在本文中,您将会了解到关于Docker快速搭建Clickhouse集群(3分片3副本)的新资讯,同时我们还将为您解释dockerclickhouse集群的相关在本文中,我们将带你探索Docker快速搭
在本文中,您将会了解到关于Docker快速搭建Clickhouse集群(3分片3副本)的新资讯,同时我们还将为您解释docker clickhouse集群的相关在本文中,我们将带你探索Docker快速搭建Clickhouse集群(3分片3副本)的奥秘,分析docker clickhouse集群的特点,并给出一些关于ClickHouse (02) ClickHouse 架构设计介绍概述与 ClickHouse 数据分片设计、ClickHouse docker in practice.、Clickhouse 副本表和分片表(高可用)、ClickHouse 表引擎 & ClickHouse性能调优 - ClickHouse团队 Alexey Milovidov的实用技巧。
本文目录一览:- Docker快速搭建Clickhouse集群(3分片3副本)(docker clickhouse集群)
- ClickHouse (02) ClickHouse 架构设计介绍概述与 ClickHouse 数据分片设计
- ClickHouse docker in practice.
- Clickhouse 副本表和分片表(高可用)
- ClickHouse 表引擎 & ClickHouse性能调优 - ClickHouse团队 Alexey Milovidov
(docker clickhouse集群)")
Docker快速搭建Clickhouse集群(3分片3副本)(docker clickhouse集群)
背景
前文简单介绍了下Clickhouse的安装和客户端使用,在实际生产环境中,Clickhouse常常是以集群模式部署的,由于很多系统不满足sse4.2指令,这里使用docker来搭建一个Clickhouse的集群。
1. 环境说明
1.1 机器列表
机器名 | IP | 配置 | 操作系统 | 部署的服务 | 备注 |
server01 | 192.168.21.21 | 8c8g | centos7.3 | clickhouserver(cs01-01)和 clickhouserver(cs01-02) | clickhouse01-01: 实例1, 端口: tcp 9000, http 8123, 同步端口9009, 类型: 分片1, 副本1 clickhouse01-02: 实例2, 端口: tcp 9001, http 8124, 同步端口9010, 类型: 分片2, 副本2 (clickhouse2的副本) |
server02 | 192.168.21.69 | 8c8g | centos7.3 | clickhouserver(cs02-01)和 clickhouserver(cs02-02) | clickhouse02-01: 实例1, 端口: tcp 9000, http 8123, 同步端口9009, 类型: 分片2, 副本1 clickhouse02-02: 实例2, 端口: tcp 9001, http 8124, 同步端口9010, 类型: 分片3, 副本2 (clickhouse3的副本) |
server03 | 192.168.21.6 | 8c8g | centos7.3 | clickhouserver(cs03-01)和 clickhouserver(cs03-02) | clickhouse03-01: 实例1, 端口: tcp 9000, http 8123, 同步端口9009, 类型: 分片3, 副本1 clickhouse03-02: 实例2, 端口: tcp 9001, http 8124, 同步端口9010, 类型: 分片1, 副本2 (clickhouse1的副本) |
1.2 机器初始化
1.2.1 配置host
执行:vi /etc/hosts, 加入下面三行:
192.168.21.21 server01
192.168.21.69 server02
192.168.21.6 server03
1.2.2 安装docker
每台机器上均安装相同版本的docker
参照:docker环境搭建
1.2.3 安装Zookeeper
参照zookper集群搭建(3节点)安装
1.3 目录初始化
1.3.1 创建对应本地路径
分别在三台服务器,创建数据存储目录:
mkdir /data/clickhouse
1.3.2 获取clickhouse-server的配置
1)在server01服务器做如下操作
先按照官方教程的docker命令启动Clickhouse-Server
docker run -d --name clickhouse-server --ulimit nofile=262144:262144 --volume=/data/clickhouse/:/var/lib/clickhouse yandex/clickhouse-server
2)启动完成后,复制容器内的配置文件到本机目录下
#拷贝容器内容的配置到/etc目录下 docker cp clickhouse-server:/etc/clickhouse-server/ /etc/ #将server01上的目录重命名 cp -rf /etc/clickhouse-server/ /etc/clickhouse-server01/ cp -rf /etc/clickhouse-server/ /etc/clickhouse-server02/
3)然后将/etc/clickhouse-server/ 分别拷贝到每个机器上
#拷贝配置到server02上 scp /etc/clickhouse-server/ server02:/etc/clickhouse-server01/ scp /etc/clickhouse-server/ server02:/etc/clickhouse-server02/ #拷贝配置到server03上 scp /etc/clickhouse-server/ server03:/etc/clickhouse-server01/ scp /etc/clickhouse-server/ server03:/etc/clickhouse-server02/
2. 集群环境搭建
2.1 集群环境拓扑图

集群环境说明:
clickhouse01-01: 实例1, 端口: tcp 9000, http 8123, 同步端口9009, 类型: 分片1, 副本1
clickhouse01-02: 实例2, 端口: tcp 9001, http 8124, 同步端口9010, 类型: 分片2, 副本2 (clickhouse2的副本)
clickhouse02-01: 实例1, 端口: tcp 9000, http 8123, 同步端口9009, 类型: 分片2, 副本1
clickhouse02-02: 实例2, 端口: tcp 9001, http 8124, 同步端口9010, 类型: 分片3, 副本2 (clickhouse3的副本)
clickhouse03-01: 实例1, 端口: tcp 9000, http 8123, 同步端口9009, 类型: 分片3, 副本1
clickhouse03-02: 实例2, 端口: tcp 9001, http 8124, 同步端口9010, 类型: 分片1, 副本2 (clickhouse1的副本)
2.2 配置集群
2.2.1 待修改的配置文件
需要修改的配置有两个(如果有需要也可以配置user.xml):
- /etc/clickhouse-server/config.xml
- /etc/clickhouse-server/metrika.xml(新增文件)
2.2.2 server1上配置clickhouse-server的实例
2.2.2.1 clickhouse-01-01的配置:
1)/etc/clickhouse-server01/config.xml(其他实例此配置内容和这个一样就行)
修改include from节点为实际的引用到的文件
<!-- If element has 'incl' attribute, then for it's value will be used corresponding substitution from another file. By default, path to file with substitutions is /etc/metrika.xml. It Could be changed in config in 'include_from' element. Values for substitutions are specified in /yandex/name_of_substitution elements in that file. --> <include_from>/etc/clickhouse-server/metrika.xml</include_from> <listen_host>0.0.0.0</listen_host> <listen_host>127.0.0.1</listen_host>
2)/etc/clickhouse-server01/metrika.xml(所有实例的配置内容都和这个一样就行)
<!--所有实例均使用这个集群配置,不用个性化 --> <yandex> <!-- 集群配置 --> <!-- clickhouse_remote_servers所有实例配置都一样 --> <!-- 集群配置 --> <clickhouse_remote_servers> <cluster_3s_1r> <!-- 数据分片1 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server01</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server03</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片2 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server02</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server01</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片3 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server03</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server02</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> </cluster_3s_1r> </clickhouse_remote_servers> <!-- ZK --> <!-- zookeeper_servers所有实例配置都一样 --> <zookeeper-servers> <node index="1"> <host>192.168.21.66</host> <port>2181</port> </node> <node index="2"> <host>192.168.21.57</host> <port>2181</port> </node> <node index="3"> <host>192.168.21.17</host> <port>2181</port> </node> </zookeeper-servers> <!-- marcos每个实例配置不一样 分片1, 副本1 --> <macros> <layer>01</layer> <shard>01</shard> <replica>cluster01-01-1</replica> </macros> <networks> <ip>::/0</ip> </networks> <!-- 数据压缩算法 --> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex>
2.2.2.2 clickhouse-01-02的配置:
1)/etc/clickhouse-server02/metrika.xml(所有实例的配置内容都和这个一样就行)
<!--所有实例均使用这个集群配置,不用个性化 --> <yandex> <!-- 集群配置 --> <!-- clickhouse_remote_servers所有实例配置都一样 --> <clickhouse_remote_servers> <cluster_3s_1r> <!-- 数据分片1 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server01</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server03</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片2 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server02</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server01</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片3 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server03</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server02</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> </cluster_3s_1r> </clickhouse_remote_servers> <!-- ZK --> <!-- zookeeper_servers所有实例配置都一样 --> <zookeeper-servers> <node index="1"> <host>192.168.21.66</host> <port>2181</port> </node> <node index="2"> <host>192.168.21.57</host> <port>2181</port> </node> <node index="3"> <host>192.168.21.17</host> <port>2181</port> </node> </zookeeper-servers> <!-- marcos每个实例配置不一样 分片2, 副本2--> <macros> <layer>01</layer> <shard>02</shard> <replica>cluster01-02-2</replica> </macros> <networks> <ip>::/0</ip> </networks> <!-- 数据压缩算法 --> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex>
2.2.3 server2上配置clickhouse-server的实例
2.2.3.1 clickhouse-02-01的配置:
/etc/clickhouse-server01/metrika.xml
<!--所有实例均使用这个集群配置,不用个性化 --> <yandex> <!-- 集群配置 --> <!-- clickhouse_remote_servers所有实例配置都一样 --> <clickhouse_remote_servers> <cluster_3s_1r> <!-- 数据分片1 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server01</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server03</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片2 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server02</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server01</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片3 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server03</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server02</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> </cluster_3s_1r> </clickhouse_remote_servers> <!-- ZK --> <!-- zookeeper_servers所有实例配置都一样 --> <zookeeper-servers> <node index="1"> <host>192.168.21.66</host> <port>2181</port> </node> <node index="2"> <host>192.168.21.57</host> <port>2181</port> </node> <node index="3"> <host>192.168.21.17</host> <port>2181</port> </node> </zookeeper-servers> <!-- marcos每个实例配置不一样 分片2, 副本1--> <macros> <layer>01</layer> <shard>02</shard> <replica>cluster01-02-1</replica> </macros> <networks> <ip>::/0</ip> </networks> <!-- 数据压缩算法 --> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex>
2.2.3.2 clickhouse-02-02的配置:
/etc/clickhouse-server02/metrika.xml
<!--所有实例均使用这个集群配置,不用个性化 --> <yandex> <!-- 集群配置 --> <!-- clickhouse_remote_servers所有实例配置都一样 --> <clickhouse_remote_servers> <cluster_3s_1r> <!-- 数据分片1 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server01</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server03</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片2 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server02</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server01</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片3 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server03</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server02</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> </cluster_3s_1r> </clickhouse_remote_servers> <!-- ZK --> <!-- zookeeper_servers所有实例配置都一样 --> <zookeeper-servers> <node index="1"> <host>192.168.21.66</host> <port>2181</port> </node> <node index="2"> <host>192.168.21.57</host> <port>2181</port> </node> <node index="3"> <host>192.168.21.17</host> <port>2181</port> </node> </zookeeper-servers> <!-- marcos每个实例配置不一样 分片3, 副本2--> <macros> <layer>01</layer> <shard>03</shard> <replica>cluster01-03-2</replica> </macros> <networks> <ip>::/0</ip> </networks> <!-- 数据压缩算法 --> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex>
2.2.4 server3上配置clickhouse-server的实例
2.2.4.1 clickhouse-03-01的配置:
1)/etc/clickhouse-server01/metrika.xml
<!--所有实例均使用这个集群配置,不用个性化 --> <yandex> <!-- 集群配置 --> <!-- clickhouse_remote_servers所有实例配置都一样 --> <clickhouse_remote_servers> <cluster_3s_1r> <!-- 数据分片1 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server01</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server03</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片2 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server02</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server01</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片3 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server03</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server02</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> </cluster_3s_1r> </clickhouse_remote_servers> <!-- ZK --> <!-- zookeeper_servers所有实例配置都一样 --> <zookeeper-servers> <node index="1"> <host>192.168.21.66</host> <port>2181</port> </node> <node index="2"> <host>192.168.21.57</host> <port>2181</port> </node> <node index="3"> <host>192.168.21.17</host> <port>2181</port> </node> </zookeeper-servers> <!-- marcos每个实例配置不一样 分片3, 副本1--> <macros> <layer>01</layer> <shard>03</shard> <replica>cluster01-03-1</replica> </macros> <networks> <ip>::/0</ip> </networks> <!-- 数据压缩算法 --> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex>
2.2.4.2 clickhouse-03-02的配置:
1. /etc/clickhouse-server02/metrika.xml
<!--所有实例均使用这个集群配置,不用个性化 --> <yandex> <!-- 集群配置 --> <!-- clickhouse_remote_servers所有实例配置都一样 --> <clickhouse_remote_servers> <cluster_3s_1r> <!-- 数据分片1 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server01</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server03</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片2 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server02</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server01</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> <!-- 数据分片3 --> <shard> <internal_replication>true</internal_replication> <replica> <host>server03</host> <port>9000</port> <user>default</user> <password></password> </replica> <replica> <host>server02</host> <port>9001</port> <user>default</user> <password></password> </replica> </shard> </cluster_3s_1r> </clickhouse_remote_servers> <!-- ZK --> <!-- zookeeper_servers所有实例配置都一样 --> <zookeeper-servers> <node index="1"> <host>192.168.21.66</host> <port>2181</port> </node> <node index="2"> <host>192.168.21.57</host> <port>2181</port> </node> <node index="3"> <host>192.168.21.17</host> <port>2181</port> </node> </zookeeper-servers> <!-- marcos每个实例配置不一样 分片1, 副本2--> <macros> <layer>01</layer> <shard>01</shard> <replica>cluster01-01-2</replica> </macros> <networks> <ip>::/0</ip> </networks> <!-- 数据压缩算法 --> <clickhouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </clickhouse_compression> </yandex>
2.3 运行clickhouse集群
2.3.1 运行clickhouse01-01实例
登陆到server01:ssh server01
#先删除cs01-01容器 docker rm -f cs01-01 #运行Clickhouse-server docker run -d \ --name cs01-01 \ --ulimit nofile=262144:262144 \ --volume=/data/clickhouse01/:/var/lib/clickhouse \ --volume=/etc/clickhouse-server01/:/etc/clickhouse-server/ \ --add-host server01:192.168.21.21 \ --add-host server02:192.168.21.69 \ --add-host server03:192.168.21.6 \ --add-host i-r9es2e0q:192.168.21.21 \ --add-host i-o91d619w:192.168.21.69 \ --add-host i-ldipmbwa:192.168.21.6 \ --hostname $(hostname) \ -p 9000:9000 \ -p 8123:8123 \ -p 9009:9009 \ yandex/clickhouse-server
说明:
--add-host参数:因为我们在配置文件中使用了hostname来指代我们的服务器,为了让容器能够识别,所以需要加此参数,对应的host配置会自动被添加到容器主机的/etc/hosts里面
--hostname参数:clickhouse中的system.clusters表会显示集群信息,其中is_local的属性如果不配置hostname的话clickhouse无法识别是否是当前本机。is_local都为0的话会影响集群操作,is_local通过clickhouse-client登录到任一clickhouse-server上查看:SELECT * FROM system.clusters;
--p参数:暴露容器中的端口到本机端口中。
2.3.2 运行clickhouse01-02实例
登陆到server01:ssh server01;
docker run -d \ --name cs01-02 \ --ulimit nofile=262144:262144 \ --volume=/data/clickhouse02/:/var/lib/clickhouse \ --volume=/etc/clickhouse-server02/:/etc/clickhouse-server/ \ --add-host server01:192.168.21.21 \ --add-host server02:192.168.21.69 \ --add-host server03:192.168.21.6 \ --add-host i-r9es2e0q:192.168.21.21 \ --add-host i-o91d619w:192.168.21.69 \ --add-host i-ldipmbwa:192.168.21.6 \ --hostname $(hostname) \ -p 9001:9000 \ -p 8124:8123 \ -p 9010:9009 \ yandex/clickhouse-server
2.3.3 运行clickhouse02-01实例
登陆到server02:ssh server02
docker run -d \ --name cs02-01 \ --ulimit nofile=262144:262144 \ --volume=/data/clickhouse01/:/var/lib/clickhouse \ --volume=/etc/clickhouse-server01/:/etc/clickhouse-server/ \ --add-host server01:192.168.21.21 \ --add-host server02:192.168.21.69 \ --add-host server03:192.168.21.6 \ --add-host i-r9es2e0q:192.168.21.21 \ --add-host i-o91d619w:192.168.21.69 \ --add-host i-ldipmbwa:192.168.21.6 \ --hostname $(hostname) \ -p 9000:9000 \ -p 8123:8123 \ -p 9009:9009 \ yandex/clickhouse-server
2.3.4 运行clickhouse02-02实例
登陆到server02:ssh server02
docker run -d \ --name cs02-02 \ --ulimit nofile=262144:262144 \ --volume=/data/clickhouse02/:/var/lib/clickhouse \ --volume=/etc/clickhouse-server02/:/etc/clickhouse-server/ \ --add-host server01:192.168.21.21 \ --add-host server02:192.168.21.69 \ --add-host server03:192.168.21.6 \ --add-host i-r9es2e0q:192.168.21.21 \ --add-host i-o91d619w:192.168.21.69 \ --add-host i-ldipmbwa:192.168.21.6 \ --hostname $(hostname) \ -p 9001:9000 \ -p 8124:8123 \ -p 9010:9009 \ yandex/clickhouse-server
2.3.5 运行clickhouse03-01实例
登陆到server03:ssh server03
docker run -d \ --name cs03-01 \ --ulimit nofile=262144:262144 \ --volume=/data/clickhouse01/:/var/lib/clickhouse \ --volume=/etc/clickhouse-server01/:/etc/clickhouse-server/ \ --add-host server01:192.168.21.21 \ --add-host server02:192.168.21.69 \ --add-host server03:192.168.21.6 \ --add-host i-r9es2e0q:192.168.21.21 \ --add-host i-o91d619w:192.168.21.69 \ --add-host i-ldipmbwa:192.168.21.6 \ --hostname $(hostname) \ -p 9000:9000 \ -p 8123:8123 \ -p 9009:9009 \ yandex/clickhouse-server
2.3.6 运行clickhouse03-02实例
登陆到server03:ssh server03
docker run -d \ --name cs03-02 \ --ulimit nofile=262144:262144 \ --volume=/data/clickhouse02/:/var/lib/clickhouse \ --volume=/etc/clickhouse-server02/:/etc/clickhouse-server/ \ --add-host server01:192.168.21.21 \ --add-host server02:192.168.21.69 \ --add-host server03:192.168.21.6 \ --add-host i-r9es2e0q:192.168.21.21 \ --add-host i-o91d619w:192.168.21.69 \ --add-host i-ldipmbwa:192.168.21.6 \ --hostname $(hostname) \ -p 9001:9000 \ -p 8124:8123 \ -p 9010:9009 \ yandex/clickhouse-server
2.4 clickhouse集群的数据操作
2.4.1 运行客户端连接clickhouse server
1)随便在哪一台实例的机器上执行如下(连不同的clickhouse实例只需要改下host和port的值即可)
docker run -it \ --rm \ --add-host server01:192.168.21.21 \ --add-host server02:192.168.21.69 \ --add-host server03:192.168.21.6 \ yandex/clickhouse-client \ --host server01 \ --port 9000
2)执行下如下命令查看下配置信息:
#需要看下,是否和metrika.xml配置的分片和副本信息一致,如果不一致,需要check下每个clickhouse-server实例的配置
#应该is_local显示为0,且分片和副本信息都正确
SELECT * FROM system.clusters;
2.4.2 创建本地复制表和分布式表
所有实例配置完上面这些之后,分别执行启动命令启动,然后所有实例都执行下面语句创建数据库:
例如在实例01-02上执行:
#执行Clickhouse client进入Clickhouse docker run -it --rm --add-host server01:192.168.21.21 --add-host server02:192.168.21.69 --add-host server03:192.168.21.6 \ yandex/clickhouse-client --host server01 --port 9001 ClickHouse client version 19.17.5.18 (official build). Connecting to server01:9001 as user default. Connected to ClickHouse server version 19.17.5 revision 54428. i-r9es2e0q :) CREATE DATABASE test; CREATE DATABASE test Ok.
2.4.3 创建复制表
然后对于所有实例分别创建对应的复制表,这里测试创建一个简单的表:
#在clickhouse01-01 9000上执行:
docker run -it --rm --add-host server01:192.168.21.21 --add-host server02:192.168.21.69 --add-host server03:192.168.21.6 \
yandex/clickhouse-client --host server01 --port 9000
#然后执行
CREATE TABLE test.device_thing_data (
time UInt64,
user_id String,
device_id String,
source_id String,
thing_id String,
identifier String,
value_int32 Int32,
value_float Float32,
value_double Float64,
value_string String,
value_enum Enum8('0'=0,'1'=1,'2'=2,'3'=3,'4'=4,'5'=5,'6'=6,'7'=7,'8'=8),
value_string_ex String,
value_array_string Array(String),
value_array_int32 Array(Int32),
value_array_float Array(Float32),
value_array_double Array(Float64),
action_date Date,
action_time DateTime
) Engine= ReplicatedMergeTree('/clickhouse/tables/01-01/device_thing_data','cluster01-01-1') PARTITION BY toYYYYMM(action_date) ORDER BY (user_id,device_id,thing_id,identifier,time,intHash64(time)) SAMPLE BY intHash64(time) SETTINGS index_granularity=8192
#在clickhouse01-02 9001上执行:
docker run -it --rm --add-host server01:192.168.21.21 --add-host server02:192.168.21.69 --add-host server03:192.168.21.6 \
yandex/clickhouse-client --host server01 --port 9001
然后执行
CREATE TABLE test.device_thing_data (
time UInt64,
user_id String,
device_id String,
source_id String,
thing_id String,
identifier String,
value_int32 Int32,
value_float Float32,
value_double Float64,
value_string String,
value_enum Enum8('0'=0,'1'=1,'2'=2,'3'=3,'4'=4,'5'=5,'6'=6,'7'=7,'8'=8),
value_string_ex String,
value_array_string Array(String),
value_array_int32 Array(Int32),
value_array_float Array(Float32),
value_array_double Array(Float64),
action_date Date,
action_time DateTime
) Engine= ReplicatedMergeTree('/clickhouse/tables/01-02/device_thing_data','cluster01-02-2') PARTITION BY toYYYYMM(action_date) ORDER BY (user_id,device_id,thing_id,identifier,time,intHash64(time)) SAMPLE BY intHash64(time) SETTINGS index_granularity=8192
#在clickhouse02-01 9000上执行:
docker run -it --rm --add-host server01:192.168.21.21 --add-host server02:192.168.21.69 --add-host server03:192.168.21.6 \
yandex/clickhouse-client --host server02 --port 9000
#然后执行
CREATE TABLE test.device_thing_data (
time UInt64,
user_id String,
device_id String,
source_id String,
thing_id String,
identifier String,
value_int32 Int32,
value_float Float32,
value_double Float64,
value_string String,
value_enum Enum8('0'=0,'1'=1,'2'=2,'3'=3,'4'=4,'5'=5,'6'=6,'7'=7,'8'=8),
value_string_ex String,
value_array_string Array(String),
value_array_int32 Array(Int32),
value_array_float Array(Float32),
value_array_double Array(Float64),
action_date Date,
action_time DateTime
) Engine= ReplicatedMergeTree('/clickhouse/tables/01-02/device_thing_data','cluster01-02-1') PARTITION BY toYYYYMM(action_date) ORDER BY (user_id,device_id,thing_id,identifier,time,intHash64(time)) SAMPLE BY intHash64(time) SETTINGS index_granularity=8192
#在clickhouse02-02 9001上执行:
docker run -it --rm --add-host server01:192.168.21.21 --add-host server02:192.168.21.69 --add-host server03:192.168.21.6 \
yandex/clickhouse-client --host server02 --port 9001
#然后执行
CREATE TABLE test.device_thing_data (
time UInt64,
user_id String,
device_id String,
source_id String,
thing_id String,
identifier String,
value_int32 Int32,
value_float Float32,
value_double Float64,
value_string String,
value_enum Enum8('0'=0,'1'=1,'2'=2,'3'=3,'4'=4,'5'=5,'6'=6,'7'=7,'8'=8),
value_string_ex String,
value_array_string Array(String),
value_array_int32 Array(Int32),
value_array_float Array(Float32),
value_array_double Array(Float64),
action_date Date,
action_time DateTime
) Engine= ReplicatedMergeTree('/clickhouse/tables/01-03/device_thing_data','cluster01-03-2') PARTITION BY toYYYYMM(action_date) ORDER BY (user_id,device_id,thing_id,identifier,time,intHash64(time)) SAMPLE BY intHash64(time) SETTINGS index_granularity=8192
#在clickhouse03-01 9000上执行:
docker run -it --rm --add-host server01:192.168.21.21 --add-host server02:192.168.21.69 --add-host server03:192.168.21.6 \
yandex/clickhouse-client --host server03 --port 9000
#然后执行
CREATE TABLE test.device_thing_data (
time UInt64,
user_id String,
device_id String,
source_id String,
thing_id String,
identifier String,
value_int32 Int32,
value_float Float32,
value_double Float64,
value_string String,
value_enum Enum8('0'=0,'1'=1,'2'=2,'3'=3,'4'=4,'5'=5,'6'=6,'7'=7,'8'=8),
value_string_ex String,
value_array_string Array(String),
value_array_int32 Array(Int32),
value_array_float Array(Float32),
value_array_double Array(Float64),
action_date Date,
action_time DateTime
) Engine= ReplicatedMergeTree('/clickhouse/tables/01-03/device_thing_data','cluster01-03-1') PARTITION BY toYYYYMM(action_date) ORDER BY (user_id,device_id,thing_id,identifier,time,intHash64(time)) SAMPLE BY intHash64(time) SETTINGS index_granularity=8192
#在clickhouse03-02 9001上执行:
docker run -it --rm --add-host server01:192.168.21.21 --add-host server02:192.168.21.69 --add-host server03:192.168.21.6 \
yandex/clickhouse-client --host server03 --port 9001
然后执行
CREATE TABLE test.device_thing_data (
time UInt64,
user_id String,
device_id String,
source_id String,
thing_id String,
identifier String,
value_int32 Int32,
value_float Float32,
value_double Float64,
value_string String,
value_enum Enum8('0'=0,'1'=1,'2'=2,'3'=3,'4'=4,'5'=5,'6'=6,'7'=7,'8'=8),
value_string_ex String,
value_array_string Array(String),
value_array_int32 Array(Int32),
value_array_float Array(Float32),
value_array_double Array(Float64),
action_date Date,
action_time DateTime
) Engine= ReplicatedMergeTree('/clickhouse/tables/01-01/device_thing_data','cluster01-01-2') PARTITION BY toYYYYMM(action_date) ORDER BY (user_id,device_id,thing_id,identifier,time,intHash64(time)) SAMPLE BY intHash64(time) SETTINGS index_granularity=81922.4.3 创建分布式表(用于查询)
然后创建完上面复制表之后,可以创建分布式表,分布式表只是作为一个查询引擎,本身不存储任何数据,查询时将sql发送到所有集群分片,然后进行进行处理和聚合后将结果返回给客户端,因此clickhouse限制聚合结果大小不能大于分布式表节点的内存,当然这个一般条件下都不会超过;分布式表可以所有实例都创建,也可以只在一部分实例创建,这个和业务代码中查询的示例一致,建议设置多个,当某个节点挂掉时可以查询其他节点上的表,分布式表的建表语句如下:
#在clickhouse-server集群上一次性创建所有的分布式表,操作卡主了。原因不明 CREATE TABLE device_thing_data_all ON CLUSTER cluster_3s_1r AS test.device_thing_data ENGINE = distributed(cluster_3s_1r, default, device_thing_data, rand()) #如下这个需要每个机器上都操作一遍 CREATE TABLE device_thing_data_all AS test.device_thing_data ENGINE = distributed(cluster_3s_1r, test, device_thing_data, rand())
2.4.4 测试可用性
#客户端连接到某个clickhouse-server实例(例如cs01-01)
#查询分布式表,此时没有查询到数据
select * from image_label_all;
#在cs01-01上执行如下查看是否有数据
#查询本地复制表,此时没有查询到数据
select * from test.device_thing_data;
#往复制表中表里插入一条数据
INSERT INTO test.device_thing_data; (user_id) VALUES ('1')
#由于刚才在cs01-01上插入一条数据,所以应该有数据了
select * from test.device_thing_data;
#查询分布式表,也有数据了
select * from image_label_all;
#在cs03-02上查询复制表的数据(由于cs03-02是cs01-01的副本,所以数据被自动同步过来了),所以应该有数据了
select * from test.device_thing_data;
#在cs03-01上插入一条数据,此时应该会把数据同步到cs02-02上
INSERT INTO test.device_thing_data (user_id) VALUES ('2')
#再次查询分布式表,此时应该查到cs03-01和cs01-01上的两条数据
select * from image_label_all;博主:测试生财(一个不为996而996的测开码农)
座右铭:专注测试开发与自动化运维,努力读书思考写作,为内卷的人生奠定财务自由。
内容范畴:技术提升,职场杂谈,事业发展,阅读写作,投资理财,健康人生。
csdn:https://blog.csdn.net/ccgshigao
博客园:https://www.cnblogs.com/qa-freeroad/
51cto:https://blog.51cto.com/14900374
在码农的苦闷岁月里,期待我们一起成长,欢迎关注,感谢拍砖!
 ClickHouse 架构设计介绍概述与 ClickHouse 数据分片设计")
ClickHouse (02) ClickHouse 架构设计介绍概述与 ClickHouse 数据分片设计
ClickHouse 核心架构设计是怎么样的?ClickHouse 核心架构模块分为两个部分:ClickHouse 执行过程架构和 ClickHouse 数据存储架构,下面分别详细介绍。
ClickHouse 执行过程架构
总的来说,结合目前搜集到的一些资料,可以看到目前 ClickHouse 核心架构由下图构成,主要的抽象模块是 Column、DataType、Block、Functions、Storage、Parser 与 Interpreter。
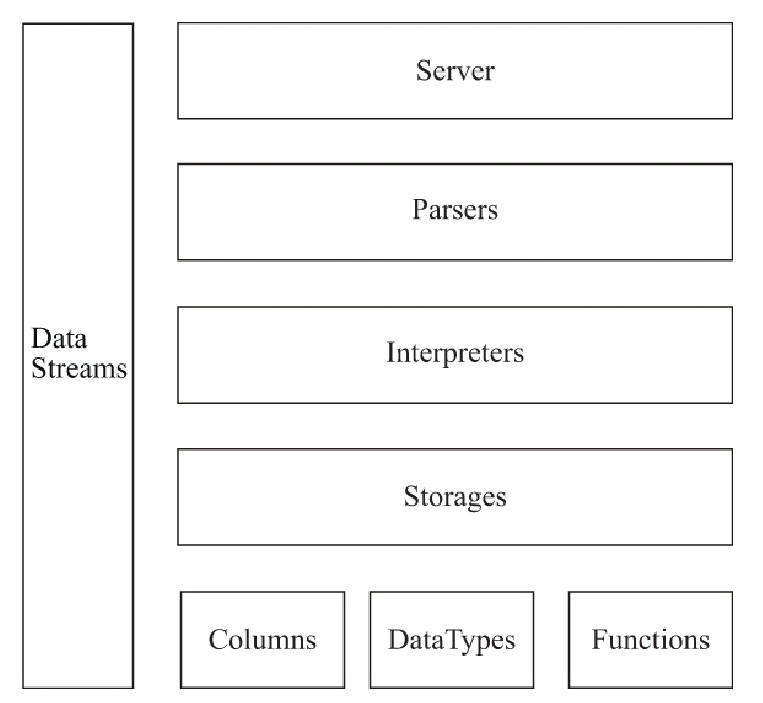
简单来说,就是一条 sql, 会经由 Parser 与 Interpreter,解析和执行,通过调用 Column、DataType、Block、Functions、Storage 等模块,最终返回数据,下面是各个模块具体的介绍。
Columns
表示内存中的列(实际上是列块),需使用 IColumn 接口。该接口提供了用于实现各种关系操作符的辅助方法。几乎所有的操作都是不可变的:这些操作不会更改原始列,但是会创建一个新的修改后的列。
Column 对象分为接口和实现两个部分,在 IColumn 接口对象中,定义了对数据进行各种关系运算的方法,例如插入数据的 insertRangeFrom 和 insertFrom 方法、用于分页的 cut,以及用于过滤的 filter 方法等。而这些方法的具体实现对象则根据数据类型的不同,由相应的对象实现,例如 ColumnString、ColumnArray 和 ColumnTuple 等。
Field
表示单个值,有时候也可能需要处理单个值,可以使用 Field。Field 是 UInt64、Int64、Float64、String 和 Array 组成的联合。与 Column 对象的泛化设计思路不同,Field 对象使用了聚合的设计模式。在 Field 对象内部聚合了 Null、UInt64、String 和 Array 等 13 种数据类型及相应的处理逻辑。
DataType
IDataType 负责序列化和反序列化:读写二进制或文本形式的列或单个值构成的块。IDataType 直接与表的数据类型相对应。比如,有 DataTypeUInt32、DataTypeDateTime、DataTypeString 等数据类型。
IDataType 与 IColumn 之间的关联并不大。不同的数据类型在内存中能够用相同的 IColumn 实现来表示。比如,DataTypeUInt32 和 DataTypeDateTime 都是用 ColumnUInt32 或 ColumnConstUInt32 来表示的。另外,相同的数据类型也可以用不同的 IColumn 实现来表示。比如,DataTypeUInt8 既可以使用 ColumnUInt8 来表示,也可以使用过 ColumnConstUInt8 来表示。
IDataType 仅存储元数据。比如,DataTypeUInt8 不存储任何东西(除了 vptr);DataTypeFixedString 仅存储 N(固定长度字符串的串长度)。
IDataType 具有针对各种数据格式的辅助函数。比如如下一些辅助函数:序列化一个值并加上可能的引号;序列化一个值用于 JSON 格式;序列化一个值作为 XML 格式的一部分。辅助函数与数据格式并没有直接的对应。比如,两种不同的数据格式 Pretty 和 TabSeparated 均可以使用 IDataType 接口提供的 serializeTextEscaped 这一辅助函数。
Block
Block 是表示内存中表的子集(chunk)的容器,是由三元组:(IColumn,IDataType, 列名) 构成的集合。在查询执行期间,数据是按 Block 进行处理的。如果我们有一个 Block,那么就有了数据(在 IColumn 对象中),有了数据的类型信息告诉我们如何处理该列,同时也有了列名(来自表的原始列名,或人为指定的用于临时计算结果的名字)。
当我们遍历一个块中的列进行某些函数计算时,会把结果列加入到块中,但不会更改函数参数中的列,因为操作是不可变的。之后,不需要的列可以从块中删除,但不是修改。这对于消除公共子表达式非常方便。
Block 用于处理数据块。注意,对于相同类型的计算,列名和类型对不同的块保持相同,仅列数据不同。最好把块数据(block data)和块头(block header)分离开来,因为小块大小会因复制共享指针和列名而带来很高的临时字符串开销。
Block Streams
块流用于处理数据。我们可以使用块流从某个地方读取数据,执行数据转换,或将数据写到某个地方。IBlockInputStream 具有 read 方法,其能够在数据可用时获取下一个块。IBlockOutputStream 具有 write 方法,其能够将块写到某处。
块流负责:
- 读或写一个表。表仅返回一个流用于读写块。
- 完成数据格式化。比如,如果你打算将数据以 Pretty 格式输出到终端,你可以创建一个块输出流,将块写入该流中,然后进行格式化。
- 执行数据转换。假设你现在有 IBlockInputStream 并且打算创建一个过滤流,那么你可以创建一个 FilterBlockInputStream 并用 IBlockInputStream 进行初始化。之后,当你从 FilterBlockInputStream 中拉取块时,会从你的流中提取一个块,对其进行过滤,然后将过滤后的块返回给你。查询执行流水线就是以这种方式表示的。
Storage
IStorage 接口表示一张表。该接口的不同实现对应不同的表引擎。比如 StorageMergeTree、StorageMemory 等。这些类的实例就是表。
IStorage 中最重要的方法是 read 和 write,除此之外还有 alter、rename 和 drop 等方法。read 方法接受如下参数:需要从表中读取的列集,需要执行的 AST 查询,以及所需返回的流的数量。read 方法的返回值是一个或多个 IBlockInputStream 对象,以及在查询执行期间在一个表引擎内完成的关于数据处理阶段的信息。
在大多数情况下,read 方法仅负责从表中读取指定的列,而不会进行进一步的数据处理。进一步的数据处理均由查询解释器完成,不由 IStorage 负责。
但是也有值得注意的例外:AST 查询被传递给 read 方法,表引擎可以使用它来判断是否能够使用索引,从而从表中读取更少的数据。有时候,表引擎能够将数据处理到一个特定阶段。比如,StorageDistributed 可以向远程服务器发送查询,要求它们将来自不同的远程服务器能够合并的数据处理到某个阶段,并返回预处理后的数据,然后查询解释器完成后续的数据处理。
Parser 与 Interpreter
Parser 和 Interpreter 是非常重要的两组接口:Parser 分析器负责创建 AST 对象;而 Interpreter 解释器则负责解释 AST,并进一步创建查询的执行管道。它们与 IStorage 一起,串联起了整个数据查询的过程。Parser 分析器可以将一条 SQL 语句以递归下降的方法解析成 AST 语法树的形式。不同的 SQL 语句,会经由不同的 Parser 实现类解析。例如,有负责解析 DDL 查询语句的 ParserRenameQuery、ParserDropQuery 和 ParserAlterQuery 解析器,也有负责解析 INSERT 语句的 ParserInsertQuery 解析器,还有负责 SELECT 语句的 ParserSelectQuery 等。
Interpreter 解释器的作用就像 Service 服务层一样,起到串联整个查询过程的作用,它会根据解释器的类型,聚合它所需要的资源。首先它会解析 AST 对象;然后执行 “业务逻辑”(例如分支判断、设置参数、调用接口等);最终返回 IBlock 对象,以线程的形式建立起一个查询执行管道。
Functions
函数既有普通函数,也有聚合函数。
普通函数不会改变行数 - 它们的执行看起来就像是独立地处理每一行数据。实际上,函数不会作用于一个单独的行上,而是作用在以 Block 为单位的数据上,以实现向量查询执行。
还有一些杂项函数,比如块大小、rowNumberInBlock,以及跑累积,它们对块进行处理,并且不遵从行的独立性。
ClickHouse 具有强类型,因此隐式类型转换不会发生。如果函数不支持某个特定的类型组合,则会抛出异常。但函数可以通过重载以支持许多不同的类型组合。比如,plus 函数(用于实现 + 运算符)支持任意数字类型的组合:UInt8+Float32,UInt16+Int8 等。同时,一些可变参数的函数能够级接收任意数目的参数,比如 concat 函数。
实现函数可能有些不方便,因为函数的实现需要包含所有支持该操作的数据类型和 IColumn 类型。比如,plus 函数能够利用 C++ 模板针对不同的数字类型组合、常量以及非常量的左值和右值进行代码生成。
这是一个实现动态代码生成的好地方,从而能够避免模板代码膨胀。同样,运行时代码生成也使得实现融合函数成为可能,比如融合 « 乘 - 加 »,或者在单层循环迭代中进行多重比较。
由于向量查询执行,函数不会 « 短路 »。比如,如果你写 WHERE f (x) AND g (y),两边都会进行计算,即使是对于 f (x) 为 0 的行(除非 f (x) 是零常量表达式)。但是如果 f (x) 的选择条件很高,并且计算 f (x) 比计算 g (y) 要划算得多,那么最好进行多遍计算:首先计算 f (x),根据计算结果对列数据进行过滤,然后计算 g (y),之后只需对较小数量的数据进行过滤。
ClickHouse 数据存储架构
ClickHouse 数据存储架构由分片(Shard)组成,而每个分片又通过副本(Replica)组成。ClickHouse 分片有限免两个特点。
- ClickHouse 的 1 个节点只能拥有 1 个分片,也就是说如果要实现 1 分片、1 副本,则至少需要部署 2 个服务节点。
- 分片只是一个逻辑概念,其物理承载还是由副本承担的。
下面是 cluster 拥有 1 个 shard(分片)和 2 个 replica(副本),且副本由 192.37.129.6 服务节点和 192.37.129.7 服务节承载。从本质上看,这个配置是是一个分片一个副本,因为分片最终还是由副本来实现,所以这个其中一个副本是属于分片,分片是一个逻辑概念,它指的是其中的一个副本,这个和 Elasticsearch 中的分片和副本的概念有所不同。
<ch_cluster>
<shard>
<replica>
<host>192.37.129.6</host>
<port>9000</port>
</replica>
<replica>
<host>192.37.129.7</host>
<port>9000</port>
</replica>
</shard>
</ch_cluster>
ClickHouse 相关资料分享
ClickHouse 经典中文文档分享
资料参考:ClickHouse (02) ClickHouse 架构设计介绍概述与 ClickHouse 数据分片设计

ClickHouse docker in practice.
1. downlod click house server docker images
sudo docker pull yandex/clickhouse-server:19.9Note: you can choose the download the most fitable version by browsing the docker hub web site, in my practice, I used v19.9
2. start click house server docker container
docker run -d --name lenmom-clickhouse-server \
--ulimit nofile=262144:262144 \
-v $HOME/some_clickhouse_database:/var/lib/clickhouse \
-v /path/to/your/config.xml:/etc/clickhouse-server/config.xml \
yandex/clickhouse-server:19.9Note: if we don''t want to customize configuration, we can ommit the volumn to config.xml
for quick start click-house server, you can use the command as follows:
sudo docker run -d --name lenmom-clickhouse-server --ulimit nofile=262144:262144 yandex/clickhouse-server:19.9

3. download click house client docker image
sudo docker pull yandex/clickhouse-client:19.9
4. connect to click house server using client
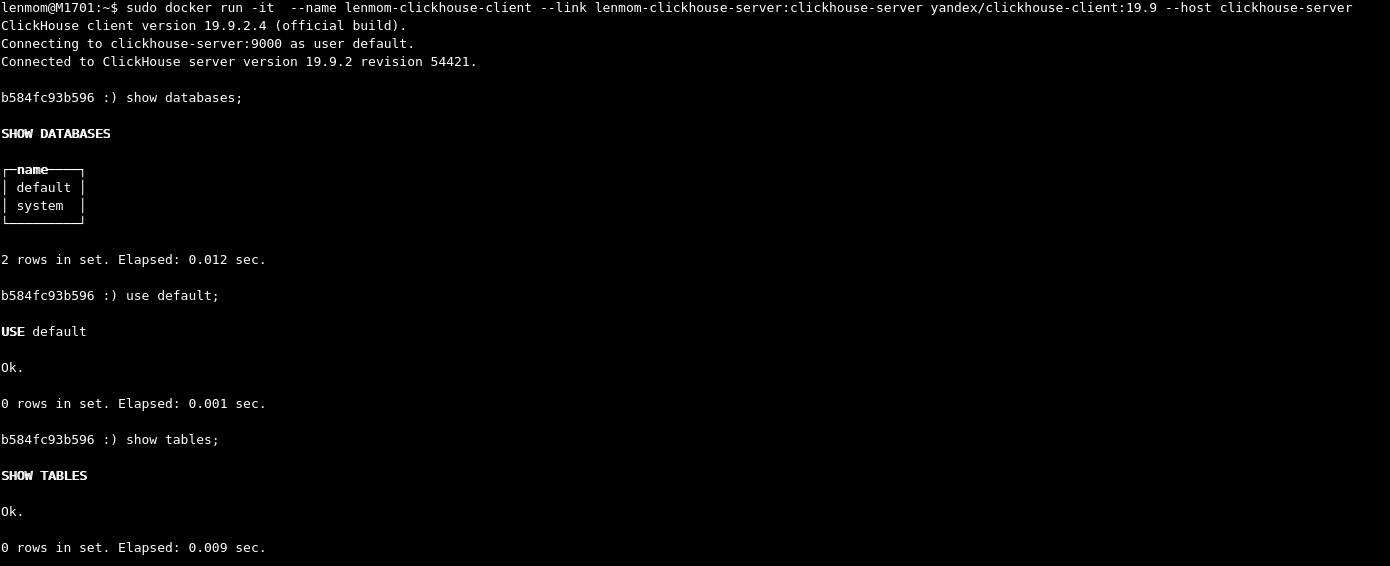
sudo docker run -it --name lenmom-clickhouse-client --link lenmom-clickhouse-server:clickhouse-server yandex/clickhouse-client:19.9 --host clickhouse-serverafter connected to the click-house server, it shows as follows:
")
Clickhouse 副本表和分片表(高可用)
使用的 CH 版本:19.16.9.37
官方的文档看得晕头转向,可能还是自己英文功底不够,在读完官方的相关文档后,自己又做了大量测试,总结一下心得。
推荐阅读的官方文档:
- https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication
- https://clickhouse.tech/docs/en/getting-started/tutorial/#cluster-deployment
- https://clickhouse.tech/docs/en/engines/table-engines/special/distributed
如果看完本文仍有疑惑的地方,建议阅读下官方文档。
在 CH 中单独提及“副本”涉及到两个概念,副本表和副本分片,顾名思义,一个是为表做副本,一个是为分片做副本。
为了避免混乱后面会分开说这两种副本。
副本表(replicated table)
副本表比较容易理解,所有的副本表之间会相互同步数据,注意是相互同步。
副本表从使用角度来看并没有主副之分,任何一个副本表都可以拿来正常使用,
因此在创建副本表时,即便是第一个副本表也需要用 Replicated* 系列引擎创建。
副本表依赖 zookeeper,但并不依赖集群。
我想再解释一下“副本表并不依赖集群”这句话:
首先,在多个实例上创建副本表时,副本表并不要求这些实例们必须组成集群,也就是说即便是两个毫无关系的 CH 实例,
只要他们之间可以通过网络互相访问,就可以在这两个实例上创建副本表,当然如果组成集群也是可以的;
其次,多个副本表也可以在单个 CH 中也可以创建出来,但个人认为这其实没有太大的意义,
因为这种模式下,副本数据的安全性在发生硬盘物理损坏时得不到保障。
创建副本表时,引擎函数最少需要两个参数,其他参数可以继续在括号内顺序填写:
- zookeeper_path
在 zookeeper 中创建的路径,用来标识一组副本表,同一组的副本表存储的都是相同的数据,它们之间互为副本,
同一组副本表在不同实例上创建时要使用相同的路径,示例:
/clickhouse/tables/replications/database_name/table_name - replica_name
在 zookeeper 中 zookeeper_path/replicas 路径下注册节点,用来识别同一组内的副本表,
组内每个副本表应该使用不同的 replica_name,建议使用 CH 实例服务器主机名或域名。
当 CH 实例比较多且实例间组成了集群时,可以使用 CH 的 DDL 特性,即 ON CLUSTER 语句,一次性在多个实例上创建副本表,
这种情况下,建表语句中的引擎函数就不能把 replica_name 参数写死了,官方推荐在配置文件中设置宏来进行自动替换。
此外,CH 服务的配置文件中有两个重要的配置项:
- interserver_http_host
- interserver_http_port
这两个参数用来设置副本表所在 CH 实例之间的通讯地址和端口,
各 CH 实例会将自己的地址注册到 zookeeper_path/replicas/replica_name/host 中,这样其他实例就知道怎么访问了。
如果 CH 实例是运行在 docker 容器内的,还需要注意以下两点:
- host 参数不能使用 0.0.0.0 或 127.0.0.1,需要使用明确的主机 IP,以确保其他实例可以正常访问
- port 参数设置的值需要在创建容器时增加对应的端口映射
副本表示例
这里使用两个 CH 实例进行搭建,二者可以互通,主机名分别为:DBServerA 和 DBServerB。
在 DBServerA 上部署并启动一个 Zookeeper 服务,然后再分别在两台机器上部署并启动两个 CH 服务。
启动前注意修改服务配置文件,将 zookeeper 配置好。
分别连接到两个 CH 实例,命令行或图形化客户端均可,在 DBServerA 上执行如下 SQL 创建第一个副本表:
1 2 3 4 5 |
CREATE TABLE default.test (`data` Float64) ENGINE = ReplicatedMergeTree(''/clickhouse/tables/replications/default/test'', ''DBServerA'') ORDER BY `data` SETTINGS index_granularity = 8192 |
在 DBServerB 上执行如下 SQL 创建第二个副本表:
1 2 3 4 5 |
CREATE TABLE default.test (`data` Float64) ENGINE = ReplicatedMergeTree(''/clickhouse/tables/replications/default/test'', ''DBServerB'') ORDER BY `data` SETTINGS index_granularity = 8192 |
可以看到上面两个 SQL 分别在两个 CH 实例上创建了两个同名的表:test,
使用了 ReplicatedMergeTree 引擎,引擎函数的第一个参数是相同的,用来表示这两个副本表是同一组的,存储的是相同的数据。
引擎函数的第二个参数是不同的,用来表示这个组内共有两个副本表。
在 DBServerA 上执行如下 SQL 插入一条数据:
1 2 3 |
insert into default.test values (6) |
插入完成后可以在两个 CH 实例中执行 SELECT 语句查看,会发现 DBServerB 中也有了这一条值为 1 的数据。
也可以在 DBServerB 上继续执行插入语句,注意修改值 1 到其他值,会发现 DBServerA 也会自动同步过去。
关闭 DBServerA 的 CH 服务,继续在 DBServerB 上执行插入,修改,删除操作后,再启动 DBServerA 上的 CH 服务,
会发现 DBServerA 将自己同步到了与 DBServerB 相同的状态。
至此,同步表测试完成。
副本分片
副本分片(replica)依赖 zookeeper 和集群。
需要了解 CH 的集群知识才能理解副本分片,首先不考虑副本,我们先看看什么是分片?
先来看一段 CH 集群的最简配置,两台机器组成集群:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<remote_servers incl="clickhouse_remote_servers" > <my_test_cluster> <shard> <replica> <host>192.168.1.101</host> <port>9000</port> </replica> </shard> <shard> <replica> <host>192.168.1.102</host> <port>9000</port> </replica> </shard> </my_test_cluster> </remote_servers> |
上述配置创建了一个名为:my_test_cluster 的集群,整个集群的数据被拆分为两个分片,每个分片有一个 CH 节点,
之所以称之为分片,是从集群数据角度来看的,每个分片只包含整个集群的一部分数据,当需要查询整个集群的数据时,
需要使用到 CH 的分布式表引擎。
再来看上述配置,每一个 shard 小节就是一个分片,而 shard 小节内部的 replica 即为副本分片。
在这里明确强调一下两个概念:
- shard:分片,集群完整数据的一部分
- replica:副本分片,真正为分片存储数据的地方,当仅有一个 replica 时,shard 等价于 replica
分片的概念不能与 CH 实例或节点划等号的,分片只与数据有关,分片更像是节点的上一层概念。
有多少分片就意味着数据被拆分成了多少份,倒是副本分片的存在方式与节点差不多。
**
注意!一个分片下的 CH 实例是不可以在其他分片下再次出现的,否则在查询数据时就会出问题,
CH 有可能会重复查询出同一分片下的数据,我留意到国内有不少相关文档出现了此错误。
**
只配置一个副本分片时 CH 集群就已经可以正常工作了,在通过分布式表引擎查询整个集群的数据时,
就会使用到所有节点的硬件资源,但是这种形式的集群可称之为高性能集群,但没有丝毫高可用性的保障,
因为任何一个节点掉线时,都会导致查询报错。
设置多个副本分片(replica)的目的就是为了提高可用性,其配置方法也很简单,
就是在一个 shard 小节内部配置多个 replica 小节即可,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<remote_servers incl="clickhouse_remote_servers" > <my_test_cluster> <shard> <internal_replication>false</internal_replication> <replica> <host>192.168.1.101</host> <port>9000</port> </replica> <replica> <host>192.168.1.103</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>false</internal_replication> <replica> <host>192.168.1.102</host> <port>9000</port> </replica> <replica> <host>192.168.1.104</host> <port>9000</port> </replica> </shard> </my_test_cluster> </remote_servers> |
当一个分片拥有了多个副本分片时,就相当于有了备用军。
在某个副本出现问题导致掉线后,分布式表引擎在查询这一分片的数据时,会自动到可用的副本上去查找数据。
但如果一个分片的所有副本都掉线的话,那集群也是不能工作的,可以将分片的副本实例部署在多地区多机房来尽量避免这种问题。
副本分片的数据同步
到这里看起来一切都很美好,我原以为设置完多个副本分片后,它们之间就会自动相互同步,
但其实副本分片与前面提到的副本表完全不同,它并不会自动将一个副本上的所有表同步到其他副本上。
副本分片只能保证明确指定的表之间的同步关系,其他表则不会同步。
要想保持副本分片中的指定表的数据是同步的,从操作方法来看有三种方法:
- 普通表 + 分布式引擎表写入能力 +
internal_replication(false) - 副本表 + 分布式引擎表写入能力 +
internal_replication(true) - 副本表
前两种方法都涉及到一个非常关键的配置项:internal_replication(上面多副本分片示例配置中有)。
要解释这个配置项需要先了解分布式引擎表,文章开头的链接中有官方文档,这里只笼统得提一下它的作用:
1 |
分布式引擎表提供了 CH 集群模式下的跨分片读写能力。 |
而这个配置项则控制了分布式引擎表的数据写入行为:
- 设置为
false时,分布式引擎表会把分到一个分片下的数据,写入到所有副本分片上,false也是默认值。 - 设置为
true时,分布式引擎表只把分到一个分片下的数据,写入到发现的第一个可用副本分片上。
同步方法 1(不推荐)
首先需要说明的是,第一种方法官方不推荐使用,因为这种方法 CH 不能保证副本分片的数据一致性,
多个副本分片里的数据随着时间的推移会出现数据不一致的情况。
虽然此方法不被推荐,但为了文章内容完整性,还是简单说一下用法。
其实有了前面的知识积累,用法已经很明朗了,核心就是让分布式表引擎在写数据时主动写多份。
- 确保
internal_replication选项设置为false - 创建一个包含两个分片的集群,每个分片包含两个副本分片
- 在四个节点上创建普通数据表:
test,注意不能是副本表 - 在四个节点上创建分布式引擎表:
test_all,其读写上面test表 - 在任一节点上往
test_all表写入多次数据 - 在四个节点上分别查询
test表内容,查看属于同一分片的表内容是否相同 - 不出意外应该是相同的,这表示这种方法已经走通了
同步方法 2
这第二种方法的同步原理则是利用了副本表,CH 通过 zookeeper 可以保证数据的一致性。
上层应用将数据写入分布式引擎表,其根据配置将数据分为多个块,分别写入各个分片。
由于副本表已经提供了数据同步功能,因此需要将 internal_replication 设置为 true,
告诉分布式引擎一个分片的数据,只需要写完成一个分片副本即可。
同步方法 3
方法 3 与 方法 2 核心相同,但不使用分布式引擎表的写能力,故而也不需要配置 internal_replication。
这种方法使用的场景是:集群分为多个分片,每个分片上的数据有着明确的界限,虽然可以最终聚合在一起查询,但数据的写入和存储都需要分开,说起来有点类似于分库分表的概念。
由于不使用分布式表引擎写能力,因此上层应用需要分别与不同分片上的节点建立数据库连接,将数据分别写入,
个人更推荐的方法是将上层应用根据业务或者说数据界限拆分成多个模块,分别对应多个分片,各自写各自的数据,
最后上层应用提供给使用者的查询接口则是用分布式表引擎来查询所有分片的数据,即整个集群的数据。
高可用集群示例
这里使用同步方法 2 举例高可用集群的搭建方法。
使用四个 CH 实例进行搭建,它们之间可以互通,它们的 IP 地址分别为:
- 192.168.1.101
- 192.168.1.102
- 192.168.1.103
- 192.168.1.104
后续使用 101 102 103 104 简称它们。
在 101 上部署并启动一个 Zookeeper 服务,然后再分别在四台机器上部署并启动 CH 服务。
启动前注意修改服务配置文件,有两点需要修改:
- zookeeper 配置项
- cluster 配置项,四台机器配置相同,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33<!-- 方法 1 依赖 internal_replication 为 false 方法 2 依赖 internal_replication 为 true 方法 3 忽略 internal_replication 的配置 且方法 1 不推荐使用,那么综上条件,无论使用方法 2 还是 3, 都建议始终配置 internal_replication 为 true --> <remote_servers incl="clickhouse_remote_servers" > <my_test_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>192.168.1.101</host> <port>9000</port> </replica> <replica> <host>192.168.1.103</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>192.168.1.102</host> <port>9000</port> </replica> <replica> <host>192.168.1.104</host> <port>9000</port> </replica> </shard> </my_test_cluster> </remote_servers>
上述配置设置了一个名为 my_test_cluster 的集群,整个集群中的数据被分为了两份,即共两个分片,每个分片内有两个副本分片。
1 2 3 4 5 6 7 8 9 10 11 |
-- 101 / -- shard01 -- / \ / -- 103 cluster -- \ -- 102 \ / -- shard02 -- \ -- 104 |
我们计划让每组副本分片内部节点上数据完全相同,所以要确保所有新建的数据表(不包括分布式引擎表)都是用副本表,
在这里我们认为 101 和 103 属于一组,组名为 shard01,而 102 和 104 属于另一组,组名为 shard02。
需要在 101 和 103 上创建同组副本表,在 102 和 104 上创建另一组副本表,控制是否是同一组的方法是建表时的引擎参数。
分别连接到四个 CH 实例,命令行或图形化客户端均可,在 101 节点上执行如下 SQL 创建一个副本表:
1 2 3 4 5 |
CREATE TABLE default.test (`data` Float64) ENGINE = ReplicatedMergeTree(''/clickhouse/tables/shard01/default/test'', ''101'') ORDER BY `data` SETTINGS index_granularity = 8192 |
在 103 节点上执行如下 SQL 创建一个副本表:
1 2 3 4 5 |
CREATE TABLE default.test (`data` Float64) ENGINE = ReplicatedMergeTree(''/clickhouse/tables/shard01/default/test'', ''103'') ORDER BY `data` SETTINGS index_granularity = 8192 |
在 102 节点上执行如下 SQL 创建一个副本表:
1 2 3 4 5 |
CREATE TABLE default.test (`data` Float64) ENGINE = ReplicatedMergeTree(''/clickhouse/tables/shard02/default/test'', ''102'') ORDER BY `data` SETTINGS index_granularity = 8192 |
在 104 节点上执行如下 SQL 创建一个副本表:
1 2 3 4 5 |
CREATE TABLE default.test (`data` Float64) ENGINE = ReplicatedMergeTree(''/clickhouse/tables/shard02/default/test'', ''104'') ORDER BY `data` SETTINGS index_granularity = 8192 |
可以看到上面 4 个 SQL 分别在 4 个节点上创建了 4 个同名的表:test,使用了 ReplicatedMergeTree 引擎,
其中 101 和 102 一组所以引擎函数的第一个参数是相同的,103 和 104 同理,引擎函数的第二个参数是不同的,用来标识出每一个副本表。
接着创建分布式引擎表用来查询整个集群的完整数据,在 4 个节点上都执行如下 SQL:
1 2 |
CREATE TABLE default.test_all AS default.test ENGINE = Distributed(my_test_cluster, default, test, rand()) |
接着开始验证集群内同步和高可用能力,在 101 节点上执行如下 SQL 插入一条数据:
1 2 3 |
insert into default.test values (1) |
在 102 节点上执行如下 SQL 插入一条数据:
1 2 3 |
insert into default.test values (2) |
执行完成后可以在 4 个节点上查询 test 表,会发现除了 101 节点,103 中也有了这一条值为 1 的数据,但没有值为 2 的数据;而 102 和 104 上只有值为 2 的数据,这说明分片内副本表同步工作正常。
接着在任一节点上查询 test_all 表,会发现可以查出 1 和 2 两条数据,这说明集群跨分片读取功能正常。
然后执行如下 SQL 直接往 test_all 表插入数据,建议调整 SQL 中的值多次执行插入操作,因为一两次的插入操作可能都为分配到同一个分片上:
1 2 3 |
insert into default.test_all values (2) |
每执行一次插入操作,就分别查询一次所有节点上的 test 表和 test_all 表来观察集群行为,会发现数据会被随即分配到两个分片上,分片内部的副本分片(副本表)则会始终保持同步。
关闭掉 101 节点,在剩余节点上查询 test_all 表发现集群工作正常,数据也没有缺失,接着关闭 103 节点,然后在剩余节点上查询 test_all 表发现会报错,说明如果一个分片上的所有分片副本都掉线的话,则集群瘫痪。
接着恢复 101 节点,然后再查询 test_all 表发现集群工作正常,说明集群可以自动重连掉线节点;在 101 节点上插入、删除、修改一些数据,再启动 103 节点,再查询 103 节点上的 test 表,发现在 103 掉线时组内 101 节点的操作都已经同步到了 103 上。
至此,高可用集群测试完成。
其它问题
上述方案仔细分析的话会发现只做到了集群内部的高可用,这对于上层应用来说还不够。
比如沿用上述高可用配置的例子,上层应用使用了 104 节点作为整个集群的外部出入口,只与 104 建立了连接,如果 104 节点掉线了的话,即便集群内部高可用优化的再好,上层应用也无法使用集群。
这种情况下如果不想改动上层应用,或者说想对上层应用屏蔽高可用实现细节,可以使用 keepalived 技术,为整个集群所有节点创建一个虚拟 IP,上层应用只与这个虚拟 IP 连接就可以了。关于 keepalived 的具体使用方法就不在这篇文章里展开了。
https://listenerri.com/2021/03/11/Clickhouse-%E6%95%B0%E6%8D%AE%E5%89%AF%E6%9C%AC%E4%B8%8E%E9%9B%86%E7%BE%A4%E9%AB%98%E5%8F%AF%E7%94%A8/
https://bbs.huaweicloud.com/blogs/375043
https://blog.csdn.net/haveanybody/article/details/123983070

ClickHouse 表引擎 & ClickHouse性能调优 - ClickHouse团队 Alexey Milovidov

https://clickhouse.com/
引子
什么是“更快”?
顺序读/写吞吐量?
随机读/写延迟?
特定并行性和工作负载下的IOPS。
显然RAM可能比磁盘慢,例如单个clnannel RAM与10倍 PCIe 4.0 SSD。
Why ClickHouse
Our feature rich and hardware efficient OLAP data management system is the right choice for your organization.
Performance
ClickHouse supports best in the industry query performance, while significantly reducing storage requirements through our innovative use of columnar storage and compression.
Scalability
Battle tested in production, with linear horizontal scalability from single-server deployments to clusters with many thousands of nodes.
Reliability
ClickHouse deployments feature best in class availability. There are no single points of failure, with the architecture supporting multi-master replication, performing effectively in multi-region configurations.
Security
ClickHouse comes with enterprise grade security features and fail-safe mechanisms protecting against data corruption from application bugs and human errors.
Quick Start
MacOS安装:
wget ''https://builds.clickhouse.com/master/macos/clickhouse''
chmod a+x ./clickhouse
./clickhouse
https://clickhouse.com/
ClickHouse 表引擎
引擎表决定:
数据的存储方式和存储位置:写入数据的位置&读取数据的位置
支持哪些请求以及如何支持
并行数据访问
如果有索引,请使用
是否可以执行多线程查询
数据复制
读取数据时,引擎只需要检索所需的列集。但是,在某些情况下,查询可能会在表引擎中部分处理。
MergeTree 系列的引擎用于最重要的任务。
小日志表引擎 TinyLog
最简单的表引擎,它将数据存储在磁盘上。每列都存储在一个单独的压缩文件中。在编写时,数据被附加到文件的末尾。
无并发数据访问限制:
如果从一个表中读取,在另一个查询中写入会报错
如果同时在多个查询中写入该表,数据将被破坏
使用该表的典型方法是一次写入:只写入一次数据,然后根据需要多次读取数据。请求在一个线程中执行。换句话说,这个引擎是为相对较小的表准备的(建议最多 100 万行)。如果你有很多小表,那么使用这个表引擎是有意义的,因为它比日志引擎更简单(需要打开的文件更少)。当你有大量的小表时,这种情况会导致效率低下。也不支持索引
TinyLog 表用于小批量处理的中间数据。
日志引擎
Log 和 TinyLog 的区别在于一个小的“标签”文件与一个列文件并存。
这些标签写在每个数据块上,并包含一个偏移量,指示从哪里开始读取文件以跳过指定的行数。这允许在多个线程中读取表数据。对于并发数据访问,读操作可以并发进行,而写操作则相互阻塞读和读。日志引擎不支持索引。同样,如果写入表失败,该表将被销毁并且从中读取数据将返回错误。注册机制适用于临时数据、写表、测试或演示。
内存引擎
内存引擎将未压缩的数据存储在 RAM 中。数据的存储方式与读取时接收到的数据完全相同。换句话说,从该表中读取是完全免费的。并行数据访问是同步的。锁很短:读和写操作不会互相阻塞。不支持索引。阅读是并行的。由于不会从磁盘读取、解压缩或反序列化数据,因此可以通过简单的查询实现最高性能(超过 10 Gbps)。(请注意,在许多情况下,MergeTree 引擎的性能几乎一样好。)
当服务器重新启动时,数据从表中消失,表变为空。通常,这个表引擎是不实用的。但是,它可以在相对较少的行数(约 100 万条)中用于测试和需要最大速度的任务
系统使用内存机制作为带有外部查询数据的临时表(参见“处理查询的外部数据”一节)并实现全局 IN(参见“运算符”一节)。
合并树MergeTree 引擎
MergeTree¶
The most universal and functional table engines for high-load tasks. The property shared by these engines is quick data insertion with subsequent background data processing. MergeTree family engines support data replication (with Replicated* versions of engines), partitioning, secondary data-skipping indexes, and other features not supported in other engines.
Engines in the family:
MergeTree
ReplacingMergeTree
SummingMergeTree
AggregatingMergeTree
CollapsingMergeTree
VersionedCollapsingMergeTree
GraphiteMergeTree
MergeTree 引擎支持主键和日期的索引,并提供实时更新数据的能力。它是 ClickHouse 中最先进的桌面引擎。不要将此与合并引擎混淆
该机制接受参数:包含日期的日期类型列的名称、选择表达式(可选)、定义表主键的元组以及索引的粒度。例如:
没有采样支持的示例:
MergeTree(EventDate, (CounterID, EventDate), 8192)
带采样支持的示例:
MergeTree(EventDate, intHash32(UserID), (CounterID, EventDate, intHash32(UserID)), 8192)
MergeTree 类型表必须有一个单独的日期列。在本例中,它是“EventDate”列。日期列类型必须是“DATE”(不是“DateTime”)
主键可以是任何表达式的元组(通常只是列的元组),也可以是单个表达式。
要检查 ClickHouse 在执行查询时是否可以使用此索引,请使用 force_index_by_date 和 force_primary_key 参数。
您可以使用一个大表并以小块的形式不断向其中添加数据 - 这就是 MergeTree 的目的
MergeTree族中所有的表类型都可以复制。
自定义分区键:
自定义节键:从 1.1.54310 版本开始,您可以在 MergeTree 系列中创建任何节表达式(不仅仅是按月)
分区键可以是表列表达式或此类表达式的集合(类似于主键)。分区键可以省略。创建表时,使用新语法在机制描述中指定部分键:
ENGINE [=] Name(...) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
对于MergeTree表,section表达式在section之后指定,主键在order之后,fetch key在fetch之后,参数可以指定索引的粒度(可选;默认为8192)等来自MergeTreeSettings.h。设置。
例如:
ENGINE = ReplicatedCollapsingMergeTree(''/clickhouse/tables/name'', ''replica1'', Sign)
PARTITION BY (toMonday(StartDate), EventType)
ORDER BY (CounterID, StartDate, intHash32(UserID))
样本由 intHash32(用户 ID)
要在 ALTER PARTITION 命令中指定节,请指定节(或元组)表达式的值。支持常量和常量表达式。例子:
ALTER TABLE table DROP PARTITION(toMonday(today()),1)
使用事件类型 1 删除本周的部分。优化查询也是如此。要在单分区表中指定单个节,请为节 () 指定一个元组。
段号含义:
之前:2014031720140323220(最小数据-最大数据-最小块-最大块系列)
之后:201403220(部分 ID - 最小块数 - 最大块级别)
节标识符是它的字符串标识符(如果可能是人类可读的),用于命名文件系统和 ZooKeeper 中的数据组件。您可以在 ALTER 查询中指定部分键。例如:section key toYYYYMM(EventDate); ALTER 可以指定节 201710 或节 ID“201710”
替换合并树ReplacingMergeTree
此引擎表与 MergeTree 的不同之处在于它删除具有相同主键值的重复记录。
表引擎的最后一个可选参数是版本列。连接时,所有具有相同主键值的行将减少为一行。如果指定了版本列,则保留版本最高的行,否则保留最后一行。
ReplacingMergeTree(EventDate, (OrderID, EventDate, BannerID, ...), 8192, ver)
版本列类型必须是UInt相关的Date,或者DateTime。
请注意,数据仅在合并过程中重复。合并发生在后台的未知时间,因此您无法安排它。部分数据仍无法处理
虽然您可以使用优化查询来执行计划外合并,但不要指望使用它们,因为优化查询会读取和写入大量数据。
因此,替换mergetree适合在后台去除重复数据以节省空间,但不能保证没有重复数据。
求和合并树 SummingMergeTree
这种机制与 MergeTree 的不同之处在于它在合并时收集数据。
SummingMergeTree(EventDate, (OrderID, EventDate, BannerID, ...), 8192)
总列数是隐式的。连接时,具有相同主键值(在本例中为 OrderId、EventDate、BannerID ...)的所有行都有自己的值,并且它们都不是主键的一部分。
SummingMergeTree(EventDate, (OrderID, EventDate, BannerID, ...), 8192, (Shows, Clicks, Cost, ...))
列的总数是明确设置的(最后一个参数是显示、点击、成本...)。连接时,所有具有相同主键值的行在指定列中都有它们的值。指定的列也必须是数字,并且不能是主键的一部分。
对于不属于主键的其他行,将选择串联中选择的第一个值。
这个桌面引擎不是特别有用。请记住,如果您保存预先聚合的数据,将会失去一些系统优势。
聚合合并树 AggregatingMergeTree
这种机制与 MergeTree 的不同之处在于合并将存储在表中的聚合函数的状态组合成具有相同主键值的行。为了使其工作,它在聚合和聚合数据类型上使用 -State 和 -Merge 修饰符。
请注意,在大多数情况下,使用聚合合并树是不切实际的,因为查询可以有效地在非聚合数据上运行。
折叠合并树CollapsingMergeTree
这个引擎是专门为 Yandex.Metrica 设计的
它与 MergeTree 的不同之处在于,它允许在连接时自动删除或折叠某些行。
Yandex.Metrica 具有正常日志(例如,命中日志)和更改日志。更改日志用于逐步计算数据更改统计信息。例如会话更改日志或记录用户历史的日志。在 Yandex.Metrica 中,对话不断变化。例如,每个会话的点击次数增加。我们称任何对象的变化为一对(“旧值,新值”)。如果创建了对象,则旧值可能会丢失。如果对象被删除,新值可能会丢失。如果对象已被修改,但之前存在且未被删除
CollapsingMergeTree(EventDate, (CounterID, EventDate, intHash32(UniqID), VisitID), 8192, Sign)
这里的 Sign 是一列,其中包含 -1 代表“旧”值和 1 代表“新”值
拼接时,每组顺序主键值(用于对数据进行排序的列)减少到不超过一行,“signcolumn = -1”(负行)列的值减少到no多于一行,且列值“signcolumn = 1”(“正线”)。换句话说,更改日志中的条目将被折叠。
————————————————————————————————————————
数据复制
复制仅支持来自 MergeTree 系列的表。复制工作在单个表的级别,而不是整个服务器。服务器可以存储复制表和非复制表。
插入和修改被复制(有关更多信息,请参阅 ALTER)。复制压缩数据,而不是请求文本。CREATE、DROP、ATTACH、DETACH 和重命名请求。它们不会被复制。换句话说,它们属于同一台服务器。CREATE TABLE 查询在运行查询的服务器上创建一个新的复制表。如果此表已存在于其他服务器上,它将添加一个新副本。DROP TABLE 查询删除运行该查询的服务器上的副本。RENAME 查询重命名副本中的表。换句话说,复制的表可能有
复制是异步和多主的。插入(和 ALTER)请求可以发送到任何可用的服务器。数据插入到这个服务器,然后发送到其他服务器。由于数据是异步的,最近插入的数据会滞留在其他副本上。如果副本的一部分不可用,那么当它们可用时,它们的数据将被写入。如果副本可用,则延迟是通过网络传输压缩数据块所需的时间。
如果您将一个数据包写入副本,并且在该数据有时间到达其他副本之前,拥有该数据的服务器已不复存在,则数据将丢失。
在复制过程中,只有粘贴的原始数据通过网络传输。进一步的数据转换(合并)是一致的,并以相同的方式对所有副本执行。这将最大限度地减少网络使用,这意味着当副本位于不同的数据中心时,复制可以很好地工作。(请注意,跨不同数据中心复制数据是复制的主要目的。)
创建复制表
故障后恢复
如果报告异常,系统会检查本地文件系统中的数据集是否与预期的数据集匹配(ZooKeeper 存储了此信息)。如果存在小的不一致,系统会通过将数据与副本同步来纠正它们。
如果系统检测到损坏的数据片段(错误的文件大小)或无法识别的片段(部分写入文件系统,但未写入 ZooKeeper),它会将它们移动到“单独的”子目录(它们不会被删除)。任何丢失的片段从副本中复制
请注意,ClickHouse 不会执行任何破坏性操作,例如自动删除大量数据。
如果本地数据与预期数据偏差太大,则会触发安全机制。服务器将其输入日志并拒绝启动。这是因为这种情况可能表示配置错误,例如,如果一个段的副本被意外配置为另一个段的副本。但是,此机制的阈值设置得足够低,以至于它可以在正常恢复过程中发生。在这种情况下,数据会通过“按下按钮”自动恢复
数据完全丢失后的恢复
如果服务器上的所有数据和元数据都消失了,请按照以下步骤进行恢复:
1.在服务器上安装 ClickHouse。如果您正在使用它,请在包含分段标识符和副本的配置文件中正确定义替换。
2.如果你有非复制表,你必须手动复制服务器,从复制中复制它们的数据(在/var/lib/clickhouse/data/db_name/table_name/目录下)
3.复制表定义位于/var/lib/clickhouse/metadata/replica。如果在表定义中明确定义了段或副本 ID,请更正它以匹配该副本。(还要启动服务器并允许对表进行任何其他查询,它应该在 /var/lib/clickhouse/metadata/.sql 中。)
4.运行恢复,使用任何创建管理节点/path_to_table/replicant_name/flag/force_restore_data 或运行此命令来恢复所有复制的表:sudo -u clickhouse touch /var/lib/clickhouse/flags/force_restore_data
在恢复期间,网络带宽不受限制。如果您要同时恢复多个副本,请记住这一点。
从 MergeTree 转换为 ReplicatedMergeTree
如果不同副本上的数据不同,请先同步数据或删除除一个副本外的所有副本上的数据。
从 ReplicatedMergeTree 转换为 MergeTree
创建一个具有不同名称的 MergeTree 表。将合并树表的复制数据中的所有数据移动到新表的数据目录中。然后删除复制的mergetree表并重启服务器。
删除.sql文件对应的元数据目录
删除ZooKeeper中对应的路径(/pathtotable/replicaname)。
之后,您可以启动服务器,创建 MergeTree 表,将数据移动到其目录,然后重新启动服务器。
ZooKeeper 集群中的元数据丢失或损坏时的恢复
如果 ZooKeeper 数据丢失或损坏,您可以通过将数据移动到上述非重做表来保存数据。
如果其他副本具有相同的部分,请将它们添加到工作集中。如果不是,那么这些部分将从它们所属的副本中加载。
分布式表引擎 DistributedTableEngine
分布式:分布式引擎本身不存储数据,但允许跨多个服务器进行分布式查询处理,查询是自动并行的。在读取数据期间,如果有的话,将使用远程服务器上的表索引。
分布式引擎接受参数:
服务器配置文件中的集群名称、远程数据库名称、远程表名称和(可选)分片键
Distributed(logs, default, hits[, sharding_key])
默认情况下,将从日志集群中的所有服务器读取数据。命中位于集群中的每台服务器上。数据不仅会被读取,还会在远程服务器上进行部分处理(在某种程度上,这是可能的)。例如,对于 GROUP BY 查询,数据将在远程服务器上聚合,聚合函数的中间状态将发送到请求服务器。然后将数据进一步聚合。
有两种方式将数据写入集群:
首先,您可以定义哪些服务器要写入哪些数据,并直接对每个块执行写入操作。换句话说,插入操作是在表的分布式表“视图”上执行的。这是最灵活的解决方案 - 您可以使用由于域的需要而可能不重要的任何拆分解决方案。这也是一个最佳解决方案,因为数据可以完全独立地写入不同的段。
其次,您可以对分布式表执行插入操作。在这种情况下,表会将插入的数据传播到服务器本身。要将其写入分布式表,它必须设置一个分片键(最后一个参数)。另外,如果只有一个split,写操作不指定segment key,因为在这个例子中没有意义。
每个分片都可以在配置文件中定义其权重。默认情况下,权重为 1。数据分布在分片之间,与分片的权重成正比。例如,如果有两个分区,第一个的权重是 9,第二个是 10,那么第一个将在字符串的 9/19 部分上发送,第二个将在 10/19 上发送。
每个片段可以在配置文件中定义“internal_replication_system”参数。
如果此参数设置为true,则写入操作将选择第一个健康副本并将数据写入其中。如果分布式表“查找”复制的表,则使用此替代方法。换句话说,用于记录数据的表将被自己复制。
如果设置为 false(默认值),数据将写入所有副本。基本上,这意味着分布式表会复制数据本身。这比使用副本表更糟糕。由于副本没有经过一致性检查,它们会随着时间的推移而略有不同。
请求使用特定键连接到数据(IN 或 JOIN)。如果数据用这个key分隔,可以使用local IN或JOIN代替GLOBAL IN或GLOBAL JOIN,效率更高
大量服务器(数百个或更多)使用大量小请求(来自一个客户、网站、广告商或合作伙伴的请求)。为了防止小查询影响整个集群,将一个客户端的数据放在一个段中是有意义的。或者就像我们在 Yandex 中所做的那样。您可以设置双向分片:将整个集群划分为“层”,其中一层可以由多个分片组成。一个客户的数据位于一层,但可以根据需要在该层中添加切片,数据随机分布。
数据是异步写入的。插入分布式表,数据块只写入本地文件系统。数据会尽快发送到后台远程服务器。您应该检查文件列表(数据等待发送)检查数据是否发送成功
如果服务器不存在,或者插入分布式表后发生暴力重启(例如设备故障),插入的数据可能会丢失。如果在表目录中发现损坏的数据块,则将其移动到“损坏”的子目录中,不再使用。
合并机制(不要与 MergeTree 混淆)本身不存储数据,但允许您同时读取任意数量的其他表。阅读是自动并行的。不支持写入表。读取时,如果存在,将使用正在读取的表的索引。合并机制采用参数:数据库名称和表正则表达式。
Merge(hits,''^WatchLog'')
数据将从“matches”数据库中的表中读取,这些表的名称匹配正则表达式,正则表达式区分大小写。
除了数据库名称之外,您还可以使用返回字符串的常量表达式。例如currentDatabase()
合并机制的一个典型用途是使用大量的 TinyLog 表,就像使用单个表一样。
虚拟列
虚拟列:虚拟列是表引擎提供的列,与表定义无关。换句话说,这些列未列在 CREATE TABLE 中,但它们是可选的。
虚拟列和常规列的区别如下:
它们未列在表定义中
无法将数据添加到 INSERT
当使用 INSERT 而不指定列列表时,虚拟列将被忽略
使用星号 (SELECT) 时,它们不会被选中
虚拟列不会出现在 SHOW CREATE TABLE 和 DESC 表查询中
缓冲
缓存:缓冲数据以写入 RAM 并定期将其刷新到另一个表。在读操作期间,数据同时从缓冲区和另一个表中读取。
Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes)
Buffer 参数说明:
database,table:数据更新到哪个库表。除了数据库名称之外,您还可以使用返回字符串的常量表达式。
num_layers :并行层数。在物理上,该表将在单独的缓冲区中显示为“num_layers”。推荐值:16.
mintime, maxtime, minrows, maxrows, minbytes 和 maxbytes 都是用于从缓冲区更新数据的条件。
如果满足所有“最小”条件或至少一个“最大”条件,则从缓冲区更新数据并写入目标表。从第一次写入缓冲区的时间,从 seconds 到 seconds, minrows , maxrows - 缓冲区中行数的条件。最小字节,maxbytes - 缓冲区中字节数的条件。
在写操作期间,数据被插入到一个随机的 numlayers 缓冲区中。或者,如果插入的数据块足够大(超过 maxrows 或 maxbytes),则直接写入目标表,跳过缓冲区。
例如:
CREATETABLEmerge.hits_bufferASmerge.hitsENGINE= Buffer(merge, hits,16,10,100,10000,1000000,10000000,100000000)
创建合并。与“合并”具有相同结构的 Hitsbuffer 表。单击并使用缓冲引擎。写入此表时,数据将缓存在 RAM 中,然后写入“联合”。敲桌子。已创建 16 个缓冲区。如果写入超过 100 秒或 100 MB 的数据或 100 MB 的数据,则将更新所有数据。或者,如果同时过去了 10 秒并且写入了 1000 行和 10 MB 的数据。如果只记录一行,100秒后会更新。如果写了很多行,数据很快就会更新。
当服务器使用 DROP TABLE 或单独的表停止时,缓冲的数据也将在目标表中更新。
您可以为数据库和表名称设置空单引号字符串。这表明没有目标表。在这种情况下,当达到数据更新条件时,缓冲区将被清除。这对于将数据窗口保存在内存中很有用。
从缓冲区表中读取数据时,无论是从缓冲区还是从目标表(如果有),都必须对数据进行处理。请注意,缓冲表不支持索引。换句话说,缓冲区中的数据被完全扫描,这对于大缓冲区来说可能很慢。(从属表中的数据将使用它支持的索引。
如果服务器异常重启,缓冲区中的数据就会丢失。如果您需要对从属表和缓冲区表运行 ALTER,我们建议您先删除缓冲区表,在从属表上运行 ALTER,然后重新创建缓冲区表。如果缓冲表中的列集与从属表中的列集不匹配,则在两个表中插入列的子集。
当数据添加到缓冲区时,其中一个缓冲区被阻塞。如果同时从表中执行读操作,会造成延迟。
MergeTree vs Memory
ClickHouse中有多个表引擎:
MergeTree表将数据存储在磁盘上。
内存表将数据存储在内存中。
RAM比磁盘快, 那么内存表比MergeTree快吗?
本文同步分享在 博客“东海陈光剑”(CSDN)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
我们今天的关于Docker快速搭建Clickhouse集群(3分片3副本)和docker clickhouse集群的分享就到这里,谢谢您的阅读,如果想了解更多关于ClickHouse (02) ClickHouse 架构设计介绍概述与 ClickHouse 数据分片设计、ClickHouse docker in practice.、Clickhouse 副本表和分片表(高可用)、ClickHouse 表引擎 & ClickHouse性能调优 - ClickHouse团队 Alexey Milovidov的相关信息,可以在本站进行搜索。
本文标签:




