在本文中,您将会了解到关于序列化DateTime时强制JSON.NET包含毫秒的新资讯,同时我们还将为您解释即使ms组件为零的相关在本文中,我们将带你探索序列化DateTime时强制JSON.NET包
在本文中,您将会了解到关于序列化DateTime时强制JSON.NET包含毫秒的新资讯,同时我们还将为您解释即使ms组件为零的相关在本文中,我们将带你探索序列化DateTime时强制JSON.NET包含毫秒的奥秘,分析即使ms组件为零的特点,并给出一些关于.net – DateTime和xsd:Date的往返XML序列化?、.net – 如何使XML序列化DateTimeOffset属性?、.net – 将DateTime序列化为毫秒毫秒和gmt的时间、ASP.NET MVC Controller.Json DateTime序列化与NewtonSoft Json DateTime序列化的实用技巧。
本文目录一览:- 序列化DateTime时强制JSON.NET包含毫秒(即使ms组件为零)(localdatetime序列化)
- .net – DateTime和xsd:Date的往返XML序列化?
- .net – 如何使XML序列化DateTimeOffset属性?
- .net – 将DateTime序列化为毫秒毫秒和gmt的时间
- ASP.NET MVC Controller.Json DateTime序列化与NewtonSoft Json DateTime序列化
(localdatetime序列化)")
序列化DateTime时强制JSON.NET包含毫秒(即使ms组件为零)(localdatetime序列化)
我正在使用JSON.NET直接从对象实例中序列化DateTime值(不将DateTime.ToString()与格式化程序一起使用)。
有没有办法强制JSON.NET在序列化中包含毫秒,即使DateTime的毫秒部分为零?
背景:这个JSON端点的Web服务使用者非常慢。条件逻辑对于消费者来说是昂贵的,因此我想每次都提供相同的数据格式。
答案1
小编典典我们在我当前的项目中遇到了同样的问题。我们正在使用Web API(因此使用JSON.Net)来实现REST
API。我们发现,在序列化DateTime对象时,JSON.Net从毫秒中删除尾随零,或者如果从零开始则从日期中完全删除毫秒。我们的客户希望使用固定长度的日期时间字符串,毫秒数必须为3位数字。我们通过执行以下操作来修复它Application_Start():
JsonSerializerSettings settings = HttpConfiguration.Formatters.JsonFormatter.SerializerSettings;IsoDateTimeConverter dateConverter = new IsoDateTimeConverter { DateTimeFormat = "yyyy''-''MM''-''dd''T''HH'':''mm'':''ss.fff''Z''" };settings.Converters.Add(dateConverter);如果您不使用Web
API,则可以通过创建的新实例JsonSerializerSettings,IsoDateTimeConverter如上所示将其添加到,然后将序列化程序设置传递到来执行相同的操作JsonConvert.SerializeObject()。
注意:如果您要序列化DateTimeOffset或本地,DateTime并且要包括时区偏移,请用''Z''unquoted
替换上述格式中的引号K。有关更多信息,请参见文档中的“ 自定义日期和时间格式字符串 ”。

.net – DateTime和xsd:Date的往返XML序列化?
In versions 2.0 and later of the .Net
Framework,with this property set to
roundtripDateTime objects are examined
to determine whether they are in the
local,UTC or an unspecified time
zone,and are serialized in such a way
that this information is preserved.
This is the default behavior and is
recommended for all new applications
that do not communicate with older
versions of the framework.
然而:
namespace ConsoleApplication1 {
public class DateSerTest {
[XmlElement(DataType = "date")]
public DateTime Date { get; set; }
}
class Program {
static void Main(string[] args) {
DateSerTest d = new DateSerTest {
Date = DateTime.SpecifyKind(new DateTime(2009,8,18),DateTimeKind.Utc),};
XmlSerializer ser = new XmlSerializer(typeof(DateSerTest));
using (FileStream fs = new FileStream("out.xml",FileMode.Create)) {
ser.Serialize(fs,d);
}
// out.xml will contain:
// <Date>2009-08-18</Date>
using (FileStream fs = new FileStream("out.xml",FileMode.Open)) {
DateSerTest d1 = (DateSerTest) ser.Deserialize(fs);
Console.WriteLine(d1.Date); // yields: 8/18/2009 12:00:00 AM
Console.WriteLine(d1.Date.Kind); // yields: Unspecified
}
// in.xml:
// <DateSerTest>
// <Date>2009-08-18Z</Date>
// </DateSerTest>
using (FileStream fs = new FileStream("in.xml",FileMode.Open)) {
DateSerTest d1 = (DateSerTest) ser.Deserialize(fs);
Console.WriteLine(d1.Date); // yields: 8/17/2009 8:00:00 PM
Console.WriteLine(d1.Date.Kind); // yields: Local
using (FileStream fs1 = new FileStream("out2.xml",FileMode.Create)) {
ser.Serialize(fs1,d1);
// out2.xml will contain:
// <Date>2009-08-17</Date>
}
}
Console.ReadKey();
}
}
}
因此,对于定义为“date”而不是“dateTime”的XSD元素,日期不会以UTC序列化.这是一个问题,因为如果我反序列化这个XML,那么生成的日期将是“未指定的”类型,并且任何转换为UTC(实际上应该是无效的,因为UTC的日期应该在往返期间被保留),将至少改变一天的时间,昨天有50%的机会提供日期,具体取决于您是否在格林威治的东部或西部.
日期不得写为:
<Date>2009-08-18Z</Date>
?
实际上,如果我反序列化包含上述的文档,我会收到一个已经被转换为本地时间的DateTime(我在纽约,所以这是8月17日20:00),如果我立即将该对象序列化回XML,我得到:
<Date>2009-08-17</Date>
所以,UTC被转换为本地的方式,而当地的一部分在出路的时候,这将使它在未来的路上重新出现.我们对8月18日原始UTC日期规格的了解不全面.
以下是W3C对xsd的说法:date:
[DeFinition:] The ·value space· of
date consists of top-open intervals of
exactly one day in length on the
timelines of dateTime,beginning on
the beginning moment of each day (in
each timezone),i.e. ’00:00:00′,up to
but not including ’24:00:00′ (which is
identical with ’00:00:00′ of the next
day). For nontimezoned values,the
top-open intervals disjointly cover
the nontimezoned timeline,one per
day. For timezoned values,the
intervals begin at every minute and
therefore overlap.
根本的问题是,如果我做以下:
>构造(或以其他方式接收)UTC DateTime值.
>使用将该字段定义为xsd:date的模式将其序列化为XML
>将XML反序列化为DateTime.
>将DateTime转换为UTC(应该没有影响,因为“往返”应该保留这个).
或以下:
>对包含UTC xsd:date对象的XML文档进行反序列化(例如:2009-08-18Z).
>将其序列化回新的XML文档,而不用触摸它.
这些程序中的任何一个应该让我和我放在一起的日期一样.
解决方法
到目前为止,我可以看到获得往返行为的唯一方法是实现Date属性如下,假设所有xsd:date元素都代表UTC:
[XmlElement(DataType = "date")]
public DateTime Date {
get { return _dt; }
set { _dt = value.Kind == DateTimeKind.Unspecified ?
DateTime.SpecifyKind(value,DateTimeKind.Utc) :
value.ToUniversalTime(); }
}
We have different behaviors for handling Date,Time and DateTime values. For DateTime values,if XmlDateTimeSerializationMode is not Local the information about the kind (UTC,Local or Unspecified) is preserved. This is also true while deserializing. However,for Date and Time,they are always serialized out with the same format: (yyyy-MM-dd for Date and HH:mm:ss.fffffff.zzzzzz for Time). So the information about kind is lost on serializing and deserializing. We are opening a documentation bug on our side in order to improve the documentation about this.

.net – 如何使XML序列化DateTimeOffset属性?
[XmlRoot("playersConnected")]
public class PlayersConnectedViewData
{
[XmlElement("playerConnected")]
public PlayersConnectedItem[] playersConnected { get; set; }
}
[XmlRoot("playersConnected")]
public class PlayersConnectedItem
{
public string name { get; set; }
public DateTimeOffset connectedOn { get; set; } // <-- This property fails.
public string server { get; set; }
public string gameType { get; set; }
}
和一些样本数据…
<?xml version="1.0" encoding="utf-8"?>
<playersConnected
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<playerConnected>
<name>jollyroger1000</name>
<connectedOn />
<server>log1</server>
<gameType>Battlefield 2</gameType>
</playerConnected>
</playersConnected>
更新
我希望可能会有一种方式通过属性,我可以在物业上装饰…
奖金问题
以任何方式摆脱在根节点中声明的两个命名空间?我是不是该?
[XmlElement("lastUpdatedTime")]
public string lastUpdatedTimeForXml // format: 2011-11-11T15:05:46.4733406+01:00
{
get { return lastUpdatedTime.ToString("yyyy-MM-ddTHH:mm:ss.fffffffzzz"); }
set { lastUpdatedTime = DateTimeOffset.Parse(value); }
}
[XmlIgnore]
public DateTimeOffset lastUpdatedTime;

.net – 将DateTime序列化为毫秒毫秒和gmt的时间
private System.DateTime timeField;
[System.Xml.Serialization.XmlElementAttribute(DataType="time")]
public System.DateTime Time {
get {
return this.timeField;
}
set {
this.timeField = value;
}
}
序列化后,文件的内容如下所示:
<Time>14:04:02.1661975+02:00</Time>
是否可以使用属性上的XmlAttributes来使其呈现毫秒毫秒和GMT值?
<Time>14:04:02</Time>
这是可能的,还是我需要在类被序列化之后将某种类型的xsl / xpath替换魔术组合在一起?
将对象更改为String不是解决方案,因为它在应用程序的其余部分使用像是DateTime,并允许我们使用XmlSerializer.Serialize()方法从对象创建一个xml表示.
我需要从该字段中删除额外信息的原因是接收系统不符合时间数据类型的w3c标准.

ASP.NET MVC Controller.Json DateTime序列化与NewtonSoft Json DateTime序列化
return Json(value);
我收到的客户
"/Date(1336618438854)/"
如果我使用返回相同的值
return Json(JsonConvert.SerializeObject(value));
然后返回的序列化值(与序列化对象一起)是时区感知的:
"/Date(1336618438854-0400)/"
有没有办法在没有双序列化的情况下获得一致的DateTime结果?我在某处读过MS会将Newtonsoft JSON包含到MVC中吗?
解决方法
我将我的项目切换为ISO 8601 DateTime格式.只需使用JsonConverter属性修饰对象上的datetime属性,就可以很好地与JSON.net完成序列化.
public class ComplexObject
{
[JsonProperty]
public string ModifiedBy { get; set; }
[JsonProperty]
[JsonConverter(typeof(IsoDateTimeConverter))]
public DateTime Modified { get; set; }
...
}
要将序列化对象返回给客户端ajax调用,我可以这样做:
return Json(JsonConvert.SerializeObject(complexObjectInstance));
在客户端:
jsObject = JSON.parse(result)
现在我认为将默认的ASP.NET MVC默认JSON序列化器覆盖到我们的Newtonsoft JSON.net ISO 8601序列化可能很简单,并且是原则应该类似于此线程:Change Default JSON Serializer Used In ASP MVC3.
今天的关于序列化DateTime时强制JSON.NET包含毫秒和即使ms组件为零的分享已经结束,谢谢您的关注,如果想了解更多关于.net – DateTime和xsd:Date的往返XML序列化?、.net – 如何使XML序列化DateTimeOffset属性?、.net – 将DateTime序列化为毫秒毫秒和gmt的时间、ASP.NET MVC Controller.Json DateTime序列化与NewtonSoft Json DateTime序列化的相关知识,请在本站进行查询。
对于如果我将其他人的私人 Github 存储库分叉到我的帐户中,它会作为公共存储库出现在我的帐户中吗?感兴趣的读者,本文将提供您所需要的所有信息,并且为您提供关于GitHub 操作:使用来自同一组织中另一个存储库的私有 github npm 包、GitHub派生了一个分叉的存储库、GitHub转移存储库-到新组织并更改存储库名称、Google Apps脚本:是否可以将blob文件存储在用户个人驱动器中,然后将其插入电子表格中? 在主帐户中:现在,朋友登录了他们的帐户:参考:的宝贵知识。
本文目录一览:- 如果我将其他人的私人 Github 存储库分叉到我的帐户中,它会作为公共存储库出现在我的帐户中吗?
- GitHub 操作:使用来自同一组织中另一个存储库的私有 github npm 包
- GitHub派生了一个分叉的存储库
- GitHub转移存储库-到新组织并更改存储库名称
- Google Apps脚本:是否可以将blob文件存储在用户个人驱动器中,然后将其插入电子表格中? 在主帐户中:现在,朋友登录了他们的帐户:参考:

如果我将其他人的私人 Github 存储库分叉到我的帐户中,它会作为公共存储库出现在我的帐户中吗?
有人让我访问了他们在 Github 上的一个私人仓库。我想做的是将该项目分叉到我自己的帐户中,这样我就可以利用 Github 的拉取请求功能。
我在 Github 上只有一个基本帐户,所以我不能自己进行私人回购,但是如果我将别人的私人回购分叉到我的帐户中,它会在我的帐户中显示为公开吗?
答案1
小编典典不,你可以分叉它,它仍然是私有的。
私人合作者可以分叉您将他们添加到的任何私人存储库,而无需他们自己的付费计划。他们的分叉不计入您的私有存储库配额。
https://github.com/plans

GitHub 操作:使用来自同一组织中另一个存储库的私有 github npm 包
如何解决GitHub 操作:使用来自同一组织中另一个存储库的私有 github npm 包?
在我的 GitHub 组织中,我有 2 个存储库:
-
my-app-package具有将其发布为 GitHub npm 包的操作。 -
my-app,它依赖于my-app-package,并且具有构建 docker 镜像并将其发布到 GitHub 容器存储库的操作。
因此,这一切都在 GitHub 生态系统内,针对同一组织。
在我的 my-app 工作流程中有没有办法使用 npm install 令牌验证 my-app-package 的 secrets.GITHUB_TOKEN 依赖项?
基本上,我想避免从一个 repo 到另一个 repo 创建访问令牌,而是使用自动 GITHUB_TOKEN,因为所有这些都发生在单个组织的上下文中(所有者相同)。
这有意义吗?这可能吗?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

GitHub派生了一个分叉的存储库
只需单击分叉存储库GitHub页面上的 Fork 按钮,即可为您创建分叉存储库的叉子。如果将鼠标悬停在merged results in dictionary with id 1 {'city': 'b','id': 1,'name': 'a'}
叉子页面上的叉子按钮上,它将显示
将自己的smith / some-random-stuff副本复制到您的帐户中
因此,您只需要单击叉子smith/some-random-stuff

GitHub转移存储库-到新组织并更改存储库名称
转让所有权,然后更改名称。或更改名称,然后转移所有权。
所有权的转移和重命名都提供了从旧位置的重定向。
重命名存储库时,所有现有信息(项目站点URL除外)都将自动重定向到新名称...除了重定向Web流量外,所有git clone,git fetch或git push操作均以以前的位置将继续像在新位置上一样起作用。
所有到先前存储库位置的链接都将自动重定向到新位置。在转移的存储库上使用git clone,git fetch或git push时,这些命令将重定向到新的存储库位置或URL。但是,为避免混淆,我们强烈建议更新任何现有的本地克隆以指向新的存储库URL。

Google Apps脚本:是否可以将blob文件存储在用户个人驱动器中,然后将其插入电子表格中? 在主帐户中:现在,朋友登录了他们的帐户:参考:
我不知道您是否已设置Web应用程序(权限,如果脚本链接到电子表格,则是独立的,如果每个用户都必须拥有自己的电子表格),但这是与您类似的示例。
说明:
我有我的主帐户和一个朋友的帐户。
在主帐户中:
- 创建了新的脚本项目。
- 创建了新的电子表格。
- 在云端硬盘中制作了一个名为“ doggo.jpg”的图片。
- 具有一些功能:
function insertImg (fileName) {
const ssDA = SpreadsheetApp.openById("{spreadsheetid}"); // use your new spreadsheet id
const wsDA = ssDA.getSheetByName("{sheetname}");
const ufileName = fileName
const files = DriveApp.getFiles();
while (files.hasNext()) {
let file = files.next();
let fFileName = file.getName();
if(fFileName === ufileName){
uBlob = file.getBlob();
}
}
wsDA.insertImage(uBlob,10,10);
}
function testInsert() { // THIS IS THE TEST FUNCTION
insertImg("doggo.jpg")
}
function doGet(e) {
return HtmlService.createHtmlOutputFromFile("page"); // next we will make this page
}
- 在脚本项目中制作了一个带有按钮和addEventListener的html文件“ page.html”,以运行测试功能,在此示例中,我不包括样板html(Doctype,head等) ):
<body>
<h1>Hello</h1>
<button id="btn">Run Function</button>
<script>
document.getElementById("btn").addEventListener("click",doStuff);
function doStuff(){
google.script.run.insertImg("doggo.jpg"); // here is the running of the test function.
};
</script>
</body>
- 运行测试并确保我已授予脚本所有权限。
- 已发布的网络应用
Execute the app as: User accessing the web app,Who has access to the app: Anyone - 打开Web应用程序,按一下按钮,它将图像插入到电子表格中。到这里,和我想的一样。
- 与朋友的帐户共享了Google表格。-非常重要。
现在,朋友登录了他们的帐户:
- 在朋友帐户的云端硬盘中又获得了另一个名称为“ doggo.jpg”的图片。
- 打开Web应用程序的URL并授予必要的权限。
- 测试了按钮,它起作用了!
参考:
https://developers.google.com/apps-script/guides/web
我们今天的关于如果我将其他人的私人 Github 存储库分叉到我的帐户中,它会作为公共存储库出现在我的帐户中吗?的分享就到这里,谢谢您的阅读,如果想了解更多关于GitHub 操作:使用来自同一组织中另一个存储库的私有 github npm 包、GitHub派生了一个分叉的存储库、GitHub转移存储库-到新组织并更改存储库名称、Google Apps脚本:是否可以将blob文件存储在用户个人驱动器中,然后将其插入电子表格中? 在主帐户中:现在,朋友登录了他们的帐户:参考:的相关信息,可以在本站进行搜索。
对于想了解如何在 MongoDB 中将集合从一个数据库复制到另一个数据库的读者,本文将是一篇不可错过的文章,我们将详细介绍mongodb拷贝集合命令,并且为您提供关于android – 如何快速地将表从一个数据库复制到另一个数据库、mysql 把一个数据库中的数据复制到另一个数据库中的表 2 个表结构相同、mysql把某一个数据库上的表的一些字段,复制到另一个数据库上的、navicat怎么将数据库复制到另一个数据库的有价值信息。
本文目录一览:- 如何在 MongoDB 中将集合从一个数据库复制到另一个数据库(mongodb拷贝集合命令)
- android – 如何快速地将表从一个数据库复制到另一个数据库
- mysql 把一个数据库中的数据复制到另一个数据库中的表 2 个表结构相同
- mysql把某一个数据库上的表的一些字段,复制到另一个数据库上的
- navicat怎么将数据库复制到另一个数据库
")
如何在 MongoDB 中将集合从一个数据库复制到另一个数据库(mongodb拷贝集合命令)
有没有一种简单的方法可以做到这一点?
答案1
小编典典目前 MongoDB 中没有可以执行此操作的命令。请注意带有相关功能请求的 JIRA
票证。
您可以执行以下操作:
db.<collection_name>.find().forEach(function(d){ db.getSiblingDB(''<new_database>'')[''<collection_name>''].insert(d); });请注意,这样,两个数据库需要共享同一个 mongod 才能工作。
除此之外,您可以对一个数据库中的集合进行 mongodump,然后将集合 mongorestore 到另一个数据库。

android – 如何快速地将表从一个数据库复制到另一个数据库
我有一个数据库,一个表和另一个数据库.我需要将这一个表从第一个数据库(使用简单表)复制到第二个数据库. (在第二个数据库中它应该是fts3表).因此,我可以打开两个数据库,在第二个数据库中创建新的fts3,并通过select – >将所有数据从第一个数据复制到第二个数据库.插入查询.但还有其他方法可以更快更好地完成吗?
解决方法:
据我所知,您描述的方法(即INSERT INTO db2.tbl SELECT * FROM db1.tbl)通常应该是最有效的.
你可以做的是调整sqlite以更快地完成它.首先想到的是禁用journaling(通常是危险的,但在您的场景中应该可以接受,因为您仍然拥有数据的原始内容):
pragma PRAGMA journal_mode=OFF:
你也可以关掉synchronous pragma(也很危险):
PRAGMA synchronous=OFF;
你可以玩一两个pragma可能会有所作为,但我认为我提到的两个将产生最大的影响.
确保在复制后将这些编译指示恢复为其原始值.

mysql 把一个数据库中的数据复制到另一个数据库中的表 2 个表结构相同
首页
问题
- 全部问题
- 经济金融
- 企业管理
- 法律法规
- 社会民生
- 科学教育
- 健康生活
- 体育运动
- 文化艺术
- 电子数码
- 电脑网络
- 娱乐休闲
- 行政地区
- 心理分析
- 医疗卫生
精选
- 知道专栏
- 知道日报
- 知道大数据
- 知道非遗
用户
机构合作
知道福利
- 知道合伙人
- 芝麻团
- 芝麻将
- 日报作者
- 知道之星
- 开放平台
- 品牌合作
- 财富商城
特色
- 经验
- 宝宝知道
- 作业帮
- 手机版
- 我的知道
mysql 把一个数据库中的数据复制到另一个数据库中的表 2 个表结构相同
我来答
分享
举报浏览 31689 次 2 个回答
#过年啦 # 年夜饭应该在娘家吃还是婆家吃?
 ice 千
ice 千
推荐于 2017-10-04
1。表结构相同的表,且在同一数据库(如,table1,table2)
Sql :insert into table1 select * from table2 (完全复制)
insert into table1 select distinct * from table2 (不复制重复纪录)
insert into table1 select top 5 * from table2 (前五条纪录)
2。 不在同一数据库中(如,db1 table1,db2 table2)
sql: insert into db1..table1 select * from db2..table2 (完全复制)
insert into db1..table1 select distinct * from db2table2 (不复制重复纪录)
insert into tdb1..able1 select top 5 * from db2table2 (前五条纪录)

mysql把某一个数据库上的表的一些字段,复制到另一个数据库上的
server A上的一个mysql数据库,其的一张表A,下的某几个字段复制到server B上的数据库,的表B,表B的字段就只有要复制的字段,请问有什么好的工具去复制。能支持到复制一张表,或者一张表下的某几个字段,或者不同表的字段拼在一起,复制到server B上的表中

navicat怎么将数据库复制到另一个数据库
使用 navicat 复制数据库的步骤:连接源和目标数据库。选择要复制的数据库对象(表、视图、存储过程)。右键单击对象并选择“复制数据库对象”。选择目标数据库并自定义复制选项(数据复制、重命名表、放弃约束)。单击“开始”执行复制。检查目标数据库中的复制结果,验证数据和约束的正确性。

如何在 Navicat 中将数据库复制到另一个数据库
Navicat 是一款强大的数据库管理工具,支持多种数据库平台。它能够轻松地将一个数据库复制到另一个数据库,无论它们位于同一服务器还是不同的服务器上。以下是如何在 Navicat 中复制数据库:
步骤 1:建立源数据库和目标数据库的连接
打开 Navicat,连接到源数据库和目标数据库。确保您具有足够的权限来复制源数据库。
步骤 2:选择要复制的数据库对象
在导航树中,找到您要复制的源数据库对象。这可能包括表、视图、存储过程和函数。
步骤 3:右键单击并选择“复制数据库对象”
右键单击您要复制的对象,然后选择“复制数据库对象”选项。
步骤 4:选择目标数据库
在“复制数据库对象向导”中,选择目标数据库。您还可以指定目标模式和对象名称。
步骤 5:自定义复制选项
您可以选择复制哪些对象类型,并自定义其他选项,例如:
- 复制数据:选择是否复制对象中的数据。
- 重命名表:指定是否重命名复制的表。
- 放弃约束:选择是否放弃复制表的约束。
步骤 6:执行复制
单击“开始”按钮以执行复制过程。这可能需要一段时间,具体取决于数据库的大小和复制选项。
步骤 7:验证结果
复制完成,转到目标数据库并检查复制的对象。验证数据是否正确复制,并且约束是否按预期执行。
以上就是
今天关于如何在 MongoDB 中将集合从一个数据库复制到另一个数据库和mongodb拷贝集合命令的介绍到此结束,谢谢您的阅读,有关android – 如何快速地将表从一个数据库复制到另一个数据库、mysql 把一个数据库中的数据复制到另一个数据库中的表 2 个表结构相同、mysql把某一个数据库上的表的一些字段,复制到另一个数据库上的、navicat怎么将数据库复制到另一个数据库等更多相关知识的信息可以在本站进行查询。
在本文中,我们将详细介绍如何使用 POST 使用 NameValuePair 将参数添加到 HttpURLConnection的各个方面,并为您提供关于post请求可以把参数放在url里吗的相关解答,同时,我们也将为您带来关于Android HTTPUrlConnection POST、android – 如何使用NameValuePair使用POST向HttpURLConnection添加参数、Http - Do a POST with HttpURLConnection、HttpUrlConnection Get 和Post请求的有用知识。
本文目录一览:- 如何使用 POST 使用 NameValuePair 将参数添加到 HttpURLConnection(post请求可以把参数放在url里吗)
- Android HTTPUrlConnection POST
- android – 如何使用NameValuePair使用POST向HttpURLConnection添加参数
- Http - Do a POST with HttpURLConnection
- HttpUrlConnection Get 和Post请求
")
如何使用 POST 使用 NameValuePair 将参数添加到 HttpURLConnection(post请求可以把参数放在url里吗)
我正在尝试使用POST (HttpURLConnection我需要以这种方式使用它,不能使用HttpPost)并且我想向该连接添加参数,例如
post.setEntity(new UrlEncodedFormEntity(nvp));在哪里
nvp = new ArrayList<NameValuePair>();存储了一些数据。我找不到如何将其添加ArrayList到我的HttpURLConnection方法,这里是:
HttpsURLConnection https = (HttpsURLConnection) url.openConnection();https.setHostnameVerifier(DO_NOT_VERIFY);http = https;http.setRequestMethod("POST");http.setDoInput(true);http.setDoOutput(true);尴尬的 https 和 http 组合的原因是不需要 验证 证书。不过,这不是问题,它可以很好地发布服务器。但我需要它来发表论据。
有任何想法吗?
重复免责声明:
早在 2012 年,我不知道参数是如何插入到 HTTP POST
请求中的。我一直在坚持,NameValuePair因为它在教程中。
答案1
小编典典您可以获取连接的输出流并将参数查询字符串写入其中。
URL url = new URL("http://yoururl.com");HttpsURLConnection conn = (HttpsURLConnection) url.openConnection();conn.setReadTimeout(10000);conn.setConnectTimeout(15000);conn.setRequestMethod("POST");conn.setDoInput(true);conn.setDoOutput(true);List<NameValuePair> params = new ArrayList<NameValuePair>();params.add(new BasicNameValuePair("firstParam", paramValue1));params.add(new BasicNameValuePair("secondParam", paramValue2));params.add(new BasicNameValuePair("thirdParam", paramValue3));OutputStream os = conn.getOutputStream();BufferedWriter writer = new BufferedWriter( new OutputStreamWriter(os, "UTF-8"));writer.write(getQuery(params));writer.flush();writer.close();os.close();conn.connect();…
private String getQuery(List<NameValuePair> params) throws UnsupportedEncodingException{ StringBuilder result = new StringBuilder(); boolean first = true; for (NameValuePair pair : params) { if (first) first = false; else result.append("&"); result.append(URLEncoder.encode(pair.getName(), "UTF-8")); result.append("="); result.append(URLEncoder.encode(pair.getValue(), "UTF-8")); } return result.toString();}
Android HTTPUrlConnection POST
我正在使用HttpURLConnection通过POST将数据发送到服务器.我设置头,然后获取输出流并写入5个字节的数据(“ M = 005”),然后关闭输出流.
在服务器上,我收到了所有标头,正确的内容长度,但是随后得到的长度为零,并且服务器挂在readLine上.
似乎发生的事情是客户端关闭实际上从未发生,因此不会写入整个数据,因此服务器永远不会获得它.
我已经阅读了许多示例,并尝试了各种更改,以查看我是否可以以任何方式实现此目标,而效果均不理想.例如,关闭保持活动状态,然后在数据末尾强制执行CRLF(这会迫使我的数据在服务器端发出,但连接仍无法关闭.(仅用于测试),尝试使用打印写程序.
由于很多示例都在执行我的操作,因此我认为这很简单,但是我看不到它.任何帮助,将不胜感激.
StringBuilder postDataBuilder.append("M=").append(URLEncoder.encode("005", UTF8));
byte[] postData = null;
postData = postDataBuilder.toString().getBytes();
url = new URL("http://" + serverAddress + ":" + String.valueOf(serverPort));
conn = (HttpURLConnection) url.openConnection();
conn.setDoOutput(true);
conn.setRequestMethod("POST");
conn.setRequestProperty("Content-Length", Integer.toString(postData.length));
conn.setUseCaches(false);
OutputStream out = conn.getoutputStream();
out.write(postData);
out.close();
int responseCode = conn.getResponseCode();
// After executing the above line the server starts to successfully readLines
// until it gets to the post data when the server hangs. If I restart the
// client side then the data finally gets through but the connection on the
// server side never ends.
解决方法:
哎呀我们服务器端的错误是执行readLine而不是字符读取.由于没有CRLF,它将挂起.

android – 如何使用NameValuePair使用POST向HttpURLConnection添加参数
我正在尝试使用HttpURLConnection进行POST(我需要以这种方式使用它,不能使用HttpPost)并且我想将参数添加到该连接中,例如
post.setEntity(new UrlEncodedFormEntity(nvp));
哪里
nvp = new ArrayList<NameValuePair>();
有一些数据存储在.我找不到如何将这个ArrayList添加到我的HttpURLConnection的方法,这是在这里:
HttpsURLConnection https = (HttpsURLConnection) url.openConnection();
https.setHostnameVerifier(DO_NOT_VERIFY);
http = https;
http.setRequestMethod("POST");
http.setDoInput(true);
http.setDoOutput(true);
这种尴尬的https和http组合的原因是不需要验证证书.但这不是问题,它可以很好地发布服务器.但是我需要用论据发帖.
有任何想法吗?
重复免责声明:
回到2012年,我不知道如何将参数插入到HTTP POST请求中.我在NameValuePair上,因为它是在教程中.这个问题可能看似重复,但是,我的2012年自己阅读了other问题并且它没有使用NameValuePair.事实上,它并没有解决我的问题.
解决方法:
您可以获取连接的输出流并将参数查询字符串写入其中.
URL url = new URL("http://yoururl.com");
HttpsURLConnection conn = (HttpsURLConnection) url.openConnection();
conn.setReadTimeout(10000);
conn.setConnectTimeout(15000);
conn.setRequestMethod("POST");
conn.setDoInput(true);
conn.setDoOutput(true);
List<NameValuePair> params = new ArrayList<NameValuePair>();
params.add(new BasicNameValuePair("firstParam", paramValue1));
params.add(new BasicNameValuePair("secondParam", paramValue2));
params.add(new BasicNameValuePair("thirdParam", paramValue3));
OutputStream os = conn.getoutputStream();
BufferedWriter writer = new BufferedWriter(
new OutputStreamWriter(os, "UTF-8"));
writer.write(getQuery(params));
writer.flush();
writer.close();
os.close();
conn.connect();
…
private String getQuery(List<NameValuePair> params) throws UnsupportedEncodingException
{
StringBuilder result = new StringBuilder();
boolean first = true;
for (NameValuePair pair : params)
{
if (first)
first = false;
else
result.append("&");
result.append(URLEncoder.encode(pair.getName(), "UTF-8"));
result.append("=");
result.append(URLEncoder.encode(pair.getValue(), "UTF-8"));
}
return result.toString();
}

Http - Do a POST with HttpURLConnection
In a GET request, the parameters are sent as part of the URL.
In a POST request, the parameters are sent as a body of the request, after the headers.
To do a POST with HttpURLConnection, you need to write the parameters to the connection after you have opened the connection.
This code should get you started:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.Reader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
import java.util.LinkedHashMap;
import java.util.Map;
public class Test {
public static void main(String[] args) throws Exception {
URL url = new URL("http://example.net/new-message.php");
Map<String, Object> params = new LinkedHashMap<>();
params.put("name", "Freddie the Fish");
params.put("email", "fishie@seamail.example.com");
params.put("reply_to_thread", 10394);
params.put("message",
"Shark attacks in Botany Bay have gotten out of control. We need more defensive dolphins to protect the schools here, but Mayor Porpoise is too busy stuffing his snout with lobsters. He''s so shellfish.");
StringBuilder postData = new StringBuilder();
for (Map.Entry<String, Object> param : params.entrySet()) {
if (postData.length() != 0)
postData.append(''&'');
postData.append(URLEncoder.encode(param.getKey(), "UTF-8"));
postData.append(''='');
postData.append(URLEncoder.encode(String.valueOf(param.getValue()), "UTF-8"));
}
byte[] postDataBytes = postData.toString().getBytes("UTF-8");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
conn.setRequestProperty("Content-Length", String.valueOf(postDataBytes.length));
conn.setDoOutput(true);
conn.getOutputStream().write(postDataBytes);
Reader in = new BufferedReader(new InputStreamReader(conn.getInputStream(), "UTF-8"));
for (int c; (c = in.read()) >= 0;)
System.out.print((char) c);
}
}If you want the result as a String instead of directly printed out do:
StringBuilder sb = new StringBuilder();
for (int c; (c = in.read()) >= 0;)
sb.append((char)c);
String response = sb.toString();
参考:
http://stackoverflow.com/questions/4205980/java-sending-http-parameters-via-post-method-easily
http://hgoebl.github.io/DavidWebb/

HttpUrlConnection Get 和Post请求
package com.example.demo;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.NameValuePair;
import org.apache.http.message.BasicNameValuePair;
import android.text.TextUtils;
public class UrlConnManager {
/**
* Get 请求
* @param path
* @return
*/
public static String getDataByGet(String path){
try {
URL url = new URL(path.trim());
//打开连接
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
//设置链接超时时间
urlConnection.setConnectTimeout(15000);
//设置读取超时时间
urlConnection.setReadTimeout(15000);
if(200 == urlConnection.getResponseCode()){
//得到输入流
InputStream is =urlConnection.getInputStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = 0;
while(-1 != (len = is.read(buffer))){
baos.write(buffer,0,len);
baos.flush();
}
return baos.toString("utf-8");
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* Post 请求 (参数以&连接)
* @param url
*/
public static String getDataByPost(String url) {
String result = null;
InputStream mInputStream = null;
HttpURLConnection mHttpURLConnection = UrlConnManager.getHttpURLConnection(url);
try {
List<NameValuePair> postParams = new ArrayList<>();
//要传递的参数
postParams.add(new BasicNameValuePair("username", "moon"));
postParams.add(new BasicNameValuePair("password", "123"));
UrlConnManager.postParams(mHttpURLConnection.getOutputStream(), postParams);
mHttpURLConnection.connect();
mInputStream = mHttpURLConnection.getInputStream();
int code = mHttpURLConnection.getResponseCode();
result = converStreamToString(mInputStream);
mInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
/**
* Post 请求 (参数为json字符串)
* @param url
*/
public static String getDataByPost(String url,String json) {
String result = null;
try {
URL mUrl = new URL(url);
HttpURLConnection conn = (HttpURLConnection) mUrl.openConnection();
conn.setRequestMethod("POST");// 提交模式
//是否允许输入输出
conn.setDoInput(true);
conn.setDoOutput(true);
//设置请求头里面的数据,以下设置用于解决http请求code415的问题
conn.setRequestProperty("Content-Type","application/json"); //设置json格式
//链接地址
conn.connect();
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
//发送参数
writer.write(json);
//清理当前编辑器的左右缓冲区,并使缓冲区数据写入基础流
writer.flush();
BufferedReader reader = new BufferedReader(new InputStreamReader(
conn.getInputStream()));
result =reader.readLine();//读取请求结果
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
public static void postParams(OutputStream output,List<NameValuePair>paramsList) throws IOException{
StringBuilder mStringBuilder=new StringBuilder();
for (NameValuePair pair:paramsList){
if(!TextUtils.isEmpty(mStringBuilder)){
mStringBuilder.append("&");
}
mStringBuilder.append(URLEncoder.encode(pair.getName(),"UTF-8"));
mStringBuilder.append("=");
mStringBuilder.append(URLEncoder.encode(pair.getValue(),"UTF-8"));
}
BufferedWriter writer=new BufferedWriter(new OutputStreamWriter(output,"UTF-8"));
writer.write(mStringBuilder.toString());
writer.flush();
writer.close();
}
public static HttpURLConnection getHttpURLConnection(String url){
HttpURLConnection mHttpURLConnection=null;
try {
URL mUrl=new URL(url);
mHttpURLConnection=(HttpURLConnection)mUrl.openConnection();
//设置链接超时时间
mHttpURLConnection.setConnectTimeout(15000);
//设置读取超时时间
mHttpURLConnection.setReadTimeout(15000);
//设置请求参数
mHttpURLConnection.setRequestMethod("POST");
//添加Header
mHttpURLConnection.setRequestProperty("Connection","Keep-Alive");
//接收输入流
mHttpURLConnection.setDoInput(true);
//传递参数时需要开启
mHttpURLConnection.setDoOutput(true);
} catch (IOException e) {
e.printStackTrace();
}
return mHttpURLConnection ;
}
private static String converStreamToString(InputStream is) {
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
StringBuilder sb = new StringBuilder();
String line = null;
try {
while ((line = reader.readLine()) != null) {
sb.append(line + "/n");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return sb.toString();
}
}
今天关于如何使用 POST 使用 NameValuePair 将参数添加到 HttpURLConnection和post请求可以把参数放在url里吗的介绍到此结束,谢谢您的阅读,有关Android HTTPUrlConnection POST、android – 如何使用NameValuePair使用POST向HttpURLConnection添加参数、Http - Do a POST with HttpURLConnection、HttpUrlConnection Get 和Post请求等更多相关知识的信息可以在本站进行查询。
在本文中,我们将给您介绍关于Perl、Python、AWK 和 sed 有什么区别?的详细内容,并且为您解答sed grep awk区别的相关问题,此外,我们还将为您提供关于Java、JavaScript、C、C++、PHP、Python有什么区别?、Linux 系统中 awk 和 sed 有什么区别?、Perl,Python,AWK和sed之间有什么区别?、Perl、PHP、Python、Java 和 Ruby 比较【转载+整理】的知识。
本文目录一览:- Perl、Python、AWK 和 sed 有什么区别?(sed grep awk区别)
- Java、JavaScript、C、C++、PHP、Python有什么区别?
- Linux 系统中 awk 和 sed 有什么区别?
- Perl,Python,AWK和sed之间有什么区别?
- Perl、PHP、Python、Java 和 Ruby 比较【转载+整理】
")
Perl、Python、AWK 和 sed 有什么区别?(sed grep awk区别)
它们之间的主要区别是什么?在哪些典型场景中使用每种语言更好?
答案1
小编典典按出现顺序,语言是sed, awk, perl, python.
该sed程序是一个流编辑器,旨在将脚本中的操作应用于输入文件的每一行(或更一般地说,应用于指定的行范围)。它的语言基于edUnix
编辑器,虽然它有条件等,但很难用于复杂的任务。你可以用它创造小奇迹——但要付出你头上的头发的代价。但是,在尝试其职权范围内的任务时,它可能是最快的程序。(它具有讨论的程序中最不强大的正则表达式
- 适用于许多目的,但肯定不是 PCRE - Perl-Compatible Regular Expressions)
该awk程序(名称来自其作者的首字母 - Aho、Weinberger 和
Kernighan)最初是用于格式化报告的工具。它可以用作增强剂sed;在其最新版本中,它在计算上是完整的。它使用了一个有趣的想法——该程序基于“模式匹配”和“模式匹配时采取的操作”。这些模式相当强大(扩展正则表达式)。动作的语言类似于
C。其主要特点之一awk是它自动将输入拆分为记录,并将每条记录拆分为字段。
Perl 部分是作为 awk-killer 和 sed-killer
编写的。它提供的两个程序是a2p和s2p用于将awk脚本和sed脚本转换为 Perl。Perl 是最早的下一代脚本语言之一(Tcl/Tk
可能占据主导地位)。它具有强大的集成正则表达式处理和更强大的语言。它提供对几乎所有系统调用的访问,并具有 CPAN
模块的可扩展性。(两者都awk不可sed扩展。)Perl 的座右铭之一是“TMTOWTDI - 有不止一种方法可以做到”(发音为“tim-
toady”)。Perl 有“对象”,但它更像是一个附加组件,而不是语言的基本部分。
Python 是最后编写的,可能部分是对 Perl 的反应。它有一些有趣的句法思想(缩进表示级别 - 没有大括号或等价物)。它比 Perl
更基本面向对象;它和 Perl 一样可扩展。
好的 - 什么时候使用每个?
- Sed - 当您需要对文件进行简单的文本转换时。
- awk - 当您只需要简单的格式化和汇总或数据转换时。
- Perl - 几乎适用于任何任务,尤其是当任务需要复杂的正则表达式时。
- Python - 用于您可以使用 Perl 的相同任务。
我不知道 Perl 可以做 Python 做不到的任何事情,反之亦然。两者之间的选择将取决于其他因素。我在 Python 出现之前就学习了
Perl,所以我倾向于使用它。Python 具有较少的附加语法,并且通常更易于学习。Perl 6,当它可用时,将是一个引人入胜的发展。
(请注意,Perl 和 Python 的“概述”尤其是非常不完整;整本书都可以写在这个主题上。)

Java、JavaScript、C、C++、PHP、Python有什么区别?
用任何编程语言来开发程序,都是为了让计算机干活,比如编写一篇文章,下载一首MP3等,而计算机干活的CPU只认识机器的指令;
所以,尽管不同的编程语言差异极大,最后都得“翻译”成CPU可以执行的机器指令。理论上任何语言干任何事情几乎都可以, 但是主要干什么那就不一样了。
今天大雄就来给大家说下面这几门语言都是干什么的?
01 C和C++
C/C++理论上说可以做任何开发, 只要有合适的硬件驱动和API,特点是效率高,基本上是编译语言里面效率最高的。
除非系统中连C/C++编译器都不具备.,某些系统C++编译器是不具备的, 但是C一般都具备。
目前而言, C语言主要用来开发底层模块(比如驱动,解码器,算法实现), 服务应用(比如web服务器)和嵌入式应用(比如微波炉里的程序).。


C++也可以做这些, 不过由于C++的复杂性和标准问题, 大家普遍还是更愿意使用C来做。
C++更适合比较复杂但又特别需要高效率的设施,比如大型游戏,一些基础库, 大型桌面应用。
用途:
C:系统底层, 驱动, 嵌入式开发
C++: 游戏开发, 大规模, 高性能, 分布式要求的程序开发。
02 Java
Java常常跟”企业”联系在一起, 因为具备一些很好的语言特性, 以及丰富的框架。在企业应用中最被青睐。
同时, Java在手机领域也有一席之地, 在普遍智能化之前, 很多手机就是以支持Java应用作为卖点的, 而智能手机爆发之后, Java手机主场变成了android, 作为安卓的标准编程语言而存在。

用途:
Java用于网页, 企业级开发, 普通应用软件, 游戏后台。
03 JavaScript
Javascript听起来好像跟Java有关系, 其实并没有任何关系, 只是名字像而已。就好比雷峰塔和雷锋的关系一样,虽然只差一个字。
Js最广泛的应用毫无疑问是在web前端。
简单的说, 网站传过来的是一堆用各种标签表示格式的文档, 而Js负责操纵这些文档实现一些客户端动态效果.。
Js的领地还不仅如此, 现在的Node.js还可以用于服务器端的开发。

用途:
JavaScript是浏览器的脚本语言,一般和Html,CSS这些一起学,主要做网站的前端开发,展现各种酷炫的画面。
04 PHP
PHP这三个字我们常常会在浏览器地址栏里看到, 所以不意外PHP是用来开发网站的,也是web后端的王者语言,无数的网站后端都运行着PHP代码。

用途:
PHP:主要是网络前端,用于生成网页。也可以整个web服务器都用PHP,比如很多论坛引擎。
05 Python
Python由于具有丰富和强大的库,它又叫做胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。

常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写;
比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。
用途:
Python是做服务器开发与物联网开发。信息安全,大数据处理,数据可视化机器学习,物联网开发,各大软件的api,桌面应用,都需要python。
Python:动态解释型,开发效率高,开源,灵活,入门门槛低。
怎么样?现在这几门语言的区别,以及他们分别都是用来干什么的,小伙伴们应该都有所了解了吧。
小伙伴对哪门语言最感兴趣呢?欢迎大家和我一起来讨论哦

Linux 系统中 awk 和 sed 有什么区别?
Linux 文本三剑客,即 awk、grep、sed,这三个命令是 Linux 中常用的文本处理命令,主要作用是对文本内容做查看、修改等操作,那么 Linux 系统中 awk 和 sed 有什么区别?相信很多人都比较好奇,小编通过这篇文章为大家介绍一下。
Linux sed 命令是利用脚本来处理文本文件。sed 可依照脚本的指令来处理、编辑文本文件。sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
Linux awk 命令是一种处理文本文件的语言,是一个强大的文本分析工具。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho、Peter Weinberger 和 Brian Kernighan 的 Family Name 的首字符。
主要区别如下:
1、sed 是一种非交互式且面向字符流的编辑器,awk 则是一门模式匹配的编程语言,因为它的主要功能是用于匹配文本并处理,同时它有一些编程语言才有的语法,例如函数、分支循环语句、变量等等,当然比起我们常见的编程语言,AWK 相对比较简单。
2、sed 一般对行进行操作,awk 对列进行操作。
3、sed 擅长数据修改,awk 擅长数据切片,数据格式化,功能最复杂。
4、sed 全称 Stream Editor,擅长对文件做数据做修改的操作,非常高效。
5、awk 更适合格式化文本,对文本进行较复杂格式处理,awk 程序对输入文件的每一行进行操作;awk 是一门解释型的编程语言,文本处理、输出格式化的文本报表、执行算数运算、执行字符串操作等等。

Perl,Python,AWK和sed之间有什么区别?
编辑:它不是“对”喜欢的主题,只是信息。
解决方法
sed程序是流编辑器,并且被设计为将来自脚本的动作应用于输入文件的每一行(或者更一般地,应用于指定的行范围)。它的语言基于ed,Unix编辑器,虽然它有条件等,但是很难与复杂的任务一起工作。你可以与它工作小奇迹 – 但是在你头上的头发成本。但是,它可能是在其职权范围内尝试任务时最快的程序。 (它具有所讨论的程序中最不强大的正则表达式 – 适用于许多目的,但肯定不是PCRE – Perl兼容的正则表达式)
awk程序(来自作者的首字母缩写的名字–Aho,Weinberger和Kernighan)是最初用于格式化报告的工具。它可以用作汤羹;在其更新的版本中,它是计算完成的。它使用一个有趣的想法 – 程序是基于“模式匹配”和“模式匹配时采取的行动”。模式是相当强大的(扩展正则表达式)。操作的语言类似于C. awk的一个关键功能是将输入行自动分割为字段。
Perl被部分地写成awk-killer和sed-killer。提供的两个程序是a2p和s2p,用于将awk脚本和sed脚本转换为Perl。 Perl是下一代脚本语言中最早的一种(Tcl / Tk可能声称优先)。它具有强大的集成正则表达式处理与更强大的语言。它提供对几乎所有系统调用的访问,并且具有CPAN模块的可扩展性。 (awk和sed都不可扩展。)Perl的座右铭之一是“TMTOWTDI – 有多种方法”(发音为“tim-toady”)。 Perl有“对象”,但它更多是一个附加组件,而不是语言的基本部分。
Python是最后写的,可能部分作为对Perl的反应。它有一些有趣的句法思想(缩进表示水平 – 没有大括号或等同)。它比Perl更基本的面向对象;它就像Perl一样可扩展。
确定 – 何时使用每个?
> sed – 当你需要对文件进行简单的文本转换。
> awk – 当你只需要简单的格式化和汇总或转换数据。
> perl – 几乎任何任务,但特别是当任务需要复杂的正则表达式时。
> python – 对于可以使用Perl的相同任务。
我不知道任何Perl可以做的Python不能,反之亦然。两者之间的选择将取决于其他因素。我学习了Perl之前有一个Python,所以我倾向于使用它。 Python有更少的accreted语法,通常有点更容易学习。 Perl 6,当它可用时,将是一个迷人的发展。
(请注意,特别是Perl和Python的“概述”是非常不完整的;整本书可以写在这个主题上。)

Perl、PHP、Python、Java 和 Ruby 比较【转载+整理】
从本文的内容上,写的时间比较早,而且有些术语我认为也不太准,有点口语化,但是意思到了。 问题: Perl、Python、Ruby 和 PHP 各自有何特点? 为什么动态语言多作为轻量级的解决方案? LAMP 为什么受欢迎? Ruby on Rails 为什么会流行? 编程语言的发展趋
从本文的内容上,写的时间比较早,而且有些术语我认为也不太准,有点口语化,但是意思到了。
问题:
-
Perl、Python、Ruby 和 PHP 各自有何特点?
-
为什么动态语言多作为轻量级的解决方案?
-
LAMP 为什么受欢迎?
-
Ruby on Rails 为什么会流行?
立即学习“PHP免费学习笔记(深入)”;
-
编程语言的发展趋势是什么?
“剩下四种动态语言,我们将之归为后台脚本语言。”冒号说着,画了张图表——

引号听得仔细,说:“我记得你之前把这些语言划分为 C 族静态语言、非 C 族静态语言和动态语言三类的。”
冒号解释:“那是按语法来划分的,偏重理论;现在是按应用来划分,偏重实践。”
句号立刻联想到:“这种分法貌似三层架构——前台语言对应表现层;平台语言和后台脚本语言对应业务逻辑层;系统语言对应数据层。”
“的确有几分神似,但千万不能混淆。”冒号提醒道,“三层架构是模块设计上的逻辑划分;而这里是按语言应用范围进行的物理划分——与用户交互的是前台语言,与机器交互的是系统语言,介于其中的为前台提供服务同时又需要底层系统服务的是后台语言。”
逗号,询问:“后台语言,又细分成平台语言与后台脚本语言?”
“这是基于程序与脚本、静态与动态而分的。”冒号说明,“其实 Perl,PHP,Python 和 Ruby 都有自己的虚拟机,从这种意义上,它们也可作为平台语言。但在实际应用中,它们没有 Java 平台和 .NET 平台那种整合凝聚力和核心作用,通常作为轻量级的解决方案。”
问号,想探个究竟:“这是由于它们都是动态语言的缘故吗?”
冒号,回答:“理论上动态语言同样能承担大型应用,但实践上它们多作为“胶水”语言或用于中小型应用。用句时髦的话来形容,暂时还是主流的配角或非主流的主角。毕竟在运行效率、类型安全、可用资源、开发工具、技术支持等方面,与 Java、C# 相比尚有一定差距。另外它们同属‘草根’语言,虽有开源社区的大力支持,在影响力上与后者不可同日而语。”
叹号,揣测:“说不定,在不久将来,动态语言也会成为主流的。”
“世易时移,殊难逆料。但有一点可以肯定,语言的发展趋势一定是动静结合、刚柔并济。”冒号断言,“一方面,以 Java 和 C# 为代表的静态语言中嫁接了动态语言的枝条;另一方面,以 Java 和 .NET 为代表的平台与动态语言的交壤地带也在逐步扩大。比如,JRuby 允许 Ruby 与 Java 之间互相调用,还有 Jython、IronRuby、IronPython 等。值得一提的是,动态语言最活跃的舞台当数 LAMP,L-A-M-P。”
引号,接过话茬:“L 是 Linux,A 是 Apache,M 是 MySQL,P 是 PHP。这四大组件形成了一个完整的开源网络开发平台。”
冒号,补充道:“P 也可指 Perl、Python,甚至 Ruby。”
逗号,调侃:“可惜 Ruby 的‘R’比‘P’多了一根尾巴。”
“有人为了自圆其说,干脆让 P 表示‘Programming language’,这下所有语言都囊括其中了。老外就喜欢玩这种首字母缩写的文字游戏,尤其是 LAMP 正好还有‘灯’的含义,寓意开源世界是一盏明灯,他们一定更得意了。”冒号边说边笑道,“前面我们曾提及,网络应用是生长动态语言最肥沃的土壤,而 LAMP 就是这块土壤上搭建的平台。作为网络平台,LAMP 以其开放灵活、开发迅速、部署方便、高可配置、安全可靠、成本低廉等优势而与 Java 平台和 .NET 平台三足鼎立,特别受中小企业的欢迎。LAMP 中,Linux 是操作系统,Apache 是 Web 服务器,MySQL 是数据库系统,而我们当下最关心的是‘P 族语言’:PHP、Perl、Python 还有 Ruby。”
问号,建议:“作为动态语言,它们的共性上面已经谈了不少,能说说它们的个性吗?”
“它们的个性极为鲜明:Perl 凝练晦涩,Python 优雅明晰,Ruby 精巧灵动,PHP 简明单纯。先看老大哥 Perl,它博采众家之长,综合了 C 语言的结构、sed 的正则表达式、AWK 的关联数组(associative array)、Lisp 的表(list)和 Unix Shell 的命令,此外,它还借鉴了一种语言,你们知道是哪种吗?”冒号忽然卖起了个关子。
逗号,猜想:“应该是某种 OOP 语言吧。”
“Perl 中确有不少 C++ 的影子,但它的对象模型在 5.0 以后才引入,典型的半路出家,远不如前面的特征那么自然。与其说是一种自然而然的发展,不如说是在 OOP 潮流裹挟下的一种身不由己的迎合。真正深入骨髓的借鉴是自然语言。”冒号,给出了答案,“我们提过,Perl 发明者 Larry Wall 是一名语言学家,他认为程序语言应该与自然语言一样,简洁自然、易读易写、表达多样、不拘一格。Perl 还有不少的格言或哲学,使得编程语言一改严谨刻板的面孔,散发出浓郁的人文气息。”
叹号幽了一默:“我见过 Perl 代码,人文气息没闻出来,但我怀疑有乙醚气息——看一会就觉得晕晕乎乎的。”
众人大笑……
“有人仅用一行 Perl 代码就实现了 RSA 算法,你看了那还不得当场晕倒啊?”冒号打趣道,“Perl 各种魔符好似一把锋利的剪刀,做起文本裁剪之类的工作游刃有余。这是它最大的长处,当初 Perl 就是 Wall 用来做 Unix 系统管理的,以后在 CGI 上的广泛应用也得益于此。这也赋予 Perl 极强的粘合力,因而有‘internet上的胶带(duct tape)’的说法。它又号称瑞士军刀,精练而复杂,实用而强大。但Perl过于灵活自由,缺乏规范,影响了程序的可读性、一致性、整洁性和可维护性。不熟悉该语言的固然如读天书,熟悉语言而不熟悉问题的也颇费思量。相比之下,Python 被认为是 Perl 有力的挑战者,不仅在于它天然的 OO 设计和丰富的类库,更重要的是它的友好度大大超过 Perl。Python 也有一系列的被称为禅(Zen)的哲学,不少与 Perl 针锋相对。比如,Perl 认为做一件事可以有多种方法,而 Python 认为一件事应该最好只有一种方法;Perl 追求语言的表现力,Python 追求简单优雅;Perl 喜欢隐性暗示,Python 强调显性明示;Perl 强调紧凑,Python 强调松散;Perl 语法和语义丰富,Python 语法和语义简单,类库丰富。或许 Python 最让人不习惯的是它对空白符敏感性。”
引号,感到惊奇:“对空白符敏感?这个倒真怪异。”
冒号,见怪不怪:“虽然有点违反习惯,但非常符合 Python 一贯的规范简洁的风格——一方面,从语法上,保证了良好的编码风格;另一方面,每个代码块不再需要起始的大括号或 begin/end 之类,减少了的代码行数。顺便提一句,另外一种优雅的语言 Haskell 同样对空白符敏感,或许优雅正是来自对细节和规范的重视吧。此外,许多人抱怨 Python 中的自引用 self 太多,殊不知这也是它倡导显式表达的一种体现。总的看来,Python 主要的问题还是在性能效率上不尽如人意。”
叹号,好奇地问:“Ruby 怎么样?据说它将取代 Java。”
“不要轻言‘取代’二字。”冒号说道,“Java 没有取代 C++,也不会被 Ruby 取代,顶多是再分配。不过 Ruby 的确是门很可爱的语言,兼具 Perl 的表现力和 Python 的可读性。Ruby 背后最具特色的理念是:关注程序员使用语言时的感受超过语言本身的功能。通俗地说,上手的兵器比锋利更重要;文雅地说,应给予程序员更多的人文关怀。拿代码块(block)和迭代器(iterator)来说,虽然这不是 Ruby 首创,但其语法最为赏心悦目。Ruby 元编程能力特别强,也是它高度灵活的一种体现,但并不是所有人都喜欢这种风格。Ruby 主要弱点有两个:一个与 Python 类似,在性能上还有待提高;另一个是它的线程由用户空间(user space),而不是内核空间(kernel space)来管理,不能充分利用多核或多 CPU。真正让 Ruby 变得炙手可热的是 Web 应用框架 Ruby on Rails(RoR)的成功,它们还催生了 Java 平台上的 Groovy 语言和 Groovy on Grails 框架。RoR 奉行的 CoC(Convention over Configuration)和 DRY(Don’t repeat yourself )原则以及 MVC 架构看似了无新意,但与 Ruby 结合之后,便如一只猱身而上灵猫,立刻衬托出 Java 和 .NET 大象般的身影。”
逗号,有些怀疑:“框架竟然捧红了语言,框架真有这么重要吗?”
“如果 Web 应用中动态页面较少或业务逻辑不复杂,框架的价值并不大。以前 CGI 编程就是往 Perl 之类的代码中嵌入HTML代码,如同 Java 中的 Servlet;PHP 则单纯地在 HTML 代码中插入 PHP 代码,如同早期的 JSP。没有 MVC,也不管什么三层架构,更没有 ORM。但是——”冒号拖了个转折音,“一旦业务逻辑变得复杂,开发人员增多,手工作坊式编程开始捉襟见肘,引入框架这个流水生产线来提高生产力便是大势所趋。”
句号,不解:“我想 Perl、Python 和 PHP 一定也有不少框架,Java中的框架更是泛滥成灾,何以独独 RoR 脱颖而出?”
冒号,分析道:“正值 Web 2.0 和敏捷开发的概念流行之际,RoR 将 AJAX 与 Ruby 组合在一起成为绝佳的回应。以前各种 Web 应用框架是不少,但在 RoR 之前轻量级套餐式解决方案并不多。Perl 中 Catalyst、Python 中 Pylon,还有 PHP 中 CakePHP 等应是效仿之作。因此,RoR 出现的时机可说正当其时。此外,Perl 和 PHP 由于过于流行,反而有不少的历史包袱,人们习惯了将表示逻辑和业务逻辑编织在一起。至于 Java 企业解决方案,框架太多,搭配组合更多,增加了选择的难度。即使采用最常见的轻量级 SSH(Struts+Spring+Hibernate)组合,维护起来也比 RoR 繁杂得多。”
叹号,愈发担忧:“听这意思,Java 还是危险啊!”
“言之过早。”冒号不以为然,“首先,RoR 还有待进一步检验,目前无论是应用广度还是深度上尚无法与 Java 相提并论;其次,Java 在性能、安全等方面还是有不少优势,而这些对于大型和关键性的应用来说尤为重要。即使在中小型 Web 应用中,RoR 较之 PHP 还远为不及。”
问号接下话题:“PHP为何如此流行?”
“因为它简单、专一。”冒号答得很干脆,“与 Python 和 Ruby 一开始就定位通用语言不同,PHP 是专为网络而生的。同早期的 Perl 相似,PHP 起初主要起文本过滤器的作用,只不过 Perl 多处理文件流,而 PHP 多处理套接字流。PHP 语法简单,为网络应用度身定造,受到网络开发人员的追捧当在情理之中。它虽很实用很流行,但并不完美。比如,变量名大小写敏感,而函数名大小写不敏感;函数命名规则不一致;不支持 namespace 和 unicode;与 Perl 一样,它的对象模型不是先天的,直到 PHP 5 才真正完善;对线程支持不足;相比 Perl、Python 和 Ruby,它的功能稍显单薄等等。”
引号,突然想起:“我记得你以前提到,PHP 还能用于桌面应用。”
“不仅 PHP,Perl、Python 还有 Ruby,都能作为前台语言来开发命令行或图形界面的应用。同样地,VB、Delphi 和 JavaScript 也能作为后台语言。现代的程序语言既有自己的专长,又向通用化和全能化发展,以争取更多的生存空间。试想一下,现代的程序员又何尝不是如此呢?”言及于此,冒号收住话题,“语言简评告一段落,还有不少既有趣又有用的语言,在此就不一一评说了。我们看到,每种编程语言都有其独特的惯例用法和哲学理念,它们与编程范式一道形成了语言的编程风格。体悟愈深者编程语感愈强,思维与语言愈交融无碍,渐从必然王国走向自由王国。”
逗号,满怀憧憬:“那是不是一种人剑合一的境界?”
“或许人器合一更准确吧,程序员可不能只会一种兵器哟。”冒号故意抠他的字眼,“现在请大家每人写一句对本节课的感言。”
众人沉思片刻,齐齐挥笔而就——
- 叹号——没有最好的语言,只有最合适的语言。
- 逗号——没有糟糕的语言,只有糟糕的程序员。
- 问号——没有一种语言是万能的,只会一种语言是万万不能的。
- 引号——废除对语言的宗教信仰,建立对语言的哲学思维。
- 句号——编程就是在人脑和电脑之间寻找最佳平衡点的过程。
冒号读罢大悦,顺手一掌拍出五记马屁:“精彩之极!可谓字字珠玑、句句联璧啊。兹决定,给诸位的奖赏是——立时下课!”
众人欣然领赏而去。
总结
- 比起 Java 平台和 .NET 平台,动态语言轻便灵活、开发效率高,但整合凝聚力不够,在运行效率、类型安全、可用资源、开发工具、技术支持以及影响力等方面也有一定差距,故通常作为轻量级的解决方案。
- LAMP 是由 Linux、Apache、MySQL 和包括 PHP、Perl、Python 或 Ruby 在内的脚本语言组成的网络开发平台,具有开放灵活、开发迅速、部署方便、高可配置、安全可靠、成本低廉等优点。
- Perl 精练、复杂、强大、灵活、自由、隐晦、表现力强,但规范性、可读性、一致性、整洁性和可维护性较差。
- Python 优雅规范、简洁明晰、易学易用、类库丰富,但效率稍差,有些人不喜欢它对空白符敏感的特性。
- Ruby 语法精巧、高度灵活,兼具 Perl 的表现力和 Python 的可读性,尤其注重程序员的感受,但其性能和线程模型尚有待改进。
- PHP 简单、专一、实用、流行,在但相比其他三种语言,在语法和功能上稍有欠缺。
- RoR 是一种轻量级套餐式的web应用解决方案,是由好的设计(MVC架构和CoC、DRY原则)加上好的语言(Ruby)在好的时机(Web2.0和敏捷开发风行之际)打造出的好的框架。
- 静态语言与动态语言从语言特征到运行环境都在逐渐融合。
- 程序员应该与程序语言一样,既要有自己的专长,又要向通用化和全能化发展。
- 编程语言惯例用法、哲学理念和编程范式形成了语言的编程风格。
今天关于Perl、Python、AWK 和 sed 有什么区别?和sed grep awk区别的讲解已经结束,谢谢您的阅读,如果想了解更多关于Java、JavaScript、C、C++、PHP、Python有什么区别?、Linux 系统中 awk 和 sed 有什么区别?、Perl,Python,AWK和sed之间有什么区别?、Perl、PHP、Python、Java 和 Ruby 比较【转载+整理】的相关知识,请在本站搜索。
关于JsonObjectRequest 发送空参数和http发送json数据的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于Android - 在 JsonObjectRequest 之后移动到主线程、android volley JsonObjectRequest,它只返回200个正文、Android Volley JsonObjectRequest每次都会在移动数据上返回相同的响应、Android Volley POST JsonObject并获取JsonArray或JsonObject或其他响应等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- JsonObjectRequest 发送空参数(http发送json数据)
- Android - 在 JsonObjectRequest 之后移动到主线程
- android volley JsonObjectRequest,它只返回200个正文
- Android Volley JsonObjectRequest每次都会在移动数据上返回相同的响应
- Android Volley POST JsonObject并获取JsonArray或JsonObject或其他响应
")
JsonObjectRequest 发送空参数(http发送json数据)
我正在尝试将带有 json 参数的请求发送到我的节点后端。这是Android中的功能:
public boolean checkUser(String user, String passw) { final String url = "http://10.0.2.2:3000/"; final String get = "auth"; JSONObject paramJson = new JSONObject(); try { paramJson.put("user", "value1"); paramJson.put("pass", "value2"); } catch (JSONException e) { e.printStackTrace(); } Log.d("JSON", paramJson.toString()); JsonObjectRequest jsonObjectRequest = new JsonObjectRequest(Request.Method.GET,url + get, paramJson, response -> { Toast.makeText(getApplicationContext(), response.toString(), Toast.LENGTH_LONG); }, error -> { Toast.makeText(getApplicationContext(), error.toString(), Toast.LENGTH_LONG); }); queue.add(jsonObjectRequest); return false; }但是,当我尝试在后端获取 json 值时,我得到了一个空的正文。
app.get("/auth", async (req, res) => { let user = req.body.user; let pass = req.body.pass; console.log(req.body); if (!user || !pass) { res.status(500).send("Missing user or pass"); return; } ...}所以基本上我不知道如何访问数据,我尝试记录整个请求,但我找不到 json 字段或值。这里有什么帮助吗?
编辑:
我已经尝试了以下方法:
CustomRequest.java
package com.example.apptonia;import java.io.UnsupportedEncodingException;import java.util.Map;import org.json.JSONException;import org.json.JSONObject;import com.android.volley.NetworkResponse;import com.android.volley.ParseError;import com.android.volley.Request;import com.android.volley.Response;import com.android.volley.Response.ErrorListener;import com.android.volley.Response.Listener;import com.android.volley.toolbox.HttpHeaderParser;public class CustomRequest extends Request<JSONObject> { private Listener<JSONObject> listener; private Map<String, String> params; public CustomRequest(String url, Map<String, String> params, Listener<JSONObject> reponseListener, ErrorListener errorListener) { super(Method.GET, url, errorListener); this.listener = reponseListener; this.params = params; } public CustomRequest(int method, String url, Map<String, String> params, Listener<JSONObject> reponseListener, ErrorListener errorListener) { super(method, url, errorListener); this.listener = reponseListener; this.params = params; } protected Map<String, String> getParams() throws com.android.volley.AuthFailureError { return params; }; @Override protected Response<JSONObject> parseNetworkResponse(NetworkResponse response) { try { String jsonString = new String(response.data, HttpHeaderParser.parseCharset(response.headers)); return Response.success(new JSONObject(jsonString), HttpHeaderParser.parseCacheHeaders(response)); } catch (UnsupportedEncodingException e) { return Response.error(new ParseError(e)); } catch (JSONException je) { return Response.error(new ParseError(je)); } } @Override protected void deliverResponse(JSONObject response) { // TODO Auto-generated method stub listener.onResponse(response); }}MainActivity.java
公共布尔检查用户(字符串用户,字符串密码){
final String url = "http://10.0.2.2:3000/";final String get = "auth";JSONObject paramJson = new JSONObject();try { paramJson.put("user", "value1"); paramJson.put("pass", "value2");} catch (JSONException e) { e.printStackTrace();}Log.d("JSON", paramJson.toString());Map<String, String> paramMap = new HashMap<String, String>();paramMap.put("user", "value1");paramMap.put("pass", "value2");CustomRequest jsObjRequest = new CustomRequest(Request.Method.GET, url + get, paramMap, response -> { Toast.makeText(getApplicationContext(), response.toString(), Toast.LENGTH_LONG); }, error -> { Toast.makeText(getApplicationContext(), error.toString(), Toast.LENGTH_LONG); });queue.add(jsObjRequest);return false;}
上下文:我正在开发一个带有可以对用户进行身份验证的 API 的演示项目,因此我正在发送一个带有参数用户/密码的 get 请求。如果对此有更充分的要求,请告诉我。这是我的第一次。
答案1
小编典典https://johncodeos.com/how-to-make-post-get-put-and-delete-requests-with-retrofit-using-kotlin/
如何使用带有字符串正文的 volley 发送 POST 请求?
https://www.itsalif.info/content/android-volley-tutorial-http-get-post-put
请按照上面的链接获取 post json 数据

Android - 在 JsonObjectRequest 之后移动到主线程
如何解决Android - 在 JsonObjectRequest 之后移动到主线程?
我对 Android 还很陌生(仅限 Java),恐怕我可能没有正确地学到一些东西。
目前我有一个片段,它显示了一个 recyclerview。数据从远程 Json 文件加载。
这是我在片段中的内容:
@Override
public View onCreateView(LayoutInflater inflater,ViewGroup container,Bundle savedInstanceState) {
View v = inflater.inflate(R.layout.fragment_library,container,false);
libraryList = new LibraryHandler().getLibrary(new ShowListAsyncResponse() {
@Override
public void processFinished(ArrayList<Object> showArrayList) {
recyclerViewAdapter = new LibraryRecyclerViewAdapter(getContext(),libraryList);
libraryRecyclerView = v.findViewById(R.id.libraryRecyclerView);
libraryRecyclerView.setHasFixedSize(true);
libraryRecyclerView.setLayoutManager(new linearlayoutmanager(getActivity()));
libraryRecyclerView.setAdapter(recyclerViewAdapter);
}
});
return v;
}
LibraryHandler 是从服务器加载数据的类:
public class LibraryHandler {
private final String url = "https://path/to/api";
private ArrayList<Object> libraryList = new ArrayList<>();
public ArrayList<Object> getLibrary(final ShowListAsyncResponse callBack) {
JsonObjectRequest jsonObjectRequest = new JsonObjectRequest(
Request.Method.GET,url,null,new Response.Listener<JSONObject>() {
@Override
public void onResponse(JSONObject response) {
try {
JSONArray showsJsonArray = response.getJSONArray("shows");
JSONArray moviesJsonArray = response.getJSONArray("movies");
// Shows
for (int i = 0; i< showsJsonArray.length(); i++) {
JSONObject showObject = showsJsonArray.getJSONObject(i);
Gson gson = new Gson();
Show show = gson.fromJson(String.valueOf(showObject),Show.class);
libraryList.add(show);
}
// Movies
for (int i = 0; i< moviesJsonArray.length(); i++) {
JSONObject movieObject = moviesJsonArray.getJSONObject(i);
Gson gson = new Gson();
Movie movie = gson.fromJson(String.valueOf(movieObject),Movie.class);
libraryList.add(movie);
}
} catch (JSONException e) {
e.printstacktrace();
}
if (null != callBack) callBack.processFinished(libraryList);
}
},new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
}
}
);
AppController.getInstance().addToRequestQueue(jsonObjectRequest);
return libraryList;
}
界面很简单
public interface ShowListAsyncResponse {
void processFinished(ArrayList<Object> showArrayList);
}
我了解到应该从主线程调用适配器代码。我是否在 processFinished 函数的主线程中?如果没有,我该如何修改以从主线程运行这些行?
解决方法
文档:
Volley 总是在主线程上提供解析的响应。在主线程上运行便于使用接收到的数据填充 UI 控件,因为您可以直接从响应处理程序自由修改 UI 控件
因此 onResponse() 回调在主线程中触发,因此 callBack.processFinished() 调用。
因此,您可以在触发 RecyclerView 时安全地建立 processFinished()。
您可以查看 documentation 了解更多信息。
还要确保不要在此回调上做繁重的工作,因为它在主线程上运行。

android volley JsonObjectRequest,它只返回200个正文
JsonObjectRequest request = new JsonObjectRequest(
method,url,myJsonObject,responseListener,errorListener) {
@Override
public Map<String,String> getHeaders() throws AuthFailureError {
HashMap<String,String> headers = new HashMap<String,String>();
String creds = String.format("%s:%s",login,password);
String auth = "Basic " + Base64.encodetoString(creds.getBytes(),Base64.DEFAULT);
headers.put("Authorization",auth);
return headers;
}
};
new Response.Listener<String>(){
@Override
public void onResponse(String response) {
Toast.makeText(getActivity(),response,1000).show();
}
我尝试使用字符串或JSON对象,对象的不同种类的响应侦听器,但始终存在错误:
android volley org.json.JSONException:字符0的输入结束
或者是否有任何其他类型的请求在volley中支持和json对象和authentification标头在正文和响应只是一个http状态代码?
解决方法
您需要创建一个扩展Request类的自定义类,并在该类中覆盖这些方法
@Override
protected Response parseNetworkResponse(NetworkResponse response) {
return Response.success(response.statusCode,HttpHeaderParser.parseCacheHeaders(response));
}
@Override
protected void deliverResponse(Integer statusCode) {
mListener.onResponse(statusCode);
}
这是班上的核心和灵魂.
有关完整代码和说明,请查看我的博客主题 –
从Android Volley库获取服务器响应状态200
link 1
希望能帮助到你,谢谢

Android Volley JsonObjectRequest每次都会在移动数据上返回相同的响应
我使用Volley JsonObjectRequest从服务器获取数据.
代码段:
JsonObjectRequest jsObjRequest = new JsonObjectRequest
(Request.Method.GET, url, null, new Response.Listener<JSONObject>() {
@Override
public void onResponse(JSONObject response) {
System.out.println("Response: " + response.toString());
}
}, new Response.ErrorListener() {
@Override
public void one rrorResponse(VolleyError error) {
// Todo Auto-generated method stub
}
});
但是我每次在移动数据连接上都得到相同的JSONObject响应.
注意:它在WiFi连接上完美运行.
有人面临这个问题吗?任何解决方案
解决方法:
@BNK request.setShouldCache(false);为我工作.这是凌空缓存管理的问题.
我假设,当发送请求时:
>它会首先点击缓存并将其发送到onResponse
>然后当结果从远程服务器传来时,它会将它提供给onResponse
如果你使用volley中实现的任何默认Request类(例如StringRequest,JsonRequest等),那么在将请求对象添加到volley RequestQueue之前调用setShouldCache(false)
request.setShouldCache(false);
myQueue.add(request);
您还可以为缓存设置过期策略.
See this answer for more details

Android Volley POST JsonObject并获取JsonArray或JsonObject或其他响应
在齐射中,我们具有从服务器检索数据的能力,例如jsonObject,jsonArray和String.在以下示例中,我们可以从服务器获取jsonObject或jsonArray响应,
public static void POST(HashMap<String, String> params, final Listeners.ServerResponseListener listener) {
JsonObjectRequest req1 = new JsonObjectRequest(ApplicationController.URL, new JSONObject(params),
new Response.Listener<JSONObject>() {
@Override
public void onResponse(JSONObject response) {
Log.e("Response:", response.toString());
if (listener != null)
listener.onResultJsonObject(response);
else
Log.e(TAG,"Error: SetServerResponse interface not set");
}
}, new Response.ErrorListener() {
@Override
public void one rrorResponse(VolleyError error) {
Log.e("Error: ", error.getMessage());
}
});
ApplicationController.getInstance().addToRequestQueue(req1);
}
我的问题是我想从此方法发送jsonObject并从服务器获取jsonArray或jsonObject,而我无法使用此方法简单地从服务器获取数组.例如,我必须对此jsonObject进行过滤服务器响应:
HashMap<String, String> params = new HashMap<String, String>();
params.put("token", "AbCdEfGh123456");
params.put("search_count", "10");
params.put("order_by", "id");
服务器返回jsonArray并且我无法通过Volley响应得到它
解决方法:
查看JsonArrayRequest的源代码.有一个构造函数,它接收JSONObject.你应该检查一下
我们今天的关于JsonObjectRequest 发送空参数和http发送json数据的分享已经告一段落,感谢您的关注,如果您想了解更多关于Android - 在 JsonObjectRequest 之后移动到主线程、android volley JsonObjectRequest,它只返回200个正文、Android Volley JsonObjectRequest每次都会在移动数据上返回相同的响应、Android Volley POST JsonObject并获取JsonArray或JsonObject或其他响应的相关信息,请在本站查询。
本文将介绍为什么在 Python 中使用抽象基类?的详细情况,特别是关于python抽象基类的作用的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于c++ ——为什么要使用多态?什么是虚函数、抽象基类?、C++ 函数继承详解:如何定义和使用抽象基类?、Python abc—抽象基类、python – 为什么在字符串连接中使用os.path.join?的知识。
本文目录一览:- 为什么在 Python 中使用抽象基类?(python抽象基类的作用)
- c++ ——为什么要使用多态?什么是虚函数、抽象基类?
- C++ 函数继承详解:如何定义和使用抽象基类?
- Python abc—抽象基类
- python – 为什么在字符串连接中使用os.path.join?
")
为什么在 Python 中使用抽象基类?(python抽象基类的作用)
因为我习惯了 Python 中鸭子类型的旧方法,所以我无法理解对
ABC(抽象基类)的需求。关于如何使用它们的帮助很好。
我试图阅读PEP中的基本原理,但它超出了我的想象。如果我正在寻找一个可变序列容器,我会检查__setitem__,或者更有可能尝试使用它(EAFP)。我还没有遇到过数字模块的实际用途,它确实使用了 ABC,但这是我必须理解的最接近的。
谁能给我解释一下原因吗?
答案1
小编典典简洁版本
ABC 在客户端和实现的类之间提供更高级别的语义契约。
长版
类与其调用者之间存在契约。该类承诺做某些事情并具有某些属性。
合同有不同的层次。
在非常低的级别上,合同可能包括方法的名称或其参数的数量。
在静态类型语言中,该契约实际上将由编译器强制执行。在 Python
中,您可以使用EAFP或类型自省来确认未知对象是否符合此预期合同。
但合同中也有更高级别的语义承诺。
例如,如果有一个__str__()方法,它应该返回对象的字符串表示。它 可以
删除对象的所有内容,提交事务并从打印机中吐出一个空白页......但是对于它应该做什么有一个共同的理解,在 Python 手册中进行了描述。
这是一种特殊情况,在手册中描述了语义契约。方法应该print()怎么做?它应该将对象写入打印机还是将一行写入屏幕,还是其他什么?这取决于 -
您需要阅读评论以了解此处的完整合同。一段简单地检查print()方法是否存在的客户端代码已经确认了合同的一部分——可以进行方法调用,但没有就调用的更高级别语义达成一致。
定义抽象基类 (ABC) 是在类实现者和调用者之间产生契约的一种方式。它不仅仅是一个方法名称列表,而是对这些方法应该做什么的共同理解。如果你从这个 ABC
继承,你承诺遵循注释中描述的所有规则,包括print()方法的语义。
Python 的鸭子类型在灵活性方面比静态类型有很多优势,但它并不能解决所有问题。ABC 提供了介于 Python
的自由形式和静态类型语言的束缚和纪律之间的中间解决方案。

c++ ——为什么要使用多态?什么是虚函数、抽象基类?
多态可分为静态多态和动态多态
- 静态多态就是在系统编译期间就可以确定程序执行到这里将要执行哪个函数,比如函数的重载。
- 动态多态则是利用虚函数实现了运行时的多态,也就是说在系统编译的时候并不知道程序将要调用哪一个函数,只有在运行到这里的时候才能确定接下来会跳转到哪一个函数的栈帧。
虚函数:
在基类中声明该函数是虚拟的(在函数之前加virtual关键字),然后在子类中正式的定义(子类中的该函数的函数名,返回值,函数参数个数,参数类型,全都与基类的所声明的虚函数相同,此时才能称为重写,才符合虚函数,否则就是函数的重载),再定义一个指向基类对象的指针,然后使该指针指向由该基类派生的子类对象,再然后用这个指针来调用改虚函数,就能实现动态多态。
下面以"计算器"举例说明:
- 不使用多态的版本如下:
class Caculator
{
public:
int getResult(char fun){
if(fun == ''+'') return a+b;
else if(fun == ''-'') return a-b;
else if(fun == ''*'') return a*b;
//增加计算方式时 需要手动增删源代码
}
int a;
int b;
};
int main()
{
char fun;
Caculator x;
x.a=5;
x.b=10;
cin >> fun;
cout << x.getResult(fun);
} - 使用多态的版本如下:
class Caculator//父类计算器
{
public:
virtual int getResult(){
return 0;
}
int a;
int b;
};
//子类:加法器
class Add : public Caculator{
public:
int getResult(){
return a+b;
}
};
//此处省略减法器、乘法器等。
int main(){
Caculator* c = new Add;
c->a=1;
c->b=2;
cout << c->getResult() << endl;
return 0;
} 可以见得,使用多态的优点有:
1.组织结构清晰
2.可读性强
3.易于扩展,可维护性高 (tips:在实际开发中,提倡扩展而不提倡修改,也正是多态的优势所在)
在多态中,父类中的虚函数实现是毫无意义的,主要都由子类编写对应函数。
所以可以将父类中的虚函数编写为纯虚函数。纯虚函数:
- 意义:告诉用户这个函数是没有实际意义的。
- 用法:在函数体的位置书写=0; 例如:
class A{
public:
...
virtual void function(){
...}
}抽象基类
- 定义:含有纯虚函数的类是抽象基类。
- 解释:①抽象基类负责定义接口,而后续的其他类可以覆盖该接口。②我们不能直接创建一个抽象基类的对象(即不能实例化),并且抽象基类的派生类中必须对抽象基类中的纯虚函数进行重写。

C++ 函数继承详解:如何定义和使用抽象基类?
函数继承允许派生类复用基类的函数定义,通过以下步骤实现:定义抽象基类,包含纯虚函数。在派生类中使用 override 关键字继承并实现基类的函数。实战案例:创建抽象基类 shape,派生类 circle 和 rectangle 计算不同形状的面积。

C++ 函数继承详解:定义和使用抽象基类
什么是函数继承?
函数继承是一种 C++ 特性,它允许派生类继承基类的函数定义,从而在子类中复用基类的功能。
立即学习“C++免费学习笔记(深入)”;
定义抽象基类
一个抽象基类是一个不打算被实例化的基类,它只作为其他类的基类。它包含纯虚函数(即没有函数体的函数),这些函数必须在派生类中被重写。要声明一个抽象基类,可以使用 virtual 和 = 0,例如:
class Shape {
public:
virtual double area() const = 0;
};派生类中的函数继承
派生类可以继承抽象基类的函数定义,方法是使用 override 关键字并提供函数的实现。例如:
class Circle : public Shape {
public:
override double area() const {
return M_PI * radius * radius;
}
private:
double radius;
};实战案例:形状面积计算
让我们以计算形状面积为例进行一个实战演示。我们创建一个 Shape 抽象基类,并创建 Circle 和 Rectangle 派生类来计算圆和矩形的面积:
#include <iostream>
#include <cmath>
using namespace std;
class Shape {
public:
virtual double area() const = 0;
};
class Circle : public Shape {
public:
Circle(double radius) : radius(radius) {}
override double area() const {
return M_PI * radius * radius;
}
private:
double radius;
};
class Rectangle : public Shape {
public:
Rectangle(double width, double height) : width(width), height(height) {}
override double area() const {
return width * height;
}
private:
double width;
double height;
};
int main() {
Circle circle(5);
cout << "Circle area: " << circle.area() << endl;
Rectangle rectangle(3, 4);
cout << "Rectangle area: " << rectangle.area() << endl;
return 0;
}运行输出:
Circle area: 78.5398 Rectangle area: 12
以上就是C++ 函数继承详解:如何定义和使用抽象基类?的详细内容,更多请关注php中文网其它相关文章!

Python abc—抽象基类
该模块提供了在Python中定义抽象基类(ABC - Abstract Base Class)的基础结构,参考PEP 3119;至于为何将其添加到 Python,也可以看看PEP 3141和numbers模块有关基于ABC的 numbers 的类层次结构的模块。
容器collections模块具有一些衍生自ABC的具体类。当然,这些可以进一步继承衍生。此外, collections.abc子模块具有一些 ABC,可用于测试:类或实例是否提供特定的接口,例如,是否可哈希或是否为映射。
此模块提供ABCMeta用于定义ABC 的元类和帮助程序类,ABC以通过继承来替代地定义ABC:
classabc.`ABC
具有ABCMeta作为其元类的帮助程序类。使用此类,可以通过ABC 避免有时混淆元数据用法的简单派生来创建抽象基类,例如:
from abc import ABC
class MyABC(ABC):
pass请注意,类型ABC为still ABCMeta,因此从继承继承ABC需要有关元类使用的常规预防措施,因为多重继承可能会导致元类冲突。也可以通过传递 metaclass 关键字并ABCMeta直接使用来定义抽象基类,例如:
from abc import ABCMeta
class MyABC(metaclass=ABCMeta):
pass3.4版的新功能。
class abc.`ABCMeta`
用于定义抽象基类(ABC)的元类。
使用此元类创建一个ABC。ABC可以直接子类化,然后充当混合类。您还可以将不相关的具体类(甚至是内置类)和不相关的ABC注册为“虚拟子类” –内置issubclass()函数会将它们及其后代视为注册ABC的子类,但是注册ABC不会显示在其 MRO(方法解决顺序)中,由注册ABC定义的方法实现也将不可调用(甚至不能通过调用 super())。1个
使用元类创建的类ABCMeta具有以下方法:
register(_subclass_)
将__subclass__注册为该ABC的“虚拟子类”。例如:
from abc import ABC
class MyABC(ABC):
pass
MyABC.register(tuple)
assert issubclass(tuple, MyABC)
assert isinstance((), MyABC)在版本3.3中更改:返回注册的子类,以允许用作类装饰器。
在版本3.4中更改:要检测对的调用register(),可以使用该 get_cache_token()功能。
您还可以在抽象基类中重写此方法:
__subclasshook__(_子类_)
(必须定义为类方法。)
检查_子类_是否被视为此ABC的子类。这意味着您可以自定义issubclass进一步的行为,而无需调用register()要考虑为ABC的子类的每个类。(此类方法是从__subclasscheck__()ABC 的方法中调用的。)
这个方法应该返回True,False或NotImplemented。如果返回True,则将该_子类_视为此ABC的子类。如果返回False,则即使该子类通常是一个_子类,_也不会将该_子类_视为该ABC的子类。如果返回 NotImplemented,则使用常规机制继续子类检查。
为了演示这些概念,请看以下示例ABC定义:
class Foo:
def __getitem__(self, index):
...
def __len__(self):
...
def get_iterator(self):
return iter(self)
class MyIterable(ABC):
@abstractmethod
def __iter__(self):
while False:
yield None
def get_iterator(self):
return self.__iter__()
@classmethod
def __subclasshook__(cls, C):
if cls is MyIterable:
if any("__iter__" in B.__dict__ for B in C.__mro__):
return True
return NotImplemented
MyIterable.register(Foo)ABC MyIterable将标准可迭代方法定义 __iter__()为抽象方法。此处给出的实现仍可以从子类中调用。该get_iterator()方法也是MyIterable抽象基类的一部分,但是在非抽象派生类中不必重写此方法~~~~。
__subclasshook__()此处定义的类方法表示,任何__iter__()在其类__dict__(或通过__mro__列表访问的基类之一)中具有方法的 类也被视为类MyIterable。
最后,即使没有定义方法,最后一行仍是Foo的虚拟子类(它使用按照和 定义的旧式可迭代协议)。请注意,这不能 作为的方法使用,因此是单独提供的。MyIterable__iter__()__len__()__getitem__()get_iterator`Foo`
该abc模块还提供以下装饰器:
@`abc.`abstractmethod[](https://docs.python.org/3/lib... "此定义的永久链接")
装饰器,指示抽象方法。
使用此装饰器要求该类的元类是ABCMeta 或从其派生的。ABCMeta除非实例化了其所有抽象方法和属性,否则无法实例化具有派生自其的元类的类 。可以使用任何正常的“超级”调用机制来调用抽象方法。 abstractmethod()可以用来声明属性和描述符的抽象方法。
不支持将动态方法添加到类,或在创建方法或类后尝试修改其抽象状态。将abstractmethod()仅影响使用常规继承派生的子类; 使用ABC register()方法注册的“虚拟子类” 不受影响。
当abstractmethod()与其他方法描述符结合使用时,应将其用作最里面的装饰器,如以下用法示例所示:~~~~
class C(ABC):
@abstractmethod
def my_abstract_method(self, ...):
...
@classmethod
@abstractmethod
def my_abstract_classmethod(cls, ...):
...
@staticmethod
@abstractmethod
def my_abstract_staticmethod(...):
...
@property
@abstractmethod
def my_abstract_property(self):
...
@my_abstract_property.setter
@abstractmethod
def my_abstract_property(self, val):
...
@abstractmethod
def _get_x(self):
...
@abstractmethod
def _set_x(self, val):
...
x = property(_get_x, _set_x)为了正确地与抽象基类机制互操作,描述符必须使用标识自己为抽象 __isabstractmethod__。通常,True 如果用于构成描述符的任何方法都是抽象的,则此属性应为。例如,Python的内置功能property等效于:
class Descriptor:
...
@property
def __isabstractmethod__(self):
return any(getattr(f, ''__isabstractmethod__'', False) for f in (self._fget, self._fset, self._fdel))注意
与Java抽象方法不同,这些抽象方法可能具有实现(Java新版也有接口默认实现)。可以通过super()覆盖它的类中的机制来调用此实现。在使用协作式多重继承的框架中,这可用作超级调用的端点。
该abc模块还支持以下旧式装饰器:
@`abc.`abstractclassmethod[](https://docs.python.org/3/lib... "此定义的永久链接")
3.2版中的新功能。
自从3.3版本不推荐使用:现在可以使用classmethod用 abstractmethod(),使这个装饰是多余的。
内置的子类classmethod(),指示抽象的类方法。否则它类似于abstractmethod()。
不建议使用这种特殊情况,因为classmethod()现在将装饰器应用于抽象方法时,可以正确地将其标识为抽象:
class C(ABC):
@classmethod
@abstractmethod
def my_abstract_classmethod(cls, ...):
...@`abc.`abstractstaticmethod
3.2版中的新功能。
自从3.3版本不推荐使用:现在可以使用staticmethod用 abstractmethod(),使这个装饰是多余的。
内置的子类staticmethod(),指示抽象的静态方法。否则它类似于abstractmethod()。
不建议使用这种特殊情况,因为staticmethod()现在将装饰器应用于抽象方法时,可以正确地将其标识为抽象:
class C(ABC):
@staticmethod
@abstractmethod
def my\_abstract\_staticmethod(...):
...@abc.abstractproperty
自从3.3版本不推荐使用:现在可以使用property,property.getter(), property.setter()和property.deleter()用 abstractmethod(),使这个装饰是多余的。
内置的子类property(),指示抽象属性。
不建议使用这种特殊情况,因为property()现在将装饰器应用于抽象方法时,可以正确地将其标识为抽象:
class C(ABC):
@property
@abstractmethod
def my_abstract_property(self):
...上面的示例定义了一个只读属性;您还可以通过适当地将一个或多个基础方法标记为抽象来定义读写抽象属性:
class C(ABC):
@property
def x(self):
...
@x.setter
@abstractmethod
def x(self, val):
...如果只有某些组件是抽象的,则仅需要更新那些组件即可在子类中创建具体属性:
class D(C):
@C.x.setter
def x(self, val):
...该abc模块还提供以下功能:
abc.get_cache_token()
返回当前抽象基类缓存令牌。
令牌是一个不透明的对象(支持相等性测试),用于标识虚拟子类的抽象基类缓存的当前版本。令牌随着ABCMeta.register()在任何ABC上的每次调用而改变。
3.4版的新功能。
脚注
1个
C++程序员应注意,Python的虚拟基类概念与C++不同。

python – 为什么在字符串连接中使用os.path.join?
我主要使用VBScript,所以我不明白这个功能的意义.
解决方法
编写文件路径操作一次,它可以在许多不同的平台上免费使用.分隔字符被抽象化,使您的工作更轻松.
聪明
您不再需要担心该目录路径是否具有trailing slash or not. os.path.join将在需要时添加它.
明确
使用os.path.join可以让其他人阅读您正在使用文件路径的代码.人们可以快速扫描代码并发现它本质上是一个文件路径.如果您决定自己构建它,您可能会让读者不要发现代码的实际问题:“嗯,一些字符串concats,一个替换.这是一个文件路径还是什么?Gah!为什么他没有使用os.path .加入?”
总结
以上是小编为你收集整理的python – 为什么在字符串连接中使用os.path.join?全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。
今天关于为什么在 Python 中使用抽象基类?和python抽象基类的作用的讲解已经结束,谢谢您的阅读,如果想了解更多关于c++ ——为什么要使用多态?什么是虚函数、抽象基类?、C++ 函数继承详解:如何定义和使用抽象基类?、Python abc—抽象基类、python – 为什么在字符串连接中使用os.path.join?的相关知识,请在本站搜索。
本文将为您提供关于这个thread.abort的详细介绍,我们还将为您解释是否正常且安全?的相关知识,同时,我们还将为您提供关于Android中的新Thread(task).start()VS ThreadPoolExecutor.submit(task)、C# Thread.Abort方法与ThreadAbortException异常(取消线程与异常处理)、c# – 在ReportDocument.ExportToHttpResponse中尝试/捕获不捕获System.Threading.ThreadAbortException、delphi – TThread本身的线程安全字段是否安全?的实用信息。
本文目录一览:- 这个thread.abort()是否正常且安全?(this thread yield)
- Android中的新Thread(task).start()VS ThreadPoolExecutor.submit(task)
- C# Thread.Abort方法与ThreadAbortException异常(取消线程与异常处理)
- c# – 在ReportDocument.ExportToHttpResponse中尝试/捕获不捕获System.Threading.ThreadAbortException
- delphi – TThread本身的线程安全字段是否安全?
是否正常且安全?(this thread yield)")
这个thread.abort()是否正常且安全?(this thread yield)
我创建了一个自定义自动完成控件,当用户按下一个键时,它将在另一个线程上查询数据库服务器(使用远程处理)。当用户快速键入时,程序必须取消先前执行的请求/线程。
我以前首先将其实现为AsyncCallback,但我发现它很麻烦,要遵循的内部规则过多(例如AsyncResult,AsyncState,EndInvoke),另外您还必须检测BeginInvoke’d对象的线程,以便可以终止先前执行的线程。此外,如果我继续执行AsyncCallback,则那些AsyncCallbacks上没有任何方法可以正确终止先前执行的线程。
EndInvoke无法终止线程,它仍将完成待终止线程的操作。我仍然会最终在线程上使用Abort()。
因此,我决定仅使用纯线程方法来实现它,而无需使用AsyncCallback。这是thread.abort()正常且对您安全吗?
public delegate DataSet LookupValuesDelegate(LookupTextEventArgs e);internal delegate void PassDataSet(DataSet ds);public class AutoCompleteBox : UserControl{ Thread _yarn = null; [System.ComponentModel.Category("Data")] public LookupValuesDelegate LookupValuesDelegate { set; get; } void DataSetCallback(DataSet ds) { if (this.InvokeRequired) this.Invoke(new PassDataSet(DataSetCallback), ds); else { // implements the appending of text on textbox here } } private void txt_TextChanged(object sender, EventArgs e) { if (_yarn != null) _yarn.Abort(); _yarn = new Thread( new Mate { LookupValuesDelegate = this.LookupValuesDelegate, LookupTextEventArgs = new LookupTextEventArgs { RowOffset = offset, Filter = txt.Text }, PassDataSet = this.DataSetCallback }.DoWork); _yarn.Start(); }}internal class Mate{ internal LookupTextEventArgs LookupTextEventArgs = null; internal LookupValuesDelegate LookupValuesDelegate = null; internal PassDataSet PassDataSet = null; object o = new object(); internal void DoWork() { lock (o) { // the actual code that queries the database var ds = LookupValuesDelegate(LookupTextEventArgs); PassDataSet(ds); } }}笔记
在用户连续键入键时取消上一个线程的原因,不仅是为了防止文本的添加发生,而且还取消了上一个网络往返,因此该程序不会因为连续执行而消耗过多的内存。网络操作。
我担心是否完全避免使用thread.Abort(),该程序可能会占用太多内存。
这是不带thread.Abort()的代码,使用一个计数器:
internal delegate void PassDataSet(DataSet ds, int keyIndex);public class AutoCompleteBox : UserControl{ [System.ComponentModel.Category("Data")] public LookupValuesDelegate LookupValuesDelegate { set; get; } static int _currentKeyIndex = 0; void DataSetCallback(DataSet ds, int keyIndex) { if (this.InvokeRequired) this.Invoke(new PassDataSet(DataSetCallback), ds, keyIndex); else { // ignore the returned DataSet if (keyIndex < _currentKeyIndex) return; // implements the appending of text on textbox here... } } private void txt_TextChanged(object sender, EventArgs e) { Interlocked.Increment(ref _currentKeyIndex); var yarn = new Thread( new Mate { KeyIndex = _currentKeyIndex, LookupValuesDelegate = this.LookupValuesDelegate, LookupTextEventArgs = new LookupTextEventArgs { RowOffset = offset, Filter = txt.Text }, PassDataSet = this.DataSetCallback }.DoWork); yarn.Start(); }}internal class Mate{ internal int KeyIndex; internal LookupTextEventArgs LookupTextEventArgs = null; internal LookupValuesDelegate LookupValuesDelegate = null; internal PassDataSet PassDataSet = null; object o = new object(); internal void DoWork() { lock (o) { // the actual code that queries the database var ds = LookupValuesDelegate(LookupTextEventArgs); PassDataSet(ds, KeyIndex); } }}答案1
小编典典不,这 是不是
安全的。Thread.Abort()最好的时候是足够粗略的,但是在这种情况下,您的控件无法(委托)控制委托回调中的操作。您不知道该应用程序的其余部分将保留在什么状态,并且当需要再次致电该委托人时,很可能会陷入困境。
设置一个计时器。文本更改后稍等片刻,然后再调用委托。然后等待它返回,然后再次调用它。如果它 是 缓慢的,或用户打字 是
快的话,他们可能不希望自动完成反正。
关于更新的(无Abort())代码:
现在,您将为(可能) 每个按键 启动一个新线程。这不仅会降低性能,而且没有必要-如果用户没有暂停,他们很可能不在寻找该控件来完成输入的内容。
我之前提到过,但是P Daddy说的更好:
您最好只实现一个一键式定时器(可能会有一个半秒的超时),并在每次击键时将其重置。
想想看:即使是快速连接到快速数据库,快速打字员也可能在第一个自动完成回调有机会完成之前创建线程得分。但是,如果你们推迟,直到最后一次按键后的短时间内请求已过,那么你打的是甜蜜点,其中用户已键入了所有他们想要更好的机会(或所有他们知道!),并且是
刚 开始等待自动完成功能开始。延迟播放-
半秒可能适合不耐烦的触摸打字员,但是如果您的用户更放松…或者您的数据库更慢…那么您可能会延迟2-3秒甚至更长的时间来获得更好的结果。但是,此技术最重要的部分是您resetthe timer on every keystroke。
并且除非您期望数据库请求实际 挂起 ,否则请不要试图允许多个并发请求。如果当前正在处理一个请求,请在另一个请求完成之前等待它完成。
.start()VS ThreadPoolExecutor.submit(task)")
Android中的新Thread(task).start()VS ThreadPoolExecutor.submit(task)
在我的Android项目中,我有很多地方需要异步运行一些代码(Web请求,对db的调用等)。这不是长时间运行的任务(最多几秒钟)。到目前为止,我一直在通过创建新线程,将任务传递给新的可运行线程来进行此类操作。但是最近我读了一篇有关Java中线程和并发的文章,并且了解到为每个任务创建一个新的Thread并不是一个好的决定。
所以现在我ThreadPoolExecutor在我的Application课堂上创建了一个包含5个线程的。这是代码:
public class App extends Application { private ThreadPoolExecutor mPool; @Override public void onCreate() { super.onCreate(); mPool = (ThreadPoolExecutor)Executors.newFixedThreadPool(5); }}而且我还有一种方法可以将Runnable任务提交给执行者:
public void submitRunnableTask(Runnable task){ if(!mPool.isShutdown() && mPool.getActiveCount() != mPool.getMaximumPoolSize()){ mPool.submit(task); } else { new Thread(task).start(); }}因此,当我想在代码中运行异步任务时,我得到的实例,App并调用submitRunnableTask将可运行对象传递给它的方法。如您所见,我还检查线程池中是否有空闲线程来执行任务,否则,我将创建一个新线程(我不认为会发生这种情况,但是无论如何……我不会希望我的任务排在队列中并降低应用速度)。
在onTerminate应用程序的回调方法中,我关闭了池。
所以我的问题是:这种模式是否比在代码中创建新线程更好?我的新方法有什么优点和缺点?会导致我尚不了解的问题吗?您能建议我一些比这更好的方法来管理我的异步任务吗?
PS:我在Android和Java方面有一定的经验,但是我并不是一名并发专家。)因此,在某些问题上可能有些方面我不太了解。任何建议将被认真考虑。
答案1
小编典典该答案假设您的任务很短
这样的模式是否比在代码中创建新的线程更好?
更好,但仍远非理想。您 仍在为短期任务创建线程 。相反,您只需要创建其他类型的线程池-例如byExecutors.newScheduledThreadPool(int corePoolSize)。
行为上有什么区别?
- A
FixedThreadPool将始终具有一组要使用的线程,并且如果所有线程都忙,则将新任务放入队列。 ScheduledThreadPool由Executors类创建的(默认)(即使空闲)具有 最小的 线程池。如果有新任务出现时所有线程都忙, 它将为它创建一个新线程 ,并在完成后60秒钟处理该线程,除非再次需要它。
第二个可以让您不要自己创建新线程。无需“预定”部分就可以实现此行为,但是您将不得不自己构造执行程序。构造函数是
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)各种选项使您可以微调行为。
如果有些任务很长…
我的意思是很长。与您的应用程序生命周期中的大部分时间一样(实时2路连接?服务器端口?多播侦听器?)。在这种情况下,将您Runnable的遗嘱执行人置于不利地位–标准的遗嘱执行人
并非 旨在应对这种情况,它们的性能将下降。
考虑一下您的固定线程池-如果您有5个长时间运行的任务,那么任何新任务都会产生一个新线程,从而完全破坏该池的所有可能收益。如果您使用更灵活的执行程序-
一些线程将被共享,但并非总是如此。
经验法则是
- 如果 任务 很 短 ,请使用执行程序。
- 如果 任务很长,请 确保您的执行程序可以处理它(即,它没有最大的池大小,或者没有足够的最大线程来处理多一个线程一段时间)
- 如果这是一个需要始终与主线程一起运行的并行进程,请使用另一个线程。
")
C# Thread.Abort方法与ThreadAbortException异常(取消线程与异常处理)
1、Abort当前线程,后续程序不会执行
class Program
{
public static Thread thread1;
static void Main(string[] args)
{
thread1 = new Thread(Method1);
thread1.Start();
Console.ReadKey();
}
public static void Method1()
{
try
{
for (int i = 0; i < 10; i++)
{
Console.WriteLine("Mthod1: " + i.ToString());
Thread.Sleep(1000);
if (i == 3)
{
Thread.CurrentThread.Abort(); // 抛出的ThreadAbortException异常
}
Console.WriteLine("Mthod1: " + i.ToString() + " End");
}
}
catch (SocketException ex)
{
Console.WriteLine("Method1 SocketException: " + ex.ToString());
}
catch (ThreadAbortException ex)
{
// ThreadAbortException要在Exception的前面,因为Exception能够匹配所有异常
Console.WriteLine("Method1 ThreadAbortException: " + ex.ToString());
}
catch (Exception ex)
{
Console.WriteLine("Method1 Exception: " + ex.ToString());
}
finally
{
Console.WriteLine("Method1 Finally:");
}
}
}执行结果:
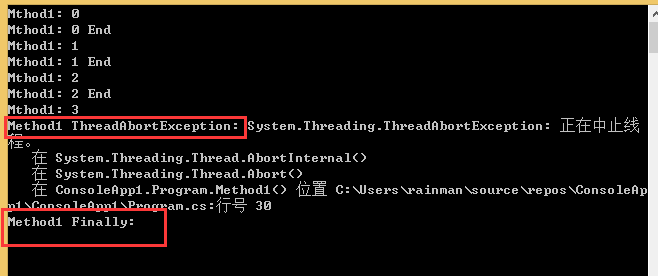
1、thread1.Abort()执行后会直接抛出ThreadAbortException异常。
2、异常会停止后续所有程序的执行(没有输出"Method1: 3 End")。
3、catch语句会执行。catch (Exception ex)和catch (ThreadAbortException ex)都可以捕获异常,由于Exception可以匹配所有异常,因此catch (ThreadAbortException ex)应该在catch (Exception ex)的前面使用,所以输出了“"Method1 ThreadAbortException”。
4、finally语句会执行。
2、Abort当前线程,进行try catch捕获异常
class Program
{
public static Thread thread1;
static void Main(string[] args)
{
thread1 = new Thread(Method1);
thread1.Start();
Console.ReadKey();
}
public static void StopMethod1()
{
try
{
thread1.Abort(); // 首先捕获抛出的ThreadAbortException异常
}
catch (Exception ex)
{
Console.WriteLine("StopMethod1: " + ex.ToString());
}
}
public static void Method1()
{
try
{
for (int i = 0; i < 10; i++)
{
Console.WriteLine("Mthod1: " + i.ToString());
Thread.Sleep(1000);
if (i == 5) StopMethod1(); // 再次捕获抛出的ThreadAbortException异常
}
}
catch (Exception ex)
{
Console.WriteLine("Method1: " + ex.ToString());
}
}
}运行结果:
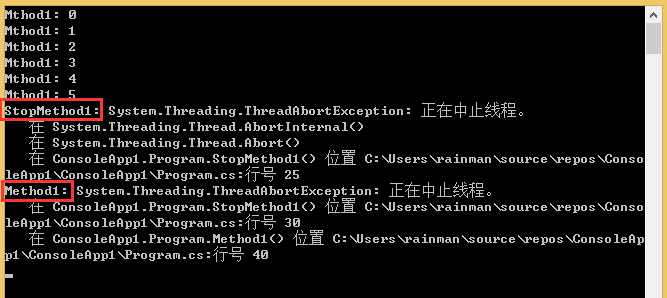
try catch{} 捕获两次抛出的ThreadAbortException。
2、Abort当前线程,不进行try catch捕获异常
class Program
{
public static Thread thread1;
static void Main(string[] args)
{
thread1 = new Thread(Method1);
thread1.Start();
Console.ReadKey();
}
public static void StopMethod1()
{
thread1.Abort();
}
public static void Method1()
{
for (int i = 0; i < 10; i++)
{
Console.WriteLine("Mthod1: " + i.ToString());
Thread.Sleep(1000);
if (i == 5) StopMethod1();
}
}
}运行结果:

1、虽然线程抛出了ThreadAbortException异常,由于线程中没有使用try catch的语句捕获异常,所以看上去线程很平静的退出了。
2、而且,由于是在线程中抛出的异常,所以主进程没有任何错误提示。
3、for循环只输出到5,Abort()后一般线程会直接停止。
3、在一个线程中Abort另一个线程
class Program
{
public static Thread thread1;
public static Thread thread2;
static void Main(string[] args)
{
thread1 = new Thread(Method1);
thread2 = new Thread(Method2);
thread1.Start();
thread2.Start();
Console.ReadKey();
}
public static void StopMethod1()
{
try
{
thread2.Abort();
}
catch (Exception ex)
{
Console.WriteLine("StopMethod1: " + ex.ToString());
}
}
public static void Method1()
{
try
{
for (int i = 0; i < 10; i++)
{
Console.WriteLine("Method1: " + i.ToString());
Thread.Sleep(1000);
if (i == 5) StopMethod1();
}
}
catch (Exception ex)
{
Console.WriteLine("Method3: " + ex.ToString());
}
}
public static void Method2()
{
try
{
for (int i = 0; i < 10; i++)
{
Console.WriteLine("Method2: " + i.ToString());
Thread.Sleep(1000);
}
}
catch (Exception ex)
{
Console.WriteLine("Method2: " + ex.ToString());
}
}
}运行结果:
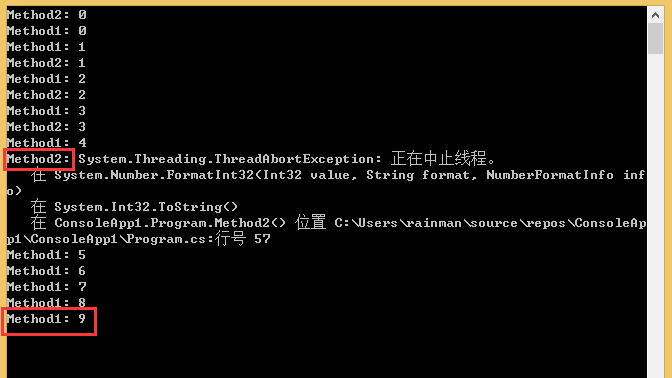
1、可以看到只在thread2中捕获到了ThreadAbortException异常。
2、thread1完整的运行完毕了,并且没有ThreadAbortException异常抛出。
总结
1、theadX.Abort()方法会在线程X中抛出ThreadAbortException异常,线程X中所有正在执行的try catch都会捕获该异常。
2、theadX.Abort()有可能在Y线程中调用的,不会在Y线程中抛出ThreadAbortException异常。

c# – 在ReportDocument.ExportToHttpResponse中尝试/捕获不捕获System.Threading.ThreadAbortException
report.ExportToHttpResponse(exportOptions,HttpContext.Current.Response,true,"test");
当我第一次尝试运行它时,我收到了System.Threading.ThreadAbortException.在阅读了this question中ExportToHttpResponse的已知错误之后,我尝试实现了在try / catch块中包装语句的建议解决方法,如下所示:
try
{
report.ExportToHttpResponse(expOptions,"test");
}
catch (System.Threading.ThreadAbortException e)
{
}
据我了解,这应该捕获并忽略错误,然后继续.但是,我仍然在catch语句的结束括号上获得System.Threading.ThreadAbortException.我的问题是为什么即使我显然正在捕获它仍然会收到异常,我怎么能去修复它以便忽略异常?
解决方法
但是,请记住,response.end是一个坏主意.每当你可以尝试调用HttpApplication.CompleteRequest(),并阅读 this SO问题,这对我来说在这方面真的很有用.

delphi – TThread本身的线程安全字段是否安全?
TMyClass = class(TThread) public FInputBuffer : TThreadedQueue<TBytes>; protected procedure Execute; override; end;
使用(在TMyClass和其他类中)FInputBuffer是线程安全吗?
编辑:
样本使用:在TMyClass中:
procedure TMyClass.Execute;
var x :TBytes;
begin
inherited;
FInputBuffer:= TThreadedQueue<TBytes>.Create;
while not Terminated do begin
if FInputBuffer.QueueSize > 0 then begin
x:= FInputBuffer.PopItem;
//some code to use x
end;
end;
FInputBuffer.Free;
end;
在其他课程:
var MyClass :TMyClass ; procedure TForm1.btn1Click(Sender: TObject); var x :TBytes; begin //set x MyClass.FInputBuffer.PushItem(x); end;
解决方法
但是,如果在Execute()内部创建了FInputBuffer,那么它不是线程安全的,因为在创建FInputBuffer之前,btn1Click()可能会在线程开始运行之前尝试访问队列.这就是你需要在构造函数中创建FInputBuffer的原因,例如:
TMyClass = class(TThread)
public
FInputBuffer: TThreadedQueue<TBytes>;
constructor Create(ACreateSuspended: Boolean); override;
destructor Destroy; override;
protected
procedure Execute; override;
end;
constructor TMyClass.Create(ACreateSuspended: Boolean);
begin
inherited;
FInputBuffer := TThreadedQueue<TBytes>.Create;
end;
destructor TMyClass.Destroy;
begin
FInputBuffer.Free;
inherited;
end;
procedure TMyClass.Execute;
var
x: TBytes;
begin
while not Terminated do begin
if FInputBuffer.QueueSize > 0 then begin
x := FInputBuffer.PopItem;
// some code to use x
end;
end;
end;
如果要在Execute()内部创建FInputBuffer,那么线程应该暴露在实际创建FInputBuffer之后设置的标志/信号,然后在设置该标志/信号之前,其他任何代码都不应尝试访问FInputBuffer.创建线程实例的代码应该在将控制权返回到代码的其余部分之前等待该标志/信号,例如:
TMyClass = class(TThread)
public
FInputBuffer: TThreadedQueue<TBytes>;
FInputBufferCreated: TEvent;
constructor Create(ACreateSuspended: Boolean); override;
destructor Destroy; override;
protected
procedure Execute; override;
procedure DoTerminate; override;
end;
constructor TMyClass.Create(ACreateSuspended: Boolean);
begin
inherited;
FInputBufferCreated := TEvent.Create(nil,True,False,'');
end;
destructor TMyClass.Destroy;
begin
FInputBufferCreated.Free;
inherited;
end;
procedure TMyClass.Execute;
var
x: TBytes;
begin
FInputBuffer := TThreadedQueue<TBytes>.Create;
FInputBufferCreated.SetEvent;
while not Terminated do begin
if FInputBuffer.QueueSize > 0 then begin
x := FInputBuffer.PopItem;
// some code to use x
end;
end;
end;
procedure TMyClass.DoTerminate;
begin
if FInputBufferCreated <> nil then
FInputBufferCreated.ResetEvent;
FreeAndNil(FInputBuffer);
inherited;
end;
.
var
MyClass: TMyClass = nil;
procedure TForm1.StartBufferThread;
var
I: Integer;
begin
MyClass := TMyClass.Create(False);
if MyClass.FInputBufferCreated.WaitFor(2500) <> wrSignaled then
begin
MyClass.Terminate;
MyClass.WaitFor;
FreeAndNil(MyClass);
raise Exception.Create('MyClass.FInputBuffer not created after 2.5 seconds!');
end;
end;
procedure TForm1.btn1Click(Sender: TObject);
var
x: TBytes;
begin
//set x
if MyClass <> nil then
MyClass.FInputBuffer.PushItem(x);
end;
关于这个thread.abort和是否正常且安全?的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于Android中的新Thread(task).start()VS ThreadPoolExecutor.submit(task)、C# Thread.Abort方法与ThreadAbortException异常(取消线程与异常处理)、c# – 在ReportDocument.ExportToHttpResponse中尝试/捕获不捕获System.Threading.ThreadAbortException、delphi – TThread本身的线程安全字段是否安全?的相关信息,请在本站寻找。
本文将介绍clang 错误:未知参数:'-mno-fused-madd'的详细情况,特别是关于python 包安装失败的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于Anaconda运行时错误:未将Python安装为框架吗?、c – 错误Xcode 5.1:未知参数:’ – cclib'[-Wunused-command-line-argument-hard-error-in-future]、CMake 错误:未知参数 --clean-first、command not found: django-admin.py 的解决办法(python2.7)的知识。
本文目录一览:- clang 错误:未知参数:'-mno-fused-madd'(python 包安装失败)(未知错误code=0)
- Anaconda运行时错误:未将Python安装为框架吗?
- c – 错误Xcode 5.1:未知参数:’ – cclib'[-Wunused-command-line-argument-hard-error-in-future]
- CMake 错误:未知参数 --clean-first
- command not found: django-admin.py 的解决办法(python2.7)
(未知错误code=0)")
clang 错误:未知参数:'-mno-fused-madd'(python 包安装失败)(未知错误code=0)
尝试psycopg2在 Mavericks 10.9 上通过 pip 安装时出现以下错误:
clang: error: unknown argument: ''-mno-fused-madd'' [-Wunused-command-line-argument-hard-error-in-future]不知道如何继续,并已在此处和其他地方搜索此特定错误。任何帮助深表感谢!
这是 pip 的完整输出:
$ pip install psycopg2Downloading/unpacking psycopg2 Downloading psycopg2-2.5.2.tar.gz (685kB): 685kB downloaded Running setup.py (path:/private/var/folders/0z/ljjwsjmn4v9_zwm81vhxj69m0000gn/T/pip_build_tino/psycopg2/setup.py) egg_info for package psycopg2Installing collected packages: psycopg2 Running setup.py install for psycopg2 building ''psycopg2._psycopg'' extension cc -fno-strict-aliasing -fno-common -dynamic -arch x86_64 -arch i386 -g -Os -pipe -fno-common -fno-strict-aliasing -fwrapv -mno-fused-madd -DENABLE_DTRACE -DMACOSX -DNDEBUG -Wall -Wstrict-prototypes -Wshorten-64-to-32 -DNDEBUG -g -fwrapv -Os -Wall -Wstrict-prototypes -DENABLE_DTRACE -arch x86_64 -arch i386 -pipe -DPSYCOPG_DEFAULT_PYDATETIME=1 -DPSYCOPG_VERSION="2.5.2 (dt dec pq3 ext)" -DPG_VERSION_HEX=0x090303 -DPSYCOPG_EXTENSIONS=1 -DPSYCOPG_NEW_BOOLEAN=1 -DHAVE_PQFREEMEM=1 -I/System/Library/Frameworks/Python.framework/Versions/2.7/include/python2.7 -I. -I/usr/local/Cellar/postgresql/9.3.3/include -I/usr/local/Cellar/postgresql/9.3.3/include/server -c psycopg/psycopgmodule.c -o build/temp.macosx-10.9-intel-2.7/psycopg/psycopgmodule.o clang: error: unknown argument: ''-mno-fused-madd'' [-Wunused-command-line-argument-hard-error-in-future] clang: note: this will be a hard error (cannot be downgraded to a warning) in the future error: command ''cc'' failed with exit status 1 Complete output from command /usr/bin/python -c "import setuptools, tokenize;__file__=''/private/var/folders/0z/ljjwsjmn4v9_zwm81vhxj69m0000gn/T/pip_build_tino/psycopg2/setup.py'';exec(compile(getattr(tokenize, ''open'', open)(__file__).read().replace(''\r\n'', ''\n''), __file__, ''exec''))" install --record /var/folders/0z/ljjwsjmn4v9_zwm81vhxj69m0000gn/T/pip-bnWiwB-record/install-record.txt --single-version-externally-managed --compile: running installrunning buildrunning build_pycreating buildcreating build/lib.macosx-10.9-intel-2.7creating build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/__init__.py -> build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/_json.py -> build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/_range.py -> build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/errorcodes.py -> build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/extensions.py -> build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/extras.py -> build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/pool.py -> build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/psycopg1.py -> build/lib.macosx-10.9-intel-2.7/psycopg2copying lib/tz.py -> build/lib.macosx-10.9-intel-2.7/psycopg2creating build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/__init__.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/dbapi20.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/dbapi20_tpc.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_async.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_bug_gc.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_bugX000.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_cancel.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_connection.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_copy.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_cursor.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_dates.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_extras_dictcursor.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_green.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_lobject.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_module.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_notify.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_psycopg2_dbapi20.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_quote.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_transaction.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_types_basic.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_types_extras.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/test_with.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/testconfig.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testscopying tests/testutils.py -> build/lib.macosx-10.9-intel-2.7/psycopg2/testsrunning build_extbuilding ''psycopg2._psycopg'' extensioncreating build/temp.macosx-10.9-intel-2.7creating build/temp.macosx-10.9-intel-2.7/psycopgcc -fno-strict-aliasing -fno-common -dynamic -arch x86_64 -arch i386 -g -Os -pipe -fno-common -fno-strict-aliasing -fwrapv -mno-fused-madd -DENABLE_DTRACE -DMACOSX -DNDEBUG -Wall -Wstrict-prototypes -Wshorten-64-to-32 -DNDEBUG -g -fwrapv -Os -Wall -Wstrict-prototypes -DENABLE_DTRACE -arch x86_64 -arch i386 -pipe -DPSYCOPG_DEFAULT_PYDATETIME=1 -DPSYCOPG_VERSION="2.5.2 (dt dec pq3 ext)" -DPG_VERSION_HEX=0x090303 -DPSYCOPG_EXTENSIONS=1 -DPSYCOPG_NEW_BOOLEAN=1 -DHAVE_PQFREEMEM=1 -I/System/Library/Frameworks/Python.framework/Versions/2.7/include/python2.7 -I. -I/usr/local/Cellar/postgresql/9.3.3/include -I/usr/local/Cellar/postgresql/9.3.3/include/server -c psycopg/psycopgmodule.c -o build/temp.macosx-10.9-intel-2.7/psycopg/psycopgmodule.oclang: error: unknown argument: ''-mno-fused-madd'' [-Wunused-command-line-argument-hard-error-in-future]clang: note: this will be a hard error (cannot be downgraded to a warning) in the futureerror: command ''cc'' failed with exit status 1----------------------------------------Cleaning up...Command /usr/bin/python -c "import setuptools, tokenize;__file__=''/private/var/folders/0z/ljjwsjmn4v9_zwm81vhxj69m0000gn/T/pip_build_tino/psycopg2/setup.py'';exec(compile(getattr(tokenize, ''open'', open)(__file__).read().replace(''\r\n'', ''\n''), __file__, ''exec''))" install --record /var/folders/0z/ljjwsjmn4v9_zwm81vhxj69m0000gn/T/pip-bnWiwB-record/install-record.txt --single-version-externally-managed --compile failed with error code 1 in /private/var/folders/0z/ljjwsjmn4v9_zwm81vhxj69m0000gn/T/pip_build_tino/psycopg2答案1
小编典典您可以通过在编译之前设置以下环境变量来告诉 clang 不要将此作为错误提出:
export CFLAGS=-Qunused-argumentsexport CPPFLAGS=-Qunused-arguments然后pip install psycopg2应该工作。
尝试时我也有同样的情况pip install lxml。
编辑:如果您以超级用户身份安装(如果您尝试附加到/Library/Python/2.7/site-packagesOS X 附带的原生 Apple
工厂安装的 Python 发行版,而不是您随后自己安装的其他 Python 发行版,则可能会出现这种情况),那么您将需要按照@Thijs Kuipers
在以下评论中的描述进行操作:
sudo -E pip install psycopg2或等效的,对于您可能替换的任何其他包名称psycopg2.
更新 [2014-05-16]:Apple 已通过更新的系统 Python(2.7、2.6 和 2.5)修复了此问题,OS X10.9.3因此在使用最新的 Mavericks 和Xcode 5.1+. OS X10.8.x但是,到目前为止,如果您在那里使用(Mountain Lion,目前为 10.8.5),仍然需要解决方法Xcode 5.1+。

Anaconda运行时错误:未将Python安装为框架吗?
我已经使用pkg安装程序安装了Anaconda:
Python 2.7.10 |Continuum Analytics,Inc.| (default,May 28 2015,17:04:42)
[GCC 4.2.1 (Apple Inc. build 5577)] on darwin
Type "help","copyright","credits" or "license" for more information.
Anaconda is brought to you by Continuum Analytics.
Please check out: http://continuum.io/thanks and https://binstar.org
但是当我尝试使用matplotlib中的任何东西时,即:
from matplotlib import pyplot as plt
我懂了
RuntimeError: Python is not installed as a framework.
The Mac OS X backend will not be able to function correctly if Python is not installed
as a framework. See the Python documentation for more information on installing Python
as a framework on Mac OS X. Please either reinstall Python as a framework,or try one of the other backends.
我真的不确定这意味着什么,或者如何解决它。
![c – 错误Xcode 5.1:未知参数:’ – cclib'[-Wunused-command-line-argument-hard-error-in-future]](http://www.gvkun.com/zb_users/upload/2025/02/8bdbb23b-87c6-4d5a-8da0-4b12507be0771739581743748.jpg "c – 错误Xcode 5.1:未知参数:’ – cclib'[-Wunused-command-line-argument-hard-error-in-future]")
c – 错误Xcode 5.1:未知参数:’ – cclib'[-Wunused-command-line-argument-hard-error-in-future]
unkNown argument: ''-cclib'' [-Wunused-command-line-argument-hard-error-in-future]
有人告诉:这是一个严重的问题,因为clang不支持几个常见的gcc标志(最明显的是-mno-fused-madd)
那么,我该如何解决这个问题,或者我必须等待Apple的修复版本?
解决方法
解决:
我找到了这个问题的答案.我在Build Setting / Other Linker Flag中删除了-cclib标志.并且没有错误发生.我认为clang编译器不需要-cclib.
我看到有人也有同样的问题:未知参数:-fno-obj-arc''[-Wunused-command-line-argument-hard-error-in-future].请用-fno-objc-arc替换-fno-obj-arc

CMake 错误:未知参数 --clean-first
如何解决CMake 错误:未知参数 --clean-first?
运行以下 CMake 命令时,我收到错误消息。我正在使用 CMake 版本 3.20.5。
cmake --clean-first ./src/basis_universal/CMakeLists.txt
CMake Error: UnkNown argument --clean-first
然而,--clean-first appears to be supported。
解决方法
只是为了让您清楚地了解...通常在任何 cmake 项目中都需要执行 2 个步骤...配置和构建。
在配置步骤中,CMake 会在您的系统、编译器等中查找文件,并为构建做好一切准备。
将代码实际转换为可执行文件的构建步骤是第二个单独的步骤。
跑步时
cmake --clean-first ./src/basis_universal/CMakeLists.txt
您只是在配置您的项目。 --clean-first 命令在配置期间不可用。
配置完成后,您需要构建您的项目。在该步骤中,您可以使用 --clean-first 选项。
")
command not found: django-admin.py 的解决办法(python2.7)
天升级了 linux 下的 python,又安装了 Django,按照网上的思路
在 linux 命令行下
|
1
2
3
|
python
#在进入python命令行之后再导入django
improt django
|
再执行
|
1
|
django-admin.py startproject mysite
|
提示 command not found: django-admin.py 问题应该就就是没有把 django-admin.py 的路径加入环境变量
只需要找到 django-admin.py 的路径就行。我参考了官方文档:
https://code.djangoproject.com/wiki/InstallationPitfalls
但是那个文档是 2 年前的东西,只有 2.4 和 2.6 的,而我的 python 是 2.7 版本的。我试了下,完全不对。
不过思路是清晰了,就是加软链接的操作
linux 命令也忘记的差不多了。用 find /-name django-admin.py 找不到,不知道是不是命令有误。。。
最后打开文件夹找,在 python27/bin/ 里面看到了 django-admin.py。
那就行了!如下图!


今天关于clang 错误:未知参数:'-mno-fused-madd'和python 包安装失败的分享就到这里,希望大家有所收获,若想了解更多关于Anaconda运行时错误:未将Python安装为框架吗?、c – 错误Xcode 5.1:未知参数:’ – cclib'[-Wunused-command-line-argument-hard-error-in-future]、CMake 错误:未知参数 --clean-first、command not found: django-admin.py 的解决办法(python2.7)等相关知识,可以在本站进行查询。
针对System.Web.HttpContext.Current.User.Identity.Name与ASP.NET中的System.Environment.UserName这个问题,本篇文章进行了详细的解答,同时本文还将给你拓展.NET System.Web.HttpContext.Current.Request报索引超出数组界限。、.net – 为什么System.Environment.MachineName值大写?、ASP.NET Core-Environment、IWebHostEnvironment、IApplicationLifetime Environment、Asp.net System.Web.HttpContext.Current.Session null in global.asax等相关知识,希望可以帮助到你。
本文目录一览:- System.Web.HttpContext.Current.User.Identity.Name与ASP.NET中的System.Environment.UserName
- .NET System.Web.HttpContext.Current.Request报索引超出数组界限。
- .net – 为什么System.Environment.MachineName值大写?
- ASP.NET Core-Environment、IWebHostEnvironment、IApplicationLifetime Environment
- Asp.net System.Web.HttpContext.Current.Session null in global.asax

System.Web.HttpContext.Current.User.Identity.Name与ASP.NET中的System.Environment.UserName
是什么区别System.Web.HttpContext.Current.User.Identity.Name,并System.Environment.UserName在ASP.Net
Web应用程序项目的情况下?
这是我要执行的操作的代码:
Database myDB = DatabaseFactory.CreateDatabase();bool IsAuthUser = myDB.ExecuteScalar("procIsAuthorizedUser", System.Environment.UserName);如果它们在功能上相同,那么在性能方面哪个更好?
这是一个C#4.0 / ASP.Net Web应用程序,在组织内部将看到适度的使用情况。谢谢你的回答。
答案1
小编典典System.Environment.UserName返回用于运行托管您的Web应用程序的应用程序池的标识。如果您使用Windows身份验证和模拟,那么它将是实际用户的名称,但是在所有情况下,最好使用HTTP上下文提供的信息。两种方式都不会影响性能。

.NET System.Web.HttpContext.Current.Request报索引超出数组界限。
移动端使用Dio发送 FormData, 请求类型 multipart/form-data, FormData内可以一个或多个包含文件时。
请求接口时获取上传的fomdata数据使用 System.Web.HttpContext.Current.Request 接受时 报索引超出数组界限问题。
使用MultipartFormDataStreamProvider接受数据不受影响。
解决过程不多说。说多了都是泪。下面是解决方案
解决方法:
1.修改IIS的applicationhost.config
a.文件位置: %windir%/system32/inetsrv/config/applicationhost.config
b.找到 <requestFiltering> 节点
c.然后找到<serverRuntime />此项。如果设置了uploadReadAheadSize的大小 则删除掉就可以了。
附加知识点:
iis7上传文件大小是有限制的。根据自己需求来进行设置相对应的处理
1.web.config中添加如下内容
<configuration>
<system.web>
<httpRuntime maxRequestLength="上传大小的值(单位:byte)" executionTimeout="120"/>
</system.web>
</configuration>2.web.config中,把以下内容加在<system.webServer>节点
<security>
<requestFiltering >
<requestLimits maxAllowedContentLength="上传大小的值(单位:KB)" >
</requestLimits>
</requestFiltering>
</security>

.net – 为什么System.Environment.MachineName值大写?
解决方法

ASP.NET Core-Environment、IWebHostEnvironment、IApplicationLifetime Environment
Environment
静态类,提供有关当前环境的信息和操作方法和平台。
System.Environment.GetEnvironmentvariable("ASPNETCORE_ENVIRONMENT");//读取环境变量
IWebHostEnvironment
IWebHostEnvironment接口中是一些该应用程序的环境信息,包括程序名称信息,根目录,环境名称 等等基本信息
IWebHostEnvironment接口继承IHostEnvironment接口
await context.Response.WriteAsync($"name=\"{env.ApplicationName}\"");
await context.Response.WriteAsync($"name=\"{env.ContentRootFileProvider}\"");
//网站根目录
await context.Response.WriteAsync($"name=\"{env.ContentRootPath}\"");
await context.Response.WriteAsync($"name=\"{env.EnvironmentName}\"");
//wwwroot目录对应的FileProvider
await context.Response.WriteAsync($"name=\"{env.WebrootFileProvider}\"");
//wwwroot目录
await context.Response.WriteAsync($"name=\"{env.WebrootPath}\"");
env.IsDevelopment();//是否开发环境,ASPNETCORE_ENVIRONMENT环境变量值是否是Development
env.IsProduction();//是否生产环境,ASPNETCORE_ENVIRONMENT环境变量值是否是Production
env.Isstaging();
env.IsEnvironment("ok");//ASPNETCORE_ENVIRONMENT环境变量值是否是ok
ASP.NET Core 在应用启动时读取环境变量 ASPNETCORE_ENVIRONMENT,ASPNETCORE_ENVIRONMENT 可设置为任意值,但框架仅支持三个值:Development(开发)、Staging(测试)、Production(生产)。 如果未设置 ASPNETCORE_ENVIRONMENT,则默认为 Production(即生产环境)
env.IsDevelopment();//是否开发环境
env.IsProduction();//是否生产环境
env.Isstaging();//是否测试环境
env.IsEnvironment("xxx");//是否自定义环境
设置环境变量的三种方法:
1、在CMD中设置(临时): set ASPNETCORE_ENVIRONMENT=Staging
2、电脑环境变量全局设置:我的电脑属性→环境变量→ASPNETCORE_ENVIRONMENT :Development
3、代码层次launchSettings.json中配置,配置文件中有两个选项,一个是IIS Express,一个是项目名称,这两个对应上面VS工具栏不同的启动方式,省略的话默认为 Production环境。
注意:前两种方式只适用于通过命令启动的模式,如: dotnet ManyEnvironment.dll
IApplicationLifetime
IApplicationLifetime是用来绑定应用程序的运行时事件的
applicationLifetime.ApplicationStarted.Register(() =>
{
Console.WriteLine("Strated");
});
applicationLifetime.ApplicationStopping.Register(() =>
{
Console.WriteLine("Stoping");
});
applicationLifetime.ApplicationStopped.Register(() =>
{
Console.WriteLine("Strated");
}
IHostApplicationLifetime:与IApplicationLifetime接口作用相同
Asp.net System.Web.HttpContext.Current.Session null in global.asax
但是,我只是添加一个动态图像功能,让一个页面提供图像,每当加载动态图像页面System.Web.HttpContext.Current.Session是null在global.asax,这阻止我设置安全校长是从那时开始的正常和级联问题.
通常,在用户登录时,在开始时的会话期间,global.asax中的Session仅为null,之后它始终可用于此单个异常.
当浏览器碰到原始页面中的图像时,加载动态图像页面,即
我猜这是浏览器在不发送一些凭据的情况下请求该页面的一个方面呢?
任何帮助将不胜感激.
解决方法
我假设你正在为处理程序使用一个ashx处理程序.如果是这样,请务必从IRequiresSessionState派生例如:
public class Images : IHttpHandler,System.Web.SessionState.IRequiresSessionState
{ }
如果您不使用ashx,您可以描述动态图像页面的意思吗?
玩笑
关于System.Web.HttpContext.Current.User.Identity.Name与ASP.NET中的System.Environment.UserName的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于.NET System.Web.HttpContext.Current.Request报索引超出数组界限。、.net – 为什么System.Environment.MachineName值大写?、ASP.NET Core-Environment、IWebHostEnvironment、IApplicationLifetime Environment、Asp.net System.Web.HttpContext.Current.Session null in global.asax等相关内容,可以在本站寻找。
本文标签:




