如果您想了解ValueError:无法压缩dim[1],预期尺寸为1,为'sparse_softmax_cross_entropy_loss获得了3的相关知识,那么本文是一篇不可错过的文章,我们将为您
如果您想了解ValueError:无法压缩dim [1],预期尺寸为1,为'sparse_softmax_cross_entropy_loss获得了3的相关知识,那么本文是一篇不可错过的文章,我们将为您提供关于1、求 loss:tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits (logits, labels, name=None))、binary_cross_entropy_with_logits 产生负输出、Difference between nn.softmax & softmax_cross_entropy_with_logits & softmax_cross_entropy...、from_logits = True和from_logits =False获得针对UNet的tf.losses.CategoricalCrossentropy的不同训练结果的有价值的信息。
本文目录一览:- ValueError:无法压缩dim [1],预期尺寸为1,为'sparse_softmax_cross_entropy_loss获得了3
- 1、求 loss:tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits (logits, labels, name=None))
- binary_cross_entropy_with_logits 产生负输出
- Difference between nn.softmax & softmax_cross_entropy_with_logits & softmax_cross_entropy...
- from_logits = True和from_logits =False获得针对UNet的tf.losses.CategoricalCrossentropy的不同训练结果
![ValueError:无法压缩dim [1],预期尺寸为1,为'sparse_softmax_cross_entropy_loss获得了3](http://www.gvkun.com/zb_users/upload/2025/02/6fee4ccd-e65d-4b8f-9a9a-bf06f68cd9e61739671527529.jpg "ValueError:无法压缩dim [1],预期尺寸为1,为'sparse_softmax_cross_entropy_loss获得了3")
ValueError:无法压缩dim [1],预期尺寸为1,为'sparse_softmax_cross_entropy_loss获得了3
如何解决ValueError:无法压缩dim [1],预期尺寸为1,为''sparse_softmax_cross_entropy_loss获得了3?
这里的错误来自 。
TensorFlow文档明确指出“标签向量必须为logits的每一行提供一个用于真实类的特定索引”。因此,您的标签向量必须仅包含类索引(例如0,1,2),而不应包括它们各自的一键编码(例如[1,0,0],[0,1,0],[0,0,1])。
重现错误以进一步说明:
import numpy as np
import tensorflow as tf
# Create random-array and assign as logits tensor
np.random.seed(12345)
logits = tf.convert_to_tensor(np.random.sample((4,4)))
print logits.get_shape() #[4,4]
# Create random-labels (Assuming only 4 classes)
labels = tf.convert_to_tensor(np.array([2, 2, 0, 1]))
loss_1 = tf.losses.sparse_softmax_cross_entropy(labels, logits)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
print ''Loss: {}''.format(sess.run(loss_1)) # 1.44836854
# Now giving one-hot-encodings in place of class-indices for labels
wrong_labels = tf.convert_to_tensor(np.array([[0,0,1,0], [0,0,1,0], [1,0,0,0],[0,1,0,0]]))
loss_2 = tf.losses.sparse_softmax_cross_entropy(wrong_labels, logits)
# This should give you a similar error as soon as you define it
因此,请尝试在Y_Labels向量中提供类索引而不是一键编码。希望这能消除您的疑问。
解决方法
我试图用本地图像替换训练和验证数据。但是在运行训练代码时,出现了以下错误:
ValueError:无法挤压dim
[1],预期尺寸为1,输入形状为[100,3]的’sparse_softmax_cross_entropy_loss /
remove_squeezable_dimensions / Squeeze’(op:’Squeeze’)得到3。
我不知道该如何解决。模型定义代码中没有可见变量。该代码是从TensorFlow教程中修改的。图像是jpg。
这是详细的错误消息:
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {''_log_step_count_steps'': 100,''_is_chief'': True,''_model_dir'': ''/tmp/mnist_convnet_model'',''_tf_random_seed'': None,''_session_config'': None,''_save_checkpoints_secs'': 600,''_num_worker_replicas'': 1,''_save_checkpoints_steps'': None,''_service'': None,''_keep_checkpoint_max'': 5,''_cluster_spec'': <tensorflow.python.training.server_lib.ClusterSpec object at 0x00000288088D50F0>,''_keep_checkpoint_every_n_hours'': 10000,''_task_type'': ''worker'',''_master'': '''',''_save_summary_steps'': 100,''_num_ps_replicas'': 0,''_task_id'': 0}
Traceback (most recent call last):
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\common_shapes.py",line 686,in _call_cpp_shape_fn_impl
input_tensors_as_shapes,status)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\errors_impl.py",line 473,in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.InvalidArgumentError: Can not squeeze dim[1],expected a dimension of 1,got 3 for ''sparse_softmax_cross_entropy_loss/remove_squeezable_dimensions/Squeeze'' (op: ''Squeeze'') with input shapes: [100,3].
During handling of the above exception,another exception occurred:
Traceback (most recent call last):
File "D:\tf_exe_5_make_image_lables\cnn_mnist.py",line 214,in <module>
tf.app.run()
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\platform\app.py",line 124,in run
_sys.exit(main(argv))
File "D:\tf_exe_5_make_image_lables\cnn_mnist.py",line 203,in main
hooks=[logging_hook])
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\estimator\estimator.py",line 314,in train
loss = self._train_model(input_fn,hooks,saving_listeners)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\estimator\estimator.py",line 743,in _train_model
features,labels,model_fn_lib.ModeKeys.TRAIN,self.config)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\estimator\estimator.py",line 725,in _call_model_fn
model_fn_results = self._model_fn(features=features,**kwargs)
File "D:\tf_exe_5_make_image_lables\cnn_mnist.py",line 67,in cnn_model_fn
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels,logits=logits)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\ops\losses\losses_impl.py",line 790,in sparse_softmax_cross_entropy
labels,logits,weights,expected_rank_diff=1)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\ops\losses\losses_impl.py",line 720,in _remove_squeezable_dimensions
labels,predictions,expected_rank_diff=expected_rank_diff)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\ops\confusion_matrix.py",line 76,in remove_squeezable_dimensions
labels = array_ops.squeeze(labels,[-1])
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\ops\array_ops.py",line 2490,in squeeze
return gen_array_ops._squeeze(input,axis,name)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\ops\gen_array_ops.py",line 7049,in _squeeze
"Squeeze",input=input,squeeze_dims=axis,name=name)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\op_def_library.py",line 787,in _apply_op_helper
op_def=op_def)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\ops.py",line 3162,in create_op
compute_device=compute_device)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\ops.py",line 3208,in _create_op_helper
set_shapes_for_outputs(op)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\ops.py",line 2427,in set_shapes_for_outputs
return _set_shapes_for_outputs(op)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\ops.py",line 2400,in _set_shapes_for_outputs
shapes = shape_func(op)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\ops.py",line 2330,in call_with_requiring
return call_cpp_shape_fn(op,require_shape_fn=True)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\common_shapes.py",line 627,in call_cpp_shape_fn
require_shape_fn)
File "C:\Users\ASUS\AppData\Local\Programs\Python\Python35\lib\site-packages\tensorflow\python\framework\common_shapes.py",line 691,in _call_cpp_shape_fn_impl
raise ValueError(err.message)
ValueError: Can not squeeze dim[1],3].
>>>
这是我的代码:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
#imports
import numpy as np
import tensorflow as tf
import glob
import cv2
import random
import matplotlib.pylab as plt
import pandas as pd
import sys as system
from mlxtend.preprocessing import one_hot
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
tf.logging.set_verbosity(tf.logging.INFO)
def cnn_model_fn(features,mode):
"""Model function for CNN"""
#Input Layer
input_layer = tf.reshape(features["x"],[-1,320,3])
#Convolutional Layer #1
conv1 = tf.layers.conv2d(
inputs = input_layer,filters = 32,kernel_size=[5,5],padding = "same",activation=tf.nn.relu)
#Pooling Layer #1
pool1 = tf.layers.max_pooling2d(inputs=conv1,pool_size=[2,2],strides=2)
#Convolutional Layer #2 and Pooling Layer #2
conv2 = tf.layers.conv2d(
inputs=pool1,filters=64,padding="same",activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2,strides=2)
#Dense Layer
pool2_flat = tf.reshape(pool2,80*80*64])
dense = tf.layers.dense(inputs=pool2_flat,units=1024,activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense,rate=0.4,training=mode == tf.estimator.ModeKeys.TRAIN)
#Logits Layer
logits = tf.layers.dense(inputs=dropout,units=3)
predictions = {
#Generate predictions (for PREDICT and EVAL mode)
"classes": tf.argmax(input=logits,axis=1),#Add ''softmax_tensor'' to the graph. It is used for PREDICT and by the
#''logging_hook''
"probabilities": tf.nn.softmax(logits,name="softmax_tensor")
}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode,predictions=predictions)
# Calculate Loss (for both TRAIN and EVAL modes
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels,logits=logits)
# Configure the Training Op (for TRAIN mode)
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode,loss=loss,train_op=train_op)
# Add evaluation metrics (for EVAL mode)
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(
labels=labels,predictions=predictions["classes"])}
return tf.estimator.EstimatorSpec(
mode=mode,eval_metric_ops=eval_metric_ops)
def main(unused_argv):
''''''
#Load training and eval data
mnist = tf.contrib.learn.datasets.load_dataset("mnist")
train_data = mnist.train.images
train_labels = np.asarray(mnist.train.labels,dtype=np.int32)
eval_data = mnist.test.images
eval_labels = np.asarray(mnist.test.labels,dtype=np.int32)
''''''
#Load cats,dogs and cars image in local folder
X_data = []
files = glob.glob("data/cats/*.jpg")
for myFile in files:
image = cv2.imread (myFile)
imgR = cv2.resize(image,(320,320))
imgNR = imgR/255
X_data.append(imgNR)
files = glob.glob("data/dogs/*.jpg")
for myFile in files:
image = cv2.imread (myFile)
imgR = cv2.resize(image,320))
imgNR = imgR/255
X_data.append(imgNR)
files = glob.glob ("data/cars/*.jpg")
for myFile in files:
image = cv2.imread (myFile)
imgR = cv2.resize(image,320))
imgNR = imgR/255
X_data.append (imgNR)
#print(''X_data count:'',len(X_data))
X_data_Val = []
files = glob.glob ("data/Validation/cats/*.jpg")
for myFile in files:
image = cv2.imread (myFile)
imgR = cv2.resize(image,320))
imgNR = imgR/255
X_data_Val.append (imgNR)
files = glob.glob ("data/Validation/dogs/*.jpg")
for myFile in files:
image = cv2.imread (myFile)
imgR = cv2.resize(image,320))
imgNR = imgR/255
X_data_Val.append (imgNR)
files = glob.glob ("data/Validation/cars/*.jpg")
for myFile in files:
image = cv2.imread (myFile)
imgR = cv2.resize(image,320))
imgNR = imgR/255
X_data_Val.append (imgNR)
#Feed One hot lables
Y_Label = np.zeros(shape=(300,1))
for el in range(0,100):
Y_Label[el]=[0]
for el in range(101,200):
Y_Label[el]=[1]
for el in range(201,300):
Y_Label[el]=[2]
onehot_encoder = OneHotEncoder(sparse=False)
#Y_Label_RS = Y_Label.reshape(len(Y_Label),1)
Y_Label_Encode = onehot_encoder.fit_transform(Y_Label)
#print(''Y_Label_Encode shape:'',Y_Label_Encode.shape)
Y_Label_Val = np.zeros(shape=(30,10):
Y_Label_Val[el]=[0]
for el in range(11,20):
Y_Label_Val[el]=[1]
for el in range(21,30):
Y_Label_Val[el]=[2]
#Y_Label_Val_RS = Y_Label_Val.reshape(len(Y_Label_Val),1)
Y_Label_Val_Encode = onehot_encoder.fit_transform(Y_Label_Val)
#print(''Y_Label_Val_Encode shape:'',Y_Label_Val_Encode.shape)
train_data = np.array(X_data)
train_data = train_data.astype(np.float32)
train_labels = np.asarray(Y_Label_Encode,dtype=np.int32)
eval_data = np.array(X_data_Val)
eval_data = eval_data.astype(np.float32)
eval_labels = np.asarray(Y_Label_Val_Encode,dtype=np.int32)
print(train_data.shape)
print(train_labels.shape)
#Create the Estimator
mnist_classifier = tf.estimator.Estimator(
model_fn=cnn_model_fn,model_dir="/tmp/mnist_convnet_model")
# Set up logging for predictions
tensor_to_log = {"probabilities": "softmax_tensor"}
logging_hook = tf.train.LoggingTensorHook(
tensors=tensor_to_log,every_n_iter=50)
# Train the model
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": train_data},y=train_labels,batch_size=100,num_epochs=None,shuffle=True)
mnist_classifier.train(
input_fn=train_input_fn,#original steps are 20000
steps=1,hooks=[logging_hook])
# Evaluate the model and print results
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": eval_data},y=eval_labels,num_epochs=1,shuffle=False)
eval_results = mnist_classifier.evaluate(input_fn=eval_input_fn)
print(eval_results)
if __name__ == "__main__":
tf.app.run()
)")
1、求 loss:tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits (logits, labels, name=None))
1.求loss:
tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None))
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes([Y1,Y2,Y3...]其中Y1,Y2,Y3...分别代表了是属于该类的概率第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵,公式如下:
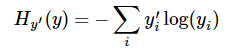
其中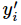 指代实际的标签中第i个的值(用mnist数据举例,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
指代实际的标签中第i个的值(用mnist数据举例,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
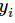 就是
就是softmax的输出向量[Y1,Y2,Y3...]
显而易见,预测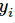 越准确,结果的值越小(别忘了前面还有负号),最后求一个平均,得到我们想要的loss
越准确,结果的值越小(别忘了前面还有负号),最后求一个平均,得到我们想要的loss
注意!!!这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到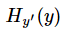 ,如果求loss,则要做一步
,如果求loss,则要做一步tf.reduce_mean操作,对向量求均值!
import tensorflow as tf
logits=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
y=tf.nn.softmax(logits)
y_=tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]])
cross_entropy = -tf.reduce_sum(y_*tf.log(y)) #交叉熵公式
cross_entropy2=tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_))#代入函数
with tf.Session() as sess:
softmax=sess.run(y)
c_e = sess.run(cross_entropy)
c_e2 = sess.run(cross_entropy2)
print("step1:softmax result=")
print(softmax)
print("step2:cross_entropy result=")
print(c_e)
print("Function(softmax_cross_entropy_with_logits) result=")
print(c_e2)step1:softmax result=
[[0.09003057 0.24472848 0.66524094]
[0.09003057 0.24472848 0.66524094]
[0.09003057 0.24472848 0.66524094]]
step2:cross_entropy result=
1.222818
Function(softmax_cross_entropy_with_logits) result=
1.2228179

binary_cross_entropy_with_logits 产生负输出
如何解决binary_cross_entropy_with_logits 产生负输出?
我正在开发一个机器学习模型来检测骨骼图像中的骨骼。 我使用的是 pytorch,我使用的模型是 hourglass model。
当我使用 binary_cross_entropy_with_logits 时,我可以看到损失减少,但是当我尝试测试模型时,我注意到:
- 输出永远不会大于零。
- 输出不正确(未检测到骨骼)。
这就是我调用 binary_cross_entropy_with_logits 的方式
loss = F.binary_cross_entropy_with_logits(ouputs[i],Y,weight=Mask,reduction=''sum'') / Mask.sum()
这就是我做测试的方式
ouput = model(X)
ouput_sig = torch.sigmoid(ouput)
plot_voxel2d(ouput_soft1)
如果我像这样使用 mse 损失,完全相同的模型、输入、目标可以工作:
loss = torch.sum(((ouputs[i] - Y) ** 2) * Mask) / torch.sum(Mask)
我确保目标在 0 和 1 之间。 感谢您的帮助。
解决方法
以下代码块是 G. Hinton 在他的课程中提出的:http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
optimizer = optim.RMSprop(net.parameters(),lr=0.005,weight_decay=1e-8)
if net.n_classes > 1:
criterion = nn.CrossEntropyLoss()
else:
criterion = nn.BCEWithLogitsLoss()
然后您将需要以与以下代码示例类似的方式使用 sigmoid(Torch Functional:F.sigmoid):
for isample,sample in enumerate(ds):
mask_torch = net2(sample[''image''][None,:,:].type(torch.cuda.FloatTensor))
mask = (F.sigmoid(mask_torch.type(torch.cuda.FloatTensor)) > 0.4925099).type(torch.FloatTensor)
print(mask)
for ichan in range(3):
ax[isample,ichan].imshow(sample[''image''][ichan].cpu())
ax[isample,3].imshow(sample[''mask''][0].cpu())
ax[isample,4].imshow(mask[0,0].cpu().detach().numpy())
将 sigmoid 放在所有层之后的最后。它看起来像这样:
对于 sigmoid,它看起来像这样:
def forward(self,x):
#print(x.shape)
x = self.layer_1(x)
x = self.layer_2(x)
x = self.layer_3(x)
logits = F.sigmoid(self.outc(x))
return logits

Difference between nn.softmax & softmax_cross_entropy_with_logits & softmax_cross_entropy...
nn.softmax 和 softmax_cross_entropy_with_logits 和 softmax_cross_entropy_with_logits_v2 的区别
You have every reason to be confused, because in supervised learning one doesn''t need to backpropagate to labels. They are considered fixed ground truth and only the weights need to be adjusted to match them.
But in some cases, the labels themselves may come from a differentiable source, another network. One example might be adversarial learning. In this case, both networks might benefit from the error signal. That''s the reason why tf.nn.softmax_cross_entropy_with_logits_v2 was introduced. Note that when the labels are the placeholders (which is also typical), there is no difference if the gradient through flows or not, because there are no variables to apply gradient to.
import tensorflow as tf
import numpy as np
Truth = np.array([0,0,1,0])
Pred_logits = np.array([3.5,2.1,7.89,4.4])
loss = tf.nn.softmax_cross_entropy_with_logits(labels=Truth,logits=Pred_logits)
loss2 = tf.nn.softmax_cross_entropy_with_logits_v2(labels=Truth,logits=Pred_logits)
loss3 = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(Truth),logits=Pred_logits)
with tf.Session() as sess:
print(sess.run(loss))
print(sess.run(loss2))
print(sess.run(loss3))

from_logits = True和from_logits =False获得针对UNet的tf.losses.CategoricalCrossentropy的不同训练结果
如果我Softmax Activation像这样设置最后一层,我正在用unet进行图像语义分割工作:
...
conv9 = Conv2D(n_classes,(3,3),padding = 'same')(conv9)
conv10 = (Activation('softmax'))(conv9)
model = Model(inputs,conv10)
return model
...
然后使用即使只有一个训练图像loss =
tf.keras.losses.CategoricalCrossentropy(from_logits=False) ,训练也 不会收敛 。
但是,如果我没有Softmax Activation像这样设置最后一层:
...
conv9 = Conv2D(n_classes,padding = 'same')(conv9)
model = Model(inputs,conv9)
return model
...
然后使用loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True) 训练将
收敛 为一个训练图像。
我的groundtruth数据集是这样生成的:
X = []
Y = []
im = cv2.imread(impath)
X.append(im)
seg_labels = np.zeros((height,width,n_classes))
for spath in segpaths:
mask = cv2.imread(spath,0)
seg_labels[:,:,c] += mask
Y.append(seg_labels.reshape(width*height,n_classes))
为什么?我的用法有问题吗?
这是我的git实验代码:https :
//github.com/honeytidy/unet
您可以检出并运行(可以在cpu上运行)。您可以更改激活层和CategoricalCrossentropy的from_logits并查看我说的内容。
今天关于ValueError:无法压缩dim [1],预期尺寸为1,为'sparse_softmax_cross_entropy_loss获得了3的讲解已经结束,谢谢您的阅读,如果想了解更多关于1、求 loss:tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits (logits, labels, name=None))、binary_cross_entropy_with_logits 产生负输出、Difference between nn.softmax & softmax_cross_entropy_with_logits & softmax_cross_entropy...、from_logits = True和from_logits =False获得针对UNet的tf.losses.CategoricalCrossentropy的不同训练结果的相关知识,请在本站搜索。
本文标签:




