData true com.patech.testApp.test/androidx.test.runner.AndroidJUnitRunner
...
05:40:41 V/InstrumentationResultParser: com.patech.testApp.EspressoTest:
...
05:40:58 V/InstrumentationResultParser: Time: 17.669
05:40:58 V/InstrumentationResultParser:
05:40:58 V/InstrumentationResultParser: OK (5 tests)
05:40:58 V/InstrumentationResultParser:
05:40:58 V/InstrumentationResultParser:
05:40:58 V/InstrumentationResultParser: Generated code coverage data to /data/data/com.patech.testApp/coverage.ec
05:40:58 V/InstrumentationResultParser: INSTRUMENTATION_CODE: -1
...
05:40:59 I/XmlResultReporter: XML test result file generated at D:\androidStudio\MyApplication\app\build\outputs\androidTest-results\connected\TEST-VOG-AL10 - 9-app-.xml. Total tests 5, passed 5,
05:40:59 V/ddms: execute ''am instrument -w -r -e coverageFile /data/data/com.patech.testApp/coverage.ec -e coverage true -e clearPackageData true com.patech.testApp.test/androidx.test.runner.AndroidJUnitRunner'' on ''APH0219430006864'' : EOF hit. Read: -1
...
05:40:59 D/com.patech.testApp.coverage.ec: Downloading com.patech.testApp.coverage.ec from device ''APH0219430006864''
...
执行完毕后查看build下的reports的详情
二.编写jacoco+instrument的代码,执行功能测试后,在本地生成ec文件,传到pc端后解析成html格式,查看功能测试操作的代码覆盖率执行情况
1.编写FinishListener接口
public interface FinishListener {
void onActivityFinished();
void dumpIntermediateCoverage(String filePath);
}
编写jacocoInstrumentation方法,实现上面这个接口,网上抄来的,实现了执行完成后生成覆盖率文件并保存到手机本地:
package com.patech.test;
import android.app.Activity;
import android.app.Instrumentation;
import android.content.Intent;
import android.os.Bundle;
import android.os.Looper;
import android.util.Log;
import com.patech.testApp.InstrumentedActivity;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.lang.reflect.InvocationTargetException;
public class JacocoInstrumentation extends Instrumentation implements FinishListener{
public static String TAG = "JacocoInstrumentation:";
private static String DEFAULT_COVERAGE_FILE_PATH = "/mnt/sdcard/coverage.ec";
private final Bundle mResults = new Bundle();
private Intent mIntent;
//LOGD 调试用布尔
private static final boolean LOGD = true;
private boolean mCoverage = true;
private String mCoverageFilePath;
public JacocoInstrumentation(){
}
@Override
public void onCreate(Bundle arguments) {
Log.d(TAG, "onCreate(" + arguments + ")");
super.onCreate(arguments);
//DEFAULT_COVERAGE_FILE_PATH = getContext().getFilesDir().getPath() + "/coverage.ec";
File file = new File(DEFAULT_COVERAGE_FILE_PATH);
if (!file.exists()) {
try {
file.createNewFile();
}catch (IOException e) {
Log.d(TAG, "异常 :" + e);
e.printStackTrace();
}
}
if (arguments != null) {
mCoverageFilePath = arguments.getString("coverageFile");
}
mIntent = new Intent(getTargetContext(), InstrumentedActivity.class);
mIntent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
start();
}
public void onStart() {
if (LOGD)
Log.d(TAG,"onStart()");
super.onStart();
Looper.prepare();
/* InstrumentedActivity activity = (InstrumentedActivity) startActivitySync(mIntent);
activity.setFinishListener(this);*/
}
private boolean getBooleanArgument(Bundle arguments, String tag) {
String tagString = arguments.getString(tag);
return tagString != null && Boolean.parseBoolean(tagString);
}
private String getCoverageFilePath() {
if (mCoverageFilePath == null) {
return DEFAULT_COVERAGE_FILE_PATH;
}else {
return mCoverageFilePath;
}
}
private void generateCoverageReport() {
Log.d(TAG, "generateCoverageReport():" + getCoverageFilePath());
OutputStream out = null;
try {
out = new FileOutputStream(getCoverageFilePath(),false);
Object agent = Class.forName("org.jacoco.agent.rt.RT")
.getMethod("getAgent")
.invoke(null);
out.write((byte[]) agent.getClass().getMethod("getExecutionData",boolean.class)
.invoke(agent,false));
} catch (FileNotFoundException e) {
Log.d(TAG, e.toString(), e);
} catch (IOException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public void UsegenerateCoverageReport() {
generateCoverageReport();
}
private boolean setCoverageFilePath(String filePath){
if (filePath != null && filePath.length() > 0) {
mCoverageFilePath = filePath;
}
return false;
}
private void reportEmmaError(Exception e) {
reportEmmaError(e);
}
private void reportEmmaError(String hint, Exception e) {
String msg = "Failed to generate emma coverage. " +hint;
Log.e(TAG, msg, e);
mResults.putString(Instrumentation.REPORT_KEY_IDENTIFIER,"\nError: " + msg);
}
@Override
public void onActivityFinished() {
if (LOGD) {
Log.d(TAG,"onActivityFinished()");
}
finish(Activity.RESULT_OK,mResults);
}
@Override
public void dumpIntermediateCoverage(String filePath) {
if (LOGD) {
Log.d(TAG,"Intermidate Dump Called with file name :" + filePath);
}
if (mCoverage){
if (!setCoverageFilePath(filePath)) {
if (LOGD) {
Log.d(TAG,"Unable to set the given file path :" +filePath + "as dump target.");
}
}
generateCoverageReport();
setCoverageFilePath(DEFAULT_COVERAGE_FILE_PATH);
}
}
}
2.修改AndroidManifest.xml文件,添加往手机读写的权限,以及instrument的设置,该标签与application标签同级:
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE" /> <!-- Jacoco权限 -->
<uses-permission android:name="android.permission.USE_CREDENTIALS" />
<uses-permission android:name="android.permission.GET_ACCOUNTS" />
<uses-permission android:name="android.permission.READ_PROFILE" />
<uses-permission android:name="android.permission.READ_CONTACTS" />
<instrumentation
android:name="com.patech.test.JacocoInstrumentation"
android:handleProfiling="true"
android:label="CoverageInstrumentation"
android:targetPackage="com.patech.testApp" />3.编写jacoco.gradle,用于解析ec,转换成html或者其他格式的报告:
apply plugin: ''jacoco''
//https://docs.gradle.org/current/userguide/jacoco_plugin.html
jacoco {
toolVersion = "0.8.4"
}
task jacocoTestReport(type: JacocoReport) {
group = "Reporting"
description = "Generate Jacoco coverage reports after running tests."
def debugTree = fileTree(dir: "${buildDir}/intermediates/javac/debug",
// includes: ["**/*Presenter.*"],
excludes: [''**/R*.class'',
''**/*$InjectAdapter.class'',
''**/*$ModuleAdapter.class'',
''**/*$ViewInjector*.class''
])//指定类文件夹、包含类的规则及排除类的规则,这里我们生成所有Presenter类的测试报告
def coverageSourceDirs = "${project.projectDir}/src/main/java" //指定源码目录
def reportDirs="$buildDir/outputs/reports/jacoco/jacocoTestReport"
reports {
xml.enabled = true
html.enabled = true
}
// destinationFile=file(reportDirs)
classDirectories = files(debugTree)
sourceDirectories = files(coverageSourceDirs)
executionData = files("$buildDir/outputs/code-coverage/connected/coverage.ec")
}4.连接手机,安装apk后执行adb语句,通过jacoco开启应用:
adb shell am instrument -w -r com.patech.testApp/com.patech.testcoverage.test.JacocoInstrumentation5.可以在手机上开始做功能测试了,测试完毕后导出ec文件:
adb pull mnt/sdcard/coverage.ec C:\Users\user\Desktop\testReport\jacoco6.将ec文件放入build/outputs/code-coverage/connected下
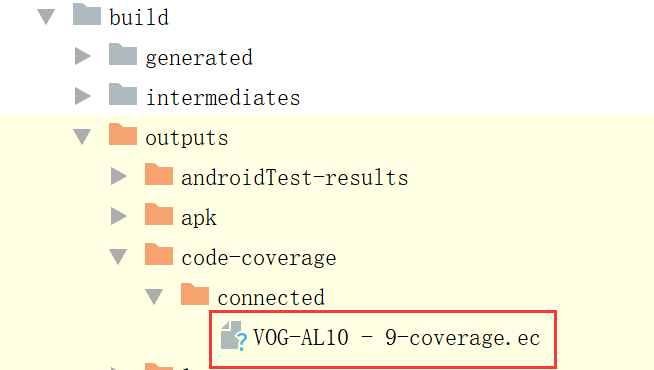
执行jacocoTestReport的task
在build/reports/jacoco/jacocoTestReport下查看解析的报告
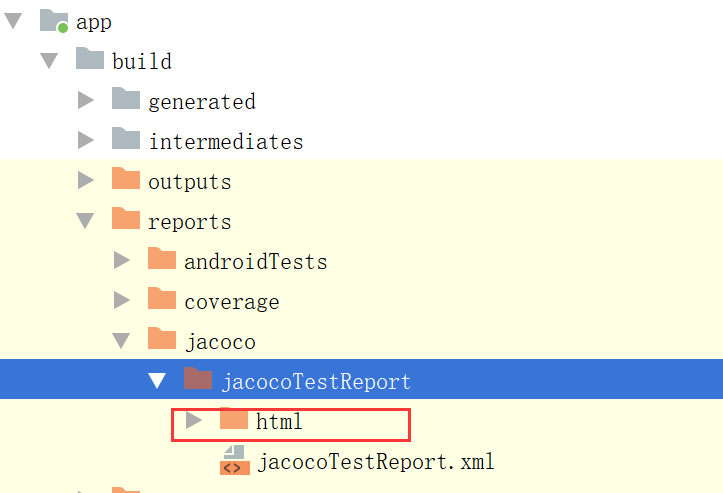
查看报告:

golang 框架的新特性如何提高测试覆盖率?
go 框架可以提升测试覆盖率:使用 testing.t 提供的方法(fail()、error()、fatalf() 等)编写全面的测试。运行 go-cover 生成报告,显示每个文件的测试覆盖率和未覆盖的代码行。

Go 框架的新特性,如何提高测试覆盖率
在 Go 语言中,测试覆盖率是一个重要的指标,它表示代码库中有多少代码被测试覆盖。测试覆盖率越高,我们就越有信心代码是准确无误的。
在 Go 中,有一些框架可以让提高测试覆盖率变得更加容易。其中一个框架是 testing.T,它提供了各种用于编写测试的方法。另一个框架是 go-cover,它可以生成一个报告,显示代码库中哪些代码被测试覆盖,哪些没有。
立即学习“go语言免费学习笔记(深入)”;
使用 testing.T 提高测试覆盖率
testing.T 提供了许多有用的方法,可以帮助提高测试覆盖率。这些方法包括:
- Fail():当测试失败时使用此方法
- Error():当测试遇到错误时使用此方法
- Fatalf():当测试遇到致命错误时使用此方法
- Skip():当测试被跳过时使用此方法
- Skipf():当测试因特定原因被跳过时使用此方法
通过使用这些方法,我们可以更轻松地编写全面的测试,并确保代码库中的所有代码都被覆盖。
使用 go-cover 提高测试覆盖率
go-cover 是一个工具,可以生成代码库的测试覆盖率报告。要使用此工具,只需在命令行中运行以下命令:
go test -coverprofile=coverage.out
这将生成一个名为 coverage.out 的文件,其中包含测试覆盖率报告。报告将显示以下信息:
- 总测试覆盖率
- 覆盖百分比的每个文件
- 未被覆盖的代码行
通过使用此报告,我们可以轻松识别并修复代码库中测试覆盖率较低的部分。
实战案例
以下是一个实战案例,演示如何使用 testing.T 和 go-cover 提高测试覆盖率:
import (
"testing"
)
func Add(a, b int) int {
return a + b
}
func TestAdd(t *testing.T) {
tests := []struct {
a, b, expected int
}{
{1, 2, 3},
{3, 4, 7},
{-1, -2, -3},
}
for _, test := range tests {
actual := Add(test.a, test.b)
if actual != test.expected {
t.Errorf("Add(%d, %d) = %d, expected %d", test.a, test.b, actual, test.expected)
}
}
}
func main() {
go test -coverprofile=coverage.out
}在上面的示例中,我们使用 testing.T 写了一个测试用例,为 Add 函数编写了三个测试。我们还使用了 go-cover 来生成一个测试覆盖率报告,该报告将显示哪些代码被测试覆盖了,哪些没有。
以上就是

golang框架的测试覆盖率监控实践
答案:通过使用 ginkgo、gomega 和 covertt 工具,我们可以监控 go 框架的测试覆盖率,以评估其有效性和全面性。详细描述:安装依赖项,包括 ginkgo、gomega 和 covertt。为框架编写 ginkgo 测试。使用 ginkgo --coverprofile=coverage.txt --covermode=count 命令运行测试并收集覆盖率数据。使用 covertt -coverprofile=coverage.txt -threshold=80 命令解析覆盖率数据并将其与覆盖率阈值进行比较。

Go 框架的测试覆盖率监控实践
前言
测试覆盖率是一个重要的指标,它可以帮助我们评估测试套件的有效性和全面性。在 Go 中,有许多工具可以帮助我们衡量测试覆盖率,并将其与既定的阈值进行比较。
在本篇文章中,我们将介绍如何使用 Ginkgo 和 Gomega 测试框架,以及 covertt 工具,来监控 Go 框架的测试覆盖率。
实战案例
准备工作
我们首先需要安装必要的依赖项:
立即学习“go语言免费学习笔记(深入)”;
go get github.com/onsi/ginkgo/v2 go get github.com/onsi/gomega go get github.com/matm/go-covertt
编写测试
接下来,我们为待测框架编写测试。以下是 Ginkgo 测试的一个示例:
package my_package
import (
"testing"
. "github.com/onsi/ginkgo/v2"
. "github.com/onsi/gomega"
)
var _ = Describe("MyFramework", func() {
It("should do something", func() {
Expect(true).To(BeTrue())
})
})运行测试并收集覆盖率数据
要运行测试并收集覆盖率数据,我们可以使用以下命令:
ginkgo --coverprofile=coverage.txt --covermode=count
这将运行测试并生成一个名为 coverage.txt 的覆盖率数据文件。
解析覆盖率数据
使用 covertt 工具,我们可以解析覆盖率数据并将其与既定的阈值进行比较。以下是 covertt 用法的示例:
covertt -coverprofile=coverage.txt -threshold=80
此命令将显示覆盖率报告,并报告是否达到 80% 的覆盖率阈值目标。
结论
通过使用 Ginkgo、Gomega 和 covertt,我们可以轻松地监控 Go 框架的测试覆盖率。这样做可以帮助我们确保测试套件的有效性和全面性。
以上就是

Go的测试覆盖率
测试覆盖率是一个术语,用于统计通过运行程序包的测试多少代码得到执行。 如果执行测试套件导致80%的语句得到了运行,则测试覆盖率为80%。
计算测试覆盖率的通常方法是埋点二进制可执行文件。 例如,GNU gcov 在二进制文件中设置执行分支断点。 当每个分支执行时,断点被清除,并且分支的目标语句被标记为“被覆盖”。
这种方法是成功和广泛使用的。 Go的早期测试覆盖工具甚至以相同的方式工作。但它有问题。 由于分析二进制文件的执行是很困难的,所以很难实现。 它还需要将执行跟踪绑定回源代码的可靠方法,这也可能是困难的。 那里的问题包括不正确的调试信息和诸如内联功能的问题, 使分析变得复杂。 最重要的是,这种方法非常不具有可移植性。 对于每个机器架构需要重新编写,在某种程度上,可能对于每个操作系统都需要重新编写,因为从系统到系统的调试支持差异很大。
Go 1.2 的发布引入了一个 test coverage 的新工具, 它采用了一种不寻常的方式来生成覆盖率统计数据,这种方法建立在Godoc的技术的基础上。
1 Go的测试覆盖率
对于Go的新测试覆盖工具,采取了一种避免动态调试的不同方法。 想法很简单:在编译之前重写包的源代码,以埋点,编译和运行修改的源,并转储统计信息。 重写很容易编排,因为 go的工具链 控制从源到测试到执行的整个流程。
示例代码如下:
func Size(a int) string {
switch {
case a < 0:
return "negative"
case a == 0:
return "zero"
case a < 10:
return "small"
case a < 100:
return "big"
case a < 1000:
return "huge"
}
return "enormous"
}测试代码如下:
type Test struct {
in int
out string
}
var tests = []Test{
{-1, "negative"},
{5, "small"},
}
func TestSize(t *testing.T) {
for i, test := range tests {
size := Size(test.in)
if size != test.out {
t.Errorf("#%d: Size(%d)=%s; want %s", i, test.in, size, test.out)
}
}
}执行代码覆盖率测试如下:
cd ../src/cover/size/
go test ./... -cover
cd -PASS
coverage: 42.9% of statements
ok _/home/parallels/program/org/github-pages/source/src/cover/size 0.001s
/home/parallels/program/org/github-pages/source/_posts启用测试覆盖后,/go test/ 运行 cover 工具,在编译之前重写源代码。 以下是重写后的 Size 函数:
func Size(a int) string {
GoCover.Count[0] = 1
switch {
case a < 0:
GoCover.Count[2] = 1
return "negative"
case a == 0:
GoCover.Count[3] = 1
return "zero"
case a < 10:
GoCover.Count[4] = 1
return "small"
case a < 100:
GoCover.Count[5] = 1
return "big"
case a < 1000:
GoCover.Count[6] = 1
return "huge"
}
GoCover.Count[1] = 1
return "enormous"
}上面示例的每个可执行部分用赋值语句进行注解,赋值语句用于在运行时做统计。 计数器与 cover 工具生成的第二个只读数据结构记录的语句的原始源位置相关联。 测试运行完成后,收集计数器,通过查看设置的数量的来计算百分比。
虽然分配注解看起来可能很昂贵,但是它被编译为单个“移动”指令。 因此,其运行时开销不大,运行典型(或更实际)测试时只增加约3%开销。 这使得把测试覆盖率作为标准开发流程的一部分是合情合理的。
2 查看结果
上面的例子的测试覆盖率很差。 为了探索具体为什么,需要 go test 写一个 coverage profile , 这是一个保存收集的统计信息的文件,以便能详细地研究覆盖的细节。 这很容易做:使用 -coverprofile 标志来指定输出的文件:
cd ../src/cover/size/
go test -coverprofile=size_coverage.out注: -coverprofile 标志自动设置 -cover 来启用覆盖率分析。
测试与以前一样运行,但结果保存在文件中。 要研究它们,需要运行 test coverage tool 。 一开始,可以要求 覆盖率 按函数分解,虽然在当前情况下没有太多意义,因为只有一个函数:
cd ../src/cover/size/
go tool cover -func=size_coverage.out查看的更有趣的方式是获取 覆盖率信息注释的源代码 的HTML展示。 该显示由 -html 标志调用:
cd ../src/cover/size/
go tool cover -html=size_coverage.out运行此命令时,浏览器将弹出窗口,已覆盖(绿色),未覆盖(红色)和 未埋点(灰色)。 下面是一个屏幕截图:
<img src="/images/go-test-cover-set.png"/>有了这个信息页,问题变得很明显:上面忽略了几个 case 的测试! 可以准确地看出具体是哪一个,这样可以轻松地提高的测试覆盖率。
3 热力图
源代码级方式来测试覆盖率的一大优点在于,可以很容易用不同的方式对代码进行埋点处理。 例如,不仅可以检测是否已执行了一个语句,而且还可以查询执行了多少次。
go test 命令接受 -covermode 标志将覆盖模式设置为三种设置之一:
- set: 每个语句是否执行?
- count: 每个语句执行了几次?
- atomic: 类似于 count, 但表示的是并行程序中的精确计数
set 是默认设置,上面示例已经看到了。 只有运行并行算法需要精确的计数时,才需要进行 atomic 设置。 它使用来自 sync/atomic 包的原子操作,这可能会相当昂贵。 然而,对于大多数情况, count 模式工作正常,并且像默认设置模式一样非常快。
下面来试试一个标准包, fmt 格式化包语句执行的计数。 进行测试并写出 coverage profile ,以便能够很好地进行信息的呈现。
go test -covermode=count -coverprofile=../src/cover/count.out fmt这比以前的例子好的测试覆盖率。 (覆盖率不受覆盖模式的影响)可以显示函数细节:
go tool cover -func=../src/cover/count.outHTML输出产生了巨大的回报:
go tool cover -html=../src/cover/count.outpad 函数如下所示:
<img src="/images/go-test-cover-count.png"/>注意绿色的强度是如何变化。 最明亮的绿色的代表较高的执行数; 较少灰暗的绿色代表较低的执行数。 甚至可以将鼠标悬停在语句上,以便在弹出的 tool tip 中提示实际计数。 test coverage 产生了关于函数执行的大量信息,在分析中很有用的信息。
4 基础块
你可能已经注意到,上一个示例中/ 有关于闭合大括号中间的行的计数/ 不是你所期望的那样。 这是因为一直以来 test coverage 都不是一个不精确的科学。
这里发生的很值得解释。 我们希望覆盖注解由程序中的分支划分,当二进制文件在传统方法中被调用时,它们是分开的。 不过,通过重写源代码很难做到这一点,因为分支没有明确展示在源代码中。
覆盖注解的作用是是埋点,通常由大括号来限定。 一般来说,使之工作正常是非常困难的。 所使用的算法的处理结果是闭合括号看起来像属于它配对的块,而开放大括号看起来像属于块之外。 一个更有趣的结果出现在如下的一个表达式中:
f() && g()没有试图单独调用对f和g的调用,无论事实如何,它们总是看起来像是运行相同的次数。
公平来说,即使gcov在这里也有麻烦。 该工具使机制正确,但呈现是基于行的,因此可能会错过一些细微差别。
5 总结
这是关于 Go 1.2 test coverage 故事。 具有有趣实现的新工具不仅可以实现测试覆盖率的统计,而且易于解释,甚至可以提取 profile 信息。
测试是软件开发和的重要组成部分,/test coverage/ 为测试策略添加一个简单的标准。 走向前, test 和 cover 。
我们今天的关于如何获得Kotlin Common的测试覆盖率?和kotlin test的分享就到这里,谢谢您的阅读,如果想了解更多关于Android-jacoco代码覆盖率:单元测试覆盖率+功能测试覆盖率、golang 框架的新特性如何提高测试覆盖率?、golang框架的测试覆盖率监控实践、Go的测试覆盖率的相关信息,可以在本站进行搜索。
本文将介绍在Pycharm中的Pandas python中上传CSV文件的详细情况,特别是关于python pandas csv文件写入的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于CSV文件在Python中的几种处理方式、PyCharm中的Python错误消息:无法附加到共享内存段、python pandas不从csv文件中读取第一列、Python Pandas处理CSV文件的常用技巧分享的知识。
本文目录一览:- 在Pycharm中的Pandas python中上传CSV文件(python pandas csv文件写入)
- CSV文件在Python中的几种处理方式
- PyCharm中的Python错误消息:无法附加到共享内存段
- python pandas不从csv文件中读取第一列
- Python Pandas处理CSV文件的常用技巧分享
")
在Pycharm中的Pandas python中上传CSV文件(python pandas csv文件写入)
在您的错误中,它表明该错误来自循环导入。使用pip uninstall pandas卸载熊猫,然后使用pip install pandas进行安装。此外,请阅读this article on circular imports以及如何处理它们。

CSV文件在Python中的几种处理方式
Comma Separated Values,简称CSV,它是一种以逗号分隔数值的文件类型。在数据库或电子表格中,它是最常见的导入导出格式,它以一种简单而明了的方式存储和共享数据,CSV文件通常以纯文本的方式存储数据表。今天,我将给大家分享在Python中如何操作CSV文件。
一、数据源
首先,我们来看看本次操作的数据源,图1 CSV文件是在Excel中打开的,图2 CSV文件是在Notepad++中打开的,我们在图2中可以看到数值之间是以逗号分隔开的,每行末尾是CR回车符和LF换行符(请注意,Linux系统以LF结尾,MacOS系统以CR结尾)。


二、使用Python基本语法读写CSV文件
使用基本语法读取CSV文件中的数据大概思路是:获取文件对象,读取表头,按逗号分隔符拆分表头字段,使用for循环语句获取表体记录数据,拆分后再次写入另一张CSV文件中(如果要将数据写入xls*格式的文件中,请参考前期公众号文章),步骤如下:
Step 1:导入必要模块,获取输入输出文件路径。
import sys
infile = sys.argv[1]
outfile = sys.argv[2]
Step 2:使用open内置函数获取文件对象。
with open(infile, "r", newline='''') as fr, open(outfile, "w", newline='''') as fw:
Step 3:使用文件对象的readline方法或者迭代器的next方法读取表头(文件对象是一个迭代器对象,支持迭代协议),使用str.split方法对表头进行拆分(注意,要使用strip函数去掉尾部换行符)。
header = next(fr)
header = header.strip()
header_list = header.split(",")
Step 4:既然表头已经查分好了,我们需要将表头写入文件对象中(注意尾部需要添加一个换行符哦)。
fw.write(",".join(map(str, header_list)) + "\n")
当然,上面的代码也可以这么写:
print(*header_list, sep=",", file=fw)
Step 5:使用for循环读取表体数据,并将其拆分成列表写入到文件中。
for row in fr:
row = row.strip()
row_list = row.split(",")
fw.write(",".join(map(str, header_list)) + "\n")
以上步骤完成后,在命令提示符中输入:
python csvrw.py inputfile.csv outputfile.csv
输入输出csv文件名称以及脚本名称请自定义,以上只是举例说明。
以上代码如下:

三、使用csv模块读写CSV文件
csv模块是Python内置的一个模块,它考虑了csv文件中的各种复杂情况,平时处理文件基本上使用此模块,下面来看看csv模块处理csv文件的方式,其步骤如下:
Step 1:首先,导入必要模块,获取输入输出文件路径。
import sys
import csv
infile = sys.argv[1]
outfile = sys.argv[2]
Step 2:使用open内置函数获取文件对象。
with open(infile, "r", newline='''') as incsv, open(outfile, "w", newline='''') as outcsv:
Step 3:使用csv模块中的reader和writer函数分别获取reader和writer对象。
freader = csv.reader(incsv, delimiter=",")
fwriter = csv.writer(outcsv, delimiter=",")
Step 4:使用for循环语句读取和写入数据。
for rowlist in freader:
fwriter.writerow(rowlist)
以上步骤完成后,在命令提示符中输入相应命令即可(请参照)
代码如下:

四、使用pandas读写CSV文件
pandas库是一个强大的数据处理和数据分析库,使用pandas处理csv文件更简单,其步骤如下:
Step 1:首先,导入必要模块,获取输入输出文件路径。
import sys
import pandas as pd
infile = sys.argv[1]
outfile = sys.argv[2]
Step 2:使用pandas的read_csv方法将数据存储到一个DataFrame对象中。
dataframe = pd.read_csv(infile)
Step 3:然后使用DataFrame的to_csv方法将其输出到另一张csv表中。
dataframe.to_csv(outfile, index=False)
以上步骤完成后,在命令提示符中输入相应命令即可(请参照)
代码如下:


PyCharm中的Python错误消息:无法附加到共享内存段
我开始在Ubuntu 15.04中使用PyCharm和Python 2.7编写代码.同时,我已经安装了Ubuntu 15.10和PyCharm 4.5.4 CE.现在,当我运行代码时,出现以下错误:
QNativeImage: Unable to attach to shared memory segment.
(python2.7:8078): Gdk-WARNING **: shmget Failed: error 28 (No space left on device)
X Error: BadDrawable (invalid pixmap or Window parameter) 9
Major opcode: 62 (X_copyArea)
Resource id: 0x0
尽管并不是每次我运行代码时都会发生这种情况.会是什么呢?
解决方法:
我使用旧的Openjdk软件包遇到此错误.在sudo apt-get更新和升级后,此错误消失了.

python pandas不从csv文件中读取第一列
我有一个简单的2列csv文件,名为st1.csv:
GRID St1 1457 614 1458 657 1459 679 1460 732 1461 754 1462 811 1463 748但是,当我尝试读取csv文件时,未加载第一列:
a = pandas.DataFrame.from_csv(''st1.csv'') a.columns输出:
Index([u''ST1''], dtype=object)为什么不读取第一列?
答案1
小编典典根据您的数据判断,看起来您正在使用的分隔符是``。
请尝试以下操作:
a = pandas.DataFrame.from_csv(''st1.csv'', sep='' '')另一个问题是,假设您的第一列是索引,我们也可以禁用它:
a = pandas.DataFrame.from_csv(''st1.csv'', index_col=None)
Python Pandas处理CSV文件的常用技巧分享
Pandas处理CSV文件,分为以下几步:
- 读取Pandas文件
- 统计列值出现的次数
- 筛选特定列值
- 遍历数据行
- 绘制直方图(柱状图)
读取Pandas文件
df = pd.read_csv(file_path, encoding=''GB2312'') print(df.info())
注意:Pandas的读取格式默认是UTF-8,在中文CSV中会报错:
UnicodeDecodeError: ''utf-8'' codec can''t decode byte 0xd1 in position 2: invalid continuation byte
修改编码为 GB2312 ,即可,或者忽略encode转义错误,如下:
df = pd.read_csv(file_path, encoding=''GB2312'') df = pd.read_csv(file_path, encoding=''unicode_escape'')
df.info()显示df的基本信息,例如:
<class ''pandas.core.frame.DataFrame''>
RangeIndex: 3840 entries, 0 to 3839
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 实验时间批次 3840 non-null object
1 物镜倍数 3840 non-null object
2 板子编号 3840 non-null object
3 板子编号及物镜倍数 3840 non-null object
4 图名称 3840 non-null object
5 细胞类型 3840 non-null object
6 板子孔位置 3840 non-null object
7 孔拍摄位置 3840 non-null int64
8 细胞培养基 3840 non-null object
9 细胞培养时间(小时) 3840 non-null int64
10 扰动类别 3840 non-null object
11 扰动处理时间(小时) 3840 non-null int64
12 扰动处理浓度(ug/ml) 3840 non-null float64
13 标注激活(1/0) 3840 non-null int64
14 unique 3840 non-null object
15 tvt 3840 non-null int64
dtypes: float64(1), int64(5), object(10)
memory usage: 480.1+ KB
统计列值出现的次数
df[列名].value_counts(),如df["扰动类别"].value_counts():
df["扰动类别"].value_counts()
输出:
coated OKT3 720
OKT3 720
coated OKT3+anti-CD28 576
DMSO 336
anti-CD28 288
PBS 288
Nivo 288
Pemb 288
empty 192
coated OKT3 + anti-CD28 144
Name: 扰动类别, dtype: int64
直接绘制value_counts()的柱形图,参考Pandas - Chart Visualization:
import matplotlib.pyplot as plt
%matplotlib inline
plt.close("all")
plt.figure(figsize=(20, 8))
df["扰动类别"].value_counts().plot(kind="bar")
# plt.xticks(rotation=''vertical'', fontsize=10)
plt.show()
柱形图:

筛选特定列值
df.loc[筛选条件],筛选特定列值之后,重新赋值,只处理筛选值,也可以写入csv文件。
df_plate1 = df.loc[df["板子编号"] == "plate1"]
df_plate1.info()
# df.loc[df["板子编号"] == "plate1"].to_csv("batch3_IOStrain_klasses_utf8_plate1.csv") # 存储CSV文件
注意:筛选的内外两个df需要相同,否则报错
pandas loc IndexingError: Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match).
输出,数据量由3840下降为1280。
<class ''pandas.core.frame.DataFrame''>
Int64Index: 1280 entries, 0 to 1279
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 实验时间批次 1280 non-null object
1 物镜倍数 1280 non-null object
2 板子编号 1280 non-null object
3 板子编号及物镜倍数 1280 non-null object
4 图名称 1280 non-null object
5 细胞类型 1280 non-null object
6 板子孔位置 1280 non-null object
7 孔拍摄位置 1280 non-null int64
8 细胞培养基 1280 non-null object
9 细胞培养时间(小时) 1280 non-null int64
10 扰动类别 1280 non-null object
11 扰动处理时间(小时) 1280 non-null int64
12 扰动处理浓度(ug/ml) 1280 non-null float64
13 标注激活(1/0) 1280 non-null int64
14 unique 1280 non-null object
15 tvt 1280 non-null int64
dtypes: float64(1), int64(5), object(10)
memory usage: 170.0+ KB
遍历数据行
for idx, row in df_plate1_lb0.iterrows():,通过row[“列名”],输出具体的值,如下:
for idx, row in df_plate1_lb0.iterrows():
img_name = row["图名称"]
img_ch_format = img_format.format(img_name, "{}")
for i in range(1, 7):
img_path = os.path.join(plate1_img_folder, img_ch_format.format(i))
img = cv2.imread(img_path)
print(''[Info] img shape: {}''.format(img.shape))
break
输出:
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
绘制直方图(柱状图)
统计去除背景颜色的灰度图字典
# 去除背景颜色
pix_bkg = np.argmax(np.bincount(img_gray.ravel()))
img_gray = np.where(img_gray <= pix_bkg + 2, 0, img_gray)
img_gray = img_gray.astype(np.uint8)
# 生成数值数组
hist = cv2.calcHist([img_gray], [0], None, [256], [0, 256])
hist = hist.ravel()
# 数值字典
hist_dict = collections.defaultdict(int)
for i, v in enumerate(hist):
hist_dict[i] += int(v)
# 去除背景颜色,已经都统计到0,所以0值非常大,删除0值,观察分布
hist_dict[0] = 0
绘制柱状图:
- plt.subplots:设置多个子图,figsize背景尺寸,facecolor背景颜色
- ax.set_title:设置标题
- ax.bar:x轴的值,y轴的值
- ax.set_xticks:x轴的显示间隔
- plt.savefig:存储图像
- plt.show:展示
fig, ax = plt.subplots(1, 1, figsize=(10, 8), facecolor=''white'')
ax.set_title(''channel {}''.format(ci))
n_bins = 100
ax.bar(range(n_bins+1), [hist_dict.get(xtick, 0) for xtick in range(n_bins+1)])
ax.set_xticks(range(0, n_bins, 5))
plt.savefig(res_path)
plt.show()
效果:

到此这篇关于Python Pandas处理CSV文件的常用技巧分享的文章就介绍到这了,更多相关Pandas处理CSV文件内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- 了解不常见但是实用的Python技巧
- Python小技巧练习分享
- python绘制子图技巧之plt.subplot、plt.subplots及坐标轴修改
- Python中的字典合并与列表合并技巧
- 卡尔曼滤波数据处理技巧通俗理解及python实现
- Python同步方法变为异步方法的小技巧分享
- 分享Python中四个不常见的小技巧
关于在Pycharm中的Pandas python中上传CSV文件和python pandas csv文件写入的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于CSV文件在Python中的几种处理方式、PyCharm中的Python错误消息:无法附加到共享内存段、python pandas不从csv文件中读取第一列、Python Pandas处理CSV文件的常用技巧分享等相关知识的信息别忘了在本站进行查找喔。
在本文中,您将会了解到关于GitVersion在TeamCity构建中引发身份验证错误的新资讯,同时我们还将为您解释teamcity git的相关在本文中,我们将带你探索GitVersion在TeamCity构建中引发身份验证错误的奥秘,分析teamcity git的特点,并给出一些关于api – 如何在TeamCity中的特定构建中添加Web钩子、asp.net-mvc – 尝试使用TeamCity构建asp.net mvc Web应用程序时出错、aws elastcisearch 身份验证错误并显示 403、c# – Nuget包的teamcity构建失败的实用技巧。
本文目录一览:- GitVersion在TeamCity构建中引发身份验证错误(teamcity git)
- api – 如何在TeamCity中的特定构建中添加Web钩子
- asp.net-mvc – 尝试使用TeamCity构建asp.net mvc Web应用程序时出错
- aws elastcisearch 身份验证错误并显示 403
- c# – Nuget包的teamcity构建失败
")
GitVersion在TeamCity构建中引发身份验证错误(teamcity git)
设置构建的工件以捕获GitVersion生成的日志输出后,发现以下消息:
TeamCity doesn't make the current branch available through environmental variables.
Depending on your authentication and transport setup of your git VCS root things
may work. In that case,ignore this warning.
In your TeamCity build configuration,add a parameter called `env.Git_Branch` with
value %teamcity.build.vcs.branch.<vcsid>%
See http://gitversion.readthedocs.org/en/latest/build-server-support/build-server/teamcity
for more info
通过将env.Git_Branch参数设置为%teamcity.build.vcs.branch。%值,GitVersion开始工作。这本来应该是一个简单的解决方案,但是由于未捕获日志并且错误消息的搜索结果不成功,因此我决定发布此答案以帮助可能遇到此问题的其他人。

api – 如何在TeamCity中的特定构建中添加Web钩子
我查看了所有TC REST文档,但没有找到答案.
谢谢.
解决方法
我没有使用它,但是有一个插件,tcWebHooks,它允许管理员为TeamCity项目here配置webhooks,它有一些应该能够帮助你入门的文档.

asp.net-mvc – 尝试使用TeamCity构建asp.net mvc Web应用程序时出错
E:\TeamCity\buildAgent\work\48e528785fe346fa\src\Web\Web.csproj(489,
11): error MSB4019: The imported
project “C:\Program
Files\MSBuild\Microsoft\VisualStudio\v9.0\WebApplications\Microsoft.WebApplication.targets”
was not found. Confirm that the path
in the declaration is
correct,and that the file exists on
disk.
我在google上找到了几个点击,但没有任何接受。建议安装Visual Studio或将某些目录从Visual Studio复制到服务器等。
我可以如何使TeamCity在dev / build服务器上构建我的项目。
解决方法

aws elastcisearch 身份验证错误并显示 403
如何解决aws elastcisearch 身份验证错误并显示 403?
/_cluster/health: {"error":{"root_cause":[{"type":"security_exception","reason":"no permissions for
[cluster:monitor/health] and User [name=arn:aws:iam::271481610659:user/developer_2,backend_roles=[],requestedTenant=null]"}],"type":"security_exception","reason":"no permissions for [cluster:monitor/health] and User [name=arn:aws:iam::271481610659:user/developer_2,requestedTenant=null]"},"status":403}
嗨,
我的 aws elasticsearch 工作正常,但突然出现此错误。这里有什么问题。 由于我无法理解这些新事物,它所说的凭据是错误的
解决方法
错误表明用户“developer_2”“没有权限”。 从同一消息中,我们可以看到该用户的后端角色为空 - backend_roles=[]。
要解决此问题,请使用管理员身份登录并使用 Fine-grained access control settings 为用户“developer_2”分配后端角色。

c# – Nuget包的teamcity构建失败
他们工作得很好,项目在我的电脑中编译.
当我声明构建服务器构建此解决方案时,我得到了以下消息:
[MSBuild] AutoMapper\AutoMapperSpike.csproj: Build default targets (1s)
[10:35:50][AutoMapper\AutoMapperSpike.csproj] ResolveAssemblyReferences
[10:35:50][ResolveAssemblyReferences] ResolveAssemblyReference
[10:35:50][ResolveAssemblyReference] Primary reference "AutoMapper".
[10:35:50][ResolveAssemblyReference] C:\Windows\Microsoft.NET\Framework\v4.0.30319\Microsoft.Common.targets(1360,9): warning MSB3245: Could not resolve this reference. Could not locate the assembly "AutoMapper". Check to make sure the assembly exists on disk. If this reference is required by your code,you may get compilation errors.
[10:35:50][ResolveAssemblyReference] For SearchPath "{HintPathFromItem}".
[10:35:50][ResolveAssemblyReference] Considered "..\packages\AutoMapper.2.2.1\lib\net40\AutoMapper.dll",but it didn't exist.
有谁知道如何解决这个问题?
我注意到的另一件事是它使用packages文件夹在构建服务器中创建了artificts.
它唯一能做的就是在构建服务器中构建项目.
解决方法
我建议不要尝试在构建脚本或.csproj文件中设置环境变量. Here’s the blog article all about why it happened and what to set on your dev machine/build server.
关于GitVersion在TeamCity构建中引发身份验证错误和teamcity git的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于api – 如何在TeamCity中的特定构建中添加Web钩子、asp.net-mvc – 尝试使用TeamCity构建asp.net mvc Web应用程序时出错、aws elastcisearch 身份验证错误并显示 403、c# – Nuget包的teamcity构建失败的相关信息,请在本站寻找。
如果您想了解如何记录动态变化的情节python的相关知识,那么本文是一篇不可错过的文章,我们将对动态记录法进行全面详尽的解释,并且为您提供关于IPython:如何在不同的单元格中显示相同的情节?、Nature | 新技术 scSLAM-seq 可在单细胞水平揭示转录动态变化的核心特征、python – 如何计算熊猫状态变化的数量?、Python 动态变量名定义与调用方法的有价值的信息。
本文目录一览:- 如何记录动态变化的情节python(动态记录法)
- IPython:如何在不同的单元格中显示相同的情节?
- Nature | 新技术 scSLAM-seq 可在单细胞水平揭示转录动态变化的核心特征
- python – 如何计算熊猫状态变化的数量?
- Python 动态变量名定义与调用方法
")
如何记录动态变化的情节python(动态记录法)
如何解决如何记录动态变化的情节python?
import numpy as np
import cv2
import matplotlib.pyplot as plt
# image = cv2.imread(''img.jpg'',0)
# rows,cols = image.shape
image = cv2.imread(''img.jpg'') # read image
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
normalizedImg = cv2.normalize(gray,None,255,cv2.norM_MINMAX)
gray_invert = cv2.bitwise_not(normalizedImg)
r,c = gray_invert.shape
print(r,c)
# r = 2
image_array= np.array(gray_invert)
for rows in range(r):
plt.clf()
row = gray_invert[rows,:]/255
print(row)
plt.plot(row)
print(rows,"th")
plt.pause(0.05)
plt.show()
cv2.imshow(''Gray image'',gray)
cv2.waitKey(0)
cv2.destroyAllWindows()
我目前正在通过循环每行numpy数组来动态绘制图像的每一行。 有什么方法可以记录此情节并将其另存为gif或mp4?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

IPython:如何在不同的单元格中显示相同的情节?
我正在使用以下代码在Jupyter笔记本中创建散点图:
import numpy as np import matplotlib.pyplot as plt n = 1024 X = np.random.normal(0,1,n) Y = np.random.normal(0,n) plt.axes([0.025,0.025,0.95,0.95]) plt.scatter(X,Y,s=50) plt.show()
我的问题是,我怎样才能获得对绘图对象的引用,以便以后可以在笔记本中的不同单元格中使用它?此外,我可能需要在再次显示之前修改绘图.
另外,我的笔记本顶部有%matplotlib内联.
以下是有关我的环境的一些信息:
> Python:3.5.2 64位[MSC v.1900 64位(AMD64)]
> IPython:4.2.0
> numpy:1.11.1
> scipy:0.17.1
> matplotlib:1.5.1
>同情:1.0
>操作系统:Windows 7 6.1.7601 SP1
解决方法
>创建一个图形对象 – fig = plt.figure()>向其添加轴 – ax = fig.add_axes([0.025,0.95])>在创建的轴上绘图 – ax.plot(X,Y)

Nature | 新技术 scSLAM-seq 可在单细胞水平揭示转录动态变化的核心特征

scSLAM-seq reveals core features of transcription dynamics in single cells
摘要
单细胞转录组测序(single-cell RNA-seq, scRNA-seq)强调了细胞间表达异质性在健康和疾病表型变异中的重要作用。然而,目前的 scRNA-seq 方法仅仅提供了基因表达的一个快照,很少传达关于转录的真实时间动态和随机特性的信息。scRNA-seq 分析的另一个关键限制是每个细胞的 RNA 图谱只能分析一次。原文作者开发了单细胞巯基连接的 RNA 烷基化代谢标记测序技术 scSLAM-seq,它整合了代谢 RNA 标记、生化核苷转化和 scRNA-seq,通过区分每个单细胞数千个基因的新老 RNA 来直接记录转录活性。通过使用 scSLAM-seq 来研究裂解性巨细胞病毒在单个小鼠成纤维细胞中的感染情况。从旧 RNA 推断出的细胞周期状态和感染剂量使得能够基于新 RNA 进行剂量反应分析。因此,scSLAM-seq 既可视化又解释了单细胞水平转录活性的差异。此外,scSLAM-seq 描述了宿主基因表达中的 “开 - 关” 控制和转录动力学,以及与启动子内在特征 (BP–TATA-box 相互作用和 DNA 甲基化) 相关的广泛基因特异性差异。因此,基因特异性而非细胞特异性的特征解释了单个细胞之间的转录组异质性和转录对扰动的反应。
<更多精彩,可关注微信公众号:AIPuFuBio,和大型免费综合生物信息学资源和工具平台 AIPuFu:www.aipufu.com>
前言
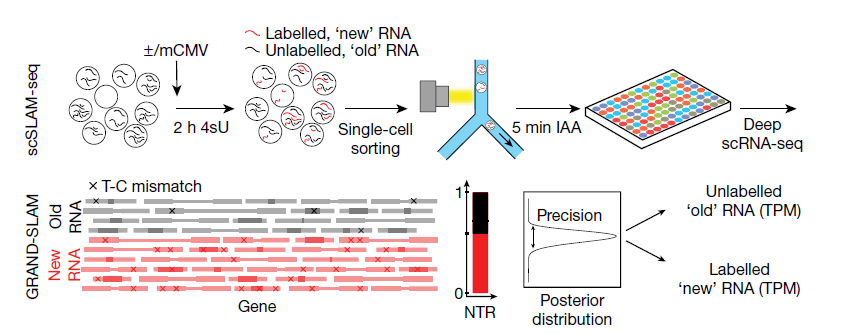
SLAM-seq 技术可将细胞短暂暴露于核苷类似物 4 - 硫尿苷 (4sU)。4sU 在转录过程中被整合到新的 RNA 中,并在 RNA 测序前用碘乙酰胺转化为胞嘧啶类似物。源自新 RNA 的测序读段(reads)可以在总 RNA 读段库中根据特征性的铀转化为碳的转化进行鉴定。通过应用 SLAM-seq 技术在单细胞水平上解决裂解性小鼠巨细胞病毒 (CMV) 感染的发作。在优化单细胞测序 (scSLAM-seq)(图 1) 后,原文作者在 107 个小鼠成纤维细胞上构建 scSLAM-seq,并使用 (大量) SLAM-seq 并行分析匹配较大 (1
× 10) 细胞群体 (n = 2) 的全局转录变化。在对具有超过 2,500 个可检测基因的细胞进行质量过滤后,剩余样品 (49 个巨细胞病毒感染的,45 个未感染的细胞) 显示了高质量 scSLAM-seq 文库的所有特征,包括 4% 至 6% 之间的 U-C 转化率。因此,在单细胞水平上,4sU 的结合既有效又均匀。
结果和讨论
由于 4sU 掺入率约为在 50-200 个核苷酸中有 1 个,因此所有来源于新 RNA 的 SLAM 序列读段中,有高达 50% 可能不含铀转化成碳。为了克服这个问题,原文作者开发了 “使用 SLAM-seq 技术对新转录的 RNA 和衰变率进行全局精确分析的方法(GRAND-SLAM)”,其为一种贝叶斯方法,以包括可信区间在内的完全量化的方式计算新 RNA 与总 RNA 的比率(new to total RNA,NTR)(图 1)。原文作者还开发了 GRAND-SLAM 2.0 用于并行分析数百个来源于单个细胞的 SLAM-seq 文库。通过在成对端模式下分析长读段 (150 个核苷酸),进一步提高了定量的准确性,这使得 4sU 转化能够有效地与重叠序列中的测序误差区分开。从而获得了每个细胞数千个基因的精确测量值 (90% 可信区间 < 0.2),从而接单细胞转录组测序 scRNA-seq 的总灵敏度,并与多细胞 SLAM-seq 的数据高相关 (相关系数 R > 0.73)。
高度可变细胞基因的无偏主成分分析(PCA)结果显示,不能区分感染巨细胞病毒的细胞和未感染的细胞,无论是总 RNA 还是旧 RNA,对新 RNA 只能有轻微的区分 (图 2a)。因此,细胞间异质性超过了病毒诱导的变化,这种变化在感染后两小时内很难在总 RNA 中检测到,这是因为哺乳动物 RNA 的周转缓慢。相比之下,NTR 上的主成分分析可高精度从感染细胞中分离出未感染的细胞 (图 2a),并显示出与病毒基因表达程度的明显正相关 (皮尔逊相关系数 R = 0.59,P-value= 7.3 × 10)。
最近的研究表明,从单细胞转录组测序 scRNA-seq 数据中获得的内含子读段可以用来估计个体细胞中基因表达的时间导数,称为 “RNA 速度”。这些表明了单个细胞的未来轨迹可投射到基因表达的低维空间中。然而,受感染的细胞不能通过无偏主成分分析从未受感染的细胞中分离出来,该主成分分析是根据相应的 RNA 速度计算的,或根据使用速度预测未来的表达谱计算的,或直接根据内含子 / 外显子比率计算的。为了直接将 scSLAM-seq 与针对更大细胞群计算的 RNA 速度进行比较,原文作者在数百个未感染 (n = 793) 和巨细胞病毒感染 (n = 353) 的细胞上使用相同的实验条件进行了 10x Genomics Chromium droplet-based 的单细胞转录组测序。尽管成熟转录物 (仅外显子读取) 上的主成分分析不能分离未感染和感染的细胞,但使用内含子 / 外显子比率可以进行区分。然而,在 scSLAM-seq 和 10x 数据中没有观察到有意义的 RNA 速率 (图 2b)。原文作者使用 scSLAM-seq 获得的新的和总的 RNA 水平来代替内含子和外显子的 read 水平,并确定 “NTR 速度”。值得注意的是,这些进一步区分了感染细胞和未感染细胞 (图 2c)。
为了直接比较 NTRs 和 RNA 的速度,原文作者问进一步分析了哪一个能最好地预测一个基因在大细胞群中是上调还是下调。虽然这在某种程度上是可能的,分别使用从 scSLAM-seq 或 10x 数据中的数十或数百个细胞计算的 RNA 速度 (AUC 值分别为 0.68 和 0.74),但是通过使用 NTRs (AUC > 0.94) 可获得更好的结果 (图 2d)。此外,NTRs 相对于 velocities (分别来自 scSLAM-seq 和 10x 数据,n =131 和 n = 295),可以确定更多受调控的基因 (n =583)。因此,NTR 和 RNA 速率传递了不同但互补的信息,并可以合并到 NTR 速度中,以更可靠地预测细胞的未来状态。
病毒学中的一个基本问题是为什么一个细胞的感染会导致广泛的裂解性病毒复制而感染的第二个细胞没有。在感染 2 小时后,大多数细胞的巨细胞病毒感染已经从 “立即早期”(仅限于少数基因) 发展到 “早期” 感染阶段,其中大多数病毒基因已经转录。尽管所有细胞中的大多数病毒转录物都是新的,但原文作者也观察到一些病毒基因的大量旧 RNA。这代表病毒粒子相关的 RNA,由传入的病毒粒子传递到受感染的细胞。它与从病毒源中分离的病毒颗粒相关 RNA 有很好的相关性 (相关系数 R =0.48),因此,提供了每个细胞接受的感染剂量的替代标记。相比之下,新的病毒 RNA 反映了感染的效率。感染剂量解释了 52% 的感染效果差异。所以,几乎不表达任何新病毒 RNA 的细胞中的旧病毒 RNA 的量比其它细胞中的低得多,这表明这些细胞对巨细胞病毒感染的许可性并没有降低,而是接受了低得多的病毒剂量。基于细胞周期特征基因,可以分别从旧的和总的 RNA 推断 4sU 代谢标记开始和结束时的细胞周期状态,从而提供细胞周期轨迹 (图 2e)。虽然裂解性感染始于所有细胞周期阶段,但在 G1 期感染的细胞导致明显更强的病毒基因表达和细胞周期破坏 (P-value <0.05)。这使得新病毒基因表达的解释差异增加到 59%(图 2f)。因此,在成纤维细胞中单个细胞水平启动裂解性病毒基因表达的效率可以通过感染剂量和细胞周期的相互作用得到很好的解释。
为了评估巨细胞病毒感染对细胞基因表达的影响,原文作者使用单细胞两相检测程序 (SC2P) 从总的、新的和旧的 RNA 中鉴定了巨细胞病毒感染和未感染的单细胞之间差异表达的基因。大多数下调 (87 个基因中的 61 个) 和上调 (309 个基因中的 188 个) 基因 (超过 60%) 只有通过专门考虑新的 RNA 才能被发现 (图 3a)。基因表达的双峰性是单细胞中一个很好描述的特征。双峰性表达的基因在一个细胞亚群中检测不到表达,但可在其他细胞群中检测到表达。scSLAM-seq 直接观察细胞中给定基因的启动子在研究的时间范围内是否 “开启”。值得注意的是,原文作者发现大多数巨细胞病毒诱导的新 RNA 的变化更多地与开关动力学相一致,而不是与上调或下调相一致 (图 3b,c)。
巨细胞病毒感染在感染的前两个小时诱导强烈的 I 型干扰素和 NF-κB 反应。根据预测的转录因子靶标和基因本体条目(Gene Ontology terms)进行的基因富集分析表明,干扰素和 NF-κB 的激活高度依赖于病毒剂量。然而,虽然干扰素的激活只限于大约一半的感染细胞,但在巨细胞病毒感染的大多数细胞都发生了 NF-κB 激活 (图 3d)。病毒剂量依赖性激活所有细胞中的 NF-κB 与 M45 被膜蛋白介导的 IKK 激酶复合体处或上游的 NF-κB 激活一致。相比之下,干扰素反应需要检测病原体相关的分子模式,受自分泌和旁分泌信号的影响,因此可能在单个细胞之间表现出更大的可变性。为了进行更集中的分析,原文作者根据以前发表的关于 NF-κB 诱导的数据和干扰素治疗的 bulk SLAM-seq 数据,定义了巨细胞病毒感染特异的 NF-κB 和干扰素应答基因组。干扰素 (图 3e) 和 NF-κB (图 3f) 反应的大小在单个细胞之间明显不同,但两者都与病毒基因表达高度相关 (斯皮尔曼相关系数 ρ > 0.52,P-value < 3 × 10)。因此,大多数 NF-κB - 和干扰素诱导型基因表达出现在最强感染的细胞中,在 S 期感染的细胞中诱导最弱的反应。
单细胞水平上的转录活性不是一个连续的过程,而是由间歇的转录爆发组成,中间相隔几分钟到几小时的转录不活跃,表明启动子暂时不允许。原文作者推断,scSLAM-seq 应该可以检测到基因的这种爆发因子。为了全面评估转录爆发动力学,原文作者将基因爆发评分 (B - 评分) 定义为所有未感染细胞的正常参考时间分布的标准偏差,其中相应基因的 RNA 可以可靠地量化 (正常参考时间的 90% 可信区间 < 0.2;n = 5540)。从两个独立的生物重复中获得的 B - 分数高度相关 (相关系数 R =0.74)。在某些情况下,接近 0.5 的极端 B - 分数对应于在每个细胞中仅检测到单个或非常少的 mRNA 分子 (新的或旧的) 的基因。
当前的单细胞转录组测序(scRNA-seq)技术要么提供了独特分子的识别标签 (UMIs) 来估计捕获的 mRNA 分子的数量,并且是链特异性的,但是仅克隆转录了末端 (例如,10x Genomics Chromium 单细胞转录组测序),或者可测全长的 mRNAs,但是没有 UMIs 并且失去链特异性 (例如,Smart-seq2)。原文作者基于 Smart-seq 技术开发的 scSLAM-seq 方法至少部分包含了所有三个特性。4sU 的随机合并转化为 mRNA 分子提供了基于核苷酸转化的独特分子标识 (nUMIs),这使得能够估计每个细胞和基因取样的新的 mRNA 分子数量的下限,并且 —— 通过外推 (EnUMIS)—— 也是旧的 mRNA 的下限。基于这些对样本多克隆抗体数量的保守估计,发现所有可检测基因中超过 30%(5540 个中的 1718 个;矫正后 P-value< 0.01,χ 检验) 的方差 (B - 得分) 大于采样时的预期 (图 4a)。B 分数与表达水平的相关性可以忽略不计。此外,NTR 中观察到的异质性不是由细胞周期依赖性差异引起的,而是与 mRNA 半衰期相关的。
无偏基因本体(Gene Ontoloy)富集分析显示,高 B 分数的基因与蛋白质磷酸化和泛素化等功能类别相关。启动子分析确定了六个显著富集的低 (TATA box motif) 或高 (富含 CG 和嘌呤 motif) B - 分数。Correctly placed TATA boxes 富集的最明显 (P-value< 10-8), 与 TATA box 的启动子一致,在几分钟的时间尺度上频繁的转录爆发。没有观察到与其他核心启动子 motif 的关联 (图 4b)。富含 CG 的 motif 可以对应于显示振荡激活模式的特定转录因子的结合位点,或者反映相应启动子内富含 CpG 的区域。超过 50% 的哺乳动物转录起始于靠近 CpG 岛的启动子 (CGI 启动子),这些启动子代表几十到几百个核苷酸的富含 CpG 的区域。CpG 岛的高甲基化是基因沉默的表观遗传控制机制。来自小鼠成纤维细胞的亚硫酸氢盐测序数据揭示了甲基化的降钙素基因相关肽启动子与低 B - 评分的显著相关性,而甲基化的非降钙素基因相关肽启动子倾向于显示高 B - 评分 (图 4c)。对于含有 TATA box 的启动子也观察到同样的情况 (图 4d)。通过重复对 1718 个具有显著 B 值的基因和前 50% 最强表达基因的分析,证实了这些结果。虽然不能完全排除这里所用细胞系的转录活性和核型复杂性的等位基因差异导致了一些观察到的效应,但这并不能解释 B - 评分与启动子内在特征的强烈相关性。原文作者提出了一个模型,其中基因启动子中的 DNA 甲基化通过在数小时内的时间尺度上暂时抑制基因的启动子而参与短暂的启动子活性调控。最后,B 分数与观察到的单个细胞转录组的异质性高度相关 (图 4e)。因此,基因启动子特异性特征是细胞间异质性的主要原因。
使用 4sU 的代谢标记适用于所有主要模式生物,包括脊椎动物、昆虫、植物和酵母。嘌呤类似物 6 - 硫代鸟嘌呤 (6sG) 现在也能通过氧化 - 亲核 - 芳香取代 (TimeLapse-seq chemistry) 实现从 G 到 A 的转换。短而连续的 4sU 和 6sG 脉冲,结合巯基 -(SH) 介导的核苷转化,可以实现单细胞转录活性的两个独立记录。最后,scSLAM-seq 与基于 CRISPR 的扰动相结合,将可极大地提高各种方法破译分子机制的灵敏度,这对发育生物学、感染和癌症具有重要意义。
<更多精彩,可关注微信公众号:AIPuFuBio 和大型免费综合生物信息学资源和工具平台 AIPuFu:www.aipufu.com>

python – 如何计算熊猫状态变化的数量?
计算每列的0-> 1,1-> 0的数量.在下面的数据框中
‘a’列状态更改编号为6,’b’状态更改编号为3
,’c’状态变化数是2 ..实际上我不知道如何
熊猫中的代码.
number a b c 1 0 0 0 2 1 0 1 3 0 1 1 4 1 1 1 5 0 0 0 6 1 0 0 7 0 1 0
实际上我在熊猫中没有想法..因为最近只使用过r.
但现在我必须使用python pandas.所以有点困难
任何人都可以帮忙的情况?提前致谢 !
解决方法
rolling并比较每个值,然后用sum计算所有True值:
df = df[[''a'',''b'',''c'']].rolling(2).apply(lambda x: x[0] != x[-1],raw=True).sum().astype(int) a 6 b 3 c 2 dtype: int64

Python 动态变量名定义与调用方法
动态变量名赋值
在使用 tkinter 时需要动态生成变量,如动态生成 var1…var10 变量。
使用 exec 动态赋值
exec 在 python3 中是内置函数,它支持 python 代码的动态执行。
示例:
In [1]: for i in range(5):
...: exec(''var{} = {}''.format(i, i))
...:
In [2]: print(var0, var1, var2, var3 ,var4)
0 1 2 3 4
利用命名空间动态赋值
在Python的命名空间中,将变量名与值存储在字典中,
可以通过locals(),globals()函数分别获取局部命名空间和全局命名空间。
示例
>>> names = locals()
>>> for i in range(5):
... names[''n'' + str(i) ] = i
...
>>> print(n0, n1, n2, n3, n4)
0 1 2 3 4
>>>
在类中使用动态变量
Python 的类对象的属性储存在的 dict 中。dict 是一个词典,键为属性名,值对应属性的值。
示例
>>> print(n0, n1, n2, n3, n4)
0 1 2 3 4
>>> class Test_class(object):
... def __init__(self):
... names = self.__dict__
... for i in range(5):
... names[''n'' + str(i)] = i
...
>>> t = Test_class()
>>> print(t.n0, t.n1, t.n2, t.n3, t.n4)
0 1 2 3 4
调用动态变量
事实上,对于重复性的变量,我们一般不会这样调用变量,如:var0, var1, var2, var3 ,var4…varN,可以利用下面方法动态调用变量。
先定义如下变量:
示例
>>> for i in range(5):
... exec(''var{} = {}''.format(i, i))
...
>>> print(var0, var1, var2, var3 ,var4)
0 1 2 3 4
利用 exec 函数
同样地,可以使用 exec 调用变量In
[3]: for i in range(5):
...: exec(''print(var{}, end=" ")''.format(i))
...:
0 1 2 3 4
利用命名空间
因为命令空间的locals()与globals()均会返回一个字典,利用字典的get方法获取变量的值
In [4]: names = locals()
In [5]: for i in range(5):
...: print(names.get(''var'' + str(i)), end='' '')
...:郑州专业妇科医院 http://www.hnzzkd.com/
0 1 2 3 4
下面是其他网友的补充
Python 定义动态变量
问题描述
在做数据处理时,对一些分组得来的数据,所做的操作大同小异,变量的命名也都拥有相同的结构,比如对每个月份的数据求均值、方差等统计量,变量的命名可取为“n月的均值”,“n月的方差”,抽象出来就是“n月的 ‘m统计量’ ”
在编程实现的时候,对上述变量的定义以及引用,都可以一同实现,从而减少了重复代码的数量
实现的时候遇到了动态定义变量的问题,这里总结一下
利用 exec 动态定义变量
我们可以如此动态定义变量
for n in range(1, 13):
exec(''month_{} = {}''.format(n, value or expression))
一般这种语句都可以正确定义变量,但有时上述语句会出错,比如后方传入的expression返回一个 DataFrameGroupBy 类变量时,会出现语法错误
File "", line 1
month_12 =
^
SyntaxError: invalid syntax
原因未明…经过搜索,我发现还有另一种定义方法,可以解决上述问题
for n in range(1, 13):
exec(''month_{} = temp''.format(n), {''temp'': expression})
这种方法有两个问题:
1、利用format替换的部分需在变量名的最后方,例 month_{} ,方可执行成功,而 {}_month 便不可行,原因待查…还请各位同学指点!
File “”, line 1
12_month = temp
^
SyntaxError: invalid token
2、这种方法定义的变量,只在 exec 中有效,在 exec 语句外便无效,这或许是因为python将 exec 中复杂的指令当做了局部变量,可以在利用以下语句检验
for n in range(1, 13):
exec(''month_{} = temp\nprint(locals()==globals())''.format(n), {''temp'': expression})
其中locals()与globals()是python的内部方法,它们提供了基于字典的访问局部与全局变量的方式。
如果返回 True ,说明当前环境处于全局级别,在 exec 中的语句可以在 exec 外生效
如果返回 False ,说明当期环境处于局部级别,定义的变量被看做局部变量,所以不能在 exec 外调用,可以在语句中传入globals()使其在全局生效
for n in range(1, 13):
exec(''month_{} = temp''.format(n), {''temp'': expression}, globals())
exec 方式太容易混乱,还有另外一种动态定义变量的方法,便是上文提到的globals()与locals()方法
利用命名空间动态定义变量
首先创建locals()的副本
varDict = locals()
对于上文提到的变量便可如此定义
for n in range(1, 13):
varDict[''month_''+str(n)] = value or expression
关于如何记录动态变化的情节python和动态记录法的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于IPython:如何在不同的单元格中显示相同的情节?、Nature | 新技术 scSLAM-seq 可在单细胞水平揭示转录动态变化的核心特征、python – 如何计算熊猫状态变化的数量?、Python 动态变量名定义与调用方法等相关知识的信息别忘了在本站进行查找喔。
在本文中,我们将为您详细介绍Python3套接字编程错误,丢弃最后一个数据包的相关知识,并且为您解答关于python 套接字的疑问,此外,我们还会提供一些关于iptables 不丢弃 python 套接字、PHP套接字或Python,Perl,Bash套接字?、Python 3套接字的子类中的WinError 10038、python socket 套接字编程 单进程服务器 实现多客户端访问的有用信息。
本文目录一览:- Python3套接字编程错误,丢弃最后一个数据包(python 套接字)
- iptables 不丢弃 python 套接字
- PHP套接字或Python,Perl,Bash套接字?
- Python 3套接字的子类中的WinError 10038
- python socket 套接字编程 单进程服务器 实现多客户端访问
")
Python3套接字编程错误,丢弃最后一个数据包(python 套接字)
如何解决Python3套接字编程错误,丢弃最后一个数据包?
我正在尝试在python3中模拟回溯N网络错误检测协议,为此我创建了2个python文件server.py和client.py,它们的简单工作如下
- client.py:连接到服务器,并从1到9依次向服务器发送数字,并接收来自服务器的确认,如果服务器未确认最后4个数据包,它将返回4个数字并开始再次发送
- server.py:接受来自客户端的连接并接受数据,如果正确,它将发送回确认,如果不正确,则停止发送确认,直到接收到正确的数据包顺序 问题是,在我运行完这两个包之后,即使客户端已发送所有9个数据包,最后的客户端也只能确认到8个。 这是代码和输出:
client.py
library(dplyr)
dt %>%
group_by(g) %>%
summarise(!! cn := mean(xa),.groups = ''drop'')
# A tibble: 3 x 2
# g sa
# <int> <dbl>
#1 1 0.201
#2 2 0.471
#3 3 0.487
server.py
import socket
import time
import select
import random
n=9
ack=0
data=0
flag=0
print("Hello")
HOST = ''127.0.0.1'' # The server''s hostname or IP address
TCP_PORT = 1234 # The port used by the server
with socket.socket(socket.AF_INET,socket.soCK_STREAM) as s: # TCP
s.connect((HOST,TCP_PORT))
s.setblocking(0)
while n>0:
ready = select.select([s],[],1 )
msg=str(10-n)
if(n==5 and flag==0):
msg=str(random.randint(1,9))
flag=1
if(n>=0):
s.sendall(msg.encode(''utf-8''))
print(msg," sent")
if(ready[0]):
data=s.recv(1024)
if(data):
ack+=1
print("\t\t\t",data.decode(''utf-8''),"ackNowledged")
data=0
if(ack<10-n-3):
n=n+3
time.sleep(1)
continue
time.sleep(1)
n-=1
输出:
server.py
import socket
import time
track = 0
HOST = ''127.0.0.1'' # (localhost),use 0.0.0.0 for automatic
TCP_PORT = 1234 # Port to listen on (non-privileged ports are > 1023)
with socket.socket(socket.AF_INET,socket.soCK_STREAM) as s: # af_inet=ipv4,sock_stream=TCP
s.bind((HOST,TCP_PORT))
s.listen()
print("TCP server online and listening..")
while True:
conn,addr = s.accept()
with conn:
print(''TCP connection by '',addr)
while True:
data = conn.recv(1024)
if not data:
break
print("Message from TCP client: ",data.decode(''utf-8''))
if(int(data.decode(''utf-8'')) == track+1):
print(data.decode(''utf-8''),end="")
track+=1
conn.sendall(data)
print(">")
data = 0
time.sleep(1)
print("TCP Client left..")
track=0
client.py
TCP server online and listening..
TCP connection by (''127.0.0.1'',57528)
Message from TCP client: 1
1>
Message from TCP client: 2
2>
Message from TCP client: 3
3>
Message from TCP client: 4
4>
Message from TCP client: 1
Message from TCP client: 6
Message from TCP client: 7
Message from TCP client: 8
Message from TCP client: 5
5>
Message from TCP client: 6
6>
Message from TCP client: 7
7>
Message from TCP client: 8
8>
Message from TCP client: 9
9>
我尝试在线搜索,但找不到解决方案。所以,我在这里问。我希望有人能帮助我。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

iptables 不丢弃 python 套接字
如何解决iptables 不丢弃 python 套接字?
我在虚拟机中使用 python 脚本来验证与某些路由器的端口 22 和 23 的连接。但是,与此同时,我在 VM 中使用了 iptables,因为我想删除一些路由器,但是当我执行我的脚本时,它连接到在 iptables 中有删除规则的路由器。这很奇怪,因为如果直接从 VM 进行测试,我将无法连接到应用规则的路由器。你有什么想法可以解决我的问题吗?我希望我的脚本向我显示端口被阻止,因为我在 Iptable 中有规则。
这是我脚本的一部分:
sock = socket.socket(socket.AF_INET,socket.soCK_STREAM)
sock.settimeout(2)
result1 = sock.connect_ex((ip,22))
result2 = sock.connect_ex((ip,23))
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

PHP套接字或Python,Perl,Bash套接字?
我正在尝试实现一个将在大多数共享PHP主机中运行的套接字服务器.
要求是可以自动安装,启动和停止Socket服务器,而无需用户执行任何操作.套接字服务器编写的语言并不重要,只要它将在全局的大多数共享主机上运行.
目前,我已经编写了一个带有PHP的Socket服务器,它实现了一个对象缓存:
http://code.google.com/p/php-object-cache/
但是,必须使用套接字支持编译PHP,并且运行PHP套接字支持的服务器不多.
我真正的问题是:我应该使用什么语言来实现套接字服务器,并且具有最大的平台支持并且可以在PHP中调用.
换句话说,在启用PHP的服务器上最常用的脚本语言是什么?
或者我是否必须使用编译语言编写套接字服务器以使其适用于所有服务器?
让我们暂时不让IIS退出图片,只需Linux服务器.我不认为许多PHP站点在IIS上运行…
编辑:
对不起我觉得我的问题不明确.
我想知道,根据以下要求,哪种语言最适合创建套接字服务器:
该语言必须存在于共享主机中,以及在Apache(而不是CLI)中运行的PHP.
必须以本机方式启用套接字支持,而不是通过必需的扩展.
PHP必须能够将deamon写入文件以及启动和停止deamon.
我不是要求单个服务器的解决方案.它必须在大多数共享托管服务器上本机运行.
解决方法:
这实际上取决于安装要求.编写套接字服务器的最简单和最标准的方法通常是写一个inet.d service.这是我的unix机器上的标准守护进程,它将分叉一个进程并处理套接字级别的细节.如果您希望您的服务在Unix上的1024以下端口上运行,这是完成它的更简单的方法之一.但是,初始安装需要root来配置inet.d.
如果您共享托管允许PHP执行exec调用,那么您可以通过这种方式启动守护程序.但请记住,它需要在1024端口上运行.接下来需要确定您的程序是多线程还是多进程.通常,Java程序是多线程的,而Apache实例通常是多进程的.
最后,主机可能有防火墙.这有助于防止共享主机帐户成为僵尸网络的一部分.如果防火墙规则不允许连接到其他端口,则无法远程连接到该端口.

Python 3套接字的子类中的WinError 10038
错误10038为WSAENOTSOCK。
尝试对非套接字的对象进行操作。
之所以发生这种情况,是因为在连接之前要关闭插座。如果调用close(),则必须在此之后创建一个新套接字。

python socket 套接字编程 单进程服务器 实现多客户端访问
服务器:
1 import socket
2 #单进程服务器 实现多客户端访问 IO复用
3 #吧所有的客户端套接字 放在一个列表里面,一次又一次的便利过滤
4 #这就是apache: select模型 6 server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
7 server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #设置端口复用
8 #AF_INET: IPV4
9 #AF_INET6: IPV6
10 #SOCK_STREAM: TCP
11 #SOCK_DGRAM: UDP
12 Host = ''''
13 port = 23333
14 server.bind((Host,port))
15 #服务器绑定端口 8080
16 server.listen(5)
17 #服务器同时监听5个 最大链接数 5
18
19 print(''[+] server open'')
20
21 c_server = {}
22 #定义一个全局字典
23 server.setblocking(0)
24 #设置服务器recv接受信息和send发送信息为非阻塞状态(默认为阻塞状态)
25 #是否阻塞(默认True),如果设置False,那么accept和recv时一旦无数据,则报错。
26 while True:
27 try:
28 try:
29
30 client,c_addr = server.accept()
31
32 except BlockingIOError:
33 #无法立即完成一个非阻止性套接字操作。
34 if not c_server:
35 #如果字典为空
36 continue
37 #重新接收套接字
38 pass
39 else:
40 client.setblocking(0)#设置套接字属性为非阻塞
41 #是否阻塞(默认True),如果设置False,那么accept和recv时一旦无数据,则报错。
42 #[WinError 10035] 无法立即完成一个非阻止性套接字操作。
43 c_server[client] = c_addr#以字典形式存储新链接的套接字
44 print(''[+] from'',c_addr)
45 for a in list(c_server.keys()):
46 #这里将字典的keys取出来 在列表化,在没有信息的时候删除套接字了
47 try:
48 msg = a.recv(1024).decode(''utf-8'')
49 #非阻塞接受消息,但是如果客户端不马上发送,就会报错,所以设置一个延迟接收
50 except BlockingIOError as e:
51 continue
52
53 if not msg:
54 print(''[%s] closed''%(c_server[a][0]))
55 a.close()
56 del c_server[a]
57 continue
58 print("来自%s的消息: %s"%(c_server[a][0],msg))
59 a.send(msg.encode(''utf-8''))
60 #发送重复的消息
61 except KeyboardInterrupt:
62 break
63
64
65 server.close()
客户端:
1 #coding:utf-8
2
3 import socket
4 client = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
5 #创建一个客户端链接,socket.AF_INET代表ipv4,socket.SOCK_STREAM代表tcp套接字
6 client.connect((''127.0.0.1'',23333))
7 #客户端链接
8 print(''[+] 链接成功'')
9 #链接成功显示
10 while True:
11 msg = input(''>>>'')
12 if msg == ''quit'':
13 #如果输入的信息是quit 就退出链接
14 break
15 if len(msg) == 0:#如果直接输入的一个回车的话
16 #就重新输入,因为不能发送空 ,发送空的花 客户端会卡住
17 continue
18 client.send(msg.encode(''utf-8''))
19 #客户端发送信息msg 以utf8格式发送数据
20 data = client.recv(1024).decode(''utf-8'')
21 if not data:
22 #如果数据为空/0
23 #服务器主动断开s
24 break
25 print(''[+] 服务器主动断开了链接......'')
26
27 print(''服务器发来:'',data)
28
29
30 print(''[+] 链接关闭...'')
31
32 client.close()
服务器就是apache: select模型
关于Python3套接字编程错误,丢弃最后一个数据包和python 套接字的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于iptables 不丢弃 python 套接字、PHP套接字或Python,Perl,Bash套接字?、Python 3套接字的子类中的WinError 10038、python socket 套接字编程 单进程服务器 实现多客户端访问的相关信息,请在本站寻找。
在这篇文章中,我们将带领您了解返回Mongoose文档时,NestJS过滤掉空属性的全貌,包括mongo返回指定字段的相关情况。同时,我们还将为您介绍有关Express cookieSession和Mongoose:如何使request.session.user成为Mongoose模型?、fastjson 过滤掉不需要序列化的属性、fastjson转json的时候过滤掉某些属性、fastjson过滤掉不需要返回的字段的知识,以帮助您更好地理解这个主题。
本文目录一览:- 返回Mongoose文档时,NestJS过滤掉空属性(mongo返回指定字段)
- Express cookieSession和Mongoose:如何使request.session.user成为Mongoose模型?
- fastjson 过滤掉不需要序列化的属性
- fastjson转json的时候过滤掉某些属性
- fastjson过滤掉不需要返回的字段
")
返回Mongoose文档时,NestJS过滤掉空属性(mongo返回指定字段)
如何解决返回Mongoose文档时,NestJS过滤掉空属性?
我在猫鼬文档中有一个深层嵌套的对象,其中包含以下数据:
static void Main(string[] args)
{
List<Shape> shapes = new List<Shape>();
shapes.Add(new Triangle());
shapes.Add(new Sphere());
foreach (var shape in shapes)
{
_ = (shape is Triangle) ?
((Triangle)shape).Getnormale() :
((Sphere)shape).Getnormale(0,0);
}
Console.ReadLine();
}
当我从数据库中检索它并用console.log记录时,这就是我得到的。 但是当我将文档作为响应返回时,空对象被过滤掉,而我只能得到:
{
blocks: [
{
key: ''3a673'',text: ''kjhkhj'',type: ''unstyled'',depth: 0,inlinestyleRanges: [],entityRanges: [],data: {}
}
],entityMap: {}
}
我该如何解决?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

Express cookieSession和Mongoose:如何使request.session.user成为Mongoose模型?
创建新用户帐户后,我创建了newUser,这是一个Mongoose模型实例,如下所示:
_events: Objecterrors: undefinedisNew: falsesave: function () {arguments: nullcaller: null_doc: Object name: ''Joe Smith''...该对象的实际数据位于 _doc 属性中,尽管存在getter和setter,所以您可以运行:
user.name = ''Jane Doe''这样就可以了。我跑:
request.session.user = newUser;将用户保存到会话。到目前为止,一切都很好。
但是,在后续请求中,request.session.user似乎只是_doc中的内容。例如:
name: ''Joe Smith''很好,但这意味着我无法运行例如 request.session.user.save() 来保存更改。
我可以简单地制作一些中间件来查找与数据关联的用户。但是我想了解更多有关Express和Mongoose在这里做什么的信息。
如何使request.session.user成为Mongoose模型?
更新 :我当前的中间件黑客:
// Use as a middleware on routes which need users// TODO: only needed due to request.session.user being saved weirdlyvar rehydrateUser = function(request, response, next) { if ( request.session.user ) { var hydrated = request.session.user.save if ( ! hydrated ) { console.log(''Rehydrating user...''); models.User.findOne({ somefield: request.session.user.somefield }, function (err, user) { if ( err ) { request.session.error = ''User not found in DB!''; request.redirect(''/''); } else { request.session.user = user; console.log(''Rehydrated user! All repos already being monitored.''); next(); } }) } else { next(); } } else { console.log(''No user in session'') next(); }}答案1
小编典典Express会话存储为单独的存储,并且对可以在那里存储的内容有限制。它不能存储原型数据(方法)。看起来更像是key<>value存储。
这样做的原因是会话可以存储在任何地方(很多),例如:进程内存;数据库(mongodb); 重做 等等
因此,一旦在会话对象中放入任何内容并完成请求,express就会获取会话数据,将其解析并像纯对象一样粘贴到会话存储中。默认情况下,它是进程内存,但是如前所述-
可以是任何其他存储。
因此,当下一个http请求发生时,会话中间件将尝试使用请求标头中的cookie(如果使用了)数据来恢复会话,并要求会话存储提供数据。因为它已经被格式化-
它不会有.prototype的东西,但只是数据(object,array,string,number,和其他简单的东西)。
因此,您需要再次根据该数据创建模型。
您可以通过中间件快速完成。因此,app.configure在定义后,session 您可以直接执行以下操作:
app.use(function(req, res, next) { if (req.session && req.session.user) { req.session.user = new UserModel(req.session.user); } return next();});这将检查是否定义了会话以及用户。然后将根据该数据重新创建猫鼬模型。
如此处的注释中所述-您不应在会话中存储用户数据,因为由于责任与数据所有权的划分会导致不一致。因此,仅存储ID用户,然后使用中间件从数据库加载它。
app.use(function(req, res, next) { if (req.session && req.session.userID) { UserModel.findById(req.session.userID, function(err, user) { if (!err && user) { req.user = user; next(); } else { next(new Error(''Could not restore User from Session.'')); } }); } else { next(); }});在您可以创建中间件以检查用户是否登录后:
function userRequired(req, res, next) { if (req.user) { next(); } else { next(new Error(''Not Logged In''); }}并像这样使用它:
app.get(''/items'', userRequired, function(req, res, next) { // will only come here if user is logged in (req.user !== undefined)});
fastjson 过滤掉不需要序列化的属性
第一种方式,使用PropertyFilter。
可根据属性名称或属性值进行过滤。
PropertyFilter filter = new PropertyFilter() {
// name:属性名称,value:属性值
public boolean apply(Object source,String name,Object value) {
// 当属性名称是“name”且属性值是“chennp2008”时,将其过滤出来
if ("name".equals(name) && "chennp2008".equals(value)) {
// true 需要序列化,过滤出来
return true;
}
// false 无需序列化,不过滤出来
return false;
}
};
SerializeWriter out = new SerializeWriter();
JSONSerializer serializer = new JSONSerializer(out);
serializer.getPropertyFilters().add(filter);
A a = new A();
a.setName("chennp2008");
serializer.write(a);
String text = out.toString();
Assert.assertEquals("{\"name\":\"chennp2008\"}",text);实体类Entity
public class A {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
第二种方式,使用SimplePropertyPreFilter。
根据属性名称过滤。
VO vo = new VO();
vo.setId(123);
vo.setName("flym");
// SimplePropertyPreFilter第二个参数:传入需要序列化属性的名称
SimplePropertyPreFilter filter = new SimplePropertyPreFilter(VO.class,"name");
// 只序列化name,不序列化id
Assert.assertEquals("{\"name\":\"flym\"}",JSON.toJSONString(vo,filter));实体类Entity
class VO {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
fastjson转json的时候过滤掉某些属性
@JSONType(orders = { "prop1","prop2","prop3","prop4" })
@Data
public class AppResourceModel implements ParserModel {
private String prop1;
private String prop2;
private String prop3;
private List<String> prop4;
@Override
public String toJson() {
if (StringUtil.isBlank(prop1) && StringUtil.isBlank(prop2) && StringUtil.isBlank(prop3)) {
return null;
}
return JSON.toJSONString(this);
}
/*
* @return 添加json格式过滤,防止这个在转json的时候自动添加到json中
* 通过这种方法来过滤掉不需要的属性
*/
@Override
@JSONField(serialize = false) public int getSelect() { return 0; }}

fastjson过滤掉不需要返回的字段
使用场景
在项目中,后端查询数据库返回的字段需要过滤传给前端,或者只需要一部分字段
方法一 new
newVO,DTO类,实体类来解决 (太老土的做法)
方法二 使用transient关键字 (密码,和身份证号字段多使用)
把需要过滤掉字段使用transient关键字修饰,这样在调用JSON的toString方法时,被transient修饰的字段不会出现在最终的json字符串中
例子: private transient String id; (在多个接口中使用这个字段 ,如果不是都要过滤这个字段时候, 就不适合使用)
方法三 使用注解@JSONField(serialize=false) 作用和使用情况同方法二
例子: @JSONField(serialize=false)
private String id;
方法四 使用fastjson属性过滤器SimplePropertyPreFilter (推荐使用 更灵活)
SimplePropertyPreFilter实现了PropertyPreFilter

例子: Student 相当于VO,DTO类或者实体类
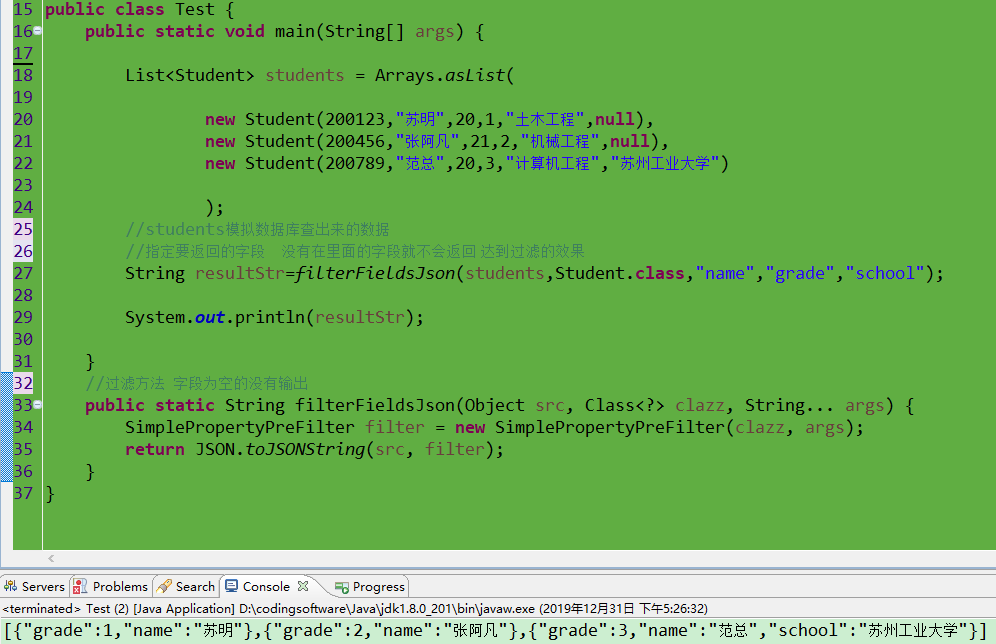
要输出字段为空的情况 增加一个参数 SerializerFeature.WriteMapNullValue


public class Student {
/** 学号 */
private long id;
private String name;
private int age;
/** 年级 */
private int grade;
/** 专业 */
private String major;
/** 学校 */
private String school;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getGrade() {
return grade;
}
public void setGrade(int grade) {
this.grade = grade;
}
public String getMajor() {
return major;
}
public void setMajor(String major) {
this.major = major;
}
public String getSchool() {
return school;
}
public void setSchool(String school) {
this.school = school;
}
public Student(long id, String name, int age, int grade, String major, String school) {
super();
this.id = id;
this.name = name;
this.age = age;
this.grade = grade;
this.major = major;
this.school = school;
}
}public class Test {
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student(200123,"苏明",20,1,"土木工程",null),
new Student(200456,"张阿凡",21,2,"机械工程",null),
new Student(200789,"范总",20,3,"计算机工程","苏州工业大学")
);
//students模拟数据库查出来的数据
//指定要返回的字段 没有在里面的字段就不会返回 达到过滤的效果
String resultStr=filterFieldsJson(students,Student.class,"name","grade","school");
System.out.println(resultStr);
}
//过滤方法 字段为空也输出 增加一个参数 SerializerFeature.WriteMapNullValue
public static String filterFieldsJson(Object src, Class<?> clazz, String... args) {
SimplePropertyPreFilter filter = new SimplePropertyPreFilter(clazz, args);
return JSON.toJSONString(src, filter,SerializerFeature.WriteMapNullValue);
}
}我们今天的关于返回Mongoose文档时,NestJS过滤掉空属性和mongo返回指定字段的分享已经告一段落,感谢您的关注,如果您想了解更多关于Express cookieSession和Mongoose:如何使request.session.user成为Mongoose模型?、fastjson 过滤掉不需要序列化的属性、fastjson转json的时候过滤掉某些属性、fastjson过滤掉不需要返回的字段的相关信息,请在本站查询。
本文标签:




